mapreduce作业提交源码解读(创建不同模式下的runner、在工作区间生成切片规划文件和配置文件后提交)
文章目录1.判断作业状态是否为DEFINE后,调用submit方法 1.1 再次确认作业状态,使用新api 1.2 创建连接(不同执行模式,创建不同的runner) 1.3 获取提交器对象 1.4 提交器对象提交作业(生成切片规划文件和配置文件) 1.5 修改状态为RUNNING2.verbose设置为true时,监控和打印job信息提交作业入口boolean b = job.waitF
文章目录
提交作业入口
boolean b = job.waitForCompletion(true);
1.判断作业状态是否为DEFINE后,调用submit方法
public enum JobState {DEFINE, RUNNING};
if (state == JobState.DEFINE) {
submit();
}
1.1 再次确认作业状态,使用新api
ensureState(JobState.DEFINE);
setUseNewAPI();
1.2 创建连接(不同执行模式,创建不同的runner)
connect();
实例化Cluster对象
private synchronized void connect()
throws IOException, InterruptedException, ClassNotFoundException {
if (cluster == null) {
cluster =
ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
public Cluster run()
throws IOException, InterruptedException,
ClassNotFoundException {
return new Cluster(getConfiguration());
}
});
}
}
调用Cluster构造函数时,核心在于通过遍历providerList,判断作业运行在yarn或本地
public Cluster(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
this.conf = conf;
this.ugi = UserGroupInformation.getCurrentUser();
initialize(jobTrackAddr, conf);
}
private void initialize(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
initProviderList();
final IOException initEx = new IOException(
"Cannot initialize Cluster. Please check your configuration for "
+ MRConfig.FRAMEWORK_NAME
+ " and the correspond server addresses.");
if (jobTrackAddr != null) {
LOG.info(
"Initializing cluster for Job Tracker=" + jobTrackAddr.toString());
}
for (ClientProtocolProvider provider : providerList) {
LOG.debug("Trying ClientProtocolProvider : "
+ provider.getClass().getName());
ClientProtocol clientProtocol = null;
try {
if (jobTrackAddr == null) {
clientProtocol = provider.create(conf);
} else {
clientProtocol = provider.create(jobTrackAddr, conf);
}
if (clientProtocol != null) {
clientProtocolProvider = provider;
client = clientProtocol;
LOG.debug("Picked " + provider.getClass().getName()
+ " as the ClientProtocolProvider");
break;
} else {
LOG.debug("Cannot pick " + provider.getClass().getName()
+ " as the ClientProtocolProvider - returned null protocol");
}
} catch (Exception e) {
final String errMsg = "Failed to use " + provider.getClass().getName()
+ " due to error: ";
initEx.addSuppressed(new IOException(errMsg, e));
LOG.info(errMsg, e);
}
}
if (null == clientProtocolProvider || null == client) {
throw initEx;
}
}
YarnClientProtocolProvider读取配置参数,判断是否创建YARNRunner
public static final String FRAMEWORK_NAME = "mapreduce.framework.name";
@Override
public ClientProtocol create(Configuration conf) throws IOException {
if (MRConfig.YARN_FRAMEWORK_NAME.equals(conf.get(MRConfig.FRAMEWORK_NAME))) {
return new YARNRunner(conf);
}
return null;
}
LocalClientProtocolProvider读取配置参数,判断是否创建LocalJobRunner
public static final String FRAMEWORK_NAME = "mapreduce.framework.name";
public static final String NUM_MAPS = "mapreduce.job.maps";
@Override
public ClientProtocol create(Configuration conf) throws IOException {
String framework =
conf.get(MRConfig.FRAMEWORK_NAME, MRConfig.LOCAL_FRAMEWORK_NAME);
if (!MRConfig.LOCAL_FRAMEWORK_NAME.equals(framework)) {
return null;
}
conf.setInt(JobContext.NUM_MAPS, 1);
return new LocalJobRunner(conf);
}
1.3 获取提交器对象
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
1.4 提交器对象提交作业(生成切片规划文件和配置文件)
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
验证作业输出路径
//validate the jobs output specs
checkSpecs(job);
调用OutputFormat实现类的checkOutputSpecs方法(FileOutputFormat)
private void checkSpecs(Job job) throws ClassNotFoundException,
InterruptedException, IOException {
JobConf jConf = (JobConf)job.getConfiguration();
// Check the output specification
if (jConf.getNumReduceTasks() == 0 ?
