Pytorch7深度学习计算
本文介绍了深度学习中的块和层概念,通过PyTorch实现自定义神经网络组件。主要内容包括:1)块的基本功能与编程实现,包括前向传播和参数存储;2)从零构建多层感知机(MLP)类,展示如何继承nn.Module并实现关键方法;3)仿制Sequential类的实现原理,通过有序字典管理网络层;4)讨论在自定义块中执行任意代码和控制流的灵活性。文章通过代码示例演示了如何组合简单层构建复杂模型,为理解神经
深度学习计算
对于深度学习方面的研究来说,理解计算是入门的基础,本文将结合实践带你快速入门。推荐先查看目录结构再开始全篇阅读 。
块和层
对于多层感知机而言,整个模型及其组成层都是这种架构。 整个模型接受原始输入(特征),生成输出(预测), 并包含一些参数(所有组成层的参数集合)。 同样,每个单独的层接收输入(由前一层提供), 生成输出(到下一层的输入),并且具有一组可调参数, 这些参数根据从下一层反向传播的信号进行更新。
事实证明,研究讨论“比单个层大”但“比整个模型小”的组件更有价值。 例如,在计算机视觉中广泛流行的ResNet-152架构就有数百层, 这些层是由层组(groups of layers)的重复模式组成。 这个ResNet架构赢得了2015年ImageNet和COCO计算机视觉比赛 的识别和检测任务 (He et al., 2016)。 目前ResNet架构仍然是许多视觉任务的首选架构。 在其他的领域,如自然语言处理和语音, 层组以各种重复模式排列的类似架构现在也是普遍存在。
为了实现这些复杂的网络,我们引入了神经网络块的概念。 块(block)可以描述单个层、由多个层组成的组件或整个模型本身。 使用块进行抽象的一个好处是可以将一些块组合成更大的组件, 这一过程通常是递归的,如下图所示。 通过定义代码来按需生成任意复杂度的块, 我们可以通过简洁的代码实现复杂的神经网络。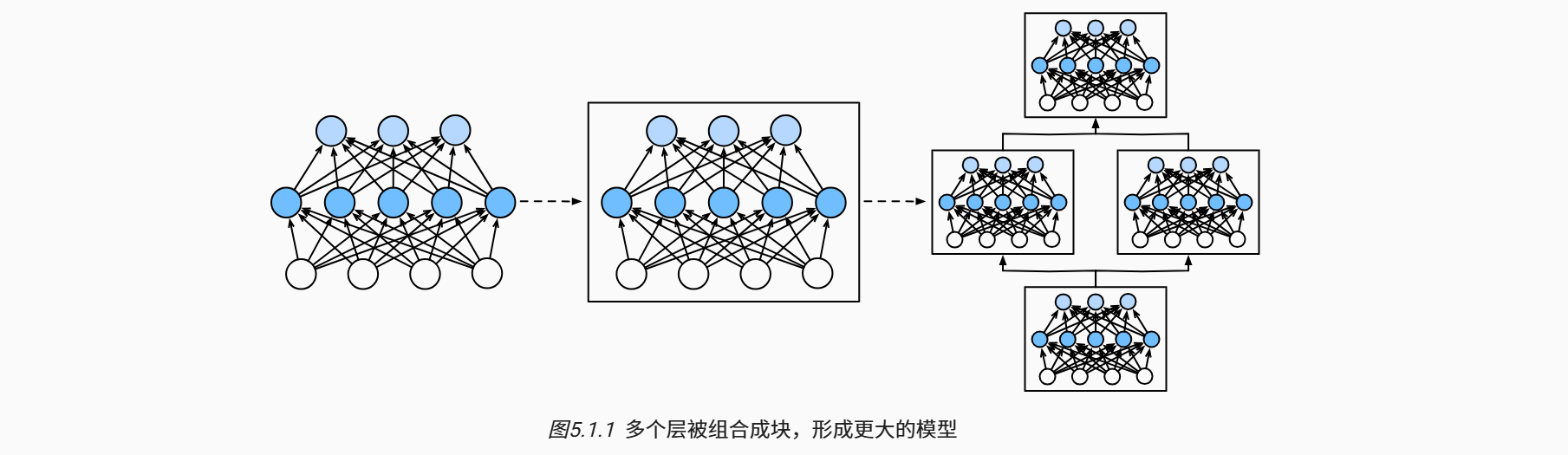
从编程的角度来看,块由类(class)表示。 它的任何子类都必须定义一个将其输入转换为输出的前向传播函数, 并且必须存储任何必需的参数。 注意,有些块不需要任何参数。 最后,为了计算梯度,块必须具有反向传播函数。 在定义我们自己的块时,由于自动微分提供了一些后端实现,我们只需要考虑前向传播函数和必需的参数。
在构造自定义块之前,我们先回顾一下多层感知机的代码。 下面的代码生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层, 然后是一个具有10个隐藏单元且不带激活函数的全连接输出层。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
net(X)
tensor([[ 0.0343, 0.0264, 0.2505, -0.0243, 0.0945, 0.0012, -0.0141, 0.0666,
-0.0547, -0.0667],
[ 0.0772, -0.0274, 0.2638, -0.0191, 0.0394, -0.0324, 0.0102, 0.0707,
-0.1481, -0.1031]], grad_fn=<AddmmBackward0>)
在这个例子中,我们通过实例化nn.Sequential来构建我们的模型, 层的执行顺序是作为参数传递的。 简而言之,nn.Sequential定义了一种特殊的Module, 即在PyTorch中表示一个块的类, 它维护了一个由Module组成的有序列表。 注意,两个全连接层都是Linear类的实例, Linear类本身就是Module的子类。 另外,到目前为止,我们一直在通过net(X)调用我们的模型来获得模型的输出。 这实际上是net.__call__(X)的简写。 这个前向传播函数非常简单: 它将列表中的每个块连接在一起,将每个块的输出作为下一个块的输入。
自定义块
要想直观地了解块是如何工作的,最简单的方法就是自己实现一个。 在实现我们自定义块之前,我们简要总结一下每个块必须提供的基本功能。
- 将输入数据作为其前向传播函数的参数。
- 通过前向传播函数来生成输出。请注意,输出的形状可能与输入的形状不同。例如,我们上面模型中的第一个全连接的层接收一个20维的输入,但是返回一个维度为256的输出。
- 计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通常这是自动发生的。
- 存储和访问前向传播计算所需的参数。
- 根据需要初始化模型参数。
从零编写一个块,它包含一个多层感知机,其具有256个隐藏单元的隐藏层和一个10维输出层。 注意,下面的MLP类继承了表示块的类。 我们的实现只需要提供我们自己的构造函数(Python中的__init__函数)和前向传播函数。
class MLP(nn.Module):
# 用模型参数声明层。这里,我们声明两个全连接的层
def __init__(self):
# 调用MLP的父类Module的构造函数来执行必要的初始化。
# 这样,在类实例化时也可以指定其他函数参数,例如模型参数params(稍后将介绍)
super().__init__()
self.hidden = nn.Linear(20, 256) # 隐藏层
self.out = nn.Linear(256, 10) # 输出层
# 定义模型的前向传播,即如何根据输入X返回所需的模型输出
def forward(self, X):
# 注意,这里我们使用ReLU的函数版本,其在nn.functional模块中定义。
return self.out(F.relu(self.hidden(X)))
我们首先看一下前向传播函数,它以X作为输入, 计算带有激活函数的隐藏表示,并输出其未规范化的输出值。 在这个MLP实现中,两个层都是实例变量。 要了解这为什么是合理的,可以想象实例化两个多层感知机(net1和net2), 并根据不同的数据对它们进行训练。 当然,我们希望它们学到两种不同的模型。
接着我们实例化多层感知机的层,然后在每次调用前向传播函数时调用这些层。 注意一些关键细节: 首先,我们定制的__init__函数通过super().__init__() 调用父类的__init__函数, 省去了重复编写模版代码的痛苦。 然后,我们实例化两个全连接层, 分别为self.hidden和self.out。 注意,除非我们实现一个新的运算符, 否则我们不必担心反向传播函数或参数初始化, 系统将自动生成这些。
我们来试一下这个函数:
net = MLP()
net(X)
tensor([[ 0.0669, 0.2202, -0.0912, -0.0064, 0.1474, -0.0577, -0.3006, 0.1256,
-0.0280, 0.4040],
[ 0.0545, 0.2591, -0.0297, 0.1141, 0.1887, 0.0094, -0.2686, 0.0732,
-0.0135, 0.3865]], grad_fn=<AddmmBackward0>)
块的一个主要优点是它的多功能性。 我们可以子类化块以创建层(如全连接层的类)、 整个模型(如上面的MLP类)或具有中等复杂度的各种组件。 我们在接下来的章节中充分利用了这种多功能性, 比如在处理卷积神经网络时。
