深度学习项目训练环境多任务支持:图像分类/目标检测基础模块预留接口扩展说明
本文介绍了如何在星图GPU平台自动化部署深度学习项目训练环境镜像,该环境专为计算机视觉任务设计,支持图像分类、目标检测等多种任务。通过预置的模块化接口和统一规范,用户可快速构建和训练AI模型,应用于智能安防、自动驾驶等场景中的视觉识别与处理。
深度学习项目训练环境多任务支持:图像分类/目标检测基础模块预留接口扩展说明
1. 环境概述与核心特性
深度学习项目训练环境是一个专为计算机视觉任务设计的完整开发平台,基于PyTorch框架构建,预装了深度学习开发所需的所有核心依赖。这个环境最大的特点是开箱即用,无需繁琐的环境配置,上传训练代码即可立即开始模型训练。
环境采用模块化设计,预留了丰富的接口扩展能力,支持图像分类、目标检测、实例分割等多种计算机视觉任务。无论是学术研究还是工业应用,这个环境都能提供稳定可靠的训练支持。
核心环境配置:
- 深度学习框架:PyTorch 1.13.0 + CUDA 11.6
- 编程语言:Python 3.10.0
- 视觉处理库:torchvision 0.14.0, OpenCV, PIL
- 科学计算:NumPy, Pandas, SciPy
- 可视化工具:Matplotlib, Seaborn, TensorBoard
2. 多任务支持架构设计
2.1 基础训练模块接口
环境内置的基础训练模块采用高度模块化的设计,通过统一的接口规范支持多种视觉任务。核心训练类预留了以下关键接口:
class BaseTrainer:
def __init__(self, config):
# 模型初始化接口
self.model = self._init_model(config)
# 数据加载接口
self.train_loader, self.val_loader = self._init_dataloader(config)
# 优化器接口
self.optimizer = self._init_optimizer(config)
# 损失函数接口
self.criterion = self._init_criterion(config)
def train_epoch(self):
# 训练周期接口
pass
def validate(self):
# 验证接口
pass
def save_checkpoint(self):
# 模型保存接口
pass
def load_checkpoint(self):
# 模型加载接口
pass
2.2 数据加载器扩展接口
环境支持多种数据格式和标注方式,通过统一的数据加载接口实现多任务支持:
class MultiTaskDataLoader:
def __init__(self, task_type):
self.task_type = task_type # 'classification', 'detection', 'segmentation'
