mHC 深度解读:当流形几何遇上残差网络
在理解 mHC 的解决方案之前,我们需要理解"流形"这个概念。流形是"局部像欧氏空间"的空间。最直观的例子是地球表面:你站在任何一点,周围看起来像平面,但整体是弯曲的球面。在深度学习中,流形通常指带约束的参数空间流形约束自由度单位球面∣w∣1|w| = 1∣w∣1n−1n-1n−1正交矩阵WTWIW^T W = IWTWInn−122nn−1双随机矩阵行和=列和=1,非负n−12(n-1)^2n
DeepSeek 在 2025 年末发布了《mHC: Manifold-Constrained Hyper-Connections》,用一个优雅的数学工具解决了大规模 Transformer 训练中的多路残差网络稳定性问题。本文将从论文技术细节出发,理解 mHC 背后的设计哲学。
问题的起源:残差连接在LLM架构中的使用瓶颈
残差连接:深度学习的基石
2015 年 ResNet 提出的残差连接,是深度学习历史上重要的架构创新。其形式极其简洁:
y=x+F(x)y = x + F(x)y=x+F(x)
这个看似简单的加法,解决了深度网络训练中的梯度消失问题。关键在于恒等映射(Identity Mapping)—当 F(x)=0F(x) = 0F(x)=0 时,y=xy = xy=x,浅层信息可以不经过连续的权重变换而被带到更深层。
递归展开到 LLL 层:
xL=xl+∑i=lL−1F(xi,Wi)x_L = x_l + \sum_{i=l}^{L-1} F(x_i, W_i)xL=xl+i=l∑L−1F(xi,Wi)
这里没有连乘项,前向传播中存在一条不需要连乘权重矩阵的“直通”累加路径,避免了权重连乘导致的梯度爆炸(mHC的优化切入点)。反向传播虽仍涉及雅可比连乘,但每层变成 𝐼(单位矩阵)+ 扰动(RMSNorm、Dropout等),使梯度更不易指数级爆炸或消失,从而支持更深网络训练。
残差连接的跷跷板困境
但在 Transformer 的主流实现里,残差往往与归一化(Norm)绑定使用,残差连接有两种主流变体:Pre-Norm 和 Post-Norm,它们各有取舍。
Pre-Norm 在每个残差块之前做归一化,有效缓解了梯度消失问题,但可能会导致表示坍塌(representation collapse),深层的隐藏特征变得高度相似,削弱了模型的表达能力。
Post-Norm 保持了特征的多样性,但在深层网络中又容易出现梯度消失。
