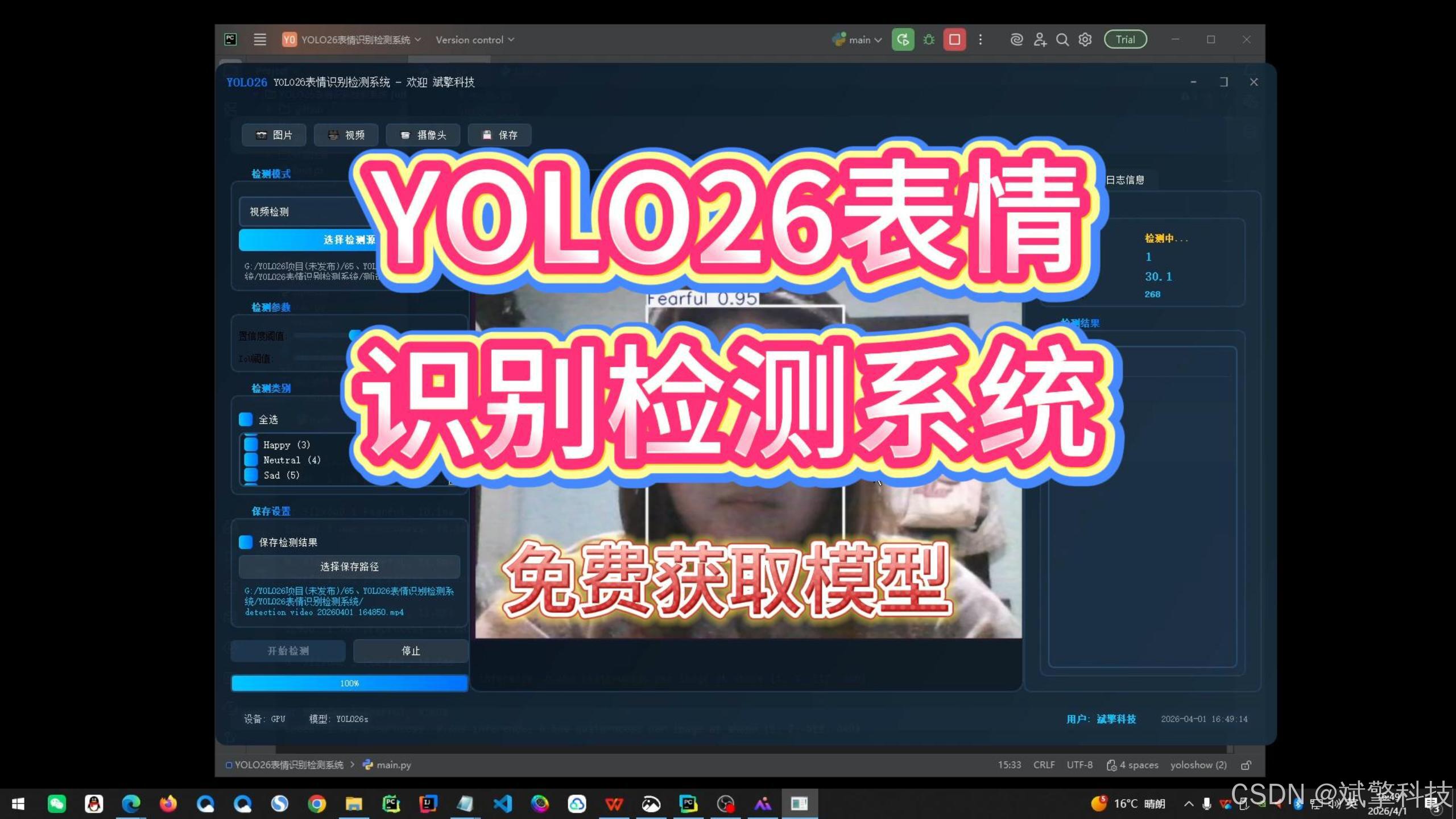
基于 YOLO26 的实时表情识别系统(7类情绪/5600图/愤怒/厌恶/恐惧/高兴/中立 /悲伤/惊讶)(项目源码+数据集+模型权重+UI界面+python+深度学习+远程环境部署)
摘要
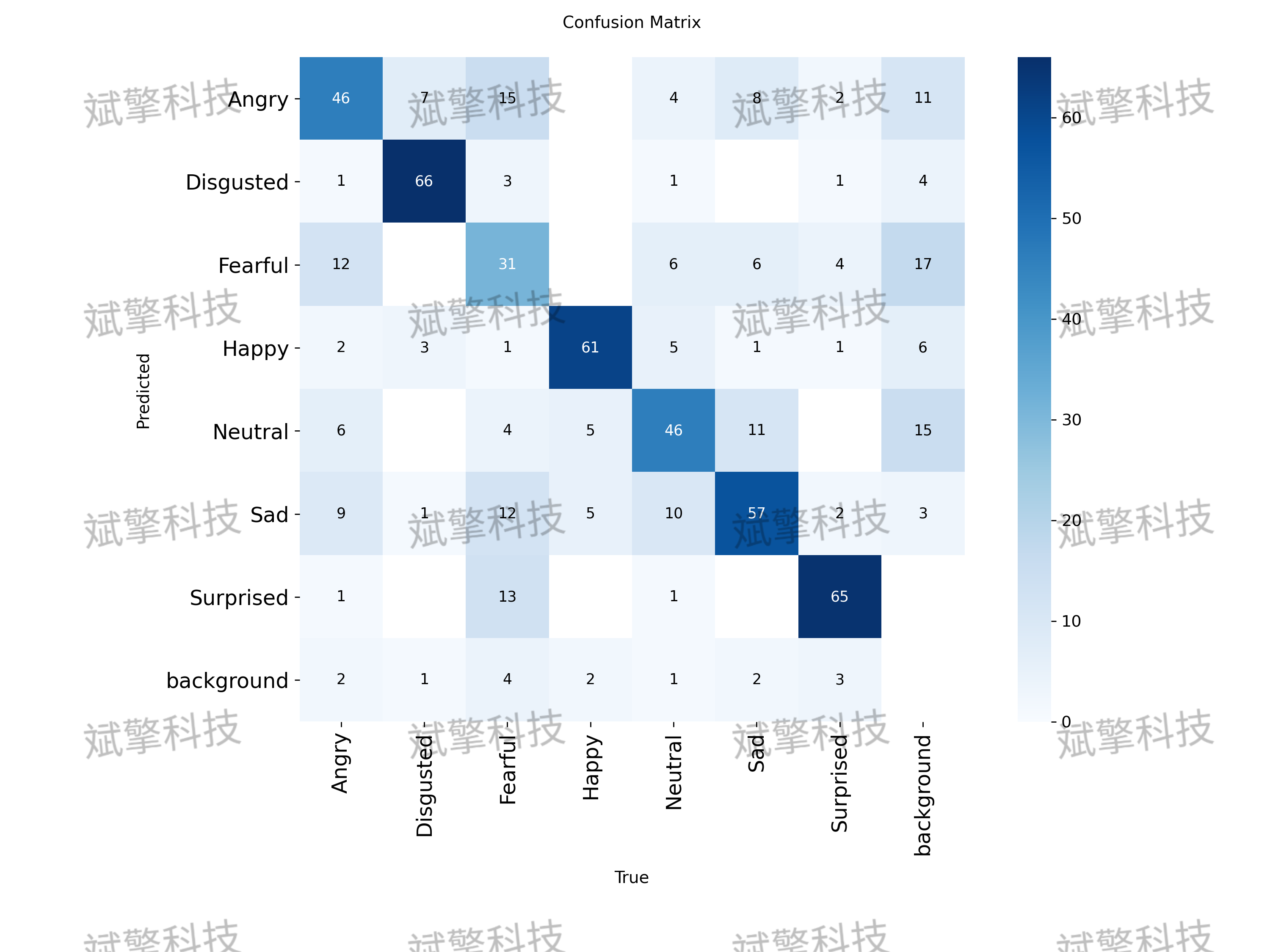
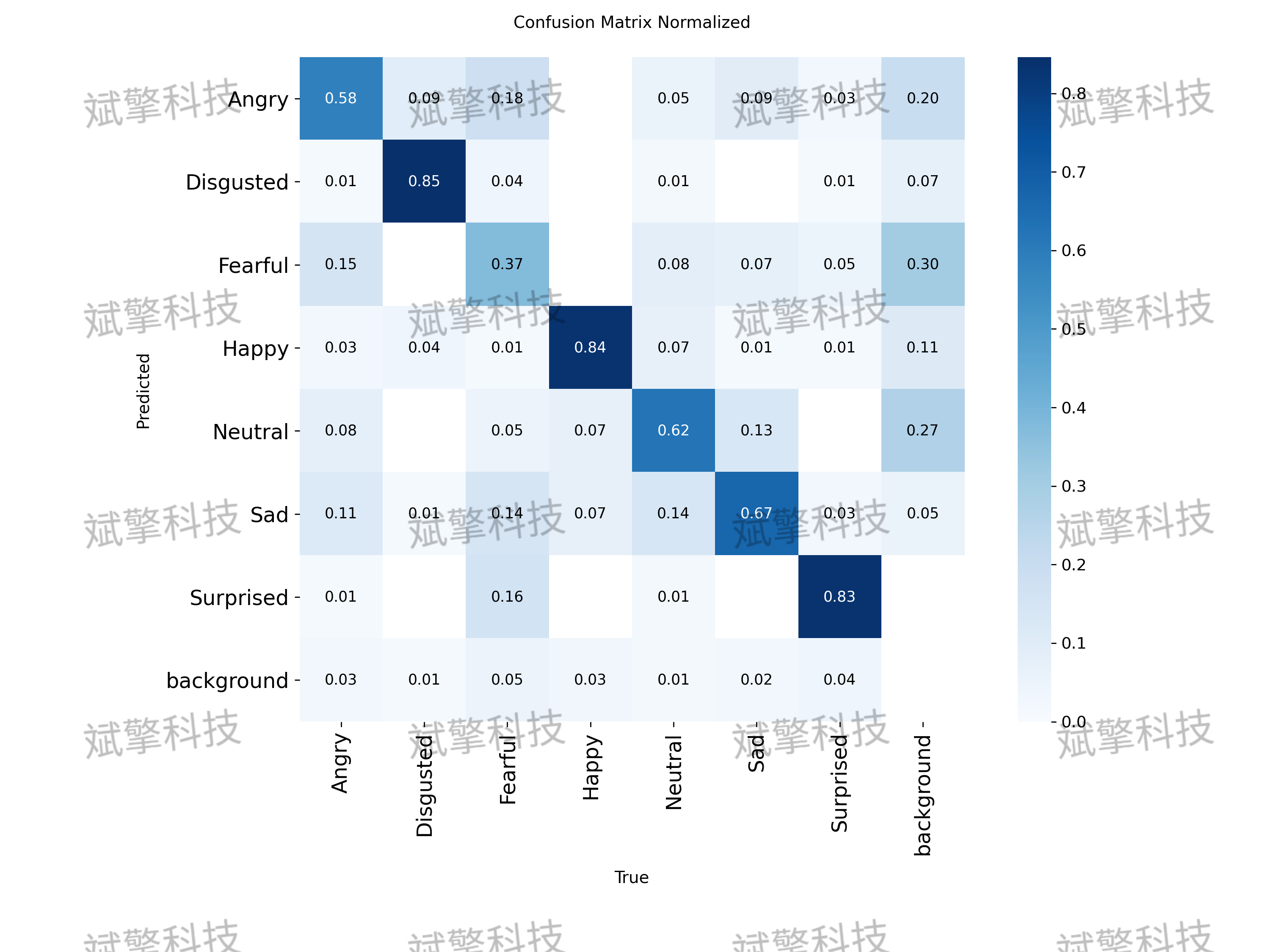
本研究基于YOLO26架构构建并训练了一款面向七类基础情绪(愤怒/厌恶/恐惧/高兴/中立 /悲伤/惊讶)的表情识别检测系统。实验数据集共包含5600余张图像,划分为训练集(4483张)、验证集(550张)及测试集(566张)。训练结果表明,该模型在验证集上取得了良好的收敛性。各类别中,“厌恶”(Disgusted)与“高兴”(Happy)的识别精度极高,mAP分别达到93.1%和91.2%。混淆矩阵分析显示,模型在区分“恐惧”与“悲伤”、“愤怒”与“中立”等相似表情时存在一定混淆。总体而言,该系统在实时性与准确率之间取得了较好的平衡,但在处理细微表情差异及类间相似性较高的样本时仍有优化空间。
详细功能展示视频
https://www.bilibili.com/video/BV1wHoWB1Efj/
目录
https://www.bilibili.com/video/BV1wHoWB1Efj/
功能模块
✅ 用户登录注册:支持密码检测,密码加密。
注册
登录
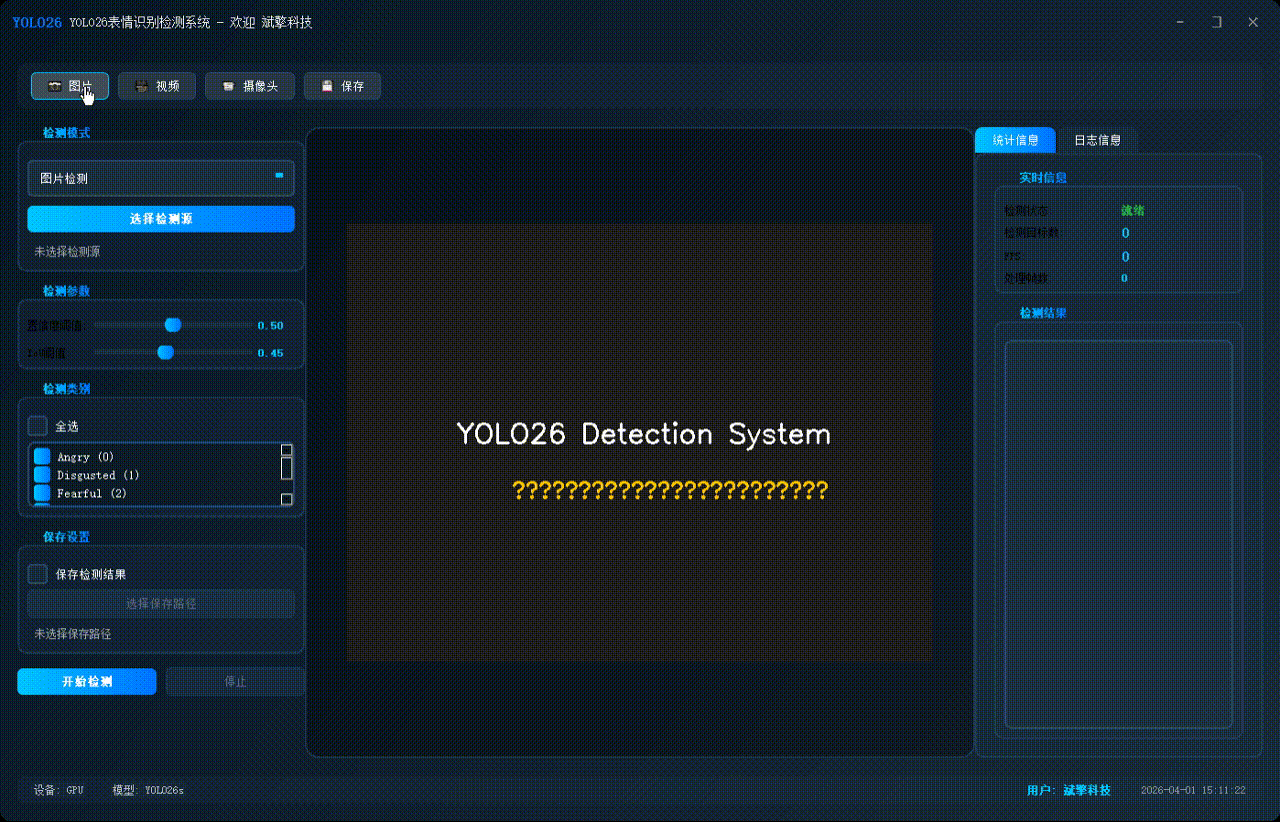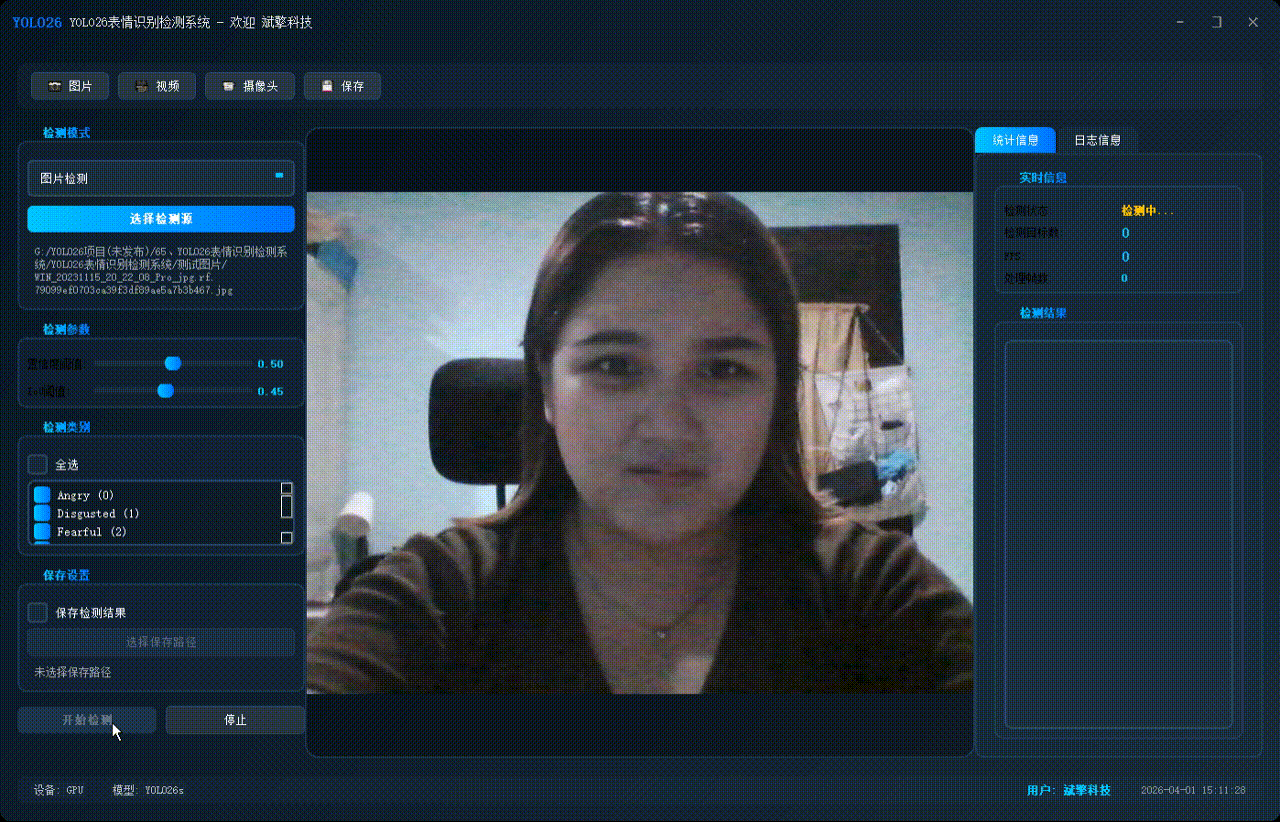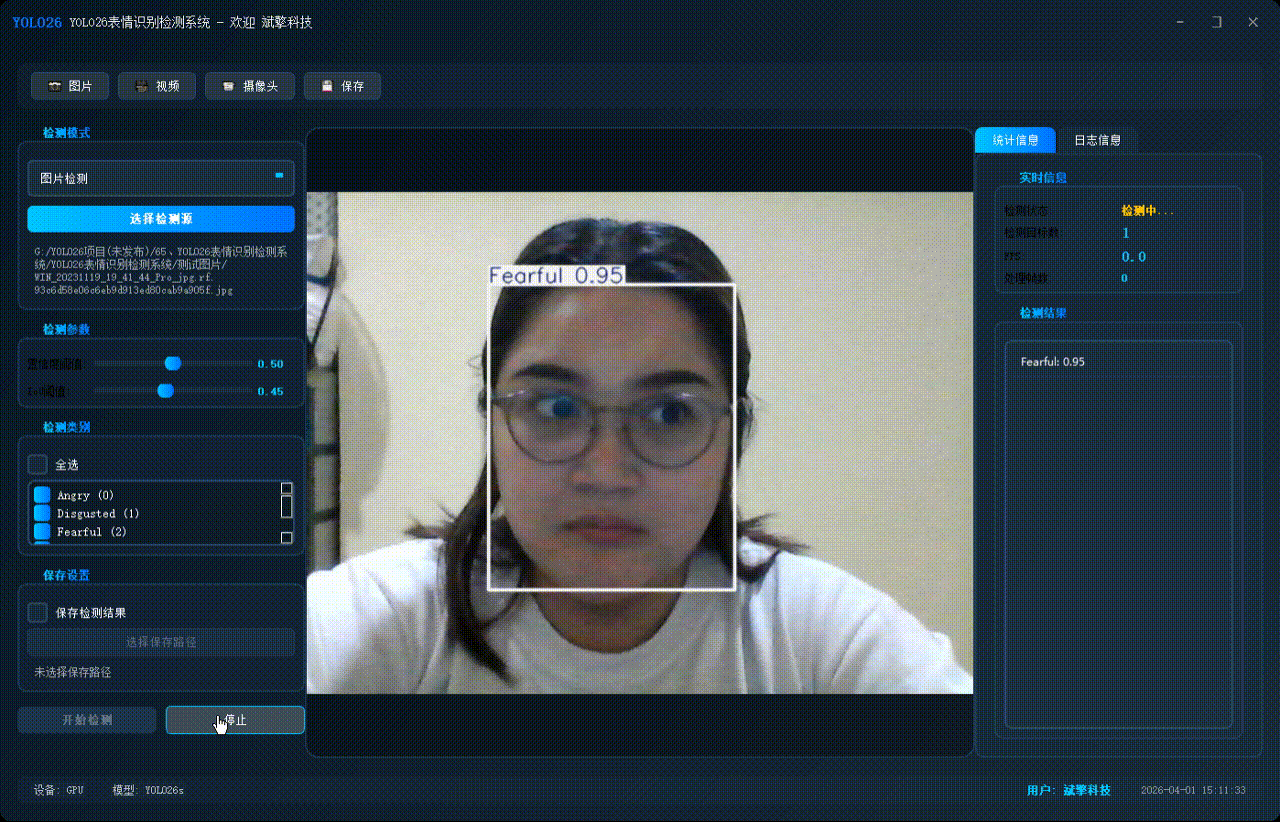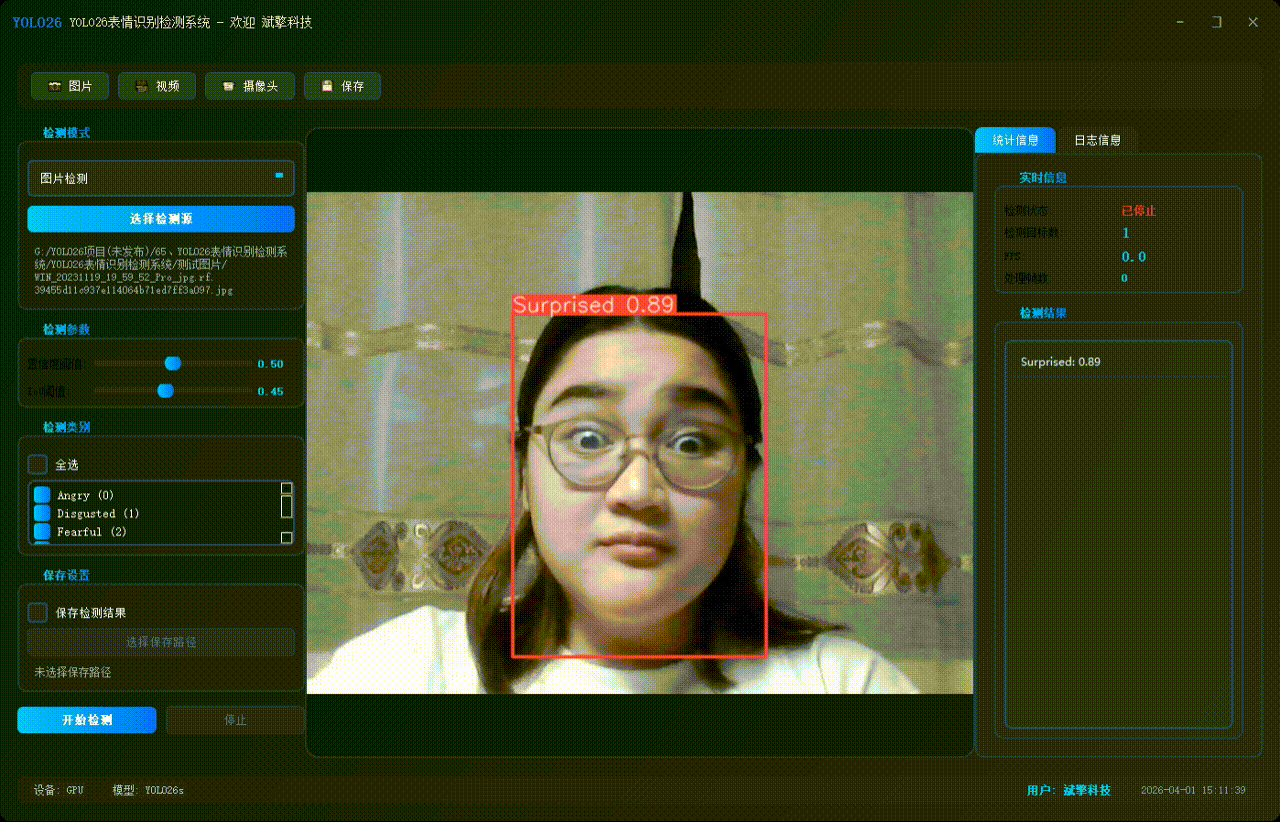
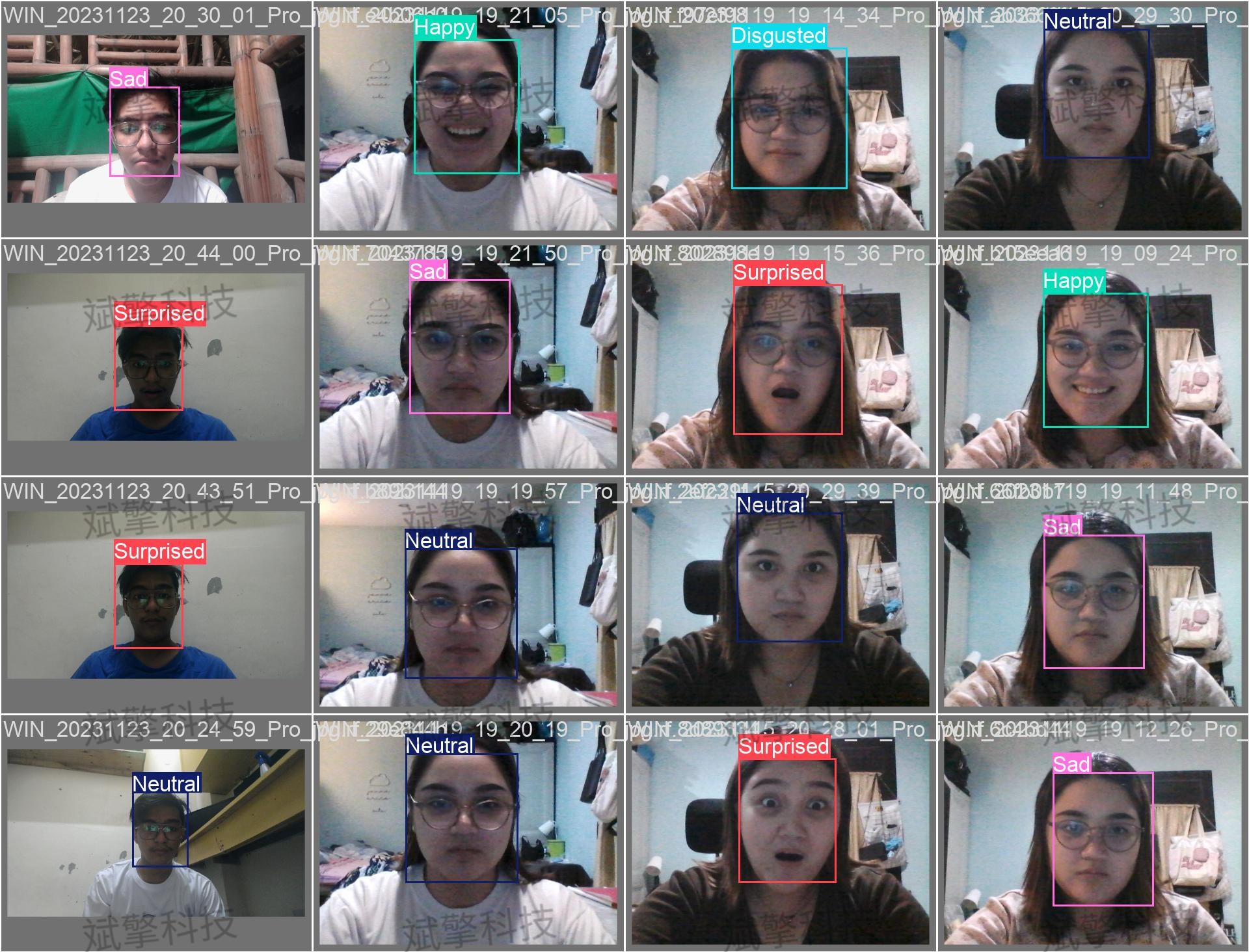
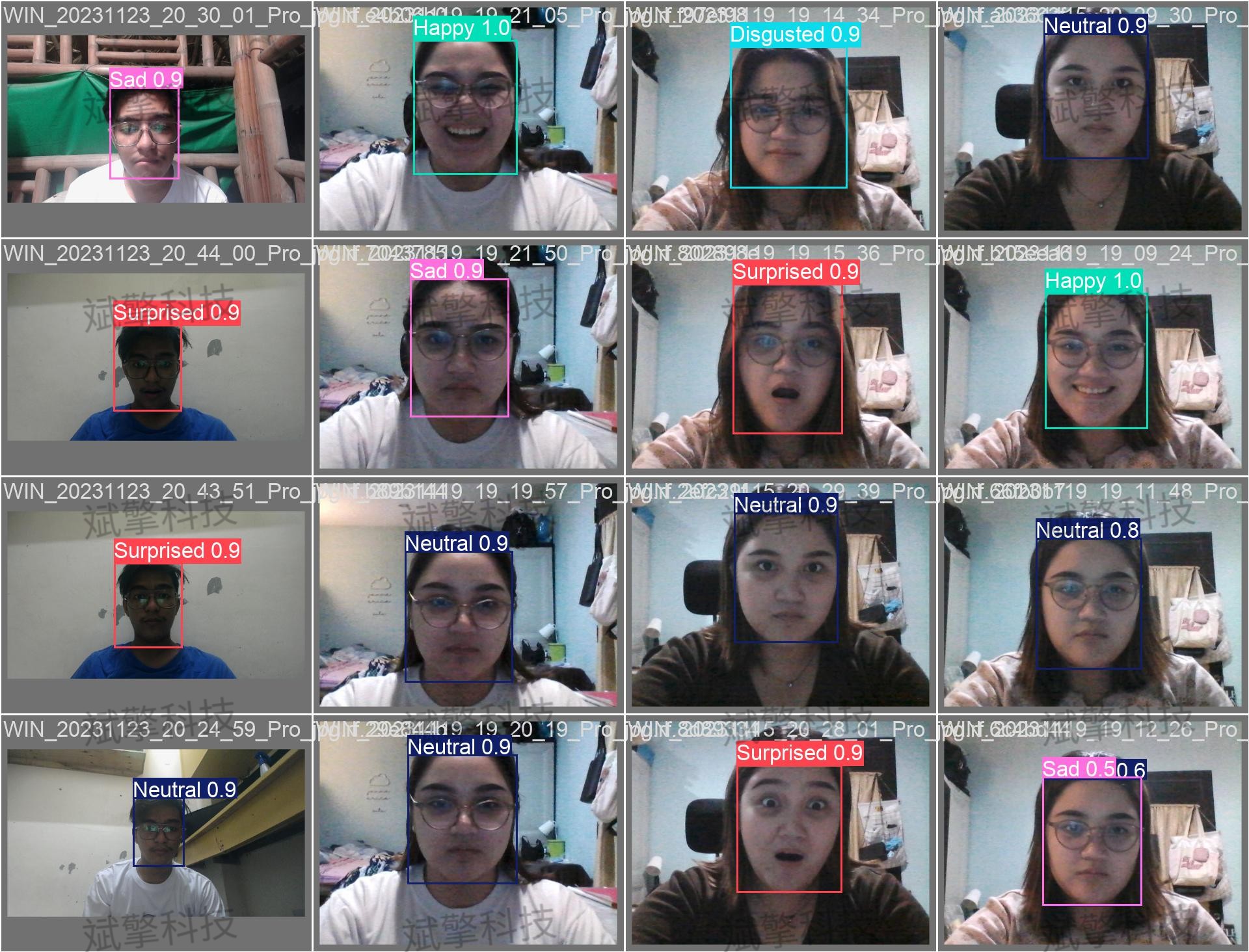
✅ 图片检测:可对图片进行检测,返回检测框及类别信息。
