【精选】基于Byte Track改进的车辆行人多目标检测与追踪系统 融合YOLOv8的智能视频分析系统开发 车辆与行人多目标检测与追踪系统
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围: 我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp

博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!

本次博客目录:

摘要:
车辆行人多目标检测与追踪系统结合了先进的YOLOv8目标检测技术与ByteTrack多目标跟踪算法,能够在实时视频画面中准确地检测并跟踪行人与车辆。这一系统对于改善交通安全、提高城市监控效率以及增强公共安全管理具有显著的重要性。本文基于YOLOv8深度学习框架,通过5607张图片,训练了一个进行车辆与行人的目标检测模型,准确率高达94%;然后结合ByteTrack多目标跟踪算法,实现了目标的追踪效果。最终基于此开发了一款带UI界面的车辆行人多目标检测与追踪系统,可用于实时检测场景中的车辆与行人检测追踪,可以更加方便的进行功能展示。该系统是基于python与PyQT5开发的,支持视频以及摄像头进行多目标检测追踪,也可选择指定目标追踪,支持保存追踪结果视频。
2.1 Python技术简介
Python是一种高级、通用型编程语言,具有语法简洁、易于学习、可读性强等特点。Python支持面向对象编程、函数式编程和过程式编程,适用于多种开发场景,如Web开发、数据分析、人工智能、自动化脚本、图形界面开发等。Python拥有丰富的第三方库和工具,尤其在人工智能、计算机视觉和数据处理领域具有广泛应用。
Python具备良好的可扩展性与跨平台能力,其庞大的开源社区也为开发者提供了丰富的文档与资源。通过模块化设计和异常处理机制,Python能够高效构建可靠的软件系统。
2.2 PyQt图形界面开发简介
PyQt是Python绑定的Qt框架,是一种强大的GUI(图形用户界面)开发工具,能够开发跨平台的桌面应用程序。PyQt结合了Qt丰富的组件和Python简洁的语法,使得开发图形化应用程序变得高效且灵活。
使用PyQt可以创建窗口界面、按钮、菜单、对话框、图像展示等常见元素,非常适合需要可视化展示、交互性强的桌面工具。例如,在AI图像识别项目中,可以通过PyQt展示图像检测结果、绘制边框、显示识别信息等。
PyQt的信号与槽机制为事件驱动编程提供了清晰的模型,使得用户操作与界面响应之间可以灵活映射。
2.3 YOLO目标检测算法简介
YOLO(You Only Look Once)是一种基于深度学习的实时目标检测算法。相比传统的目标检测方法,YOLO将图像一次性输入神经网络,直接预测目标位置和类别,因而具有高精度和高速度的优点,广泛用于安防监控、自动驾驶、智能识别等领域。
YOLO算法的主要特点包括:
-
实时性强:YOLO能在毫秒级完成图像处理,适合实时系统。
-
端到端模型:不需要复杂的后处理,直接输出检测框与类别。
-
多目标识别能力强:在一张图片中可同时识别多个目标。
-
广泛的版本支持:包括YOLOv3、YOLOv5、YOLOv8等,性能持续优化。
在Python中,YOLO通常结合PyTorch、OpenCV等工具进行部署,并可与PyQt集成,实现图形界面中的目标检测可视化。
2.4 数据管理与持久化
在PyQt+YOLO系统中,数据持久化通常使用SQLite、MySQL或Pandas进行数据记录与管理。相比Web系统依赖复杂的数据库结构,桌面系统通常以轻量级、嵌入式数据库(如SQLite)为主。
