回合制战略游戏AI设计:挑战与实践
在当今的数字娱乐时代,回合制战略游戏因其深度和策略性,成为了许多玩家的心头好。AI(人工智能)作为这一类游戏的核心组成部分,负责提供引人入胜的游戏体验,挑战玩家的决策和策略能力。本章将对回合制战略游戏AI的设计进行概述,为后续章节的深入探讨打下基础。首先,我们将探讨AI设计的基本概念和原则。AI的智能程度直接影响到游戏的平衡性和玩家的沉浸感,因此,设计者需要在复杂性与玩家体验之间找到一个合理的平衡

简介:回合制战略游戏的AI设计要求模拟真实决策过程,提供具有挑战性和趣味性的游戏体验。关键知识点包括状态机、决策树、路径规划、优先级队列、威胁评估、资源管理、学习算法、模糊逻辑、多智能体系统、脚本语言、行为树、模拟与预测、适应性及难度等级。这些技术的应用旨在使NPC行为更加智能,增强游戏沉浸感。 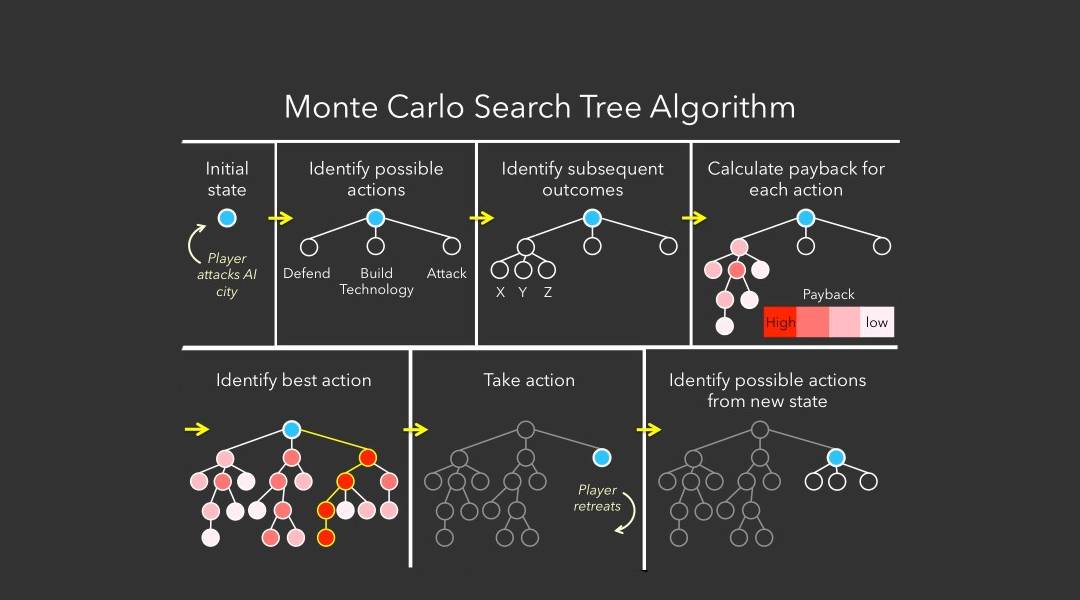
1. 回合制战略游戏AI设计概述
在当今的数字娱乐时代,回合制战略游戏因其深度和策略性,成为了许多玩家的心头好。AI(人工智能)作为这一类游戏的核心组成部分,负责提供引人入胜的游戏体验,挑战玩家的决策和策略能力。本章将对回合制战略游戏AI的设计进行概述,为后续章节的深入探讨打下基础。
首先,我们将探讨AI设计的基本概念和原则。AI的智能程度直接影响到游戏的平衡性和玩家的沉浸感,因此,设计者需要在复杂性与玩家体验之间找到一个合理的平衡点。
接下来,我们将讨论AI设计的五大支柱:状态机模型、决策树、路径规划算法、模拟与预测能力以及适应性与难度调节。这些技术构成了AI设计的基础,它们分别负责处理游戏内的不同逻辑和策略。
随着对每个支柱深入分析,我们会发现AI设计不仅仅是一门科学,更是一门艺术。设计师需要创造性地思考如何将这些技术融合到游戏中,创造出既能自我进化又能适应不同玩家行为的智能对手。
让我们开始本章内容,一起揭开回合制战略游戏AI设计的神秘面纱。
2. 状态机模型在游戏AI中的应用
2.1 状态机模型基础
2.1.1 状态机模型的定义和特点
状态机模型是一种被广泛应用于游戏AI中的行为控制系统。该模型由一系列有限的状态以及在这些状态之间转换的规则组成。状态机可以非常直观地反映游戏AI中的决策流程,其核心特点在于易于理解和实现,同时在状态转换时能够清晰表示AI的行为变化。
特点包括:
- 确定性 :从一个状态到另一个状态的转换是明确的,每个状态都有明确的入口和出口。
- 离散性 :状态机模型中的状态是离散的,不存在模棱两可的情况。
- 可预测性 :给定相同的输入和状态,输出总是可预测的。
2.1.2 状态机模型在游戏AI中的应用场景
状态机模型非常适合于处理游戏中的AI决策问题,尤其适用于需要明确状态转换逻辑的场合,如NPC(Non-Player Character)行为控制、战斗系统、事件处理等。例如,在一个角色扮演游戏中,一个NPC可能有“巡逻”、“追击”、“攻击”和“撤退”等状态,状态机可以帮助开发者清晰定义这些行为之间的转换条件。
2.2 状态机模型的设计与实现
2.2.1 设计状态机模型的步骤和方法
设计一个有效的状态机模型需要遵循以下步骤:
- 需求分析 :明确游戏AI需要完成的任务,以及在这些任务中可能出现的所有状态。
- 状态定义 :根据需求分析的结果定义所有的状态,并明确每个状态的特点和作用。
- 转换逻辑设计 :设计状态之间的转换逻辑,这通常涉及到基于事件或条件触发的转移。
- 实现细节 :在代码层面上实现状态机,包括状态的存储和状态转换的处理。
在实际实现中,状态机模型可以通过简单的条件判断实现,也可以使用更高级的设计模式如有限状态机(FSM)和行为树(BT)来实现更复杂的AI行为。
2.2.2 实现状态机模型的编程技巧
下面的代码示例展示了如何使用Python实现一个基本的状态机模型:
class State:
def enter(self):
pass
def update(self):
pass
def exit(self):
pass
class FiniteStateMachine:
def __init__(self):
self.states = {}
self.cur_state = None
self.prev_state = None
def add_state(self, name, state):
self.states[name] = state
def set_cur_state(self, name):
if self.cur_state is not None:
self.cur_state.exit()