顺序块
现在我们可以更仔细地看看Sequential类是如何工作的, 回想一下Sequential的设计是为了把其他模块串起来。 为了构建我们自己的简化的MySequential, 我们只需要定义两个关键函数:
- 一种将块逐个追加到列表中的函数;
- 一种前向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
下面的MySequential类提供了与默认Sequential类相同的功能。
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for idx, module in enumerate(args):
# 这里,module是Module子类的一个实例。我们把它保存在'Module'类的成员
# 变量_modules中。_module的类型是OrderedDict
self._modules[str(idx)] = module
def forward(self, X):
# OrderedDict保证了按照成员添加的顺序遍历它们
for block in self._modules.values():
X = block(X)
return X
__init__函数将每个模块逐个添加到有序字典_modules中。 读者可能会好奇为什么每个Module都有一个_modules属性? 以及为什么我们使用它而不是自己定义一个Python列表? 简而言之,_modules的主要优点是: 在模块的参数初始化过程中, 系统知道在_modules字典中查找需要初始化参数的子块。
当MySequential的前向传播函数被调用时, 每个添加的块都按照它们被添加的顺序执行。 现在可以使用我们的MySequential类重新实现多层感知机。
net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
net(X)
tensor([[ 2.2759e-01, -4.7003e-02, 4.2846e-01, -1.2546e-01, 1.5296e-01,
1.8972e-01, 9.7048e-02, 4.5479e-04, -3.7986e-02, 6.4842e-02],
[ 2.7825e-01, -9.7517e-02, 4.8541e-01, -2.4519e-01, -8.4580e-02,
2.8538e-01, 3.6861e-02, 2.9411e-02, -1.0612e-01, 1.2620e-01]],
grad_fn=<AddmmBackward0>)
在前向传播函数中执行代码
Sequential类使模型构造变得简单, 允许我们组合新的架构,而不必定义自己的类。 然而,并不是所有的架构都是简单的顺序架构。 当需要更强的灵活性时,我们需要定义自己的块。 例如,我们可能希望在前向传播函数中执行Python的控制流。 此外,我们可能希望执行任意的数学运算, 而不是简单地依赖预定义的神经网络层。
到目前为止, 我们网络中的所有操作都对网络的激活值及网络的参数起作用。 然而,有时我们可能希望合并既不是上一层的结果也不是可更新参数的项, 我们称之为常数参数(constant parameter)。 例如,我们需要一个计算函数 𝑓(𝑥,𝑤)=𝑐⋅𝑤⊤𝑥的层, 其中𝑥是输入, 𝑤是参数, 𝑐是某个在优化过程中没有更新的指定常量。 因此我们实现了一个FixedHiddenMLP类,如下所示:
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
# 不计算梯度的随机权重参数。因此其在训练期间保持不变
self.rand_weight = torch.rand((20, 20), requires_grad=False)
self.linear = nn.Linear(20, 20)
def forward(self, X):
X = self.linear(X)
# 使用创建的常量参数以及relu和mm函数
X = F.relu(torch.mm(X, self.rand_weight) + 1)
# 复用全连接层。这相当于两个全连接层共享参数
X = self.linear(X)
# 控制流
while X.abs().sum() > 1:
X /= 2
return X.sum()
在这个FixedHiddenMLP模型中,我们实现了一个隐藏层, 其权重(self.rand_weight)在实例化时被随机初始化,之后为常量。 这个权重不是一个模型参数,因此它永远不会被反向传播更新。 然后,神经网络将这个固定层的输出通过一个全连接层。
注意,在返回输出之前,模型做了一些不寻常的事情: 它运行了一个while循环,在𝐿1范数大于1的条件下, 将输出向量除以2,直到它满足条件为止。 最后,模型返回了X中所有项的和。 注意,此操作可能不会常用于在任何实际任务中, 我们只展示如何将任意代码集成到神经网络计算的流程中。
net = FixedHiddenMLP()
net(X)
tensor(0.1862, grad_fn=<SumBackward0>)
我们可以混合搭配各种组合块的方法。 在下面的例子中,我们以一些想到的方法嵌套块。
class NestMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU())
self.linear = nn.Linear(32, 16)
def forward(self, X):
return self.linear(self.net(X))
chimera = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP())
chimera(X)
tensor(0.2183, grad_fn=<SumBackward0>)
参数管理
- 访问管理—>调试,诊断和可视化
- 参数初始化
- 在不同模型组件之间共享参数
先以一个单层隐藏层的多层感知机为例
import torch
inport nn from torch
net = nn Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,1));
X =torch.rand(size=(2,4)); //输入为一个形状为(2, 4)的张量,表示一个批次中有两个样本,每个样本有4个特征。
tensor([[-0.0970],
[-0.0827]], grad_fn=<AddmmBackward0>)
grad_fn=<AddmmBackward0>这部分信息表示这个张量有一个与之关联的梯度函数(在这个情况下是AddmmBackward0),这通常意味着这个张量是通过一个需要梯度的操作(如反向传播)得到的。在PyTorch中,当你进行自动微分(autograd)时,每个计算图(computation graph)中的张量都会与一个梯度函数相关联,以便在需要时可以计算梯度。
由于调用了nn.Linear层,这些层在定义时默认启用了requires_grad=True(除非明确设置为False),因此对这些层进行前向传播时,输出的张量也会有一个与之关联的梯度函数。
参数访问