这就是所谓的跷跷板效应(seesaw effect):梯度稳定性和表示多样性难以兼得。
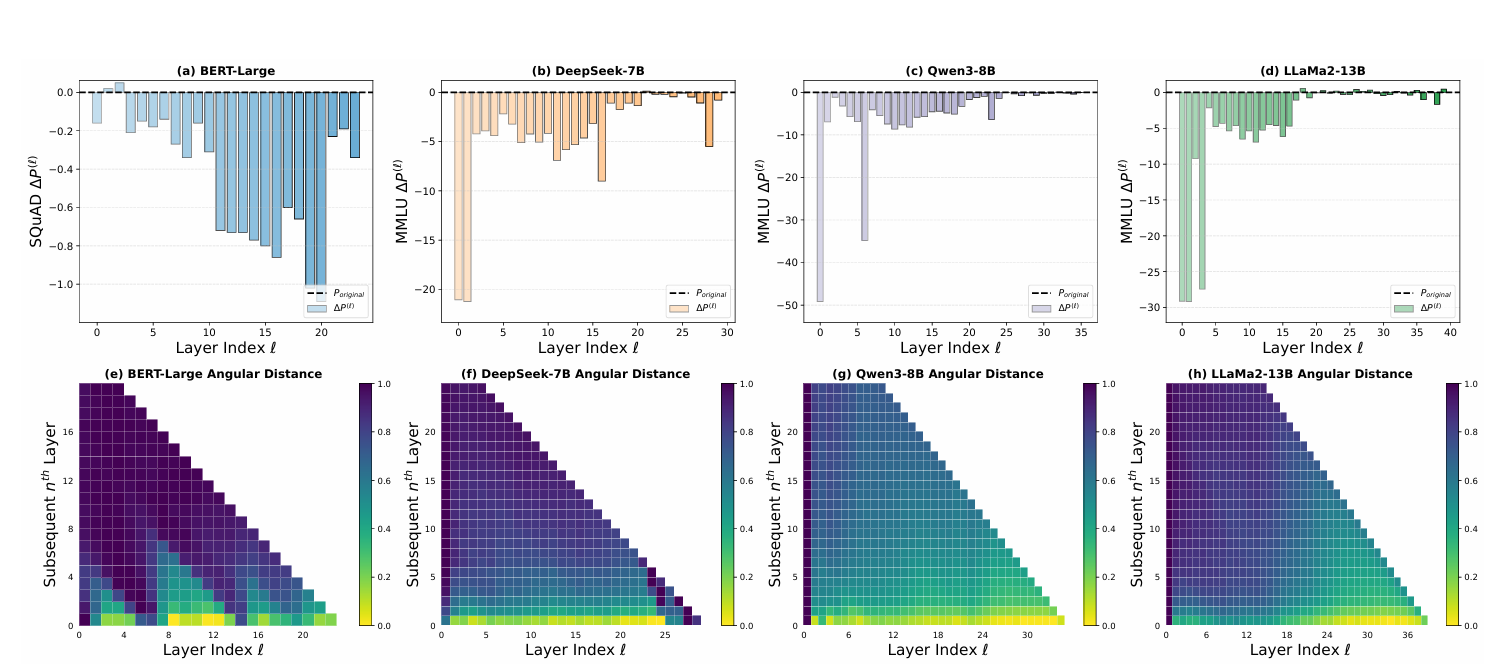
目前主流 LLM(GPT、LLaMA、DeepSeek、Qwen 等)基本都采用 Pre-Norm,因为训练稳定性是首要考量。但表示坍塌问题并非空穴来风,2025 年的西湖大学的研究[1](“Curse of Depth”)通过层剪枝实验证实:在 Llama、Mistral、DeepSeek、Qwen 等主流模型中,近半数的深层可以被移除而几乎不影响性能。这意味着这些深层的表示高度冗余,对模型能力贡献有限。理论分析表明,Pre-LN 的输出方差随深度指数增长,导致深层的梯度趋近于恒等变换,几乎不参与有效学习。
2024 年,字节跳动提出的 Hyper-Connections(HC)尝试打破这个困境。其核心洞察是:残差连接的形式过于固定,限制了网络学习最优信息流动方式的能力。
HC 将单条残差流扩展为 nnn 条并行流,并引入可学习的矩阵来控制它们的交互:
xl+1=Hlresxl+Hlpost⊤F(Hlprexl,Wl)x_{l+1} = H_l^{res} x_l + H_l^{post^\top} F(H_l^{pre} x_l, W_l)xl+1=Hlresxl+Hlpost⊤F(Hlprexl,Wl)
其中:
- xl∈Rn×Cx_l \in \mathbb{R}^{n \times C}xl∈Rn×C:nnn 条并行的残差流
- Hlres∈Rn×nH_l^{res} \in \mathbb{R}^{n \times n}Hlres∈Rn×n:控制各流之间如何混合
- Hlpre,HlpostH_l^{pre}, H_l^{post}Hlpre,Hlpost:控制从多流聚合到层输入、以及层输出分发回多流的映射
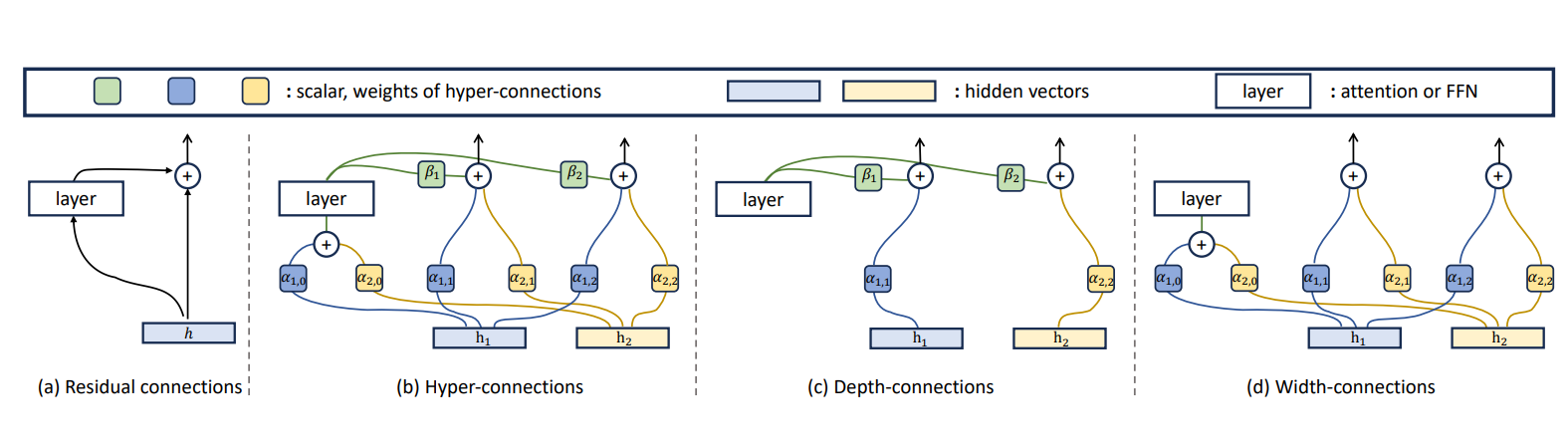
这个设计的精妙之处在于:通过学习不同的 HHH 矩阵连接权重,网络可以自适应地学习更合适的跨深度连接强度,并在拓扑意义上重排层的组合方式。当 HresH^{res}Hres 是单位矩阵时,退化为标准残差连接。当 HHH 以特定模式设置时,让网络能够学习更灵活的连接形态与重排方式(包括顺序/并行的拓扑表达,以及输入自适应的动态权重。
HC 在实验中展现了显著的性能提升,但当 DeepSeek 尝试将其应用于 27B 规模的模型训练时,问题出现了。