self.prev_state = self.cur_state
self.cur_state = self.states[name]
self.cur_state.enter()
def update(self):
if self.cur_state:
self.cur_state.update()
# 示例状态定义
class PatrolState(State):
def enter(self):
print("PatrolState entered")
def update(self):
print("PatrolState update")
def exit(self):
print("PatrolState exited")
# 创建状态机并添加状态
fsm = FiniteStateMachine()
fsm.add_state('Patrol', PatrolState())
# 切换状态并更新状态机
fsm.set_cur_state('Patrol')
fsm.update()
在这个示例中,我们首先定义了一个基本的 State 类,这个类有 enter 、 update 和 exit 三个方法。然后我们定义了一个 FiniteStateMachine 类来管理状态的切换。最后,我们创建了一个巡逻状态 PatrolState 并将其添加到状态机中。
需要注意的是,状态机的设计应该是可扩展的,允许方便地添加新的状态和转换规则,以适应游戏逻辑的变化。
此编程技巧的逻辑分析在于,通过将行为封装在状态对象中,我们能够清晰地管理状态之间的转换,以及在不同状态下的行为。在状态机中,每个状态都负责自己的行为逻辑,当状态切换发生时,前一个状态会触发 exit 方法,新状态会触发 enter 方法,并在每个 update 周期进行状态内部的更新。
在实际游戏开发中,状态机模型的设计和实现需要考虑更多细节,如避免状态转换中的竞争条件,以及如何优雅地处理状态机的保存和加载。
3. 决策树在AI中的实现
决策树是一种基础而强大的算法,广泛应用于分类和回归任务中,因其易于理解和实施而受到欢迎。在游戏AI领域,决策树可以模拟游戏中角色或NPC的决策过程,提供丰富的交互体验。在这一章节中,我们将探讨决策树模型的基础知识、在游戏AI中的应用场景、设计与实现决策树模型的步骤和方法,以及相关的编程技巧。
3.1 决策树模型基础
3.1.1 决策树模型的定义和特点
决策树是一种模拟决策过程的图形化模型,由节点和有向边组成。每个内部节点表示属性/特征的测试,每个分支代表测试结果的输出,而每个叶节点代表类的标签。决策树具有以下特点:
- 直观性: 决策树的图形化表现使它易于理解和解释。
- 非参数性: 决策树不需要对数据做任何假定。
- 多线性: 能够处理多值输出分类问题。
3.1.2 决策树模型在游戏AI中的应用场景
在游戏AI中,决策树被用来模拟角色行为,如敌人的战斗策略、NPC对话选择和游戏内事件的触发。例如:
- 角色AI: 游戏中的非玩家角色可以使用决策树来做出战斗决策,如选择攻击方式或逃跑。
- 故事情节: 决策树可以用来决定角色对话的选择,或者根据玩家的行为改变游戏世界的状态。
3.2 决策树模型的设计与实现
3.2.1 设计决策树模型的步骤和方法
设计决策树模型通常涉及以下步骤:
- 特征选择: 确定用于决策树构建的特征。
- 树生成: 基于特征和训练数据递归地选择最优特征并划分数据集,直到满足终止条件。
- 树剪枝: 减少树的大小来避免过拟合。
特征选择是关键步骤,常用的方法有信息增益、基尼指数等。
3.2.2 实现决策树模型的编程技巧
在实现决策树时,选择合适的编程语言和库至关重要。以下是一个使用Python语言和 scikit-learn 库构建简单决策树模型的示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 初始化决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Model accuracy: {accuracy:.2f}")
在上述代码中,我们首先导入所需的库和数据集,然后使用 train_test_split 划分数据,并使用 DecisionTreeClassifier 来训练和预测模型。最后,我们计算并打印出模型的准确率。代码中使用了Pandas库来展示数据,因为其具有易于理解的表格形式。
在构建决策树模型时,我们需要关注模型的复杂度和数据的维度。对数据进行预处理,比如特征缩放或缺失值处理,对于提高模型性能也是至关重要的。在训练模型后,通常需要进行模型评估和调整参数,以获得最佳的模型性能。
