告别野路子!LLM时代百万级文献语料库的架构演进与合规获取深度指南
文章目录
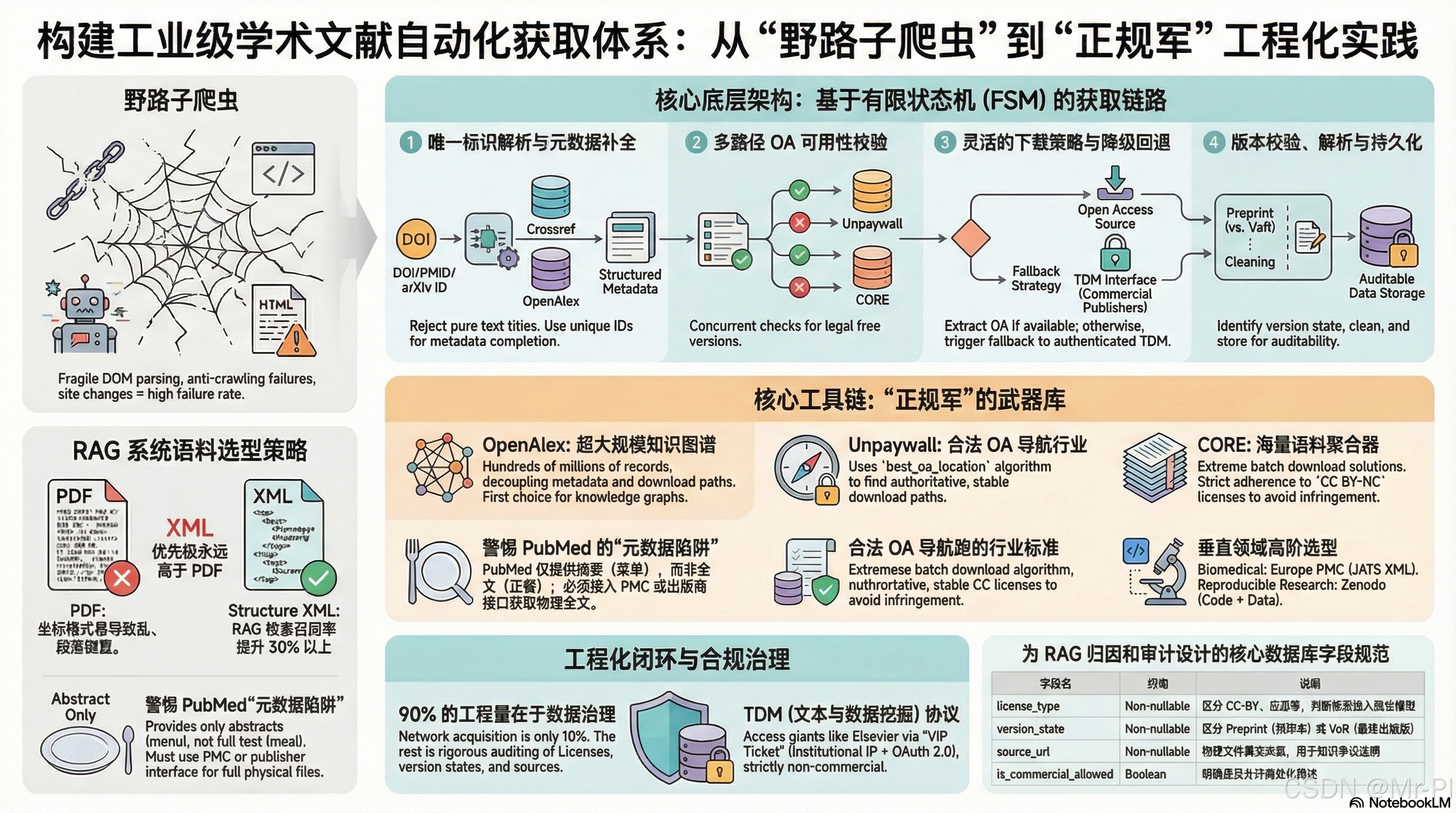
0. 引言:告别“低级爬虫”,拥抱合规自动化的“正规军”
为了给公司的 RAG(检索增强生成)系统或者垂直大模型投喂最新的学术文献,你手搓了一个基于 requests 和 BeautifulSoup 的“万能爬虫”。一开始跑得很欢,但不到三小时,IP被封禁、CSS选择器因目标网站改版而大面积失效、下回来的PDF充斥着反爬乱码……这种“黑客行为”式的野路子方案,不仅效率低下,且在法律合规性与工程稳定性上危机四伏。
架构师箴言:在数据工程的鄙视链里,依赖DOM树解析的网页爬虫处于最底端。我们要做的不应是在反爬策略的边缘试探,而是建立一套合法、稳定、高并发且可伸缩的“自动化获取方案”。
这不仅是工具的更迭,更是从“临时抓取(Scraping)”向“工程化数据治理(Data Governance)”的思维降维打击。今天,我们将深度拆解如何利用标准 API 链路与状态机架构,构建一个工业级的学术文献语料库。
1. 核心底层逻辑:基于“有限状态机 (FSM)”的 DOI 映射链路
在很多新手的认知里,文献下载是一个“输入标题 -> 吐出PDF”的黑盒。但在工业界,绝对不应存在这样一个全能的黑盒。
一个健壮的、高可用的文献获取系统,在架构上必须被设计为一个有限状态机(Finite-State Machine, FSM)。每一个节点代表一个逻辑阶段,带有明确的成功态与失败态。若当前分支失败(例如在 Unpaywall 未发现 OA 版本),系统不应崩溃,而是自动触发降级与回退策略(Fallback),流转至下一个策略(如调用出版商 TDM 接口)。
1.1 状态转移的数学期望
假设我们有三个获取链路:免费开放获取 ( A A A)、机构订阅TDM ( B B B)、以及聚合器备份 ( C C C)。每一次获取可以视为一个独立伯努利试验,其整体成功率公式可表示为:
P s u c c e s s = 1 − ∏ i ∈ { A , B , C } ( 1 − P i ) P_{success} = 1 - \prod_{i \in \{A, B, C\}} (1 - P_i) Psuccess=1−i∈{A,B,C}∏(1−Pi)
相比于单点依赖的爬虫(一旦失败 P = 0 P=0 P=0),状态机架构通过正交的API策略,将系统的整体可用性(Availability)提升到了 99.9 % 99.9\% 99.9% 以上。
1.2 核心状态机架构图
下面是我们为大模型语料管线设计的标准工程获取链路:
2. 惊人的覆盖率:构建合规体系的“三驾马车”
在“正规军”的武器库中,有三个堪称核武器级别的基础设施。它们构成了文献获取体系的核心。
2.1 OpenAlex:降维打击的超大规模图谱
别再盯着 Google Scholar 的反爬验证码了!OpenAlex 是当前构建大规模知识图谱的首选。它不仅仅是元数据索引,更是一个将 Works(论文)、Authors(作者)、Concepts(概念)高度互联的图数据库。
它声称已索引了数亿条文献记录,并缓存了数千万篇 OA PDF。其最大优势在于:将元数据(Metadata)与物理下载路径高度解耦又互通。
2.2 Unpaywall:寻找合法 OA 的“北斗导航”
作为 DOI 到合法 OA 链接转换的行业标准,Unpaywall 维护着一个庞大的数据库,记录了哪篇论文在哪个机构知识库或预印本平台上存在免费、合法的 PDF。
它的核心字段 best_oa_location 能够用算法帮你从复杂的仓储镜像中筛选出最权威、最稳定的下载路径。
2.3 CORE:海量语料的聚合器
如果你需要进行从零开始的语料预训练(Pre-training),CORE 提供了极佳的批量下载方案。但作为架构师,这里有一个天坑必须注意:
由于 CORE 采集源极广,**“许可(License)与去重治理”**是接入时的核心工作。如果你把禁止商用的 CC BY-NC 协议的文献扔进了商业大模型的训练集,法务部门明天就会找你喝茶。
2.4 【实战代码】异步并发整合 Unpaywall 与 OpenAlex
下面的 Python 代码展示了如何使用 asyncio 和 aiohttp 高效、合规地穿透这两大 API:
