深度学习(期末重点版)
一、张量
什么是张量?
答:n 维数组;张量表示由一个数值组成的数组,这个数组可能有多个维度
具有一个轴的张量对应数学上的向量(vector)
具有两个轴的张量对应数学上的矩阵(matrix)
x = torch.arange(12)
返回:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
x.shape
返回:torch.Size([12])
x.numel()
意思:获取张量中有多少个元素
返回:12
X = x.reshape(3, 4)
意思:改变一个张量的形状而不改变元素数量和元素值
返回:tensor([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]])
张量运算:对位相加减乘除
张量拼接(cat)
dim=0 是垂直拼(行数增加),dim=1 是水平拼(列数增加)
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)
返回:
(tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 4., 3.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]]),
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
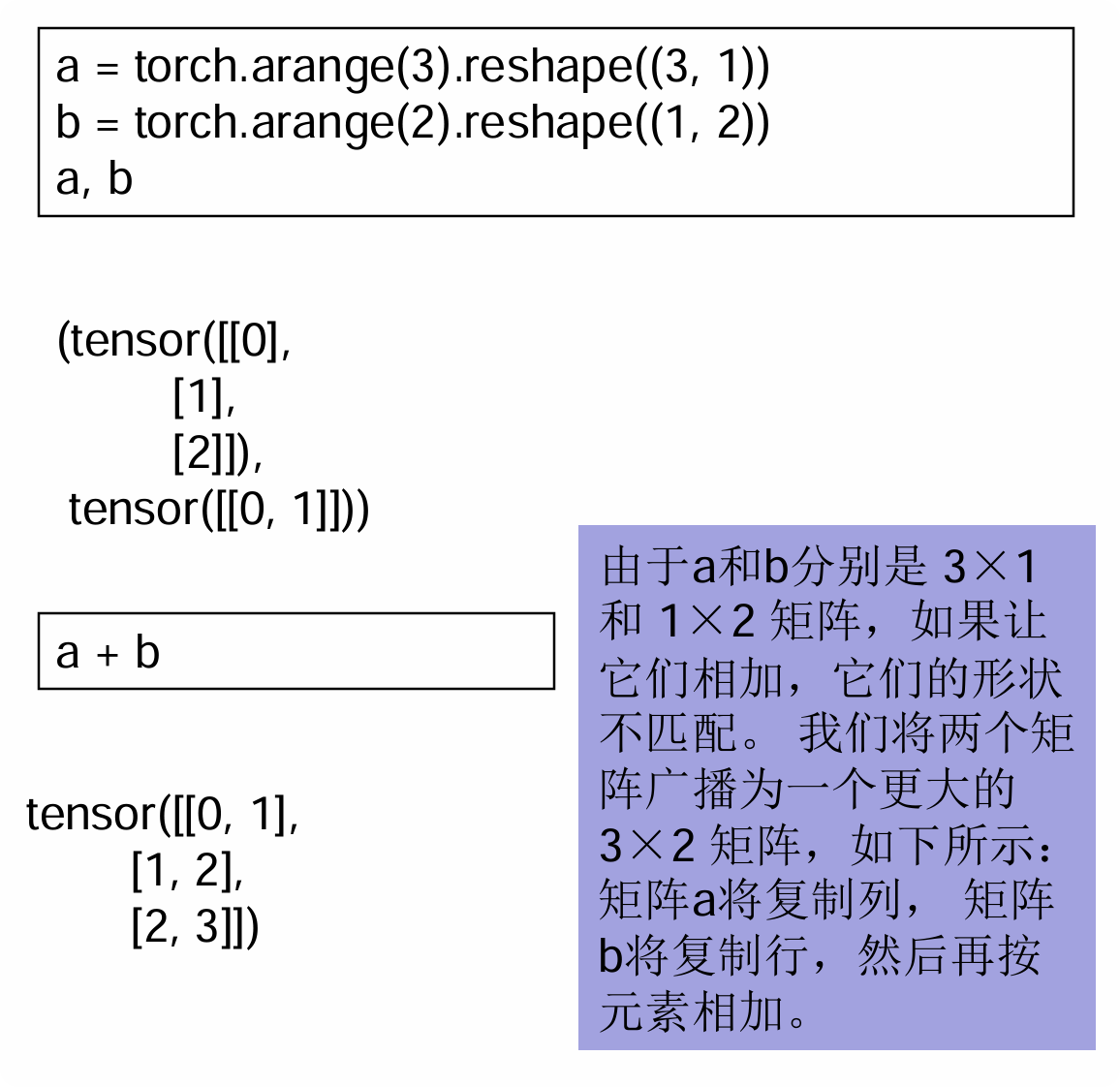
广播机制(重点)
当两个张量形状不同时,如果它们在某些维度长度是1,PyTorch 会自动“复制”这个维度,让形状匹配后再运算
索引和切片(像数组一样取数):
-
X[1, 2]取第1行第2列的元素。 -
X[0:2, :]取前两行、所有列。 -
也可以直接赋值:
X[1,2] = 9。
数据预处理:
-
读取数据:用
pandas.read_csv()读取 CSV 文件。 -
处理缺失值(NaN):
-
数值列(如房价):用该列的平均值填充空缺。
-
类别列(如巷子类型:Pave 或 NaN):用 独热编码(one-hot)。把一列变成两列:
Alley_Pave和Alley_nan。是 Pave 就 (1,0),是 NaN 就 (0,1)。把文字变成了数字。
-
-
转换成张量:用
torch.tensor()把 pandas 表格转成 PyTorch 张量,准备喂给模型。
“NaN” 项代表缺失值
线性代数:
-
标量:就是一个数(0维张量)。比如学习率
0.01,温度36.5℃。 -
向量:一列数(1维张量)。比如一个人的特征:
[年龄, 收入, 贷款次数]。-
通过下标取值,比如
x[3]。 -
长度(维度)用
len(x)或x.shape获取。
-
-
矩阵:一个表格(2维张量)。比如一批人的特征,每个人一行,每个特征一列。
-
转置(
.T)就是行列互换。对称矩阵就是转置等于自己。
-
-
张量(高阶):超过2维的统称张量。彩色图片就是 3维(高×宽×通道)。
降维(求和与平均):
-
sum()把所有元素加成一个数。 -
指定
axis=0按列求和(每一列加起来,行消失)。 -
指定
axis=1按行求和(每一行加起来,列消失)。 -
用
keepdims=True可以保持维度不变,方便后续广播除法(比如每行除以该行的总和)。
点积(对应位置相乘再求和):

实际意义:点积表示加权平均
矩阵-向量积(矩阵 × 向量 → 向量):
-
矩阵的每一行和向量做点积,结果是一个新向量。
-
意义:神经网络的一层计算就是
权重矩阵 × 输入向量 + 偏置
矩阵-矩阵乘法(矩阵 × 矩阵 → 矩阵):
-
其实就是多次矩阵-向量积。左矩阵的每一行,去和右矩阵的每一列做点积,拼成新矩阵。
-
深度学习里的全连接层、卷积层,底层都是这种乘法。
总结:
| 操作 | 函数 | 说明 |
|---|---|---|
| 创建全0 | torch.zeros((2,3)) |
2行3列全0 |
| 创建全1 | torch.ones((2,3)) |
2行3列全1 |
| 创建随机数 | torch.randn(3,4) |
标准正态分布随机数 |
| 手动创建 | torch.tensor([[2,1],[1,2]]) |
用列表直接指定 |
| 改变形状 | x.reshape(3,4) |
总量不变,重新排列;可用 -1 自动算维度 |
| 按元素运算 | + - * / ** |
对应位置相加、乘等 |
| 指数运算 | torch.exp(x) |
计算 e^x |
| 连接 | torch.cat((X,Y), dim=0) |
dim=0上下拼,dim=1左右拼 |
| 逻辑比较 | X == Y |
返回 True/False 张量 |
| 求和 | X.sum() |
所有元素加总 |
广播机制:两个张量形状不同时,如果某维度长度为1,会自动复制该维度,让形状匹配后再运算。
a = torch.arange(3).reshape((3,1)) # 3行1列 b = torch.arange(2).reshape((1,2)) # 1行2列 a + b # 结果 3行2列 # a复制列 → 变3×2,b复制行 → 变3×2,再相加
| 写法 | 含义 |
|---|---|
X[1,2] |
第1行第2列的元素 |
X[-1] |
最后一行 |
X[1:3] |
第1行到第2行(不含第3) |
X[0:2, :] |
前两行,所有列 |
X[1,2] = 9 |
给指定位置赋值 |
X[0:2, :] = 12 |
前两行所有列全部赋值为12 |
数据预处理核心流程:
-
pd.read_csv()读取原始数据 -
处理缺失值:
-
数值列:用均值填充
fillna(inputs.mean()) -
类别列:用独热编码
pd.get_dummies(dummy_na=True),把文字变数字
-
-
torch.tensor(inputs.values)转成张量
| 概念 | 定义 | 代码 |
|---|---|---|
| 标量 | 单个数字(0维) | torch.tensor(3.0) |
| 向量 | 一维数组 | x = torch.arange(4) |
| 矩阵 | 二维数组 | A = torch.arange(20).reshape(5,4) |
| 转置 | 行列互换 | A.T |
| 对称矩阵 | A == A.T |
如 [[1,2],[2,1]] |
| 操作 | 代码 | 结果形状变化 |
|---|---|---|
| 全部求和 | A.sum() |
变成一个标量 |
| 按列求和(axis=0) | A.sum(axis=0) |
行消失,剩一列 |
| 按行求和(axis=1) | A.sum(axis=1) |
列消失,剩一行 |
| 保持维度 | A.sum(axis=1, keepdims=True) |
形状不变(比如5行变5行1列) |
| 累加求和 | A.cumsum(axis=0) |
形状不变,每个位置变成该位置之前所有值的累加 |
| 运算 | 公式 | 代码 | 形状要求 |
|---|---|---|---|
| 点积(向量×向量) | Σ x_i * y_i |
torch.dot(x,y) |
长度相同,结果是标量 |
| 矩阵-向量积(矩阵×向量) | A的每一行和x做点积 | torch.mv(A,x) |
A列数 = x长度,结果是向量 |
| 矩阵-矩阵乘法 | 左行×右列,点积 | torch.mm(A,B) |
A列数 = B行数 |
-
点积 = 加权和(如特征×权重)
-
矩阵-向量积 = 神经网络一层的计算(权重×输入)
二、线性回归
最简单的神经网络——线性神经网络
-
线性回归 → 用来预测一个数值(比如房价)
-
softmax回归 → 用来分类(比如判断一张图是猫、鸡还是狗)


怎么衡量预测得好不好?→ 损失函数

平方损失 = ½ × (真实值 - 预测值)²
整个训练集上的平均损失:
总损失 = (1/2n) × Σ(真实值 - 预测值)²
训练的目标就是找到一组 (w, b),让这个总损失最小。
怎么找到最优的 w 和 b?→ 两种方法
1、解析解(只适用于线性回归)

