运维转大模型:从自动化脚本到 AIOps Agent
这篇我按“先跑起来、再讲取舍”的方式写《运维转大模型:从自动化脚本到 AIOps Agent》。概念会讲,但重点放在代码怎么组织、哪里容易踩坑。
摘要
这篇面向想从运维、SRE 转向 AI 自动化平台的工程师,但不会把“运维转大模型:从自动化脚本到 AIOps Agent”写成概念清单。我会按运维工程化实战教程的思路,把它放到真实开发、学习路线和求职准备里看,顺便讲几个容易忽略的取舍。这次我会从“从团队落地角度切入,重点写协作、日志和可维护性”展开,换一组场景和例子来讲。
目录
- 运维能力的迁移
- 日志分析
- 告警归因
- 自动处置 Agent
- 安全与审批
- 总结
运维能力的迁移
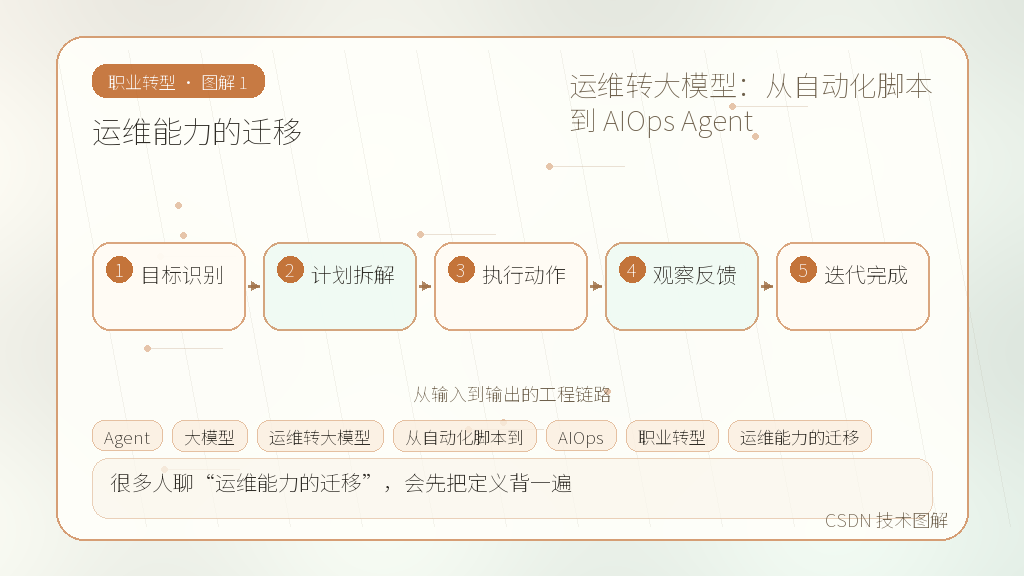
很多人聊“运维能力的迁移”,会先把定义背一遍。我的看法稍微不一样:从写代码的角度看,它必须能解释“运维转大模型:从自动化脚本到 AIOps Agent”里一个具体问题,否则就只是好听的词。
拿一个小项目来说,先别急着把框架、平台和插件全接上。我更愿意先画清楚输入是什么、输出给谁看、失败了怎么回滚。这三件事弄明白,后面的代码通常不会散。
这里最容易踩的坑,是把临时方案包装成通用架构。如果只是一次性脚本,就保持直白;如果要长期复用,再抽接口、加日志、补测试。
这一版我会把视角放在“从团队落地角度切入,重点写协作、日志和可维护性”,所以这里更关注具体场景,而不是把同一套定义再复述一遍。
日志分析
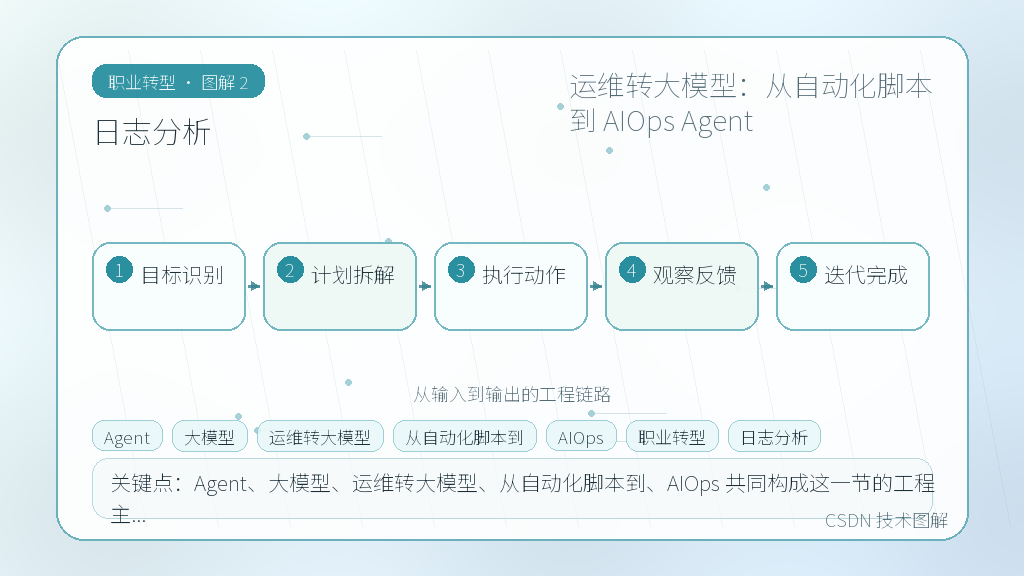
