人工智能中的概率入门基础概念
就像万事万物的不变规律是永远在变化一样,我们做事的风格永远是希望掌控全局和结果,无论大事小事都希望将成功的可能性变成100%,但是大多数情况下,最大的确定性是就是结果永远都是不确定的。这话听起来绕口,其实就是这个世界很难100%的精准,复杂性和偶然性无处不在。概率论为我们提供了有效处理不确定性的工具,它为不确定事件提供了量化的框架,帮助我们在无法确定结果的情况下依然做出合理的推断和决策。
前言-Preface
就像万事万物的不变规律是永远在变化一样,我们做事的风格永远是希望掌控全局和结果,无论大事小事都希望将成功的可能性变成100%,但是大多数情况下,最大的确定性是就是结果永远都是不确定的。这话听起来绕口,其实就是这个世界很难100%的精准,复杂性和偶然性无处不在,比如天气预报也很难准确预测明天是晴天还是下雨,股票价格会涨还是跌?如果涉及到人类复杂心理变化的因素,就更加复杂,试想一下,假如没有客观标准,你的一次小错误受到的批评和惩罚会不会跟领导的心情有很大的关系?对于一直在追求100%正确的传统软件工程人员来说,一个反常识的客观事实是,计算机进行数学计算尤其是浮点数计算时,结果也不是完全精准的(因该问题有点儿复杂,且不属于本文主题,留待感兴趣的读者自己找一下原因)。
正因为不确定性的普遍性,而我们又想从中寻找规律,增加确定性,就产生了概率论这门学科。概率论就是用于表示不确定性的数学框架,通过提供量化不确定性的方法,来指导人们的决策。正如我们在文章“AI背后的数学力量”一文中提到的,概率也是人工智能背后重要的数学理论基础,同时可以说,人工智能本身就是在最大可能的增加度量结果,以更好地帮助人们作出正确的决策。本文我们将一起了解一下概率论中与人工智能相关的基本概念。
概率论是解锁不确定性的“钥匙”-Probability Theory is a tool for quantifying uncertainty
如前言所述,我们这个世界复杂多变,不确定性无处不在,那么在人工智能专业领域中,不确定性都有哪些情况呢?
1. 不确定性的来源
在人工智能领域,不确定性(Uncertainty)的原因主要分为以下三类:
-
被建模系统本身的随机特性:许多现实世界系统本质上都是随机的,这意味着即使是在相同的条件下,系统的行为也可能会有所不同。这种内在的随机性是不可避免的,因此我们需要使用概率模型来描述这些系统。
例如:在抛硬币的实验中,即使硬币的质量分布和抛掷方式完全相同,硬币落地时正面朝上还是反面朝上的结果仍然是随机的。这种随机性是硬币实验本身的固有特性,因此我们使用概率来描述正面朝上的可能性(假设为50%)。
-
无法全面观测被建模系统的所有特征:在许多情况下,我们无法获得被建模系统的完整信息。这可能是因为观测设备的限制、信息本身的隐藏性或者观测成本过高。例如,在自动驾驶中,摄像头、雷达等传感器提供的信息可能受限于环境条件(如恶劣天气、障碍物、突然出现的动物),无法完整呈现周围的状况。
-
不完全建模:现实世界的复杂性远远超出了任何模型的描述能力。因此,我们通常使用简化的模型来近似现实,这些模型往往无法完全捕捉到所有相关的细节。天气预报 天气预报模型通常是基于大气物理学的简化模型,它们无法考虑到所有影响天气的因素,如微尺度气流、地形细节等。因此,天气预报总是存在一定的不确定性,比如预测明天的降雨概率时,模型可能会给出一个范围而不是一个确切的值。
2. 概率论的作用
概率论为我们提供了有效处理不确定性的工具,它为不确定事件提供了量化的框架,帮助我们在无法确定结果的情况下依然做出合理的推断和决策。主要包括:
1)量化不确定性
概率论为不确定性提供了一个精确的语言。例如,在抛硬币实验中,虽然我们无法预知一次具体的抛掷结果,但可以确定“正面”或“反面”出现的概率是 50%。这种概率化的描述让我们能够理解随机现象的规律,即便每次结果不确定,长期来看可以预测整体的分布和趋势。
