【Spark】Spark安装详解
Spark安装详解Spark的详情Spark的安装详解Spark Local的安装Spark Standalone模式Spark On YARN模式Spark HA模式Spark的详情Spark的简绍Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以分布式处理大量集数据的,将大量集数据先拆分,分别进行计算,然
Spark的详情
- Spark的简绍
Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以分布式处理大量集数据的,将大量集数据先拆分,分别进行计算,然后再将计算后的结果进行合并。 - 为什么使用Spark
Spark在存储器内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。Spark允许用户将数据加载至集群存储器,并多次对其进行查询,非常适合用于机器学习算法。
Spark也支持伪分布式(pseudo-distributed)本地模式,不过通常只用于开发或测试时以本机文件系统取代分布式存储系统。在这样的情况下,Spark仅在一台机器上使用每个CPU核心运行程序。 - Spark的优势
更高的性能。因为数据被加载到集群主机的分布式内存中。数据可以被快速的转换迭代,并缓存用以后续的频繁访问需求。在数据全部加载到内存的情况下,Spark可以比Hadoop快100倍,在内存不够存放所有数据的情况下快hadoop10倍。
通过建立在Java,Scala,Python,SQL(应对交互式查询)的标准API以方便各行各业使用,同时还含有大量开箱即用的机器学习库。
与现有Hadoop 1和2.x(YARN)生态兼容,因此机构可以无缝迁移。
方便下载和安装。方便的shell(REPL: Read-Eval-Print-Loop)可以对API进行交互式的学习。
借助高等级的架构提高生产力,从而可以讲精力放到计算上。 - Spark的基本节点名称及作用
Driver
Spark的驱动器,它是执行程序的main方法的进程,它负责创建SparkContext、RDD,以及RDD的转化操作和代码的执行。shell模式下,后台会制动创建Spark驱动器,创建SparkContext对象。