当通过Sequential类定义模型时, 我们可以通过索引来访问模型的任意层
print(net.state_dict())
OrderedDict([('weight', tensor([[-0.0427, -0.2939, -0.1894, 0.0220, -0.1709, -0.1522, -0.0334, -0.2263]])), ('bias', tensor([0.0887]))])
这个全连接层包含两个参数,分别是该层的权重和偏置。 两者都存储为单精度浮点数(float32)。 注意,参数名称允许唯一标识每个参数,即使在包含数百个层的网络中也是如此。
目标参数
每个参数都表示为参数类的一个实例。 要对参数执行任何操作,首先我们需要访问底层的数值。 有几种方法可以做到这一点。有些比较简单,而另一些则比较通用。 下面的代码从第二个全连接层(即第三个神经网络层)提取偏置, 提取后返回的是一个参数类实例,并进一步访问该参数的值。
print(type(net[2].bias)) # 打印偏置的类型
print(net[2].bias) # 打印偏置对象,包括grad_fn(如果有的话)
print(net[2].bias.data) # 打印偏置的数据(不包括grad_fn)
<class 'torch.nn.parameter.Parameter'>
Parameter containing:
tensor([0.0887], requires_grad=True)
tensor([0.0887])
参数是复合的对象,包含值、梯度和额外信息。 这就是我们需要显式参数值的原因。 除了值之外,我们还可以访问每个参数的梯度。 在上面这个网络中,由于我们还没有调用反向传播,所以参数的梯度处于初始状态。
net[2].weight.grad == None
True
一次性访问所有参数
print(*[(name, param.shape) for name, param in net[0].named_parameters()])
print(*[(name, param.shape) for name, param in net.named_parameters()])
('weight', torch.Size([8, 4])) ('bias', torch.Size([8]))
('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([1, 8])) ('2.bias', torch.Size([1]))
另一种访问网络参数的方式
net.state_dict()['2.bias'].data
tensor([0.0887])
从嵌套块收集参数
首先定义一个生成块的函数(可以说是“块工厂”),然后将这些块组合到更大的块中。
def block1():
return nn.Sequential(nn.Linear(4, 8), nn.ReLU(),
nn.Linear(8, 4), nn.ReLU())
def block2():
net = nn.Sequential()
for i in range(4):
# 在这里嵌套
net.add_module(f'block {i}', block1())
return net
rgnet = nn.Sequential(block2(), nn.Linear(4, 1))
rgnet(X)
tensor([[0.2596],
[0.2596]], grad_fn=<AddmmBackward0>)
设计了网络后,查看一下它是如何工作的。
print(rgnet)
Sequential(
(0): Sequential(
(block 0): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=4, bias=True)
(3): ReLU()
)
(block 1): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=4, bias=True)
(3): ReLU()
)
(block 2): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=4, bias=True)
(3): ReLU()
)
(block 3): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=4, bias=True)
(3): ReLU()
)
)
(1): Linear(in_features=4, out_features=1, bias=True)
)
因为层是分层嵌套的,所以我们也可以像通过嵌套列表索引一样访问它们。 下面,我们访问第一个主要的块中、第二个子块的第一层的偏置项。
rgnet[0][1][0].bias.data
tensor([ 0.1999, -0.4073, -0.1200, -0.2033, -0.1573, 0.3546, -0.2141, -0.2483])
参数初始化
默认情况下,PyTorch会根据一个范围均匀地初始化权重和偏置矩阵, 这个范围是根据输入和输出维度计算出的。 PyTorch的nn.init模块提供了多种预置初始化方法。
内置初始化
调用内置的初始化器。 下面的代码将所有权重参数初始化为标准差为0.01的高斯随机变量, 且将偏置参数设置为0。
def init_normal(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.zeros_(m.bias)
net.apply(init_normal)
net[0].weight.data[0], net[0].bias.data[0]
(tensor([-0.0214, -0.0015, -0.0100, -0.0058]), tensor(0.))
还可以将所有参数初始化为给定的常数,比如初始化为1。
def init_constant(m):
if type(m) == nn.Linear:
nn.init.constant_(m.weight, 1)
nn.init.zeros_(m.bias)
net.apply(init_constant)
net[0].weight.data[0], net[0].bias.data[0]
(tensor([1., 1., 1., 1.]), tensor(0.))
读写文件
加载和存储权重向量和整个模型
加载和保存张量
import torch
from torch import nn
from torch.nn import functional as F
x = torch.arange(4)
torch.save(x, 'x-file')
现在可以将存储在文件中的数据读回内存。
x2 = torch.load('x-file')
x2
tensor([0, 1, 2, 3])
可以存储一个张量列表,然后把它们读回内存。
y = torch.zeros(4)
torch.save([x, y],'x-files')
x2, y2 = torch.load('x-files')
(x2, y2)
(tensor([0, 1, 2, 3]), tensor([0., 0., 0., 0.]))
