[机器学习-从入门到入土] 词嵌入
[机器学习-从入门到入土] 词嵌入
[机器学习-从入门到入土] 词嵌入
个人导航
知乎:https://www.zhihu.com/people/byzh_rc
CSDN:https://blog.csdn.net/qq_54636039
注:本文仅对所述内容做了框架性引导,具体细节可查询其余相关资料or源码
参考文章:各方资料
词嵌入Word Embedding
神经网络只能处理数值向量,因此必须先把词映射为向量
具有相同含义的词语会获得相似的表示
大多数神经网络难以有效处理非常高维且稀疏的向量
-> 使用低维且稠密的向量
词袋模型(bag-of-words)(BOW)
计每个单词出现的次数,将任意文本转换为固定长度向量的表示方法
- 词表大小 = V V V
- 每个文本 → 一个 V V V 维向量
- 每一维表示某个词出现的次数
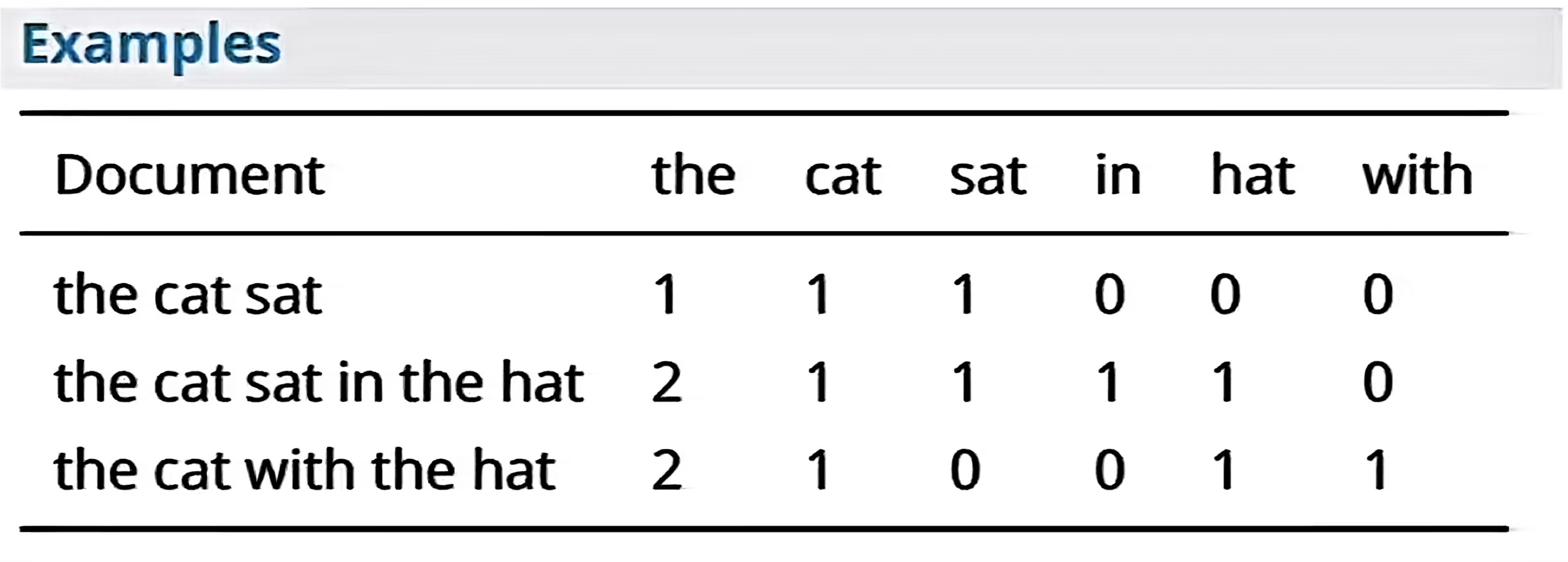
问题 1:极度稀疏
- 一个句子只包含极少数词
- 向量中几乎全是 0
问题 2:没有语义结构
- “king” 与 “queen” 在向量空间中正交
- “king” 和 “apple” 距离一样远
Word Embedding 的目标: 用低维、稠密的连续向量表示词,并让“语义相近的词在向量空间中距离更近”
Word2Vec
词的含义来自它的上下文
-> 语义相似的词会出现在相似的上下文中
Skip-gram:
给定语料:“the king loves the queen”
以窗口大小 c = 2 c=2 c=2 为例:当中心词是 king, 要预测the, loves
于是训练样本变成:
( king → the ) , ( king → loves ) (\text{king} \rightarrow \text{the}),\quad (\text{king} \rightarrow \text{loves}) (king→the),(king→loves)
Skip-gram 的目标函数(最大化):