Python中可以通过sqlite3模块或SQLAlchemy框架实现数据的增删改查,同时也可利用CSV、JSON等格式持久化检测结果,便于后期分析与调试。
2.5 本项目数据集详细数据(类别数与类别名称)
本项目采用的目标检测数据集共包含 16 个类别(nc=16),类别命名为数字字符串,表示编号类别,具体如下所示:
-
类别总数(
nc):16 -
类别名称(
names):[‘1’, ‘10’, ‘11’, ‘12’, ‘13’, ‘14’, ‘15’, ‘16’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’]
为了实现模型对各类别目标的精确识别,项目在标注阶段已按照上述类别进行标识。该命名方式虽为字符串数字,但不表示类别顺序,建议在后期处理时根据实际需求进行排序或映射处理(如按数值升序为 1~16)。
这种以编号命名类别的方法适用于对图像中目标进行匿名分类,特别是在工业检测、零部件识别、或数据脱敏场景中较为常见。若项目后续需要对类别赋予实际语义,也可以通过映射表进行转换。

Epoch gpu_mem box obj cls labels img_size
1/200 0G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843Epoch gpu_mem box obj cls labels img_size
2/200 0G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845Epoch gpu_mem box obj cls labels img_size
3/200 0G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845



-
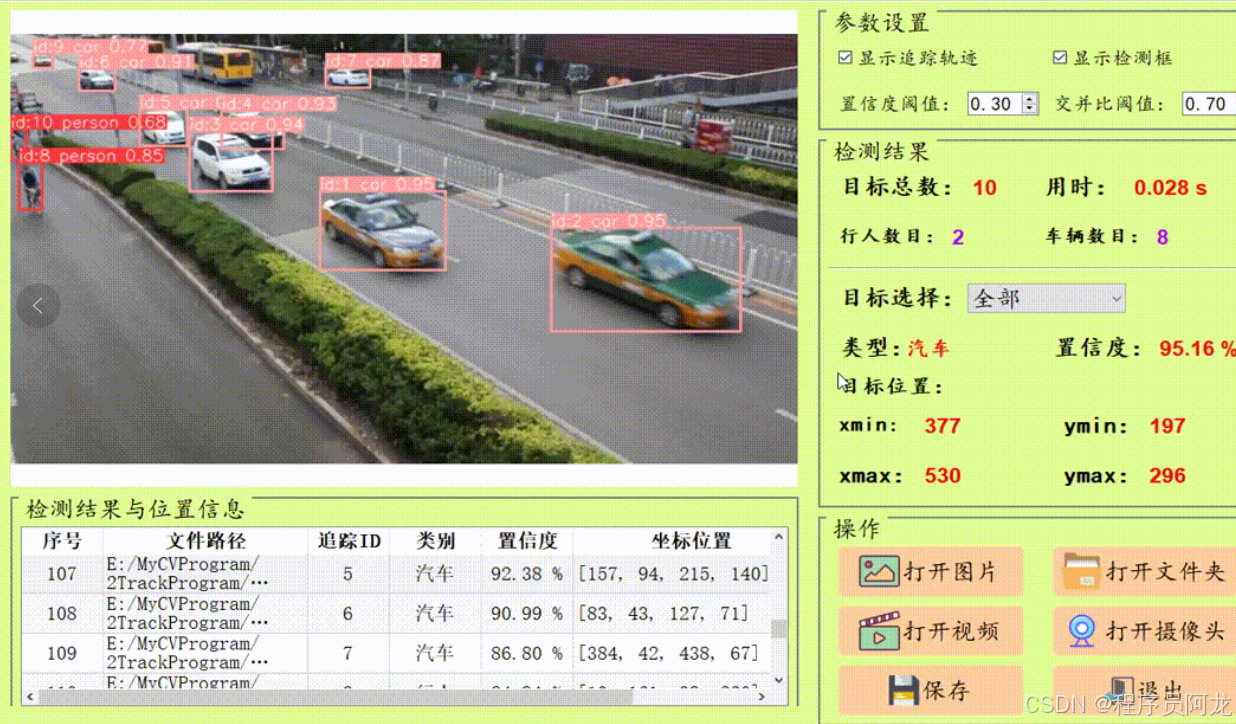
显示追踪轨迹:用于设置检测的视频中是否显示目标追踪轨迹,默认勾选:表示显示追踪轨迹,不勾选则不显示追踪轨迹; -
显示检测框:用于设置检测的视频中是否显示目标检测框与标签,默认勾选:表示显示检测框与标签,不勾选则不显示检测框与标签; -
置信度阈值:也就是目标检测时的conf参数,只有检测出的目标置信度大于该值,结果才会显示; -
交并比阈值:也就是目标检测时的iou参数,只有目标检测框的交并比大于该值,结果才会显示;IoU:全称为Intersection over Union,表示交并比。在目标检测中,它用于衡量模型生成的候选框与原标记框之间的重叠程度。IoU值越大,表示两个框之间的相似性越高。通常,当IoU值大于0.5时,认为可以检测到目标物体。这个指标常用于评估模型在特定数据集上的检测准确度。
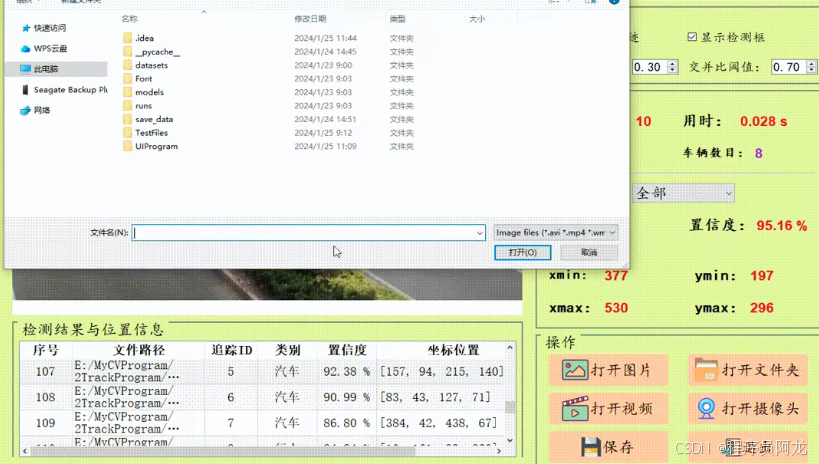
(1)图片检测演示
点击打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹,操作演示如下:
点击目标下拉框后,可以选定指定目标的结果信息进行显示。 点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
点击表格中的指定行,界面会显示该行表格所写的信息内容。
注:1.右侧目标位置默认显示置信度最大一个目标位置。所有检测结果均在左下方表格中显示。

文件功能整理表
| 文件路径 | 功能描述 |
|---|---|
ultralytics/utils/plotting.py |