✅ 参数实时调节(置信度和IoU阈值)
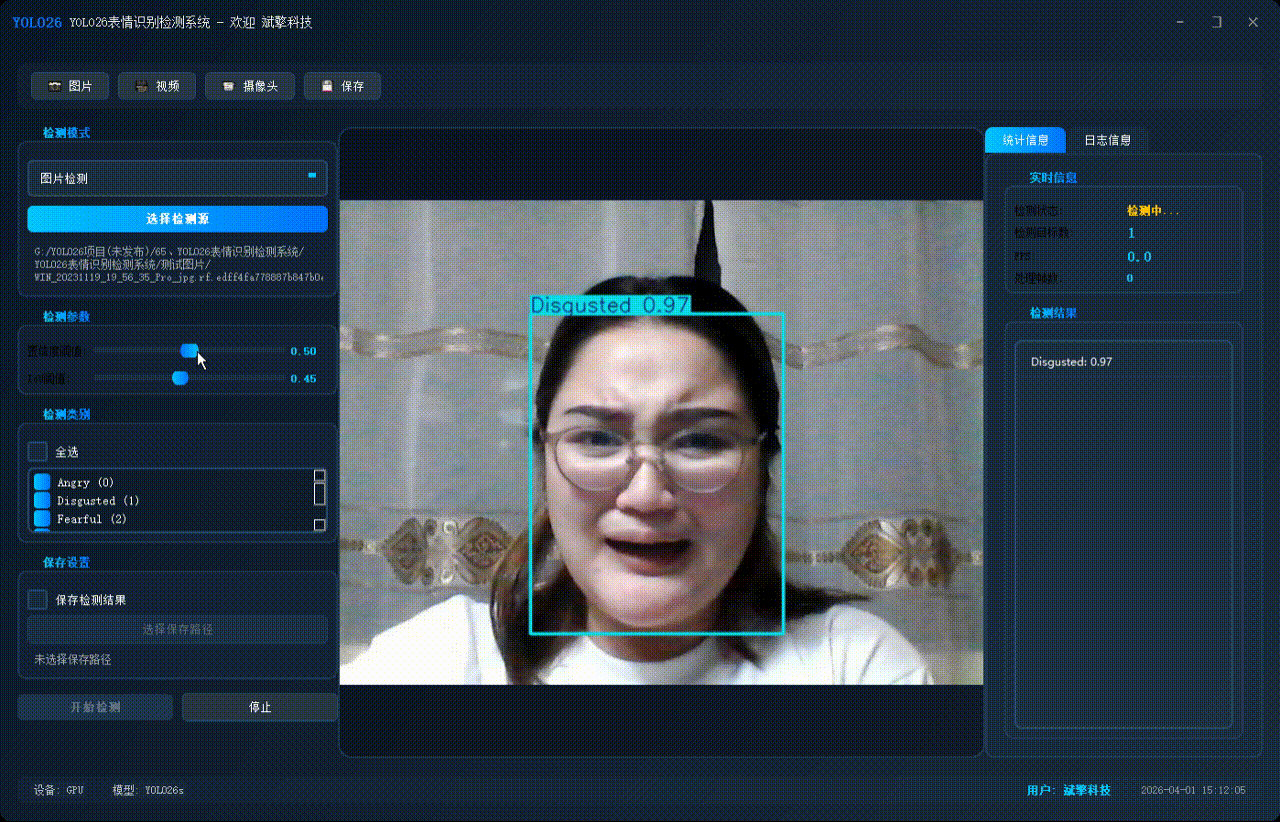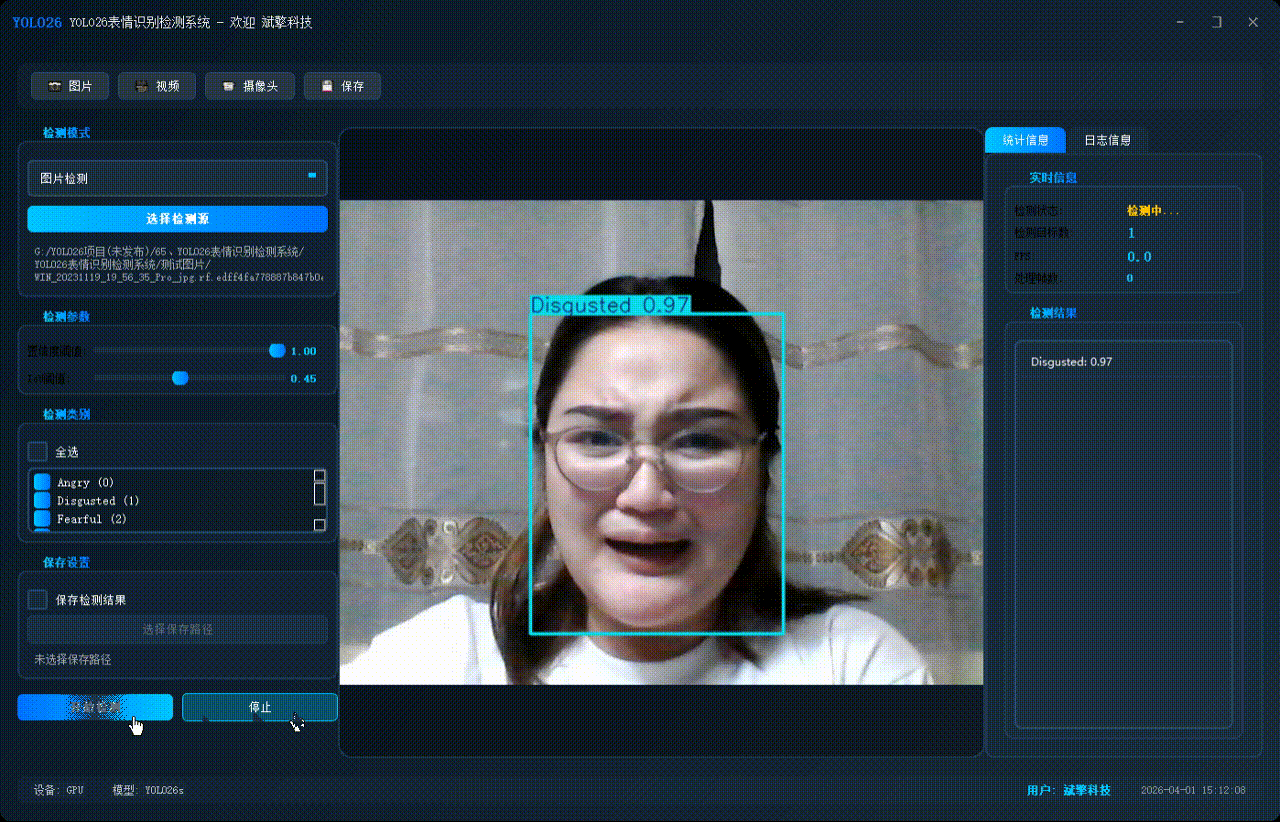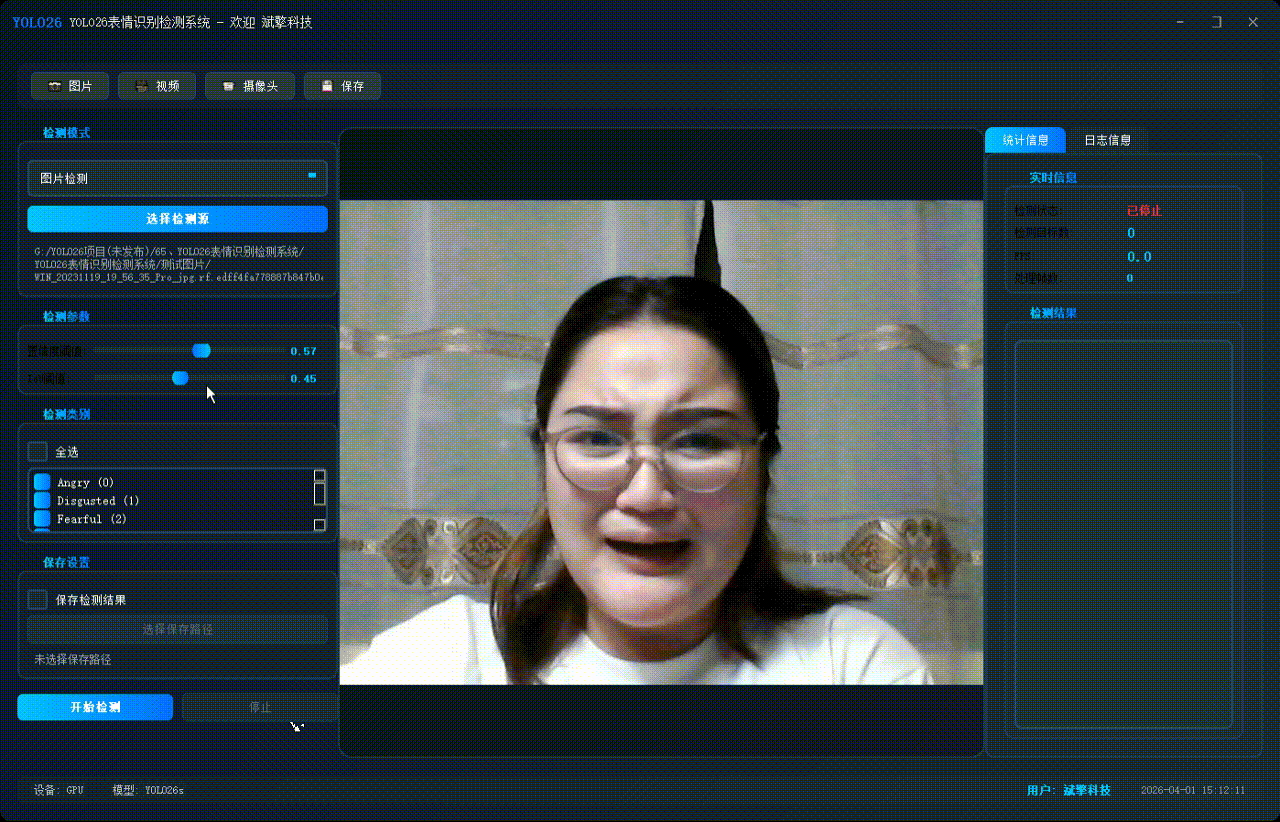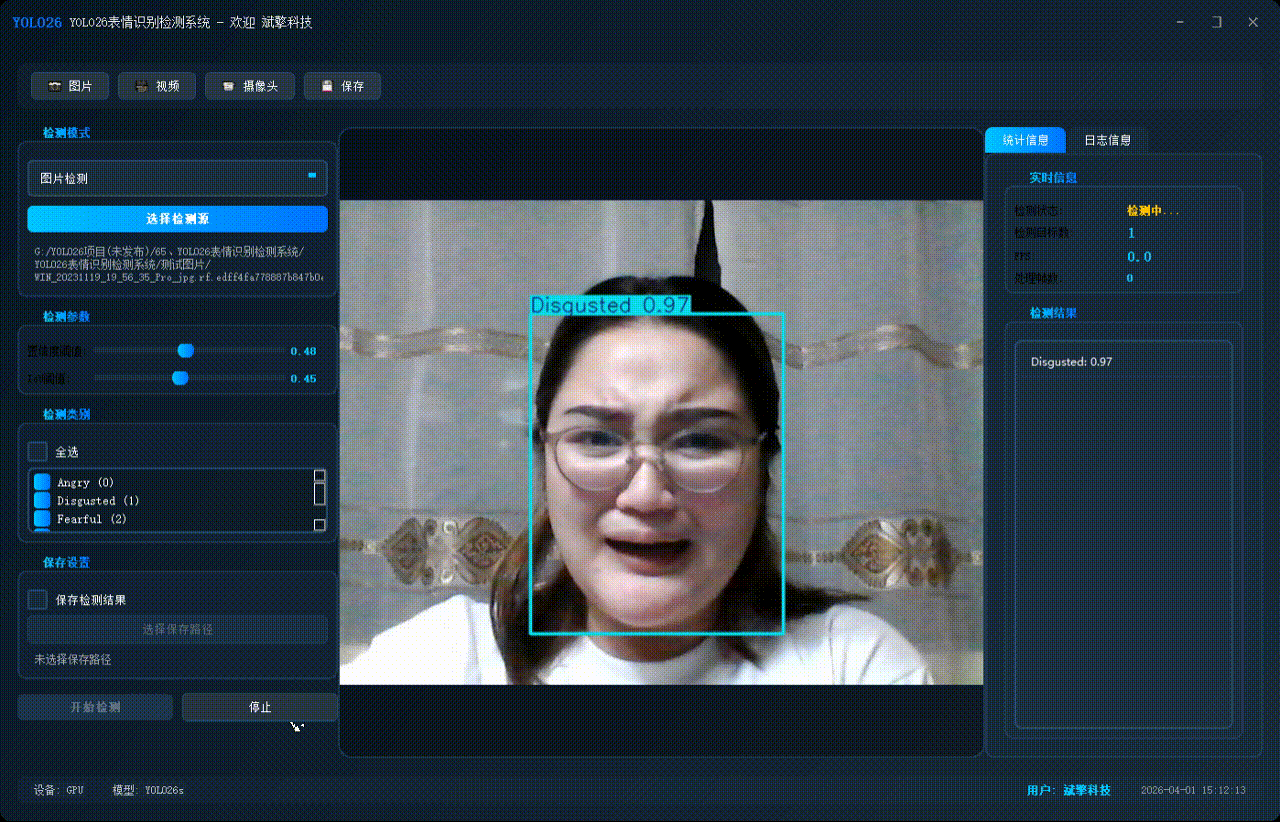
✅ 支持选择检测目标:可以选择一个或者多个类目的目标进行检测
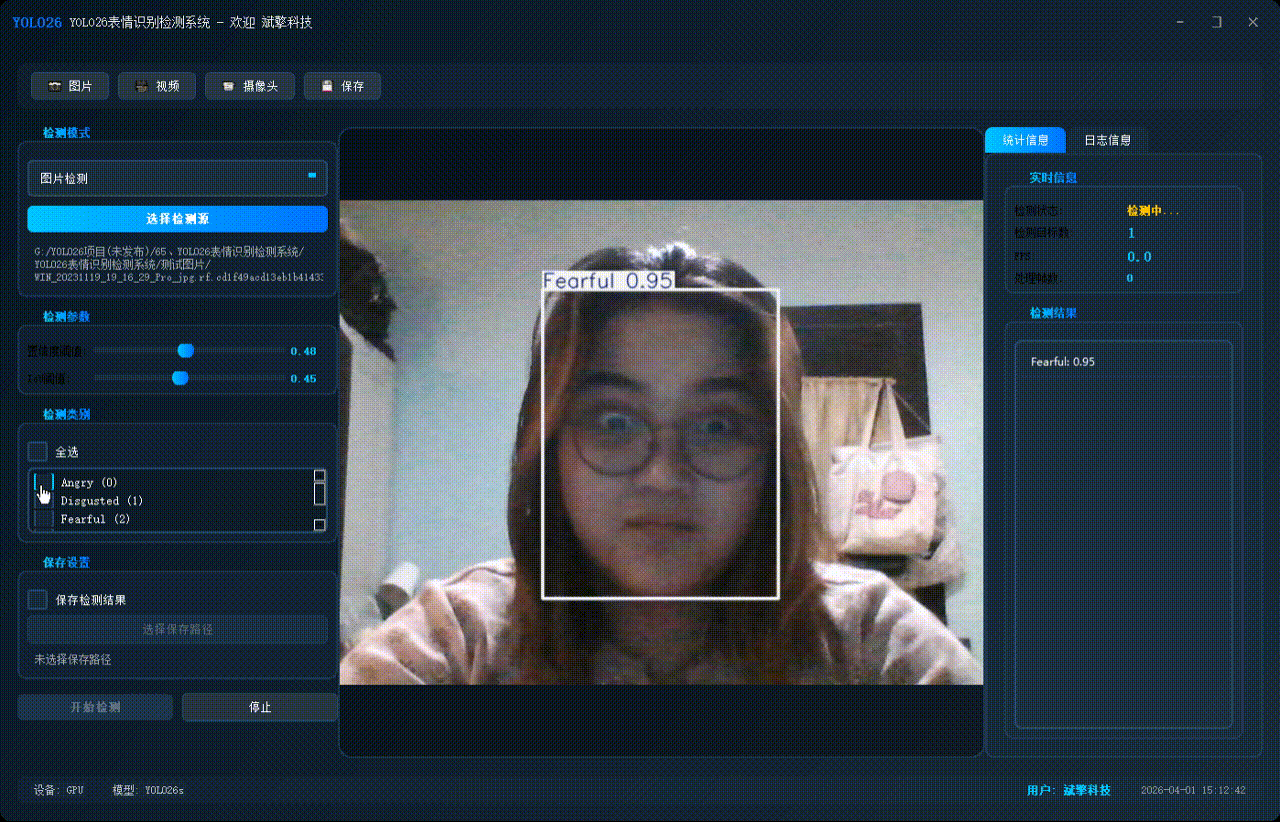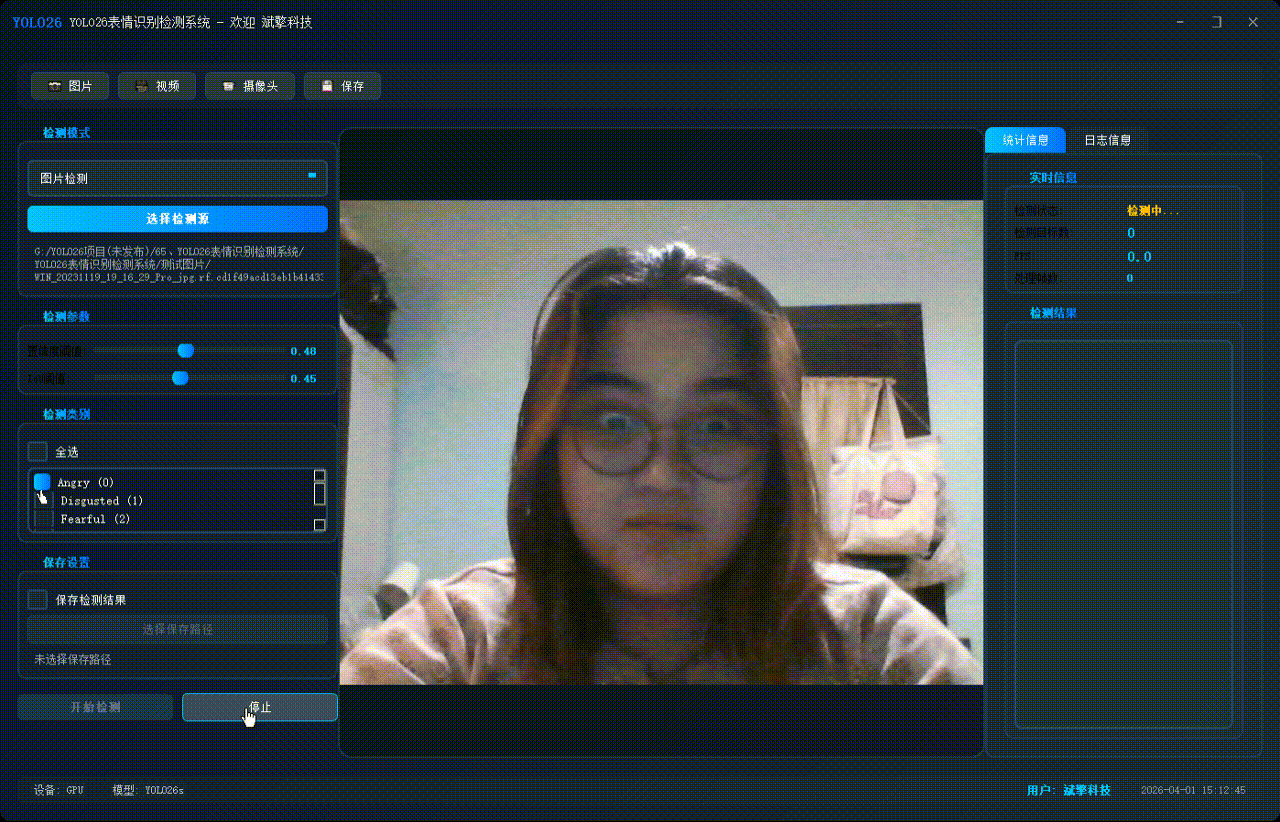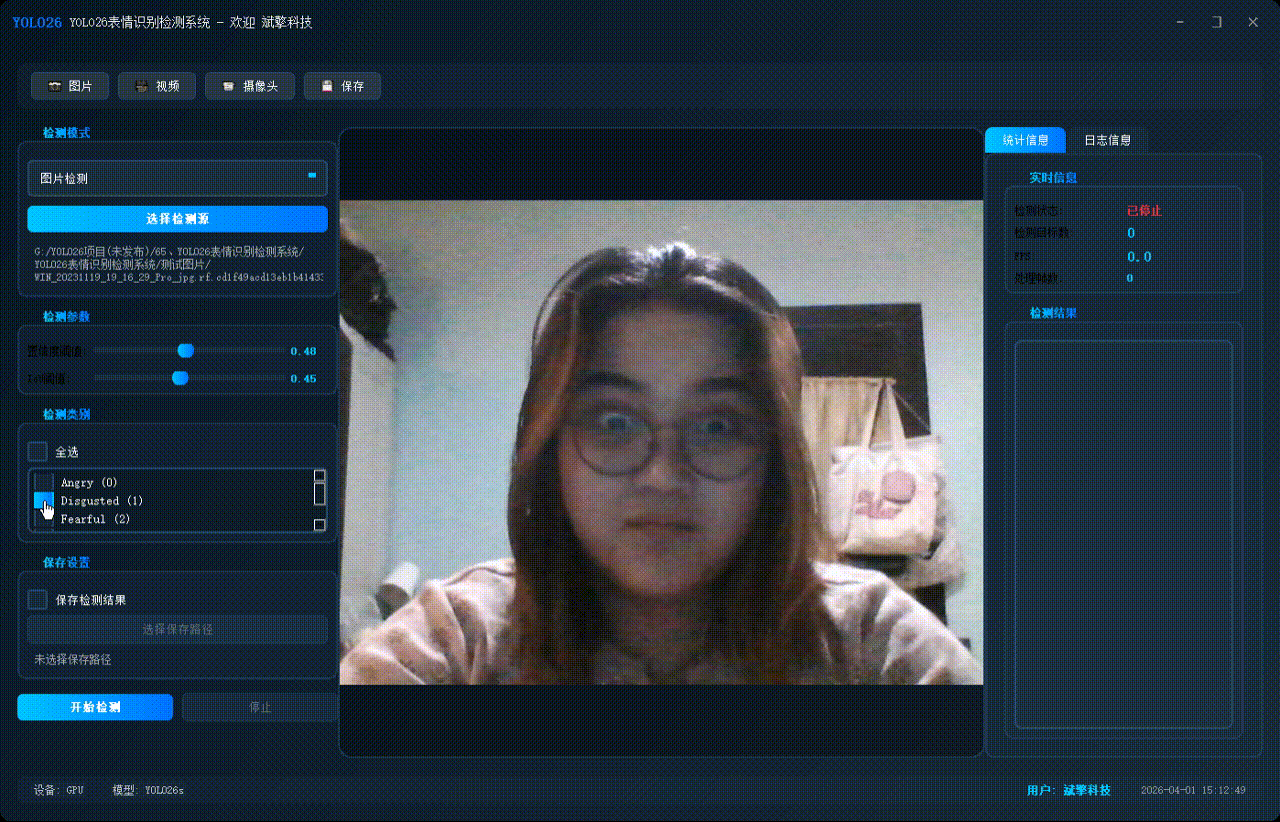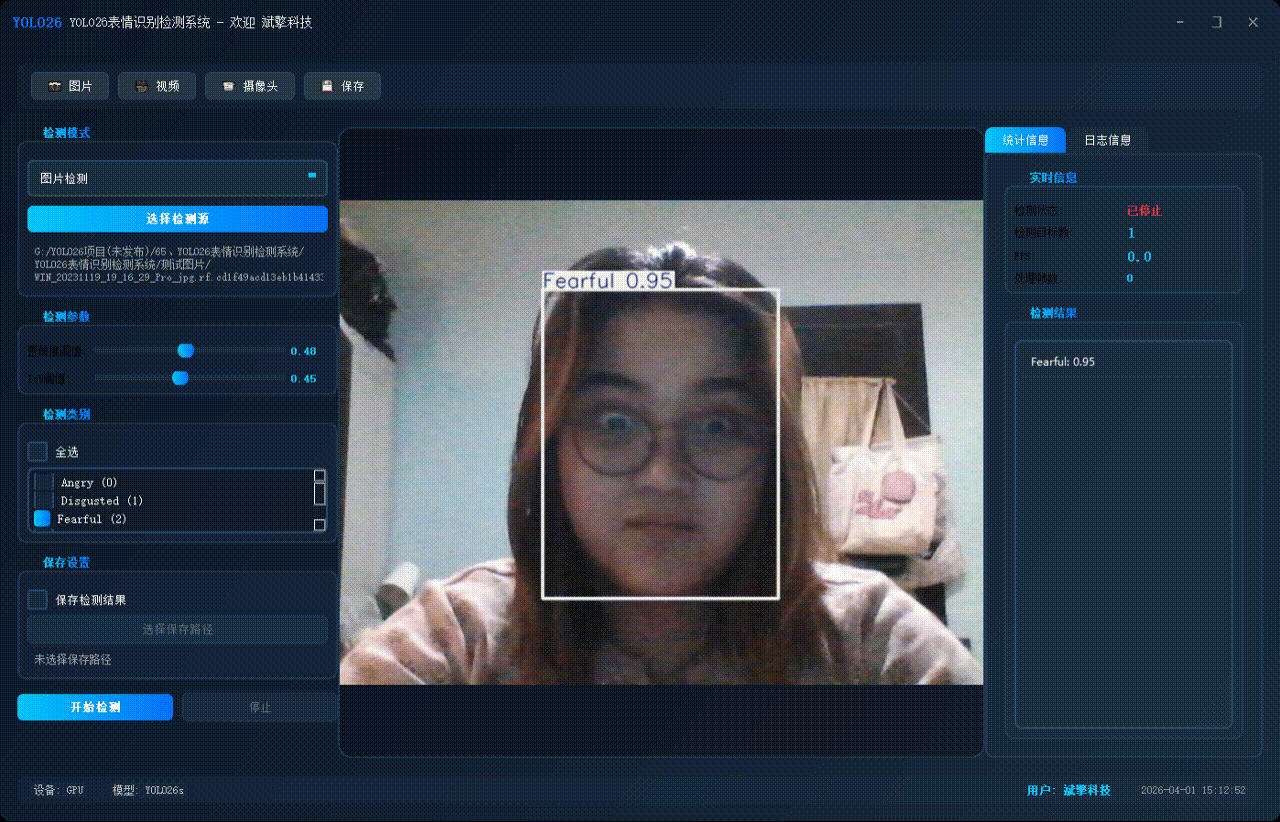
✅ 视频检测:支持视频文件输入,检测视频中每一帧的情况。
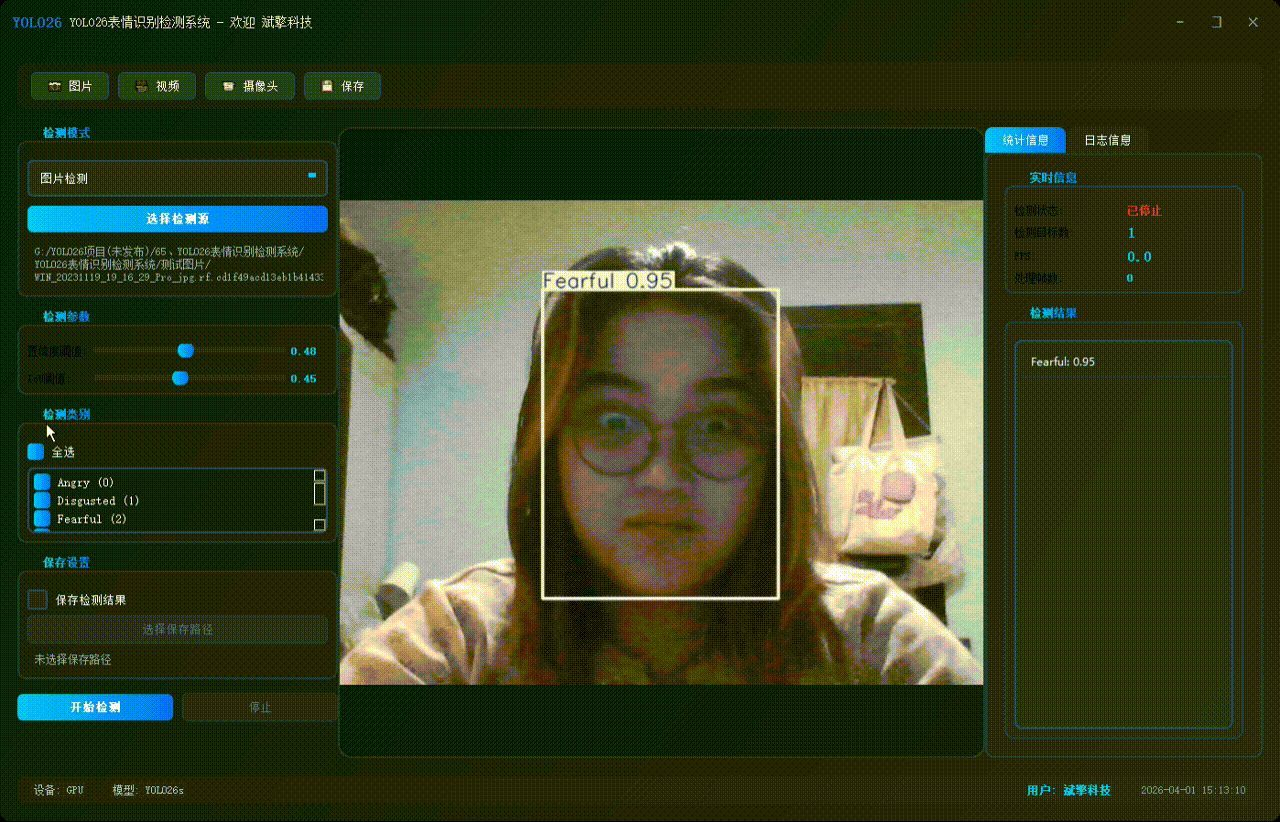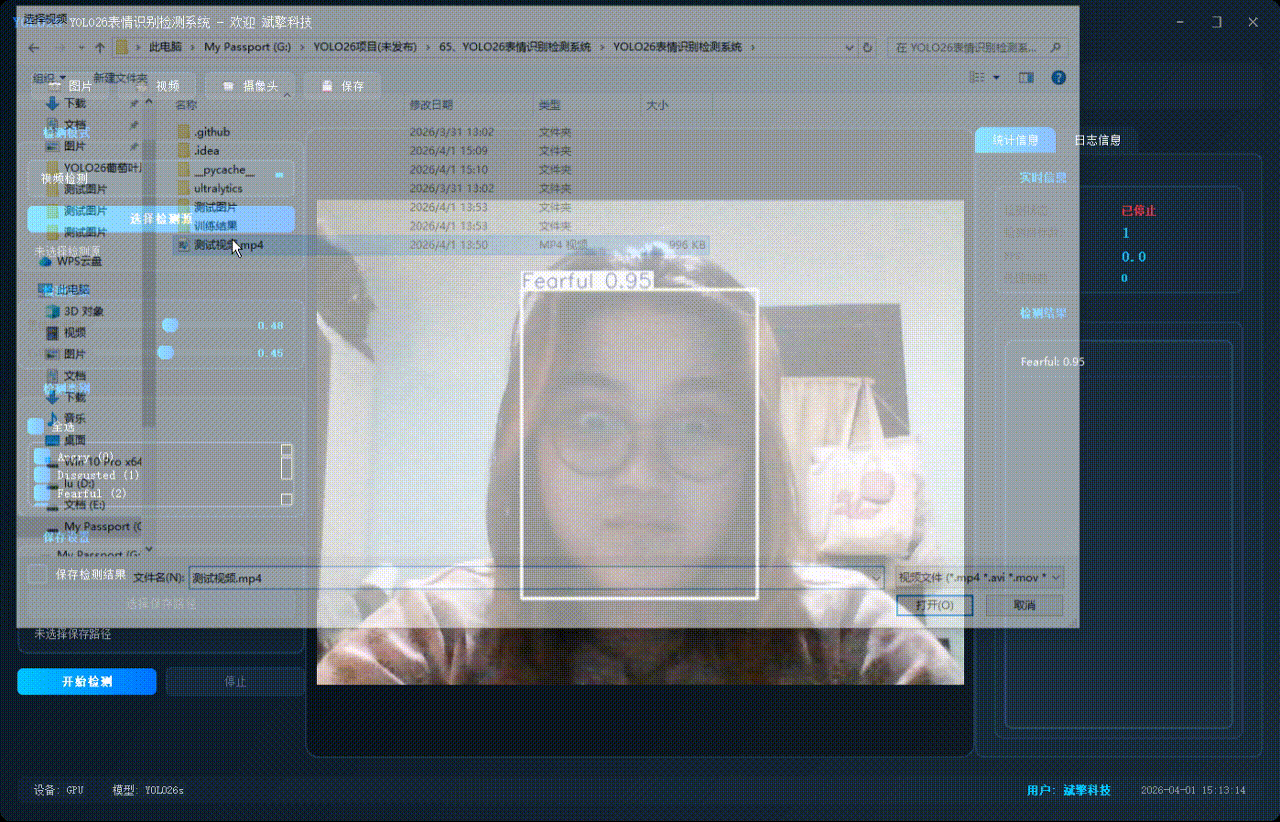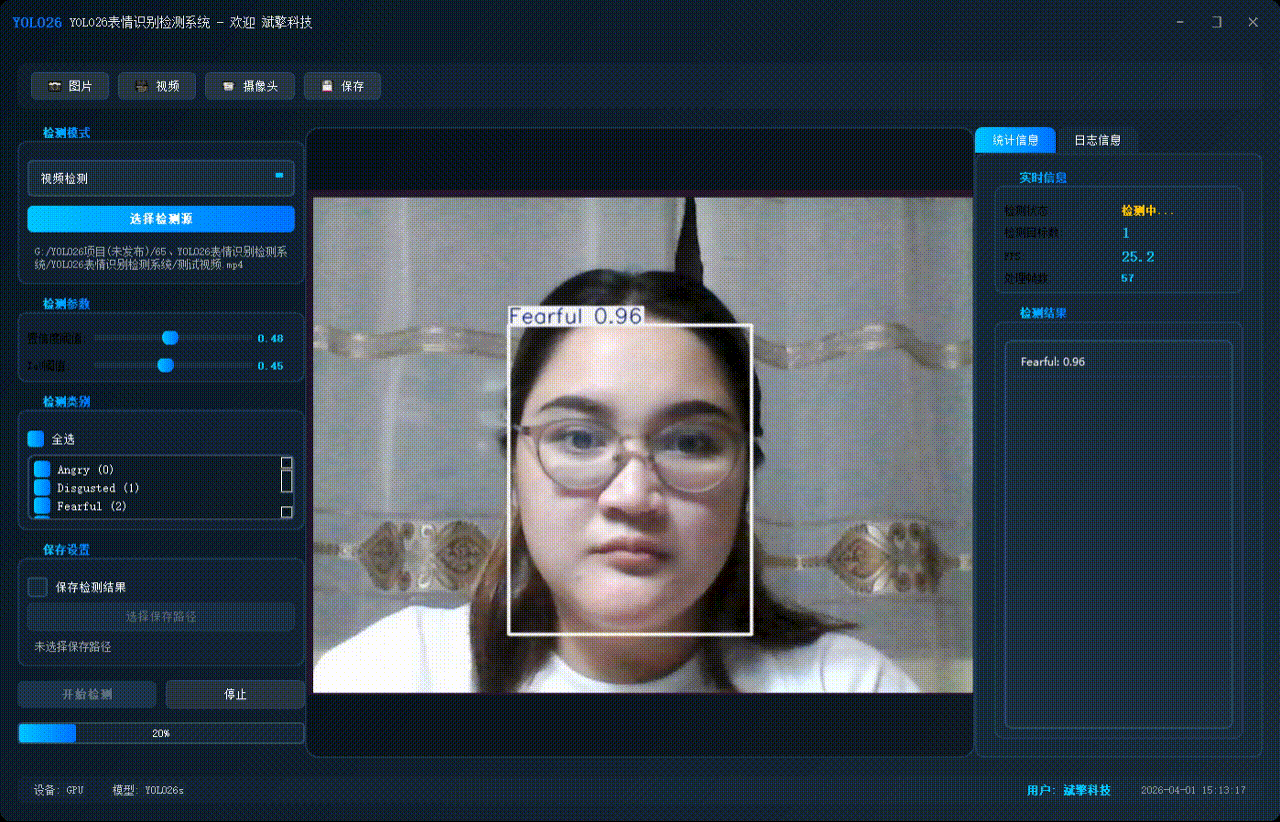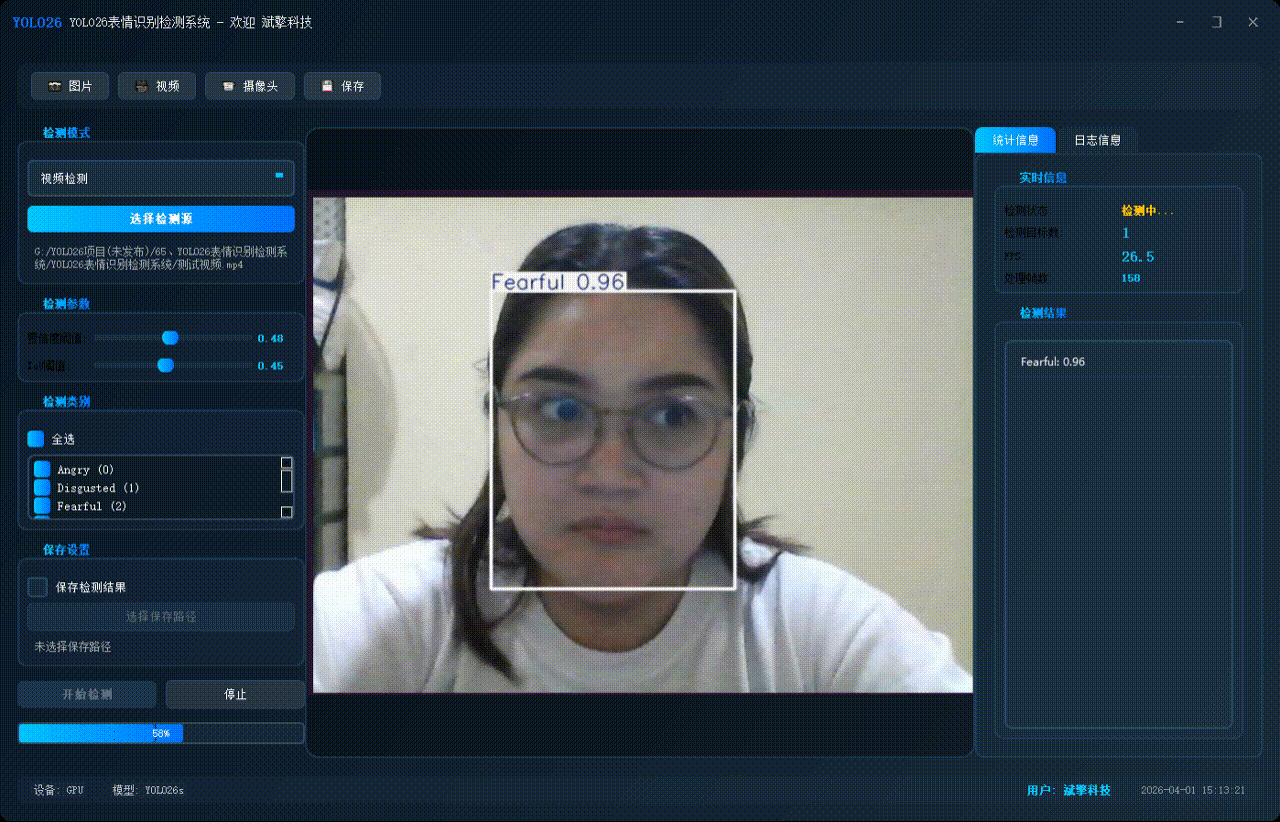
✅ 摄像头实时检测:连接USB 摄像头,实现实时监测。
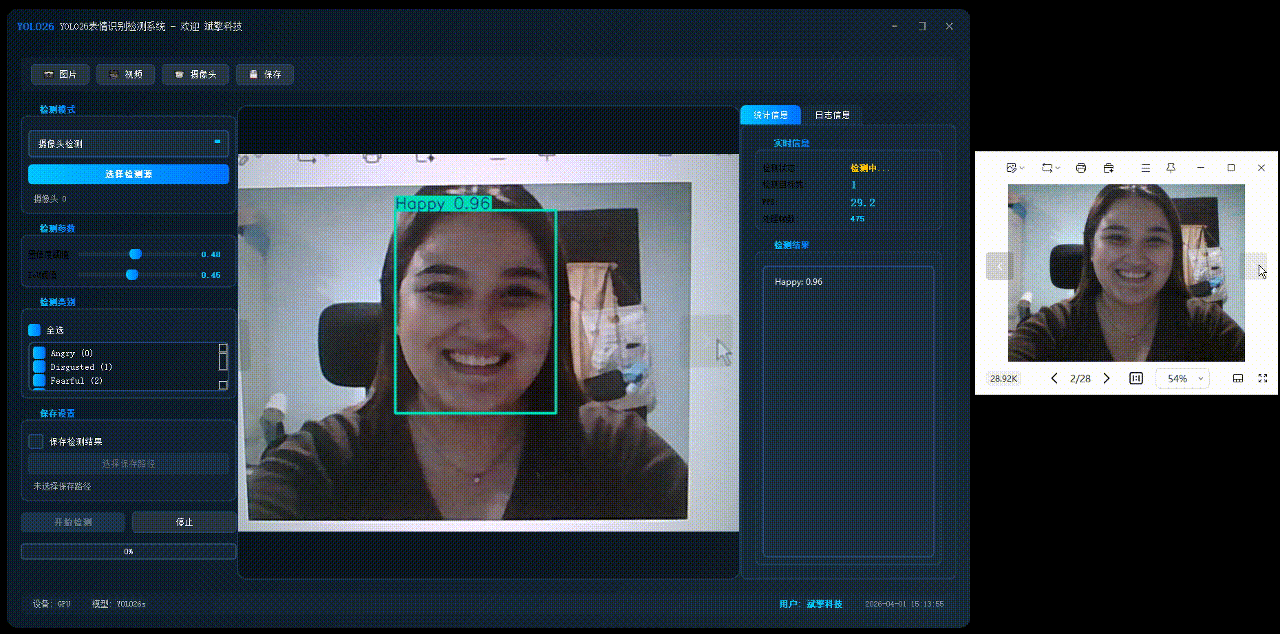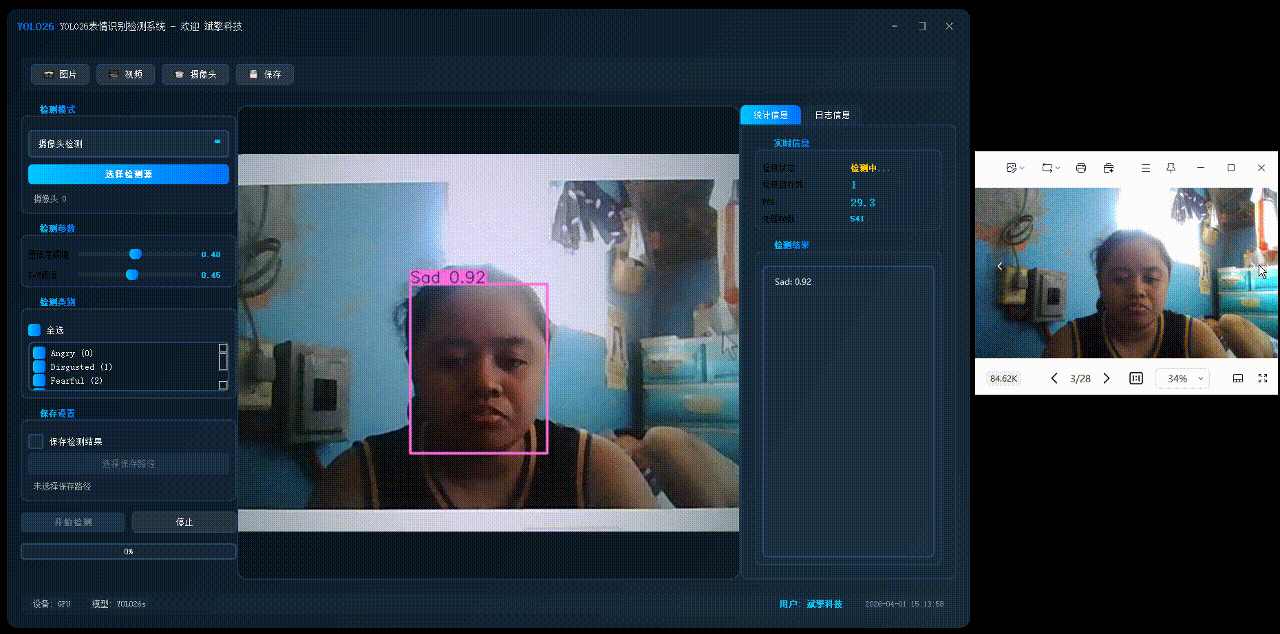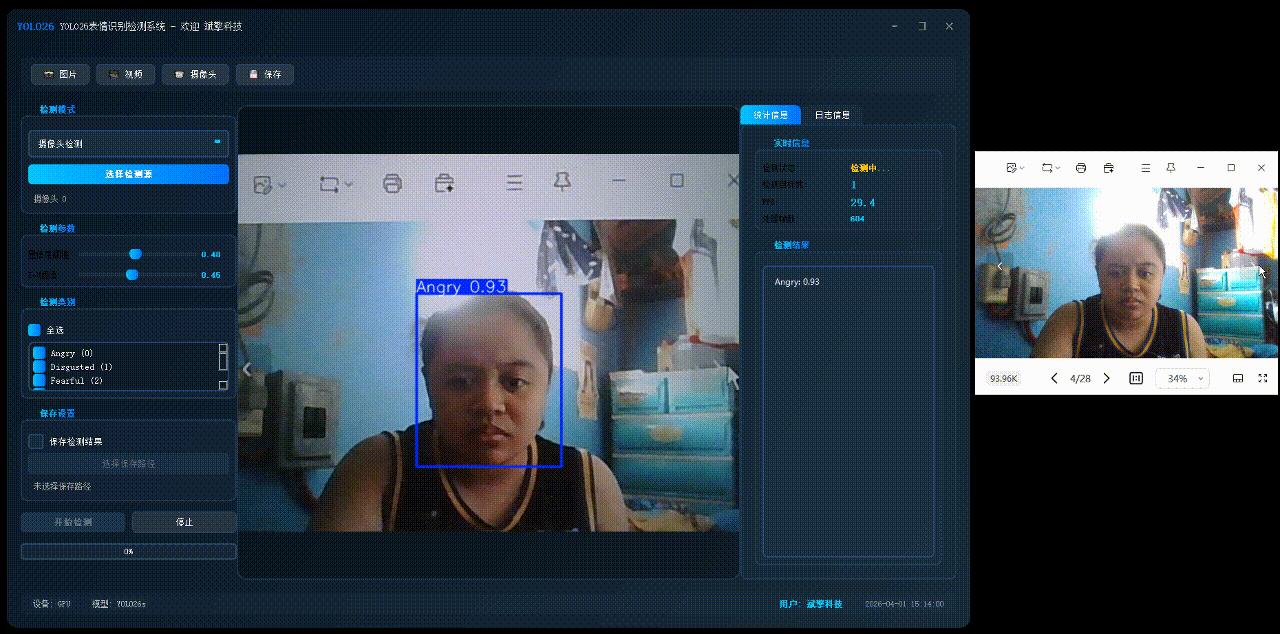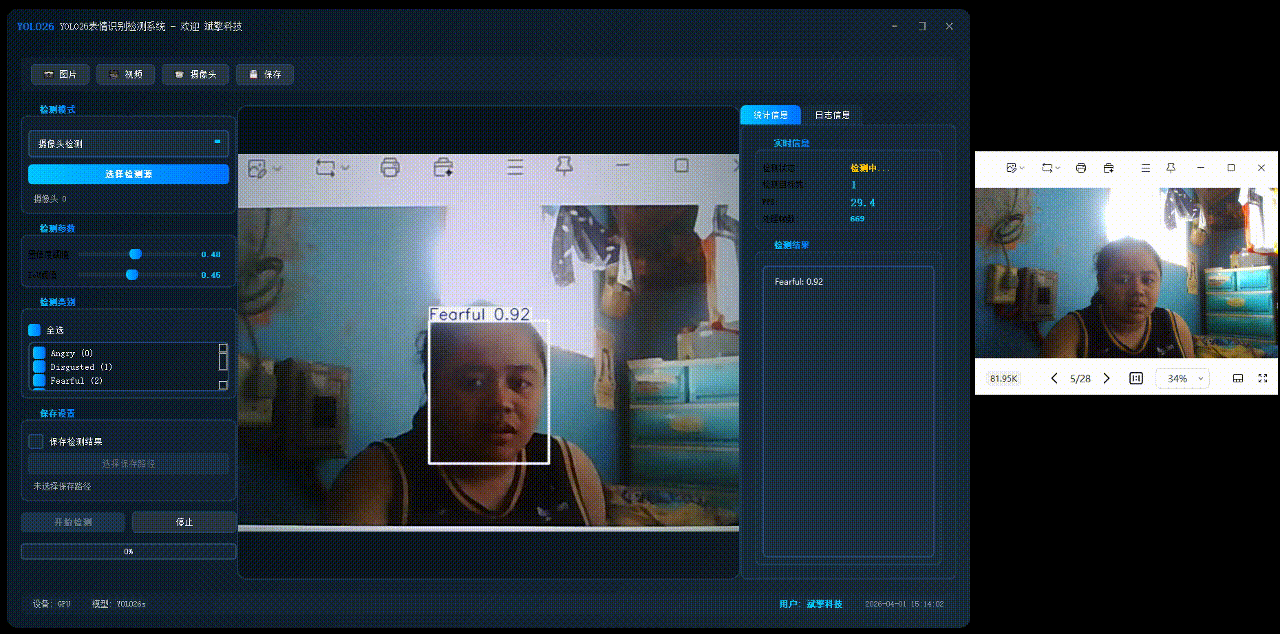
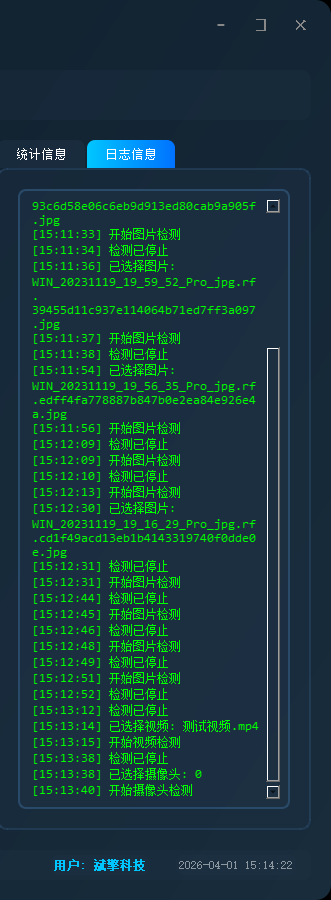
✅日志记录:日志标签页记录操作和错误信息,带时间戳
✅结果保存模块:支持图片/视频/摄像头检测结果保存
1、用户管理模块
| 功能 | 描述 |
|---|---|
| 用户注册 | 用户名、密码、确认密码、邮箱(选填)注册,密码SHA256加密存储 |
| 用户登录 | 用户名密码验证,自动跳转主界面 |