2、随机梯度下降(重点)
步骤:
-
随机初始化
w和b(比如随机给个初始值) -
每次从训练数据中随机抽一小批(叫小批量随机梯度下降)
-
计算这批样本的损失,并求出梯度(也就是损失对w和b的偏导)
-
让 w 和 b 沿着梯度相反的方向走一小步(减去 梯度 × 学习率)
-
重复第2~4步,直到损失不再下降
关键超参数(需要手动设定的):
-
学习率 η:每一步走多大(步子太大容易跳过最优解,步子太小训练太慢)
-
批量大小 |B|:每次抽多少个样本一起算
这两个值不是学出来的,是你自己调的,所以叫超参数
调参是选择超参数的过程
线性回归 = 一个单层神经网络
把线性回归画成神经网络就是:
-
输入层:每个特征是一个输入节点
-
输出层:一个输出节点
-
没有隐藏层
所以它叫“单层神经网络”。
三、Softmax回归
| 回归 | 分类 | |
|---|---|---|
| 输出 | 一个连续数值 | 一个离散类别 |
| 例子 | 房价预测(输出多少钱) | 手写数字识别(输出0~9中的某一个) |
| 损失函数 | 均方损失(L2 Loss) | 交叉熵损失 |
| 线性回归 | softmax回归 | |
|---|---|---|
| 输出 | 一个数值 | 多个类别的概率 |
| 典型场景 | 预测房价 | 图片分类 |
| 损失函数 | 平方损失 | 交叉熵损失 |
核心思想:输入一张图片(像素值作为特征),输出它属于每个类别的概率,概率最高的那个就是预测结果
独热编码(one-hot)
把类别标签变成向量:
-
猫 =
[1, 0, 0] -
鸡 =
[0, 1, 0] -
狗 =
[0, 0, 1]
softmax运算(把任意数变成概率)
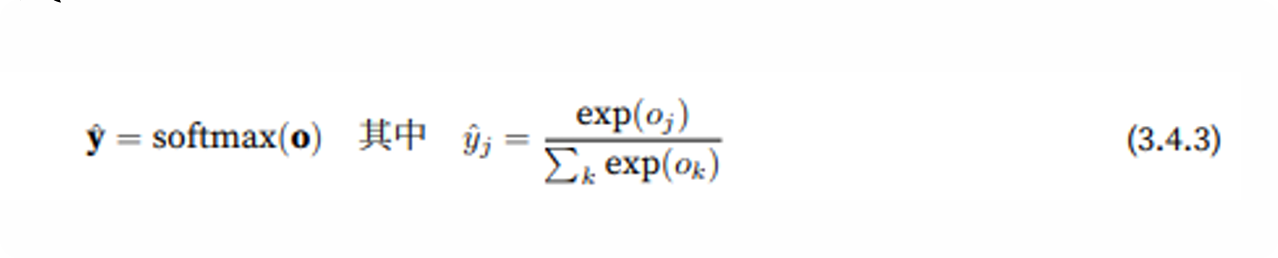
-
先取指数(保证正数)
-
再除以总和(保证加起来等于1)
-
结果就是概率
Softmax回归为线性模型
损失函数:交叉熵损失(衡量两个概率分布的差距)—— 分类问题最常用的损失之一

含义:
损失 = -log(预测正确的类别的概率)
-
预测越准(概率越接近1),损失越接近0
-
预测越离谱(概率接近0),损失趋于无穷大
三种损失函数
| 损失函数 | 公式 | 特点 |
|---|---|---|
| L2 Loss(均方损失) | ½·(y - y')² |
对离群点敏感,梯度大 |
| L1 Loss(绝对值损失) | |y - y'| |
对离群点鲁棒,但在0处不可导 |
| 交叉熵损失 | -Σy_i·log(ŷ_i) |
分类问题标准选择 |
分类问题用交叉熵,回归问题用L2或L1
Softmax及其导数:
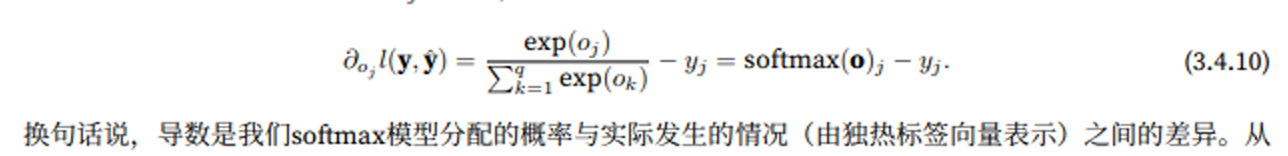
大白话:梯度 = 预测概率 - 真实标签。也就是说,模型预测多了就减,预测少了就加,和线性回归的梯度形式一样(预测值 - 真实值)。
| 概念 | 公式 |
|---|---|
| 未归一化输出 | o = X·W + b |
| Softmax | p_j = exp(o_j) / Σexp(o_k) |
| 交叉熵损失(单个样本) | l = -log(p_正确类别) |
| 交叉熵损失(批量) | L = -(1/n)·Σlog(p_正确类别) |
| 梯度 | ∂L/∂o = softmax(o) - y |
总结:
线性回归:
| 形式 | 公式 |
|---|---|
| 单个样本(标量形式) | ŷ = w₁x₁ + w₂x₂ + ... + w_d·x_d + b |
| 单个样本(向量形式) | ŷ = <w, x> + b |
| 整批样本(矩阵形式) | ŷ = X·w + b(X是 n×d 矩阵,每行一个样本) |
损失函数(平方损失)
l(ŷ, y) = ½ × (ŷ - y)²
即:平方损失 = ½ × (真实值 - 预测值)²
整个训练集上的平均损失:
L(w,b) = (1/2n) × Σ(ŷⁱ - yⁱ)²
训练目标:最小化损失函数
求解方法:
| 方法 | 公式/步骤 | 适用场景 |
|---|---|---|
| 解析解(公式法) | w* = (XᵀX)⁻¹Xᵀy |
仅限线性回归,一步算出最优解 |
| 随机梯度下降(SGD) | 每步:w ← w - η × (1/|B|) × Σ梯度 |
所有模型通用,深度学习核心算法 |
随机梯度下降的超参数:
-
学习率 η:每一步走多大(太大跳过最优解,太小训练太慢)
-
批量大小 |B|:每次抽多少个样本一起算
随机梯度下降的更新
w ← w - (η/|B|) · Σ xⁱ · (ŷⁱ - yⁱ)
b ← b - (η/|B|) · Σ (ŷⁱ - yⁱ)
本质:沿着让损失下降的方向,微调 w 和 b
Softmax回归:
| 线性回归 | Softmax回归 | |
|---|---|---|
| 输出 | 一个连续数值 | 多个类别的概率 |
| 典型场景 | 房价预测 | 图片分类(猫/鸡/狗) |
| 损失函数 | 平方损失 | 交叉熵损失 |
| 输出激活 | 无(直接输出) | softmax(转成概率) |
Softmax公式:
作用:把任意数值(可正可负、和不为1)转换成合法的概率分布
交叉熵损失(分类问题的标准损失)
l = -log(预测正确的类别的概率)
梯度:
∂损失/∂o_j = softmax(o)_j - y_j
梯度 = 预测概率 − 真实标签(独热编码)

| 名称 | 公式 |
|---|---|
| 线性回归模型 | ŷ = X·w + b |
| 平方损失 | l = ½·(ŷ - y)² |
| 解析解 | w* = (XᵀX)⁻¹Xᵀy |
| SGD更新 | w ← w - (η/|B|)·Σ∇L |
| Softmax | p_j = exp(o_j) / Σexp(o_k) |
| 交叉熵损失 | l = -Σ y_j·log(ŷ_j) |
| 交叉熵的梯度 | ∇ = softmax(o) - y |
概念:
分类问题的输出:输出 i 为预测为 i 的置信度
使用 softmax 来得到每个类的预测置信度
使用交叉熵来衡量预测和标号的区别
四、感知机
单层感知机
二分类模型,输出只有两个值:+1 或 -1(或者 1 或 0)

| 模型 | 输出类型 | 典型场景 |
|---|---|---|
| 线性回归 | 连续实数 | 预测房价 |
| Softmax回归 | 概率分布(多类) | 图像分类 |
| 感知机 | +1/-1(二分类) | 垃圾邮件判断 |
感知机的训练算法:

-
拿一个样本,算一下预测对不对
-
如果分错了,就把权重往“正确方向”调一点点
-
一直重复,直到所有样本都分对
损失函数是 max(0, -y·<w,x>)(也就是“分对了损失为0,分错了损失为正”)
收敛定理
如果数据是线性可分的(能用一条直线分开),感知机保证在有限步内找到分类线
重点:感知机不能解决异或问题(XOR)
原因:XOR的四个点在对角线上,无法用一条直线分开(线性不可分)。感知机只能画直线,所以永远搞不定
多层感知机(MLP)
如何解决异或问题?
答:加一个单层隐藏层
核心思想:单层感知机只能画一条直线,但如果先做一次变换再分类,就能处理非线性问题。
流程:输入 x → 隐藏层(变换)→ 输出层(分类)
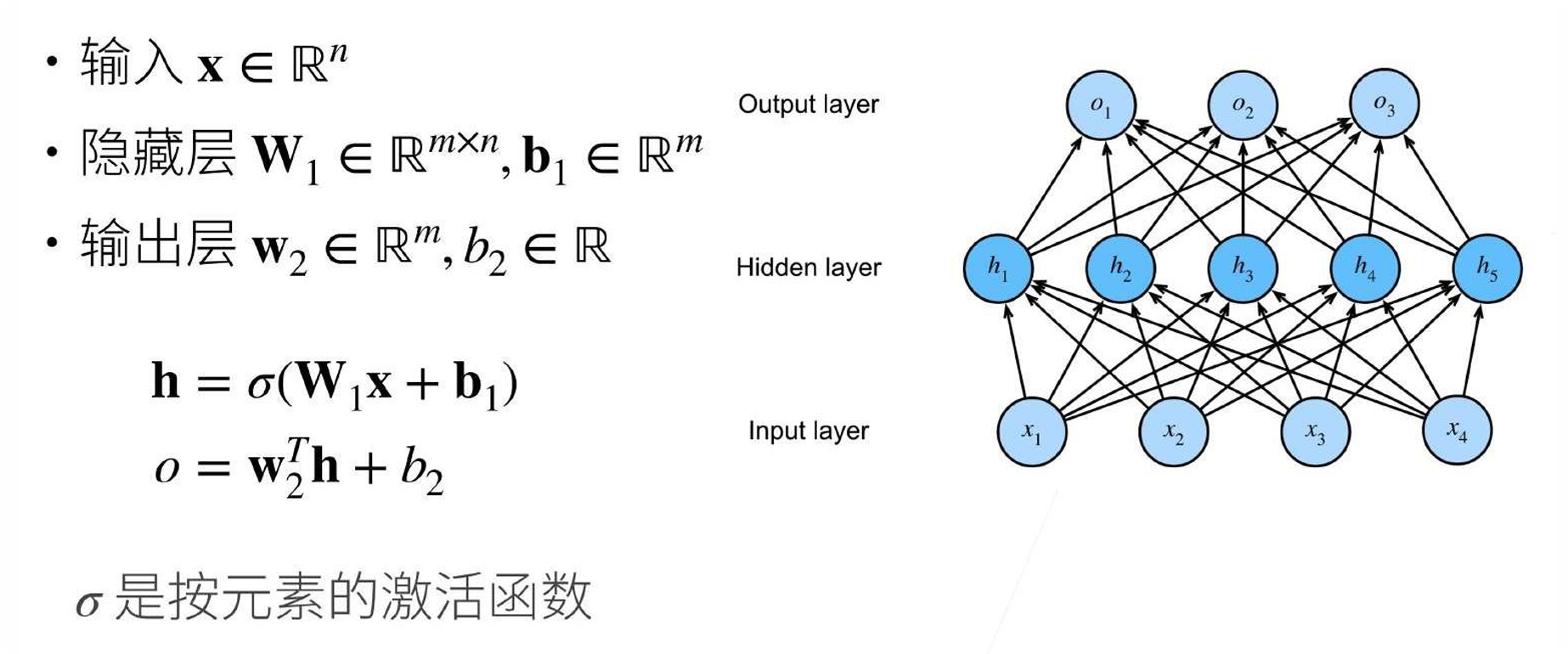
公式:
h = σ(W₁·x + b₁) # 隐藏层,σ是激活函数
o = w₂ᵀ·h + b₂ # 输出层
注意:激活函数必须为【非线性激活函数】
为什么?
非线性激活函数能使整个模型变成非线性的,能拟合 XOR 这类问题
常用激活函数
| 激活函数 | 公式 | 输出范围 | 特点 |
|---|---|---|---|
| ReLU | max(x, 0) |
[0, +∞) |
最常用,计算简单,缓解梯度消失 |
| Sigmoid | 1/(1+e⁻ˣ) |
(0, 1) |
早期常用,现在少用(梯度消失问题) |
| Tanh | (1-e⁻²ˣ)/(1+e⁻²ˣ) |
(-1, 1) |
比Sigmoid好一点,仍然有梯度消失 |
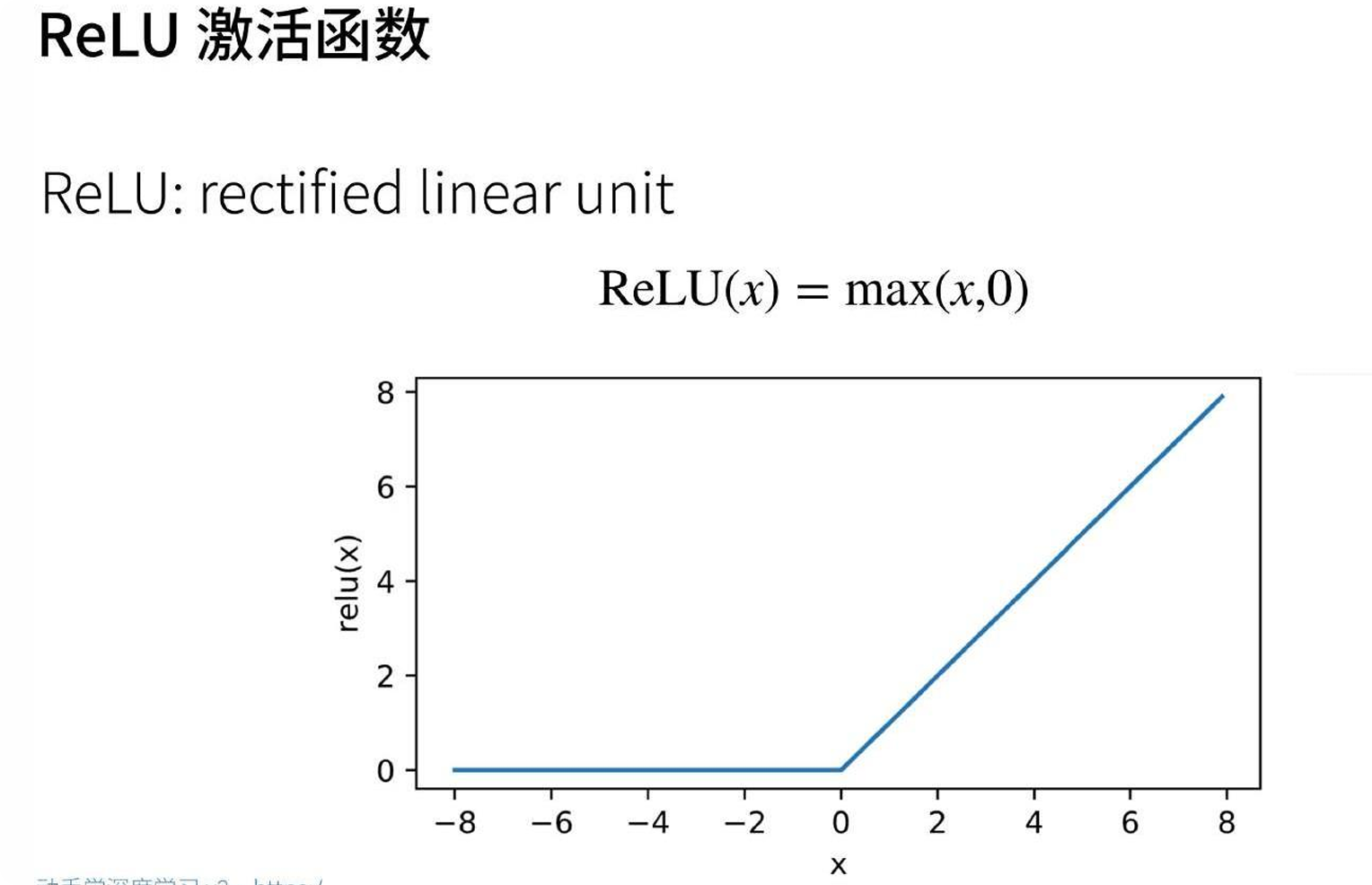
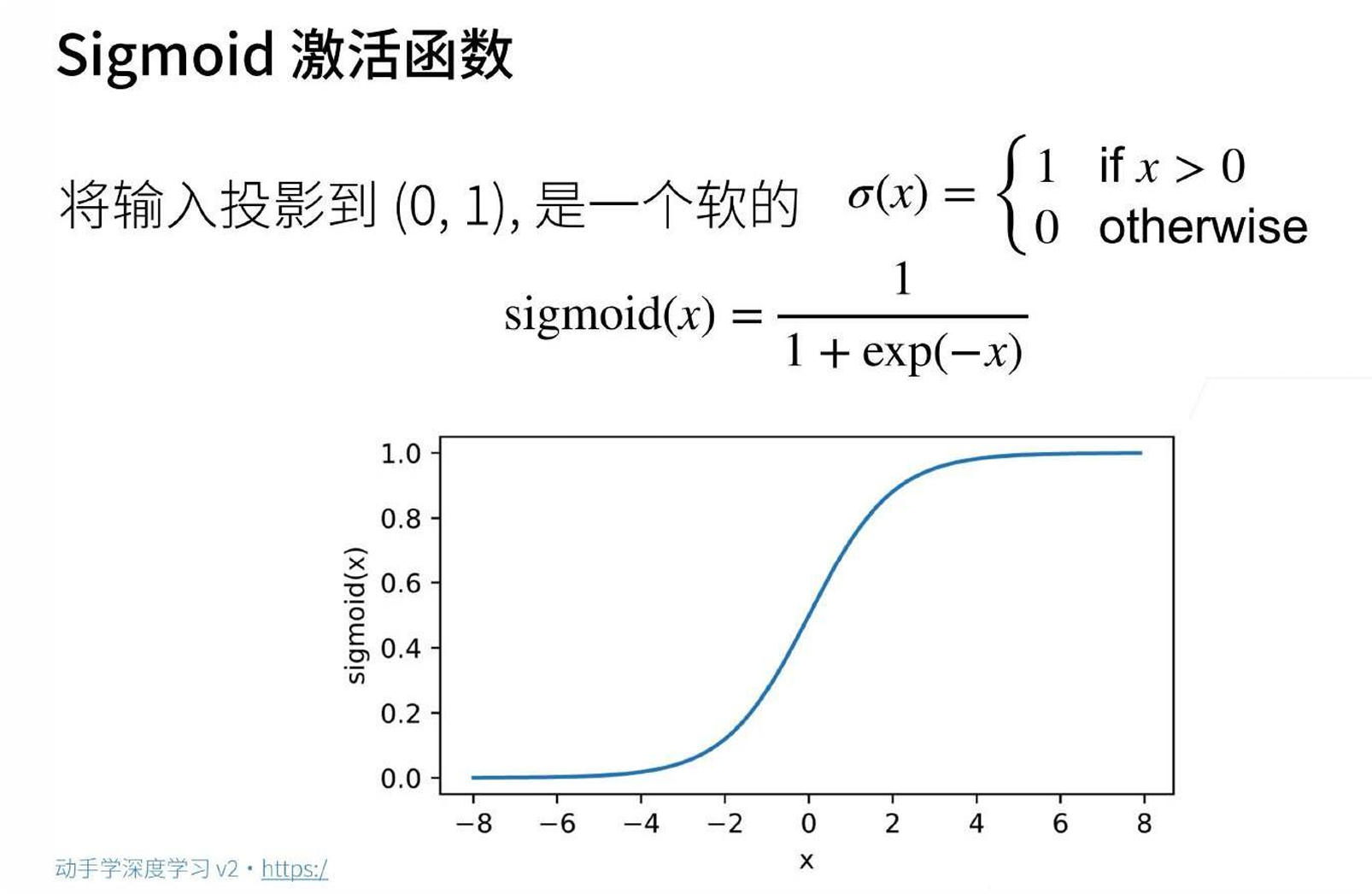
ReLU优势:正半轴梯度恒为1,缓解梯度消失
使用 softmax 来处理多分类问题:
对于多分类问题,如果有k个类别,只需要在输出层用softmax
多隐藏层(深度神经网络)
超参数:
-
隐藏层数(深度)
-
每层隐藏单元数(宽度)
总结&习题:
| 概念 | 要点 |
|---|---|
| 感知机 | 二分类线性模型,训练=错误驱动更新,不能处理XOR |
| 感知机损失 | max(0, -y·<w,x>),等价于批量=1的SGD |
| 收敛条件 | 数据线性可分,步数≤(r²+1)/ρ² |
| XOR问题 | 线性不可分,感知机搞不定 → 第一次AI寒冬 |
| MLP | 感知机 + 隐藏层 + 非线性激活函数 |
| 激活函数必要性 | 否则多层叠加=一层(线性),无法处理非线性问题 |
| 常用激活函数 | ReLU(最流行)、Sigmoid、Tanh |
| 多分类MLP | 隐藏层 + softmax输出层 |
| 超参数 | 隐藏层数、每层隐藏单元数 |
Q1:多层感知机的 “隐藏层” 有什么作用?
隐藏层的作用是提取数据的“中间特征”,并通过非线性激活函数让模型具备拟合复杂非线性关系的能力。
重点:
- 隐藏层位于位于输入层和输出层之间,可以将原始输入重新组合成更高层次的抽象特征
- 同时通过非线性激活函数(如ReLU,Sigmoid)使模型具备解决非线性问题的能力(如异或问题)
- 隐藏层数量(深度)和每层的大小(宽度)决定了模型的容量。通过增加隐藏层可以使模型拟合更加复杂的函数,从而增加模型的表达能力
Q2:写出 ReLU 函数的公式,与 Sigmoid 函数相比有什么优势?
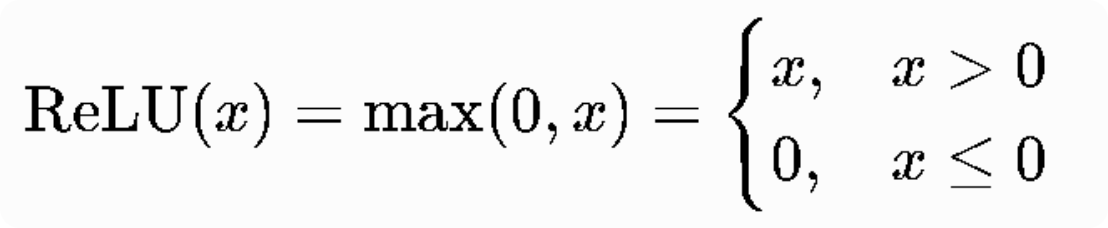
-
缓解梯度消失:正半轴梯度恒为1,深层网络也能有效训练,而Sigmoid在两端饱和、梯度趋近于0。
-
计算简单:只做比较运算,没有指数运算,训练速度更快。
-
引入稀疏性:部分神经元输出为0,让模型更高效、更具鲁棒性。
概念:
感知机为二分类模型,不能处理异或问题,他的求解算法等价于使用批量大小为1的梯度下降
五、模型选择(概念重点)
| 概念 | 定义 | 通俗理解 |
|---|---|---|
| 训练误差 | 模型在训练数据上的误差 | 做练习题时的正确率 |
| 泛化误差 | 模型在新数据上的误差 | 做高考题时的正确率 |
| 数据集 | 用途 | 特点 | 通俗理解 |
|---|---|---|---|
| 训练集 | 训练模型参数(w和b) | 平时做题 | |
| 验证集 | 选择超参数(学习率、层数等) | 训练集分出一部分作为验证集 | 模拟考(用来调整复习策略) |
| 测试集 | 只测一次,评估最终模型 | 高考(只用一次,决定最终成绩) |
K折交叉验证
数据不够多的时候使用这个方法

