预测宝可梦CP值(第三周周报)
本文系统阐述了机器学习中的回归任务,其核心目标是通过输入特征预测连续值输出,并以宝可梦进化后CP值预测为案例展开分析。首先,通过两张图明确了输入参数与输出的映射关系。随后分三步构建预测模型:定义线性模型 y=b+w⋅x,强调参数 w 和 b 的优化需求;通过损失函数 L(w,b) 评估模型性能,利用训练数据计算误差平方和,并以颜色梯度可视化参数优劣;采用梯度下降算法求解最优参数,指出线性回归的损
摘要
本文系统阐述了机器学习中的回归任务,其核心目标是通过输入特征预测连续值输出,并以宝可梦进化后CP值预测为案例展开分析。首先,通过两张图明确了输入参数与输出的映射关系。随后分三步构建预测模型:定义线性模型 y=b+w⋅x,强调参数 w 和 b 的优化需求;通过损失函数 L(w,b) 评估模型性能,利用训练数据计算误差平方和,并以颜色梯度可视化参数优劣;采用梯度下降算法求解最优参数,指出线性回归的损失函数为凸函数,确保全局最优解,同时警示非凸问题中局部最优的风险。最终,模型在训练集上平均误差为31.9,但测试集误差升至35.0,揭示泛化能力不足的问题,引发对模型改进的思考。全文结合数学公式与可视化图表,完整呈现了从理论到实践的回归建模流程。
Absrtact
