ragas官方文档中文版(二十三)
测试集生成
精选高质量测试数据集对于评估 AI 应用程序的性能至关重要。 理想测试数据集的特征
- 包含高质量数据样本
- 涵盖现实世界中观察到的各种场景
- 包含足够数量的样本以得出具有统计意义的结论
- 持续更新以防止数据漂移
手动整理这样的数据集既耗时又昂贵。Ragas 提供了一组工具来生成合成测试数据集,用于评估您的 AI 应用程序。包括:
- 用于评估检索增强生成管道的 RAG
- 用于评估智能体工作流的智能体或工具使用
RAG 的测试集生成
在 RAG 应用中,当用户通过您的应用与一组文档进行交互时,系统可能会遇到不同模式的查询。让我们首先了解 RAG 应用中可能遇到的不同类型的查询。
RAG 中的查询类型
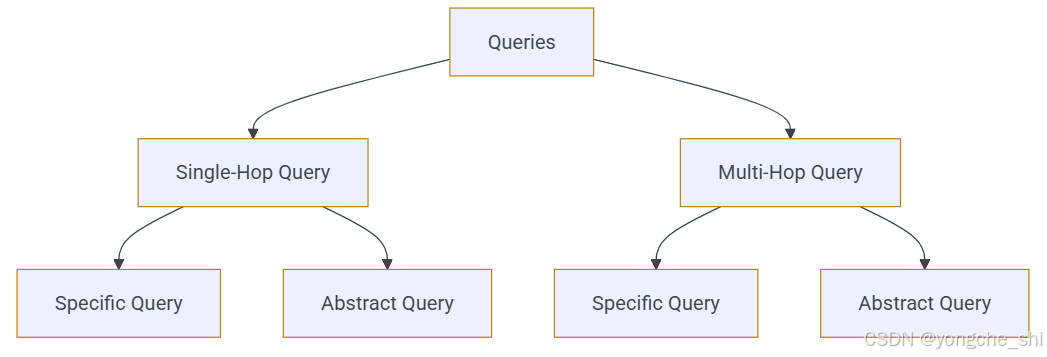
单跳查询
单跳查询是一个直接的问题,需要从单个文档或来源检索信息以提供相关答案。它只涉及一个步骤即可得出答案。
示例(具体查询):
- “阿尔伯特·爱因斯坦在哪一年发表了相对论?”
这是一个具体的、基于事实的问题,可以通过从包含该信息的文档中进行单次检索来回答。
示例(抽象查询):
- “爱因斯坦的理论如何改变了我们对时间和空间的理解?”
虽然此查询仍涉及单个概念(相对论),但它需要从源材料中进行更抽象或解释性的说明。
多跳查询
多跳查询涉及多个推理步骤,需要来自两个或多个来源的信息。系统必须从各种文档中检索信息并将这些点连接起来以生成准确的答案。
示例(具体查询):
- “哪位科学家影响了爱因斯坦的相对论研究,他们提出了什么理论?”
这需要系统检索关于影响爱因斯坦的科学家和具体理论的信息,可能来自两个不同的来源。
-
示例(抽象查询):
-
“自爱因斯坦最初发表以来,关于相对论的科学理论如何演变?”