jConf.getUseNewMapper() : jConf.getUseNewReducer()) {
org.apache.hadoop.mapreduce.OutputFormat<?, ?> output =
ReflectionUtils.newInstance(job.getOutputFormatClass(),
job.getConfiguration());
output.checkOutputSpecs(job);
} else {
jConf.getOutputFormat().checkOutputSpecs(jtFs, jConf);
}
}
public abstract RecordWriter<K, V>
getRecordWriter(TaskAttemptContext job
) throws IOException, InterruptedException;
public void checkOutputSpecs(JobContext job
) throws FileAlreadyExistsException, IOException{
// Ensure that the output directory is set and not already there
Path outDir = getOutputPath(job);
if (outDir == null) {
throw new InvalidJobConfException("Output directory not set.");
}
// get delegation token for outDir's file system
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { outDir }, job.getConfiguration());
if (outDir.getFileSystem(job.getConfiguration()).exists(outDir)) {
throw new FileAlreadyExistsException("Output directory " + outDir +
" already exists");
}
}
获取作业的临时工作区间
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);

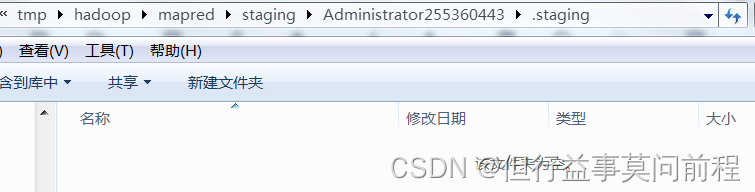
获取jobId
JobID jobId = submitClient.getNewJobID();
在临时工作区间后拼接jobId,生成job提交路径
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
拷贝配置文件和jar
copyAndConfigureFiles(job, submitJobDir);
/**
* configure the jobconf of the user with the command line options of
* -libjars, -files, -archives.
* @param job
* @throws IOException
*/
private void copyAndConfigureFiles(Job job, Path jobSubmitDir)
throws IOException {
Configuration conf = job.getConfiguration();
boolean useWildcards = conf.getBoolean(Job.USE_WILDCARD_FOR_LIBJARS,
Job.DEFAULT_USE_WILDCARD_FOR_LIBJARS);
JobResourceUploader rUploader = new JobResourceUploader(jtFs, useWildcards);
rUploader.uploadResources(job, jobSubmitDir);
// Get the working directory. If not set, sets it to filesystem working dir
// This code has been added so that working directory reset before running
// the job. This is necessary for backward compatibility as other systems
// might use the public API JobConf#setWorkingDirectory to reset the working
// directory.
job.getWorkingDirectory();
}
提交到集群时,需要上传所需的文件
private void uploadResourcesInternal(Job job, Path submitJobDir)
throws IOException {
Configuration conf = job.getConfiguration();
short replication =
(short) conf.getInt(Job.SUBMIT_REPLICATION,
Job.DEFAULT_SUBMIT_REPLICATION);
if (!(conf.getBoolean(Job.USED_GENERIC_PARSER, false))) {
LOG.warn("Hadoop command-line option parsing not performed. "
+ "Implement the Tool interface and execute your application "
+ "with ToolRunner to remedy this.");
}
//
// Figure out what fs the JobTracker is using. Copy the
// job to it, under a temporary name. This allows DFS to work,
// and under the local fs also provides UNIX-like object loading
// semantics. (that is, if the job file is deleted right after
// submission, we can still run the submission to completion)
//
// Create a number of filenames in the JobTracker's fs namespace
LOG.debug("default FileSystem: " + jtFs.getUri());
if (jtFs.exists(submitJobDir)) {
throw new IOException("Not submitting job. Job directory " + submitJobDir
+ " already exists!! This is unexpected.Please check what's there in"
+ " that directory");
}
// Create the submission directory for the MapReduce job.
submitJobDir = jtFs.makeQualified(submitJobDir);
submitJobDir = new Path(submitJobDir.toUri().getPath());
FsPermission mapredSysPerms =
new FsPermission(JobSubmissionFiles.JOB_DIR_PERMISSION);
mkdirs(jtFs, submitJobDir, mapredSysPerms);
if (!conf.getBoolean(MRJobConfig.MR_AM_STAGING_DIR_ERASURECODING_ENABLED,
MRJobConfig.DEFAULT_MR_AM_STAGING_ERASURECODING_ENABLED)) {
disableErasureCodingForPath(submitJobDir);
}
// Get the resources that have been added via command line arguments in the
// GenericOptionsParser (i.e. files, libjars, archives).