甚至可以写入或读取从字符串映射到张量的字典。 当我们要读取或写入模型中的所有权重时,这很方便
mydict = {'x': x, 'y': y}
torch.save(mydict, 'mydict')
mydict2 = torch.load('mydict')
mydict2
{'x': tensor([0, 1, 2, 3]), 'y': tensor([0., 0., 0., 0.])}
加载和保存模型参数
将模型的参数存储在一个叫做“mlp.params”的文件中
torch.save(net.state_dict(), 'mlp.params')
为了恢复模型,我们实例化了原始多层感知机模型的一个备份。 这里我们不需要随机初始化模型参数,而是直接读取文件中存储的参数。
clone = MLP()
clone.load_state_dict(torch.load('mlp.params'))
clone.eval()
MLP(
(hidden): Linear(in_features=20, out_features=256, bias=True)
(output): Linear(in_features=256, out_features=10, bias=True)
)
GPU
!nvidia-smi
在PyTorch中,每个数组都有一个设备(device), 我们通常将其称为环境(context)。 默认情况下,所有变量和相关的计算都分配给CPU。 有时环境可能是GPU。 当我们跨多个服务器部署作业时,事情会变得更加棘手。 通过智能地将数组分配给环境, 我们可以最大限度地减少在设备之间传输数据的时间。 例如,当在带有GPU的服务器上训练神经网络时, 我们通常希望模型的参数在GPU上。
计算设备
在PyTorch中,CPU和GPU可以用torch.device('cpu') 和torch.device('cuda')表示。 应该注意的是,cpu设备意味着所有物理CPU和内存, 这意味着PyTorch的计算将尝试使用所有CPU核心。 然而,gpu设备只代表一个卡和相应的显存。 如果有多个GPU,我们使用torch.device(f'cuda:{i}') 来表示第𝑖块GPU(𝑖从0开始)。 另外,cuda:0和cuda是等价的。
import torch
from torch import nn
torch.device('cpu'), torch.device('cuda'), torch.device('cuda:1')
(device(type='cpu'), device(type='cuda'), device(type='cuda', index=1))
我们可以查询可用gpu的数量。
torch.cuda.device_count()
2
张量与GPU
我们可以查询张量所在的设备。 默认在CPU上创建的。
x = torch.tensor([1, 2, 3])
x.device
device(type='cpu')
无论何时我们要对多个项进行操作, 它们都必须在同一个设备上。 例如,如果我们对两个张量求和, 我们需要确保两个张量都位于同一个设备上, 否则框架将不知道在哪里存储结果,甚至不知道在哪里执行计算。
存储在GPU上
X = torch.ones(2, 3, device=try_gpu())
X
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
神经网络与GPU
下面的代码将模型参数放在GPU上。
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())
输入为GPU上的张量时,模型将在同一GPU上计算结果。
让我们确认模型参数存储在同一个GPU上。
net[0].weight.data.device
device(type='cuda', index=0)
总结: PyTorch构建神经网络的主要工具
使用PyTorch构建神经网络使用的主要工具(或类)及相互关系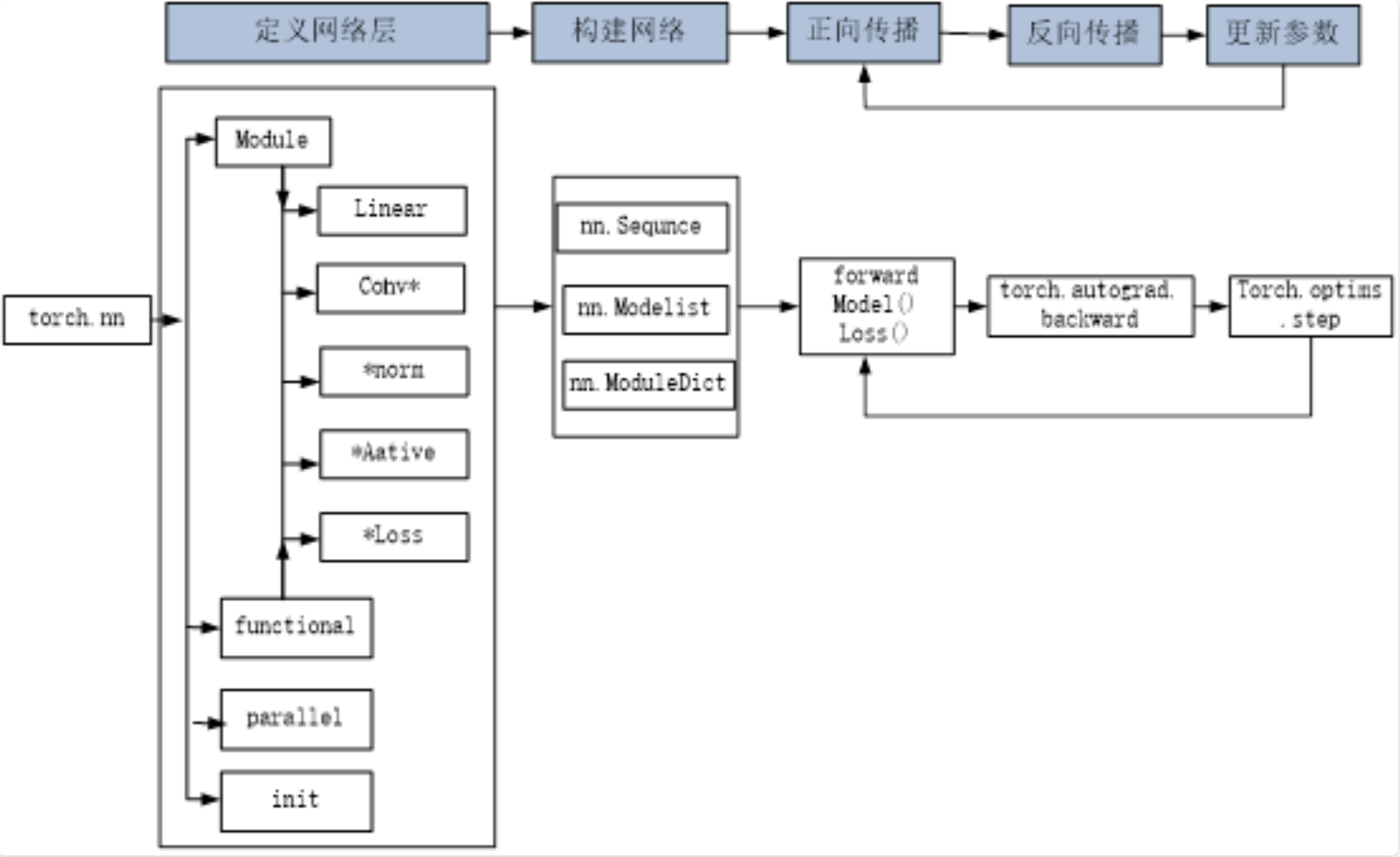
从图中可知,可以基于Module类或函数(nn.functional)构建网络层。nn中的大多数层(layer)在functional中都有与之对应的函数。nn.functional中的函数与nn.Module中的layer的主要区别是后者继承自Module类,可自动提取可学习的参数,而nn.functional更像是纯函数。两者功能相同,性能也没有很大区别,那么如何选择呢?卷积层、全连接层、dropout层等含有可学习参数,一般使用nn.Module,而激活函数、池化层不含可学习参数,可以使用nn.functional中对应的函数。
nn.Module
nn是一个有效工具。它是专门为深度学习设计的一个模块,而nn.Module是nn的一个核心数据结构。nn.Module可以是神经网络的某个层,也可以是包含多层的神经网络。在实际使用中,最常见的做法是继承nn.Module,生成自己的网络/层。nn中已实现了绝大多数层,包括全连接层、损失层、激活层、卷积层、循环层等。这些层都是nn.Module的子类,能够自动检测到自己的参数,并将其作为学习参数,且针对GPU运行进行了CuDNN优化。
nn.functional
nn中的层,一类是继承了nn.Module,其命名一般为nn.Xxx(第一个是大写),如nn.Linear、nn.Conv2d、nn.CrossEntropyLoss等。另一类是nn.functional中的函数,其名称一般为nn.funtional.xxx,如nn.funtional.linear、nn.funtional.conv2d、nn.funtional.cross_entropy等。从功能来说两者相当,基于nn.Mudle能实现的层,也可以基于nn.funtional实现
不过在具体使用时,两者还是有区别的,主要区别如下。
- nn.Xxx继承于nn.Module,nn.Xxx 需要先实例化并传入参数,然后以函数调用的方式调用实例化的对象并传入输入数据。它能够很好的与nn.Sequential结合使用,而nn.functional.xxx无法与nn.Sequential结合使用。
- nn.Xxx不需要自己定义和管理weight、bias参数;而nn.functional.xxx需要你自己定义weight、bias,每次调用的时候都需要手动传入weight、bias等参数, 不利于代码复用。
- dropout操作在训练和测试阶段是有区别的,使用nn.Xxx方式定义dropout,在调用model.eval()之后,自动实现状态的转换,而使用nn.functional.xxx却无此功能。
总的来说,两种功能都是相同的,但PyTorch官方推荐:具有学习参数的(例如,conv2d、 linear、batch_norm、dropout等)情况采用nn.Xxx方式,没有学习参数的(例如,maxpool, loss func, activation func)等情况选择使用nn.functional.xxx或者nn.Xxx方式。3.5节中使用激活层,我们采用无学习参数的F.relu方式来实现,即nn.functional.xxx方式。
构建模型
PyTorch构建模型大致有以下3种方式。
- 继承nn.Module基类构建模型。