此抽象查询需要检索跨时间和不同来源的多条信息,以形成关于理论演变的广泛、解释性的响应。
RAG 中的具体查询与抽象查询
-
具体查询 :专注于清晰的、基于事实的检索。在 RAG 中,目标是从一个或多个文档中检索高度相关的信息,直接解决具体问题。
-
抽象查询 :需要更广泛、更具解释性的响应。在 RAG 中,抽象查询对检索系统提出挑战,要求从包含更高层次推理、解释或观点的文档中提取信息,而不仅仅是简单的事实。
在单跳和多跳情况下,具体查询和抽象查询之间的区别通过确定重点是精确性(具体)还是综合更广泛的观点(抽象)来塑造检索和生成过程。
不同类型的查询需要综合不同的上下文。为解决此问题,Ragas 使用基于知识图谱的方法进行测试集生成。
知识图谱创建
鉴于我们希望从给定的文档集中生成不同类型的查询,我们的主要挑战是识别正确的分块或文档集,以使 LLM 能够创建查询。为解决此问题,Ragas 使用基于知识图谱的方法进行测试集生成。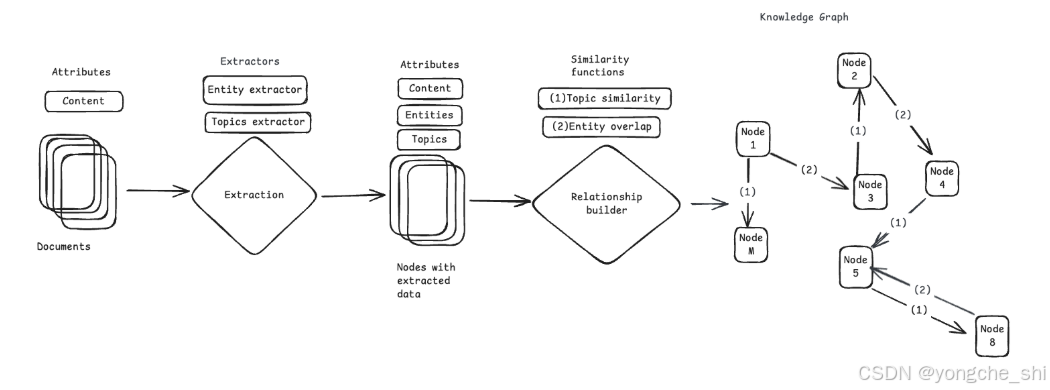
知识图谱通过以下组件创建:
文档分割器
文档被分块以形成层次节点。可以使用不同的分割器进行分块。例如,对于金融文档,可以使用基于章节(如利润表、资产负债表、现金流量表等)进行分割的分割器。您可以编写自己的自定义分割器,根据与您的领域相关的章节来分割文档。
示例
from ragas.testset.graph import Node
sample_nodes = [Node(
properties={"page_content": "Einstein's theory of relativity revolutionized our understanding of space and time. It introduced the concept that time is not absolute but can change depending on the observer's frame of reference."}
),Node(
properties={"page_content": "Time dilation occurs when an object moves close to the speed of light, causing time to pass slower relative to a stationary observer. This phenomenon is a key prediction of Einstein's special theory of relativity."}
)]
sample_nodes
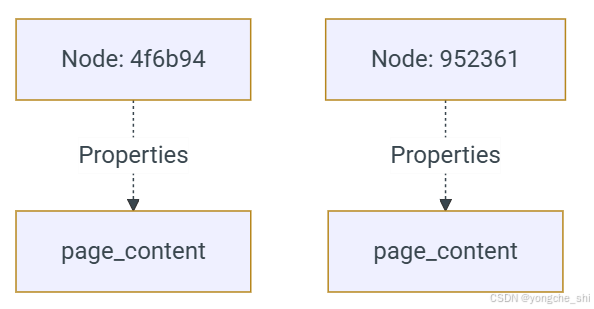
输出:
[Node(id: 4f6b94, type: , properties: ['page_content']),
Node(id: 952361, type: , properties: ['page_content'])]
提取器
使用不同的提取器从每个节点提取信息,这些信息可用于建立节点之间的关系。例如,对于金融文档,可以使用的提取器包括:实体提取器(用于提取公司名称等实体)、关键词组提取器(用于提取每个节点中存在的重要关键词组)等。您可以编写自己的自定义提取器,以提取与您的领域相关的信息。
提取器可以是基于 LLM 的(继承自 LLMBasedExtractor ),也可以是基于规则的(继承自 Extractor )。
示例
假设我们有一个来自知识图谱的示例节点。我们可以使用 NERExtractor 从该节点中提取命名实体。
from ragas.testset.transforms.extractors import NERExtractor
extractor = NERExtractor()
output = [await extractor.extract(node) for node in sample_nodes]
output[0]
