基于改进粒子群优化支持向量机的数据回归预测
这次的实践让我对PSO-SVM有了更深入的理解,也让我意识到参数优化在机器学习中的重要性。虽然代码实现起来不算太难,但调参的过程确实需要一些耐心和技巧。如果你对电力负荷预测或者回归分析感兴趣,不妨试试这个方法,说不定会有意想不到的收获!
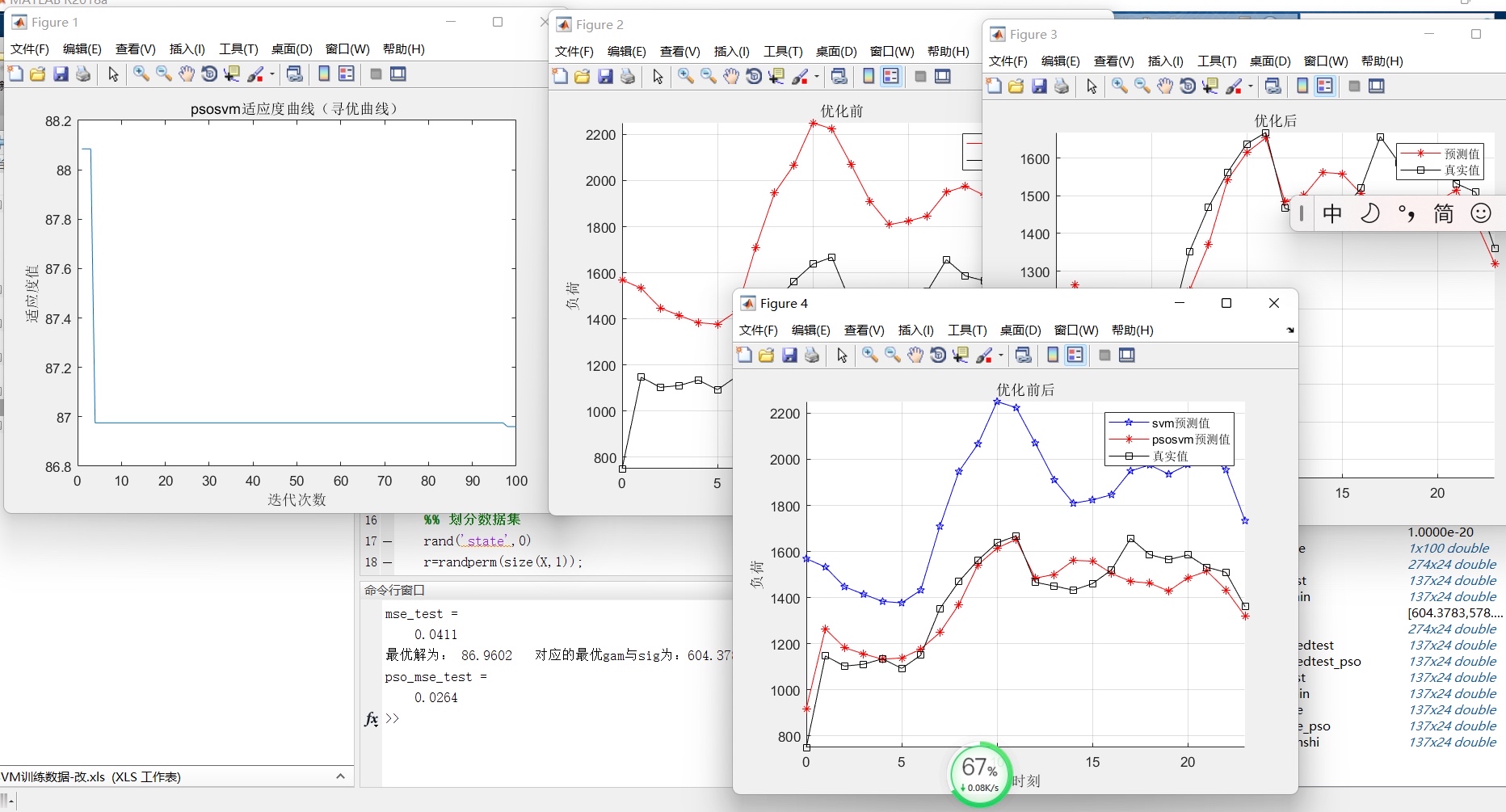
基于改进粒子群优化支持向量机(PSO-SVM)的数据回归预测 改进后粒子群权重为:线性权重递减 matlab代码 可利用于预测电力负荷 形式:程序 实现功能:使用前一天负荷数据预测下一天负荷数据 得到预测对比分析图
最近在研究电力负荷预测的问题,发现改进粒子群优化支持向量机(PSO-SVM)这个方法挺有意思的。简单来说,就是通过粒子群优化算法(PSO)来优化支持向量机(SVM)的参数,从而提升回归预测的精度。这次我主要用它来做电力负荷的预测,具体来说,就是用前一天的负荷数据来预测下一天的负荷数据。整个过程还挺有成就感的,尤其是看到预测结果和实际数据对比时,那种满足感难以言表。
一、为什么选择PSO-SVM?