“日志分析”这块不适合只看教程截图。真正有用的学习方式,是把“运维转大模型:从自动化脚本到 AIOps Agent”拆成一个可以演示的小流程。
比如先做一个最小版本:一份输入数据,一个处理函数,一个可见结果。跑通以后再考虑缓存、权限、监控和异常处理。这样推进慢一点,但每一步都能留下证据。
如果你准备把它写进简历,也别只写“熟悉”。最好能说清楚你解决了什么问题、用了什么取舍、最后效果怎么验证。
这一版我会把视角放在“从团队落地角度切入,重点写协作、日志和可维护性”,所以这里更关注具体场景,而不是把同一套定义再复述一遍。
from collections.abc import Callable
def trace_call(name: str) -> Callable:
def decorator(func: Callable) -> Callable:
def wrapper(*args, **kwargs):
print(f"start {name}")
result = func(*args, **kwargs)
print(f"finish {name}")
return result
return wrapper
return decorator
@trace_call("calculate")
def calculate_score(values: list[int]) -> int:
return sum(value * 2 for value in values)告警归因
我不建议把“告警归因”理解成一个孤立知识点。它更像是“运维转大模型:从自动化脚本到 AIOps Agent”里的一段连接层:前面接需求,后面接实现,中间全是取舍。
实际开发时,我会先保留最朴素的版本,哪怕代码看起来没那么漂亮。等需求稳定、调用频率上来,再去做抽象。过早设计通常不是专业,很多时候只是给自己增加维护成本。
检查这部分有没有做好,可以看三个信号:别人能不能接手,线上出错能不能定位,需求变化时要不要大面积重写。
这一版我会把视角放在“从团队落地角度切入,重点写协作、日志和可维护性”,所以这里更关注具体场景,而不是把同一套定义再复述一遍。
在复杂度估算中,可以把一次批处理抽象为:
$$T(n)=O(n)+O(k)$$
其中 n 表示输入规模,k 表示固定的框架调度成本。这个表达式提醒我们,优化时既要关注算法,也要关注运行时环境。

自动处置 Agent
很多人聊“自动处置 Agent”,会先把定义背一遍。我的看法稍微不一样:从写代码的角度看,它必须能解释“运维转大模型:从自动化脚本到 AIOps Agent”里一个具体问题,否则就只是好听的词。
拿一个小项目来说,先别急着把框架、平台和插件全接上。我更愿意先画清楚输入是什么、输出给谁看、失败了怎么回滚。这三件事弄明白,后面的代码通常不会散。
这里最容易踩的坑,是把临时方案包装成通用架构。如果只是一次性脚本,就保持直白;如果要长期复用,再抽接口、加日志、补测试。
这一版我会把视角放在“从团队落地角度切入,重点写协作、日志和可维护性”,所以这里更关注具体场景,而不是把同一套定义再复述一遍。
安全与审批
“安全与审批”这块不适合只看教程截图。真正有用的学习方式,是把“运维转大模型:从自动化脚本到 AIOps Agent”拆成一个可以演示的小流程。