def load_dataset(self, data_path, transform=None):
if self.task_type == 'classification':
return self._load_classification_data(data_path, transform)
elif self.task_type == 'detection':
return self._load_detection_data(data_path, transform)
elif self.task_type == 'segmentation':
return self._load_segmentation_data(data_path, transform)
def _load_classification_data(self, data_path, transform):
# 图像分类数据加载实现
dataset = datasets.ImageFolder(data_path, transform=transform)
return dataset
def _load_detection_data(self, data_path, transform):
# 目标检测数据加载实现
# 支持COCO、VOC、YOLO等多种格式
pass
def _load_segmentation_data(self, data_path, transform):
# 实例分割数据加载实现
pass
3. 快速上手与实践指南
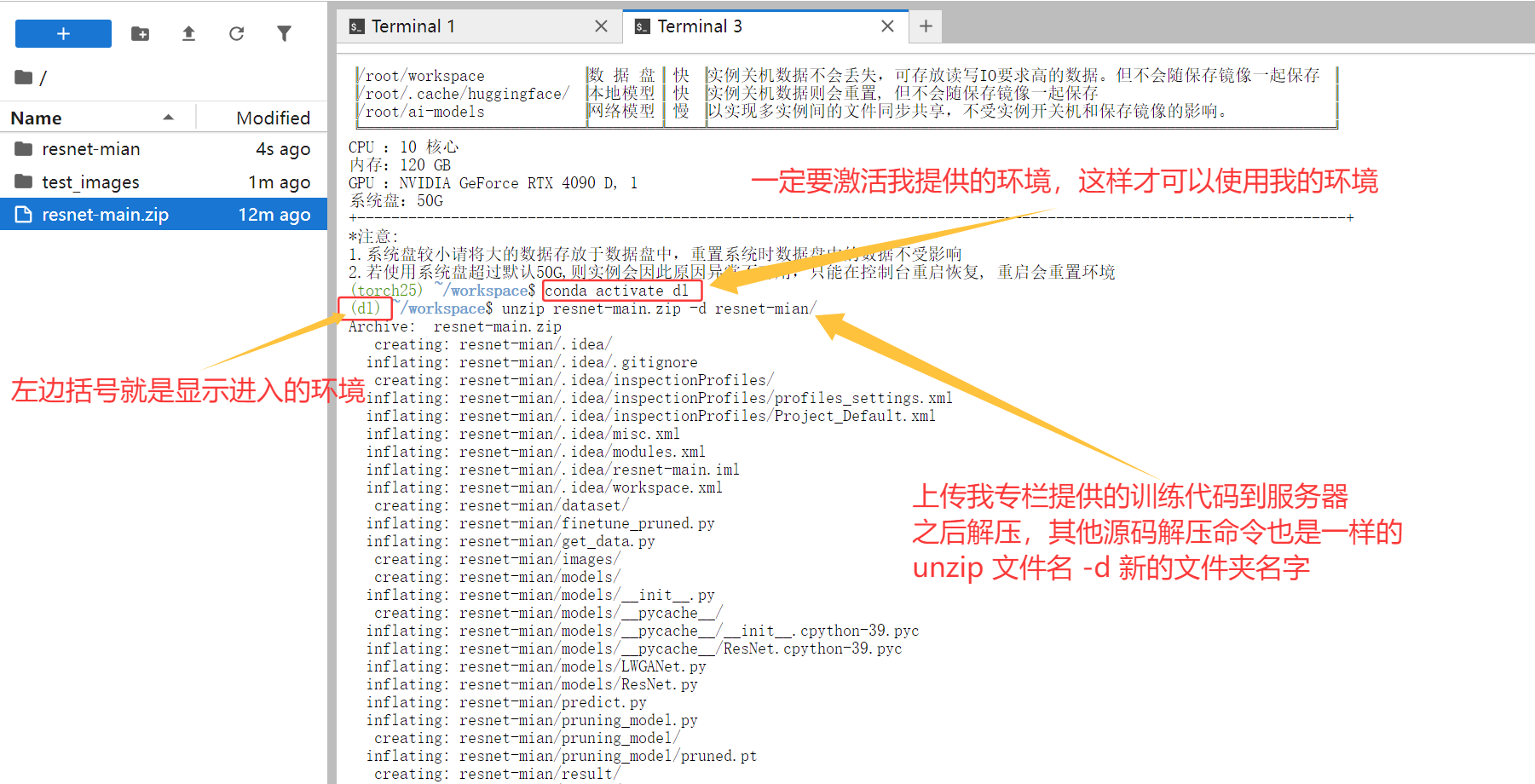
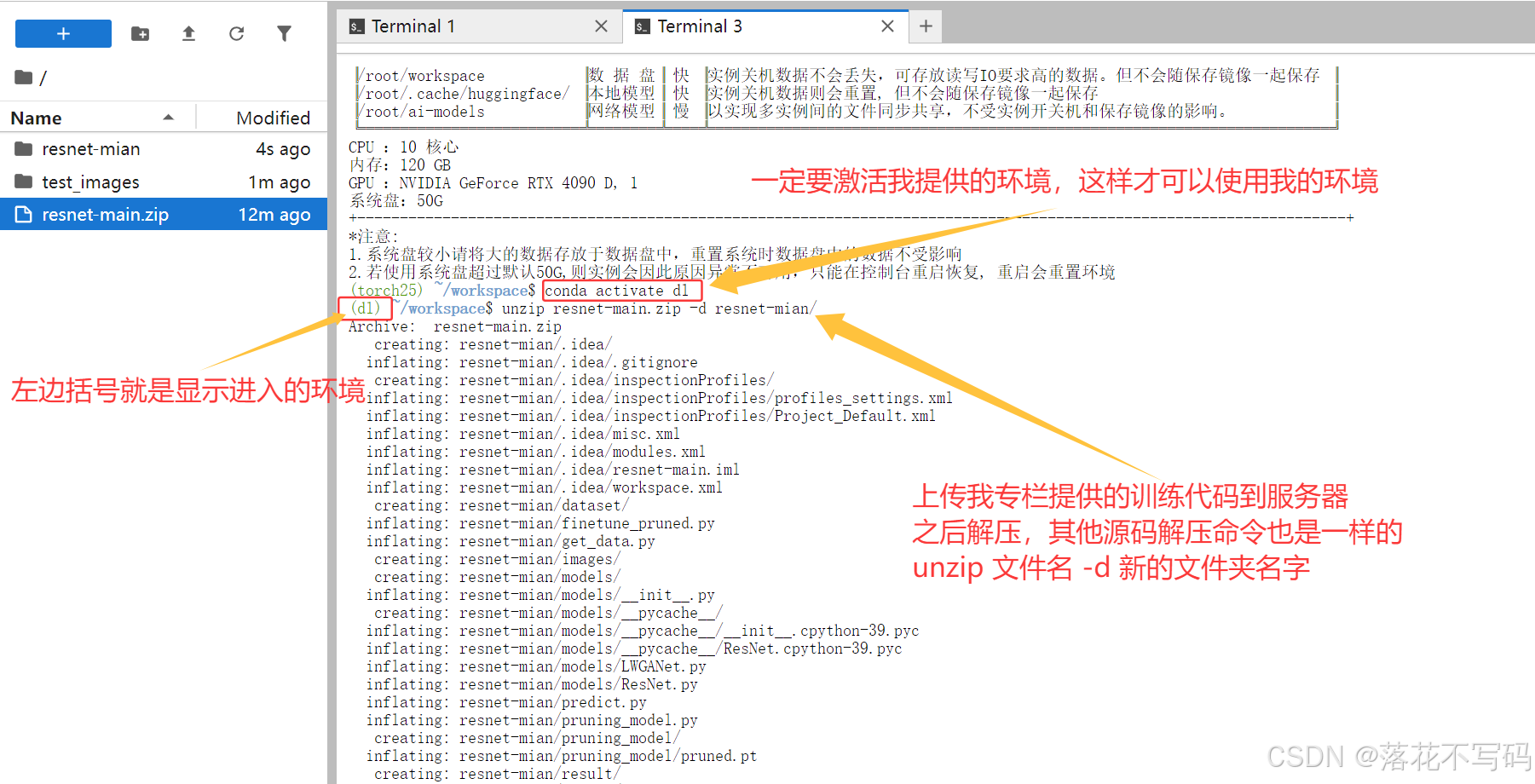
3.1 环境激活与准备工作
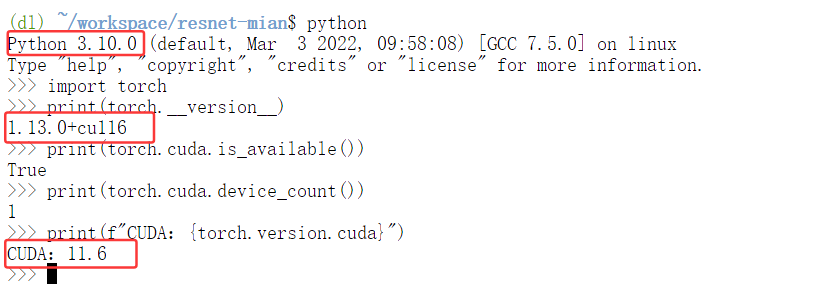
首先激活预配置的深度学习环境:
# 激活conda环境
conda activate dl
# 切换到工作目录
cd /root/workspace/your_project_folder
3.2 数据集准备与处理
环境支持常见的数据集格式,提供统一的数据处理接口:
from utils.data_utils import MultiTaskDataLoader
from torchvision import transforms
# 数据预处理配置
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 多任务数据加载示例
data_loader = MultiTaskDataLoader(task_type='classification')
dataset = data_loader.load_dataset('/path/to/your/data', transform=transform)