import asyncio
import aiohttp
import json
class AcademicCorpusBuilder:
def __init__(self, email):
# 合规第一步:必须在 User-Agent 或参数中留下邮箱,这是“正规军”的礼仪
self.email = email
self.unpaywall_api = "https://api.unpaywall.org/v2/{doi}?email={email}"
self.openalex_api = "https://api.openalex.org/works/https://doi.org/{doi}?mailto={email}"
async def fetch_json(self, session, url):
try:
async with session.get(url, timeout=10) as response:
if response.status == 200:
return await response.json()
return None
except Exception as e:
print(f"Network error: {e}")
return None
async def get_best_pdf_link(self, doi):
async with aiohttp.ClientSession() as session:
# 并发请求两大 API 寻找最优路径
task_unpaywall = self.fetch_json(
session, self.unpaywall_api.format(doi=doi, email=self.email)
)
task_openalex = self.fetch_json(
session, self.openalex_api.format(doi=doi, email=self.email)
)
res_unpaywall, res_openalex = await asyncio.gather(task_unpaywall, task_openalex)
download_url = None
source_type = None
# 策略 1: 优先相信 Unpaywall 的 best_oa_location
if res_unpaywall and res_unpaywall.get('is_oa'):
best_location = res_unpaywall.get('best_oa_location', {})
if best_location and best_location.get('url_for_pdf'):
download_url = best_location['url_for_pdf']
source_type = "Unpaywall"
# 策略 2: Fallback 到 OpenAlex 的 open_access 对象
if not download_url and res_openalex:
oa_info = res_openalex.get('open_access', {})
if oa_info.get('is_oa') and oa_info.get('oa_url'):
download_url = oa_info['oa_url']
source_type = "OpenAlex"
return {
"doi": doi,
"pdf_url": download_url,
"source": source_type
}
# 执行状态机节点
async def main():
builder = AcademicCorpusBuilder(email="your_name@your_company.com")
# 测试一个知名的深度学习论文 DOI (ResNet)
result = await builder.get_best_pdf_link("10.1109/CVPR.2016.90")
print(json.dumps(result, indent=2))
if __name__ == "__main__":
asyncio.run(main())
3. 避坑指南:分清“菜单”与“正餐”的陷阱
