基于深度学习的健身卡路里消耗预测模型
本文详细介绍了基于深度学习的健身卡路里消耗预测模型的构建过程,从项目背景、数据处理、模型构建与训练,到框架选择和前端实现,全方位展示了如何将深度学习技术应用于健身领域。通过这一项目,我们不仅能够为健身爱好者提供个性化的卡路里消耗预测,帮助他们更好地制定健身和饮食计划,还能展示深度学习在健康管理领域的广泛应用前景。未来,我们可以进一步优化模型,整合更多类型的健身数据,如运动类型、强度变化等,以提升预
目录
项目背景与目的
随着人们健康意识的提高,健身已成为许多人生活的一部分。然而,如何准确预测健身过程中的卡路里消耗,对于制定合理的健身计划和饮食计划至关重要。本项目旨在构建一个基于深度学习的预测模型,能够根据用户的健身数据(如年龄、体重、身高、心率等)预测其在健身过程中消耗的卡路里。
数据来源与预处理
-
数据来源:本项目使用了Kaggle平台上的健身会员运动追踪数据集,包含973条记录,涵盖年龄、性别、体重、身高、最大心率、平均心率、静息心率、训练时长、卡路里消耗等15个特征。
-
预处理方法:
-
数值特征标准化:对数值特征(如年龄、体重、身高、心率等)进行标准化处理,使其均值为0,标准差为1。
-
分类特征编码:对分类特征(如性别、训练类型)进行独热编码(One-Hot Encoding),将其转换为数值形式。
-
数据集划分:将数据集划分为训练集和测试集,比例为8:2。
-
# 数值特征标准化示例代码 scaler = StandardScaler() numeric_data = scaler.fit_transform(df[numeric_features]) # 分类特征编码示例代码 encoder = OneHotEncoder(sparse_output=False) categorical_data = encoder.fit_transform(df[categorical_features])模型构建与训练
-
网络结构:自定义了一个名为
FitnessNN的神经网络,包含三个全连接层(输入层到隐藏层1:128个神经元;隐藏层1到隐藏层2:64个神经元;隐藏层2到输出层:1个神经元),并在每个隐藏层后添加了ReLU激活函数和Dropout层(丢弃率0.3)以防止过拟合。 -
损失函数:采用均方误差(MSE)作为损失函数,衡量预测值与真实值之间的差异。
-
超参数调节:尝试了不同的学习率(0.001、0.0001等)和批次大小(32、64等),最终选择Adam优化器,学习率为0.001,批次大小为32,训练200个周期。
-
欠拟合与过拟合:训练过程中未出现明显的欠拟合或过拟合现象,通过添加Dropout层有效防止了过拟合。
-
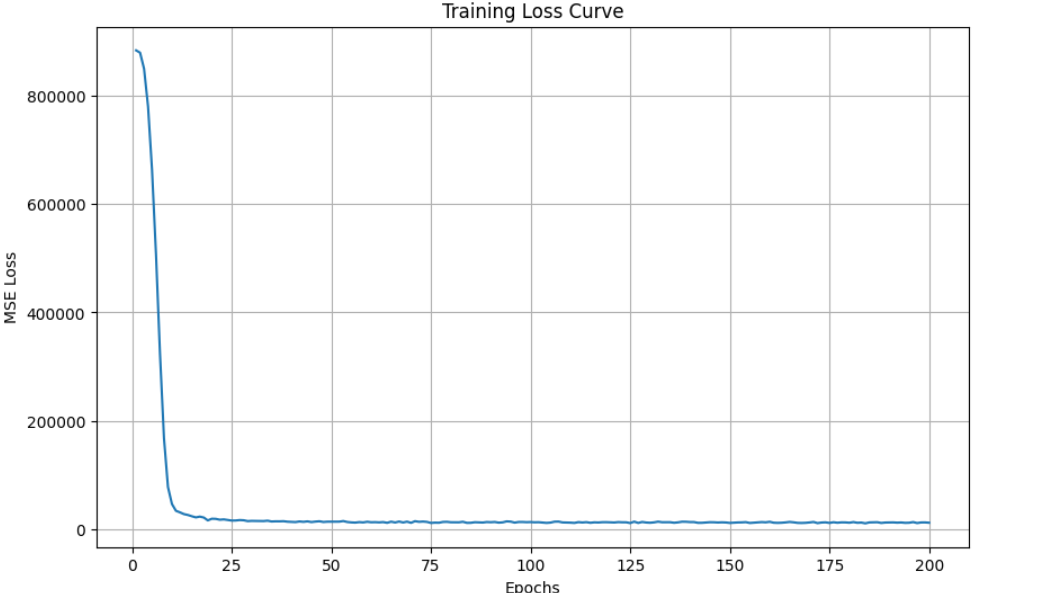
损失变化展示:训练过程中损失逐渐下降。
# 定义模型示例代码 class FitnessNN(nn.Module): def __init__(self, input_dim, hidden_dim1=128, hidden_dim2=64, output_dim=1): super(FitnessNN, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim1) self.relu1 = nn.ReLU() self.dropout1 = nn.Dropout(0.3) self.fc2 = nn.Linear(hidden_dim1, hidden_dim2) self.relu2 = nn.ReLU() self.dropout2 = nn.Dropout(0.3) self.fc3 = nn.Linear(hidden_dim2, output_dim) def forward(self, x): x = self.dropout1(self.relu1(self.fc1(x))) x = self.dropout2(self.relu2(self.fc2(x))) x = self.fc3(x) return x # 损失函数示例代码 criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=0.001)框架选择与前端实现
-
框架选择:选择PyTorch作为深度学习框架,因其灵活的动态计算图和强大的社区支持,便于模型的构建和训练。
-
前端实现:使用Gradio构建了一个用户友好的前端界面,用户可以通过滑块输入个人信息和健身数据,点击按钮即可获得卡路里消耗预测结果。
# 使用Gradio构建前端界面示例代码 with gr.Blocks(theme=gr.themes.Soft()) as demo: gr.Markdown("### 健身卡路里消耗预测器") gr.Markdown("根据您的健身数据预测卡路里消耗量") with gr.Row(): with gr.Column(): # 添加滑块和选择框 age = gr.Slider(minimum=15, maximum=80, step=1, value=30, label="年龄(岁)") weight = gr.Slider(minimum=40, maximum=150, step=0.5, value=70, label="体重(kg)") # 其他滑块和选择框... predict_btn = gr.Button("预测卡路里消耗 🚀") output = gr.Number(label="预测卡路里消耗(千卡)", value=0) predict_btn.click( fn=predict_calories, inputs=[age, weight, height, max_bpm, avg_bpm, resting_bpm, session_duration, fat_percentage, water_intake, workout_frequency, experience_level, bmi, gender, workout_type], outputs=output )训练损失变化图片
研究方向的经典算法/框架
-
线性回归:适用于简单线性关系的数据,但对非线性关系拟合能力有限。
-
支持向量机(SVM):适用于小样本、非线性数据,但对于大规模数据训练时间较长。
-
随机森林:适用于处理高维数据和非线性关系,但模型解释性较弱。
-
总结
-
本文详细介绍了基于深度学习的健身卡路里消耗预测模型的构建过程,从项目背景、数据处理、模型构建与训练,到框架选择和前端实现,全方位展示了如何将深度学习技术应用于健身领域。通过这一项目,我们不仅能够为健身爱好者提供个性化的卡路里消耗预测,帮助他们更好地制定健身和饮食计划,还能展示深度学习在健康管理领域的广泛应用前景。未来,我们可以进一步优化模型,整合更多类型的健身数据,如运动类型、强度变化等,以提升预测的精准度和实用性,为人们的健康生活提供更有力的支持。
-

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)