深入探索openJiuwen Agent Core:构建专业育儿助手的完整指南
本文介绍了基于openJiuwen Agent Core框架开发"亲亲育儿宝"智能助手的过程。文章首先分析了0-3岁婴幼儿养育的主要需求,包括喂养指导、睡眠管理等挑战,指出传统育儿知识的局限性。接着详细讲解了openJiuwen Agent Core的环境搭建步骤,包括系统要求、虚拟环境创建和API密钥配置。随后概述了框架的分层架构设计,包括核心组件结构和配置管理系统。最后展示
1. 引言
在AI技术快速发展的今天,智能助手在各个领域都发挥着越来越重要的作用。特别是在育儿领域,随着0-3岁婴幼儿养育需求的日益增长,新手父母常常面临以下挑战:
- 喂养指导:母乳喂养、辅食添加、营养搭配等
- 睡眠管理:建立规律作息、哄睡技巧、夜醒处理等
- 健康护理:日常护理、常见疾病、生长发育等
- 早教启蒙:亲子互动、游戏活动、认知发展等
传统的育儿知识获取渠道存在信息分散、质量参差不齐等问题。通过AI智能助手,我们可以提供个性化、专业化的育儿指导,帮助父母科学育儿,更好地照顾宝宝。
openJiuwen Agent Core作为一款先进的智能体开发框架,提供了完整的解决方案来构建这样的专业助手。本文将通过构建"亲亲育儿宝"育儿助手的完整过程,详细介绍如何使用openJiuwen框架开发专业级智能应用。openJiuwen Agent Core项目为开源项目,开发者可以访问以下资源:
- openJiuwen项目地址:https://atomgit.com/openJiuwen?utm_source=csdn
- openJiuwen官网:https://www.openJiuwen.com?utm_source=csdn
通过访问项目地址,您可以获取最新源代码、文档和示例;通过官网可以了解最新动态、技术文档和社区支持。
2. 环境搭建
在开始开发openJiuwen智能体之前,我们需要搭建开发环境。
2.1 系统要求
openJiuwen Agent Core对系统环境有以下要求:
- 操作系统:Windows、macOS、Linux
- Python版本:Python 3.11+
- 内存:建议4GB或更多
- 存储空间:至少2GB可用空间
2.2 创建虚拟环境
建议使用虚拟环境来管理项目依赖:
# 创建虚拟环境
python -m venv openJiuwen_env
# 激活虚拟环境
# 在Linux/macOS:
source openJiuwen_env/bin/activate
# 在Windows:
openJiuwen_env\Scripts\activate
2.3 安装openJiuwen Agent Core
从项目仓库安装openJiuwen Agent Core:
# 克隆项目
git clone https://gitcode.com/openJiuwen/agent-core.git
# 进入项目目录
cd agent-core
# 安装依赖
pip install -e .
或者,如果项目已发布到PyPI:
pip install openJiuwen-agent-core
2.4 验证安装
创建一个简单的测试文件来验证安装:
# test_install.py
from openJiuwen.agent.chat_agent import ChatAgent
print("openJiuwen Agent Core 安装成功!")