Master
主节点,用于与Worker节点通信,进行资源的调度与分配,接受Driver发来的任务请求,在Standalone模式下才会有Worker节点。
Worker
工作节点,主要用于创建执行器,接受Master的领导,在Worker接收到Matser的请求后会自动启动Executor进程。在standlone节点下才会有Worker节点。
Executor
执行Job Task,返回结果给Driver
Executor是一个工作进程,负责在Spark作业中完成运行任务,任务间互相独立,并行运行 。Executor启动后会反向向Driver注册自己,这样Driver就能更好的服务于自己的Executor。
Task
Task是一个工作任务,一个任务会发给一个Executor
Spark的安装详解
- Spark的安装模式大致可以分为以下几种
local(本地模式):常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
standalone(集群模式):典型的Mater/slave模式,但是会存在单点故障的问题
on yarn(集群模式): 运行在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算
Spark HA解决了单点故障问题
Spark在大多数情况下适合Scala连在一起的,因此我们在安装Spark之前不妨先安装Spark
解压Scala安装包到指定目录下tar -zxvf scala-2.10.4.tgz -C /home/
配置环境变量
# 打开profile文件
vi /etc/profile
# 配置变量
export SCALA_HOME=/home/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin
让变量生效source /etc/profile
测试

Spark Local的安装
解压到指定目录tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /home/