HC 在大规模训练中的挑战
为了理解 HC 的不稳定性来源,需要先看它的哪个组件最关键。mHC 论文的消融实验表明,HC 的三个映射中,HresH^{res}Hres(残差映射)对性能提升贡献最大,它控制着多条残差流之间的信息交换。但正是这个关键组件,在多层累积时带来了数值稳定性风险。

将 HC 递归展开到多层:
xL=(∏i=1L−lHL−ires)xl+∑i=lL−1(∏j=1L−1−iHL−jres)Hipost⊤F(Hiprexi,Wi) \begin{aligned} x_L &= \left(\prod_{i=1}^{L-l} H_{L-i}^{res}\right) x_l \\ &\quad + \sum_{i=l}^{L-1} \left(\prod_{j=1}^{L-1-i} H_{L-j}^{res}\right) H_i^{post^\top} F(H_i^{pre} x_i, W_i) \end{aligned} xL=(i=1∏L−lHL−ires)xl+i=l∑L−1(j=1∏L−1−iHL−jres)Hipost⊤F(Hiprexi,Wi)
与标准残差连接的关键区别在于那个连乘项 ∏i=1L−lHL−ires\prod_{i=1}^{L-l} H_{L-i}^{res}∏i=1L−lHL−ires。标准残差的递归展开是 xL=xl+∑F(xi)x_L = x_l + \sum F(x_i)xL=xl+∑F(xi),浅层信号 xlx_lxl 直接加到深层,无需经过任何矩阵变换。而 HC 的 HresH^{res}Hres 是无约束的可学习矩阵,浅层信号必须经过多个 HresH^{res}Hres 的连乘才能到达深层,这个复合映射可能显著偏离恒等映射。
论文通过 Amax Gain Magnitude(复合映射的行和/列和最大绝对值)来量化这种偏离。在 27B 模型的实测中,HC 的复合映射增益峰值达到约 3000,远远偏离理想值 1。这种信号放大在前向传播中导致激活值爆炸,在反向传播中导致梯度不稳定。
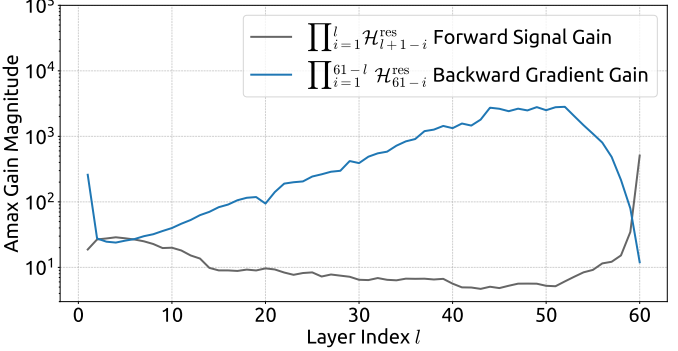
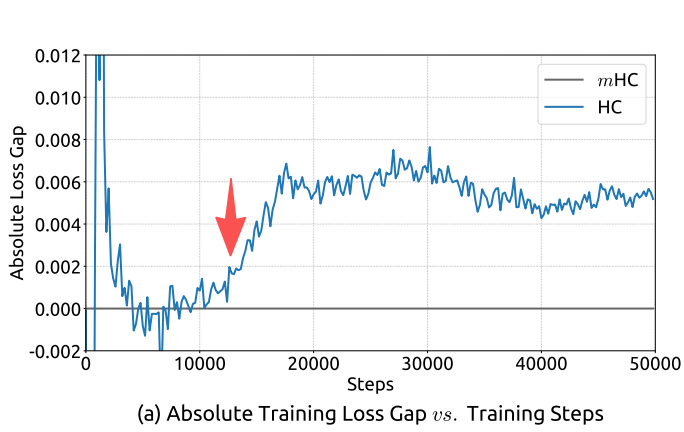
mHC实验观察到HC训练在约 12k 步时出现 loss 突增,伴随梯度范数的剧烈震荡。虽然训练最终恢复,但这种不稳定性限制了 HC 在更大规模上的应用。
流形约束:数学之美
什么是流形?
