一文拆解 RAG 全链路算法:从检索到生成
「从基本原理出发」
在接触RAG的过程中,我发现很多人把它理解成一个“检索+生成”的简单组合:先查点资料,再让大模型照着回答。
这种理解不能说错,但远远不够。
RAG本质上是一套层层耦合、精密联动的算法体系。从文档怎么切、文本怎么变成向量,到怎么召回、怎么重排、怎么评估,每个环节都有经典的数学理论支撑,系统的性能提升也依赖于各模块算法的精细化迭代。
然而,RAG的算法研究在学术界和舆论中存在感很低。没有大模型预训练那样的颠覆性突破,没有多模态那样的炫酷展示,甚至很多人把RAG带来的答案质量提升归功于大模型本身。但这恰恰说明:RAG是幕后功臣,是大模型产业落地的核心底座。
本篇文章帮你厘清RAG背后的算法逻辑:它到底由哪些环节构成?每个环节解决什么问题?用什么数学方法?
如果你正准备深入RAG的工程优化,希望这篇文章能帮你建立一个清晰的概念框架。
欢迎关注【深蓝AI】
将持续分享人工智能领域前沿动态👇
深蓝AI
1
—
RAG的核心逻辑
纯大模型生成依赖训练参数的静态知识,相当于“凭记忆作答”,面对实时信息、私有数据极易出错。RAG采用先检索、后生成的模式,让模型“先查可信资料,再组织答案”,从根源降低幻觉、提升答案可信度。
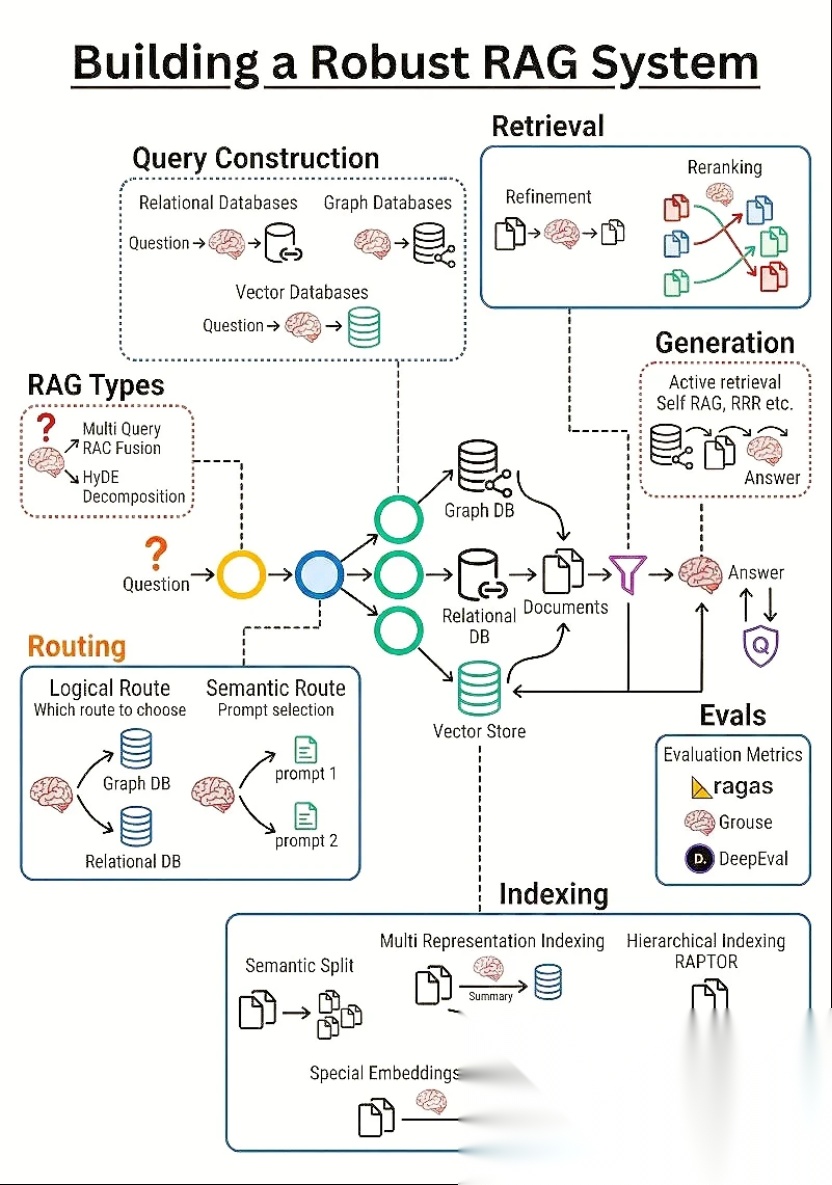
RAG标准算法链路:
原始文档分块预处理→文本嵌入向量化并构建向量库→用户问题同步向量化→稀疏+稠密检索召回候选片段→重排序精细筛选→大模型结合检索上下文生成答案。
系统整体精度、召回率、响应速度,完全由各环节算法决定。
听起来很简单,其实坑很多。
- 分块断裂:把一份合同按512个token切成块,恰好切到两条之间:一个完整的免责条款被劈成两半,断章取义了。用户问「甲方的免责条件是什么」,检索到了上半截,模型根据半截信息一本正经地胡说八道。
- 检索歧义:用户问「苹果的最新财报」,向量检索把「苹果园的种植技巧」排在了前面。因为在向量空间里,两个「苹果」的距离并不远。BM25这种传统的关键词匹配反而能搞定这种场景,但纯向量检索搞不定。
- 生成幻觉:即使检索到了正确的文档,模型在生成时依然可能把检索内容和自己的参数知识混在一起,输出一个看起来合理但实际上错误的答案。
这些问题巨头都不一定搞得定。
比如2024年WWDC,苹果以"Apple Intelligence"为主打功能,宣布将AI能力深度集成进iPhone、iPad和Mac。这是苹果官方第一次正面回应AI浪潮。但直到2026,邮件摘要功能总结了一封长邮件,摘要本身包含的事实错误可能比原文还多。(参考https://mp.weixin.qq.com/s/I8aM5mVz936Bjd2I0bIxuw )
要理解这些坑从何而来,我们需要拆解RAG的底层算法。
深蓝AI
2
—
基础层算法:RAG 的前置核心基石
基础层算法负责原始数据清洗、语义数字化映射,为后续精准检索提供高质量输入。
1. 智能文本分块算法:解决上下文断裂与信息冗余
长文本无法直接用于精准检索:块过大会冗余、块过小会断裂语义。文本分块的核心目标是平衡语义完整性与检索精细度,工业界主流为滑动窗口分块算法。
设置固定窗口长度与滑动步长,步进式切割全文,通过窗口重叠保留上下文关联,避免语义截断,保证分块语义连贯。
其中:为第 个文本分块, 为原始全文文本, 为窗口长度(单块最大字数), 为滑动步长。
重叠率计算公式:
行业通用重叠率为10%-20%,可兼顾语义完整与内容精简。进阶语义分块则依据语义相似度动态切分,让分块边界贴合真实语义段落,进一步提升检索质量。
2. 向量嵌入算法(Embedding):文字到数学空间的映射
计算机无法直接理解自然语言,向量嵌入(Embedding)是RAG的语义映射核心,作用是将离散文本映射为高维连续向量,使语义相近的文本在向量空间中距离更近,实现可量化的语义匹配。
将任意文本转换为数百至数千维数字向量,各维度对应文本的主题、逻辑、关键词等语义特征,让语义相似度可通过空间距离计算。
嵌入算法本质是拟合一个映射函数 ,满足:
其中: 为 维实数向量空间, 为向量维度(常见768维、1024维), 为嵌入模型的可学习参数。
嵌入算法本身就是大模型,ollama上随处可见embedding model。
高质量嵌入模型满足核心约束:文本语义相似度与向量空间距离严格负相关,语义越相近、空间距离越小、匹配分数越高。
文本被分块并向量化后,就进入了检索层。这是决定RAG召回质量的主战场。
深蓝AI
3
—
检索层算法:RAG 精准度的主战场
检索层负责从海量知识库中精准召回有效信息,包含稠密向量检索、BM25稀疏检索、混合检索三类。
1. 余弦相似度算法:向量检索的核心度量标准
文本向量化后,需通过相似度度量匹配问题与文档,余弦相似度是RAG主流稠密检索指标,聚焦向量方向而非长度,不受文本长度干扰,适配语义匹配任务。
将问题向量与文档向量视为高维空间射线,夹角越小、余弦值越接近1,代表语义越相似;夹角越大、语义差异越大。该算法规避了长文本向量模长偏大带来的匹配偏差。
其中: 为用户问题向量, 为文档分块向量, 为两向量点积,、 分别为两个向量的L2范数(模长)。
余弦相似度取值范围为,分数越趋近1匹配效果越好,工程中通常以0.7为筛选阈值。
2. BM25算法:稀疏关键词检索的经典范式
稠密向量检索擅长整体语义匹配,但对专有名词、专业关键词召回不足。
BM25是经典稀疏检索算法,基于关键词统计实现精准匹配,弥补向量检索的实体匹配短板。
BM25 的全称是 Best Matching 25,是 RAG 体系里弥补向量检索短板的核心算法。早期研究者在做检索模型迭代,试了1~24版效果都一般,第25版公式效果最优,因此定名 BM25,沿用至今。
它结合关键词词频、文档长度、关键词稀有度综合打分,抑制长文档天然高分偏差,精准筛选含核心实体关键词的文档。
参数释义:
- :用户提问中的核心关键词
- :关键词 在文档 中的词频
- :关键词 的逆文档频率(衡量关键词稀有度,越稀有权重越高)
- :当前文档长度,:全局文档平均长度
- 、:超参数,行业通用取值 ,
BM25对专业术语、实体名称敏感度极高,是法律、医疗、工业等垂类RAG的核心稀疏检索方案。
3.向量-BM25混合检索算法:兼顾语义与关键词
单一向量检索易丢失关键实体,单一BM25无法理解深层语义。向量-BM25混合检索融合两者优势,是工业界最优落地方案,显著提升召回准确率。
它分别计算归一化后的向量语义分与BM25关键词分,通过加权融合得到最终相关性分数,同时保障语义适配与关键词精准匹配。
融合数学公式如下:
行业常用权重,优先侧重语义匹配,辅以关键词校验,兼顾泛化性与精准性。
检索召回的候选片段往往还比较粗糙,需要进一步提纯。
深蓝AI
4
—
优化层算法:突破RAG精度瓶颈
初轮检索召回的Top-N候选片段仍存在冗余、弱相关内容。优化层算法通过重排序精细提纯、近似检索加速推理,解决RAG“召回不准、检索缓慢”的瓶颈。