This article systematically explains the regression task in machine learning, which aims to predict continuous outputs from input features, using Pokémon’s post-evolution CP value prediction as a case study. Figures illustrate the mapping between input parametersand output . The modeling process involves three steps: Step 1defines a linear model y=b+w⋅x, highlighting the need to optimize parameters w and b; Step 2evaluates model performance via a loss function L(w,b), calculating the sum of squared errors on training data and visualizing parameter quality with color gradients; Step 3 employs gradient descent to derive optimal parameters, noting that the convexity of the loss function in linear regression guarantees a global optimum, while warning about local optima in non-convex scenarios. The model achieves a training error of 31.9 but suffers a higher testing error of 35.0, exposing generalization challenges and prompting calls for improvement. The text integrates mathematical formulations and visualizations to demonstrate a complete regression modeling workflow from theory to practice.
2.2 STEP2:Goodness of function
1 Regression
回归(Regression)这一机器学习核心任务在不同领域的实际形态。它强调回归的核心目标是预测一个连续值,而非进行分类利用输入信息(可能来自各种来源)来预测或映射出一个重要的连续数值输出。如下图1.1,预测示例图。

图1.1预测示例图
本次学习的主要目标是对宝可梦的cp值进行预测,输入值为宝可梦的一系列参数。具体参数以及输入输出等,由下图1.2所示。

图1.2 宝可梦预测公式参数图
由上图可知,图中的不同标识符 xS(物种)、xhp(生命值/属性)、xw(体重)、xh(身高),并汇总作为函数 f 的参数。输出(y) 则是经过函数 f 计算后得到的一个具体的数值结果——妙蛙种子进化后的预估战斗力。
2 预测步骤
2.1 STEP1:Linear Model
假设该function为线性的,具体由下图2.1所示。线性函数 y=b+w⋅x 的形式,并承认 w 和 b 可以是任何实数。赋予 w 和 b 具体“最优值”的任务——即寻找最能拟合数据的那个特定函数,它将是后续步骤的工作重点。

图2.1线性model图
2.2 STEP2:Goodness of function
利用10个真实数据训练,大概位于下方图2.2中的蓝点。
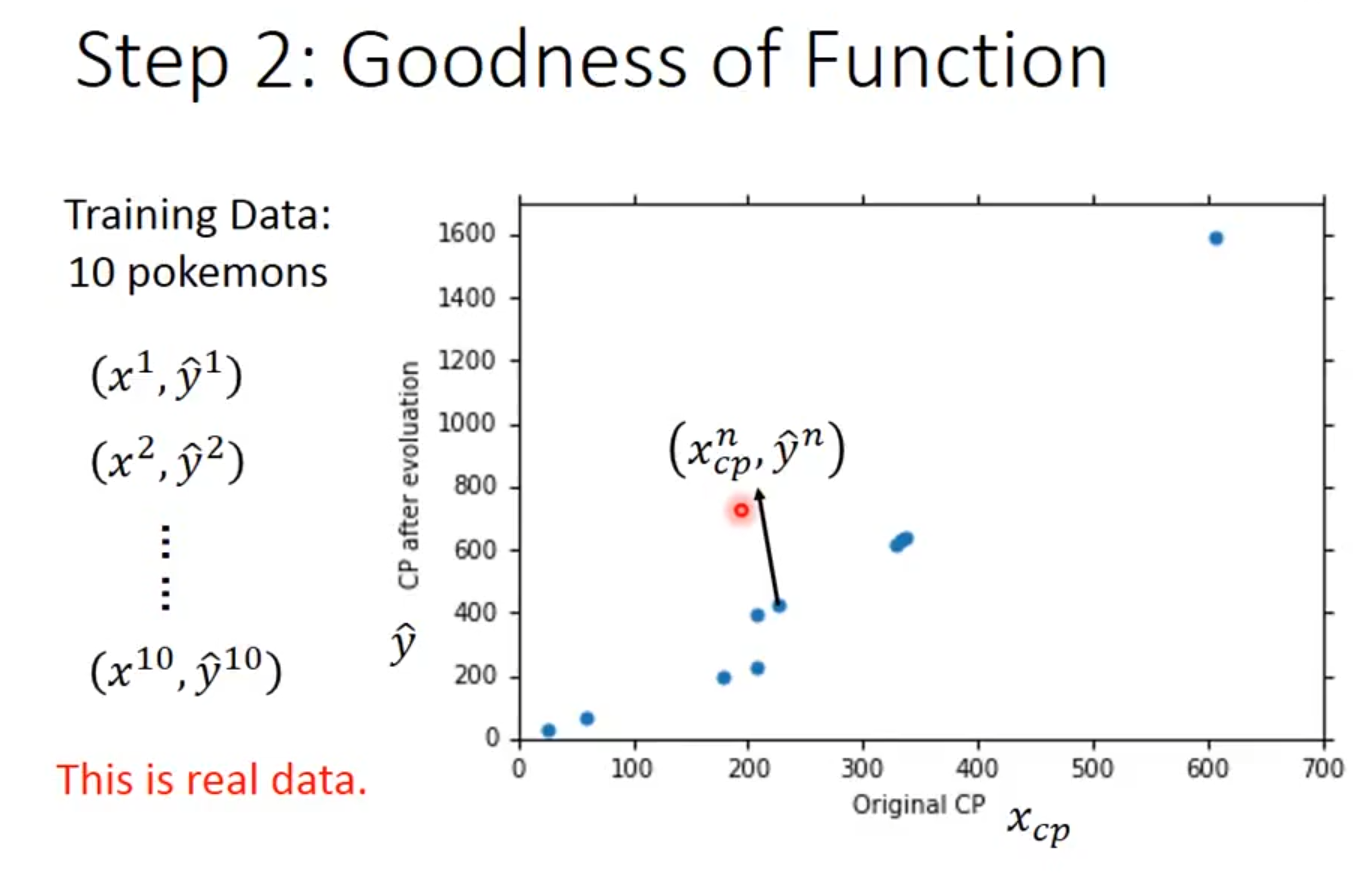
