秃头日记(1)
Hadoop分布式文件系统(HDFS):Hadoop的核心组件之一,用于存储大规模数据集,并提供高可靠性和高吞吐量的数据访问。MapReduce:Hadoop的计算模型,用于将大规模数据集分解为小的子任务,并在集群中并行处理。Hive:基于Hadoop的数据仓库工具,提供类似于SQL的查询语言,用于分析和查询大规模数据集。Hadoop YARN:Hadoop的资源管理器,用于管理集群中的计算资源,
1.介绍Hadoop生态圈配图加文字
Hadoop生态圈是指围绕Hadoop分布式计算框架所形成的一系列相关技术和工具。下面是一个简单的Hadoop生态圈配图及其相关介绍:
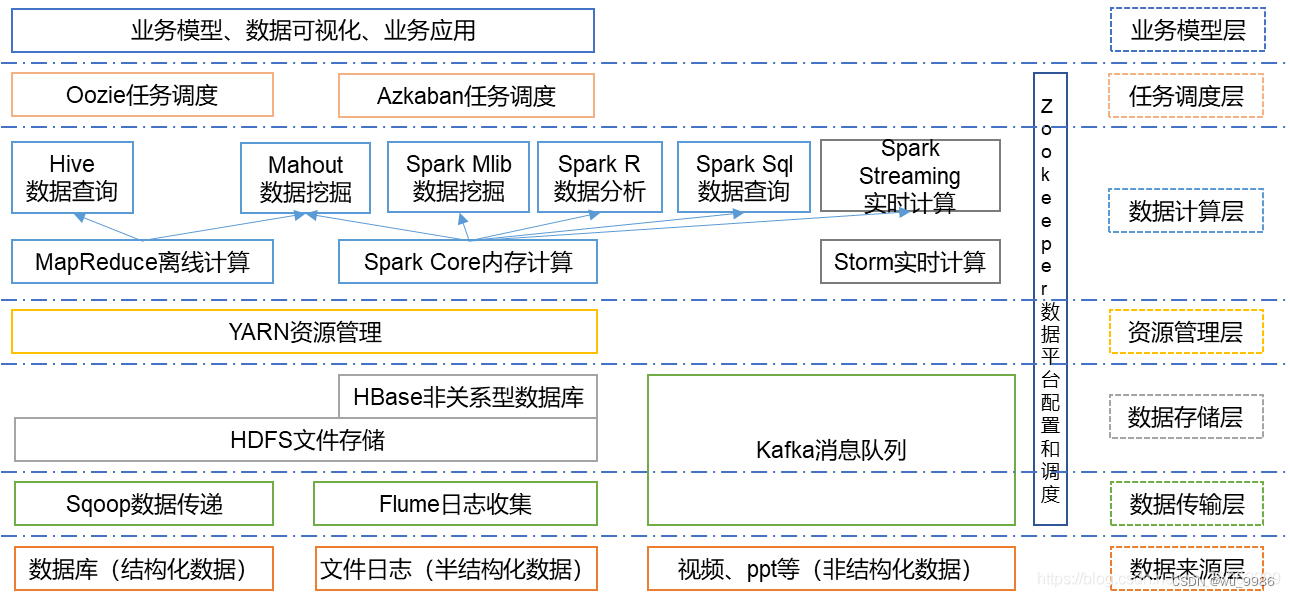
-
Hadoop分布式文件系统(HDFS):Hadoop的核心组件之一,用于存储大规模数据集,并提供高可靠性和高吞吐量的数据访问。
-
Hadoop YARN:Hadoop的资源管理器,用于管理集群中的计算资源,并调度任务执行。
-
MapReduce:Hadoop的计算模型,用于将大规模数据集分解为小的子任务,并在集群中并行处理。
-
Hive:基于Hadoop的数据仓库工具,提供类似于SQL的查询语言,用于分析和查询大规模数据集。
-
Pig:基于Hadoop的数据流编程语言和执行环境,用于快速处理和分析大规模数据。
-
HBase:分布式、可扩展的NoSQL数据库,用于存储大规模结构化数据。
-
Spark:快速、通用的大数据处理引擎,支持内存计算和多种数据处理模式。
-
ZooKeeper:分布式协调服务,用于管理和协调分布式应用程序的配置信息、命名服务等。
-
Flume:用于高效、可靠地收集、聚合和移动大规模日志数据的分布式系统。
-
Kafka:高吞吐量的分布式消息队列系统,用于实时数据流处理。
-
Sqoop:用于在Hadoop和关系型数据库之间进行数据传输的工具。
-
Oozie:用于协调和管理Hadoop作业流程的工作流调度系统。
-
Mahout:基于Hadoop的机器学习库,提供多种机器学习算法和工具。
-
Zeppelin:交互式数据分析和可视化的开源笔记本,支持多种数据处理引擎。
2.详细介绍spark的生态圈,特点
Spark的生态圈是一个功能强大的数据分析系统,旨在提供一站式解决平台,包括内存计算、实时处理、即席查询、机器学习和图处理等多种功能。具体来说,Spark生态圈即BDAS(伯克利数据分析栈)包含了多个组件,如Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等。这些组件能够无缝集成,为用户提供各种数据处理和分析的解决方案。
Spark的特点主要体现在以下几个方面:
高效性:Spark具有出色的执行速度,其DAG执行引擎支持在内存中进行迭代计算,大大提高了处理速度。根据官方数据,当数据从磁盘读取时,Spark的速度是Hadoop MapReduce的10倍以上;而数据从内存中读取时,速度更是高达100多倍。