- 使用nn.Sequential按层顺序构建模型。
- 继承nn.Module基类构建模型,又使用相关模型容器(如nn.Sequential,nn.ModuleList,nn.ModuleDict等)进行封装。
在这3种方法中,第1种方式最为常见;第2种方式比较简单,非常适合与初学者;第3种方式较灵活但复杂一些。
继承nn.Module基类构建模型
先定义一个类,使之继承nn.Module基类。把模型中需要用到的层放在构造函数__init__()中,在forward方法中实现模型的正向传播。具体代码如下。
- 导入模块
import torch
from torch import nn
import torch.nn.functional as F
- 构建模型
class Model_Seq(nn.Module):
"""
通过继承基类nn.Module来构建模型
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Model_Seq, self).__init__()
self.flatten = nn.Flatten()
self.linear1= nn.Linear(in_dim, n_hidden_1)
self.bn1=nn.BatchNorm1d(n_hidden_1)
self.linear2= nn.Linear(n_hidden_1, n_hidden_2)
self.bn2 = nn.BatchNorm1d(n_hidden_2)
self.out = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x=self.flatten(x)
x=self.linear1(x)
x=self.bn1(x)
x = F.relu(x)
x=self.linear2(x)
x=self.bn2(x)
x = F.relu(x)
x=self.out(x)
x = F.softmax(x,dim=1)
return x
3.查看模型
##对一些超参数赋值
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
model_seq= Model_Seq(in_dim, n_hidden_1, n_hidden_2, out_dim)
print(model_seq)
Model_Seq(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=784, out_features=300, bias=True)
(bn1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(linear2): Linear(in_features=300, out_features=100, bias=True)
(bn2): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(out): Linear(in_features=100, out_features=10, bias=True)
)
使用nn.Sequential按层顺序构建模型
使用nn.Sequential构建模型,因其内部实现了forward函数,因此可以不用写forward函数。nn.Sequential里面的模块按照先后顺序进行排列的,所以必须确保前一个模块的输出大小和下一个模块的输入大小是一致的。使用这种方法一般构建较简单的模型。 以下是使用nn.Sequential搭建模型的几种等价方法。
利用可变参数
Python中的函数参数个数是可变(或称为不定长参数),PyTorch中的有些函数也类似,如nn.Sequential(*args)就是一例。
- 导入模块
import torch
from torch import nn
- 构建模型
Seq_arg = nn.Sequential(
nn.Flatten(),
nn.Linear(in_dim,n_hidden_1),
nn.BatchNorm1d(n_hidden_1),
nn.ReLU(),
nn.Linear(n_hidden_1, n_hidden_2),
nn.BatchNorm1d(n_hidden_2),
nn.ReLU(),
nn.Linear(n_hidden_2, out_dim),
nn.Softmax(dim=1)
)
- 查看模型
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
print(Seq_arg)
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=300, bias=True)
(2): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU()
(4): Linear(in_features=300, out_features=100, bias=True)
(5): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU()
(7): Linear(in_features=100, out_features=10, bias=True)
(8): Softmax(dim=1)
)
使用add_module方法
- 构建模型
Seq_module = nn.Sequential()
Seq_module.add_module("flatten",nn.Flatten())
Seq_module.add_module("linear1",nn.Linear(in_dim,n_hidden_1))
Seq_module.add_module("bn1",nn.BatchNorm1d(n_hidden_1))
Seq_module.add_module("relu1",nn.ReLU())
Seq_module.add_module("linear2",nn.Linear(n_hidden_1, n_hidden_2))
Seq_module.add_module("bn2",nn.BatchNorm1d(n_hidden_2))
Seq_module.add_module("relu2",nn.ReLU())
Seq_module.add_module("out",nn.Linear(n_hidden_2, out_dim))
Seq_module.add_module("softmax",nn.Softmax(dim=1))
- 查看模型
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
print(Seq_module)
Sequential(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=784, out_features=300, bias=True)
(bn1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU()
(linear2): Linear(in_features=300, out_features=100, bias=True)