2)分析不确定性
通过条件概率,我们可以知道在给定某些信息的情况下,某个事件发生的概率,这为我们提供了进行因果推理和预测的工具。当我们考虑多个随机变量时,联合概率分布可以描述这些变量共同出现的概率,帮助我们理解变量间的相互关系。
3)量化决策优劣
概率论中的期望值概念可以帮助我们在不确定性下做出最优决策。期望值考虑了所有可能的结果及其概率,从而提供了一个决策的量化依据。另外,通过方差、标准差等统计量,我们可以量化决策的风险,从而在不确定性下做出更加谨慎的决策。
针对不确定性来源情况,解决方式可以概要描述为:
-
被建模系统本身的随机特性:通过定义随机过程的概率分布(如泊松分布、正态分布等),我们可以模拟系统的随机行为,并预测未来的可能状态。
-
无法全面观测被建模系统的所有特征:使用贝叶斯推理,我们可以结合先验知识和观测数据来推断未观测到的特征的概率分布,从而减少观测不确定性。
-
不完全建模:通过敏感性分析和模型校准,我们可以评估模型简化对结果的影响,并通过概率模型来量化这种由于模型不完美带来的不确定性。
概率论中的基础概念-Basic Concepts in Probability Theory
让我们从基础概念入手,逐步掌握人工智能中重要的基础学科,即处理不确定的“钥匙”-概率论。
1. 概率分布
通俗地讲,概率分布就是描述所有结果的可能性大小情况。想象一个骰子,它的每个面都有相等的概率出现,那么,这个骰子所有可能出现的点数(1-6)以及对应的概率就构成了一个概率分布。
1)概率分布的定义
概率分布是一个函数,它给出了随机变量取每一个可能值的概率。对于离散随机变量,这个函数称为概率质量函数(Probability Mass Function, PMF);对于连续随机变量,这个函数称为概率密度函数(Probability Density Function, PDF)。
-
离散随机变量的概率分布
离散随机变量是那些只能取有限个或可数无限多个值的变量。概率质量函数(PMF)定义了这个随机变量取每一个可能值的概率。
例如,考虑一个抛掷公平六面骰子的实验,随机变量X代表骰子的点数。X的可能值为{1, 2, 3, 4, 5, 6},其PMF可以表示为:
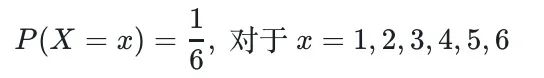
-
连续随机变量的概率分布
连续随机变量是那些可以在一个区间内取任意值的变量。概率密度函数(PDF)描述了随机变量在特定区间内取值的概率密度。
例如,正态分布(也称为高斯分布)是最常见的连续分布之一。其PDF由以下公式给出:
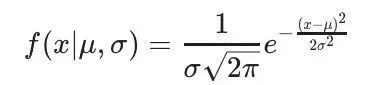
其中,μ是分布的均值,σ是分布的标准差。
2)特性
-
概率分布有非负性和归一性两个特性:
-
非负性:对于所有的X,PMF和PDF结果都是非负的。
-
归一性:所有可能值的概率之和(对于离散随机变量)或概率密度下的面积(对于连续随机变量)等于1。
2. 边缘概率
边缘概率,顾名思义,就是从某个涉及多个变量的联合概率分布(联合概率指多个随机变量同时取特定值的概率)中,将关注点放在单个随机变量上时得到的概率分布。也就是说,它描述的是单个随机变量的概率分布,而忽略了其他随机变量的影响。想象一个二维表格,每一行代表一个随机变量X的取值,每一列代表另一个随机变量Y的取值。表格中的每个单元格表示X和Y同时取到对应值的概率(即联合概率)。如果我们只关注X的概率分布,那么我们可以将每一行对应的概率相加,得到X在不同取值下的概率,这就是X的边缘概率。
1)边缘概率的定义
假设有两个随机变量X 和Y,它们的联合概率分布P(X,Y)是已知的。边缘概率P(X)表示随机变量X 发生的概率,无需关心Y的取值。对于离散变量,公式为:P(X)=∑yP(X,Y=y),即通过求和得到边缘概率;而对于连续变量,则通过积分:P(X)=∫P(X,Y)dY。
2)示例