图2.2 真实数据散点图
由下图2.3所示,这张图明确了评估标准:对于一个形式为 y=b+w⋅xcp 的候选函数 f(由其参数 w 和 b 唯一确定),我们通过损失函数L来度量它有多“糟糕”。

图2.3 样本函数图
由上图2.3所示,将所有10个样本上的预测误差平方求和,就得到了整个函数 f的总损失值 L(w,b)。损失值越小,表明模型在所有数据点上的预测结果与真实值越接近,该函数的预测性能就越好。
由下图2.4所示,得到的loss图中,这个空间上的每一点 (w,b) 都对应着一个具体的预测函数(例如点 (−180,−2) 对应函数 y=−180−2⋅xcp)。最重要的是,图中的颜色梯度直观地展现了损失函数 L(w,b) 的值:颜色越接近红色(或橙色叉号标记的“Smallest”点),表示该点对应函数的损失值越小,其预测能力越优;颜色越偏蓝、紫或标记为“Very large”的区域,则表示该点对应函数的损失值越大,预测能力越差。
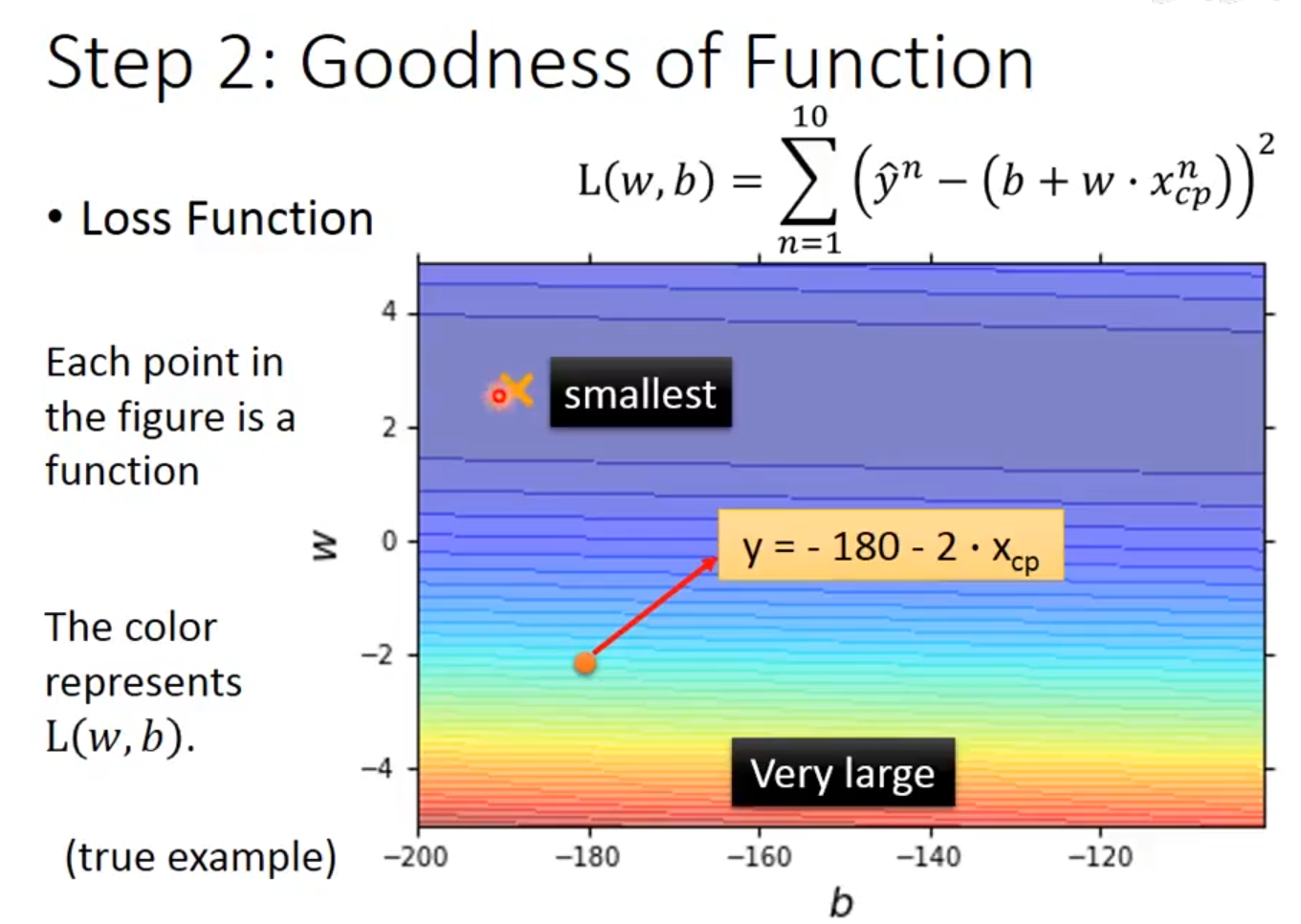
图2.4损失程度色图
2.3 STEP3:Best function