(bn2): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU()
(out): Linear(in_features=100, out_features=10, bias=True)
(softmax): Softmax(dim=1)
)
使用OrderedDict
- 导入模块
import torch
from torch import nn
from collections import OrderedDict
- 构建模型
Seq_dict = nn.Sequential(OrderedDict([
("flatten",nn.Flatten()),
("linear1",nn.Linear(in_dim,n_hidden_1)),
("bn1",nn.BatchNorm1d(n_hidden_1)),
("relu1",nn.ReLU()),
("linear2",nn.Linear(n_hidden_1, n_hidden_2)),
("bn2",nn.BatchNorm1d(n_hidden_2)),
("relu2",nn.ReLU()),
("out",nn.Linear(n_hidden_2, out_dim)),
("softmax",nn.Softmax(dim=1))]))
- 查看模型
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
print(Seq_dict)
Sequential(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=784, out_features=300, bias=True)
(bn1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU()
(linear2): Linear(in_features=300, out_features=100, bias=True)
(bn2): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU()
(out): Linear(in_features=100, out_features=10, bias=True)
(softmax): Softmax(dim=1)
)
继承nn.Module基类并应用模型容器来构建模型
当模型的结构比较复杂时,可以应用模型容器(如nn.Sequential,nn.ModuleList,nn.ModuleDict)对模型的部分结构进行封装,以增强模型的可读性,或减少代码量。
使用nn.Sequential模型容器
- 导入模块
import torch
from torch import nn
import torch.nn.functional as F
- 构建模型
class Model_lay(nn.Module):
"""
使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Model_lay, self).__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1),nn.BatchNorm1d(n_hidden_1))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2),nn.BatchNorm1d(n_hidden_2))
self.out = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x=self.flatten(x)
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = F.softmax(self.out(x),dim=1)
return x
- 查看模型
in_dim, n_hidden_1, n_hidden_2, out_dim=28 * 28, 300, 100, 10
model_lay= Model_lay(in_dim, n_hidden_1, n_hidden_2, out_dim)
print(model_lay)
Model_lay(
(flatten): Flatten(start_dim=1, end_dim=-1)
(layer1): Sequential(
(0): Linear(in_features=784, out_features=300, bias=True)
(1): BatchNorm1d(300, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(layer2): Sequential(
(0): Linear(in_features=300, out_features=100, bias=True)
(1): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(out): Sequential(
(0): Linear(in_features=100, out_features=10, bias=True)
)
)
自定义网络模块
利用以上方法,自定义一些典型的网络模块,如残差网络(ResNet18)中的残差块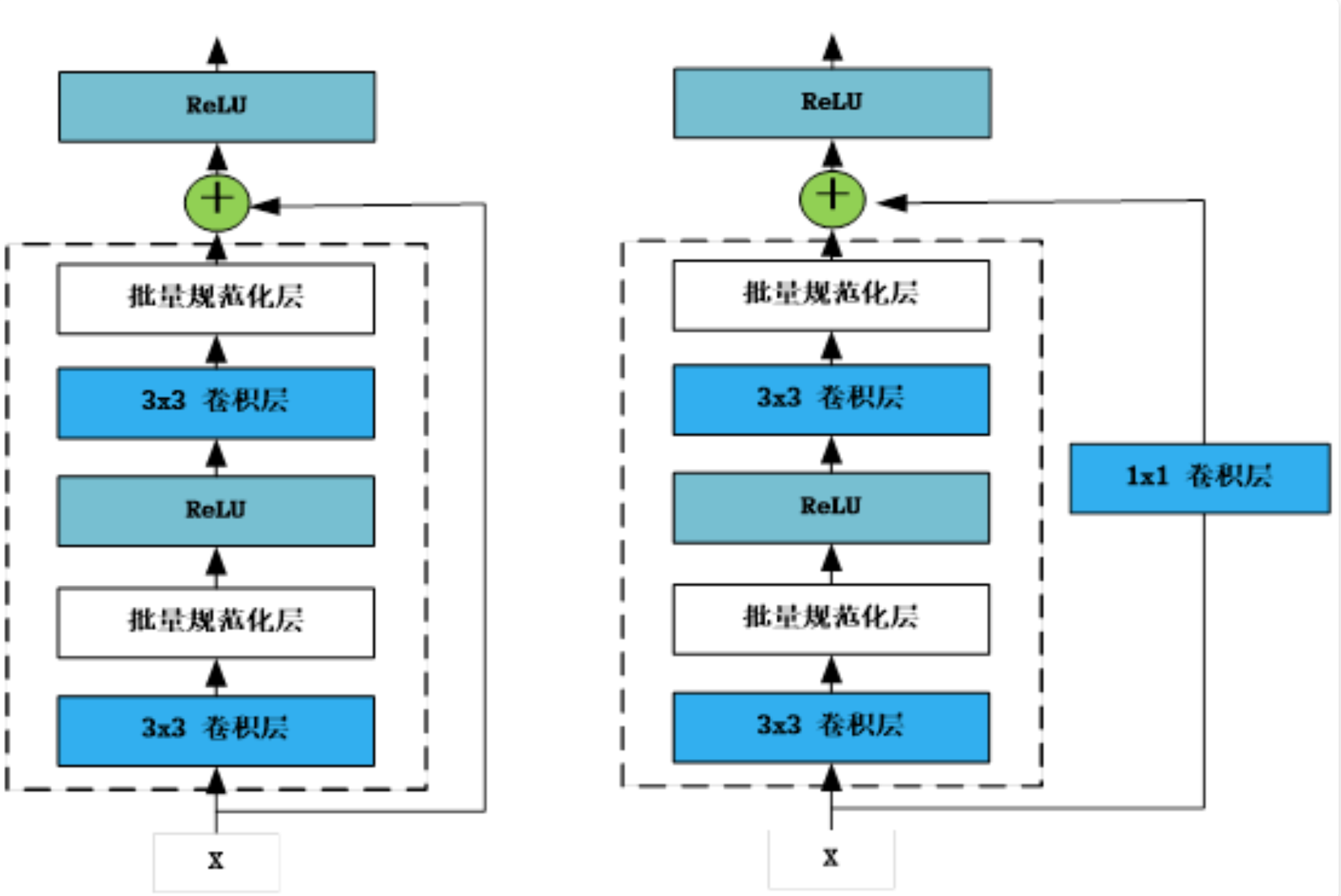
残差块网络结构
残差块有两种,一种是正常的模块方式,如图左图,将输入与输出相加,然后应用激活函数ReLU。 另一种是为使输入与输出形状一致,需添加通过1×1卷积调整通道和分辨率,如图中的右图所示。这些模块中用到卷积层、批量规范化层,具体将在第6章详细介绍,这里我们只需要了解这些是网络层即可。
定义左图的残差模块
import torch
import torch.nn as nn
from torch.nn import functional as F
class RestNetBasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetBasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
output = self.conv1(x)
output = F.relu(self.bn1(output))
output = self.conv2(output)
output = self.bn2(output)
return F.relu(x + output)
定义右图残差模块
class RestNetDownBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetDownBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride[0], padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride[1], padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.extra = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], padding=0),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
