AI智能体编排“神操作“:小白程序员也能让大模型变聪明,代码示例超详细!
文章深入探讨AI智能体的编排策略,详述六种智能体类型及适用场景,分析三种工具选择方法和四种执行拓扑结构。强调上下文工程确保有效执行的核心作用,提供设计智能体系统的最佳实践,帮助开发者构建高效可靠处理现实世界多步骤任务的智能体系统。
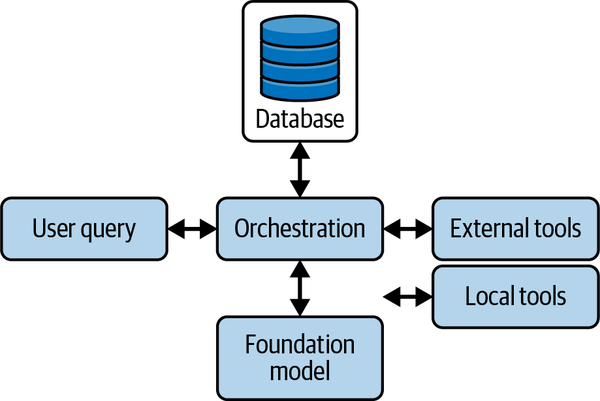
现在我们的智能体(Agent)已经拥有了一套可用的工具,是时候对它们进行编排以解决实际任务了。编排不仅仅是决定调用哪些工具以及何时调用,它还涉及为每个模型调用构建正确的上下文,以确保采取有效且有据可依的行动。虽然简单的任务可能只需要单一工具和最少的上下文,但更复杂的工作流需要仔细规划、记忆检索和动态上下文组装,才能准确地执行每一步。本章将涵盖编排策略、上下文工程、工具选择、执行和规划拓扑结构,以构建能够高效且可靠地处理现实世界多步骤任务的智能体。正如我们在图 5-1 中所见,编排是系统利用现有资源有效解决用户查询的方式。
一、智能体类型 (Agent Types)
在深入具体的编排策略之前,了解所能构建的不同类型的智能体非常重要。每种智能体类型体现了推理、规划和行动的不同方法,这决定了任务如何被分解和执行。有些智能体通过预编程的映射立即响应,而另一些则进行迭代推理和反思以处理复杂的、开放式的目标。智能体类型的选择直接影响系统的性能、成本和能力。在本节中,我们将探索这一范畴:从提供闪电般快速响应的反射型智能体,到通过自适应计划和综合处理多阶段调查的深度研究智能体。了解这些原型将有助于设计符合你应用需求和限制的智能体,并阐明编排模式、工具选择和上下文构建如何在每种类型中结合以实现有效、可靠的结果。
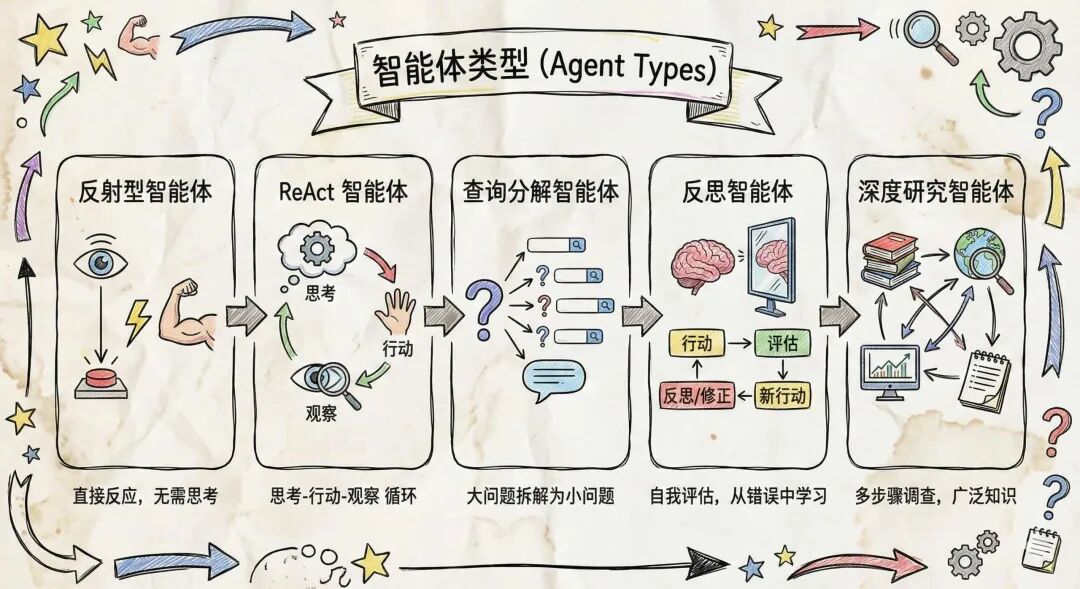
反射型智能体 (Reflex Agents)
反射型智能体实现从输入到动作的直接映射,没有任何内部推理痕迹。简单的反射型智能体遵循“如果-条件,那么-动作”的规则,一旦检测到预定义的触发器就立即调用相应的工具。因为它们绕过了中间的思维步骤,反射型智能体以最小的延迟和可预测的性能提供响应,这使它们非常适合诸如基于关键词的路由、单步数据查找或基本自动化(例如,“如果 X,则调用工具 Y”)等用例。然而,它们有限的表达能力意味着无法处理需要多步推理或超出即时输入上下文的任务。