由下图2.5所示,将训练数据转化为量化指标。这个公式如同一把尺子,通过累计所有样本的预测误差平方和,为每个函数打出一个具体的“分数”——损失值越小,函数对数据的拟合程度越高。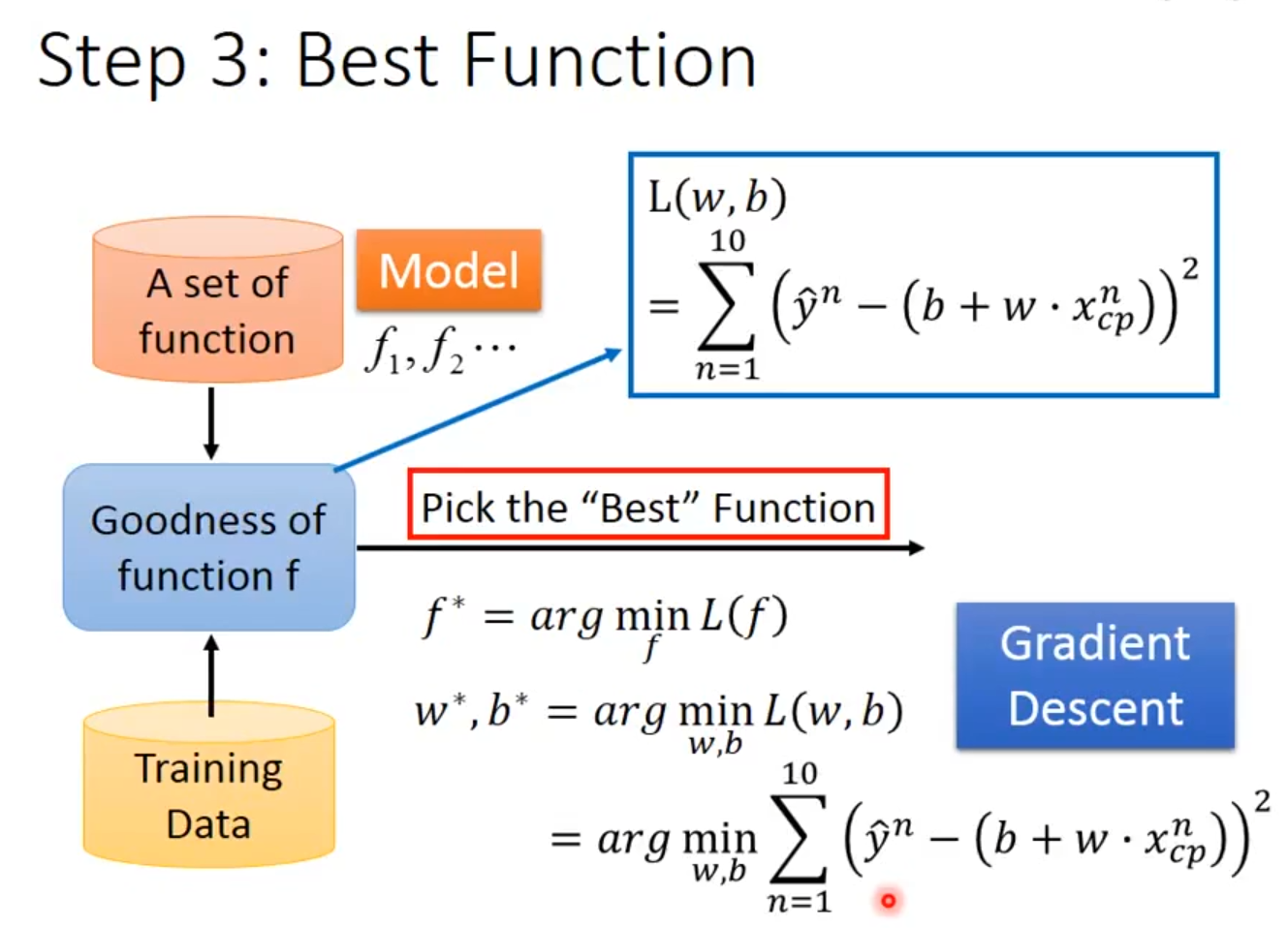
图2.5 最优函数梯度下降
由下图2.6,梯度下降局部最优图可知,损失函数的形状(棕色曲线)并非完美碗状(凸函数)。它包含了一个 “局部最优(Local optimal)” 点。该点的导数也为零(水平切线),是损失函数在一个小范围内的谷底。算法有可能在下降过程中“卡”在这个局部谷底,无法再下降到真正的全局最小值(全局最优解)。图中特别注明这个点 “not global optimal”,深刻提醒使用者:梯度下降的最终结果 依赖于初始点 w0 的选择和学习率 η 的设置,有时会收敛到次优解而非全局最优解。
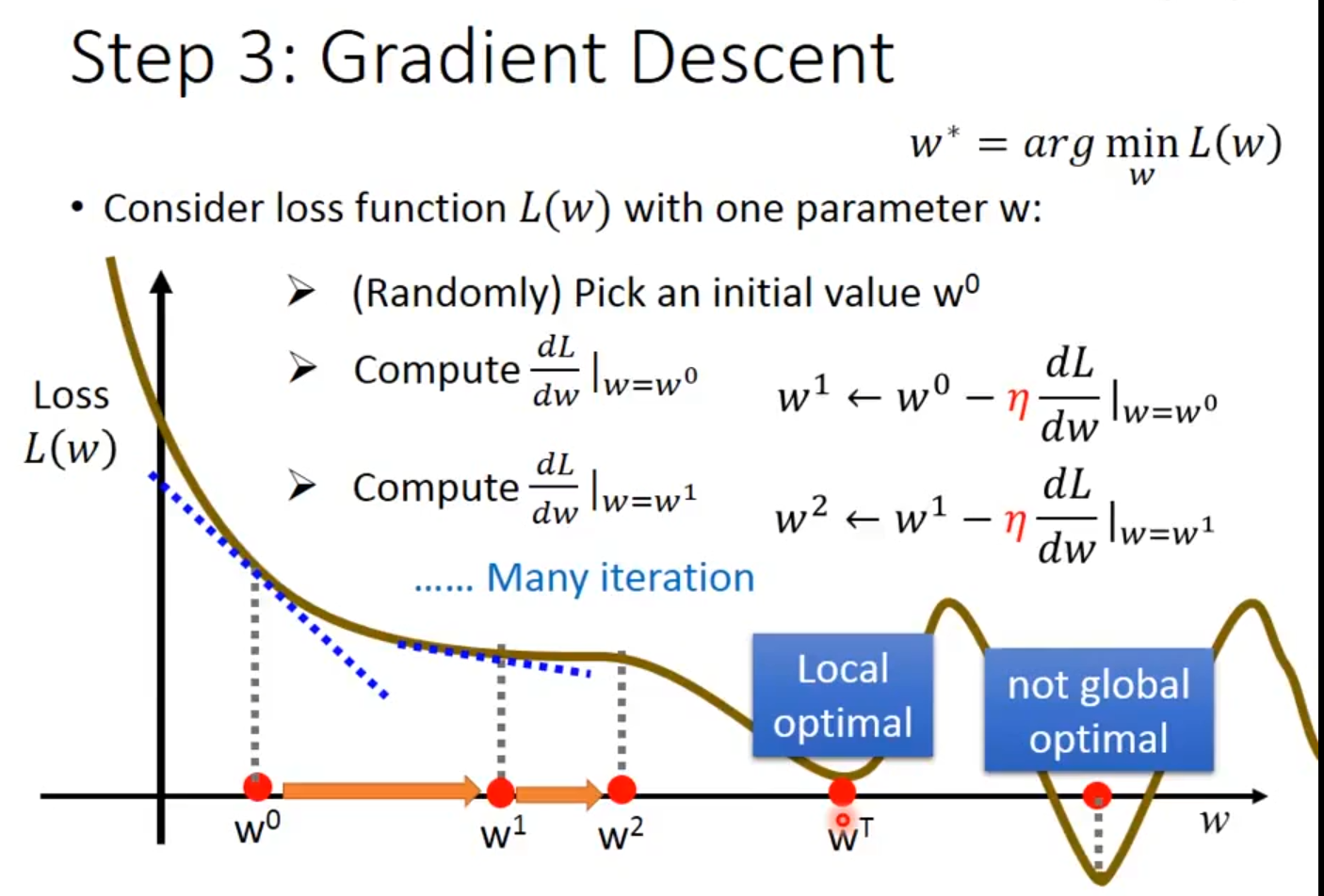
图2.6 梯度下降局部最优图
本次宝可梦需要求出两个参数,故而需要用两个参数去梯度下降,如下图2.7所示。

图2.7两个参数的计算
对于线性回归模型,其损失函数 L(w,b) 具有一个至关重要的数学性质——它是凸函数。这意味着它的曲面形状如同一个光滑的“碗”,只有一个全局最低点,而不存在多个局部最低点。因此,无论梯度下降算法从哪个随机初始点 (w0,b0) 开始,只要选择合适的学习率 η,它都必定能够收敛到同一个全局最优解 (w∗,b∗),找到使损失函数最小的最佳参数组合。如下图2.8所示。