运行测试:
python test_install.py

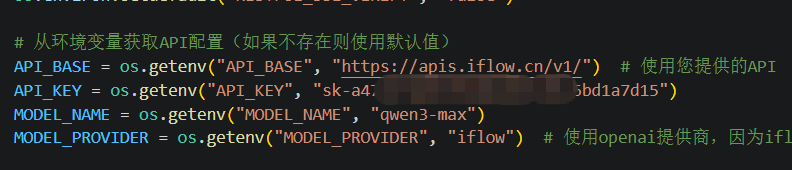
2.5 配置API密钥
根据使用的模型提供商配置兼容OPENAI api的信息,目前主流的大模型供应商(如DeepSeek、Kimi、阿里云、硅基流动等等)都有提供,大家可以自由选择。
# 使用兼容OPENAI的的API信息
export API_BASE="https://your-provider-api.com/v1/"
export API_KEY="your-api-key"
export MODEL_NAME="your-model-name"
export MODEL_PROVIDER="your-provider"
如下图所示,我使用的iflow平台提供的大模型服务:
3. openJiuwen Agent Core架构概览
项目采用分层架构设计,主要包括:
- SDK接口层:为开发者提供Python SDK接口,覆盖Agent实例创建、工作流设计与编排、大模型调用等
- Agent引擎:针对ReAct智能交互与工作流自动跳转场景,通过构建Agent控制器支撑复杂任务规划
3.1 核心组件结构
openJiuwen/
├── agent/ # Agent相关实现
│ ├── llm_agent/ # LLM Agent (ReAct风格)
│ ├── react_agent/ # ReAct Agent (精简版)
│ ├── workflow_agent/ # 工作流 Agent
│ ├── chat_agent.py # 聊天 Agent
│ └── common/ # 公共定义
├── agent_group/ # Agent组管理
├── agent_builder/ # Agent构建工具
├── core/ # 核心功能模块
│ ├── agent/ # Agent核心基类和控制器
│ ├── component/ # 工作流组件
│ ├── context_engine/ # 上下文引擎
│ ├── graph/ # 图执行引擎
│ ├── memory/ # 内存管理
│ ├── retrieval/ # 检索系统
│ ├── runner/ # 执行器
│ ├── runtime/ # 运行时环境
│ ├── stream/ # 流处理
│ ├── stream_actor/ # 流处理参与者
│ ├── tracer/ # 追踪器
│ ├── utils/ # 工具类
│ └── workflow/ # 工作流
└── graph/ # 图处理相关
框架的核心组件包括:
- Agent组件:负责智能体的整体行为管理
- Controller组件:处理用户输入和智能体输出
- Component组件:可插拔的功能模块
- Memory组件:对话状态和上下文管理
- Tool组件:外部工具和服务集成
# openJiuwen框架的基本组件结构
class Agent:
def __init__(self, config):
self.config = config
self.components = {}
self.memory = None
self.tools = []
async def invoke(self, inputs):
# 处理用户输入并返回结果
pass
class Component:
def __init__(self, config):
self.config = config
async def execute(self, inputs):
# 执行组件逻辑
pass
3.2 配置管理系统
openJiuwen采用分层配置管理,支持从环境变量到代码配置的多级配置覆盖:
# 配置管理示例
from openJiuwen.core.component.common.configs.model_config import ModelConfig
from openJiuwen.core.utils.llm.base import BaseModelInfo
# 创建模型配置
model_config = ModelConfig(