提供可视化工具,支持绘制图像、标签、边界框、混淆矩阵等,用于模型结果的直观展示。 |
ui.py |
启动 Streamlit Web 应用,提供用户界面,便于用户交互与可视化检测或分类结果。 |
train.py |
用于训练 YOLO 模型的主脚本,包含数据集加载、模型配置、训练过程控制等核心功能。 |
ultralytics/models/yolo/classify/val.py |
分类模型的验证脚本,用于评估模型的分类性能并生成相关指标。 |
ultralytics/utils/callbacks/__init__.py |
初始化回调模块,用于注册和管理训练过程中的各类回调函数。 |
ultralytics/__init__.py |
YOLO库的初始化入口,定义版本号并导入主要模块,构建统一接口。 |
ultralytics/utils/callbacks/mlflow.py |
集成 MLflow,记录训练过程中的超参数、指标和模型信息,支持可追踪实验。 |
ultralytics/utils/callbacks/tensorboard.py |
集成 TensorBoard,对训练过程进行实时可视化,如损失曲线、学习率等。 |
ultralytics/models/rtdetr/model.py |
实现 RT-DETR(实时检测变换器)模型的结构定义和推理逻辑。 |
ultralytics/models/utils/loss.py |
定义YOLO相关的损失函数模块,负责训练时的误差计算与反向传播支持。 |
ultralytics/utils/ops.py |
封装基础操作函数,包括图像处理、坐标变换、非极大值抑制(NMS)等。 |
log.py |
提供日志记录与输出功能,追踪训练过程、错误信息及调试输出。 |
ultralytics/utils/checks.py |
包含模型和数据的验证工具,用于训练前的完整性与兼容性检查。 |
二、目标检测模型的训练、评估与推理
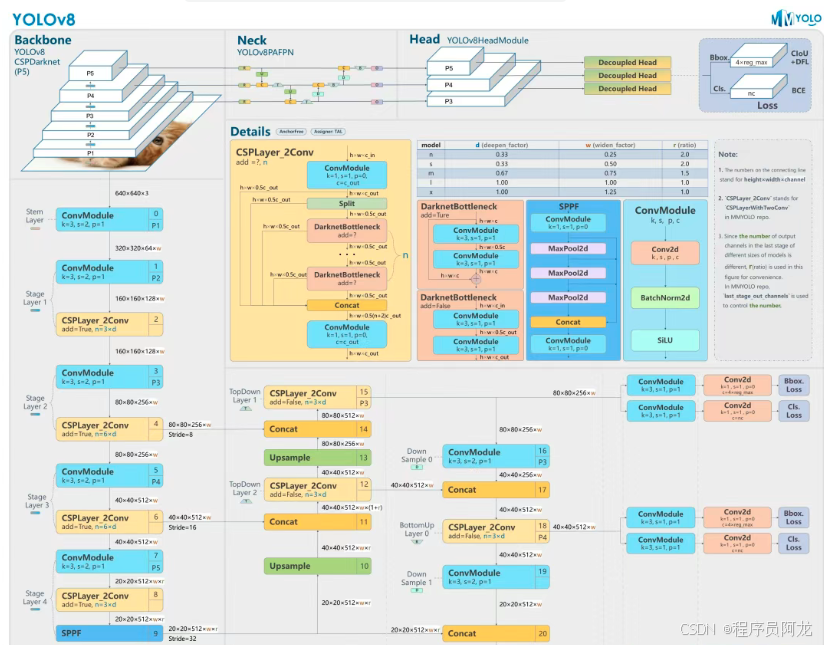
YOLOv8是一种前沿的目标检测技术,它基于先前YOLO版本在目标检测任务上的成功,进一步提升了性能和灵活性。主要的创新点包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。其主要网络结构如下:
2. 数据集准备与训练
通过网络上搜集关于车辆行人的各类图片,并使用LabelMe标注工具对每张图片中的目标边框(Bounding Box)及类别进行标注。一共包含5607张图片,其中训练集包含4485张图片,验证集包含1122张图片,部分图像及标注如下图所示。


train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
# 加载模型
model = YOLO("yolov8n.pt") # 加载预训练模型
# Use the model
if __name__ == '__main__':
# Use the model
results = model.train(data='datasets/CarPersonData/data.yaml', epochs=250, batch=4) # 训练模型
# 将模型转为onnx格式
# success = model.export(format='onnx')图片、视频、摄像头图像分割 Demo(去除 WebUI)
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from model import Web_Detector