extra_x = self.extra(x)
output = self.conv1(x)
out = F.relu(self.bn1(output))
out = self.conv2(out)
out = self.bn2(out)
return F.relu(extra_x + out)
组合这两个模块得到现代经典RetNet18网络结构。
class RestNet18(nn.Module):
def __init__(self):
super(RestNet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = nn.Sequential(RestNetBasicBlock(64, 64, 1),
RestNetBasicBlock(64, 64, 1))
self.layer2 = nn.Sequential(RestNetDownBlock(64, 128, [2, 1]),
RestNetBasicBlock(128, 128, 1))
self.layer3 = nn.Sequential(RestNetDownBlock(128, 256, [2, 1]),
RestNetBasicBlock(256, 256, 1))
self.layer4 = nn.Sequential(RestNetDownBlock(256, 512, [2, 1]),
RestNetBasicBlock(512, 512, 1))
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.fc = nn.Linear(512, 10)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out
训练模型
构建模型(假设为model)后,接下来就是训练模型。PyTorch训练模型主要包括加载数据集、损失计算、定义优化算法、反向传播、参数更新等主要步骤。
1.加载预处理数据集
加载和预处理数据集,可以使用PyTorch的数据处理工具,如torch.utils和torchvision等,这些工具将在第4章详细介绍。
2.定义损失函数
定义损失函数可以通过自定义方法或使用PyTorch内置的损失函数,如回归使用的losss_fun=nn.MSELoss(),分类使用的nn.BCELoss等损失函数,更多内容可参考本书5.2.4节。
3.定义优化方法
Pytoch常用的优化方法都封装在torch.optim里面,其设计很灵活,可以扩展为自定义的优化方法。所有的优化方法都是继承了基类optim.Optimizer,并实现了自己的优化步骤。
最常用的优化算法就是梯度下降法及其各种变种,具体将在5.4节详细介绍,这些优化算法大多使用梯度更新参数。
如使用SGD优化器时,可设置为optimizer = torch.optim.SGD(params,lr = 0.001)。
4.循环训练模型
1)设置为训练模式:
model.train()
调用model.train()会把所有的module设置为训练模式。
2)梯度清零:
optimizer. zero_grad()
在默认情况下梯度是累加的,需要手工把梯度初始化或清零,调用optimizer.zero_grad() 即可。
3)求损失值:
y_prev=model(x)
loss=loss_fun(y_prev,y_true)
4)自动求导,实现梯度的反向传播:
loss.backward()
5)更新参数:
optimizer.step()
5.循环测试或验证模型
1)设置为测试或验证模式:
model.eval()
调用model.eval()会把所有的training属性设置为False。
2)在不跟踪梯度模式下计算损失值、预测值等:
with.torch.no_grad():
6.可视化结果
下面我们通过实例来说明如何使用nn来构建网络模型、训练模型。
【说明】model.train()与model.eval()的使用
如果模型中有BN (Batch Normalization)层和Dropout,需要在训练时添加model.train(),
在测试时添加model.eval()。其中model.train()是保证BN层用每一批数据的均值和方差,而model.eval()是保证BN用全部训练数据的均值和方差;而对于Dropout,model.train()是随机取一部分网络连接来训练更新参数,而model.eval()是利用到了所有网络连接。
实现神经网络实例
通过一个构建神经网络的实例把这些内容有机结合起来。
背景说明
利用神经网络完成对手写数字进行识别的实例,来说明如何借助nn工具箱来实现一个神经网络,并对神经网络有个直观了解。在这个基础上,后续我们将对nn的各模块进行详细介绍。实例环境使用PyTorch1.5+,GPU或CPU,源数据集为MNIST。
主要步骤如下。
利用PyTorch内置函数mnist下载数据。
-
利用torchvision对数据进行预处理,调用torch.utils建立一个数据迭代器。
-
可视化源数据。
-
利用nn工具箱构建神经网络模型。
-
实例化模型,并定义损失函数及优化器。
-
训练模型。
-
可视化结果。
神经网络的结构如图
使用两个隐含层,每层使用ReLU激活函数,输出层使用softmax激活函数,最后使用torch.max(out,1)找出张量out最大值对应索引作为预测值。
准备数据
导人必要的模块
import numpy as np
import torch
# 导入 pytorch 内置的 mnist 数据
from torchvision.datasets import mnist
#导入预处理模块
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
#导入nn及优化器
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
定义一些超参数
train_batch_size = 64
test_batch_size = 128
learning_rate = 0.01
num_epoches = 20
lr = 0.01
momentum = 0.5
下载数据并进行预处理
#定义预处理函数
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5])])
#下载数据,并对数据进行预处理
train_dataset = mnist.MNIST('../data/', train=True, transform=transform, download=False)
test_dataset = mnist.MNIST('../data/', train=False, transform=transform)
#得到一个生成器
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)
【说明】
\1) transforms.Compose可以把一些转换函数组合在一起。