在带新人的过程中,我发现初级工程师最容易犯的错误,就是混淆了“发现(Discovery)”与“获取(Access)”。
打个比方,你去餐厅吃饭,服务员递给你一张菜单,上面写着详细的菜品名称、材料、价格(这就叫元数据 Metadata)。但你不能把菜单给吃了,你想要的是厨房做出来的那盘红烧肉(这就叫全文 Full-text)。
3.1 PubMed的千古误区
以生物医学大模型开发为例。很多人一上来就说:“我们接了 PubMed API,每天能抓几万篇论文!”
错! PubMed 几乎是元数据的代名词。它能告诉你这篇论文的标题、摘要、作者,但它本身不存储任何全文!
真正的物理全文通常托管在 PMC (PubMed Central) 或者原出版商的网站上。如果你的 RAG 系统只灌入了 PubMed 拿回来的数据,大模型看到的永远只是“摘要(Abstract)”,它在回答深度专业问题时必然产生严重幻觉。
架构师警示:不要尝试去爬取 PubMed 详情页上的那个“Full text links”图标指向的第三方网页。解析第三方 HTML 页面不仅会导致工程方案在网站改版时瞬间崩塌,更极易触发出版商的版权封锁机制,导致整个机构 IP 段被拉黑(Blacklisted)。
4. 跨领域选型:为 RAG 系统量身定制的高阶语料库策略
在为检索增强生成(RAG)和知识图谱配置语料库时,算法工程师需要建立一个全新的认知:PDF 是一种为了人类视觉排版而发明的极度落后的数据格式。
PDF 的本质是画布上的绝对坐标渲染。多栏排版、断字换行(Ligatures & Hyphenation)、复杂的图表嵌套,这些特性使得常规的 PDF 解析工具(如 PyMuPDF, pdfplumber)经常产生乱码、段落倒置、表格数据丢失。这也是 RAG 系统回答时“牛头不对马嘴”的主要罪魁祸首。
因此,在高质量的学术数据管道中,XML / HTML 的优先级永远高于 PDF。
RAG语料选型策略矩阵
方案 A:通用跨学科(低成本、高广度)
- 组件:Crossref (元数据) + Unpaywall (路由) + OpenAlex (聚合)
- Architect Pro-tip:利用 arXiv 获取 CS/Math 论文源文件时,请务必使用
export.arxiv.org子域名进行程序化访问(如 OAI-PMH 协议),而不要直接高频拉取arxiv.org。后者会立刻触发 Web 端流控机制封禁你。
方案 B:生命科学垂直领域(高精度、结构化)
- 组件:NCBI E-utilities + Europe PMC
- 核心优势:Europe PMC 对其 OA 子集提供了极度高质量的结构化 JATS XML。XML 中精确地用标签区分了
<abstract>,<body>,<sec>(章节), 甚至<fig>(图片) 和<table>(表格)。这种高信噪比的数据,能让 RAG 的 Chunking(文本分块)策略精准到“基于逻辑段落”,检索召回率提升至少 30%。
方案 C:可复现研究(数据集与代码融合)
- 组件:Zenodo REST API
- 价值:未来的大模型不仅要懂理论,还要会写代码复现。Zenodo 不仅存储论文,还关联了配套的 Jupyter Notebook、CSV 数据集和 Docker 环境镜像,是构建“可复现 Agent”的黄金宝库。
5. 巨头博弈:解锁出版商的“VIP 门票”(TDM 协议)
如果你的业务必须触碰非 OA(闭源付费)内容,那么与 Elsevier (爱思唯尔), Springer Nature, Wiley 或 IEEE 等出版巨头的对接是无法回避的深水区。
这套体系在业界被称为 TDM (Text and Data Mining) 协议。这是合规获取高质量闭源文献的“VIP 门票”。
TDM 接入三要素:
- 准入门槛(Auth):通常不再是简单的 API-Key,而是基于机构订阅(Institutional Subscription)IP 校验结合 OAuth 2.0 的双重认证。
- 严苛的系统约束(Rate Limits & Schema):这些 API 往往对 QPS 有严格限制(例如每秒 2 次请求)。强行突破限制不仅会导致连接重置,还可能引出法务函。此外,TDM 接口返回的往往是特定的纯文本或高度精简的 XML,专门为机器阅读优化去除了排版样式。