数据集解压命令参考:
# 解压zip格式数据集
unzip dataset.zip -d ./data/
# 解压tar.gz格式数据集
tar -zxvf dataset.tar.gz -C ./data/
3.3 模型训练与验证
图像分类任务训练
# 分类任务配置
config = {
'task_type': 'classification',
'model_name': 'resnet50',
'num_classes': 10,
'batch_size': 32,
'learning_rate': 0.001,
'epochs': 100
}
# 初始化训练器
from core.trainers import ClassificationTrainer
trainer = ClassificationTrainer(config)
# 开始训练
trainer.train()
目标检测任务训练
# 检测任务配置
detection_config = {
'task_type': 'detection',
'model_name': 'faster_rcnn',
'num_classes': 20,
'anchor_sizes': [32, 64, 128, 256, 512],
'batch_size': 16,
'learning_rate': 0.0005
}
# 初始化检测训练器
from core.trainers import DetectionTrainer
det_trainer = DetectionTrainer(detection_config)
det_trainer.train()

3.4 训练可视化与监控
环境内置丰富的可视化工具,实时监控训练过程:
# 训练结果可视化
from utils.visualization import TrainingVisualizer
visualizer = TrainingVisualizer(log_dir='./logs')
visualizer.plot_training_curves() # 绘制训练曲线
visualizer.plot_confusion_matrix() # 绘制混淆矩阵
visualizer.visualize_predictions() # 可视化预测结果

4. 高级功能与扩展应用
4.1 模型微调接口
环境提供统一的模型微调接口,支持迁移学习:
from core.finetuning import ModelFineTuner
# 微调配置
finetune_config = {
'base_model': 'resnet50',
'pretrained': True,
'freeze_backbone': True,
'custom_classifier': {