以上内容为第三章的主体部分,详细阐释了决策树模型的基础知识、应用场景、设计与实现步骤和方法,并通过代码示例展示了具体的编程技巧。决策树模型在游戏AI设计中扮演着关键角色,是实现智能交互的重要工具。
4. 路径规划算法在AI中的应用
路径规划算法是游戏AI领域中的关键技术之一,用于实现游戏角色或单位在游戏环境中的移动和导航。这一章节将深入探讨路径规划算法的基础知识、应用场景、设计与实现的详细步骤和编程技巧。
4.1 路径规划算法基础
4.1.1 路径规划算法的定义和特点
路径规划算法是一系列为移动实体从起点到终点规划最优或可行走路径的算法。它们的主要目标是在复杂环境中找到一条避开障碍物、满足特定约束(如最短路径、最小成本等)的可行路径。路径规划算法具有以下特点:
- 最优性 :寻找在某种度量标准下的最优路径,如最短距离、最少时间或最低成本。
- 可行性 :考虑实体的尺寸、移动能力以及环境中的障碍物,确保路径在物理上是可行的。
- 适应性 :能够适应环境的变化,如障碍物的移动或消失,以及地形的改变。
- 实时性 :在实时交互的游戏中,路径规划算法需要快速响应环境变化和玩家输入。
4.1.2 路径规划算法在游戏AI中的应用场景
路径规划算法在游戏AI中有广泛的应用场景,例如:
- 角色移动 :为非玩家角色(NPC)规划从当前位置到目标位置的路径。
- 动态障碍物规避 :处理动态出现的障碍物,如玩家移动或其他NPC的活动。
- 探索和巡逻 :自动规划巡逻路径或探索地图的未知区域。
- 战斗规划 :在战术游戏中,为单位规划避开敌人攻击并接近敌人的路径。
4.2 路径规划算法的设计与实现
4.2.1 设计路径规划算法的步骤和方法
设计路径规划算法通常涉及以下步骤:
- 环境建模 :构建游戏环境的地图表示,包括地形、障碍物以及可通行区域。
- 路径搜索 :采用合适的搜索算法,如A 、Dijkstra或Theta 算法,搜索从起点到终点的路径。
- 路径平滑 :对搜索得到的路径进行平滑处理,以获得更自然、高效的移动轨迹。
- 实时更新 :根据游戏环境的变化实时更新路径。
4.2.2 实现路径规划算法的编程技巧
以下是一个简化的A*搜索算法的Python示例代码,展示了如何在二维网格地图上为一个点寻找另一个点的最短路径。
import heapq
class Node:
def __init__(self, parent=None, position=None):
self.parent = parent
self.position = position
self.g = 0 # Cost from start to current node
self.h = 0 # Heuristic cost from current node to goal
self.f = 0 # Total cost
def __eq__(self, other):
return self.position == other.position
def __lt__(self, other):
return self.f < other.f
def astar(maze, start, end):
# Create start and end node
start_node = Node(None, start)
start_node.g = start_node.h = start_node.f = 0
end_node = Node(None, end)
end_node.g = end_node.h = end_node.f = 0
# Initialize open and closed list
open_list = []
closed_list = []
# Add the start node
heapq.heappush(open_list, start_node)
# Loop until you find the end
while len(open_list) > 0:
# Get the current node
current_node = heapq.heappop(open_list)
closed_list.append(current_node)
# Found the goal
if current_node == end_node:
path = []
current = current_node
while current is not None:
path.append(current.position)
current = current.parent