通用性:Spark的通用性非常强,可以处理多种类型的数据和分析任务。通过其生态圈中的各种组件,Spark可以应对内存计算、实时处理、即席查询、机器学习和图处理等多样化的需求。
易用性:Spark支持多种编程语言,如Python、Java和Scala等,使得用户可以根据自己的熟悉程度和需求选择合适的语言进行编程。特别是Scala语言,其高效性和可拓展性使得复杂的数据处理任务能够用简洁的代码完成。
运行方式多样:Spark可以在多种环境中运行,无论是单机模式还是集群模式,都能够充分发挥其性能优势。这种灵活性使得Spark可以适应各种规模和需求的数据处理任务。
此外,Spark还具有一些其他的技术特点,如有向无环图(DAG)的分布式并行计算框架、提供cache机制以支持多次迭代计算或数据共享、引入RDD(弹性分布式数据集)的抽象以保证数据的高容错性、移动计算而非移动数据等。这些技术特点使得Spark在处理大规模数据时具有更高的效率和稳定性。
总的来说,Spark的生态圈和特点是其强大和灵活性的体现,使得它成为大数据处理和分析领域的首选工具之一。无论是处理结构化数据还是非结构化数据,无论是进行批量处理还是实时分析,Spark都能够提供高效、可靠和灵活的解决方案。
3.详细介绍mapreduce的运行框架并于spark做对比
MapReduce和Spark都是处理大规模数据的分布式计算框架,但它们在运行框架和特性上有显著的区别。
MapReduce的运行框架可以概括为以下四个主要阶段:
Map阶段:在此阶段,输入数据被分割成小块,每个小块被分配给集群中的一个节点进行处理。每个节点上的Map任务读取输入数据块,并生成一系列的键值对作为中间输出。
Shuffle阶段:Map阶段结束后,系统会将具有相同键的中间结果合并在一起,这个过程称为Shuffle。Shuffle涉及到数据的重新分布,以便相同的键能够在同一节点上被处理。
Reduce阶段:在Reduce阶段,每个节点接收Shuffle阶段后具有相同键的数据,并对这些数据进行处理,生成最终的键值对作为输出。
输出阶段:最后,Reduce阶段生成的最终结果被写入到输出文件或数据库中。
MapReduce的运行框架稳定且易于理解,但它也有一些局限性,比如对于迭代算法和实时处理的支持不够高效。每次Map和Reduce操作之间都需要将中间结果写入磁盘,这不仅增加了I/O开销,也限制了处理速度。
相比之下,Spark的运行框架具有以下优势:
基于内存的计算:Spark尽可能地在内存中缓存中间结果,避免了MapReduce中频繁的磁盘I/O操作。这使得Spark在处理迭代算法和实时流数据时具有更高的效率。
有向无环图(DAG)执行计划:Spark将计算任务抽象为DAG,可以更加灵活地安排任务的执行顺序,实现多个任务的并行或串联执行。这大大提高了计算效率,并减少了不必要的数据传输和存储开销。
丰富的API和编程模型:Spark提供了多种编程API,如Scala、Java和Python等,使得开发者可以更加灵活地编写数据处理程序。此外,Spark还支持多种计算模型,如批处理、流处理、图计算和机器学习等,这使得Spark能够应对更广泛的数据处理需求。