在理解 mHC 的解决方案之前,我们需要理解"流形"这个概念。
流形是"局部像欧氏空间"的空间。 最直观的例子是地球表面:你站在任何一点,周围看起来像平面,但整体是弯曲的球面。
在深度学习中,流形通常指带约束的参数空间:
| 流形 | 约束 | 自由度 |
|---|---|---|
| 单位球面 | ∣w∣=1|w| = 1∣w∣=1 | n−1n-1n−1 |
| 正交矩阵 | WTW=IW^T W = IWTW=I | n(n−1)2\frac{n(n-1)}{2}2n(n−1) |
| 双随机矩阵 | 行和=列和=1,非负 | (n−1)2(n-1)^2(n−1)2 |
在本文语境中,流形更接近“结构化的可行域/约束集合”。需要注意的是,双随机矩阵集合也被称为 Birkhoff 多面体,它是由等式约束(行/列和为 1)和不等式约束(非负)共同定义的凸多面体,并非严格意义上处处光滑的流形。mHC 通过 exp+Sinkhorn 产生严格正的近似双随机矩阵,使优化主要发生在多面体内部,从而保持可微与数值稳定。
为什么选择双随机矩阵?
mHC 的核心创新是将 HlresH_l^{res}Hlres 约束到双随机矩阵(Doubly Stochastic Matrix)上。
双随机矩阵的定义:
- 所有元素非负
- 每行之和 = 1
- 每列之和 = 1
为什么这个约束如此完美?因为它同时满足三个关键性质:
性质 1:谱范数有界
双随机矩阵的谱范数 ∥H∥2≤1\|H\|_2 \leq 1∥H∥2≤1,这意味着它不会放大信号。
性质 2:乘法封闭
两个双随机矩阵相乘,结果仍是双随机矩阵。证明很简单:
- (AB)(AB)(AB) 的行和 = A×A \timesA× (B 的行和向量) = A×1=1A \times \mathbf{1} = \mathbf{1}A×1=1 ✓
- 列和同理 ✓
- 非负性:非负矩阵乘积仍非负 ✓
这意味着无论堆多少层,∏i=1L−lHL−ires\prod_{i=1}^{L-l} H_{L-i}^{res}∏i=1L−lHL−ires 仍然是双随机的,信号永远有界!