from chinese_name_list import Label_list
# 根据类别名称生成固定颜色
def generate_color_based_on_name(name):
np.random.seed(sum([ord(c) for c in name]))
return tuple(int(x) for x in np.random.randint(0, 255, size=3))
# 计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
# 计算圆度 Circularity = 4πA / P²
def calculate_circularity(area, perimeter):
if perimeter == 0:
return 0
return 4 * np.pi * area / (perimeter ** 2)
# 中文绘制函数
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype("simsun.ttc", font_size, encoding="unic")
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
# 根据图像大小自适应绘图参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
# 绘制检测结果(支持矩形或掩膜)
def draw_detections(image, info, alpha=0.3):
name, bbox, conf, cls_id, mask = info['class_name'], info['bbox'], info['score'], info['class_id'], info['mask']
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(25 * adjust_param)
if mask is None:
x1, y1, x2, y2 = bbox
area = (x2 - x1) * (y2 - y1)
cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))
image = draw_with_chinese(image, name, (x1, y1 - spacing), font_size=int(35 * adjust_param))
else:
mask_points = np.concatenate(mask)
area = calculate_polygon_area(mask_points)
perimeter = cv2.arcLength(mask_points.astype(np.int32), True)
circularity = calculate_circularity(area, perimeter)
mask_color = generate_color_based_on_name(name)
overlay = image.copy()
cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)
image = cv2.addWeighted(overlay, alpha, image, 1 - alpha, 0)
cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(6 * adjust_param))
