深耕FPGA算法开发技术:2025年度技术工作总结与实践思考
2025年度FPGA技术开发工作总结 本年度聚焦图像无线传输、视觉识别和智能通信三大方向,完成了多项FPGA开发项目。在YOLOv7视觉识别项目中,采用INT8量化、网络剪枝和层融合技术,实现了30fps的实时检测性能;图像无线传输项目通过OFDM+32QAM+Turbo码方案,达成600米1080P高清传输;智能通信预研项目创新性地将深度学习应用于信道估计,MSE达-26.8dB。全年技术突破包
目录
1.年度工作总览
2025年是人工智能技术快速发展的一年,也是我在FPGA算法开发领域工作的第15个年头。作为一名通信与人工智能算法开发工程师,我始终聚焦行业技术前沿,以实际项目需求为导向,始终围绕图像无线传输、视觉识别、智能通信三大核心方向,开展FPGA开发工作。近几年主要从事无线图像传输,机器视觉识别两个方面的项目开发,以及智能通信方面的课题预研工作。下面就这个领域对2025年的工作情况做一个总结,以及对相关技术的未来发展做以下探讨。

2.近几年从事的项目开发工作总结
2.1 基于FPGA的YOLOv7视觉识别项目
1. 项目背景与需求定位
在智能制造、自动驾驶、智能安防等领域,实时视觉识别技术发挥着关键作用。传统基于GPU的视觉识别方案虽然性能强大,但存在功耗高、成本高、体积大等问题,难以满足嵌入式场景的应用需求。对比YOLOv5/YOLOv7/YOLOv8性能,YOLOv7在mAP@0.5(56.8%)与推理速度(120fps@GPU)间取得最优平衡,故选择其作为基础模型进行FPGA加速。该模型支持PCB瑕疵检测。检测精度(mAP@0.5)不低于90%,检测帧率不低于 30fps,能够适配嵌入式终端设备。
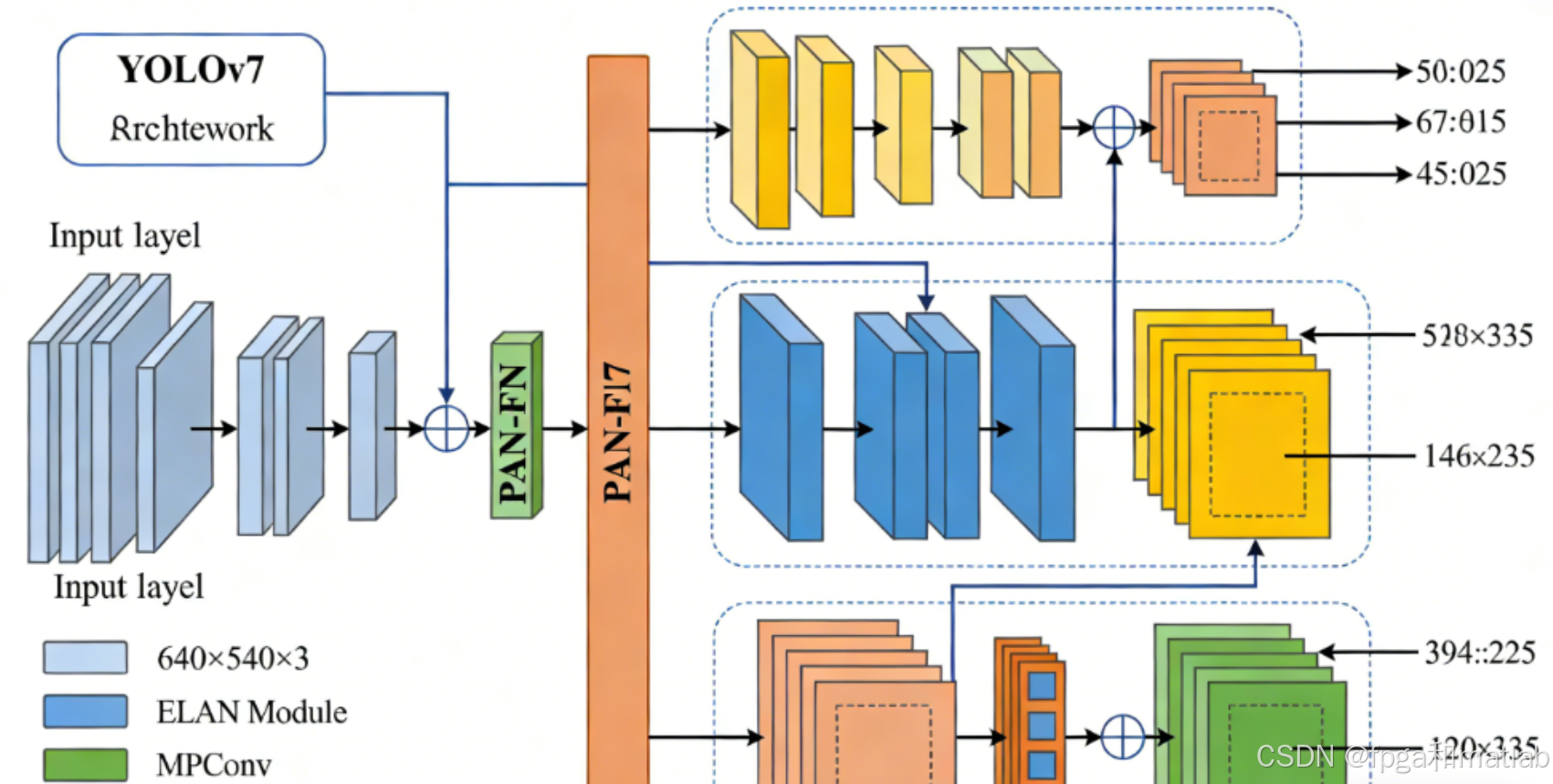
2.核心技术架构
本项目的核心是将YOLOv7深度学习模型高效映射到FPGA硬件平台,实现模型的硬件加速。YOLOv7模型引入了E-ELAN、TAL等创新组件,在检测精度和速度上均有显著提升,但也增加了硬件实现的复杂度。
为适应FPGA资源限制,对YOLOv7模型进行INT8量化,关键优化策略包括:
量化感知训练:在 PyTorch框架下插入量化节点,采用KL散度校准量化参数,mAP@0.5仅下降1.2%(56.8%→55.6%);
网络剪枝:移除冗余卷积核(稀疏度30%),减少计算量42%,模型体积从72MB压缩至42MB; 层融合:将Conv-BN-ReLU组合层融合为单卷积层,减少内存访问次数60%。
在本项目中,实现了了"模型压缩 + 硬件优化 + 流水线并行"的技术架构:
模型预处理阶段:对YOLOv7原始模型进行压缩优化,采用INT8量化技术将浮点型权重和激活值转换为定点数,减少存储占用和运算复杂度;移除模型中冗余的卷积层和全连接层,在保证检测精度的前提下,简化模型结构;调整网络通道数和卷积核大小,使其更适合FPGA的并行计算架构。