\2) Normalize([0.5], [0.5])对张量进行归一化,这里两个0.5分别表示对张量进行归一化的全局平均值和方差。因图像是灰色的只有一个通道,如果有多个通道,需要有多个数字,如三个通道,应该是Normalize([m1,m2,m3], [n1,n2,n3])。
\3) download参数控制是否需要下载,如果./data目录下已有MNIST,可选择False。
\4) 用DataLoader得到生成器,这可节省内存。
\5) torchvision及data的使用第4章将详细介绍。
可视化源数据
对数据集 中部分数据进行可视化
import matplotlib.pyplot as plt
%matplotlib inline
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
构建模型
构建网络
class Net(nn.Module):
"""
使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Net, self).__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1),nn.BatchNorm1d(n_hidden_1))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2),nn.BatchNorm1d(n_hidden_2))
self.out = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x=self.flatten(x)
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = F.softmax(self.out(x),dim=1)
return x
实例化网络
#检测是否有可用的GPU,有则使用,否则使用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#实例化网络
model = Net(28 * 28, 300, 100, 10)
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
训练模型
这里使用for循环进行迭代。其中包括对训练数据的训练模型,然后用测试数据验证模型
1)训练模型。
# 开始训练
losses = []
acces = []
eval_losses = []
eval_acces = []
writer = SummaryWriter(log_dir='logs',comment='train-loss')
for epoch in range(num_epoches):
train_loss = 0
train_acc = 0
model.train()
#动态修改参数学习率
if epoch%5==0:
optimizer.param_groups[0]['lr']*=0.9
print("学习率:{:.6f}".format(optimizer.param_groups[0]['lr']))
for img, label in train_loader:
img=img.to(device)
label = label.to(device)
# 正向传播
out = model(img)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.item()
# 保存loss的数据与epoch数值
writer.add_scalar('Train', train_loss/len(train_loader), epoch)
# 计算分类的准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
train_acc += acc
losses.append(train_loss / len(train_loader))
acces.append(train_acc / len(train_loader))
# 在测试集上检验效果
eval_loss = 0
eval_acc = 0
#net.eval() # 将模型改为预测模式
model.eval()
for img, label in test_loader:
img=img.to(device)
label = label.to(device)
img = img.view(img.size(0), -1)
out = model(img)
loss = criterion(out, label)
# 记录误差
eval_loss += loss.item()
# 记录准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_loader))
eval_acces.append(eval_acc / len(test_loader))
print('epoch: {}, Train Loss: {:.4f}, Train Acc: {:.4f}, Test Loss: {:.4f}, Test Acc: {:.4f}'
.format(epoch, train_loss / len(train_loader), train_acc / len(train_loader),
eval_loss / len(test_loader), eval_acc / len(test_loader)))
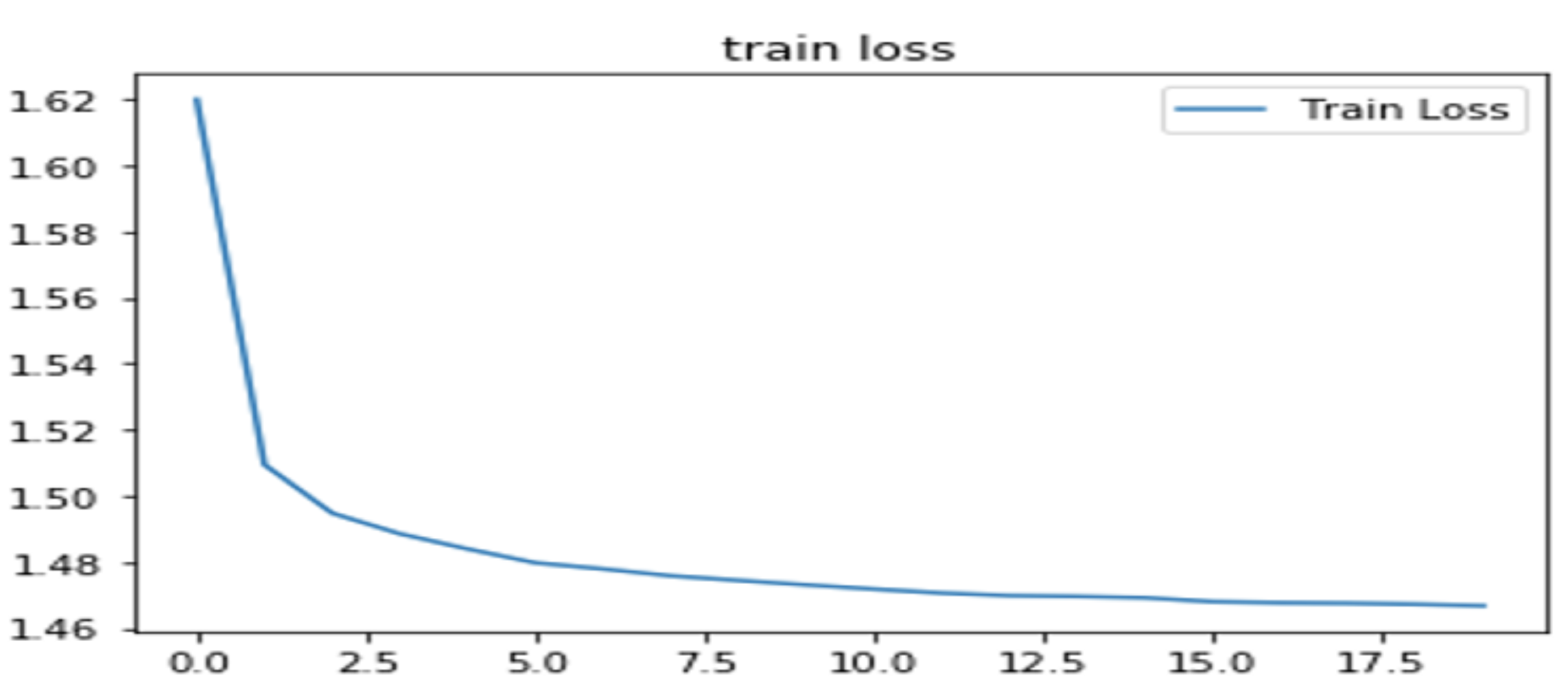
最后5次迭代的结果如下:
学习率:0.006561
epoch: 15, Train Loss: 1.4681, Train Acc: 0.9950, Test Loss: 1.4801, Test Acc: 0.9830
epoch: 16, Train Loss: 1.4681, Train Acc: 0.9950, Test Loss: 1.4801, Test Acc: 0.9833
epoch: 17, Train Loss: 1.4673, Train Acc: 0.9956, Test Loss: 1.4804, Test Acc: 0.9826
epoch: 18, Train Loss: 1.4668, Train Acc: 0.9960, Test Loss: 1.4798, Test Acc: 0.9835
epoch: 19, Train Loss: 1.4666, Train Acc: 0.9962, Test Loss: 1.4795, Test Acc: 0.9835
这个神经网络的结构比较简单,只用了两层,也没有使用dropout层,迭代20次,测试准确率达到98%左右,效果还可以。不过,还是有提升空间,如果采用cnn,dropout等层,应该还可以提升模型性能。
2)可视化训练及测试损失值。
plt.title('train loss')
plt.plot(np.arange(len(losses)), losses)
plt.legend(['Train Loss'], loc='upper right')
文章由李沐老师的教学文档改编,希望能帮到你

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)