'hidden_layers': [512, 256],
'dropout': 0.5
}
}
# 初始化微调器
fine_tuner = ModelFineTuner(finetune_config)
fine_tuner.setup_training()
fine_tuner.train()
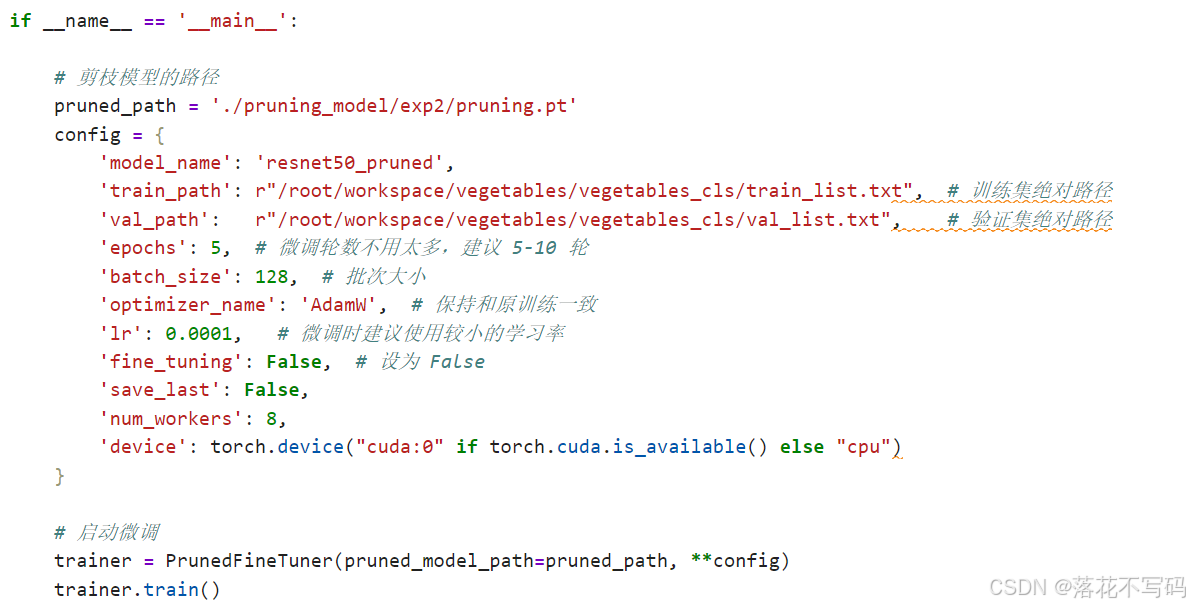
4.2 模型剪枝与优化
集成模型压缩工具,提供模型剪枝接口:
from utils.model_pruning import ModelPruner
# 模型剪枝配置
pruning_config = {
'pruning_method': 'l1_unstructured',
'pruning_amount': 0.3,
'iterative_pruning': True,
'num_iterations': 3
}
# 初始化剪枝器
pruner = ModelPruner(pruning_config)
pruned_model = pruner.prune_model(trained_model)
4.3 自定义模块扩展
环境支持用户自定义模块的扩展,只需遵循接口规范:
# 自定义数据增强模块
from torchvision import transforms
from core.interfaces import CustomTransformInterface
class MyCustomTransform(CustomTransformInterface):
def __init__(self, parameters):
self.params = parameters
def __call__(self, img):
# 实现自定义变换逻辑
return transformed_img
# 自定义模型模块
from core.interfaces import CustomModelInterface
class MyCustomModel(CustomModelInterface):
def __init__(self, config):
super().__init__(config)
self._build_model()
def _build_model(self):
# 实现自定义模型结构
pass
5. 实用技巧与最佳实践
5.1 多GPU训练支持
环境自动检测GPU资源,支持多GPU并行训练:
# 自动多GPU训练配置
distributed_config = {
'distributed': True,
'gpu_ids': [0, 1, 2, 3],
'sync_bn': True,
'gradient_accumulation': 4
}
trainer = BaseTrainer(distributed_config)
5.2 混合精度训练