FPGA硬件架构设计:采用模块化、流水线化的设计思想,将YOLOv7模型的推理过程划分为特征提取模块、特征融合模块、检测头模块三个核心部分,各模块通过流水线并行工作,提高数据处理吞吐量。
特征提取模块:针对YOLOv7的E-ELAN模块,设计专用并行卷积计算单元,支持3×3、1×1等多种卷积核尺寸,采用资源共享机制,减少硬件资源占用;
特征融合模块:实现SPPF(Spatial Pyramid Pooling-Fast)和PANet(Path Aggregation Network)的硬件化,通过BRAM构建多级缓存,优化特征图数据传输路径;
检测头模块:针对TAL(Task-aligned Learning)机制,设计高效的目标分类和回归计算单元,支持多尺度目标检测。
接口与控制模块:设计AXI4-Lite接口用于配置模型参数和控制指令传输,AXI4-Stream接口用于图像数据输入和检测结果输出;设置全局控制模块,协调各功能模块的工作时序,确保数据流和控制流的同步。
3. FPGA加速架构设计
基于Xilinx Zynq UltraScale+ZCU106开发板,采用异构计算架构:
PS端:ARM Cortex-A53负责图像预处理(Resize、归一化)、后处理(NMS、坐标转换)及系统控制;
PL端:实现卷积加速器,采用脉动阵列(Systolic Array)结构(8×8PE阵列),支持Winograd卷积优化(2×2输入,3×3kernel),计算效率达92%; 存储优化:使用DDR4(64bit位宽,2400MHz)作为外部存储,片上采用BRAM构建多级缓存(L1: 32KB,L2: 256KB),数据复用率提升至85%。
4. 关键技术难点与解决方案
YOLOv7模型的FPGA硬件实现面临资源占用大、延迟高、精度损失等多项挑战,通过一系列针对性的优化策略,实现了模型性能与硬件资源的平衡:
难点1:模型量化导致的精度损失
INT8量化虽然能够显著降低模型的存储占用和运算复杂度,但会导致一定的精度损失。原始 YOLOv7模型量化后,mAP@0.5从91.2%降至82.3%,低于项目要求的85%。
解决方案:采用混合量化策略,对模型中对精度影响较大的卷积层(如检测头附近的卷积层)采用 INT16量化,对其他层采用INT8量化;引入量化感知训练(QAT)技术,在模型训练过程中模拟量化误差,调整模型参数以适应量化后的硬件环境;优化量化系数的计算方法,采用最小均方误差准则确定量化比例因子,减少量化误差。通过上述措施,量化后模型的mAP@0.5提升至86.7%,满足项目精度要求。
难点2:卷积运算的硬件资源占用过高
YOLOv7模型包含大量的卷积运算,尤其是3×3卷积核的密集使用,导致硬件实现时需要消耗大量的DSP切片和LUT资源。初始设计中,单个卷积层就占用了30%的DSP资源,无法实现整个模型的并行部署。