| 用户数据存储 | JSON文件存储用户信息(密码加密、注册时间、邮箱) |
| 登录状态 | 主界面显示当前登录用户名 |
2、界面与交互模块
| 功能 | 描述 |
|---|---|
| 玻璃效果界面 | 半透明毛玻璃背景,圆角边框,现代化视觉风格 |
| 无边框窗口 | 自定义标题栏,支持窗口拖动、最小化、最大化、关闭 |
| 响应式布局 | 主窗口三栏布局(左侧控制区、中央显示区、右侧信息区) |
| 状态栏 | 显示设备信息、模型状态、当前用户、实时时间 |
3、检测源管理模块
| 功能 | 描述 |
|---|---|
| 图片检测 | 支持JPG/JPEG/PNG/BMP格式图片载入 |
| 视频检测 | 支持MP4/AVI/MOV/MKV格式视频载入 |
| 摄像头检测 | 实时调用摄像头(默认ID 0)进行检测 |
| 检测源切换 | 下拉菜单切换三种检测模式,自动更新界面状态 |
4、检测参数配置模块
| 功能 | 描述 |
|---|---|
| 置信度阈值 | 滑动条调节(0-100%,步长1%),实时显示当前值 |
| IoU阈值 | 滑动条调节(0-100%,步长1%),实时显示当前值 |
| 类别选择 | 动态生成检测类别复选框,支持全选/取消全选 |
| 参数同步 | 参数实时同步到检测器核心 |
5、YOLO检测核心模块
| 功能 | 描述 |
|---|---|
| 模型加载 | 加载best.pt模型文件,自动检测GPU可用性,支持CPU/GPU切换 |
| 多模式检测 | 图片检测、视频检测、摄像头实时检测 |
| 检测线程 | 基于QThread的多线程处理,避免界面卡顿 |
| 检测结果 | 返回目标类别、置信度、边界框坐标 |
| FPS计算 | 实时计算处理帧率 |
| 进度反馈 | 视频处理进度条实时更新 |
6、结果显示模块
| 功能 | 描述 |
|---|---|
| 实时画面 | 中央区域显示检测结果图像(带标注框) |
| 统计信息 | 检测状态、目标数量、FPS、处理帧数实时更新 |
| 检测列表 | 右侧列表显示当前帧所有检测到的目标(类别+置信度) |