集成自动混合精度训练,提升训练效率:
from torch.cuda.amp import autocast, GradScaler
# 混合精度训练示例
scaler = GradScaler()
with autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
5.3 训练过程恢复
支持训练中断恢复,自动保存检查点:
# 训练恢复配置
resume_config = {
'resume_training': True,
'checkpoint_path': './checkpoints/latest.pth',
'resume_optimizer': True,
'resume_scheduler': True
}
trainer = BaseTrainer(resume_config)
6. 常见问题解决方案
6.1 环境依赖问题
如果遇到缺少依赖库的情况,可以使用以下命令安装:
# 安装单个包
pip install package_name
# 安装环境requirements.txt
pip install -r requirements.txt
# 从源码安装
python setup.py install
6.2 数据集路径配置
确保数据集路径正确配置:
# 正确配置数据集路径
data_config = {
'train_data_path': '/root/workspace/data/train',
'val_data_path': '/root/workspace/data/val',
'test_data_path': '/root/workspace/data/test'
}
6.3 内存优化建议
针对大模型训练的内存优化:
# 内存优化配置
memory_config = {
'gradient_checkpointing': True,
'mixed_precision': True,
'batch_size_accumulation': 4,
'offload_optimizer': True
}
7. 总结
这个深度学习项目训练环境通过精心设计的模块化架构和统一的接口规范,为多任务计算机视觉项目提供了强大的支持。无论是图像分类、目标检测还是其他视觉任务,都可以在这个环境中快速上手和高效开发。
环境的核心优势包括:
- 开箱即用:预装完整依赖,无需繁琐配置
- 多任务支持:统一接口支持多种视觉任务
- 扩展性强:预留丰富接口,支持自定义模块
- 高效训练:集成多GPU、混合精度等优化技术
- 可视化完善:内置丰富的监控和可视化工具
通过遵循本文介绍的接口规范和使用方法,研究人员和开发者可以快速构建和训练自己的深度学习模型,专注于算法创新而不是环境配置。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)