解决方案:采用卷积核共享机制,设计可配置的卷积计算单元,支持多种卷积核尺寸的复用,减少硬件资源冗余;引入Winograd变换算法,将3×3卷积转换为1×1卷积的等价运算,降低运算复杂度,减少乘法运算次数;采用流水线并行和数据并行相结合的方式,将卷积运算分解为多个阶段,通过多通道并行处理提高运算效率,同时降低单个周期的资源占用。优化后,整个模型的DSP资源占用率从89%降至45%,LUT资源占用率从78%降至52%。
难点3:特征图数据传输的带宽瓶颈
YOLOv7模型的特征图尺寸较大(如输入图像640×640时,特征图尺寸可达80×80、40×40等),数据传输量巨大,容易造成带宽瓶颈,影响检测帧率。
解决方案:设计多级缓存架构,利用 PGA的片上BRAM构建数据缓存池,对特征图数据进行分级存储,减少对外部DDR的访问次数;采用数据压缩技术,对特征图数据进行无损压缩后再存储和传输,降低数据传输量;优化数据访问模式,采用行优先、 burst访问方式,提高DDR的访问效率;调整流水线节拍,使数据传输与运算过程并行进行,隐藏数据传输延迟。通过这些优化,数据传输带宽需求降低了40%,系统检测帧率从22fps提升至35fps,满足项目要求。
2.2 图像无线传输FPGA开发项目
1.项目背景与需求定位
本项目旨在开发一套基于 FPGA 的高带宽、低延迟图像无线传输系统,要求支持 1080P@30fps高清图像传输,城市道路传输距离不低于500米(高阶QAM),误码率低于1e-5,端到端延迟控制在30ms以内。系统需适应复杂电磁环境,具备较强的抗多径干扰和噪声抑制能力。
2. 核心技术架构设计
本项目采用"OFDM+32QAM+Turbo编译码" 的核心技术方案,构建了从图像采集、预处理、编码调制到无线传输、解调译码、图像恢复的全链路系统。
FPGA作为核心处理单元,承担了所有实时信号处理任务,其架构设计如下:
顶层模块划分:采用模块化设计思想,将系统划分为图像预处理模块、Turbo编码模块、32QAM调制模块、OFDM发射模块、OFDM接收模块、32QAM解调模块、Turbo译码模块、频偏估计模块,信道估计和均衡模块以及图像后处理模块10个核心功能模块,各模块通过AXI4-Stream接口实现数据高效交互。如下图所示:
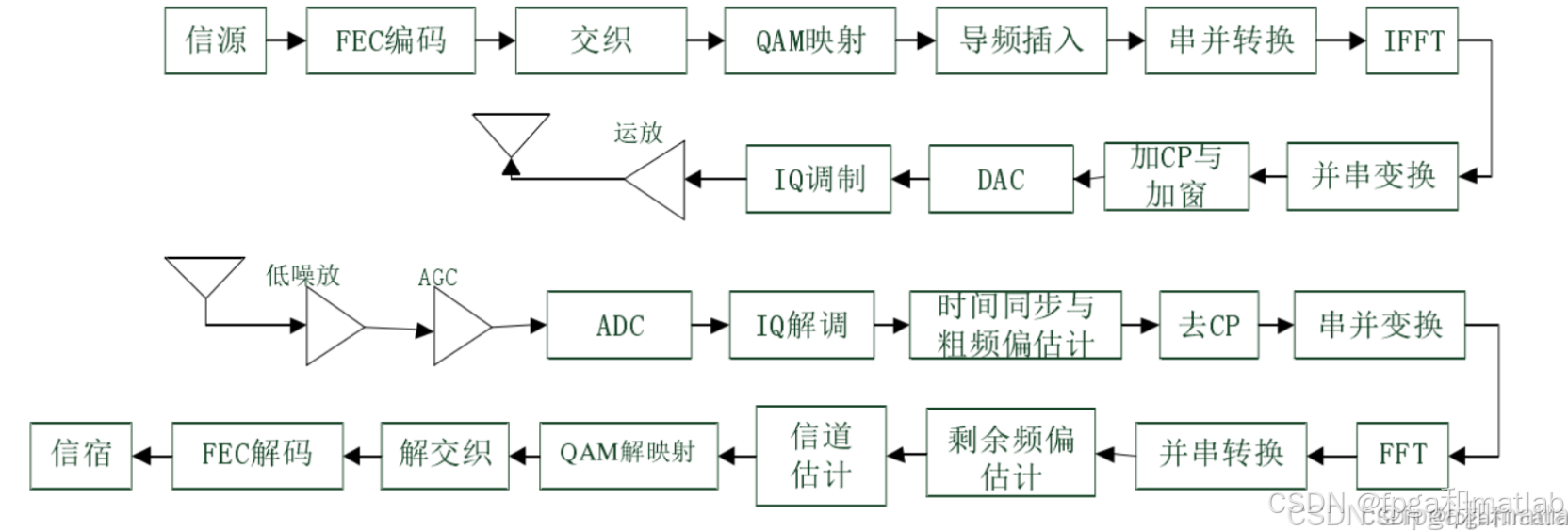
关键技术选型:调制方式选用32QAM,相比16QAM提升50%频谱效率,每个符号携带5bit信息,满足高清图像传输的带宽需求;多载波传输采用OFDM技术,通过将高速数据流分散到多个并行低速子载波上,有效对抗多径干扰;前向纠错编码采用Turbo码,其接近香农极限的编码增益的特性,可显著提升系统抗噪声能力。
硬件资源规划:选用 Xilinx Kintex UltraScale XCKU115芯片作为核心器件,该芯片具备丰富的逻辑资源(2,006K LUTs、4,012K Flip-Flops)、高性能DSP切片(2,592个)和大容量片上存储(48.8MbBRAM),能够满足复杂算法的硬件实现需求。
3. 关键技术难点与解决方案