| 日志记录 | 日志标签页记录操作和错误信息,带时间戳 |
| 占位显示 | 未选择检测源时显示系统LOGO和提示文字 |
7、结果保存模块
| 功能 | 描述 |
|---|---|
| 保存开关 | 复选框控制是否保存检测结果 |
| 路径选择 | 自定义保存路径,支持图片/视频格式自动识别 |
| 自动命名 | 保存文件自动添加时间戳(detection_result_20240101_120000.jpg) |
| 视频保存 | 支持检测结果视频录制(MP4格式) |
| 手动保存 | 工具栏保存按钮可随时保存当前画面 |
| 保存反馈 | 保存成功弹窗提示,日志记录保存路径 |
8、工具栏功能
| 功能 | 描述 |
|---|---|
| 图片按钮 | 快速切换到图片检测模式并打开文件选择器 |
| 视频按钮 | 快速切换到视频检测模式并打开文件选择器 |
| 摄像头按钮 | 快速切换到摄像头检测模式 |
| 保存按钮 | 手动保存当前显示画面 |
9、辅助功能
| 功能 | 描述 |
|---|---|
| 错误处理 | 统一错误弹窗提示,日志记录错误详情 |
| 资源清理 | 检测停止时自动释放摄像头、视频文件、视频写入器资源 |
| 时间显示 | 状态栏实时显示系统时间 |
| 模型状态 | 状态栏显示模型加载状态和当前设备(CPU/GPU) |
10、数据校验模块
| 功能 | 描述 |
|---|---|
| 注册验证 | 用户名长度≥3,密码长度≥6,密码一致性检查,邮箱格式验证 |
| 协议确认 | 注册前需勾选同意用户协议 |
| 文件校验 | 模型文件存在性检查,文件大小验证(≥6MB) |
| 输入非空 | 登录/注册时必填项非空检查 |
引言
随着人工智能与计算机视觉技术的飞速发展,人机交互(HCI)正从传统的键盘鼠标输入向更自然、更智能的情感交互转变。面部表情作为人类传递情感、意图及心理状态最直接的非语言信号,其自动识别技术在心理学研究、驾驶员疲劳监测、智能安防及市场调研等领域具有广泛的应用前景。