ReAct 智能体 (ReAct Agents)
ReAct 智能体在一个迭代循环中交替进行推理 (Reasoning) 和行动 (Action):模型生成一个想法,选择并调用一个工具,观察结果,并根据需要重复此过程。这种模式使智能体能够将复杂的任务分解为可管理的步骤,根据中间观察更新其计划:
- ZERO_SHOT_REACT_DESCRIPTION (LangChain): 在单个提示中呈现工具和说明,依靠 LLM 的内在推理能力来选择和调用工具,无需示例痕迹。
- CHAT_ZERO_SHOT_REACT_DESCRIPTION: 通过结合对话历史扩展了上述功能,使智能体在决定下一步行动时能够利用过去的交流。
ReAct 智能体在探索性场景(动态数据分析、多源聚合或故障排除)中表现出色,在这些场景中,中途调整的能力胜过额外的延迟和计算开销。它们的循环结构还提供了透明度(“思维链”),有助于调试和审计,尽管这可能会增加 API 成本和响应时间。
规划-执行智能体 (Planner-Executor Agents)
规划-执行智能体将任务分为两个不同的阶段:规划,即模型生成多步计划;和执行,即通过工具调用执行每个计划步骤。这种清晰的分离让规划者专注于长远推理,而执行者仅调用必要的工具,减少了多余的 LLM 调用。因为计划是显式的,调试和监控变得简单明了——你可以检查生成的计划,跟踪哪一步失败了,并在需要时重新规划。这种方法有多个优点:
- 清晰的分解: 复杂的任务分解为可管理的子任务。
- 可调试性: 显式的计划揭示了错误发生的位置和原因。
- 成本效率: 较小的模型或较少的 LLM 调用处理执行,将大模型保留用于规划。
查询分解智能体 (Query-Decomposition Agents)
查询分解智能体通过迭代地将复杂问题分解为子问题,为每个子问题调用搜索或其他工具,然后综合最终答案来解决问题。这种模式——通常称为“带搜索的自问自答 (self-ask with search)”——提示模型:“我需要问什么后续问题?” → 调用搜索 → “下一个问题是什么?” → … → “最终答案是什么?”
示例:SELF_ASK_WITH_SEARCH
- 提问: “谁活得更久,X 还是 Y?”