return path[::-1] # Return reversed path
# Generate children
children = []
for new_position in [(0, -1), (0, 1), (-1, 0), (1, 0)]: # Adjacent squares
node_position = (current_node.position[0] + new_position[0], current_node.position[1] + new_position[1])
# Make sure within range
if node_position[0] > (len(maze) - 1) or node_position[0] < 0 or node_position[1] > (len(maze[len(maze)-1]) -1) or node_position[1] < 0:
continue
# Make sure walkable terrain
if maze[node_position[0]][node_position[1]] != 0:
continue
# Create new node
new_node = Node(current_node, node_position)
# Append
children.append(new_node)
# Loop through children
for child in children:
# Child is on the closed list
if child in closed_list:
continue
# Create the f, g, and h values
child.g = current_node.g + 1
child.h = ((child.position[0] - end_node.position[0]) ** 2) + ((child.position[1] - end_node.position[1]) ** 2)
child.f = child.g + child.h
# Child is already in the open list
for open_node in open_list:
if child == open_node and child.g > open_node.g:
continue
# Add the child to the open list
heapq.heappush(open_list, child)
return None
# Example maze (0 = open, 1 = barrier)
maze = [[0, 0, 0, 0, 1],
[0, 1, 1, 0, 1],
[0, 0, 0, 1, 0],
[1, 1, 0, 0, 0],
[0, 0, 0, 0, 0]]
start = (0, 0)
end = (4, 4)
path = astar(maze, start, end)
print(path)
参数说明 :
- maze :表示游戏环境的地图,其中0表示可以通行,1表示障碍物。
- start :起点坐标。
- end :终点坐标。
逻辑分析 :
- 该A*算法实现了一个优先队列(最小堆),用于存储待处理的节点,并按照f值排序。
- 通过迭代的方式从起点出发,逐步扩展并更新节点的g、h和f值。
- h值采用了曼哈顿距离作为启发式评估,计算从当前节点到终点的预计成本。
- 一旦找到终点节点,算法停止并将反向构建的路径返回。
应用示例表格
| 算法类型 | 描述 | 适用场景 | 优缺点 |
|---|---|---|---|
| A*算法 | 一种广泛使用的路径规划算法,通过启发式搜索找到最短路径 | 多样化的游戏环境和角色导航 | 优点是效率高、结果好;缺点是需要预定义的启发式函数 |
| Dijkstra算法 | 一种用于在图中找到最短路径的经典算法,不依赖于启发式评估 | 适用于简单或静态的环境 | 优点是简单易实现;缺点是效率较低,不适合大型地图 |
| Theta*算法 | A*算法的扩展,允许斜向移动和更自然的路径 | 需要更自然、更流畅路径的3D或复杂地形环境 | 优点是路径更自然;缺点是实现较复杂且计算成本高 |
以上表格对比了三种常见的路径规划算法,指出了它们的适用场景和优缺点。
在实际游戏开发中,除了上述表格中列出的算法之外,还有许多其他路径规划算法,例如RRT(Rapidly-exploring Random Tree)、动态A (D )等。根据具体的游戏需求和环境复杂度选择合适的路径规划算法是实现高效AI的关键。