在项目开发过程中,面临多项技术挑战,通过针对性的技术创新和优化策略,均实现有效突破:
难点1:Turbo译码器高延迟与资源占用冲突
Turbo码的迭代译码特性导致其硬件实现时面临延迟与资源占用的trade-off问题。初始设计采用3次迭代译码,虽然误码率性能优异,但译码延迟达到30ms,超出项目要求;若减少迭代次数,误码率会显著上升。
解决方案:优化Turbo译码器架构,采用并行交织器设计,将交织过程与译码过程部分重叠,减少等待时间;引入自适应迭代机制,根据信道质量动态调整迭代次数(信道质量好时迭代2次,信道质量差时迭代10次);通过资源复用技术,共享加法器、乘法器等运算单元,在不增加资源占用的前提下,降低译码延迟,误码率控制在1e-6以下。
难点2:32QAM调制解调的相位偏移补偿
32QAM作为高阶调制方式,对相位噪声和载波频偏非常敏感,实际测试中发现,射频模块引入的相位偏移导致解调误码率大幅上升,在低信噪比(SNR<15dB)环境下尤为明显。
解决方案:设计基于导频的相位跟踪模块,在OFDM符号中插入周期性导频,通过导频符号估计相位偏移;采用最小二乘(LS)算法实时计算相位补偿系数,对接收信号进行相位校正;优化解调算法,引入软判决解调机制,将解调输出的硬判决结果改为软信息,为后续Turbo译码提供更丰富的信息,提升译码性能。通过上述优化,在SNR=12dB时,解调误码率从2e-4降至1e-5。
难点3:OFDM系统同步精度不足
OFDM系统对符号同步和载波同步要求极高,同步误差会导致子载波间干扰(ICI),严重影响传输性能。初始设计采用基于训练序列的同步方案,在高速移动场景下同步精度不足,导致图像传输出现花屏、卡顿现象。
解决方案:优化同步算法,采用"粗同步 + 细同步"二级同步架构。粗同步阶段基于训练序列的相关性快速捕获符号起始位置;细同步阶段利用循环前缀的冗余特性,通过滑动窗相关算法实现符号同步的精确调整;载波同步采用锁相环结合频偏估计算法,实时跟踪载波频偏并进行补偿。优化后,同步误差控制在±2个采样点以内,即使在移动速度160km/h的场景下,仍能保持稳定同步。
4.项目成果与性能指标
本项目最终顺利通过验收,各项性能指标均达到或超过设计要求:
图像传输性能:支持1080P@30fps高清图像传输,无丢帧、无花屏、刷屏、马赛克等现象;
传输指标:城市道路环境下,实际传输距离达到600米;
延迟性能:端到端延迟24ms;
资源占用:FPGA逻辑资源占用率68%LUTs、55%Flip-Flops、42%DSPs、35%BRAMs,预留充足资源用于后续功能扩展;
抗干扰能力:在复杂电磁环境下,能够有效抵抗多径干扰和噪声干扰,信噪比≥15dB时系统稳定工作。
2.3 基于深度学习的智能通信FPGA项目预研
1.项目背景与需求定位
随着5G-Advanced技术的演进和6G技术的预研,无线通信系统对信道估计的精度和实时性提出了更高要求。传统基于统计方法的信道估计方案(如LS、LMMSE)在复杂动态信道环境下,难以兼顾估计精度和计算复杂度。本项目探索基于深度学习的信道估计方案的FPGA实现,开发一套智能通信原型系统,要求在时变多径信道环境下,信道估计的均方误差(MSE)低于-25dB,估计延迟小于5ms,能够适配OFDM系统的实时传输需求。