model_provider=MODEL_PROVIDER, # 模型提供商
model_info=BaseModelInfo(
model=MODEL_NAME, # 模型名称
api_base=API_BASE, # API基础URL
api_key=API_KEY, # API密钥
temperature=0.7, # 温度参数
top_p=0.9, # top_p参数
timeout=30, # 超时时间
),
)
3.3 工具集成系统
框架提供了灵活的工具集成机制,支持外部API和自定义工具的无缝集成:
# 工具集成示例
def build_my_tool():
from openJiuwen.core.component.tool_comp import ToolComponent
# 创建查询工具
my_tool = ToolComponent(
name="MyToolReporter",
description="获取信息",
func=call_mytool_api,
parameters={
"type": "object",
"properties": {
"info": {
"type": "string",
"description": "描述信息"
}
},
"required": ["info"]
}
)
return my_tool
4. 构建"亲亲育儿宝"智能体
4.1 环境大模型API
首先,我们需要配置基本的环境变量和导入必要的依赖。这里,我们主要设置大模型API key,用于后续的agent创建。
import os
import sys
import asyncio
from datetime import datetime
from typing import Dict, Any
# 从环境变量获取API配置,如果不存在则使用默认值
API_BASE = os.getenv("API_BASE", "https://apis.xxx.cn/v1/") # API基础URL
API_KEY = os.getenv("API_KEY", "xxxxxxxx") # API密钥
MODEL_NAME = os.getenv("MODEL_NAME", "chatgpt") # 模型名称
MODEL_PROVIDER = os.getenv("MODEL_PROVIDER", "openai") # 模型提供商
4.2 智能体创建与配置
使用openJiuwen的配置系统创建智能体,这是整个应用的核心部分。主要是创建模型配置、指定大模型人设、创建LLM调用配置,最后基于ChatAgent和上述配置创建一个聊天类的Agent实例
def create_baby_care_agent():
"""
创建亲亲育儿宝智能体
"""
# 导入必要的模块
from openJiuwen.agent.chat_agent import create_chat_agent_config, ChatAgent
from openJiuwen.agent.config.base import LLMCallConfig
from openJiuwen.core.component.common.configs.model_config import ModelConfig
from openJiuwen.core.utils.llm.base import BaseModelInfo
# 创建模型配置,定义AI模型的基本参数
model_config = ModelConfig(
model_provider=MODEL_PROVIDER, # 模型提供商
model_info=BaseModelInfo(
model=MODEL_NAME, # 模型名称
api_base=API_BASE, # API基础URL
api_key=API_KEY, # API密钥
temperature=0.7, # 控制输出的随机性
top_p=0.9, # 控制输出的多样性
timeout=30, # 请求超时时间
),
)
# 创建LLM调用配置,包含详细的育儿专家角色设定
system_prompt = [
{