本章节所介绍的路径规划算法基础、设计与实现,为读者提供了一个全面的视角来理解并应用这些算法,以提升游戏AI的导航能力。随着技术的不断进步和游戏复杂性的增加,路径规划算法在游戏AI中的作用日益突出,成为开发者不可或缺的技能之一。
5. AI的模拟与预测能力
5.1 AI模拟与预测能力的重要性
AI的模拟与预测能力是构建复杂游戏AI系统中不可或缺的一部分。它能够使AI在没有真实世界数据输入的情况下,基于现有的游戏状态和历史数据,预测可能发生的事件和行为,并作出相应的策略调整。这种能力极大地提升了游戏的真实感和挑战性,同时也提高了玩家的沉浸感和满足度。
5.1.1 AI模拟与预测能力的定义和特点
在游戏AI领域,模拟指的是利用模型来模仿游戏世界的动态行为,而预测则是指对未来游戏状态的预判。这两种能力通常结合在一起,让AI能够根据历史数据和当前情境,推算出下一步可能出现的情况。
AI模拟与预测具有以下特点:
- 自主性 :AI可以在不受外界信息影响的情况下,自主进行模拟和预测。
- 动态适应性 :AI的模拟与预测能够根据游戏环境的变化做出动态的调整。
- 策略性 :预测的结果会影响AI的决策过程,使AI能够制定更加合理和有效的策略。
5.1.2 AI模拟与预测能力在游戏AI中的应用场景
在实时策略游戏中,AI可以通过模拟对手的可能行动来制定对抗策略;在角色扮演游戏(RPG)中,AI可以预测玩家的行为并做出适当的回应,以此来提升游戏难度;在体育模拟游戏中,AI利用预测来模拟比赛结果,使得游戏体验更为真实和具有挑战性。
5.2 AI模拟与预测能力的设计与实现
设计和实现AI的模拟与预测能力,需要考虑算法的选择、历史数据的处理、实时性要求等多个方面。在本章节中,我们将探讨这些方面的具体内容和实现方法。
5.2.1 设计AI模拟与预测能力的步骤和方法
设计AI模拟与预测能力时,以下步骤和方法是必须要考虑的:
- 需求分析 :明确游戏类型和AI需要预测与模拟的目标。
- 算法选择 :根据需求选择合适的预测算法,如蒙特卡罗树搜索(MCTS)、深度学习、启发式搜索等。
- 数据处理 :整理和处理历史数据以供AI学习和模拟使用。
- 模型训练 :使用历史数据对所选算法进行训练,以提高预测的准确性。
- 集成与测试 :将训练好的模型集成到游戏中,并进行全面测试。
5.2.2 实现AI模拟与预测能力的编程技巧
在编程实现时,我们需要特别注意以下几个方面:
- 代码效率 :模拟与预测可能需要大量的计算资源,因此优化代码性能是关键。
- 代码模块化 :将算法分解成多个模块,便于维护和更新。
- 算法调优 :根据实际运行情况对算法参数进行调优,以适应游戏的实时性要求。
以下是一个简单的模拟与预测代码示例:
# 使用Python的决策树算法进行预测
from sklearn.tree import DecisionTreeRegressor
import numpy as np
# 假设我们有一些历史数据
X = np.array([[1], [2], [3], [4]]) # 特征数据
y = np.array([1, 2, 3, 4]) # 目标数据
# 创建并训练模型
model = DecisionTreeRegressor()
model.fit(X, y)
# 预测新数据
new_data = np.array([[5], [6]])
predicted_results = model.predict(new_data)
# 打印预测结果
print(predicted_results)
在上面的代码中,我们首先导入了 DecisionTreeRegressor 类用于回归问题的预测,并创建了一个模型实例。然后,我们用已有的数据来训练这个模型,并使用训练好的模型对新的数据进行预测。这个过程展示了模拟与预测能力实现的基本步骤。
在实际应用中,我们需要更为复杂的模型和大量数据来训练AI,以便其能够更准确地预测。例如,在实时策略游戏中,AI可能需要预测对手的战术布局和未来行动,从而做出相应的调整。为了实现这一点,我们可以使用强化学习方法,如深度Q网络(DQN),来训练AI进行模拟和预测。
模拟与预测在游戏AI中的应用是多面的,不仅可以提高游戏的可玩性,还能够丰富游戏的内容。通过本文的介绍,您应该对AI模拟与预测能力有了初步的理解,并能够根据自身游戏的需求来设计和实现相应的能力。
6. AI的适应性与难度调节
6.1 AI适应性与难度调节的重要性
适应性和难度调节是游戏AI设计中的关键特性。它们确保游戏对玩家保持挑战性,同时避免过度困难或太容易,从而提高玩家的满意度和游戏的可玩性。