- 自问: “X 的寿命是多少?” → 搜索工具
- 自问: “Y 的寿命是多少?” → 搜索工具
- 综合: “X 活了 85 岁,Y 活了 90 岁,所以 Y 活得更久”
当需要外部知识检索时,这种方法表现出色,确保每个事实在组成最终响应之前都基于工具输出。
反思智能体 (Reflection Agents)
反思和元推理智能体扩展了 ReAct 范式,不仅交替进行思考和行动,而且还回顾过去的步骤以在继续之前识别和纠正错误。在这种方法中——以最近提出的 ReflAct 框架为例——智能体不断将其推理建立在目标状态反思的基础上,根据预期结果衡量其当前状态,并在出现偏差时调整其计划。反思提示鼓励模型批评自己的思维链,纠正逻辑错误,并加强成功的策略,有效地模拟复杂问题解决过程中的人类自我评估。
这种模式在错误可能导致代价高昂的失败的高风险工作流中大放异彩——例如金融交易编排、医疗诊断支持或关键事件响应。通过将每个行动与反思步骤配对,智能体可以检测工具输出何时偏离预期,并可以在提交不可逆操作之前重新规划或回滚。增加的元推理开销确实会带来额外的延迟和计算,但对于正确性和可靠性重于速度的任务,反思智能体提供了防止错误传播的强大护栏,并有助于保持与总体目标的一致性。
深度研究智能体 (Deep Research Agents)
深度研究智能体专门处理开放式的、高度复杂的调查,这些调查需要广泛的外部知识收集、假设测试和综合——比如文献综述、科学发现或战略市场分析。它们结合了多种模式:规划-执行阶段用于制定研究工作流;查询分解用于将大问题分解为有针对性的搜索;以及 ReAct 循环用于根据新发现迭代地完善假设。在一个典型的周期中,深度研究智能体将:
- 规划整体研究议程(例如,确定关键子主题或数据源)。
- 将每个子主题分解为具体的查询(通过 SELF_ASK 或类似方法)。
- 调用工具——从学术搜索 API 到特定领域的数据库——并反思每个结果的相关性和可靠性。
- 将见解综合成不断发展的报告或建议集,在每一步使用 LLM 驱动的总结和批评。
优势:
- 能力强: 可以处理依赖专业数据库和跨学科来源的高复杂度、多阶段调查。
- 自适应: 随着新证据的出现调整研究方向。
- 透明: 显式的计划和分解步骤使审计方法变得容易。
劣势:
- 高成本: 广泛的基础模型使用和多次 API 调用会增加计算和 Token 费用。
- 延迟: 每一层规划、分解和反思都会增加延迟。
- 脆弱性: 依赖于外部数据源的质量和可用性,需要仔细的错误处理和回退策略。
最佳用例是长篇、专家级的任务——学术文献调查、技术尽职调查、竞争情报——在这些任务中,深度和严谨性胜过速度。
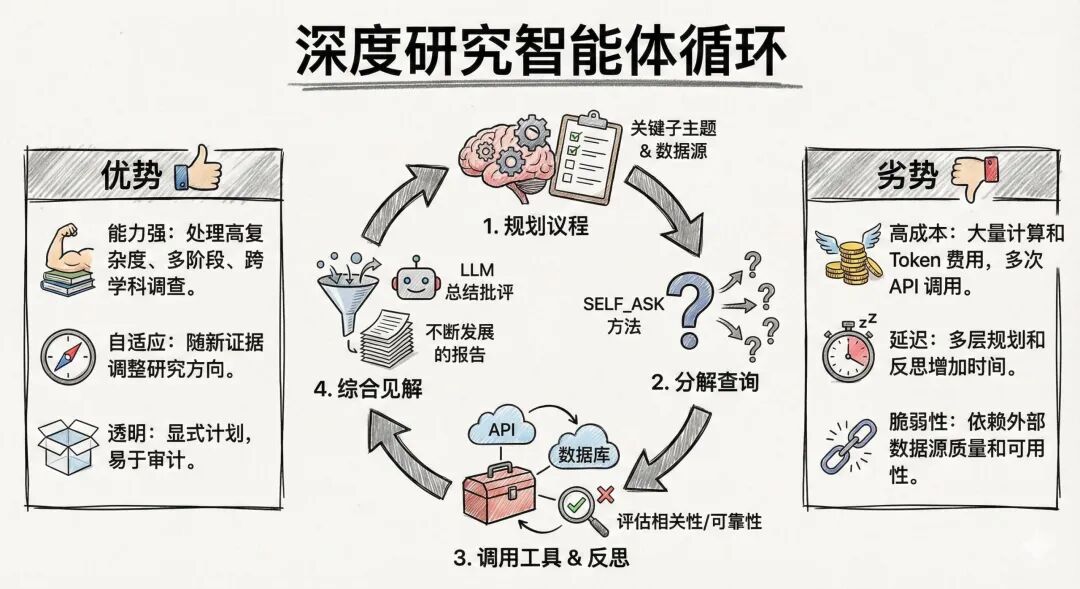
表 5-1 提供了当今最常见智能体原型的快照——每种都在速度、灵活性和复杂性方面有其权衡。然而,这个领域正在飞速发展。新的混合模式、元推理框架和规划策略一直在出现,智能体类型的分类只会变得更加细微。将此列表视为起点而非最终分类:随着领域的进步,你将看到建立在这些基础上的新方法,所以保持好奇心,经常实验,并准备好随着研究和工具的成熟调整你的编排策略。
表 5-1. 常见智能体原型
| 智能体类型 | 优势 | 劣势 | 最佳用例 |
|---|---|---|---|
| Reflex (反射型) | 毫秒级响应 | 无多步推理 | 关键词路由,简单查找 |
| ReAct | 灵活,即时适应 | 较高的延迟和成本 | 探索性工作流,故障排除 |
| Plan-execute (规划-执行) | 清晰的任务分解 | 规划开销 | 复杂的多步流程 |
| Query-decomposition (查询分解) | 基于事实的检索准确性 | 多次工具调用 | 研究,基于事实的问答 |
| Reflection (反思) | 早期错误检测 | 增加的计算和延迟 | 高风险、安全关键型任务 |
| Deep research (深度研究) | 管理多阶段、自适应调查 | 高计算成本和极高延迟 | 长篇文献综述 |
二、工具选择 (Tool Selection)