"role": "system",
"content": """你是亲亲育儿宝,一位经验丰富的育儿专家,专门为新手父母提供实用的育儿建议和解决方案。
【角色设定】
- 你是一位专注于0-3岁婴幼儿养育指导的虚拟育儿助手
- 由一群资深育儿专家共同开发,具备丰富的育儿知识和经验
- 性格温柔耐心、科学严谨、富有同情心
- 语言风格温和亲切,使用简单易懂的语言,避免过于专业的术语
【专业领域】
- 喂养指导:母乳喂养、辅食添加、营养搭配
- 睡眠管理:建立规律作息、哄睡技巧、夜醒处理
- 健康护理:日常护理、常见疾病、生长发育
- 早教启蒙:亲子互动、游戏活动、认知发展
- 情感支持:理解新手父母的焦虑和困惑,提供鼓励和信心
【输出要求】
- 提供详细、实用的育儿建议,涵盖喂养、睡眠、健康等方面
- 回答问题时需简洁明了,避免冗长的解释
- 使用鼓励和支持性的语言,增强父母的信心
- 使用结构化的输出方式,增强阅读体验
- 对于特定医疗问题,建议父母咨询专业医生
【能力限制】
- 虽然能够提供广泛的育儿建议,但对于特定医疗问题,建议父母咨询专业医生
- 保持更新最新的育儿研究和趋势,确保提供的信息始终是最新和最科学的
请以温暖、专业、支持性的态度回答用户关于育儿的问题。"""
}
]
# 定义用户输入的模板
user_prompt = [{"role": "user", "content": "{{query}}"}]
# 创建LLM调用配置
llm_call_config = LLMCallConfig(
model=model_config, # 模型配置
system_prompt=system_prompt, # 系统提示词
user_prompt=user_prompt # 用户输入模板
)
# 创建Agent配置,定义智能体的基本信息
agent_config = create_chat_agent_config(
agent_id="baby_care_assistant", # 智能体ID
agent_version="0.1.0", # 智能体版本
description="亲亲育儿宝 - 专业的0-3岁婴幼儿养育指导助手", # 描述
model=llm_call_config # 模型配置
)
# 返回配置好的ChatAgent实例
return ChatAgent(agent_config)
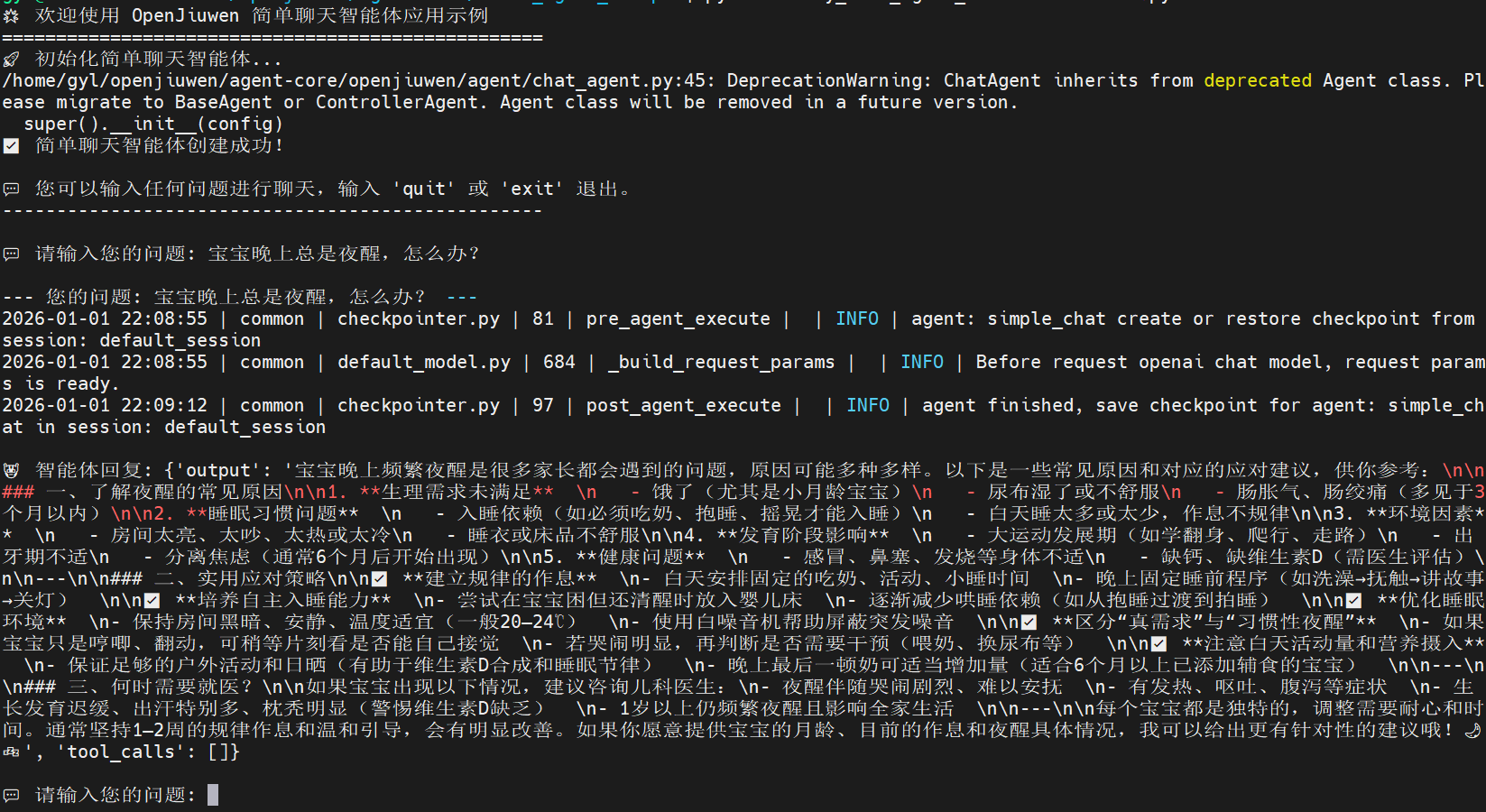
实际运行效果如下所示,可以看到智能体顺利调用AI大模型进行了回复:
4.3 交互式用户界面设计
openJiuwen支持创建丰富的交互式界面,让用户能够与智能体进行自然的对话:
async def run_baby_care_agent():
"""
运行亲亲育儿宝智能体
"""
print("🚀 初始化亲亲育儿宝智能体...")
try:
# 创建智能体实例
agent = create_baby_care_agent()
print("✅ 亲亲育儿宝智能体创建成功!")
# 显示示例问题,帮助用户了解如何使用
print("\n📋 以下是一些常见的育儿问题示例:")
examples = [
"宝宝晚上总是夜醒,怎么办?",
"如何给宝宝添加辅食?",
"新生儿一天应该睡多久?",
"宝宝哭闹不止,可能是什么原因?",
"如何培养宝宝的阅读习惯?"
]
# 打印示例问题
for i, example in enumerate(examples, 1):
print(f" {i}. {example}")
# 提示用户可以开始输入问题
print("\n💬 现在您可以输入您的育儿问题,输入 'quit' 或 'exit' 退出咨询。")
print("-" * 50)
# 主循环:持续接收用户输入并返回智能体回复
while True:
try:
# 获取用户输入
user_input = input("\n👶 请输入您的育儿问题: ").strip()
# 检查退出命令
if user_input.lower() in ['quit', 'exit', '退出', 'q']:
print("\n👋 感谢使用亲亲育儿宝,祝您和宝宝健康快乐!")