总的来说,MapReduce和Spark在运行框架和特性上各有优势。MapReduce稳定且易于理解,适用于离线批处理任务;而Spark则更加灵活和高效,适用于实时处理和复杂计算任务。在实际应用中,可以根据具体需求选择适合的框架进行处理。
4.Linux操作系统简单命令实训练习(要有演示)
5.解释结构化数据和非结构化数据
结构化数据与非结构化数据在定义、特性、存储与处理方式上存在显著的不同。
结构化数据是指可以使用关系型数据库表示和存储的数据,通常表现为二维形式。其特点在于数据以行为单位,每一行数据表示一个实体的信息,且每一行数据的属性是相同的。这样的数据格式严格且统一,便于查询和管理。例如,存储在mysql数据库中的数据或csv文件就是结构化数据的典型代表。
相对而言,非结构化数据则是指那些没有一个预先定义好的数据模型或组织方式的数据。这些数据通常无法用数字或统一的结构来描述和处理,而是需要用到全文文本、图像、声音、影视、超媒体等形式来描述和存储。非结构化数据在实际应用中非常广泛,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等。这些数据存储在分布式文件系统中,其处理和分析通常需要借助特定的工具和技术。
简单来说,结构化数据是高度组织和整齐格式化的数据,便于查询和管理;而非结构化数据则更加灵活多样,需要更复杂的处理和分析技术。两者在数据处理和分析领域都有广泛的应用,根据具体需求选择合适的数据类型和处理方式是非常重要的。
6.解释冷备,热备和温备
冷备、热备和温备是数据备份的三种主要方式,它们在备份过程中对数据库的操作影响、备份时机以及备份的效率和安全性等方面有所不同。
冷备(冷备份):冷备是在关闭数据库并且数据库不能更新的状况下进行的数据库完整备份。也就是说,在进行冷备时,数据库必须停止运行,以保证备份的数据的一致性和完整性。由于备份时需要停止数据库服务,因此这种方式对业务运行有较大影响,通常适用于对业务影响较小的时段进行。冷备的恢复耗时可能较长,且无法适应高要求的灾备发展。
热备(在线备份):热备是在数据库运行时直接进行的备份,对数据库操作没有任何影响。这种方式可以保证数据库的高可用性和业务的连续性,因为备份过程不会中断数据库的正常服务。热备软件或硬件解决方案通常用于解决计划或非计划的系统宕机问题,确保在发生故障时能够迅速恢复服务。
温备:温备介于冷备和热备之间,它在数据库运行时加全局读锁进行备份,保证了备份数据的一致性,但对性能有一定影响。这种方式在备份时数据库仍然可以提供服务,但性能可能会受到一定程度的限制。温备适用于对性能要求不是非常高,但又需要保证数据一致性的场景。
总的来说,这三种备份方式各有特点,需要根据实际的业务需求和系统环境来选择适合的备份方式。在选择备份方式时,需要综合考虑备份的效率、安全性、对业务的影响以及恢复时间等因素。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)