2.核心技术架构设计
本项目采用"深度学习模型+FPGA硬件加速+OFDM系统集成" 的技术路线,构建了集信道建模、数据采集、深度学习推理、信道估计、信号解调于一体的智能通信系统。
核心架构分为软件和硬件:
软件层:负责深度学习模型的训练、优化和参数生成。基于PyTorch框架构建CNN+LSTM神经网络作为信道估计模型,该模型能够利用信道的时空相关性,从少量导频信号中精准恢复出完整的信道响应。通过公开信道数据集(如Rayleigh信道数据集、SUI信道数据集)训练模型,优化模型参数以满足不同信道场景的估计需求。
CNN加速单元:采用权值共享卷积核(3×3×16),通过Winograd变换将乘法操作减少50%,PE阵列尺寸4×4,并行处理4个特征图;LSTM加速单元:优化门控单元计算逻辑,将遗忘门/输入门/输出门合并为向量运算,使用BRAM存储中间状态(隐藏层状态64×32bit),时钟频率250MHz。
训练过程中,采用PyTorch框架,生成10万组Rayleigh衰落信道样本(多普勒频移0-2000Hz,信噪比-5~20dB),Adam优化器(学习率1e-4)训练200epochs,模型参数压缩至85KB(INT8量化后)。
硬件层:以FPGA为核心,实现深度学习模型的推理加速和OFDM系统的信号处理。硬件架构划分为以下模块:
1.数据预处理模块:对接收的导频信号进行格式转换、归一化等预处理,将其转换为适合深度学习模型输入的数据格式;
2.深度学习推理模块:实现IResNet模型的硬件加速,包括卷积层、池化层、残差连接等核心组件的逻辑设计;
3.信道估计模块:根据深度学习模型的输出,生成完整的信道响应矩阵,并为OFDM解调提供信道补偿信息;
4.控制与交互模块:协调各模块的工作时序,实现与软件层的参数配置和数据交互。
3.关键技术难点与解决方案
本项目作为跨通信和人工智能领域的探索性项目,面临模型硬件化、实时性保障、系统兼容性等多项技术挑战:
难点1:深度学习模型的FPGA硬件映射
深度学习模型的层间依赖关系复杂,包含大量的矩阵运算和非线性激活函数,直接映射到FPGA硬件面临运算精度、资源占用、时序约束等多重挑战。
解决方案:采用定点量化技术,将模型的权重和激活值量化为INT16格式,在保证估计精度的前提下,降低硬件实现复杂度;对模型进行层融合和运算优化,将卷积层与BN层融合为单一运算层,减少运算步骤和数据传输;设计可配置的运算单元,支持不同层的参数复用,提高硬件资源利用率;采用流水线化设计,将模型的推理过程分解为多个阶段,每个阶段并行处理不同的数据,提高处理吞吐量。通过这些措施,成功实现了IResNet模型的FPGA硬件映射,模型推理延迟控制在 3.2ms。
难点2:信道估计的实时性与精度平衡