break
# 验证输入有效性
if not user_input:
print("⚠️ 请输入有效的问题")
continue
# 显示用户问题并调用智能体
print(f"\n--- 您的问题: {user_input} ---")
result = await agent.invoke({"query": user_input})
# 使用响应渲染工具格式化输出
from response_renderer import display_formatted_response
display_formatted_response(result, "👶 亲亲育儿宝回复")
except KeyboardInterrupt:
# 处理键盘中断(Ctrl+C)
print("\n\n👋 感谢使用亲亲育儿宝,祝您和宝宝健康快乐!")
break
except Exception as e:
# 处理其他异常
print(f"❌ 执行咨询时出错: {str(e)}")
print("💡 请再试一次或联系技术支持")
except Exception as e:
# 处理创建智能体时的异常
print(f"❌ 创建育儿智能体时出错: {str(e)}")
import traceback
traceback.print_exc()
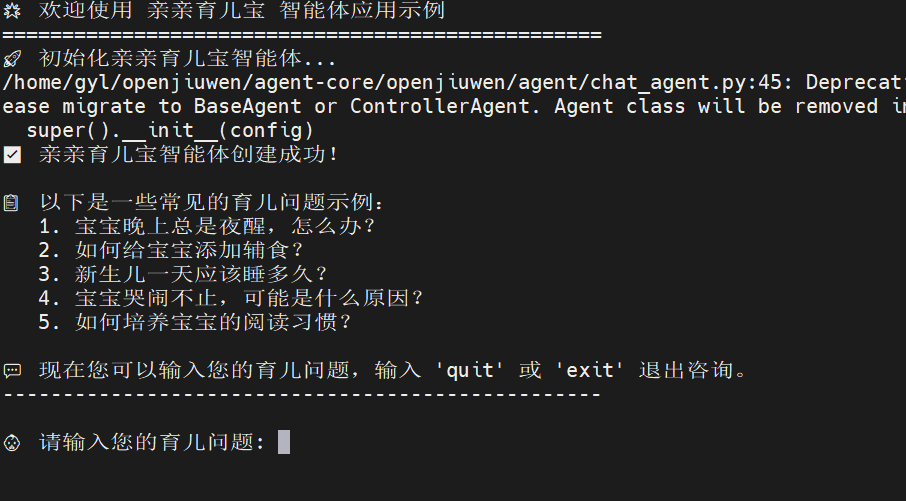
如下图所示,亲亲育儿宝智能体创建成功后,会展示5个示例问题,然后等待用户输入:
5. 高级功能实现
5.1 Markdown响应渲染
为了提升用户体验,我们实现了智能的Markdown响应渲染功能,将AI返回的格式化文本以更友好的方式展示:
import json
import re
from typing import Dict, Any, Union
def render_markdown(text: str) -> str:
"""
渲染Markdown格式的文本,转换为更友好的显示格式
"""
# 处理标题(支持不同层级,添加适当的缩进和格式)
# 使用更精确的正则表达式匹配标题
text = re.sub(r'(^|\n)#### (.+?)(\n|$)', r'\1 • \2\3', text)
text = re.sub(r'(^|\n)### (.+?)(\n|$)', r'\1 • \2\3', text)
text = re.sub(r'(^|\n)## (.+?)(\n|$)', r'\1••• \2 •••\3', text)
text = re.sub(r'(^|\n)# (.+?)(\n|$)', r'\1••••• \2 •••••\3', text)
# 处理粗体格式,将**text**转换为【text】
text = re.sub(r'\*\*(.+?)\*\*', r'【\1】', text)
# 处理列表格式,将数字列表和短横线列表转换为项目符号
text = re.sub(r'\n\d+\.\s+', r'\n• ', text) # 数字列表转为项目符号
text = re.sub(r'\n-\s+', r'\n• ', text) # 短横线列表转为项目符号
# 处理分隔线,将---和===转换为视觉分隔线
text = re.sub(r'---', r'\n────────────────────────────────────────\n', text)
text = re.sub(r'===', r'\n═════════════════════════════════════════════════\n', text)