支持向量机(SVM)本身是一个强大的机器学习模型,但在处理回归问题时,参数的选择对模型性能影响很大。传统的SVM需要手动调整核函数参数和惩罚系数,这显然不太高效。而粒子群优化(PSO)作为一种全局优化算法,非常适合用来自动优化这些参数。通过改进粒子群算法,比如引入线性权重递减策略,可以让优化过程更高效,避免陷入局部最优。
二、线性权重递减策略
在传统的PSO中,粒子的速度更新公式通常包含认知项和群体项,这两部分的权重会影响粒子的搜索行为。线性权重递减策略的核心思想是让认知权重随迭代次数线性递减,而群体权重则线性递增。这样做的好处是:在搜索初期,粒子更倾向于探索全局空间;而在后期,粒子则更关注局部最优,从而提高收敛速度和精度。
具体来说,权重更新公式可以表示为:
$$
w{c}(t) = w{max} - \frac{(w{max} - w{min})}{T} \cdot t \\
w{s}(t) = w{min} + \frac{(w{max} - w{min})}{T} \cdot t
$$
其中,\(w{c}\) 是认知权重,\(w{s}\) 是群体权重,\(w{max}\) 和 \(w{min}\) 分别是权重的最大值和最小值,\(T\) 是最大迭代次数,\(t\) 是当前迭代次数。
三、代码实现
接下来是代码部分。我用MATLAB实现了一个简单的PSO-SVM模型,用来预测电力负荷。代码大致分为以下几个部分:
- 数据预处理:加载电力负荷数据,进行归一化处理。
- PSO优化SVM参数:定义适应度函数,实现粒子群优化。
- SVM回归预测:使用优化后的参数训练SVM模型,并进行预测。
- 结果分析:绘制预测值与实际值的对比图。
以下是核心代码:
% 数据加载与预处理
load('power_load.mat'); % 假设数据存储在power_load.mat中
data = power_load;
data = data(1:end-1); % 只取负荷数据
[train_data, test_data] = split_data(data, 0.7); % 70%训练集,30%测试集
% PSO参数设置
pop_size = 30; % 粒子数量
max_iter = 100; % 最大迭代次数
w_max = 0.9; % 初始权重
w_min = 0.4; % 最终权重
c_min = 1e-3; % 惩罚系数范围
c_max = 1e3;
sigma_min = 1e-3; % 核函数参数范围
sigma_max = 1e3;
% 初始化粒子群
particles = zeros(pop_size, 2); % 每个粒子有两个参数:c和sigma
particles(:,1) = unifrnd(c_min, c_max, pop_size, 1);
particles(:,2) = unifrnd(sigma_min, sigma_max, pop_size, 1);
velocities = zeros(pop_size, 2);
pbest = particles;
gbest = particles(1,:);
% PSO优化过程
for t = 1:max_iter
% 计算权重
w_c = w_max - (w_max - w_min) * (t-1)/(max_iter-1);
w_s = w_min + (w_max - w_min) * (t-1)/(max_iter-1);
% 计算适应度
fitness = zeros(pop_size, 1);
for i = 1:pop_size
c = particles(i,1);
sigma = particles(i,2);
% 使用SVM进行回归
model = svmtrain(train_data(:,1), train_data(:,2), 'Kernel_Function', 'gaussian', ...
'Kernel_Scale', sigma, 'Box_Constraint', c);
% 预测
[predict_label, ~, ~] = svmpredict(test_data(:,1), model);
% 计算均方误差
fitness(i) = mean((test_data(:,2) - predict_label).^2);
end
% 更新pbest和gbest
for i = 1:pop_size
if fitness(i) < fitness(pbest(i,:))
pbest(i,:) = particles(i,:);
end
if fitness(i) < fitness(gbest)
gbest = particles(i,:);
end
end
% 更新速度和位置
for i = 1:pop_size
r1 = rand;
r2 = rand;
velocities(i,:) = w_c * velocities(i,:) + ...
w_s * r1 * (pbest(i,:) - particles(i,:)) + ...
w_s * r2 * (gbest - particles(i,:));
particles(i,:) = particles(i,:) + velocities(i,:);
end
end
% 使用最优参数进行预测
c = gbest(1);
sigma = gbest(2);
model = svmtrain(train_data(:,1), train_data(:,2), 'Kernel_Function', 'gaussian', ...
'Kernel_Scale', sigma, 'Box_Constraint', c);
[predict_label, ~, ~] = svmpredict(test_data(:,1), model);
% 绘制结果
figure;
plot(test_data(:,1), test_data(:,2), 'b-', 'LineWidth', 2);
hold on;
plot(test_data(:,1), predict_label, 'r--', 'LineWidth', 2);
legend('实际值', '预测值');
title('电力负荷预测结果对比');
xlabel('时间');
ylabel('负荷');
grid on;四、结果分析
运行完代码后,可以看到预测值和实际值的对比图。总体来看,预测结果还是挺接近实际数据的,尤其是在负荷波动较大的区域,模型表现得还不错。当然,这和数据的质量、特征选择以及模型的超参数设置都有很大关系。如果想进一步提升精度,可以尝试引入更多的特征(比如温度、湿度等气象数据)或者使用更复杂的优化算法。
五、总结
这次的实践让我对PSO-SVM有了更深入的理解,也让我意识到参数优化在机器学习中的重要性。虽然代码实现起来不算太难,但调参的过程确实需要一些耐心和技巧。如果你对电力负荷预测或者回归分析感兴趣,不妨试试这个方法,说不定会有意想不到的收获!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)