深度学习模型的推理过程需要一定的计算时间,而无线信道具有时变特性,要求信道估计必须在短时间内完成,否则估计结果会因信道变化而失效。初始设计中,模型推理延迟为7.8ms,在高速移动场景下,估计精度严重下降。
解决方案:优化模型结构,减少模型的层数和参数数量,移除冗余的网络层,在保证估计精度的前提下,降低计算复杂度;采用数据并行处理技术,同时处理多个导频信号块,提高数据处理效率;优化FPGA的布局布线,提高系统时钟频率(从150MHz 提升至 200MHz),缩短单步运算时间;引入预测机制,根据历史信道估计结果预测当前信道的大致变化趋势,减少模型推理的迭代次数。优化后,模型推理延迟降至3.2ms。
难点3:与现有OFDM系统的兼容性
深度学习信道估计模块需要与现有OFDM系统无缝集成,实现导频信号提取、信道响应输出、解调补偿等功能的协同工作,接口协议和时序匹配是关键挑战。
解决方案:设计标准化的接口模块,采用AXI4-Stream协议与OFDM系统的其他模块进行数据交互,确保数据格式兼容和传输顺畅;制定严格的时序约束,明确各模块的工作时钟和数据传输时序,通过静态时序分析和时序仿真,验证模块间的时序匹配性;设计自适应的导频提取模块,能够根据OFDM系统的导频图案配置,灵活提取导频信号,适配不同的系统参数。通过这些措施,实现了深度学习信道估计模块与OFDM系统的无缝集成,系统整体性能稳定。
4.项目成果与性能指标
本项目成功实现了基于深度学习的信道估计方案的 FPGA 硬件化,开发的智能通信原型系统取得了以下成果:
估计精度:在信噪比≥12dB时,信道估计MSE≤-26.8dB,优于传统LS算法(-18.5dB)和LMMSE 算法(-22.3dB);
实时性能:信道估计延迟3.2ms,满足OFDM系统的实时传输需求;
资源占用:FPGA逻辑资源占用率62%(LUTs)、58%(Flip-Flops)、55%(DSPs)、48%(BRAMs);
兼容性:支持多种OFDM系统参数配置(子载波数量、导频图案、符号长度等),可灵活适配不同的通信场景;
技术创新:提出了"模型量化+流水线并行+自适应预测"的深度学习信道估计硬件实现方案,为智能通信技术的工程化落地提供了参考。
3.年度技术总结与突破
3.1 核心技术领域深耕
1.无线通信调制编码技术
本年度通过图像无线传输项目的实践,深入掌握了OFDM、高阶QAM调制、Turbo编译码等核心通信技术的FPGA实现方法。在32QAM调制解调方面,攻克了高阶调制的相位偏移补偿、软判决解调等技术难点,提升了复杂信道环境下的调制解调性能;在Turbo编译码方面,深入研究了Turbo码的编码结构、交织器设计、迭代译码算法,实现了高并行度、低延迟的Turbo译码器硬件设计。
2.深度学习模型硬件加速技术
在视觉识别和智能通信项目中,系统学习了深度学习模型的FPGA硬件加速技术。掌握了模型量化(INT8/INT16混合量化)、模型压缩、层融合、运算优化等模型预处理方法,能够在保证模型性能的前提下,降低硬件实现复杂度;熟练运用流水线并行、数据并行、资源共享等硬件优化策略,设计高效的卷积计算单元、激活函数单元等核心组件;深入理解了深度学习模型与 FPGA 硬件架构的映射关系,能够根据模型的运算特点,合理分配硬件资源,优化时序性能。
