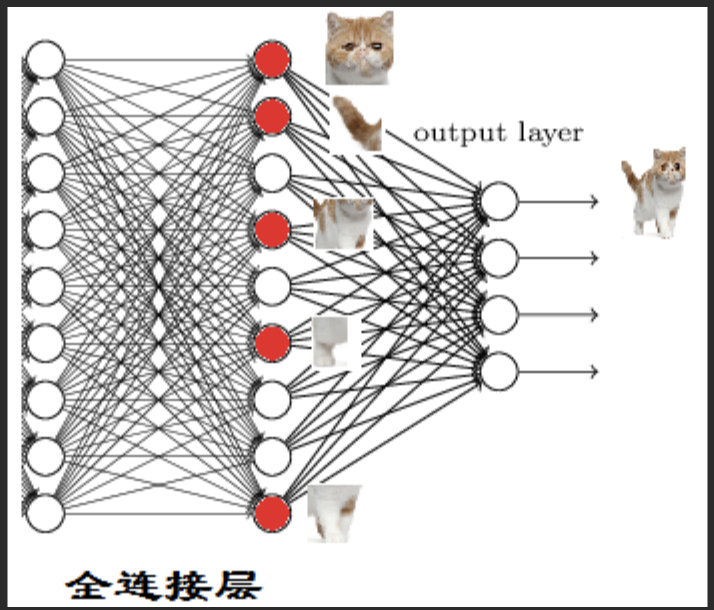
全链接层:线性变换与非线性整合
神经网络是一种受生物神经系统启发的计算模型,由大量简单处理单元(神经元)互联组成。通过调整连接权重来学习数据中的复杂模式。其中,**全连接层**(也称为线性层)作为核心组件,在结构上与生物神经元最为接近,是构建CNN、RNN等复杂网络架构的基础。
一、神经网络的本质与结构
神经网络是一种受生物神经系统启发的计算模型,由大量简单处理单元(神经元)互联组成。通过调整连接权重来学习数据中的复杂模式。其中,全连接层(也称为线性层)作为核心组件,在结构上与生物神经元最为接近,是构建CNN、RNN等复杂网络架构的基础。
全连接层的核心特征:
- 采用完全有向图结构,每层所有神经元与下一层全部神经元相连
- 每个连接拥有独立权重,用于调整信号传递强度
- 通常结合非线性激活函数,引入复杂模式表达能力
二、激活函数的核心作用
为什么需要非线性激活?
若缺少非线性激活函数,无论网络层数多少,整个模型都等价于单层线性模型,无法学习复杂模式。典型表现为:
- 无法解决非线性问题
例如XOR问题(异或逻辑),单层线性模型无法解决,而加入激活函数后可实现非线性划分:- 无激活函数:仅能学习线性划分(如直线)
- 有激活函数:可学习复杂曲线或区域划分
常见激活函数对比
| 函数类型 | 数学表达式 | 输出范围 | 特性 |
|---|---|---|---|
| Sigmoid | f(z)=11+e−zf(z) = \frac{1}{1+e^{-z}}f(z)=1+e−z1 | [0,1][0, 1][0,1] | 压缩输出至概率区间,易梯度消失 |
| ReLU | f(z)=max(0,z)f(z) = \max(0, z)f(z)=max(0,z) | [0,+∞)[0, +\infty)[0,+∞) | 单侧抑制,缓解梯度消失 |
| Tanh | f(z)=ez−e−zez+e−zf(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}f(z)=ez+e−zez−e−z | [−1,1][-1, 1][−1,1] | 零中心化输出,适合对称数据 |
激活函数可视化
下面是三种常见激活函数(Sigmoid、ReLU和Tanh)的可视化图表,通过图像可以直观地看到它们的输出特性和曲线形状。