| 概念 | 定义 | 简单记 | 通俗理解 |
|---|---|---|---|
| 欠拟合 | 训练误差和泛化误差都很大 | 训练误差大,泛化误差大 | 练习题都不及格 → 根本没学会 |
| 过拟合 | 训练误差很低,但泛化误差很高 | 训练误差小,泛化误差大 | 练习题满分 → 高考不及格(死记硬背) |
| 恰到好处 | 训练误差和泛化误差都低 | 练习题不错,高考也不错 → 真学会了 |
模型的容量
容量 = 模型拟合各种函数的能力
| 容量 | 特点 | 后果 |
|---|---|---|
| 低容量 | 太简单,学不到数据规律 | 欠拟合 |
| 高容量 | 太复杂,连噪声都记住了 | 过拟合 |
模型容量的影响:1)经验;2)VC维
数据复杂度
模型的容量要跟数据复杂度匹配
| 因素 | 说明 |
|---|---|
| 样本个数 | 数据越多,能支撑的模型越复杂 |
| 每个样本的元素个数 | 特征维度越高,数据越复杂 |
| 时间/空间结构 | 图像、序列数据比普通表格数据复杂 |
| 多样性 | 数据变化越丰富,越复杂 |
-
数据简单 + 模型太复杂 → 过拟合
-
数据复杂 + 模型太简单 → 欠拟合
总结:
| 概念 | 关键点 |
|---|---|
| 训练误差 | 练习题正确率 |
| 泛化误差 | 高考正确率(我们真正关心的) |
| 验证集 | 用来调超参数,不参与训练 |
| 测试集 | 只用一次,最终评估 |
| K折交叉验证 | 数据少时用,K=5或10,报告平均误差 |
| 欠拟合 | 训练误差高 → 模型太简单 |
| 过拟合 | 训练误差低、泛化误差高 → 模型太复杂 |
| 模型容量 | 拟合能力大小,受参数数量和参数范围影响 |
| VC维 | 理论衡量模型复杂度,深度学习中实际不常用 |
| 数据复杂度 | 样本数、特征数、结构多样性等 |
习题:
1、什么是过拟合和欠拟合?
- 过拟合:模型在训练集上的误差低,但是在测试集上的误差高
- 欠拟合:模型在训练集上的误差高,在测试集上的误差也高
2、什么是训练误差和验证误差?
- 训练误差:模型在训练数据集上计算出的误差
- 验证误差:模型在验证数据集上计算出的误差(验证数据集:一个用来评估模型好坏的数据集,通常从训练集上单独拿出50%作为验证集)
3、怎么通过训练误差和泛化误差判断是否过拟合?
- 训练误差高 + 泛化误差高 = 欠拟合
- 训练误差低 + 泛化误差高 = 过拟合
六、权重衰退
核心思想:控制模型容量
两种方法:


权重衰退通过 L2 正则项使得模型参数不会过大,从而控制模型的复杂度,从而提高模型的泛化能力

正则项权重是控制模型复杂度的超参数
权重衰退 = L2正则化,L2正则化就是在损失函数里加 λ·||w||² 这一项
七、丢弃法
一个好的模型应该对输入数据的扰动具有鲁棒性。
核心思想:给数据加一些噪声,让模型学会在“不完美”的情况下也能正确预测
丢弃法:在层之间加入噪声

训练时,每个神经元有p的概率“被关闭”(输出为0),剩下的神经元要“加班”——输出值除以(1-p),保证总体平均水平不变
丢弃法的作用位置:通常将丢弃法作用在隐藏全连接层的输出上。
总结(重要)

权重衰退(L2 正则化)
| 概念 | 内容 |
|---|---|
| 核心公式 | 新损失 = 原损失 + (λ/2)·||w||² |
| 参数更新 | w ← (1-ηλ)·w - η·∂ℓ/∂w(先衰退再更新) |
| λ的作用 | λ越大,参数被压缩得越小,模型容量越低 |
| 本质 | 限制参数大小 → 控制模型复杂度 → 防止过拟合 |
| 代码实现 | 简洁版:optimizer = SGD(params, weight_decay=wd) |
丢弃法(dropout)
| 概念 | 内容 |
|---|---|
| 核心公式 | 以p概率置0,以1-p概率除以(1-p) |
| 关键性质 | 保持期望不变(无偏扰动) |
| 使用位置 | 通常在全连接层的隐藏层输出上 |
| 训练/推理 | 训练时开启,推理时关闭 |
| p的作用 | p越大,丢弃越多,正则化越强 |
| 代码实现 | 简洁版:nn.Dropout(p) |
对比:
| 权重衰退 | 丢弃法 | |
|---|---|---|
| 作用方式 | 惩罚大参数 | 随机删除神经元 |
| 正则化机制 | 限制参数范围 | 引入噪声扰动 |
| 本质 | L2正则化 | 集成学习近似 |
两者都是通过限制模型复杂度来防止过拟合,且可以组合使用
Q:丢弃法会丢弃整个神经元(对)
八、数值稳定性
神经网络中的梯度函数
损失ℓ关于第t层参数Wᵗ的梯度 = (∂ℓ/∂hᵈ) · (∂hᵈ/∂hᵈ⁻¹) · ... · (∂hᵗ⁺¹/∂hᵗ) · (∂hᵗ/∂Wᵗ)

数值稳定性常见的两个问题:1)梯度消失;2)梯度爆炸
1)梯度爆炸(使用ReLu作为激活函数)
触发条件:使用ReLU激活函数时,权重矩阵特征值 > 1
导致的问题:
| 问题 | 说明 |
|---|---|
| 值超出范围 | 梯度变成inf(无穷大)或NaN(非数字) |
| 对16位浮点数尤为严重 | 16位浮点数范围只有6e-5到6e4,很容易溢出 |
| 对学习率极其敏感 | 学习率太大→梯度爆炸;太小→训练不动 |
| 需要不断调学习率 | 训练过程中可能要频繁调整 |
判断方法:如果训练时损失突然变成NaN(Not a Number),大概率是梯度爆炸了
2)梯度消失(使用Sigmoid作为激活函数)
触发条件:使用Sigmoid激活函数(或其他导数<1的激活函数)
如何造成梯度消失?

回顾梯度是什么:梯度 = 损失上升最快的方向 + 变化的幅度
导致的问题:
| 问题 | 说明 |
|---|---|
| 梯度变成0 | 参数完全停止更新 |
| 底部层几乎不训练 | 靠近输入的层梯度为0,只有靠近输出的层能训练 |
| 无法让网络更深 | 加再多层也没用,因为前面都"死"了 |
| 不管怎么调学习率都没用 | 因为梯度本身就是0,调大学习率也救不了 |
深度网络 = 大量连乘 → 数值要么爆炸(>1累乘)要么消失(<1累乘)→ 训练失败
那么如何让训练更加稳定?
让梯度值在一个合理的范围内?
解决方法:(主要:梯度裁剪;梯度归一化;权重初始化;采用合适的激活函数)
| 策略 | 代表技术 | 核心思路 |
|---|---|---|
| 1. 将乘法变加法 | ResNet、LSTM | 用"加法"连接代替"乘法"连接 |
| 2. 归一化 | 梯度裁剪、梯度归一化 | 把梯度限制在合理范围 |
| 3. 合理的权重初始化 | Xavier/Kaiming初始化 | 让权重"恰到好处" |
| 4. 合适的激活函数 | ReLU、调整后的Sigmoid | 避免导数极端值 |
权重初始化:
核心目标:让每一层的输出和梯度的方差保持一致
总结:
| 梯度爆炸 | 梯度消失 | |
|---|---|---|
| 现象 | 梯度→∞ | 梯度→0 |
| 典型原因 | 权重过大 × ReLU | Sigmoid激活函数(导数≤0.25) |
| 后果 | 损失变成NaN | 底部层不更新 |
| 对学习率 | 极其敏感 | 怎么调都没用 |
深度网络训练像传话游戏——信息从最后一层传到最前面,每传一层都要乘一次。乘的数>1就爆炸(ReLU+大权重),乘的数<1就消失(Sigmoid),根本训不动。解决办法是合理初始化权重(让每层方差一致)和选对激活函数(ReLU比Sigmoid好)
九、层和块
1)什么是层(layer)?
层是神经网络中最基本的数据处理单元,接收一个张量,经过某种变换,输出一个新的张量
本质:层就是一个函数——输入一个张量,输出另一个张量。你可以把任何数据处理操作封装成"层"。
2)什么是块(block)?
块是一个或多个层(或子块)的容器,是比"层"更大、更灵活的组织单位。
在PyTorch中,nn.Module就是"块"。所有东西都是nn.Module的子类
class MLP(nn.Module): # 这就是一个"块"
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20, 256) # 子层1
self.out = nn.Linear(256, 10) # 子层2
def forward(self, X):
return self.out(F.relu(self.hidden(X))) # 定义数据如何流过子层| 组件 | 作用 | 类比 |
|---|---|---|
__init__ |
注册子层("买积木") | 列出三明治的配料清单 |
forward |
定义数据流向("告诉你怎么拼") | 说明配料怎么组合 |
nn.Module最重要的能力是什么?
答:它能够递归地找到所有子模块的参数。
3、Sequential
nn.Sequential是一个特殊的块,它按顺序串联子层,数据依次流过每一层。
Sequential的基本原理:
| 步骤 | 做什么 | 代码 |
|---|---|---|
| 1 | 接收子层 | __init__(self, *args) 接收所有传入的层 |
| 2 | 注册子层 | self._modules[block] = block(_modules是PyTorch自动追踪子模块的字典) |
| 3 | 顺序执行 | forward中遍历_modules,依次调用每一层 |
总结:
| 概念 | 定义 | 特点 |
|---|---|---|
| 层 | 最小的处理单元 | 接收张量→输出张量(如Linear、ReLU) |
| 块 | 层的容器/组合 | 继承nn.Module,可嵌套,包含__init__和forward |
| Sequential | 特殊的块 | 自动按顺序执行子块,forward不需要手写 |
十、卷积(非常重要)
全连接层:上一层的全部神经元全部连到下一层的每个神经元上面
全连接层处理图片参数太多(一张12M像素的图需要36亿个参数)→ 我们根据两个原则(平移不变性、局部性)改造全连接层 → 得到卷积层 → 参数大大减少,且能检测图像中的边缘等特征
记:对全连接层使用平移不变性和局部性得到卷积层
卷积的两个原则:平移不变性 & 局部性
1)平移不变性:检测同一个特征的卷积核应该能在图像的任何位置使用
2)局部性:判断一个像素是什么,只需要看它周围一小块区域,不需要看整张图
| 步骤 | 做了什么 | 效果 |
|---|---|---|
| 全连接层 | 每个输出和所有输入相连 | 参数爆炸 💥 |
| 平移不变性 | 同一权重在不同位置复用 | 参数大幅减少 ✅ |
| 局部性 | 只用周围小区域的输入 | 参数进一步减少 ✅ |
| 卷积层 | 两者结合 | 参数可控,能泛化 🎯 |
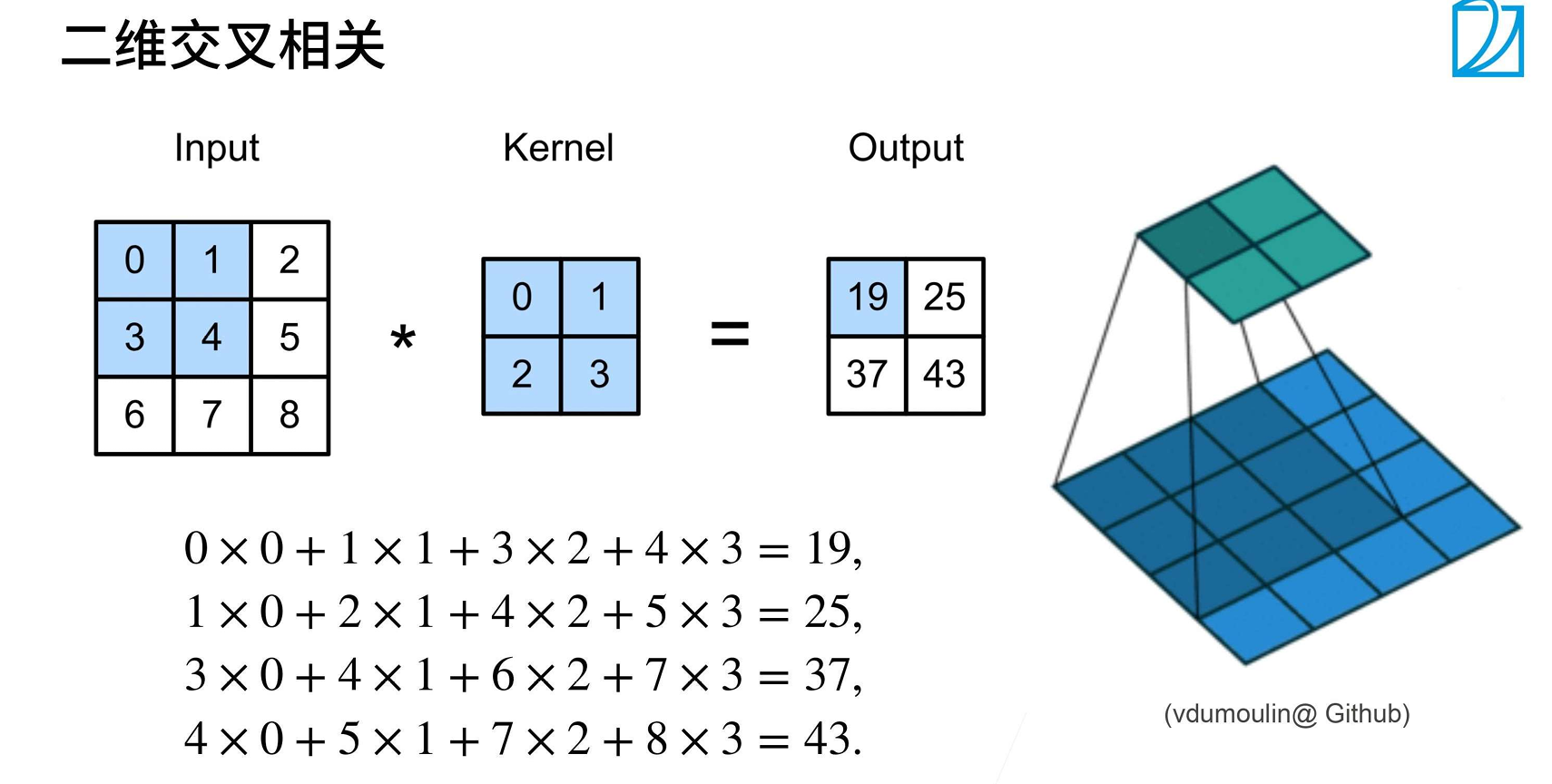
理解:Kernel 扫描 Input 的全部位置,得出 output
二维互相关运算的计算方式:卷积核在输入上"滑动",在每个位置,核与覆盖区域逐元素相乘后求和