返回一个包含提取器类型和提取信息的元组。
('entities', ['Einstein', 'theory of relativity', 'space', 'time', "observer's frame of reference"])
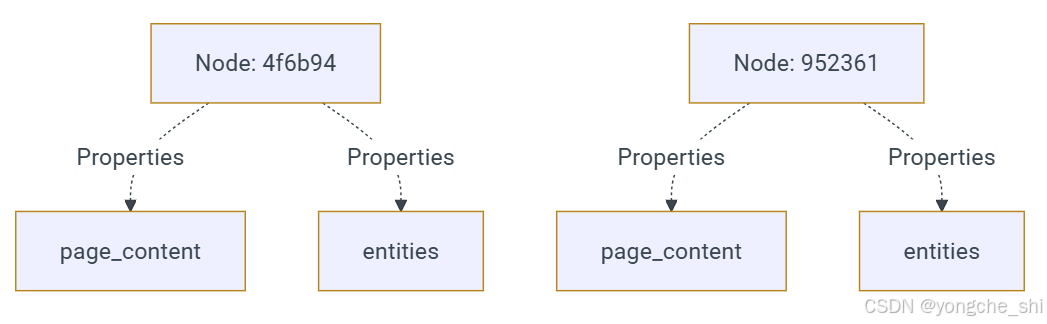
让我们将提取的信息添加到节点中。
_ = [node.properties.update({key:val}) for (key,val), node in zip(output, sample_nodes)]
sample_nodes[0].properties
输出:
{'page_content': "Einstein's theory of relativity revolutionized our understanding of space and time. It introduced the concept that time is not absolute but can change depending on the observer's frame of reference.",
'entities': ['Einstein', 'theory of relativity', 'space', 'time', 'observer']}
关系构建器
提取的信息用于建立节点之间的关系。例如,对于金融文档,可以基于节点中存在的实体在节点之间建立关系。您可以编写自己的自定义关系构建器,根据与您的领域相关的信息来建立节点之间的关系。
示例
from ragas.testset.graph import KnowledgeGraph
from ragas.testset.transforms.relationship_builders.traditional import JaccardSimilarityBuilder
kg = KnowledgeGraph(nodes=sample_nodes)
rel_builder = JaccardSimilarityBuilder(property_name="entities", key_name="PER", new_property_name="entity_jaccard_similarity")
relationships = await rel_builder.transform(kg)
relationships
输出:
[Relationship(Node(id: 4f6b94) <-> Node(id: 952361), type: jaccard_similarity, properties: ['entity_jaccard_similarity'])]
由于两个节点都具有相同的实体"爱因斯坦",因此基于实体相似度在节点之间建立了关系。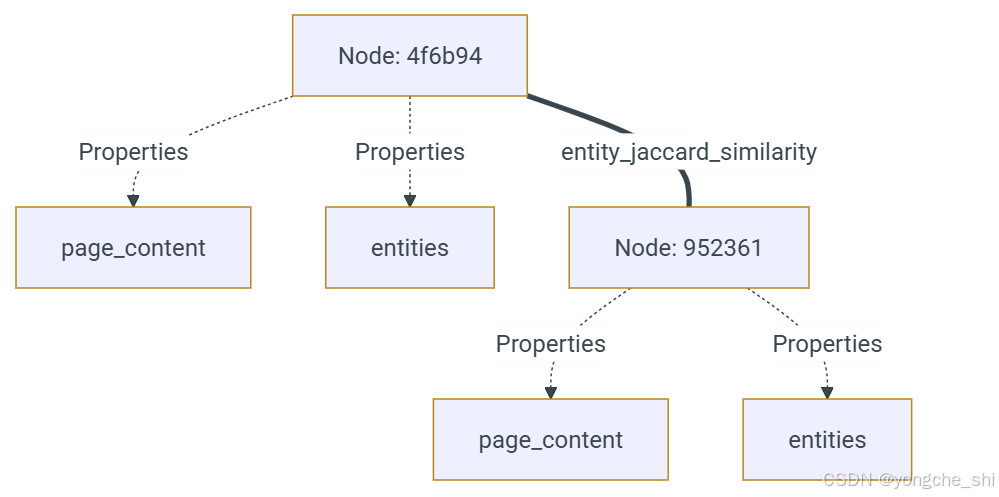
现在让我们了解如何使用上述组件和转换来构建知识图谱,这将使您的工作更轻松。
转换
用于构建知识图谱的所有组件可以组合成单个转换,该转换可以应用于知识图谱以构建知识图谱。转换由一系列按顺序应用于知识图谱的组件列表组成。它还可以处理组件的并行处理。 apply_transforms 方法用于将转换应用于知识图谱。
示例
让我们使用上述组件和转换来构建上述知识图谱。
from ragas.testset.transforms import apply_transforms
transforms = [
extractor,
rel_builder
]
apply_transforms(kg,transforms)
要并行应用部分组件,您可以将它们包装在 Parallel 类中。
from ragas.testset.transforms import KeyphraseExtractor, NERExtractor
from ragas.testset.transforms import apply_transforms, Parallel