Collection<String> files = conf.getStringCollection("tmpfiles");
Collection<String> libjars = conf.getStringCollection("tmpjars");
Collection<String> archives = conf.getStringCollection("tmparchives");
String jobJar = job.getJar();
// Merge resources that have been programmatically specified for the shared
// cache via the Job API.
files.addAll(conf.getStringCollection(MRJobConfig.FILES_FOR_SHARED_CACHE));
libjars.addAll(conf.getStringCollection(
MRJobConfig.FILES_FOR_CLASSPATH_AND_SHARED_CACHE));
archives.addAll(conf
.getStringCollection(MRJobConfig.ARCHIVES_FOR_SHARED_CACHE));
Map<URI, FileStatus> statCache = new HashMap<URI, FileStatus>();
checkLocalizationLimits(conf, files, libjars, archives, jobJar, statCache);
Map<String, Boolean> fileSCUploadPolicies =
new LinkedHashMap<String, Boolean>();
Map<String, Boolean> archiveSCUploadPolicies =
new LinkedHashMap<String, Boolean>();
uploadFiles(job, files, submitJobDir, mapredSysPerms, replication,
fileSCUploadPolicies, statCache);
uploadLibJars(job, libjars, submitJobDir, mapredSysPerms, replication,
fileSCUploadPolicies, statCache);
uploadArchives(job, archives, submitJobDir, mapredSysPerms, replication,
archiveSCUploadPolicies, statCache);
uploadJobJar(job, jobJar, submitJobDir, replication, statCache);
addLog4jToDistributedCache(job, submitJobDir);
// Note, we do not consider resources in the distributed cache for the
// shared cache at this time. Only resources specified via the
// GenericOptionsParser or the jobjar.
Job.setFileSharedCacheUploadPolicies(conf, fileSCUploadPolicies);
Job.setArchiveSharedCacheUploadPolicies(conf, archiveSCUploadPolicies);
// set the timestamps of the archives and files
// set the public/private visibility of the archives and files
ClientDistributedCacheManager.determineTimestampsAndCacheVisibilities(conf,
statCache);
// get DelegationToken for cached file
ClientDistributedCacheManager.getDelegationTokens(conf,
job.getCredentials());
}
生成切片,并返回切片个数
int maps = writeSplits(job, submitJobDir);
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job,
Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
默认使用TextInputFormat的getSplits方法,形成切片规划文件
@SuppressWarnings("unchecked")
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
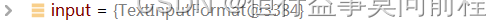
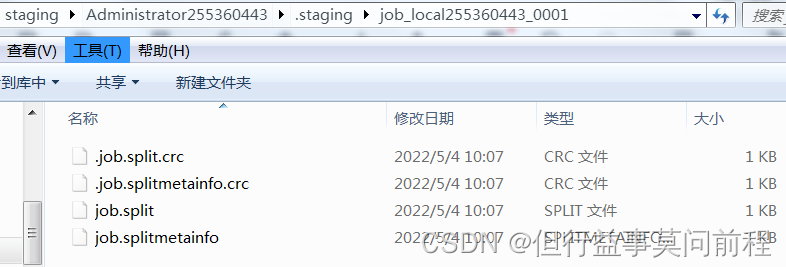
根据切片个数,设置MapTask个数
/* Config for Limit on the number of map tasks allowed per job
* There is no limit if this value is negative.
*/
public static final String JOB_MAX_MAP =
"mapreduce.job.max.map";
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP,
MRJobConfig.DEFAULT_JOB_MAX_MAP);
把配置文件真正写入提交目录
// Write job file to submit dir
writeConf(conf, submitJobFile);
private void writeConf(Configuration conf, Path jobFile)
throws IOException {
// Write job file to JobTracker's fs
FSDataOutputStream out =
FileSystem.create(jtFs, jobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
try {
conf.writeXml(out);
} finally {
out.close();
}
}
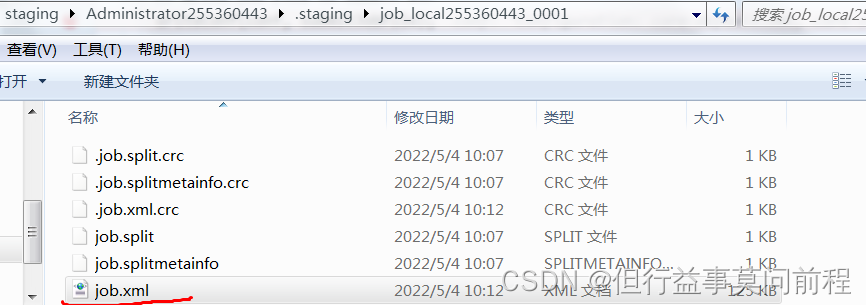
真正提交job,不同的执行模式调用不同的runner(YARNRunner\LocalJobRunner)
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
1.5 修改状态为RUNNING
state = JobState.RUNNING;
2.verbose设置为true时,监控和打印job信息
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)