Sigmoid 激活函数
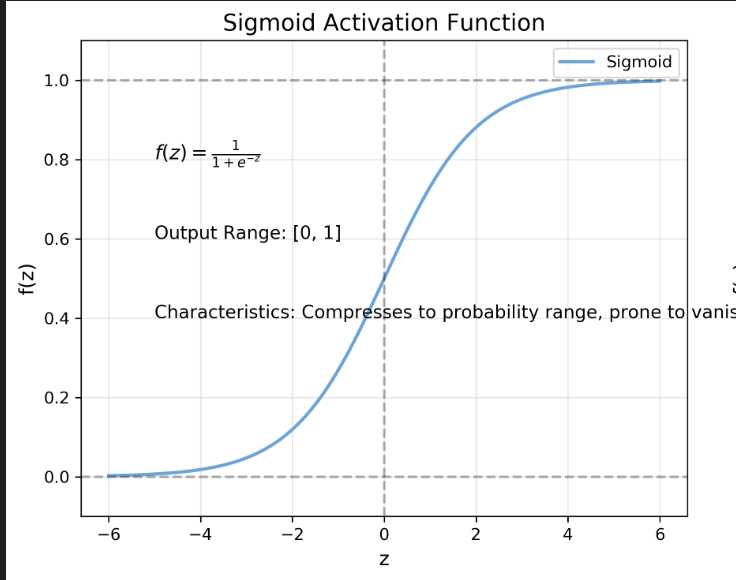
- 曲线形状:S型曲线,将任意输入压缩到[0,1]区间
- 数学表达式:f(z)=11+e−zf(z) = \frac{1}{1+e^{-z}}f(z)=1+e−z1
- 关键特性:
- 输出范围为[0,1],适合表示概率
- 当z接近±∞时,梯度趋近于0,容易导致梯度消失问题
- 输出非零中心化,可能导致神经元更新效率降低
ReLU 激活函数
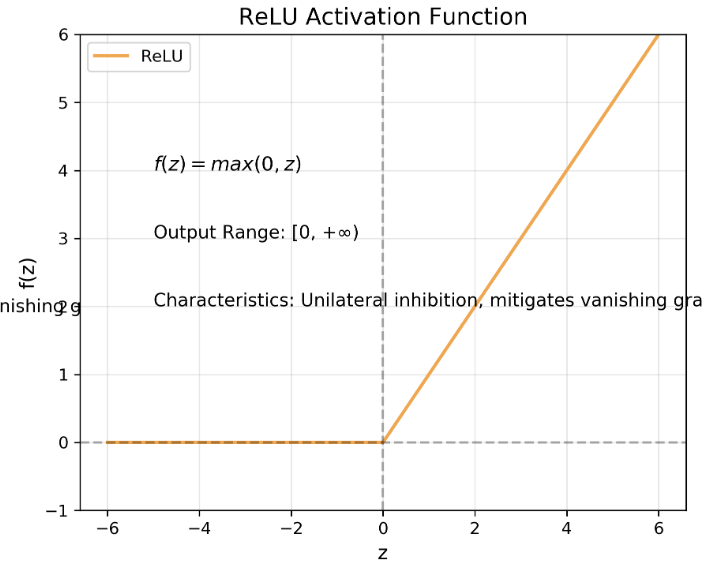
- 曲线形状:在z=0处有一个拐点,z<0时输出0,z≥0时输出z
- 数学表达式:f(z)=max(0,z)f(z) = max(0, z)f(z)=max(0,z)
- 关键特性:
- 输出范围为[0, +∞)
- 计算效率高,避免了指数运算
- 缓解了梯度消失问题,但可能导致"死神经元"问题(z<0时梯度为0)
- 单侧抑制特性,符合生物神经元的激活特性
Tanh 激活函数
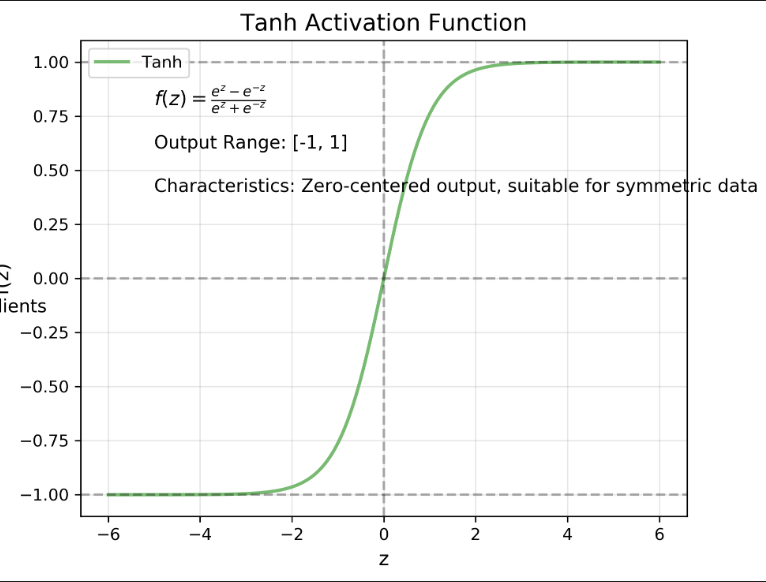
- 曲线形状:S型曲线,将任意输入压缩到[-1,1]区间
- 数学表达式:f(z)=ez−e−zez+e−zf(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}f(z)=ez+e−zez−e−z
- 关键特性:
- 输出范围为[-1,1],是零中心化的
- 解决了Sigmoid的非零中心化问题
- 当z接近±∞时,同样存在梯度消失问题
- 相比Sigmoid,Tanh通常有更好的性能表现
激活函数选择建议
- Sigmoid:适合二分类问题的输出层,或需要将输出表示为概率的场景
- ReLU:默认首选的隐藏层激活函数,计算高效且缓解梯度消失
- Tanh:适合需要零中心化输出的场景,如循环神经网络(RNN)
通过可视化可以更直观地理解这些激活函数的特性,这对于选择合适的激活函数和理解神经网络的行为非常有帮助。
三、全连接层的数学原理
1. 线性变换的矩阵表示
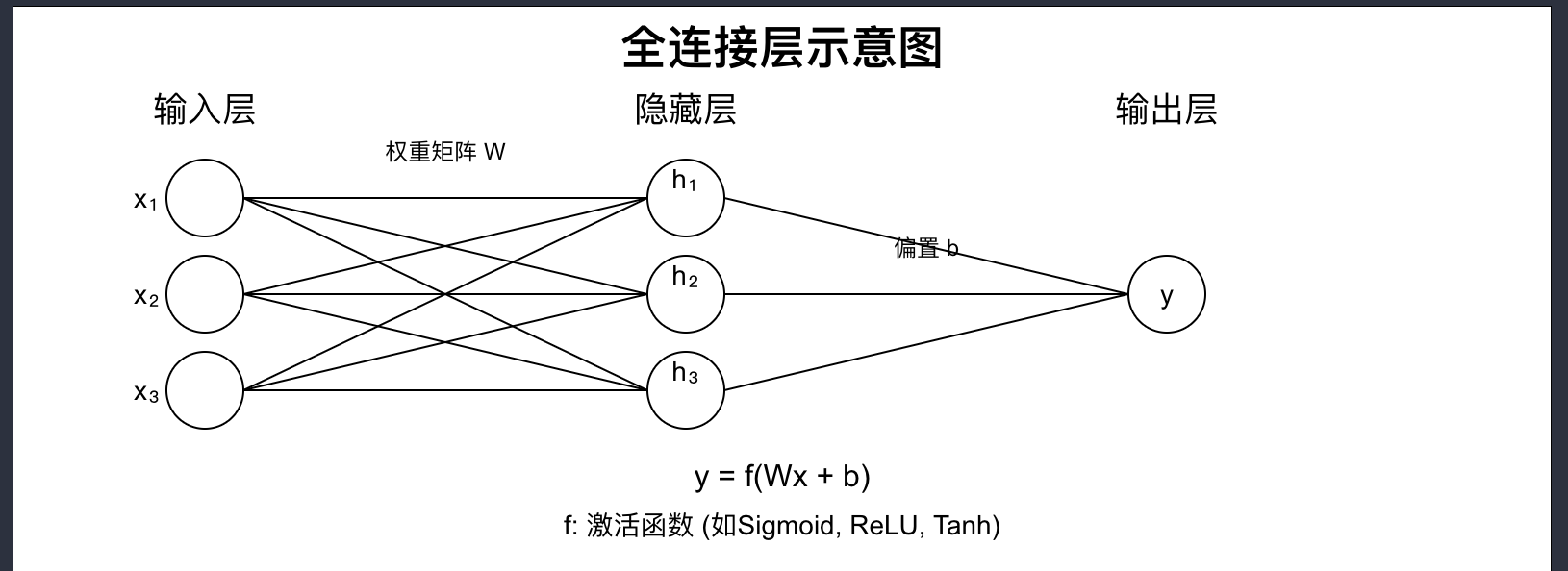
W:权重矩阵(维度:out_features×in_features\text{out\_features} \times \text{in\_features}out_features×in_features)