二维交叉相关 (基本)== 二维卷积
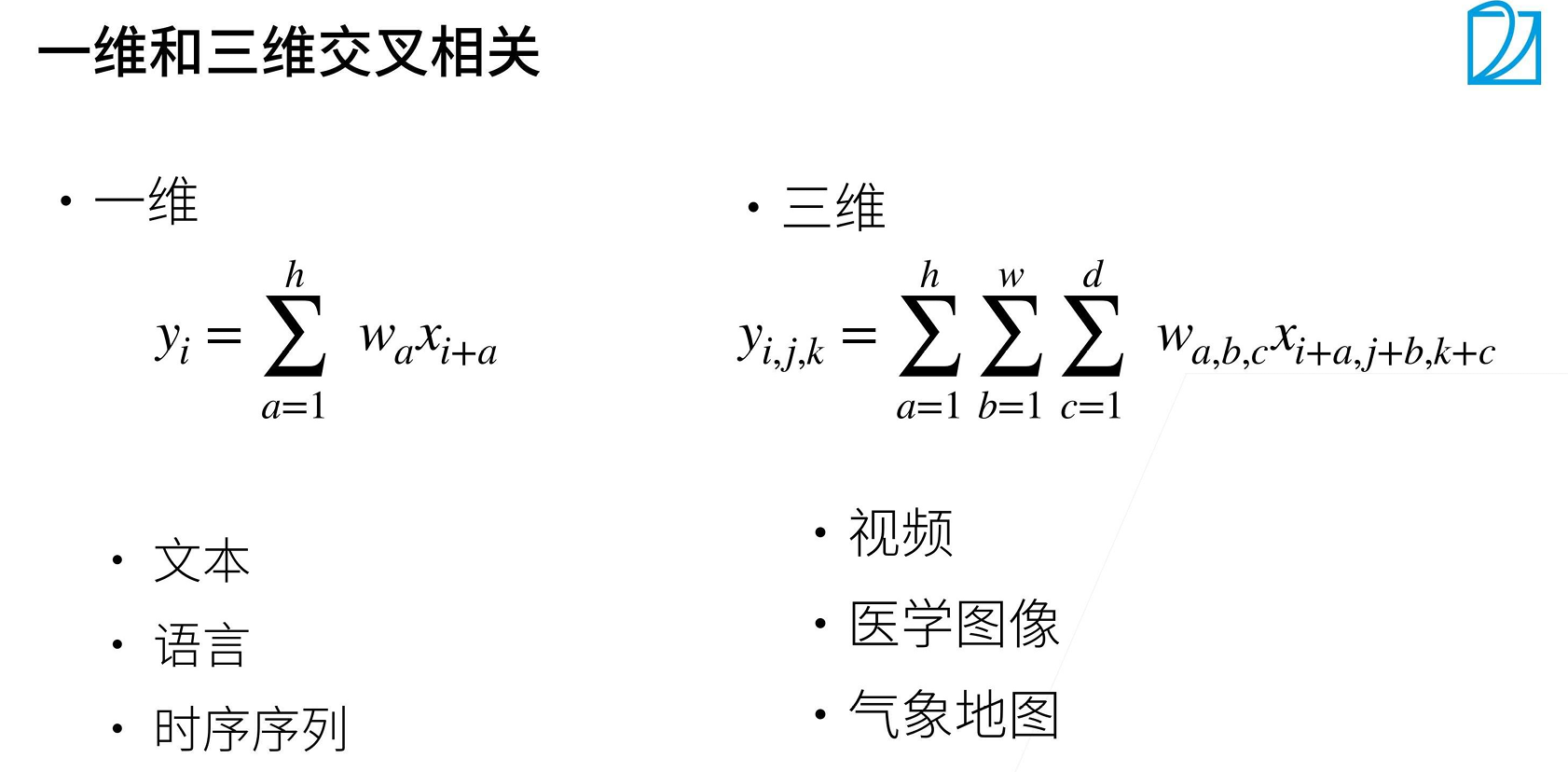
总结:
卷积层通过将输入和核矩阵进行交叉相关,加上偏置项后得到输出
核矩阵的偏置项是可学习的参数
核矩阵的大小是超参数
习题:
1、MLP的前向传播,反向传播是怎么样的
- 前向传播:数据从输入层进入,经过每一层的计算,最后输出预测结果
- 反向传播:从输出层开始,把"损失"往前传,计算每一层的参数应该怎么调整。
通过链式求导法则,将前向传播得到的预测损失从输出层反向逐层向输入层传递,计算梯度,再结合梯度下降法更新所有参数,从而最小化模型预测误差
2、卷积层的优势(相对于全连接层),能解决什么问题
解决的问题:全连接层处理大尺寸图像时参数爆炸
卷积层的优势:
- 参数大幅减少(基于"局部性"原则)
| 层类型 | 连接方式 | 参数数量 | 示例 |
|---|---|---|---|
| 全连接层 | 每个输出连接所有输入 | 输入维度 × 输出维度 |
36M×100 = 36亿 |
| 卷积层 | 每个输出只连接局部区域 | 核大小(不随输入尺寸变化) |
3×3 = 9 |
- 保留空间结构(基于"平移不变性"原则)
- 全连接层:把图片展平成一维 → 丢失了像素之间的位置关系
- 卷积层:保持二维结构 → 相邻像素一起处理,能识别局部特征
- 平移不变性
- 同一套参数(核)在所有位置共享使用
3、怎么用卷积层进行参数共享?
参数共享 = 一个卷积核(一组权重)在输入图像的所有位置使用
4、卷积层计算参数量的大小
基本公式:卷积层参数量 = (核高 × 核宽 × 输入通道数) × 输出通道数 + 输出通道数(偏置)
计算:
MLP 的输入层有 256 个神经元,隐藏层有 128 个神经元,输出层有 10 个神经元,忽略偏置,求参数数量并写出计算过程

相关公式:
1)输入层到隐藏层之间的权重参数数量(不包括偏置):公式:输入维度 × 输出维度
2)隐藏层的偏置参数数量:公式:输出神经元数(每个输出神经元对应一个偏置)
3)隐藏层 → 输出层的权重参数数量:公式:输入维度(隐藏层大小)× 输出维度(类别数)
4)输出层的偏置参数数量:公式:输出神经元数
5)整个MLP的总参数数量:总参数 = (1) + (2) + (3) + (4)
| 概念 | 公式/要点 |
|---|---|
| 全连接层前向 | Z = X·W + b,Ŷ = σ(Z) |
| 全连接层反向 | ∂L/∂W = Xᵀ·∂L/∂Z,∂L/∂X = ∂L/∂Z·Wᵀ |
| 卷积层前向 | 核在输入上滑动,逐元素乘后求和 |
| 卷积层反向 | 用翻转核做卷积(transposed convolution) |
| 卷积层优势 | ①参数少(局部性) ②保留空间结构 ③平移不变性 |
| 参数共享 | 同一核在所有位置使用 → 公式中v不依赖(i,j) |
| 参数量公式 | k_h × k_w × C_in × C_out + C_out |
卷积层相比于全连接层的核心优势是参数共享(同一核在所有位置使用)+局部连接(只关注邻域),这使得参数量从输入×输出骤降到核大小×通道数,能处理大尺寸图像,且具备平移不变性
十一、填充(Padding)& 步幅(Stride)& 通道数
卷积核在输入上滑动时,怎么滑(步幅)、边缘怎么处理(填充)、输入输出有多少层(通道数)——这三个因素共同决定了卷积层的输出形状和参数量
1、填充
为什么要填充?
答:每次卷积操作都会让输出尺寸变小
-
经过几层后,图像变得太小,无法继续做卷积
-
边缘像素只被卷积核"扫过"一次,中心像素被扫过多次 → 边缘信息丢失
填充定义:填充在输入周围添加额外的行与列,来控制输出形状的减少量
不填充的正常输出尺寸:
输出尺寸 = 输入尺寸 - 核尺寸 + 1
怎么做填充?
做法:在输入图像的周围添加额外的行/列(通常填0)
原始 5×5 图像 → 填充1圈 → 7×7 → 用3×3核 → 输出仍为5×5
输出尺寸公式:
输出高度 = n_h - k_h + p_h + 1
输出宽度 = n_w - k_w + p_w + 1
其中 p_h 是上下填充的总行数,p_w 是左右填充的总列数
-
通常取
p_h = k_h - 1,p_w = k_w - 1(这样输入输出尺寸不变) -
如果
k_h是奇数:上下各填充p_h/2 -
如果
k_h是偶数:上填充⌊p_h/2⌋,下填充⌈p_h/2⌉
最常见配置:kernel_size=3, padding=1 → 输入输出尺寸不变