- 价值对价(Legal Bound):TDM 协议通常明确规定仅限非商业化科研挖掘或者明确了大模型训练许可,绝对禁止将获取的内容进行直接转售或公开建库提供原文下载。
6. 工程化闭环:从“数据获取”到“数据治理”
一个令人清醒的现实是:在一个优秀的学术语料库架构中,网络获取代码只占不到 10% 的工程量,剩下的 90% 都在于数据的维护、清洗与治理。
如何证明你提供给大模型的知识没有侵权?如何追踪大模型回答的一句话具体出自哪篇文献的哪个版本?这需要严谨的数据库表设计。
核心数据库 Schema 设计建议 (PostgreSQL / SQLAlchemy)
在持久化存储时,以下字段必须被设置为 Non-nullable (不可为空),这是学术数据审计与 RAG 归因(Attribution)的生命线:
license(许可证): 区分 CC-BY, CC-BY-NC, 甚至完全保留版权。这是能否送入商业大模型的唯一判断标准。source_url(来源追溯): 如果产生知识争议,必须能追溯源头。version(版本控制): 论文有多种状态。是 Preprint(预印本,未同行评审)、AAM(作者录用稿)还是 VoR(最终出版记录版)?它们的权威性完全不同。ingestion_timestamp(抓取时间戳): 用于管理数据的时效性与增量更新策略。
# 基于 SQLAlchemy 的核心元数据模型精简示例
from sqlalchemy import Column, String, DateTime, Enum, Boolean
from sqlalchemy.ext.declarative import declarative_base
import datetime
Base = declarative_base()
class AcademicCorpus(Base):
__tablename__ = 'academic_corpus_governance'
# 唯一标识
doi = Column(String(100), primary_key=True, comment="论文唯一DOI标识")
# 核心元数据
title = Column(String(500), nullable=False)
# 治理与合规字段 (必须 Non-nullable)
license_type = Column(String(50), nullable=False, comment="如 CC-BY 4.0, 闭源")
source_url = Column(String(1024), nullable=False, comment="物理文件真实获取URL")
version_state = Column(String(50), nullable=False, comment="Preprint / AAM / VoR")
is_commercial_allowed = Column(Boolean, nullable=False, default=False)
# 审计时间戳
ingestion_timestamp = Column(DateTime, default=datetime.datetime.utcnow, nullable=False)
7. 结语与前瞻:为 AI 构建可计算的真理
当 Crossref 的 XML 结构越来越丰富,当 OpenAlex 的图谱每天以百万级的速度自我演进,API 的迭代成为了常态。
此时,我们不妨做一个互动思考:
当未来学术知识库 100% 实现了 API 化,且知识以结构化、携带语义标签的 XML 实时流转时,未来的研究员是否还需要“阅读” PDF 这种落后于时代的媒介?
或许,作为新一代数据架构师和算法工程师,我们的根本任务早已经不是写一个脚本“帮人去找论文”,而是**“为 AI 提供可计算的、干净的、合规的真理”**。
在这个历史性的转变过程中,放弃野路子爬虫,拥抱合规、稳定的自动化数据工程体系,不仅是技术的升级,更是保护公司资产、确保 AI 系统输出质量的唯一红线。
💡 互动话题:你在构建 RAG 语料库时,踩过最大的“解析坑”是什么?欢迎在评论区留言讨论!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)