# 颜色提取
mask_layer = np.zeros(image.shape[:2], dtype=np.uint8)
cv2.drawContours(mask_layer, [mask_points.astype(np.int32)], -1, 255, -1)
mean_color = cv2.mean(image, mask=mask_layer)[:3]
color_str = f"RGB({int(mean_color[0])},{int(mean_color[1])},{int(mean_color[2])})"
# 文本位置
x, y = np.min(mask_points, axis=0).astype(int)
image = draw_with_chinese(image, name, (x, y - spacing), font_size=int(35 * adjust_param))
# 绘制指标信息
metrics = [
("Area", f"{int(area)} px²"),
("Perimeter", f"{int(perimeter)} px"),
("Circularity", f"{circularity:.2f}"),
("Color", color_str)
]
for idx, (k, v) in enumerate(metrics):
text = f"{k}: {v}"
image = draw_with_chinese(image, text, (x, y + idx * spacing), font_si_*

模型训练结果:
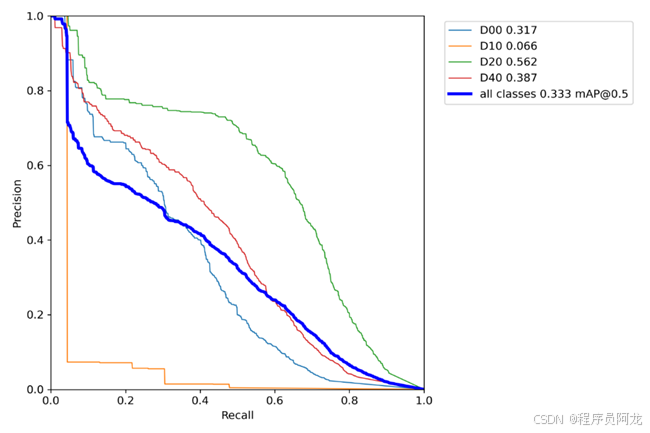
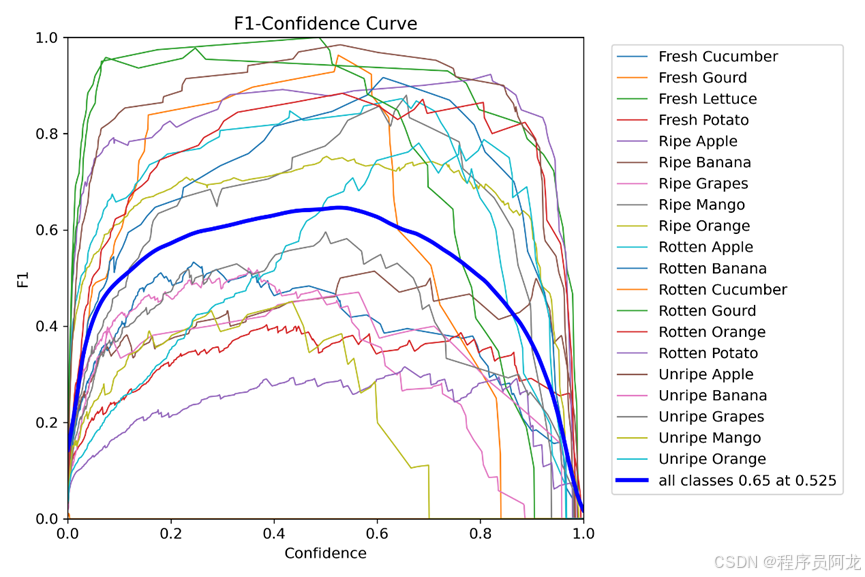
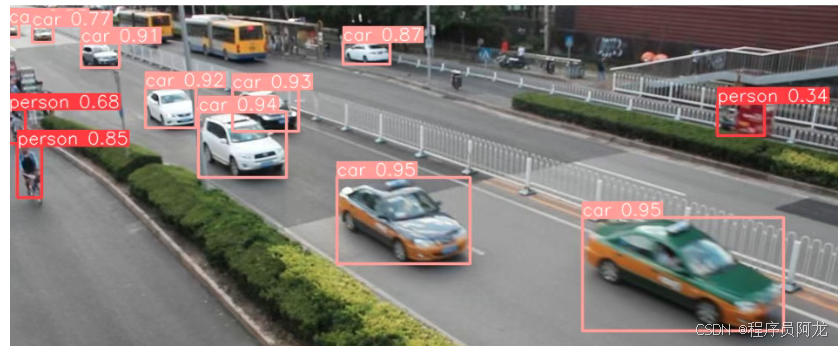 三、使用ByteTrack进行目标追踪:
三、使用ByteTrack进行目标追踪:
ByteTrack算法是一种十分强大且高效的追踪算法,和其他非ReID的算法一样,仅仅使用目标追踪所得到的bbox进行追踪。追踪算法使用了卡尔曼滤波预测边界框,然后使用匈牙利算法进行目标和轨迹间的匹配。ByteTrack算法的最大创新点就是对低分框的使用,作者认为低分框可能是对物体遮挡时产生的框,直接对低分框抛弃会影响性能,所以作者使用低分框对追踪算法进行了二次匹配,有效优化了追踪过程中因为遮挡造成换id的问题。
-
没有使用ReID特征计算外观相似度
-
非深度方法,不需要训练
-
利用高分框和低分框之间的区别和匹配,有效解决遮挡问题
ByteTrack与其他追踪算法的对比如下图所示,可以看到ByteTrack的性能还是相当不错的。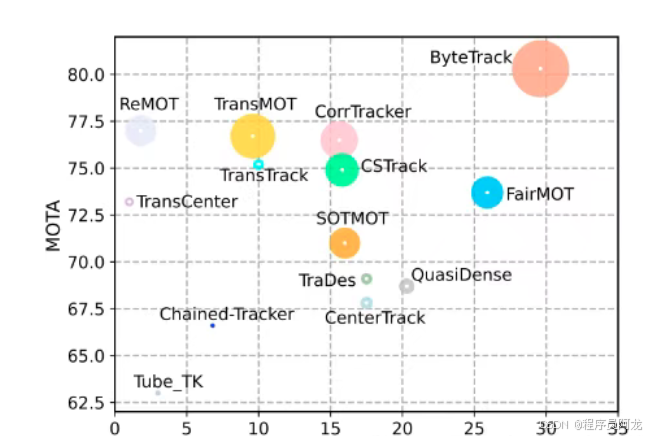
ByteTrack的实现代码如下:
class ByteTrack:
"""
Initialize the ByteTrack object.
Parameters:
track_thresh (float, optional): Detection confidence threshold
for track activation.
track_buffer (int, optional): Number of frames to buffer when a track is lost.