传统的表情识别方法多依赖于手工特征提取(如LBP、HOG)结合分类器,但这类方法在复杂背景、光照变化及遮挡情况下鲁棒性较差。近年来,基于深度学习的目标检测算法,特别是YOLO(You Only Look Once)系列,凭借其端到端的检测速度和较高的精度,成为了解决此类问题的主流方案。本研究旨在利用YOLO26算法构建一个高效的表情识别系统,针对七类基础情绪进行训练与评估。通过分析训练损失、精度召回率曲线及混淆矩阵,深入探讨模型在不同情绪类别上的表现差异及其潜在原因,为后续优化提供依据。
背景
1. 面部表情识别的研究意义与挑战
面部表情识别(Facial Expression Recognition, FER)是计算机视觉领域的一个核心课题。根据心理学家Paul Ekman的理论,人类存在七种跨文化通用的基本情绪:愤怒(Angry)、厌恶(Disgusted)、恐惧(Fearful)、高兴(Happy)、中立(Neutral)、悲伤(Sad)和惊讶(Surprised)。自动识别这些情绪不仅要求算法能够精准定位人脸,还需要捕捉面部肌肉的细微运动(如眼角皱纹、嘴角弧度)。然而,实际应用场景面临着巨大的挑战:首先是类内差异性,不同个体在表达同一情绪时的面部形态差异巨大;其次是类间相似性,例如“恐惧”与“惊讶”在眉毛抬高这一特征上高度重合,“愤怒”与“厌恶”在眉眼区域的肌肉收缩也极易混淆。此外,光照不均、头部姿态偏转以及部分遮挡(如口罩、眼镜)都会显著降低识别的准确率。
2. 从传统方法到深度学习的演进
早期的FER系统通常分为两个阶段:首先使用Viola-Jones等算法进行人脸检测,然后提取几何特征或纹理特征输入SVM等分类器。这类方法计算量小,但泛化能力弱。随着卷积神经网络(CNN)的兴起,基于深度学习的方法展现出了压倒性的优势。CNN能够自动学习从低级边缘到高级语义特征的层次化表达,极大地提升了识别精度。
3. 基于YOLO的目标检测范式
在表情识别任务中,除了分类,定位也是关键一环。YOLO作为单阶段(One-Stage)目标检测算法的代表,将检测问题转化为回归问题,在保持高精度的同时实现了实时检测。与两阶段算法(如Faster R-CNN)相比,YOLO直接在全图范围内预测边界框和类别概率,具有更快的推理速度,非常适合对实时性要求较高的应用场景。