6.1.1 AI适应性与难度调节的定义和特点
AI的适应性指的是AI系统能够根据玩家的行为和游戏进展动态调整其难度和行为策略的能力。这种适应性能够让游戏体验变得更加个性化和有趣,适应性AI可以在玩家遇到困难时降低难度,或者在面对高手时提升挑战性。
难度调节则是指游戏设计中用于控制玩家体验难度的机制。它允许游戏设计师或AI系统根据玩家的表现来调整游戏的挑战水平,确保玩家在整个游戏过程中都保持在最佳的挑战与能力的平衡点(也被称为流状态)。
6.1.2 AI适应性与难度调节在游戏AI中的应用场景
在回合制战略游戏中,适应性AI可以调整敌人的决策逻辑,例如,在玩家连续取得胜利时提高敌人AI的策略复杂度,或在玩家持续失败时减少敌人的资源或能力。难度调节也可以用于动态调整地图的障碍物、敌人的资源分配或AI的预测能力。
6.2 AI适应性与难度调节的设计与实现
6.2.1 设计AI适应性与难度调节的步骤和方法
设计AI的适应性与难度调节通常遵循以下步骤:
- 分析玩家数据 :首先,需要收集和分析玩家行为数据来了解玩家在游戏中的表现和偏好。
- 设定调整参数 :基于收集的数据,设定可以调整的参数,如敌人的生命值、攻击力、防御力等。
- 设计反馈机制 :实现一个反馈系统,根据玩家的进展和成绩来动态调整上述参数。
- 实现调整算法 :使用算法来决定何时何地以及如何调整难度。这可能涉及机器学习技术或预设的逻辑规则。
- 测试与迭代 :持续测试AI的表现,并根据玩家反馈对AI进行迭代优化。
6.2.2 实现AI适应性与难度调节的编程技巧
编程技巧涉及实现适应性AI和难度调节系统的具体技术细节。以下是一个简化的代码示例,展示了如何在游戏循环中实现基于玩家表现的简单难度调节机制:
class DifficultyManager:
def __init__(self):
self.difficulty_level = 1 # 初始难度等级
def evaluate_performance(self, player_performance):
"""
根据玩家表现评估难度等级
"""
if player_performance > 0.8: # 玩家表现超过80%
self.difficulty_level += 1
elif player_performance < 0.3: # 玩家表现低于30%
self.difficulty_level -= 1
def adjust_game_parameters(self, game_parameters):
"""
调整游戏参数以匹配当前难度等级
"""
if self.difficulty_level > 1:
# 提高敌人的生命值和攻击力
game_parameters['enemy_health'] *= 1.2
game_parameters['enemy_damage'] *= 1.1
elif self.difficulty_level < 1:
# 降低敌人的生命值和攻击力
game_parameters['enemy_health'] /= 1.2
game_parameters['enemy_damage'] /= 1.1
# 使用难度管理器
game_parameters = {'enemy_health': 100, 'enemy_damage': 20}
difficulty_manager = DifficultyManager()
# 假设我们通过某种方式获得了玩家的表现数据
player_performance = 0.6 # 玩家表现60%
# 评估玩家表现并调整难度
difficulty_manager.evaluate_performance(player_performance)
# 调整游戏参数以适应新难度
difficulty_manager.adjust_game_parameters(game_parameters)
print(f"敌人的生命值调整后为: {game_parameters['enemy_health']}")
print(f"敌人的攻击力调整后为: {game_parameters['enemy_damage']}")
在上述代码中,我们定义了一个 DifficultyManager 类,它根据玩家的表现来调整难度等级,并基于这个等级来调整游戏参数。这只是一个非常基础的例子,实际实现可能会涉及到更复杂的机制,例如使用机器学习模型来预测玩家的行为,并据此进行微调。