1.Cross-Encoder重排序reranking算法:细粒度精准筛选
重排的意思是说,初轮检索返回的TOP N结果不是最优的,有些不相关的回答排在前面,所以要重排。
普通向量检索采用问答独立编码,无法捕捉细粒度交互语义。Cross-Encoder(交叉编码器)通过问答对联合编码,实现高精度相关性判别,是RAG提精的关键算法。
通俗原理是将问题与候选文档拼接为整体输入模型,直接输出0-1相关性概率,精准过滤“语义相似、主题不符”的误召回内容。
核心逻辑公式:
其中: 为问题与文档的拼接序列, 为交叉编码器模型,输出 区间的精准相关性分数,最终按分数重排候选文档,筛选Top-K最优内容送入大模型。
2.HNSW近似最近邻算法:海量向量极速检索
向量库达到百万、千万级规模时,暴力全量遍历耗时极高。HNSW(层次化导航小世界图)是向量数据库核心加速算法,可在精度几乎无损的前提下,大幅提升检索速度,支撑大规模RAG实时推理。
通俗原理是为高维向量构建多层拓扑网络,高层稀疏节点快速粗定位,底层精细匹配,无需遍历全部向量,实现极速近似检索。
HNSW是Milvus、Chroma、FAISS等主流向量库的默认核心算法,有效平衡检索时延与召回率,是工业级RAG的性能底座。
算法优化得再好,也需要科学的评估标准来量化效果。最后我们来看RAG的评估层。
深蓝AI
5
—
评估层算法:量化RAG系统性能
完整RAG体系包含标准化评估算法,用于量化检索排序质量、指导算法调优迭代,行业核心指标为NDCG@K(Normalized Discounted Cumulative Gain at K,归一化折损累积增益)。
它对靠前位置的高相关内容赋予更高权重,惩罚优质内容排序靠后的情况,精准评估检索结果的有序性与有效性。
NDCG@K数学公式如下:
其中, 为前K个检索结果的折损累计增益, 为理想状态下的最大累计增益。DCG全称是Discounted Cumulative Gain,直接翻译为折损累积增益;IDCG全称是Ideal Discounted Cumulative Gain,直接翻译为理想折损累积增益。
代表模型真实排序的折损累计增益,由RAG检索与重排序算法自主完成文档排序,依据模型预测的相关性分数从高到低排布结果,结合相关性分值与对数折损规则计算真实总分,对排名靠后的有效内容进行权重衰减,客观反映模型实际检索排序质量; 为人工标准下的理想最大折损累计增益,以人工标注的绝对最优结果为基准,将所有真实相关文档严格按照相关性等级从高到低完美排序,代入公式计算得出理论满分值,作为统一的归一化基准,消除不同查询样本的分值差异;二者比值计算得到的NDCG@K可标准化评判检索排序优劣,
很自然的,NDCG取值越接近于1,代表检索排序越精准、RAG性能越优。
深蓝AI
6
—
写在最后
RAG 从分块策略、嵌入训练,到多路检索、交叉重排,再到近似加速与评估指标,每个环节都有坚实的数学理论与工程实践支撑。理解这些算法逻辑,是优化生产级 RAG 系统的前提。
当前 RAG 研究的前沿已拓展至多跳检索、迭代修正、Graph RAG、大模型驱动的自适应检索等方向。尽管不像预训练大模型那般炫目,但 RAG 作为大模型产业落地的核心底座,其重要性正日益凸显。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐
 4
4 0
0- 0



 已为社区贡献86条内容
已为社区贡献86条内容

所有评论(0)