match_thresh (float, optional): Threshold for matching tracks with detections.
frame_rate (int, optional): The frame rate of the video.
"""
def __init__(
self,
track_thresh: float = 0.25,
track_buffer: int = 30,
match_thresh: float = 0.8,
frame_rate: int = 30,
):
self.track_thresh = track_thresh
self.match_thresh = match_thresh
self.frame_id = 0
self.det_thresh = self.track_thresh + 0.1
self.max_time_lost = int(frame_rate / 30.0 * track_buffer)
self.kalman_filter = KalmanFilter()
self.tracked_tracks: List[STrack] = []
self.lost_tracks: List[STrack] = []
self.removed_tracks: List[STrack] = []
def update_with_detections(self, detections: Detections) -> Detections:
"""
Updates the tracker with the provided detections and
returns the updated detection results.
Parameters:
detections: The new detections to update with.
Returns:
Detection: The updated detection results that now include tracking IDs.
"""
tracks = self.update_with_tensors(
tensors=detections2boxes(detections=detections)
)
detections = Detections.empty()
if len(tracks) > 0:
detections.xyxy = np.array(
[track.tlbr for track in tracks], dtype=np.float32
)
detections.class_id = np.array(
[int(t.class_ids) for t in tracks], dtype=int
)
detections.tracker_id = np.array(
[int(t.track_id) for t in tracks], dtype=int
)
detections.confidence = np.array(
[t.score for t in tracks], dtype=np.float32
)
else:
detections.tracker_id = np.array([], dtype=int)
return detections
def update_with_tensors(self, tensors: np.ndarray) -> List[STrack]:
"""
Updates the tracker with the provided tensors and returns the updated tracks.