通过上述步骤和代码示例,我们可以看到AI的适应性与难度调节如何被设计和实现,并通过编程技巧实现期望的游戏体验。然而,在真实游戏AI开发中,可能需要更复杂的算法和数据结构,以及持续的调优和测试来实现理想的游戏体验。
7. 多智能体系统理论与应用
7.1 多智能体系统理论基础
7.1.1 多智能体系统的定义和特点
多智能体系统(Multi-Agent Systems, MAS)是由多个交互式智能体组成的计算系统,这些智能体可以是人类、软件代理、机器人或者其他设备。在游戏AI的背景下,智能体通常指的是游戏中的非玩家角色(NPCs)。MAS的关键特点是它们的分布式决策过程,即每个智能体独立作出决策,但它们的行为需要彼此协调,以达到共同的目标或执行复杂的任务。
多智能体系统的特点主要包括:
- 自组织性 :智能体能够自主地响应环境的变化,无需中央控制。
- 协同性 :智能体之间可以有效地合作,以提高任务执行的效率和效果。
- 分布性 :系统的控制分布在多个智能体之间,不依赖于单一的中央控制点。
- 可扩展性 :系统能够适应新智能体的加入或现有智能体的退出,保持整体性能。
- 异质性 :构成系统的智能体可以是不同类型的,包括不同的功能和能力。
7.1.2 多智能体系统在游戏AI中的应用场景
在游戏AI中,多智能体系统广泛应用于模拟复杂的游戏环境和交互,以下是一些典型的应用场景:
- 策略游戏 :如RTS(实时战略游戏),每个单位或者基地可以被视为一个智能体。
- 团队合作 :在多人游戏中,玩家可以与由AI控制的队友一起执行任务。
- 动态环境 :游戏世界中的环境变化,如天气系统、经济系统,可以通过多智能体的交互来模拟。
- 角色行为 :NPC行为可以由多智能体系统来管理,如敌人的追踪和围攻策略。
7.2 多智能体系统的设计与实现
7.2.1 设计多智能体系统的步骤和方法
设计多智能体系统涉及以下几个关键步骤:
- 需求分析 :明确系统的目标,包括智能体之间的交互规则和协作目标。
- 智能体建模 :根据需求,设计个体智能体的结构和行为模型。
- 通信机制 :设计智能体之间的通信协议,确保信息可以正确交换。
- 协调机制 :确定智能体如何协作以完成共同任务,包括角色分配和冲突解决。
- 测试和评估 :对系统进行测试,评估其性能,进行必要的调优。
在设计过程中,还需要采用合适的建模方法,例如UML(统一建模语言)可以用来表示智能体之间的关系和交互。
7.2.2 实现多智能体系统的编程技巧
实现多智能体系统时,编程技巧通常包括:
- 模块化 :将系统分解为独立的模块,每个智能体是一个模块,便于管理和扩展。
- 并发编程 :由于多智能体系统具有并发性,需要利用多线程或异步编程技术来处理。
- 状态管理 :智能体的状态需要实时更新和同步,通常通过状态同步机制实现。
- 事件驱动 :智能体的行为应基于事件触发,这要求系统能有效地监听和响应事件。
以下是一个简化的伪代码示例,展示了多智能体系统中一个智能体的基本结构:
class Agent:
def __init__(self):
self.state = {} # 状态字典,存储当前状态信息
self.neighbors = [] # 邻居智能体列表
def receive_message(self, message):
# 处理接收到的消息
pass
def update_state(self):
# 根据自身逻辑更新状态
pass
def make_decision(self):
# 基于当前状态和接收到的信息做出决策
pass
def send_message(self, target, message):
# 向目标智能体发送消息
pass
# 示例:创建智能体并进行简单的状态更新和信息传递
agent = Agent()
agent.update_state()
agent.make_decision()
agent.send_message(agent.neighbors[0], "协作请求")
在实际应用中,多智能体系统可能涉及到更多的细节和复杂性,例如机器学习技术的结合使用,以提升智能体的自主性和适应性。随着AI技术的不断进步,多智能体系统在游戏AI中的应用前景广阔,能够提供更加丰富和真实的交互体验。
简介:回合制战略游戏的AI设计要求模拟真实决策过程,提供具有挑战性和趣味性的游戏体验。关键知识点包括状态机、决策树、路径规划、优先级队列、威胁评估、资源管理、学习算法、模糊逻辑、多智能体系统、脚本语言、行为树、模拟与预测、适应性及难度等级。这些技术的应用旨在使NPC行为更加智能,增强游戏沉浸感。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)