性质 3:几何意义清晰
双随机矩阵构成 Birkhoff 多面体,它是所有置换矩阵的凸包。换句话说,每个双随机矩阵都可以看作"软置换",它重新分配信息而不创造或消灭信息。
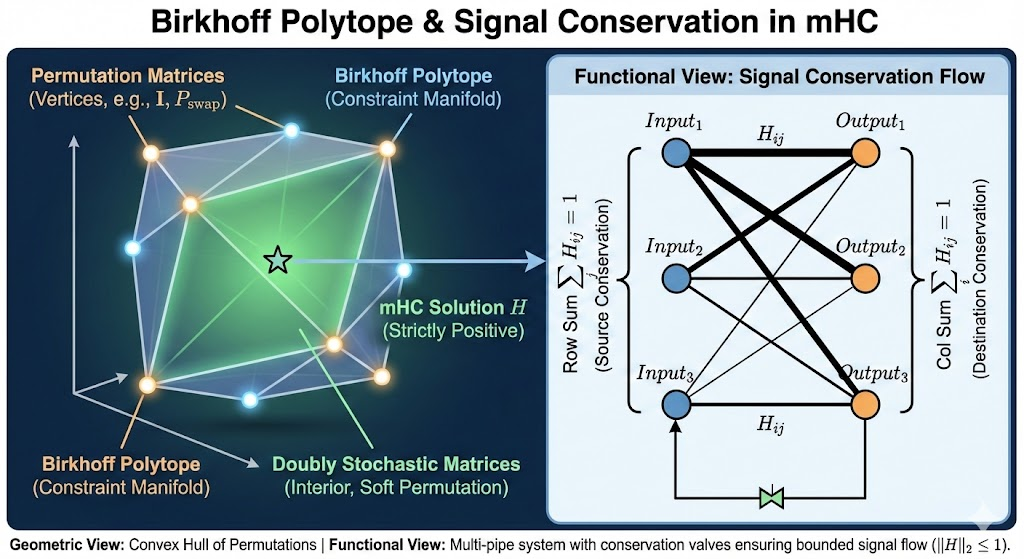
信号守恒的直觉
让我用一个直观的类比:
| 方案 | 类比 |
|---|---|
| 标准残差 | 单管道供水,水直接流过 |
| HC(无约束) | 多管道 + 任意阀门,可能积水或溢出 |
| mHC(双随机约束) | 多管道 + 守恒阀门,总水量不变 |
双随机矩阵保证了"质量守恒":每个输入特征被完整地分配到各个输出流(列和=1),每个输出流接收的特征总量也恒定(行和=1)。
工程实现:从理论到 27B 规模
有了漂亮的数学基础,如何让它在真实的大规模训练中跑起来?这是论文的另一大贡献。
Sinkhorn-Knopp 算法
如何将任意矩阵投影到双随机流形上?论文采用了经典的 Sinkhorn-Knopp 算法:
输入:任意矩阵 M
1. M⁽⁰⁾ = exp(M) // 先变成正矩阵
2. 重复 t_max 次:
- 列归一化:每列除以列和
- 行归一化:每行除以行和
3. 输出 M⁽ᵗᵐᵃˣ⁾
这个算法交替归一化行和列,迭代收敛到双随机矩阵。论文选择 tmax=20t_{max} = 20tmax=20 作为精度与效率的平衡点。
Kernel Fusion:解决内存墙
HC/mHC 的多流设计带来了严重的 I/O 开销:
| 方法 | 读取元素 | 写入元素 |
|---|---|---|
| 标准残差 | 2C2C2C | CCC |
| HC | (5n+1)C+n2+2n(5n+1)C + n^2 + 2n(5n+1)C+n2+2n | (3n+1)C+n2+2n(3n+1)C + n^2 + 2n(3n+1)C+n2+2n |