配置环境变量
# 打开profile文件
vi /etc/profile
export SPARK_HOME=/home/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
让变量生效source /etc/profile
测试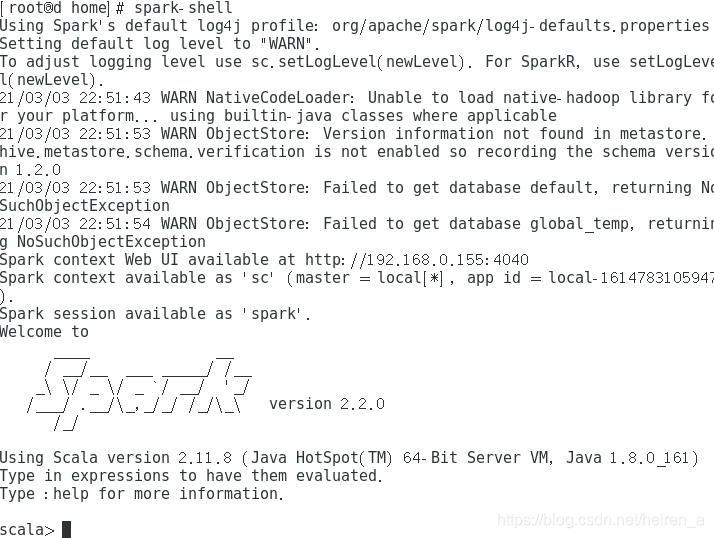
Spark Standalone模式
修改配置文件spark-env.sh
# 如果没有此文件
cp spark-env.sh.template spark-env.sh
export SCALA_HOME=/home/scala-2.10.4
export JAVA_HOME=/home/java/jdk
# 本地安装绑定
export SPARK_MASTER_IP=192.168.0.155
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1G
export SPARK_EXECUTOR_CORES=2
测试
使用启动sbin/start-all.sh脚本进行启动.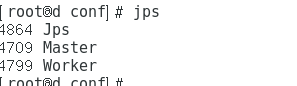
访问WebUI:http://localhost:8080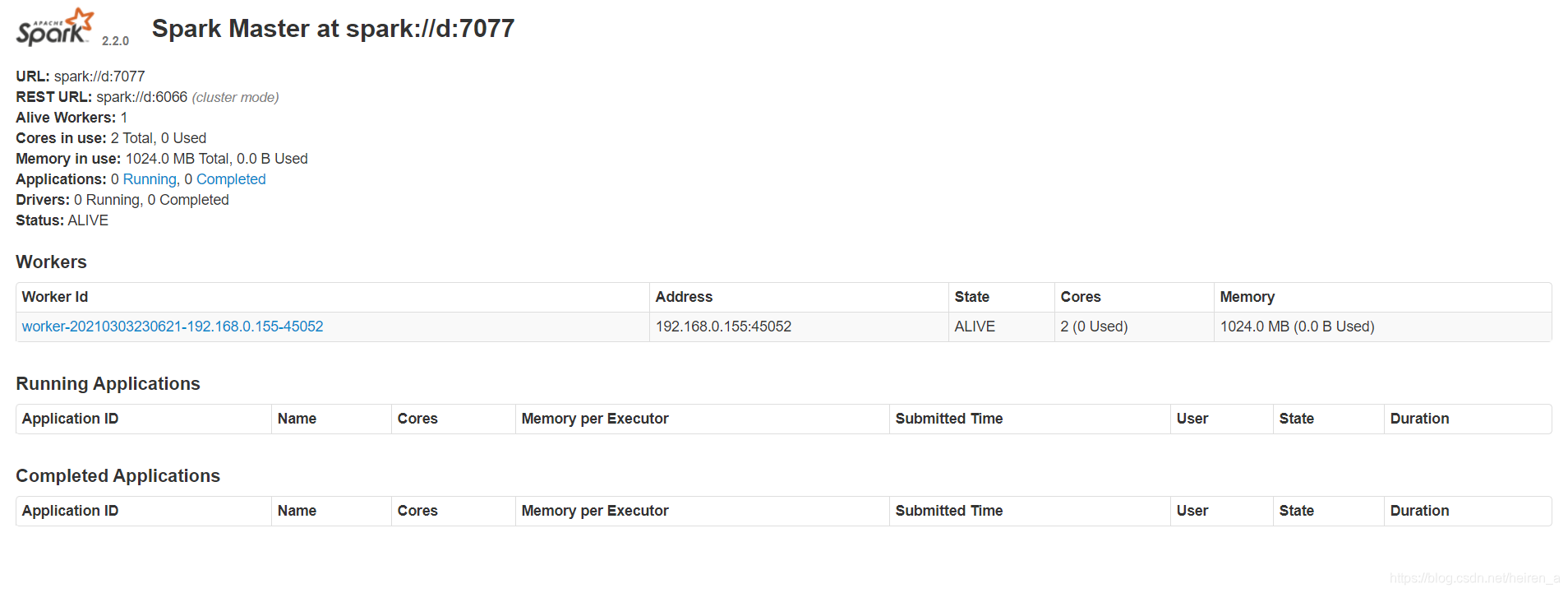
我这个只安装在一台虚拟机上,如果想安装在多台上可以将更改slaves文件,写入从节点的IP地址,然后发送配置好的安装包到各个节点
Spark On YARN模式
此模式要先安装好hadoop,并且开启
修改配置文件spark-env.sh
export SCALA_HOME=/home/scala-2.10.4
export JAVA_HOME=/home/java/jdk
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.0.155
export SPARK_MASTER_PORT=7077
export SPARK_DRIVER_MEMORY=1G