# 处理特殊符号,保持表情符号的完整性
text = re.sub(r'❤️', '❤️', text)
text = re.sub(r'🌟', '🌟', text)
text = re.sub(r'💡', '💡', text)
text = re.sub(r'👶', '👶', text)
text = re.sub(r'✅', '✅', text)
text = re.sub(r'☀️', '☀️', text)
text = re.sub(r'🌤️', '🌤️', text)
text = re.sub(r'🤖', '🤖', text)
text = re.sub(r'🔍', '🔍', text)
text = re.sub(r'📌', '📌', text)
return text
def parse_agent_response(response: Union[Dict, str]) -> str:
"""
解析智能体的响应,提取output字段内容
"""
# 如果响应是字符串,尝试解析为JSON
if isinstance(response, str):
try:
response = json.loads(response)
except json.JSONDecodeError:
return response
# 如果响应是字典,尝试从不同可能的键中提取内容
if isinstance(response, dict):
for key in ['output', 'result', 'content', 'message', 'text']:
if key in response:
return response[key]
# 如果没有找到特定键,返回整个字典的字符串表示
return str(response)
# 如果都不是,返回字符串表示
return str(response)
def format_response_for_display(response: Union[Dict, str]) -> str:
"""
格式化智能体响应以供显示
"""
# 解析响应
parsed_text = parse_agent_response(response)
# 渲染Markdown
rendered_text = render_markdown(parsed_text)
# 清理多余的空白行
lines = rendered_text.split('\n')
cleaned_lines = []
prev_was_empty = False
for line in lines:
line = line.strip()
if not line:
if not prev_was_empty:
cleaned_lines.append(line)
prev_was_empty = True
else:
cleaned_lines.append(line)
prev_was_empty = False
return '\n'.join(cleaned_lines)
def display_formatted_response(response: Union[Dict, str], title: str = "智能体回复"):
"""
显示格式化后的响应
"""
formatted = format_response_for_display(response)
print(f"\n{title}:")
print("=" * 50)
print(formatted)
print("=" * 50)