2、步幅
为什么要步幅?
目的:更快地缩小特征图的尺寸
步幅的定义:步幅是每次滑动核窗口时的行与列的大小,可以成倍快速地减少输出形状
步幅 = 卷积核每次滑动的行数/列数

注:p 为填充;s 为步幅
填充和步幅都是卷积层的超参数
3、多个输入&输出通道
1)多个输入通道
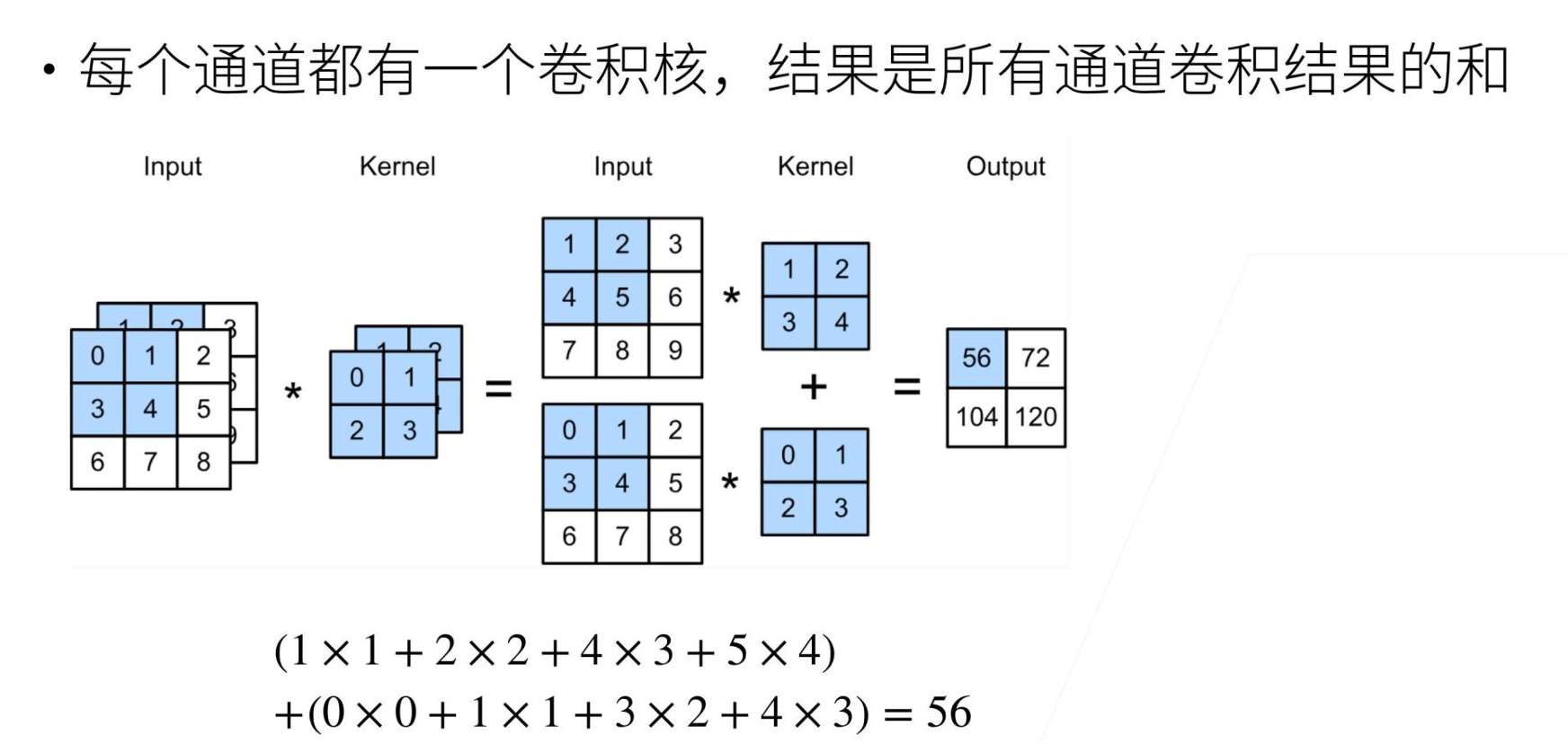
无论有多少输入通道,输出总是单通道的
每个输入通道具有独立的二维卷积核,所有通道结果加起来得到一个输出通道的结果
2)多个输出通道
每个输出通道有独立的三维卷积核
输出通道数是卷积层的超参数
3)1×1卷积核
作用:融合通道
总结:
| 情况 | 公式(输出尺寸) |
|---|---|
| 无填充,步幅1 | (n - k + 1) × (n - k + 1) |
| 有填充p,步幅1 | (n - k + p + 1) × (n - k + p + 1) |
| 有填充p,步幅s(完整版) | ⌊(n - k + p + s) / s⌋ × ⌊(n - k + p + s) / s⌋ |
| p=k-1时(简化版) | ⌊(n + s - 1) / s⌋ × ⌊(n + s - 1) / s⌋ |
| n能被s整除 | (n/s) × (n/s) |
| 概念 | 公式 |
|---|---|
| 输入到输出的映射 | 每个输出通道 = 所有输入通道 × 对应核 求和 |
| 卷积核形状 | c₀ × cᵢ × k_h × k_w |
| 输出形状 | c₀ × m_h × m_w |
| 参数量 | c₀ × cᵢ × k_h × k_w + c₀(含偏置) |
| 1×1卷积参数量 | c₀ × cᵢ + c₀ |
练习:
1、输入32×32×3,核3×3,输出通道64,填充1,步幅2 → 输出形状是什么?参数量是多少?
卷积层输出尺寸公式:
输出高度 = ⌊(输入高度 - 核高度 + 2×填充高度 + 步幅高度) / 步幅高度⌋
输出宽度 = ⌊(输入宽度 - 核宽度 + 2×填充宽度 + 步幅宽度) / 步幅宽度⌋
输出高度:16;输出宽度:16;输出通道:64
答案:输出形状为 32 * 32 * 64
卷积层参数量公式:
参数量 = 核高 × 核宽 × 输入通道数 × 输出通道数 + 输出通道数(偏置)
如果题目说有偏置,每个输出通道有1个偏置
答案:参数量为 3 * 3 * 3 * 64 + 64
卷积层输出形状由 输入尺寸、核大小、填充、步幅 共同决定;参数量只取决于 核大小×输入通道数×输出通道数(+偏置),与输入图像尺寸无关
十二、池化层
卷积层负责"找特征",池化层负责"压缩信息+增加鲁棒性";LeNet则是"卷积层提取特征 → 池化层压缩 → 全连接层分类"这一经典范式的开山之作
为什么要有池化层
作用是什么?
缓解卷积层对位置的敏感性
-
在卷积层之后加一个池化层
两种池化层:
1)二维最大池化:返回滑动窗口中的最大值
2)二维平均池化:返回滑动窗口中的平均值
| 池化类型 | 操作 | 特点 | 适用场景 |
|---|---|---|---|
| 最大池化 | 取窗口内最大值 | 保留最强特征,平移不变性好 | 最常用 |
| 平均池化 | 取窗口内平均值 | 保留背景/整体信息 | 深层网络、全连接层前 |
池化层和卷积层的相同点:
-
都有窗口大小、填充、步幅这些超参数
池化层和卷积层的不同点:
-
没有可学习的参数
-
输出通道数 = 输入通道数
注:卷积层一共有两个可以学习的参数:卷积核(权重)和偏置项
池化层 = 汇聚层
重点LeNet(第一个卷积神经网络)
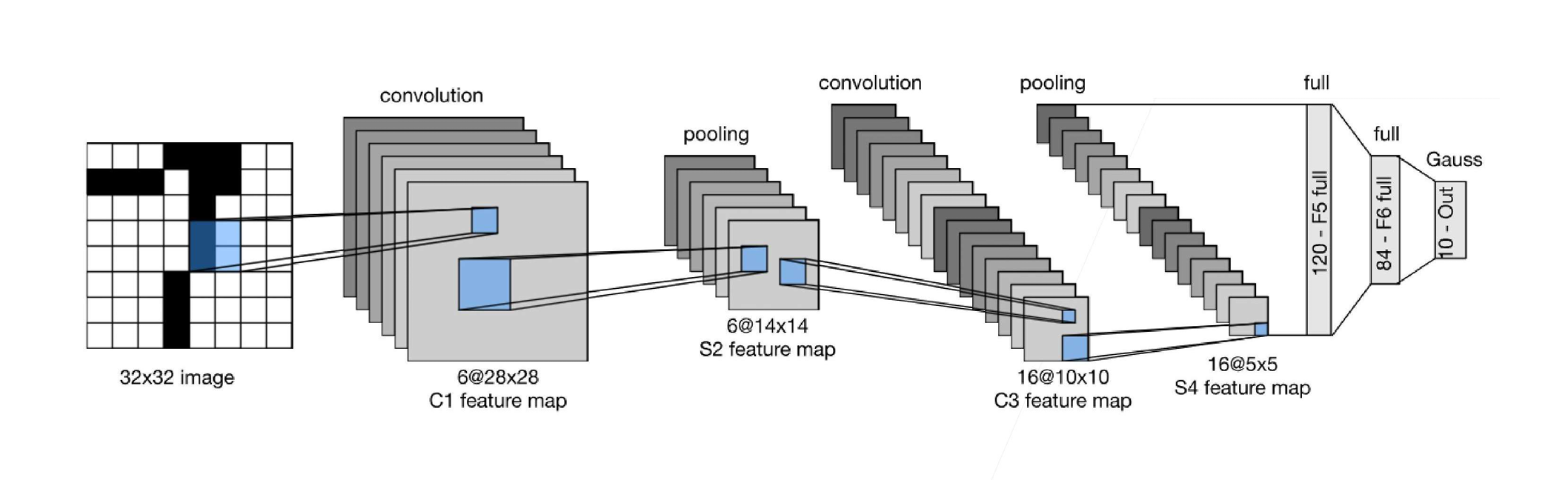
核心架构(如图)
输入:1×28×28(MNIST灰度图)
↓
【卷积层C1】nn.Conv2d(1, 6, kernel_size=5, padding=2)
6个5×5卷积核,填充2→尺寸不变
输出:6×28×28
↓ Sigmoid激活
【池化层S2】nn.AvgPool2d(kernel_size=2, stride=2)
2×2窗口,步幅=2→高宽减半
输出:6×14×14
↓
【卷积层C3】nn.Conv2d(6, 16, kernel_size=5)
16个5×5卷积核,无填充→10×10
输出:16×10×10
↓ Sigmoid激活
【池化层S4】nn.AvgPool2d(kernel_size=2, stride=2)
输出:16×5×5
↓
【展平】Flatten
16×5×5 = 400 → 展平成一维向量
↓
【全连接层C5】nn.Linear(400, 120)
400 → 120
↓ Sigmoid激活
【全连接层F6】nn.Linear(120, 84)
120 → 84
↓ Sigmoid激活
【输出层】nn.Linear(84, 10)
84 → 10(10个类别)
对该图片的理解:
1)图中从左到右第二个卷积层,写出输入通道数量、输出通道数量、卷积核形状。
输入通道 = 6,输出通道 = 16,卷积核形状 5 * 5
2)LeNet 使用卷积层和汇聚层(池化层)结合的方式,有什么作用?
卷积层负责“提取特征”,池化层负责“压缩信息+增加鲁棒性”——两者结合,让模型既能有效提取图像特征,又能减少计算量、防止过拟合。
先使用卷积层来学习图片空间信息,然后使用全连接层来转换到类别空间(重要)
卷积层的优势:1)参数共享;2)局部连接;3)平移不变性
3)LeNet 末端都是全连接层,分析其作用,为什么全连接层的参数最多?
核心作用:将“空间特征”转换为“类别决策”
为什么参数多?
全连接层是“密集连接”,全连接层的参数量公式:
参数量 = 输入维度 × 输出维度 + 输出维度(偏置)
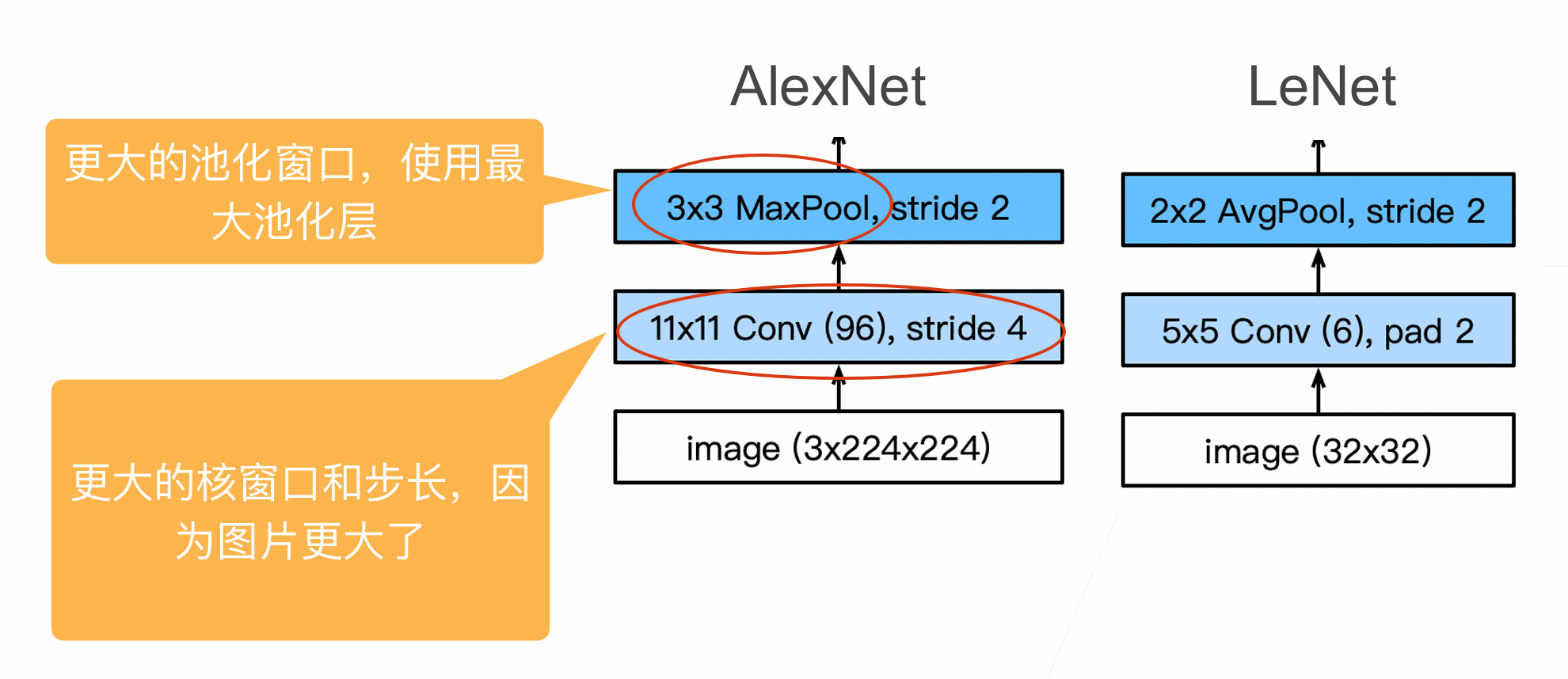
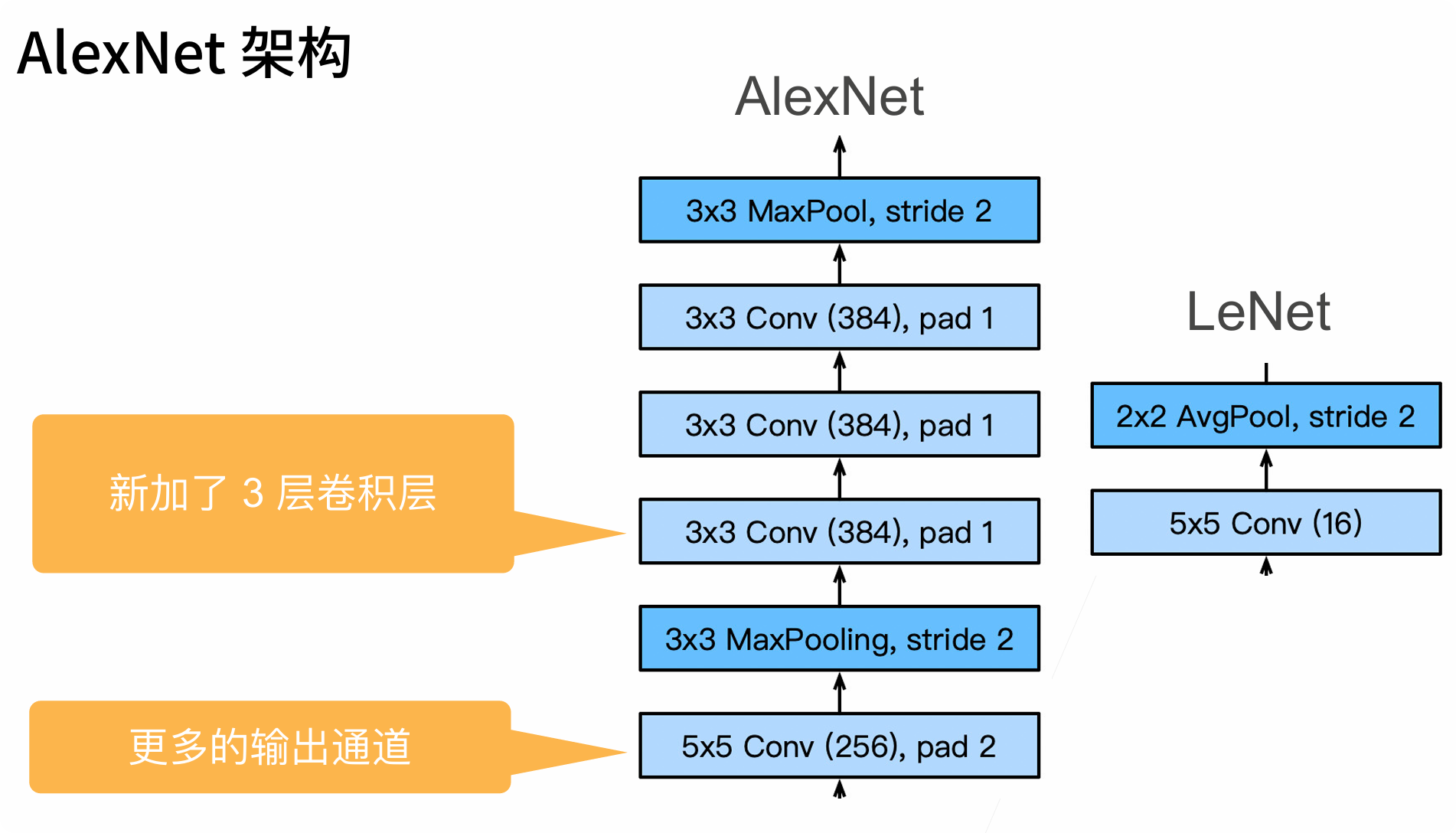
十三、AlexNet
AlexNet为在LeNet上的改进
改进1:激活函数从Sigmoid换成ReLU
| 激活函数 | LeNet | AlexNet |
|---|---|---|