假设有以下两个离散随机变量X、Y的联合概率分布如下表所示:
| X\Y | 1 | 2 | P(X=x) |
| 1 | 0.1 | 0.2 | 0.3 |
| 2 | 0.1 | 0.2 | 0.3 |
| P(Y=y) | 0.2 | 0.4 | 1 |
要找到X的边缘概率分布,我们需要对每一行的概率进行求和:
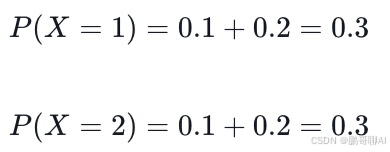
同样,要找到Y的边缘概率分布,我们需要对每一列的概率进行求和:
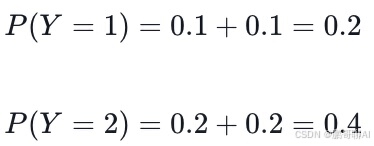
3. 条件概率
很多时候,我们要知道某个事件在给定其他事件发生的前提下,该事件出现的概率就是条件概率。条件概率在人工智能中是非常重要的概念,应用的场景包括:
-
刻画事件之间的依赖关系:条件概率可以帮助我们量化事件之间的依赖关系。例如,在抽牌游戏中,抽到一张黑桃的概率在已知抽到一张牌是A的情况下会发生变化。
-
进行因果推理:通过条件概率,我们可以进行一些简单的因果推理。例如,如果知道某种疾病与某种生活习惯有很强的条件概率联系,那么我们可以推测这种生活习惯可能是导致这种疾病的原因之一。
-
构建概率模型:条件概率是许多概率模型的基础,例如贝叶斯网络、马尔可夫模型等。
1)条件概率的定义
设A和B是样本空间Ω中的两个事件,且P(B)>0,事件A在事件B已经发生的条件下的条件概率记作P(A|B),定义为:
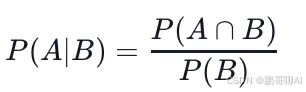
其中,P(A∩B)是事件A和事件B同时发生的概率,P(B)是事件P(B)是事件B发生的概率。
2)特性
-
范围:条件概率的值总是在0和1之间,即0<=P(A|B)<=1。
-
非负性:条件概率总是非负的。
-
归一性:如果事件B发生,则在B发生的条件下A的条件概率之和等于1。
3)示例
假设我们有52张扑克牌,我们想知道在抽到一张红牌的情况下,抽到一张A的概率。
-
事件A:抽到一张A
-
事件B:抽到一张红牌
我们可以用条件概率公式来计算:P(A|B) = P(A ∩ B) / P(B) = (4/52) / (26/52) = 1/13。
4. 期望、方差和协方差
简单来说,期望(Expectation)描述随机变量的中心位置,方差(Variance)描述随机变量的离散程度,协方差(Covariance)描述两个随机变量之间的线性关系。
1)期望
期望值反映了随机变量的平均趋势,描述了其中心位置。在机器学习中,期望值通常用于衡量模型的预测结果或损失函数的期望表现。
对于离散型随机变量E(X) 的公式为:
![]()
对于连续型随机变量E(X) 的公式为:
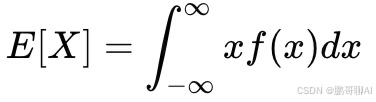
其中,f(x)是概率密度函数。
2)方差
方差描述了随机变量与其期望之间的离散程度,表示变量的波动或不确定性。方差越大,随机变量的取值偏离期望的程度越大。方差可以衡量模型预测的稳定性。对于随机变量XX,其方差Var(X)\text{Var}(X)的定义为:
![]()
3)协方差
协方差衡量了两个随机变量之间的线性相关性,反映了它们如何一起变化。对于两个随机变量X 和Y,协方差Cov(X,Y)的定义为:
![]()
协方差的应用在之前的文章“主成分分析PCA详解”中曾经提到过,感兴趣的读者可以参考这篇文章。
结语
Epilogue
通过上述内容,我们开启了了解概率论这门人工智能重要支撑学科的旅程,本文主要对概率论的一些基础概念进行了介绍,后续我们将逐步深入探讨知识细节,希望大家持续关注鹏哥聊AI和微信公众号:modatechsub。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 58
58 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)