测试开启节点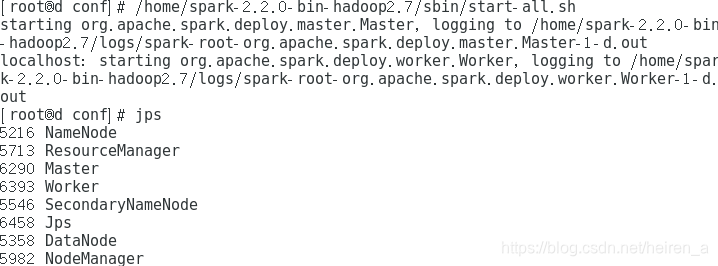
查看WebUI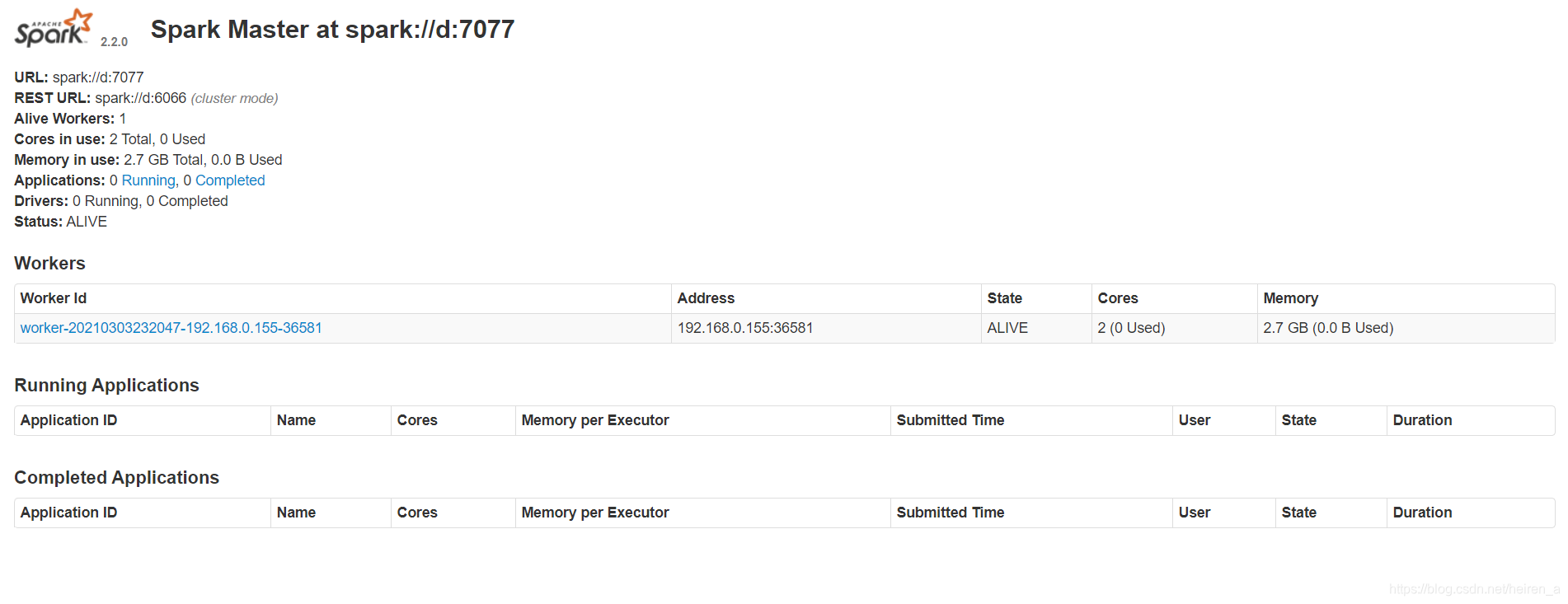
我这个只安装在一台虚拟机上,如果想安装在多台上可以将更改slaves文件,写入从节点的IP地址,然后发送配置好的安装包到各个节点
Spark HA模式
首先安装好Zookeeper,并且开启
配置文件spark-env.sh
export SCALA_HOME=/home/scala-2.10.4
export JAVA_HOME=/home/java/jdk
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
export SPARK_MASTER_PORT=7077
export SPARK_DRIVER_MEMORY=1G
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=a:2181,b:2181,c:2181
-Dspark.deploy.zookeeper.dir=/spark"
修改slaves文件
b
c
将配置好的文件发送到其他俩个节点
scp /home/spark-2.2.0-bin-hadoop2.7 b:/home
scp /home/spark-2.2.0-bin-hadoop2.7 c:/home
start-all.sh开启节点,但是会发现bc节点之开启了work进程,这是因为我们设置了slaves导致的,这里我们可以使用start-mater.sh命令开启全部的master节点,但是我们会发现只有一个节点的master是活跃的,其他都是等待状态
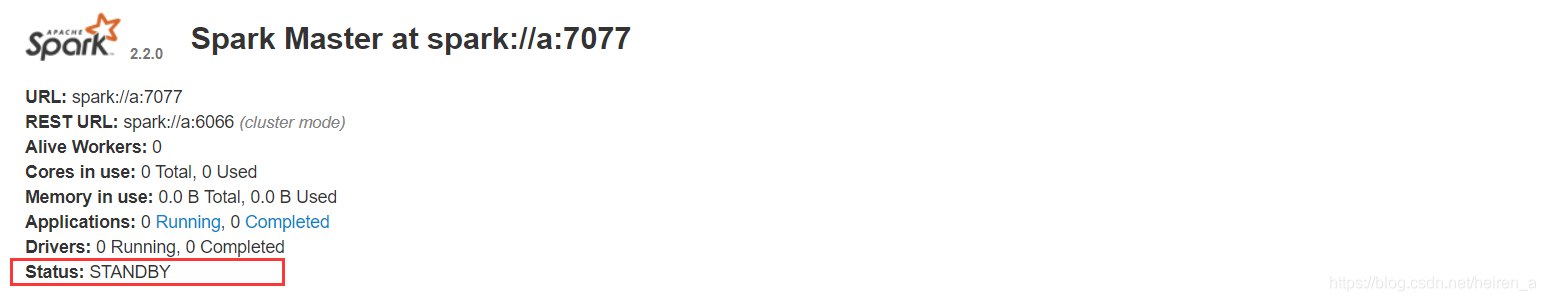


这时我们关闭b节点也就是master活跃的那个节点的master进程stop-master.sh
发现无法方法了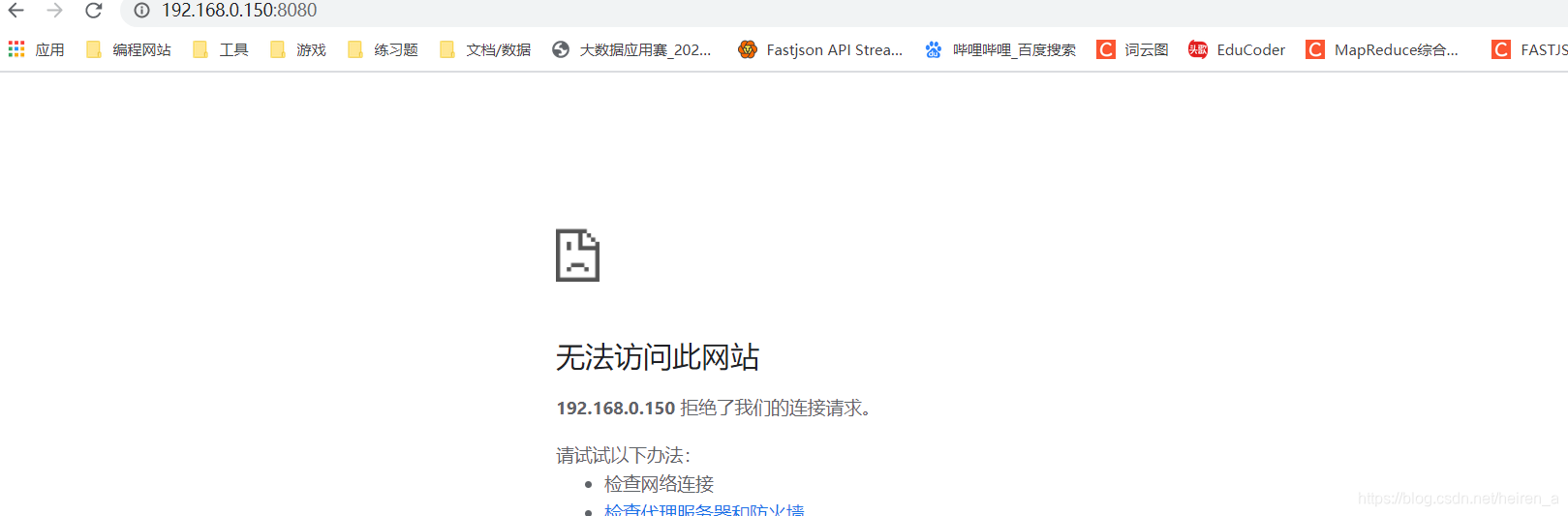
并且此时的c节点变成了活跃的状态

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)