数据集介绍
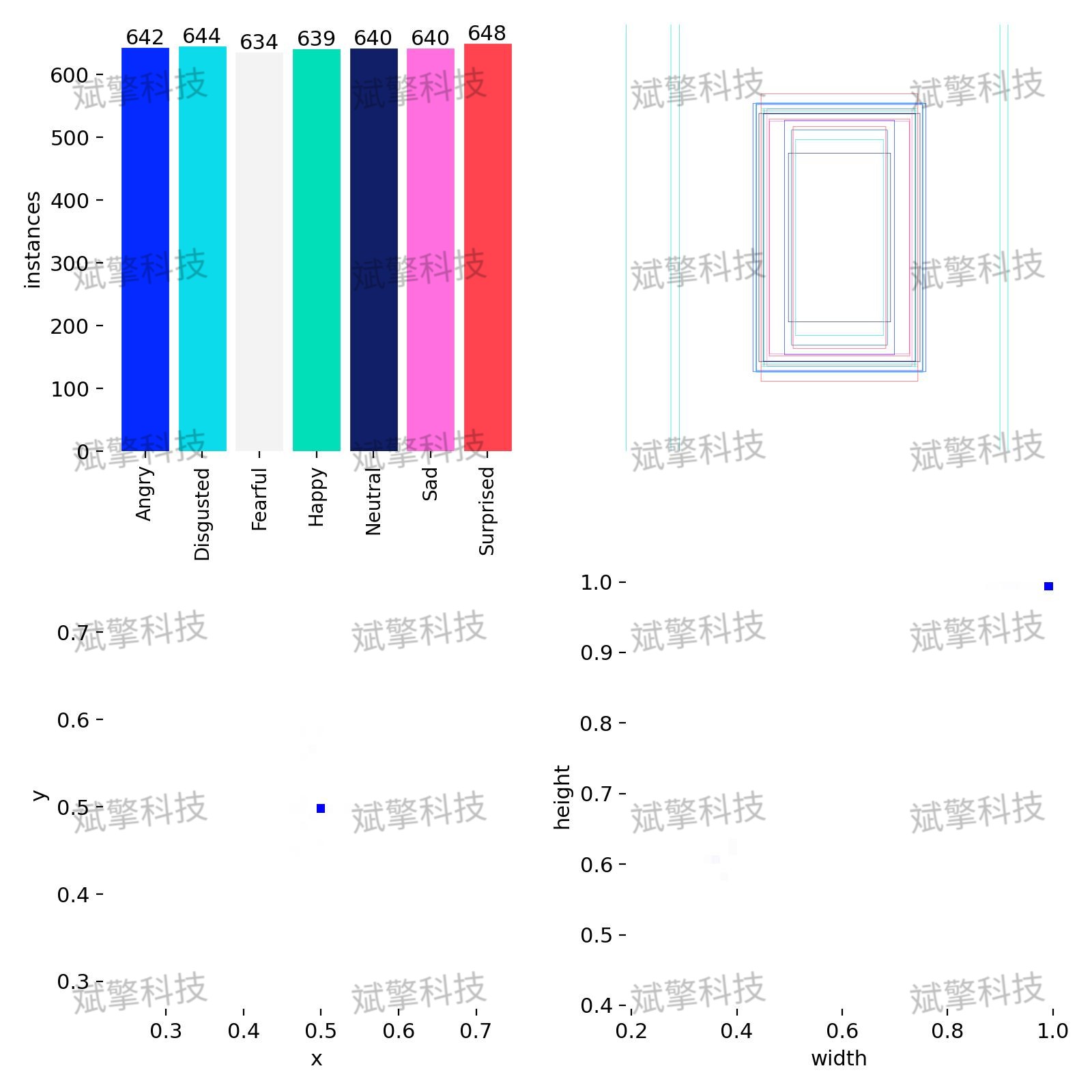
本研究使用的数据集经过精心清洗与标注,旨在覆盖日常生活中常见的七种基础情绪表达。数据集详细配置如下:
-
类别定义(nc=7):
- Angry(愤怒)
- Disgusted(厌恶)
- Fearful(恐惧)
- Happy(高兴)
- Neutral(中立/平静)
- Sad(悲伤)
- Surprised(惊讶)
-
数据划分与规模:
数据集共包含 5600 张左右的图像,按照机器学习的标准流程划分为三个部分,以确保模型评估的客观性:- 训练集(Training Set):包含 4483 张图像。
- 验证集(Validation Set):包含 550 张图像。
- 测试集(Test Set):包含 566 张图像。


训练结果
整体性能概览
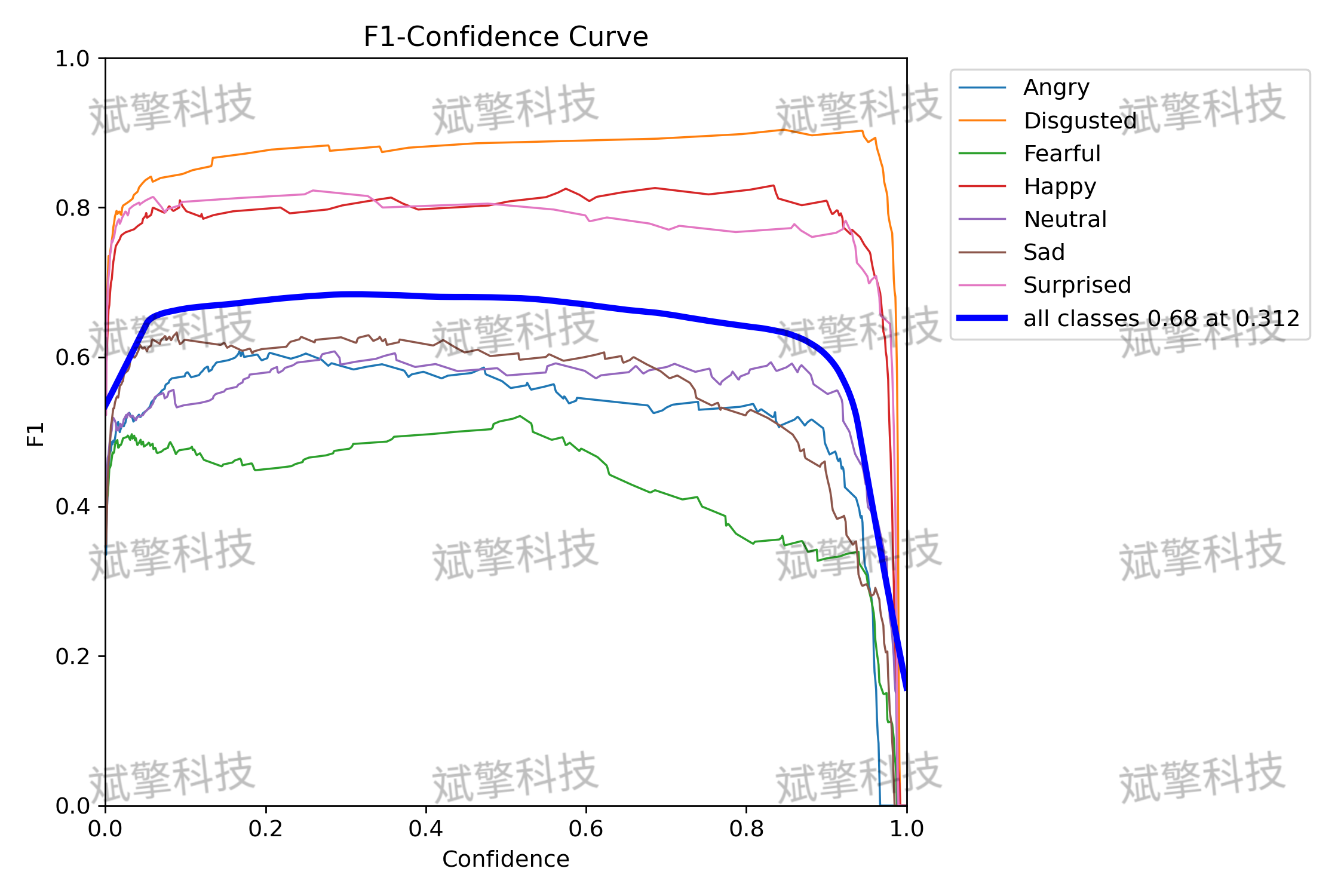
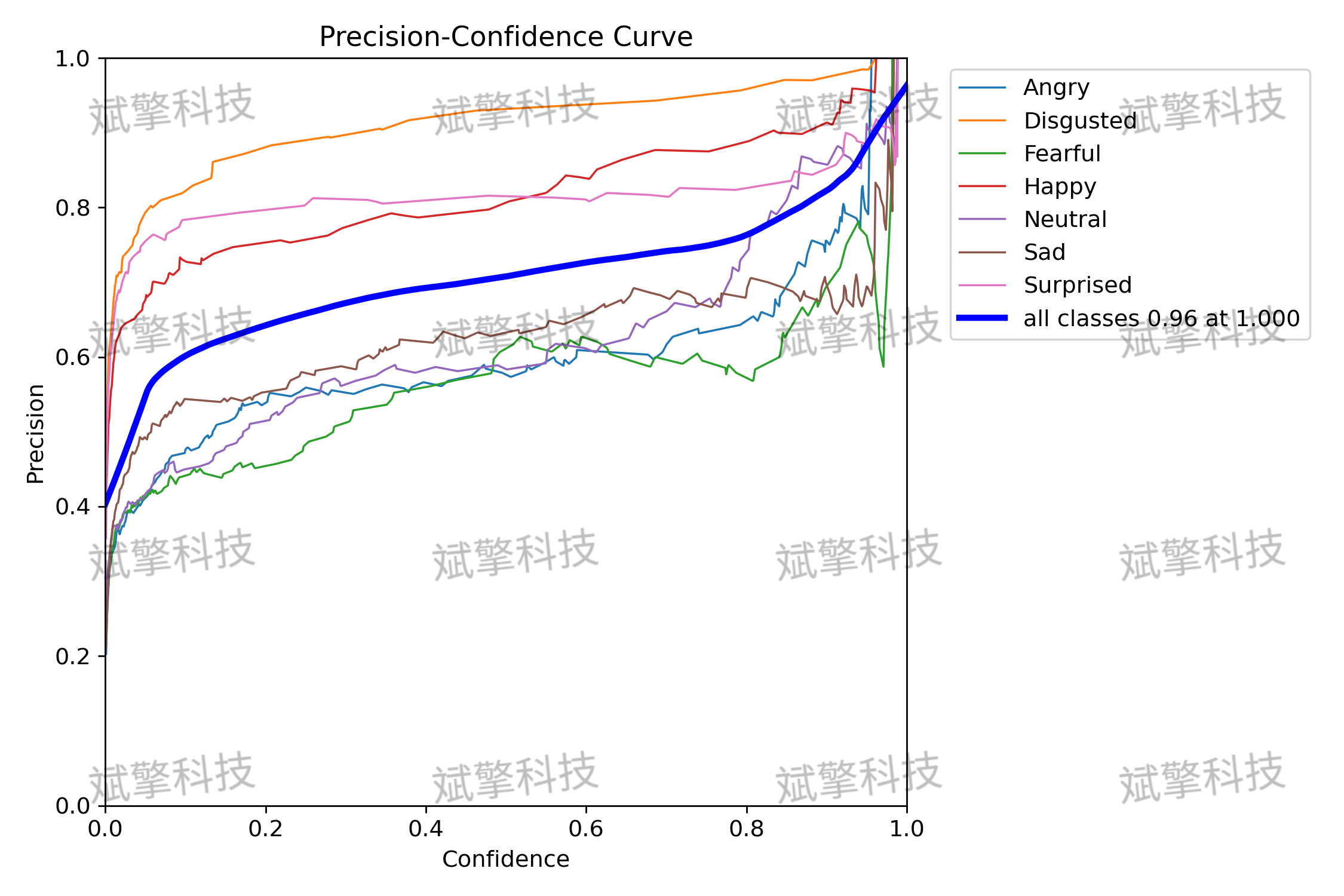
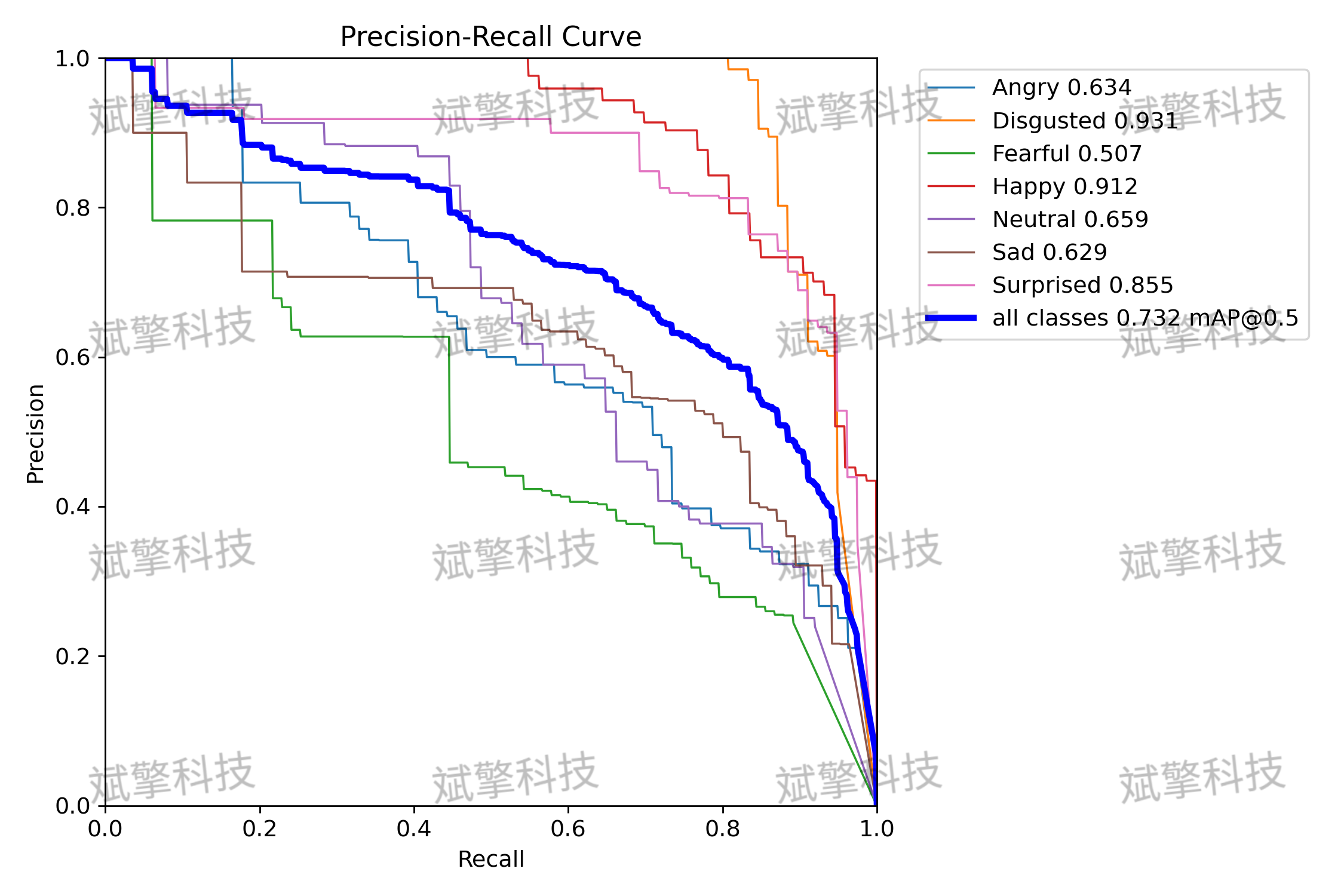
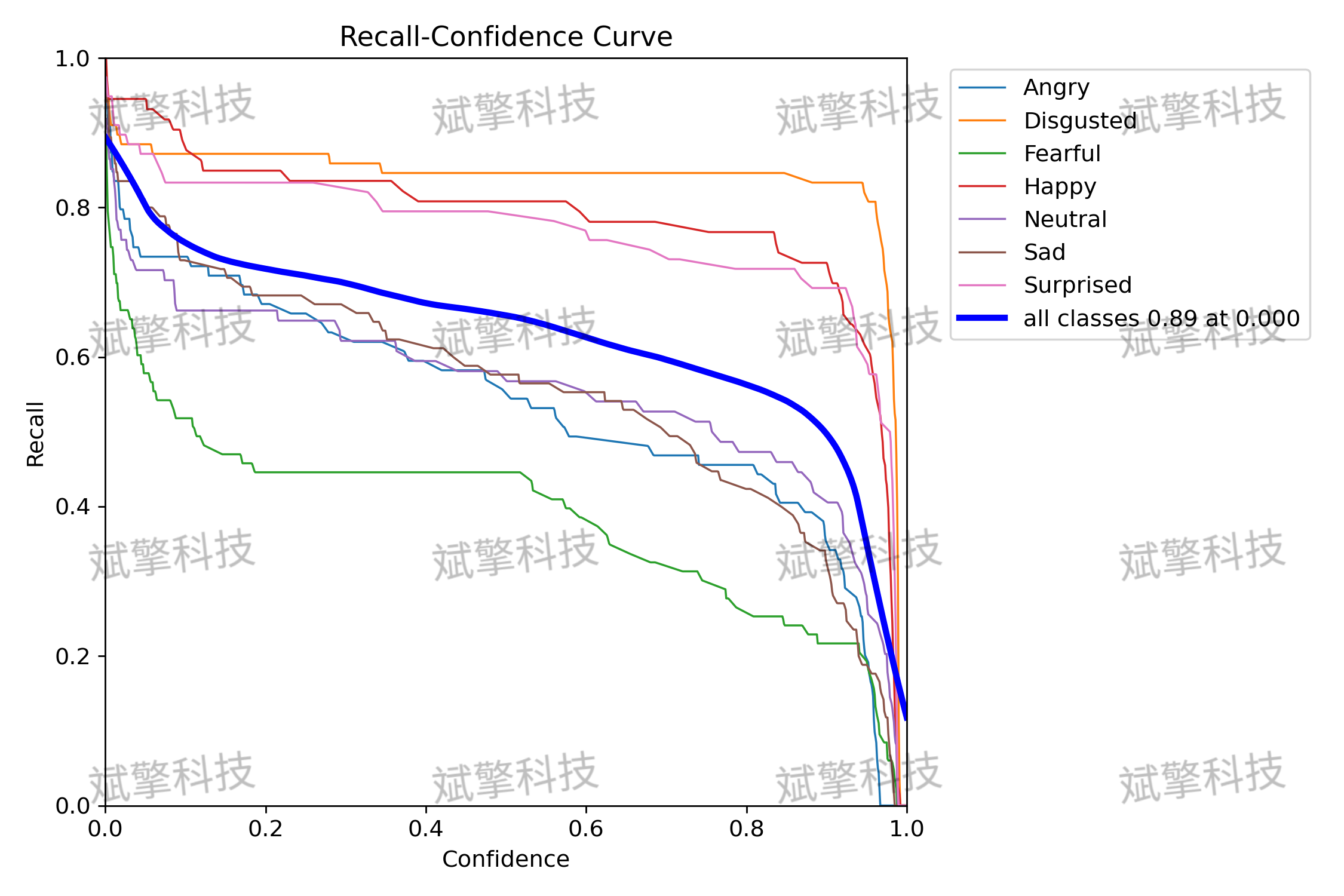
- 平均精度 (mAP): 模型在IoU阈值为0.5时的mAP达到 73.2%,在更严格的IoU阈值0.5:0.95下为 67%。这表明模型在定位和分类表情方面具有较强的综合能力。
训练过程分析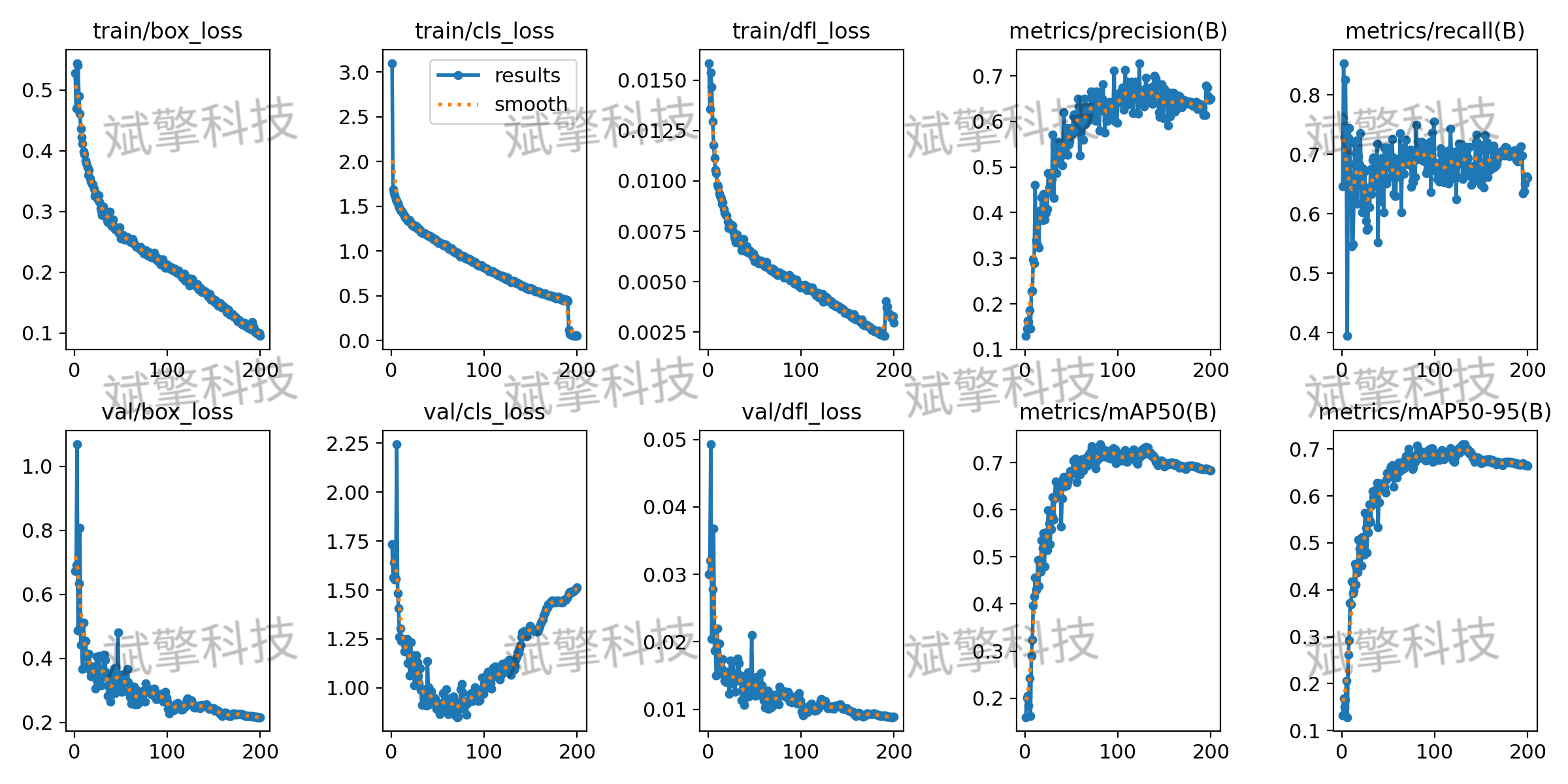
- 损失函数 (Loss): 训练集的损失(box_loss, cls_loss, dfl_loss)随着训练轮次的增加而平滑下降,表明模型正在有效学习。
各类别性能详解
模型在不同表情类别上的表现差异显著:
- 表现优异的类别:
- 厌恶 (Disgusted): mAP高达 93.1%,是所有类别中表现最好的。其精确率-召回率曲线下的面积最大,说明模型对此类别的识别非常准确和稳定。
- 高兴 (Happy): mAP为 91.2%,同样表现出色。