1 T ∑ t = 1 T ∑ − c ≤ j ≤ c , j ≠ 0 log p ( w t + j ∣ w t ) \frac{1}{T}\sum_{t=1}^{T}\sum_{-c\leq j\leq c,j\neq 0}\log p\left(w_{t+j}\mid w_{t}\right) T1t=1∑T−c≤j≤c,j=0∑logp(wt+j∣wt)
- T T T:语料中词的总数
- w t w_t wt:中心词
- w t + j w_{t+j} wt+j:上下文词
- 目标:给定中心词 w t w_t wt,最大化真实上下文词出现的概率
Skip-gram 的概率模型:(Softmax)
p ( w O ∣ w I ) = exp ( v w O ′ ⊤ v w I ) ∑ w = 1 W exp ( v w ′ ⊤ v w I ) p\left(w_{O}\mid w_{I}\right) =\frac{\exp\left(v_{w_{O}}^{\prime\top} v_{w_{I}}\right)} {\sum_{w=1}^{W}\exp\left(v_{w}^{\prime\top} v_{w_{I}}\right)} p(wO∣wI)=∑w=1Wexp(vw′⊤vwI)exp(vwO′⊤vwI)
-
v w I v_{w_I} vwI:输入词向量(中心词)
-
v w O ′ v'_{w_O} vwO′:输出词向量(上下文词)
-
训练结束后:通常只保留 v w v_w vw 作为词嵌入
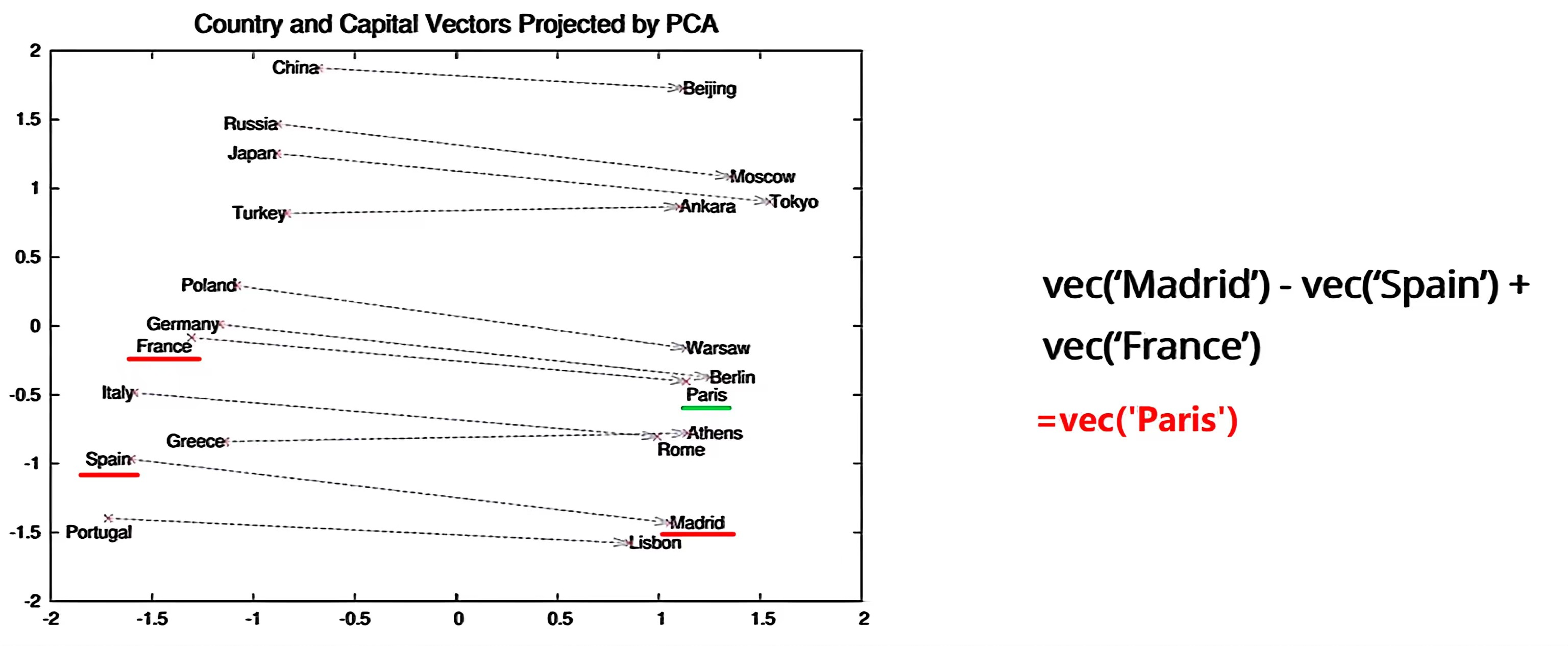
也有: King - man +woman -> Queen
说明能学到单词之间的逻辑关系
| 维度 | BOW | Word2Vec |
|---|---|---|
| 向量维度 | 词表大小(上万) | 低维(50–300) |
| 稀疏性 | 极稀疏 | 稠密 |
| 是否学习 | ❌ 固定编码 | ✅ 从数据中学 |
| 语义相似性 | ❌ 无 | ✅ 有 |
| 词间关系 | ❌ | ✅(向量运算) |

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)