当 n=4n=4n=4 时,内存访问成本几乎增加了 10倍,以 n=4 为例,21C/2C=10.5,因此必须依赖 fused kernels 才能避免吞吐显著下降。
论文的解决方案是算子融合(Kernel Fusion):
- 将多个操作合并到单个 CUDA kernel 中
- 减少中间结果的读写
- 使用 TileLang 实现高效的混合精度计算
融合后,读取元素从 (3n+1)C(3n+1)C(3n+1)C 降到 (n+1)C(n+1)C(n+1)C,写入从 3nC3nC3nC 降到 nCnCnC。
选择性重计算
nnn 条并行流意味着 nnn 倍的激活值存储。论文采用了巧妙的选择性重计算策略:
- 将模型划分为 LrL_rLr 层的块
- 每个块只保存第一层的输入 xl0x_{l_0}xl0
- 反向传播时,重新执行 mHC 核(不包括重型的 FFF 函数)
最优块大小:
Lr∗≈nLn+2L_r^* \approx \sqrt{\frac{nL}{n+2}}Lr∗≈n+2nL
这个公式平衡了常驻内存(块越大,需要保存的 xl0x_{l_0}xl0 越少)和瞬时内存(块越大,重计算时的临时开销越大)。
DualPipe 通信优化
在流水线并行中,nnn 流设计意味着 nnn 倍的跨节点通信。论文扩展了 DualPipe 调度策略:
- MLP 层的 Fpost,resF_{post,res}Fpost,res 核放在高优先级计算流
- 注意力层避免使用持久化核,允许被抢占
- 重计算与流水线通信解耦(xl0x_{l_0}xl0 已本地缓存)
最终结果:27B 模型训练,mHC 仅引入 6.7% 的额外时间开销。
实验结果:稳定性与性能的双赢
训练稳定性
最直观的对比是 HC 和 mHC在Single layer mapping和Composite Mapping上的训练稳定性。
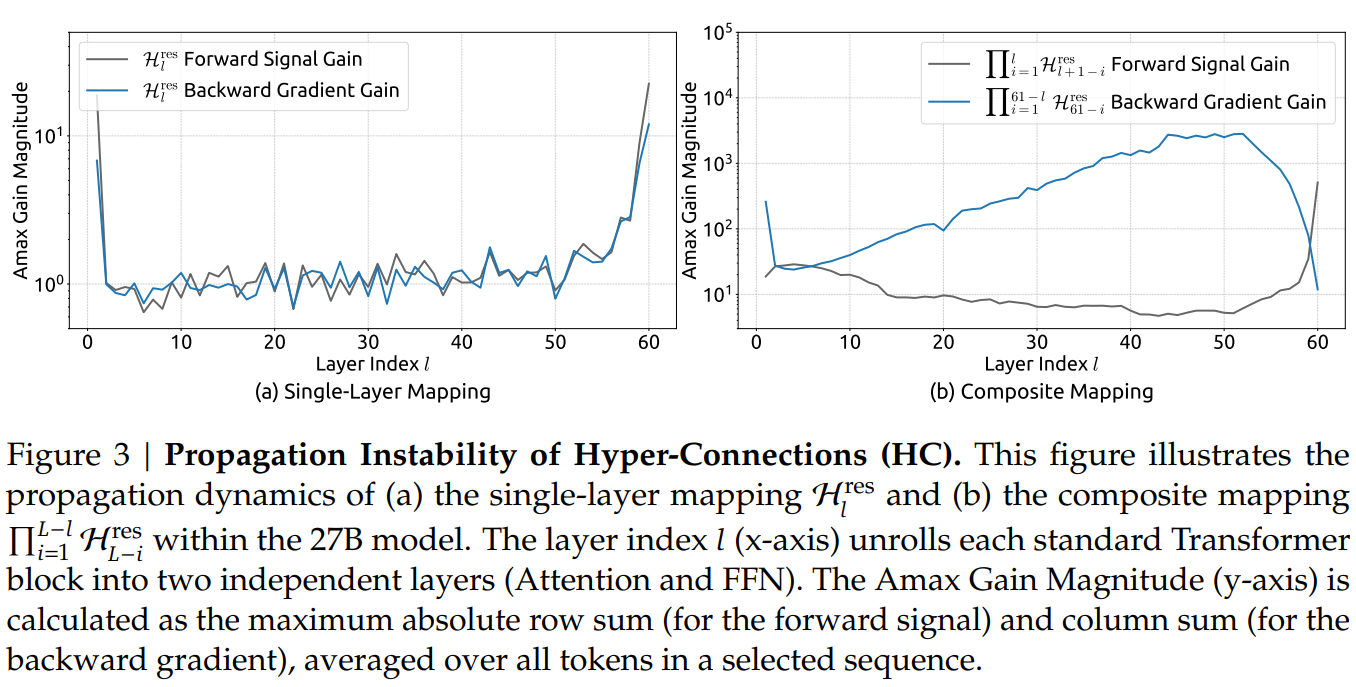
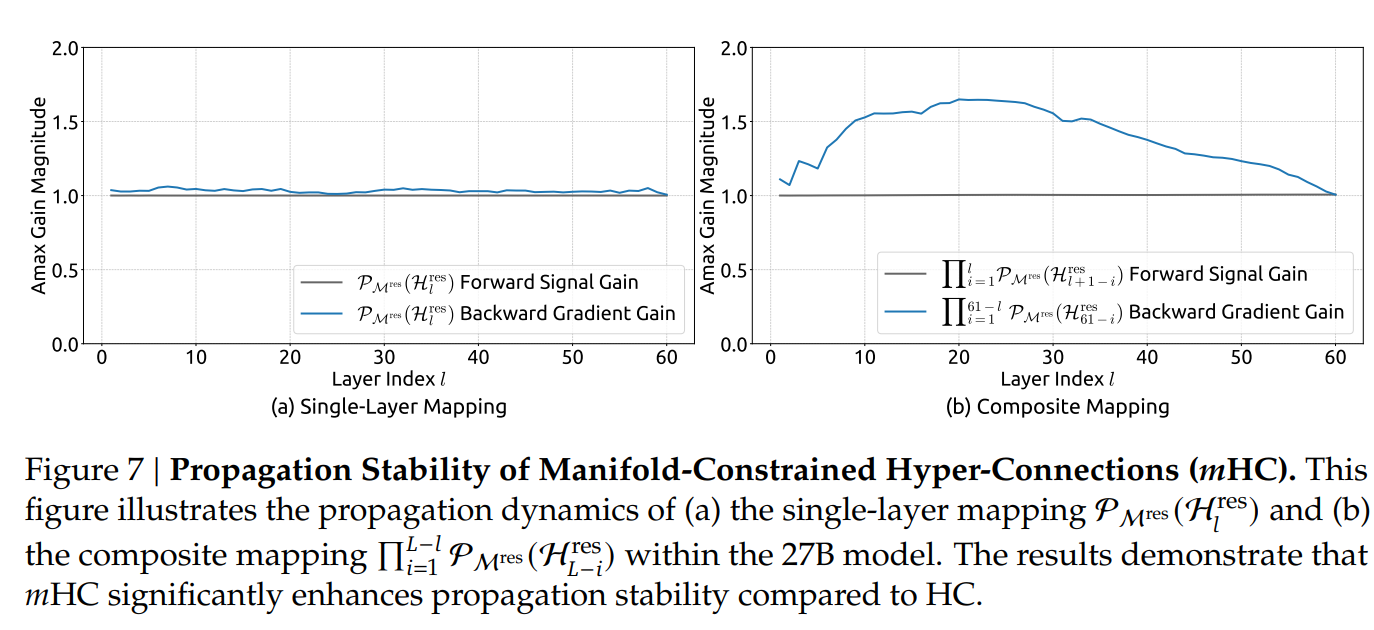
mHC 将信号增益控制在了理论值 1 附近,实现了三个数量级的改进!
