智算中心 Kubernetes 架构设计从“堆 GPU”到“算力即服务”的工程路径—— 奇点算力云的落地实践
——以奇点算力云为落地样本
过去几年,国内智算中心建设持续升温。DeepSeek 的出圈,使得 2025 年算力投资热度进一步抬升,进入 2026 年,这一趋势仍将延续。
但在大量项目落地后,一个共性问题逐渐显现:
GPU 买了、模型有了,算力却没有真正“跑起来”。
根本原因并不复杂——
硬件不等于算力能力,堆卡不等于算力体系。
一个可持续运营的智算中心,关键不在于 GPU 数量,而在于:
是否能把离散硬件组织成“可调度、可运营、可服务”的算力平台。
而在当前技术体系下,几乎所有成熟智算中心方案的底座,最终都会指向同一个答案:Kubernetes。
在此基础上,奇点算力云完成了从基础架构到商业交付的完整闭环,实现了真正意义上的 “算力即服务(Computing as a Service)”。

一、智算中心到底在“算”什么?
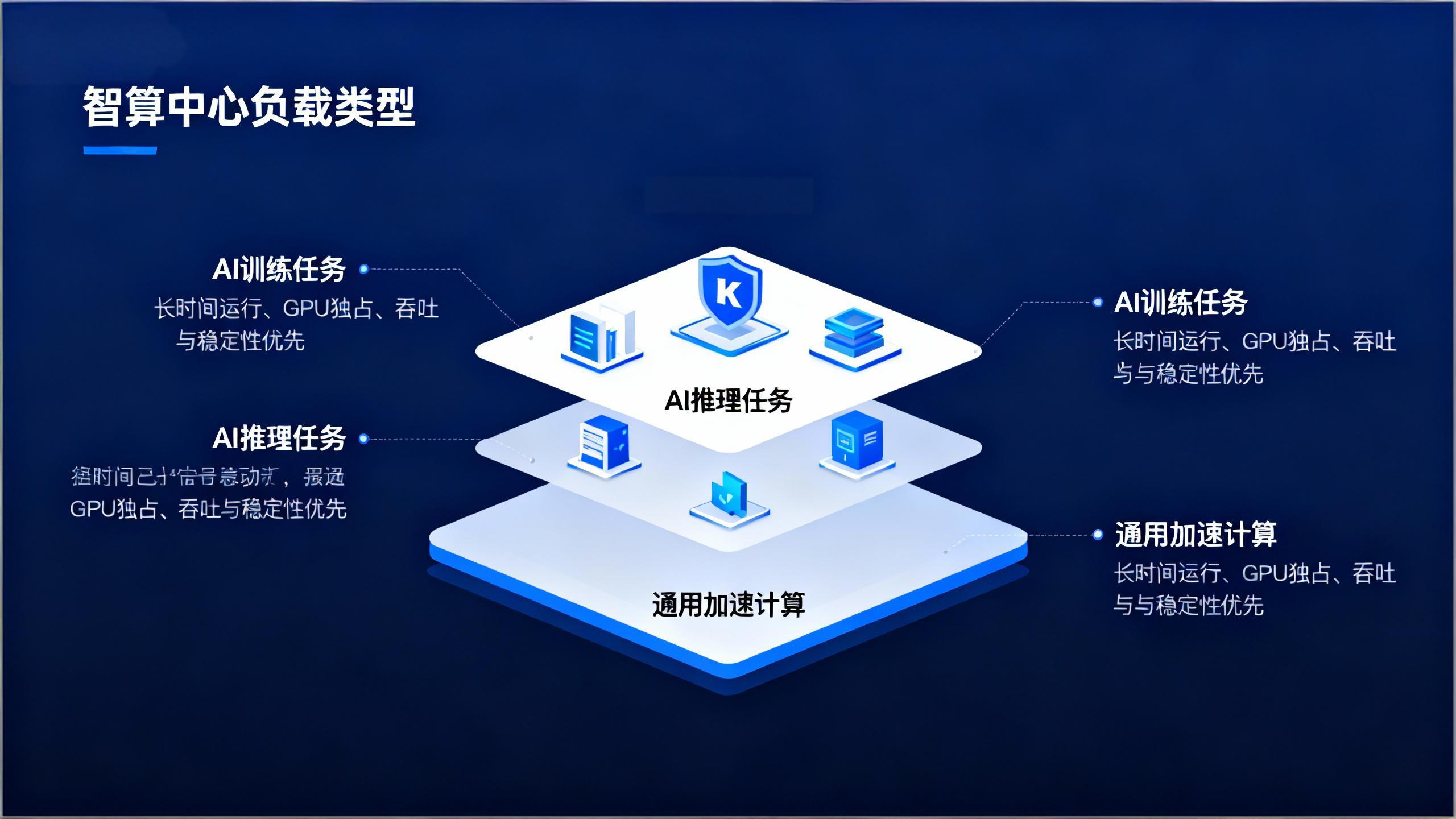
从调度角度看,智算中心的算力主要承载三类负载:
-
AI 训练任务
-
长时间运行
-
GPU 独占
-
吞吐与稳定性优先
-
-
AI 推理任务
-
高并发、低延迟
-
GPU 共享
-
强弹性伸缩需求
-
-
通用加速计算
-
CPU/GPU 混合
-
负载类型多样
-
资源碎片化明显
-
三类负载的资源使用模式几乎完全不同,这也决定了:
智算中心的 Kubernetes 架构必须是“分层 + 分池 + 分策略”的设计。
二、智算中心 Kubernetes 总体架构(落地实践视角)
在工程实践中,一个可运营的智算中心 Kubernetes 架构,通常可拆解为五层:
┌────────────────────────────┐
算力服务层(对外交付)
├────────────────────────────┤
平台能力层(调度 / 运营)
├────────────────────────────┤
Kubernetes 基础层
├────────────────────────────┤
节点与加速层(GPU / 网络)
├────────────────────────────┤
物理基础设施层(IDC)
└────────────────────────────┘
奇点算力云的算力平台,正是严格遵循这一结构搭建,并在每一层做了针对“商业化运营”的增强。
三、物理基础设施层:算力体系的“工程地基”
这一层决定的是 算力的上限与稳定性。
在奇点算力云的实践中,物理层采用标准化智算中心配置,并与头部 IDC 长期合作,核心要素包括:
-
GPU 服务器:主流 NVIDIA 架构,确保生态与软件兼容性
-
高速互联:RoCE / IB 网络,保障多卡与跨节点通信效率
-
存储体系:并行文件系统 + 对象存储,支撑训练数据与模型管理
-
基础保障:双路供电、液冷机柜,适配高功耗 GPU 的长期稳定运行
这一层的选型,将直接影响后续 Kubernetes 调度策略是否可行。
四、节点与加速层:让 Kubernetes“理解算力”
这是很多智算中心容易低估、但极其关键的一层。
核心目标只有一个:
让每一台 GPU 服务器,都能被 Kubernetes 精确识别、稳定调度。
工程实现通常包括:
-
GPU 能力标准化
-