- 惊讶 (Surprised): mAP为 85.5%,性能良好。
- 表现中等的类别:
- 生气 (Angry): mAP为 63.4%。
- 中立 (Neutral): mAP为 65.9%。
- 悲伤 (Sad): mAP为 62.9%。
这些类别的性能尚可,但有明显的提升空间。
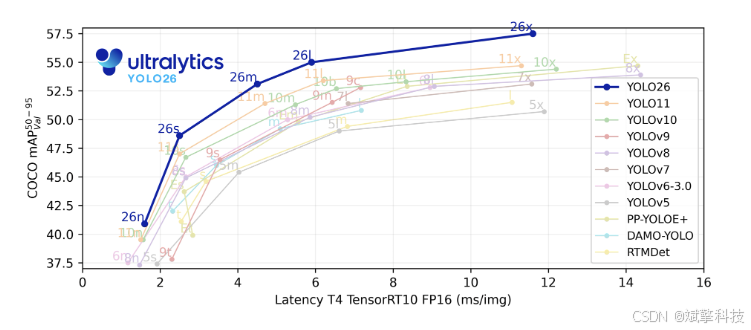
Ultralytics YOLO26
概述
Ultralytics YOLO26 是 YOLO 系列实时对象检测器的最新演进,从头开始专为边缘和低功耗设备而设计。它引入了简化的设计,消除了不必要的复杂性,同时集成了有针对性的创新,以实现更快、更轻、更易于访问的部署。
YOLO26 的架构遵循三个核心原则:
- 简洁性: YOLO26是一个原生的端到端模型,直接生成预测结果,无需非极大值抑制(NMS)。通过消除这一后处理步骤,推理变得更快、更轻量,并且更容易部署到实际系统中。这种突破性方法最初由清华大学的王傲在YOLOv10中开创,并在YOLO26中得到了进一步发展。
- 部署效率: 端到端设计消除了管道的整个阶段,从而大大简化了集成,减少了延迟,并使部署在各种环境中更加稳健。
- 训练创新:YOLO26 引入了MuSGD 优化器,它是SGD 和MUON的混合体——灵感来源于 Moonshot AI 在 LLM 训练中Kimi K2的突破。该优化器带来了增强的稳定性和更快的收敛,将语言模型中的优化进展转移到计算机视觉领域。
- 任务特定优化:YOLO26 针对专业任务引入了有针对性的改进,包括用于 Segmentation 的语义分割损失和多尺度原型模块,用于高精度 姿势估计 的残差对数似然估计 (RLE),以及通过角度损失优化解码以解决 旋转框检测 中的边界问题。
这些创新共同提供了一个模型系列,该模型系列在小对象上实现了更高的精度,提供了无缝部署,并且在 CPU 上的运行速度提高了 43% — 使 YOLO26 成为迄今为止资源受限环境中最实用和可部署的 YOLO 模型之一。
主要功能
-
DFL 移除
分布式焦点损失(DFL)模块虽然有效,但常常使导出复杂化并限制了硬件兼容性。YOLO26 完全移除了 DFL,简化了推理过程,并拓宽了对边缘和低功耗设备的支持。 -