下游任务性能
27B 模型在 8 个 benchmark 上的表现:
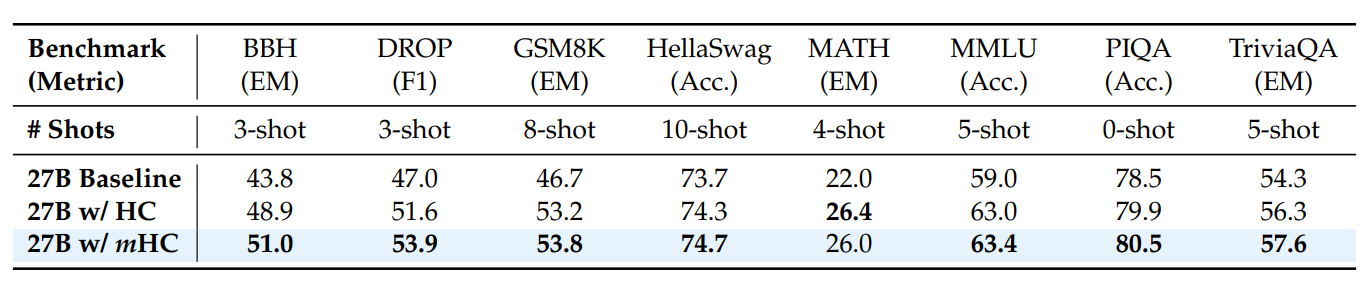
mHC 不仅比 baseline 有显著提升(继承了 HC 的多流优势),还在大多数任务上超越了不稳定的 HC。
Scaling 特性
论文验证了 mHC 在不同规模下的表现(absolutely loss gap):
- 3B → 9B → 27B:性能优势稳健保持
- Token scaling:1T tokens 训练全程优于 baseline
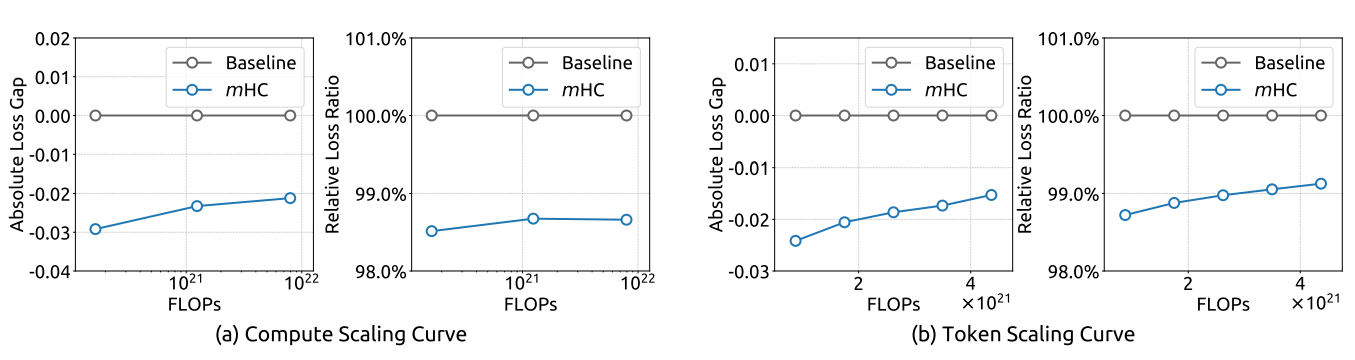
这表明 mHC 不是小规模的 trick,而是可以真正 scale 的架构改进。
扩展思考
流形约束的一般模式
mHC 体现了一个通用的设计模式:
当无约束优化导致不稳定时,将参数约束到一个"良性"流形上。
关键是找到一个流形满足:
- 包含你需要的表达能力(双随机矩阵可以表达任意"软路由")
- 排除会导致病态的参数(谱范数 > 1 的矩阵)
- 投影计算高效(Sinkhorn 迭代)
这个思路可以推广到其他场景:
- 权重归一化:球面流形
- 正交 RNN:Stiefel 流形
- 低秩适配:低秩流形(如 LoRA)
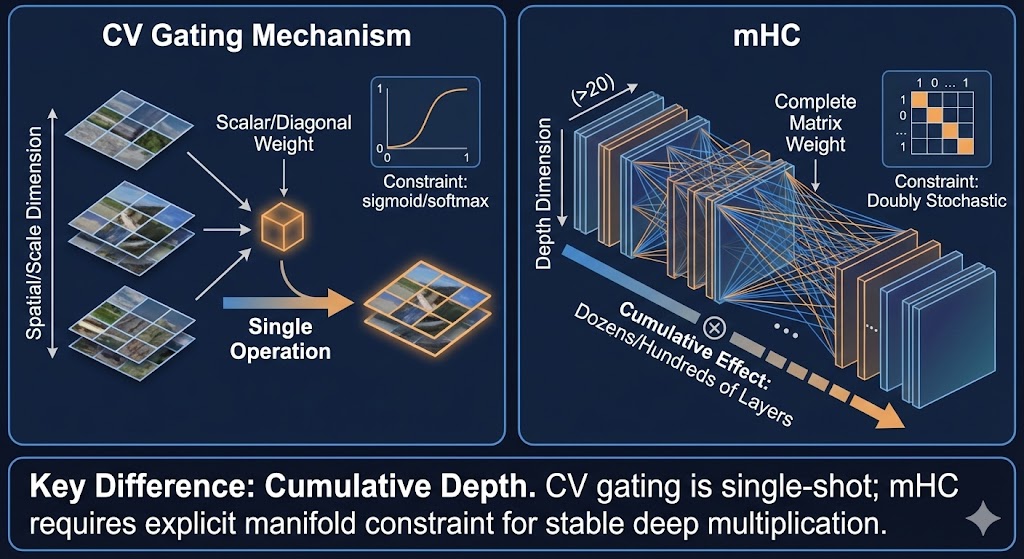
与 CV 门控机制的联系
mHC 的设计与 CV 领域的门控特征聚合有异曲同工之妙:
| CV 门控 | mHC | |
|---|---|---|
| 聚合维度 | 空间/尺度 | 深度 |
| 权重形式 | 标量/对角 | 完整矩阵 |
| 约束 | sigmoid/softmax | 双随机 |
| 累积效应 | 通常单次 | 几十上百层累乘 |
关键区别是累积深度:CV 的门控通常只在特定位置做一次,而 mHC 的矩阵要连乘几十次。这也是为什么 CV 不太需要显式的流形约束,而 LLM 需要。
技术研究启示
论文在结论中提到了几个有趣的方向:
-
其他流形的探索:除了双随机矩阵,正交矩阵、酉矩阵、单纯形约束等是否有独特优势?