Parameters:
tensors: The new tensors to update with.
Returns:
List[STrack]: Updated tracks.
"""
self.frame_id += 1
activated_starcks = []
refind_stracks = []
lost_stracks = []
removed_stracks = []
class_ids = tensors[:, 5]
scores = tensors[:, 4]
bboxes = tensors[:, :4]
remain_inds = scores > self.track_thresh
inds_low = scores > 0.1
inds_high = scores < self.track_thresh
inds_second = np.logical_and(inds_low, inds_high)
dets_second = bboxes[inds_second]
dets = bboxes[remain_inds]
scores_keep = scores[remain_inds]
scores_second = scores[inds_second]
class_ids_keep = class_ids[remain_inds]
class_ids_second = class_ids[inds_second]
if len(dets) > 0:
"""Detections"""
detections = [
STrack(STrack.tlbr_to_tlwh(tlbr), s, c)
for (tlbr, s, c) in zip(dets, scores_keep, class_ids_keep)
]
else:
detections = []
""" Add newly detected tracklets to tracked_stracks"""
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_tracks:
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
""" Step 2: First association, with high score detection boxes"""
strack_pool = joint_tracks(tracked_stracks, self.lost_tracks)
# Predict the current location with KF
STrack.multi_predict(strack_pool)
dists = matching.iou_distance(strack_pool, detections)
dists = matching.fuse_score(dists, detections)
matches, u_track, u_detection = matching.linear_assignment(
dists, thresh=self.match_thresh
)
for itracked, idet in matches:
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
track.update(detections[idet], self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
""" Step 3: Second association, with low score detection boxes"""
# association the untrack to the low score detections
if len(dets_second) > 0:
"""Detections"""
detections_second = [
STrack(STrack.tlbr_to_tlwh(tlbr), s, c)
for (tlbr, s, c) in zip(dets_second, scores_second, class_ids_second)
]
else:
detections_second = []
r_tracked_stracks = [
strack_pool[i]
for i in u_track
if strack_pool[i].state == TrackState.Tracked
]
dists = matching.iou_distance(r_tracked_stracks, detections_second)
matches, u_track, u_detection_second = matching.linear_assignment(
dists, thresh=0.5
)
for itracked, idet in matches:
track = r_tracked_stracks[itracked]
det = detections_second[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
for it in u_track:
track = r_tracked_stracks[it]
if not track.state == TrackState.Lost:
track.mark_lost()
lost_stracks.append(track)
"""Deal with unconfirmed tracks, usually tracks with only one beginning frame"""
detections = [detections[i] for i in u_detection]
dists = matching.iou_distance(unconfirmed, detections)
dists = matching.fuse_score(dists, detections)
matches, u_unconfirmed, u_detection = matching.linear_assignment(
dists, thresh=0.7
)
for itracked, idet in matches:
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_starcks.append(unconfirmed[itracked])
for it in u_unconfirmed:
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)
""" Step 4: Init new stracks"""
for inew in u_detection:
track = detections[inew]
if track.score < self.det_thresh:
continue
track.activate(self.kalman_filter, self.frame_id)
activated_starcks.append(track)
""" Step 5: Update state"""
for track in self.lost_tracks:
if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)
self.tracked_tracks = [
t for t in self.tracked_tracks if t.state == TrackState.Tracked
]
self.tracked_tracks = joint_tracks(self.tracked_tracks, activated_starcks)
self.tracked_tracks = joint_tracks(self.tracked_tracks, refind_stracks)
self.lost_tracks = sub_tracks(self.lost_tracks, self.tracked_tracks)
self.lost_tracks.extend(lost_stracks)
self.lost_tracks = sub_tracks(self.lost_tracks, self.removed_tracks)
self.removed_tracks.extend(removed_stracks)
self.tracked_tracks, self.lost_tracks = remove_duplicate_tracks(
self.tracked_tracks, self.lost_tracks
)
output_stracks = [track for track in self.tracked_tracks if track.is_activated]
return output_stracks用户资料:

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 24
24 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)