b\mathbf{b}b:偏置向量(维度:out_features×1\text{out\_features} \times 1out_features×1)
x\mathbf{x}x:输入向量(维度:in_features×1\text{in\_features} \times 1in_features×1)
2. 单神经元计算视角
输出向量 y\mathbf{y}y 的第 iii 个元素 yiy_iyi 的计算:
yi=∑j=1nwi,j⋅xj+biy_i = \sum_{j=1}^{n} w_{i,j} \cdot x_j + b_iyi=j=1∑nwi,j⋅xj+bi
其中:
- wi,jw_{i,j}wi,j:权重矩阵 WWW 的第 iii 行第 jjj 列元素
- xjx_jxj:输入向量 x\mathbf{x}x 的第 jjj 个元素
- bib_ibi:偏置向量 b\mathbf{b}b 的第 iii 个元素
3. 批量计算的矩阵优化
对于批量输入 XXX(维度:KaTeX parse error: Expected 'EOF', got '_' at position 12: \text{batch_̲size} \times \t…):
Y=XWT+BY = XW^T + BY=XWT+B
其中:
- WTW^TWT:权重矩阵的转置(维度:KaTeX parse error: Expected 'EOF', got '_' at position 9: \text{in_̲features} \time…)
- BBB:偏置向量的批量复制(维度:KaTeX parse error: Expected 'EOF', got '_' at position 12: \text{batch_̲size} \times \t…)
4. 非线性激活函数
线性变换后应用激活函数 f(⋅)f(\cdot)f(⋅) 引入非线性特性:
z=f(y)=f(Wx+b)\mathbf{z} = f(\mathbf{y}) = f(W\mathbf{x} + \mathbf{b})z=f(y)=f(Wx+b)
四、PyTorch实现全连接网络
以下是使用PyTorch构建多层全连接网络的完整示例:
import torch
import torch.nn as nn
class MultiLayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MultiLayerPerceptron, self).__init__()
# 第一层:线性变换 + ReLU激活
self.layer1 = nn.Sequential(
nn.Linear(input_dim, hidden_dim), # 线性变换
nn.ReLU() # 非线性激活
)
# 第二层:可选的隐藏层
self.layer2 = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU()
)
# 输出层:通常不使用激活(除特殊任务外)
self.output_layer = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.layer1(x) # 第一层处理
x = self.layer2(x) # 第二层处理(可选)
x = self.output_layer(x) # 输出层
return x
# 实例化模型(例如MNIST分类)
model = MultiLayerPerceptron(
input_dim=784, # 28x28像素图像
hidden_dim=256, # 隐藏层神经元数量
output_dim=10 # 10个分类类别
)
关键组件详解:
- nn.Linear:实现线性变换 y=Wx+by = Wx + by=Wx+b
- nn.ReLU:引入非线性激活 f(z)=max(0,z)f(z) = \max(0, z)f(z)=max(0,z)
- nn.Sequential:模块化组织网络层
- forward()方法:定义数据前向传播路径
五、核心总结
- 全连接层的核心作用:通过线性变换和非线性激活实现特征重组与复杂模式学习
- 激活函数的必要性:打破线性约束,使网络能够表达任意复杂函数
- PyTorch实现要点:使用
nn.Linear构建线性层,结合激活函数构建完整网络
理解全连接层的数学原理和PyTorch实现方式,是掌握深度学习基础的关键一步。后续可在此基础上扩展学习CNN、RNN等更复杂的网络架构。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)