-
宏观架构设计的复兴:过去几年社区主要关注微观设计(attention 变体、FFN 改进),mHC 提示我们:层与层之间的连接方式同样重要。
-
几何/代数先验的系统化应用:通过数学工具主动设计参数空间的结构,提供一种更系统的设计视角。
工程化复现挑战:6.7% 背后的代价
虽然mHC 在 27B 模型上仅带来 6.7% 的额外训练时间开销。这个数字看起来很诱人,但它是 DeepSeek 团队高度工程优化后的结果,而非开箱即用的性能。
优化项与实现难度
要从 50%+ 降到 6.7%,需要完成一系列精细的工程优化。
首先是 Sinkhorn-Knopp 算法的 kernel 实现。前向传播需要将 20 次迭代融合到单个 kernel 中,避免反复的显存读写。反向传播更为复杂,需要自定义梯度计算逻辑,并在芯片上重算中间结果以节省显存,这要求开发者对 GPU 内存层级有深入理解。
其次是 计算重排序与融合。论文将 RMSNorm 的除法操作重排到矩阵乘法之后,保持数学等价的同时提升了效率。此外,团队用 TileLang 手写了 5 个融合 kernel,将多个操作合并执行,最大化内存带宽利用率。
混合精度策略也至关重要。论文明确指定了各变量的精度:投影矩阵使用 tfloat32,隐藏状态使用 bfloat16,门控因子和最终系数使用 float32。精度选择不当会导致数值不稳定或性能下降。
在显存管理方面,选择性重计算策略将模型划分为多个块,每个块只保存首层输入,反向传播时重算中间激活。最优块大小 Lr∗L_r^*Lr∗ 需要与流水线阶段边界对齐,涉及理论分析和工程约束的平衡。
最复杂的是 DualPipe 通信重叠。这涉及普通计算流、通信流、高优先级计算流的三路协调,MLP 和 Attention 层需要差异化处理,同时要确保重计算过程与流水线通信解耦。这部分需要对分布式训练框架有深度定制能力。
复现的现实考量
目前论文未开源代码,这意味着想要复现 mHC 的团队需要从零实现上述所有优化。
对于大多数团队而言,使用 PyTorch 等标准框架的自动微分机制,难以实现论文中描述的深度 kernel 融合和精细的内存管理。即使有 CUDA 开发经验,完整复现 TileLang 实现的融合 kernel、Sinkhorn-Knopp 的自定义反向传播、以及 DualPipe 调度的修改版本,也需要相当的工程投入。
因此,6.7% 这个数字更多是 DeepSeek 工程能力的体现,而非 mHC 方法本身的固有开销。在没有官方开源实现的情况下,复现团队应当预期显著高于这一数字的实际开销,并根据自身的工程能力和优化投入逐步逼近论文报告的水平。
小结
mHC 是一篇兼具理论优雅和工程扎实的工作。它清晰地定义了问题,HC的多流设计破坏了残差连接的恒等映射性质导致信号爆炸,并用双随机矩阵的流形约束给出了数学上简洁的解决方案。从 Sinkhorn 投影到 kernel fusion,从选择性重计算到 DualPipe 优化,论文展示了从理论到大规模落地的完整路径。
这篇论文的价值不仅在于 mHC 本身。过去几年,社区的注意力主要集中在 Transformer 的微观设计上,更高效的 attention 变体、稀疏化的 FFN、更好的位置编码。而 mHC 提醒我们,宏观架构-层与层之间如何连接、信息如何流动,同样值得深入探索。残差连接这个十年前的设计,并非不可改进,只是需要更精细的数学工具来保证稳定性。
从更广的视角看,mHC 代表了一种设计范式:用几何/代数约束来驯服自由度过高的参数空间。双随机流形之于残差混合矩阵,正如正交约束之于 RNN 权重、低秩约束之于适配器参数。这种"先放开再约束"的思路,可能在其他架构设计中同样适用。
当然,挑战依然存在。mHC 的工程复杂度不低,6.7% 的开销是高度优化后的结果,复现门槛较高。论文验证的最大规模是 27B,在更大模型上的表现还有待观察。此外,双随机约束是否是最优选择?正交矩阵、酉矩阵等其他流形是否有独特优势?这些问题都值得进一步探索。
mHC的探索为基础模型的架构演进打开了一扇新的窗户,当 scaling law 的边际收益递减时,或许正是重新审视架构本身的好时机。
本文基于 DeepSeek-AI 的论文 “mHC: Manifold-Constrained Hyper-Connections” (arXiv:2512.24880) 撰写。
https://arxiv.org/pdf/2512.24880

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)