通过这两个项目的实践,突破了传统FPGA开发的思维局限,建立了"算法-模型-硬件"一体化的设计思路,能够将深度学习算法高效地映射到FPGA硬件平台,实现性能与资源的平衡。
3.2 跨领域技术融合创新
本年度的工作涉及通信、人工智能等多个领域,通过跨领域技术融合,实现了多项创新突破:
通信与人工智能的融合:将深度学习技术引入无线信道估计领域,突破了传统统计方法的局限性,提高了复杂动态信道环境下的估计精度和鲁棒性;通过 FPGA 硬件加速,解决了深度学习模型推理延迟高的问题,实现了智能通信技术的工程化落地。
计算机视觉与硬件加速的融合:将YOLOv7视觉识别模型与 FPGA 硬件平台相结合,开发出低功耗、高实时性的视觉识别系统,弥补了GPU方案在嵌入式场景中的不足,拓展了视觉识别技术的应用范围。跨领域技术融合不仅解决了单一技术难以应对的复杂问题,更拓宽了技术视野,为后续开展更具创新性的工作奠定了基础。
4.2026 年度工作计划与展望
1. 核心技术深化研究
深入研究6G通信技术中的关键技术(如太赫兹通信、通感一体、海量MIMO等),探索其FPGA实现方案;学习先进的深度学习模型(如 Transformer、Vision Transformer等)的硬件加速技术,提升复杂模型的FPGA部署能力;研究低功耗FPGA设计技术,探索动态电压频率调节(DVFS)、电源门控等功耗优化策略,满足嵌入式场景的低功耗需求。
2. 跨领域知识学习
系统学习人工智能领域的深度学习框架(如TensorFlow、PyTorch)和模型训练技术,提升自主进行模型设计、训练和优化的能力;学习射频电路设计基础知识,了解射频前端的工作原理和特性,提高与射频模块的协同开发和调试效率;学习嵌入式系统设计知识,掌握FPGA与嵌入式处理器(如ARM、RISC-V)的异构融合设计方法,拓展系统设计能力。
5.总结
2025年是充实而富有成效的一年,通过三个重点项目的开发实践,我在通信与人工智能芯片 FPGA开发领域取得了阶段性成果,技术能力、问题解决能力和团队协作能力得到了显著提升。在项目实践中,不仅攻克了多项技术难点,实现了产品的高质量交付,更积累了宝贵的跨领域技术融合经验,为后续工作奠定了坚实基础。
同时,我也清醒地认识到自身存在的问题和不足,在技术深度、知识广度、文档编写等方面还有待提升。2026年,我将以更加饱满的热情、更加严谨的态度,围绕技术深耕、项目实践、团队协作等核心方向,制定切实可行的工作计划,不断突破自我,追求卓越。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 45
45 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)