tranforms = [
Parallel(
KeyphraseExtractor(),
NERExtractor()
),
rel_builder
]
apply_transforms(kg,transforms)
一旦知识图谱创建完成,就可以通过遍历图谱来生成不同类型的查询。例如,要生成查询“比较公司X和公司Y在2020财年至2023财年的收入增长”,可以遍历图谱以找到包含公司X和公司Y在2020财年至2023财年收入增长信息的节点。
场景生成
现在我们有了可用于生成正确上下文以生成任何类型查询的知识图谱。当大量用户与RAG系统交互时,他们可能会根据自己的角色(例如,高级工程师、初级工程师等)、查询长度(短、长等)、查询风格(正式、非正式等)以各种方式提出查询。为了生成涵盖所有这些场景的查询,Ragas使用基于场景的方法进行测试集生成。
测试集生成中的每个场景都是以下参数的组合:
- 节点 :用于生成查询的节点
- 查询长度 :期望查询的长度,可以是短、中等或长等
- 查询风格 :查询的风格,可以是网络搜索、聊天等
- 角色 :用户的角色,可以是高级工程师、初级工程师等(即将推出)
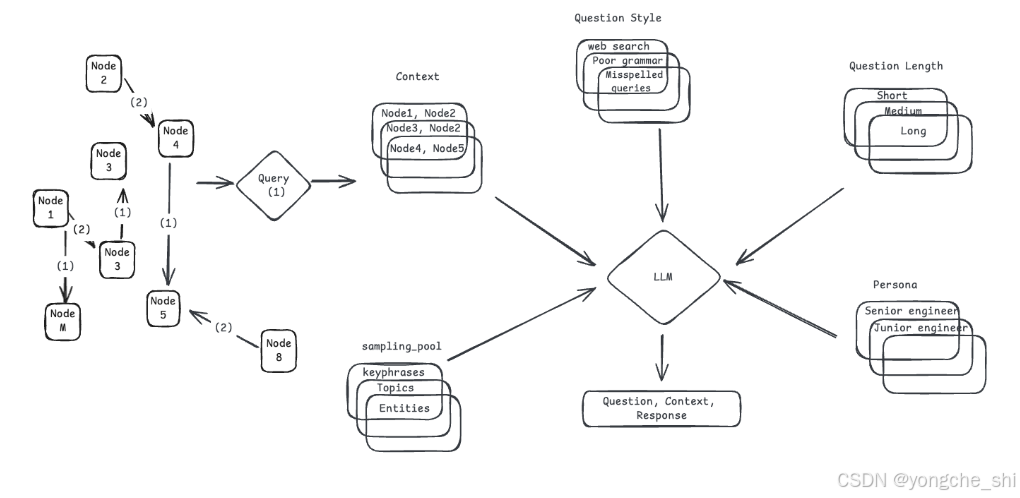
查询合成器
QuerySynthesizer 负责为单一查询类型生成不同场景。 generate_scenarios 方法用于为单一查询类型生成场景。 generate_sample 方法用于为单个场景生成查询和参考答案。让我们通过一个示例来理解这一点。
示例
在前面的示例中,我们创建了一个知识图谱,其中包含两个基于实体相似度相互关联的节点。现在假设您的知识图谱中有20对这样基于实体相似度相互关联的节点。
假设您的目标是创建50个不同的查询,每个查询都是关于比较两个实体的抽象问题。我们首先必须查询知识图谱以获取基于实体相似度相互关联的节点对。然后我们必须为每对节点生成场景,直到获得50个不同的场景。此逻辑在 generate_scenarios 方法中实现。
from dataclasses import dataclass
from ragas.testset.synthesizers.base_query import QuerySynthesizer
@dataclass
class EntityQuerySynthesizer(QuerySynthesizer):
async def _generate_scenarios( self, n, knowledge_graph, callbacks):
"""
logic to query nodes with entity
logic describing how to combine nodes,styles,length,persona to form n scenarios
"""
return scenarios
async def _generate_sample(
self, scenario, callbacks
):
"""
logic on how to use tranform each scenario to EvalSample (Query,Context,Reference)
you may create singleturn or multiturn sample
"""
return SingleTurnSample(user_input=query, reference_contexs=contexts, reference=reference)
智能体或工具使用场景的测试集生成
评估智能体或工具使用工作流具有挑战性,因为它涉及多个步骤和交互。尤其难以整理一个涵盖所有可能场景和边缘情况的测试套件。我们正在开发一组工具,用于生成合成测试数据来评估智能体工作流。
欢迎与我们交流合作,了解即将发布版本中的新功能。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)