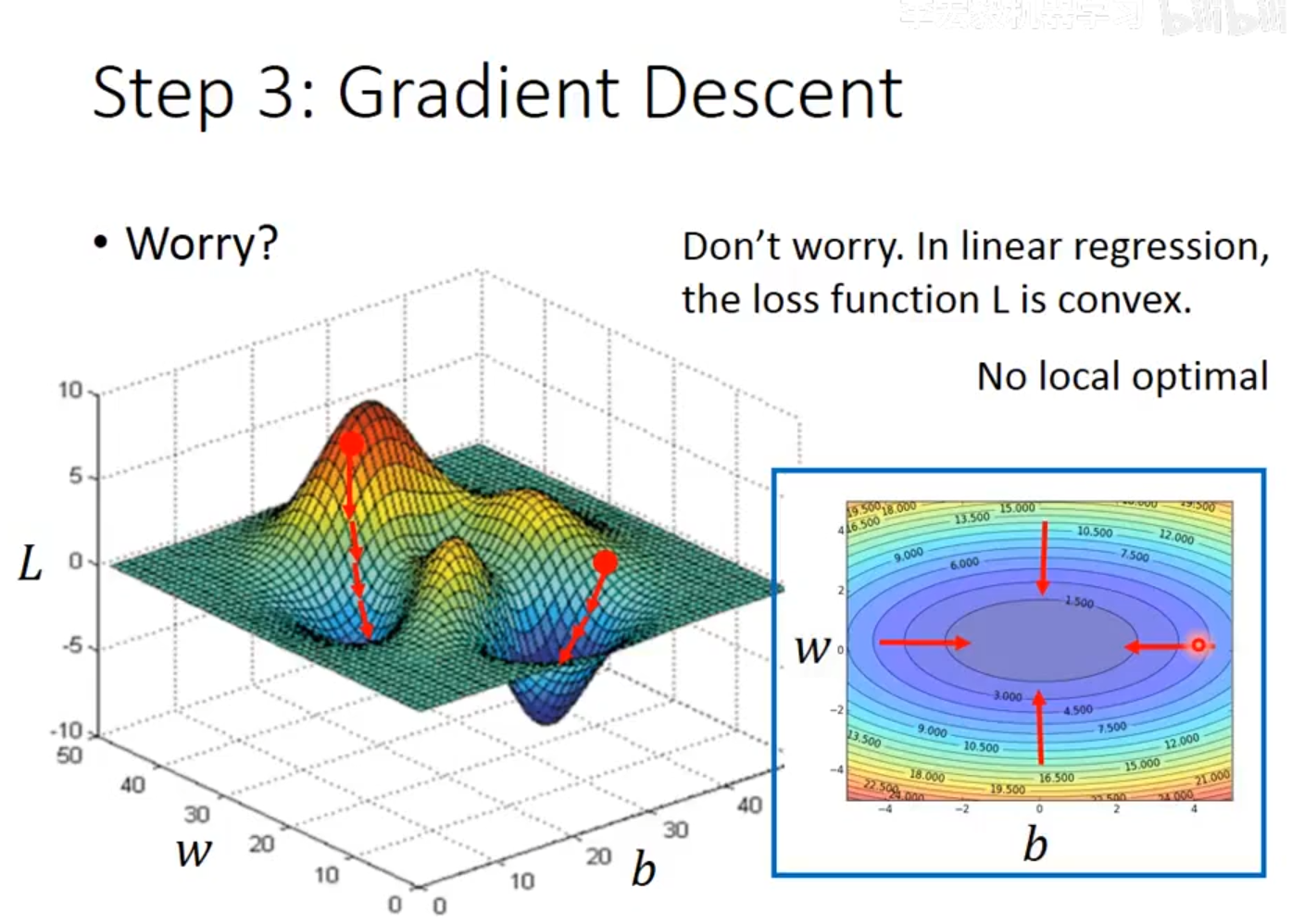
图2.8损失函数三维地形图
由上图可知,三维曲面图将抽象的损失函数 L(w,b) 具象化为一座起伏的“山脉”。曲面的高度代表损失函数值的大小——高峰区域对应高损失值,低谷区域对应低损失值。曲面上蜿蜒的红色箭头清晰地标示了梯度下降的优化路径:它从某个随机初始点 (w0,b0) 出发,沿着曲面上最陡峭的下坡方向 一步步向谷底移动。值得注意的是,这个曲面模拟了非凸函数的复杂地形,展示了多个“谷底”,暗在一般优化问题中梯度下降可能陷入局部最小值而非全局最优解的风险。
模型采用最简单的线性形式 y=b+w⋅xcp,根据训练数据学习到参数 b=−188.4 和权重 wˉ=2.7。在训练数据上的平均误差为31.9。由数据可计算,由下图2.9所示。
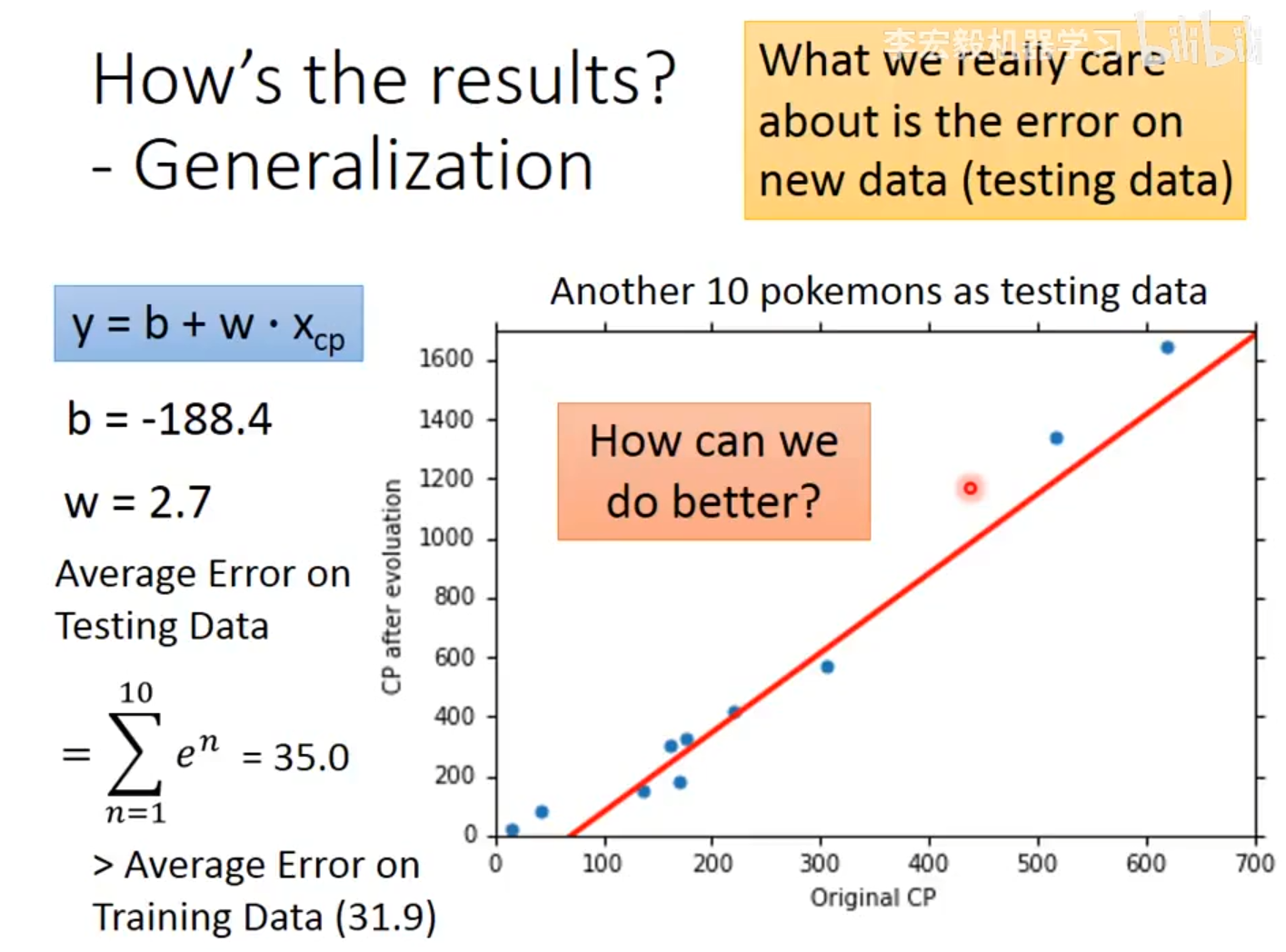
图2.9数据测试图
注:文章相关图片均为李宏毅老师的机器学习内容

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)