NVIDIA Driver / CUDA / Container Toolkit
-
Device Plugin 统一注册 GPU 资源
-
-
网络能力释放
-
SR-IOV / RDMA
-
高性能 CNI,降低跨 Pod 通信延迟
-
-
存储能力对接
-
CSI 驱动
-
本地 NVMe + 分布式存储组合
-
在奇点算力云的实践中,还额外引入了针对 GPU 散热与功耗的工程级优化,使得 有效算力利用率显著高于行业平均水平,这是其算力收益稳定的重要基础。
五、Kubernetes 基础层:算力调度的“中枢系统”
Kubernetes 本身并不“懂 AI”,但它非常擅长一件事:
在有限资源下做可控的分配与博弈。
这一层的关键能力包括:
-
标准化控制面
-
kube-apiserver / scheduler / etcd
-
保证平台稳定性与扩展性
-
-
GPU 资源抽象
-
nvidia.com/gpu资源模型 -
支持 MIG、GPU 共享等能力
-
-
调度策略增强
-
节点标签区分训练 / 推理节点
-
Pod 亲和 / 反亲和
-
不同任务优先级调度
-
通过这些机制,算力开始从“硬件”转变为 可管理的资源对象。
六、平台能力层:从“能调度”到“能运营”
如果说前几层解决的是“算力能不能用”,
这一层解决的,是“算力能不能赚钱”。
在奇点算力云的平台能力层,核心包括:
-
统一调度策略体系
-
训练任务:GPU 独占、长周期保障
-
推理任务:GPU 共享、弹性副本
-
配额与限额:防止资源被单一用户挤占
-
-
资源池化设计
-
训练池 / 推理池
-
高端卡池 / 通用卡池
-
不同价格体系对应不同资源池
-
-
多租户与运营能力
-
Namespace + ResourceQuota 隔离
-
GPU 利用率、作业状态实时监控
-
精细化成本与收益核算
-
到这一层,GPU 才真正转化为 “可定价、可结算的算力产品”。
七、算力服务层:用户真正看到的“算力形态”
这是智算中心最终对外交付的界面,常见形态包括:
-
AI 训练服务
-
Notebook / Job
-
模型与数据管理
-
-
推理服务平台
-
模型即服务(MaaS)
-
API 方式调用算力
-
-
行业定制算力服务
-
视频分析
-
语音识别
-
行业模型托管
-
对奇点算力云的合作方而言,并不需要理解 Kubernetes 的复杂性——
算力已经被平台“产品化”,只需参与资源供给,即可参与收益分配。
八、为什么 Kubernetes + 平台化是最优解?
从工程视角看,Kubernetes 天生适配智算中心场景:
-
资源抽象能力成熟
-
调度机制可扩展
-
生态完整、国产化可控
而真正的差异,不在于“是否用了 Kubernetes”,
而在于:是否能在其之上构建完整的算力运营体系。
奇点算力云的价值,正是在于把这套技术架构,转化为 可规模复制的商业模型。
九、结语:智算中心是长期工程
智算中心的难点,从来不在“买设备”,而在于:
-
算力如何分
-
资源如何用
-
成本如何控
-
服务如何卖
Kubernetes 是底座,而平台能力决定成败。
在智算产业从“建设期”走向“运营期”的阶段,
真正稀缺的,已不再是 GPU,而是 能把算力持续变现的体系能力。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)