端到端无NMS推理
与依赖NMS作为独立后处理步骤的传统检测器不同,YOLO26是原生端到端的。预测结果直接生成,减少了延迟,并使集成到生产系统更快、更轻量、更可靠。 -
ProgLoss + STAL
改进的损失函数提高了检测精度,在小目标识别方面有显著改进,这是物联网、机器人、航空影像和其他边缘应用的关键要求。 -
MuSGD Optimizer
一种新型混合优化器,结合了SGD和Muon。灵感来自 Moonshot AI 的Kimi K2,MuSGD 将 LLM 训练中的先进优化方法引入计算机视觉,从而实现更稳定的训练和更快的收敛。 -
CPU推理速度提升高达43%
YOLO26专为边缘计算优化,提供显著更快的CPU推理,确保在没有GPU的设备上实现实时性能。 -
实例分割增强
引入语义分割损失以改善模型收敛,以及升级的原型模块,该模块利用多尺度信息以获得卓越的掩膜质量。 -
精确姿势估计
集成残差对数似然估计(RLE),以实现更精确的关键点定位,并优化解码过程以提高推理速度。 -
优化旋转框检测解码
引入专门的角度损失以提高方形物体的检测精度,并优化旋转框检测解码以解决边界不连续性问题。
常用标注工具
假设您现在准备好进行标注。有几种开源工具可以帮助简化数据标注流程。以下是一些有用的开放标注工具:
Label Studio:一个灵活的工具,支持各种标注任务,并包含用于管理项目和质量控制的功能。 CVAT:一个强大的工具,支持各种标注格式和可定制的工作流程,使其适用于复杂的项目。 Labelme:一个简单易用的工具,可以快速标注带有多边形的图像,非常适合简单的任务。 LabelImg: 一款易于使用的图形图像标注工具,特别适合以 YOLO 格式创建边界框标注。
这些开源工具经济实惠,并提供一系列功能来满足不同的标注需求。
界面核心代码:

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐
 2
2 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)