| 使用 | Sigmoid | ReLU |
| 问题 | 梯度消失(深层网络很难训练) | ✅ 缓解梯度消失 |
| 速度 | 慢(需要指数运算) | ✅ 快(只做比较运算) |
改进2:使用最大池化(MaxPooling)而非平均池化
| 池化方式 | LeNet | AlexNet |
|---|---|---|
| 使用 | 平均池化 | 最大池化 |
| 效果 | 平滑特征 | ✅ 保留最强特征(边缘、纹理更清晰) |
改进3:在全连接层后引入Dropout(丢弃法)
"隐藏全连接层后加入了丢弃层" → 防止过拟合
改进4:数据增强
对训练图像进行随机裁剪、水平翻转、颜色变换等
相当于"凭空"增加了训练数据量,防止过拟合
架构对比
总结:
AlexNet是更大更深的LeNet,10倍的参数个数,260倍的计算复杂度
引入了丢弃法;ReLU;最大池化;数据增强
题目:
1、AlexNet 和 LeNet 的核心技术的主要差别是什么,并分析这些差别的作用。
主要差别:
1)激活函数不同:LeNet 使用 Sigmoid / Tanh 激活函数,AlexNet 改用 ReLU
作用:Sigmoid 容易导致梯度消失;而ReLU 可以有效缓解梯度消失这个问题
2)池化方式不同:LeNet 使用平均池化,AlexNet 改用 最大池化
作用:平均池化会平滑特征,可能稀释重要特征;而最大池化会保留窗口内的最强信号,使特征表达更突出,有利于复杂图像的特征提取
3)LeNet 没有使用正则化,AlexNet 在全连接层后引入了 Dropout(丢弃法)
作用:引入 Dropout 可以有效缓解过拟合,从而提高模型的泛化能力
4)AlexNet 有更多卷积层、深度和参数量
作用:更深的神经网络可以学习更复杂的特征层次
5)AlexNet 使用了随机裁剪、水平翻转、颜色变换等数据增强技术
作用:提高泛化能力
十四、VGG
VGG的核心思想:更大更深的AlexNet
更多卷积层;将卷积层组合成块
VGG 使用可重复使用的卷积块来构建深度卷积神经网络
不同卷积块个数和超参数可以得到不同复杂度的变种
十五、序列模型(有前后关系的数据模型)
序列数据的特点是"前后有关联"→ 我们需要对"过去→未来"建模 → 两种经典方案:马尔科夫假设(只看最近τ个)和潜变量模型(用隐变量概括整个历史)
序列数据:有顺序
时序模型中,当前数据跟之前观察到的数据相关
自回归模型使用自身的过去数据来预测未来
1、序列建模的统计工具
A、马尔可夫假设
核心思想:当前只跟最近τ个数据点相关,更早的数据可以忽略。
p(x_t | x₁,...,x_{t-1}) ≈ p(x_t | x_{t-τ},...,x_{t-1})
通俗理解:预测明天天气,不需要看过去100天的全部数据,看最近3~5天就够了
τ的选择:
-
τ太小:信息不够,模型欠拟合
-
τ太大:包含太多无关信息,过拟合且计算量大
B、潜变量模型
核心思想:引入一个潜变量 h_t来"概括"所有历史信息
h_t = f(x₁, x₂, ..., x_{t-1}) # 潜变量浓缩了所有过去
x_t = p(x_t | h_t) # 当前只依赖于潜变量
| 对比项 | 马尔科夫模型 | 潜变量模型 |
|---|---|---|
| 依赖范围 | 最近τ个观测值 | 全部历史(通过潜变量) |
| 内存需求 | τ个值 | 1个潜变量向量 |
| 计算复杂度 | 低(窗口固定) | 中(需要更新隐状态) |
| 例子 | AR模型 | RNN(循环神经网络) |
十六、循环神经网络(RNN)(重点)
专门用来处理序列数据(如文本、时间序列)的神经网络
前学的全连接层和卷积层,每个输入都是独立处理的(图片之间没有先后关系)。但文本、语音等序列数据前后有关联——RNN通过引入隐藏状态(hidden state) 来"记住"之前看到的信息,让网络具有记忆能力
上一章(序列模型)讲了两种处理序列数据的方案——马尔科夫假设(只看最近τ个值)和潜变量模型(用隐变量概括全部历史)。RNN就是潜变量模型的神经网络实现——用循环连接让网络自己学习如何"概括"历史信息
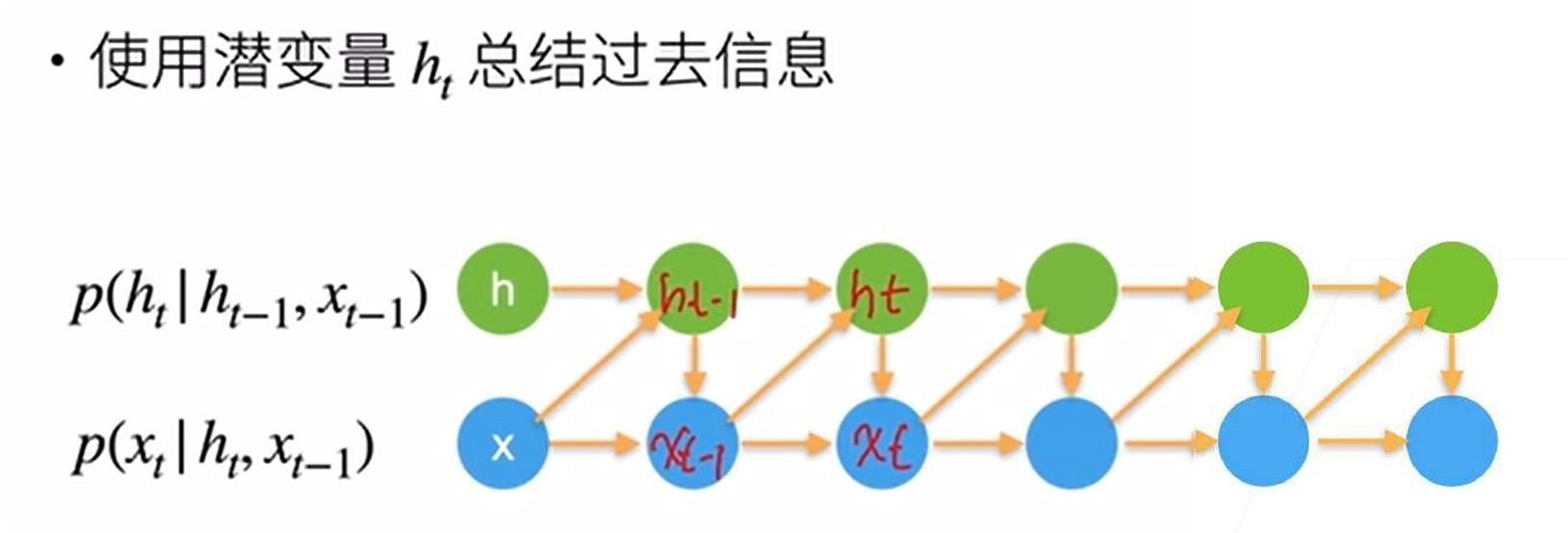
1、潜变量自回归模型
引入潜变量
h_t来概括所有过去信息
h_t = f(x₁, x₂, ..., x_{t-1})
x_t = p(x_t | h_t)
2、循环神经网络
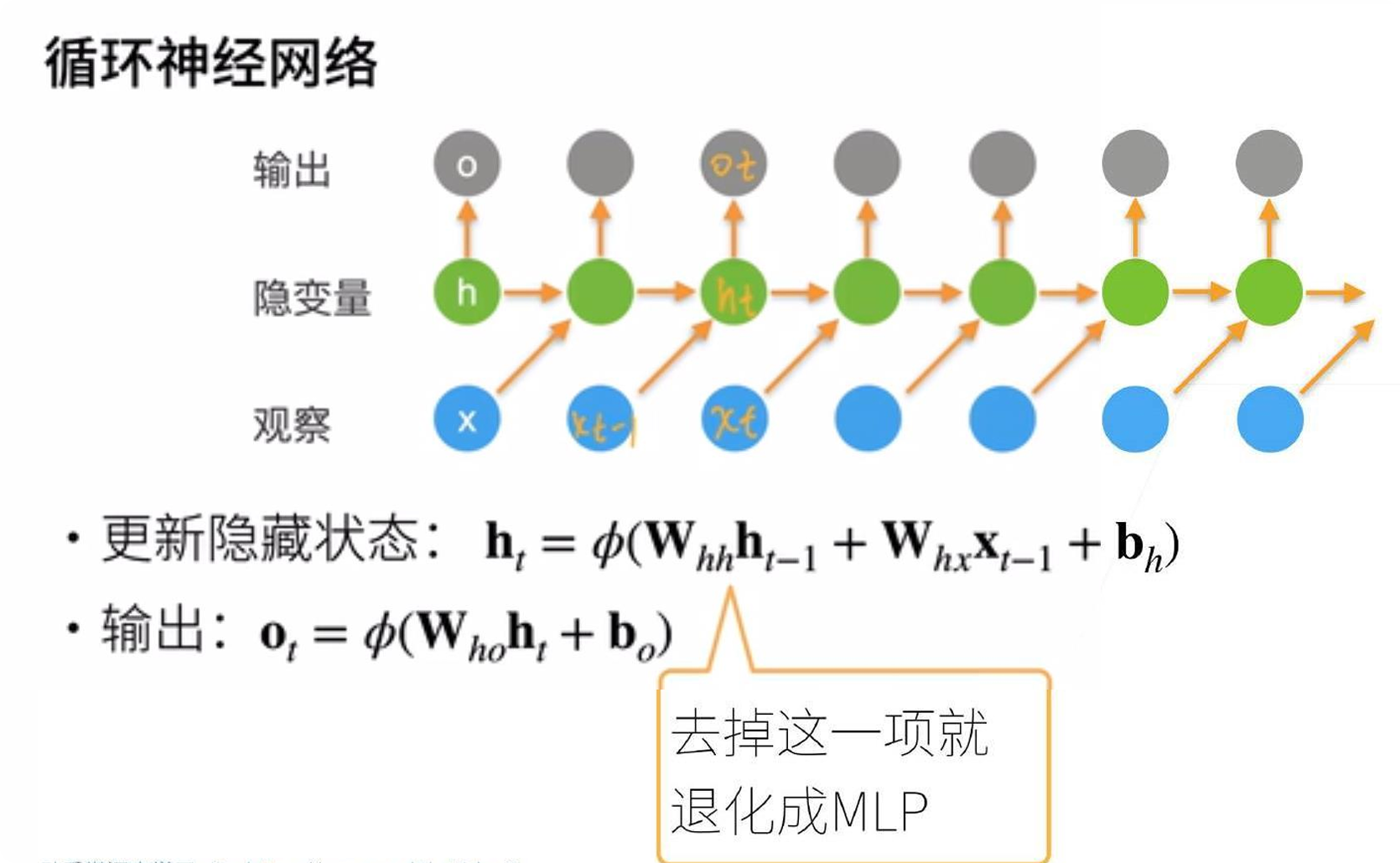
核心公式:
隐藏状态更新:h_t = φ(W_hh · h_{t-1} + W_hx · x_{t-1} + b_h)
输出计算:
o_t = φ(W_ho · h_t + b_o)
-
如果没有
h_{t-1}这一项,每个时刻的输入都是独立的 → 就是普通的MLP -
加上
h_{t-1}后,网络有了"记忆"——当前时刻的输出依赖于上一个时刻的隐藏状态
参数讲解:
| 参数 | 形状 | 作用 |
|---|---|---|
W_hh |
隐藏大小 × 隐藏大小 | 从前一时刻的隐藏状态到当前隐藏状态(记忆传递) |
W_hx |
隐藏大小 × 输入大小 | 从输入到隐藏状态(输入处理) |
W_ho |
输出大小 × 隐藏大小 | 从隐藏状态到输出(输出生成) |
b_h |
隐藏大小 | 隐藏层的偏置 |
b_o |
输出大小 | 输出层的偏置 |
| 网络类型 | 参数共享方式 | 效果 |
|---|---|---|
| MLP | 无共享(每层独立参数) | 参数量随层数增长 |
| CNN | 空间上共享(同一核在图像所有位置使用) | 参数量与图像尺寸无关 |
| RNN | 时间上共享(同一组参数在所有时间步使用) | 参数量与序列长度无关 |
RNN的参数共享让它可以处理任意长度的序列
3、RNN 在语言模型中的应用
语言模型的任务:给定前几个词,预测下一个词
4、困惑度(perplexity)
定义:困惑度(Perplexity)是衡量语言模型好坏的指标,是交叉熵损失的指数形式
困惑度 = exp(平均交叉熵损失)
平均交叉熵 = (1/n) × Σ -log p(真实词 | 前面的词)