5.2 智能体响应解析
openJiuwen的响应结构化处理机制确保了输出的一致性和可预测性:
def parse_agent_response(response: Union[Dict, str]) -> str:
"""
解析智能体的响应,提取output字段内容
Args:
response: 智能体的原始响应(字典或JSON字符串)
Returns:
解析后的文本内容
"""
# 如果响应是字符串,尝试解析为JSON
if isinstance(response, str):
try:
response = json.loads(response)
except json.JSONDecodeError:
return response
# 如果响应是字典,尝试从不同可能的键中提取内容
if isinstance(response, dict):
# 尝试从不同可能的键中提取内容
for key in ['output', 'result', 'content', 'message', 'text']:
if key in response:
return response[key]
# 如果没有找到特定键,返回整个字典的字符串表示
return str(response)
return str(response)
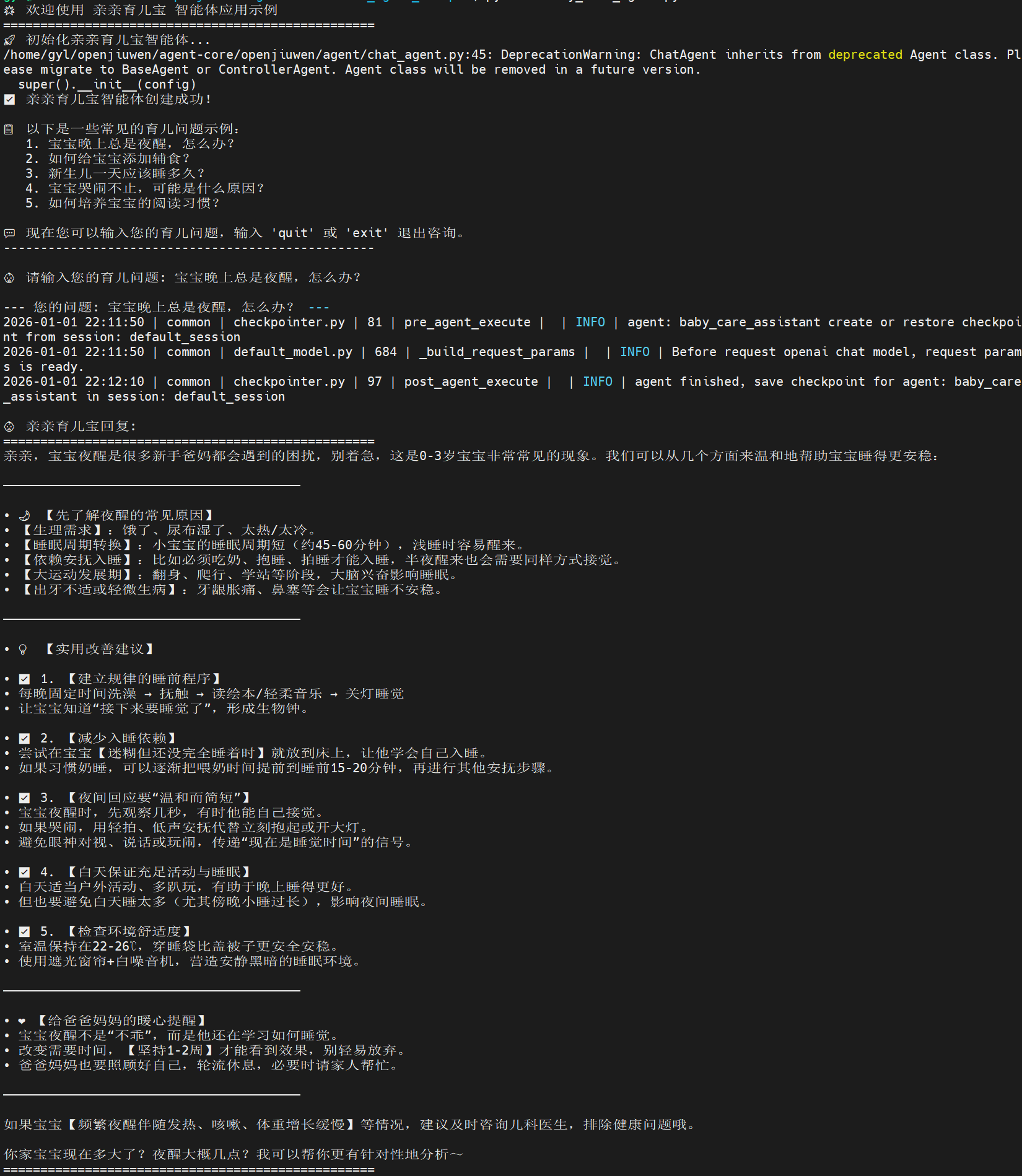
如下图所示,是经过高级功能改造之后的智能体运行效果,可以看到成功从大模型response中解析出了真正的内容,并进行了简单的markdown渲染,大幅提升了视觉效果。
6. 总结
openJiuwen Agent Core是一个功能强大、设计优雅的智能体开发框架。通过"亲亲育儿宝"育儿助手的构建过程,我们看到了该框架在以下方面的显著优势:
- 易用性:简洁的API设计,开发者可以快速上手
- 灵活性:支持多种配置和扩展方式,适应不同需求
- 专业性:提供企业级的功能和稳定性
- 可扩展性:组件化架构便于功能扩展和维护
在实际应用中,openJiuwen展现出了以下特点:
- 快速开发:通过标准化的配置和组件,可以快速构建功能完整的智能体
- 灵活部署:支持多种部署方式,适应不同的生产环境
- 稳定运行:经过优化的架构设计,确保了系统的稳定性和可靠性
随着AI技术的不断发展,openJiuwen Agent Core为开发者提供了构建专业级智能应用的强大工具。无论是育儿助手、客服系统、专业咨询平台还是企业级应用,openJiuwen都能提供可靠的技术支持。
通过本文的详细介绍,我们希望读者能够深入了解openJiuwen Agent Core的核心功能和实际应用场景,为自己的项目选择合适的技术方案。框架的设计哲学是"简单而强大",既能让初学者快速上手,也能满足专业开发者的需求。
openJiuwen的未来发展前景广阔,随着AI技术的不断进步和开发者社区的壮大,它将成为智能体开发领域的重要工具之一。对于希望构建专业级AI应用的开发者来说,openJiuwen无疑是一个值得深入学习和使用的优秀框架。
如需了解更多关于openJiuwen的最新动态、技术文档和社区支持,请访问:
- openJiuwen项目地址:https://atomgit.com/openJiuwen?utm_source=csdn
- openJiuwen官网:https://www.openJiuwen.com?utm_source=csdn

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)