比如先做一个最小版本:一份输入数据,一个处理函数,一个可见结果。跑通以后再考虑缓存、权限、监控和异常处理。这样推进慢一点,但每一步都能留下证据。
如果你准备把它写进简历,也别只写“熟悉”。最好能说清楚你解决了什么问题、用了什么取舍、最后效果怎么验证。
这一版我会把视角放在“从团队落地角度切入,重点写协作、日志和可维护性”,所以这里更关注具体场景,而不是把同一套定义再复述一遍。
总结
回到“运维转大模型:从自动化脚本到 AIOps Agent”这个主题,最重要的不是把名词背全,而是知道它该放在什么场景里用。能跑起来的小项目、说得清楚的技术取舍、能展示的结果,比泛泛而谈更有说服力。后面真做的时候,可以先挑一个小场景验证,再把代码、笔记和复盘整理成自己的作品集。
差异化补充
这篇文章再补一个更具体的角度:不要只照着通用教程复述概念,而是把自己的学习路径、项目约束和踩坑过程写出来。比如同样是做一个 AI 应用,有人卡在模型调用,有人卡在数据清洗,也有人卡在上线后的日志和权限。把这些差异写清楚,文章就不容易和其它内容撞车。
如果用于求职或账号运营,我会优先保留三类证据:可运行截图、关键代码片段、以及一次失败排查记录。它们比空泛的“掌握某技术”更像真实经验,也更容易引发读者讨论。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
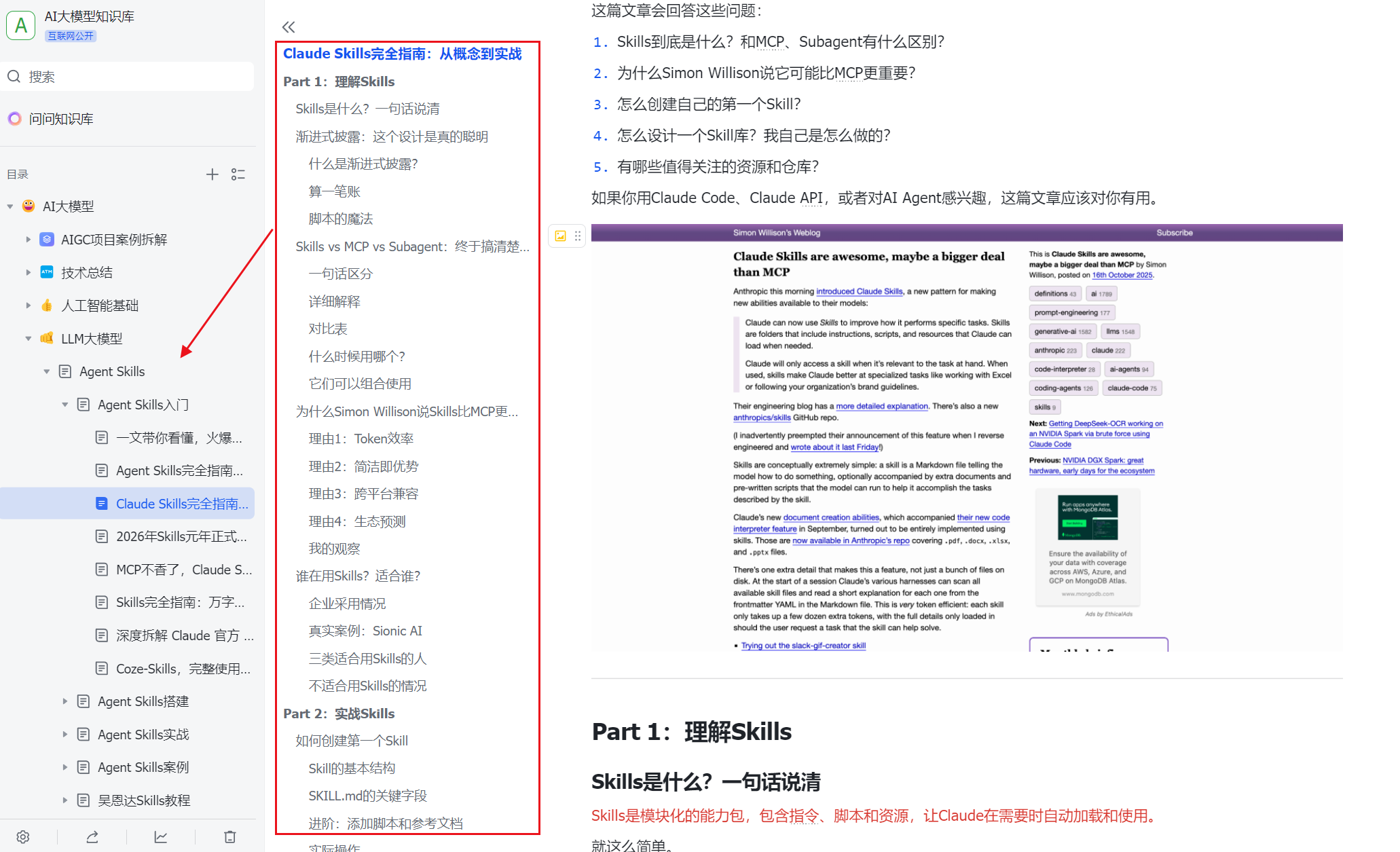
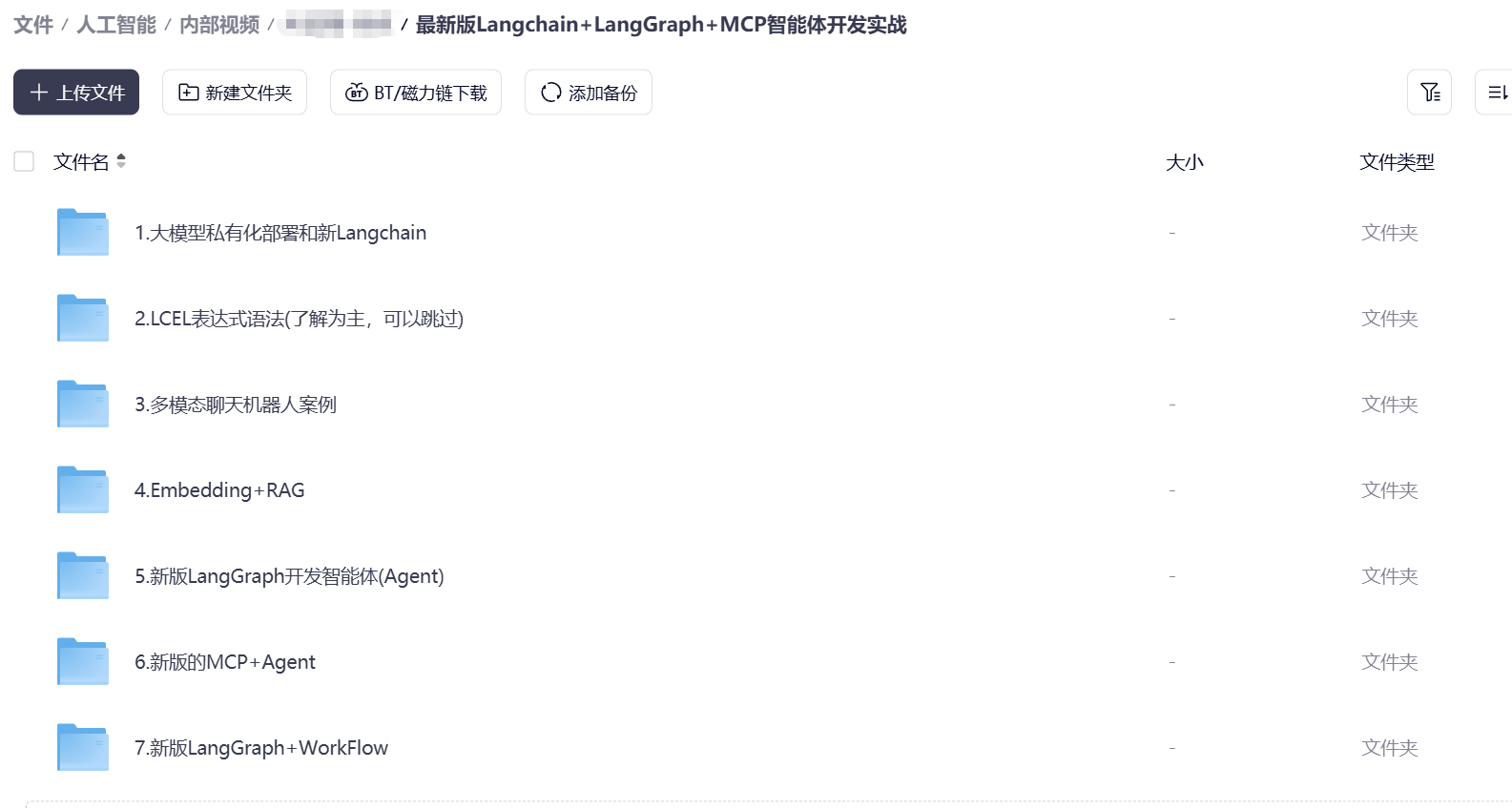

如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)