通俗解释:困惑度 = 模型在预测下一个词时,平均有多少个"候选词"让它犹豫不决
| 困惑度值 | 含义 |
|---|---|
| 1 | 完美模型(每次都100%猜对) |
| 10 | 平均在10个词之间犹豫(不错) |
| 100 | 平均在100个词之间犹豫(较差) |
| 无穷大 | 最差情况(完全随机瞎猜) |
5、梯度裁剪
1)为什么需要梯度裁剪?
RNN在时间上展开后,相当于一个很深的网络(深度 = 序列长度)
反向传播时,梯度要沿着时间步逐层回传
这会导致连乘效应(回忆之前学的"数值稳定性"章节):
-
如果梯度 > 1 → 梯度爆炸
-
如果梯度 < 1 → 梯度消失

2)什么是梯度裁剪?
核心思想:如果梯度的长度超过阈值θ,就把它"缩回来"。
| 方法 | 效果 | 问题 |
|---|---|---|
| 调小学习率 | 整体更新步长变小 | 正常梯度也变小了,训练变慢 |
| 梯度裁剪 | 只压缩过大的梯度 | ✅ 正常梯度不受影响,异常梯度被限制 |
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 梯度爆炸 | 连乘导致梯度指数级增长 | 梯度裁剪 |
| 梯度消失 | 连乘导致梯度指数级衰减 | 使用LSTM/GRU |
总结:
循环神经网络的输出 取决于:当前输入 & 前一时间的隐变量
运用到语言模型中时,RNN 根据当前词预测下一时刻的词
困惑度 —— 用于衡量语言模型的好坏
| 公式 | 含义 |
|---|---|
h_t = φ(W_hh·h_{t-1} + W_hx·x_{t-1} + b_h) |
隐藏状态更新(记忆传递) |
o_t = φ(W_ho·h_t + b_o) |
输出计算 |
去掉 W_hh·h_{t-1} |
退化成MLP(无记忆) |
| 对比项 | MLP | CNN | RNN |
|---|---|---|---|
| 适用数据 | 表格数据 | 图像 | 序列(文本、语音) |
| 参数共享 | ❌ | ✅(空间) | ✅(时间) |
| 记忆能力 | ❌ | ❌ | ✅(通过h_t) |
| 输入长度 | 固定 | 固定 | 可变 |
| 概念 | 定义 | 通俗理解 |
|---|---|---|
| 隐藏状态 h_t | 压缩了所有历史信息的向量 | 大脑的"短期记忆" |
| 循环连接 | h_{t-1} → h_t 的连接 | 把记忆传给下一时刻 |
| 参数共享 | 所有时间步用同一组W | 同一套"大脑"处理每个时刻 |
| 困惑度 | exp(平均交叉熵) | 猜词时平均有几个候选 |
| 梯度裁剪 | 限制梯度最大值 | 给梯度加"限速器" |
RNN = 带记忆的MLP。它通过隐藏状态 h_t 记住历史信息,用同一组参数在所有时间步共享,从而能处理任意长度的序列。去掉循环连接就退化成普通MLP。语言模型中用困惑度衡量好坏(越低越好),用梯度裁剪防止梯度爆炸。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)