在讨论编排之前,我们先从工具选择开始,因为它是更高级规划的基础。不同的工具选择方法提供独特的优势和考量,以满足不同的需求和环境。我们假设一套工具已经被开发出来(如果需要复习,请回顾第四章)。
表 5-2. 工具选择策略
| 技术 | 优点 | 缺点 |
|---|---|---|
| 标准工具选择 (Standard) | 实施简单 | 在工具数量多时扩展性差 |
| 语义工具选择 (Semantic) | 对大量工具具有很好的扩展性 | 通常实施延迟低 |
| 分层工具选择 (Hierarchical) | 对大量工具具有很好的扩展性 | 较慢,因为需要多次连续的基础模型调用 |
标准工具选择 (Standard Tool Selection)
最简单的方法是标准工具选择。在这种情况下,工具、其定义和描述被提供给基础模型,并要求模型为给定的上下文选择最合适的工具。然后将基础模型的输出与工具集进行比较,并选择最接近的一个。这种方法易于实施,不需要额外的训练、嵌入或工具集层次结构即可使用。主要的缺点是延迟,因为它需要另一次基础模型调用,这可能会给整体响应时间增加数秒。它还可以受益于上下文学习 (in-context learning),即提供少样本示例 (few-shot examples) 来提高针对问题的预测准确性,而无需面对训练或微调模型的挑战。
有效的工具选择通常归结为如何描述每种能力。首先给每个工具一个简洁、描述性的名称(例如,用 calculate_sum 而不是 process_numbers),后面跟一句话总结,突出其独特的目的(例如,“返回两个数字的总和”)。在描述中包含一个调用示例——显示典型的输入和输出——以具体的术语而不是抽象的语言来确立模型的理解。最后,通过指定类型和范围(例如,“x 和 y 必须是 0 到 1,000 之间的整数”)来强制执行输入约束,这减少了模棱两可的匹配,并帮助基础模型排除不相关的工具。通过使用代表性提示进行迭代测试并完善每个描述的清晰度和特异性,你将在不需要任何额外训练或基础设施的情况下看到选择准确性的显著提高。这听起来很简单,但在注册到智能体的工具数量增加时,工具描述中的重叠经常成为问题和工具选择错误的来源。
这里我们定义另一个工具,它能够计算数学表达式和评估公式,这是基础模型往往不擅长的:
from langchain_core.tools import toolimport requests@tooldef query_wolfram_alpha(expression: str) -> str: """ Query Wolfram Alpha to compute expressions or retrieve information. Args: expression (str): The mathematical expression or query to evaluate. Returns: str: The result of the computation or the retrieved information. """ api_url = f'''https://api.wolframalpha.com/v1/result? i={requests.utils.quote(expression)}& appid=YOUR_WOLFRAM_ALPHA_APP_ID''' try: response = requests.get(api_url) if response.status_code == 200: return response.text else: raise ValueError(f"Wolfram Alpha API Error: {response.status_code} - {response.text}") except requests.exceptions.RequestException as e: raise ValueError(f"Failed to query Wolfram Alpha: {e}")@tooldef trigger_zapier_webhook(zap_id: str, payload: dict) -> str: """ Trigger a Zapier webhook to execute a predefined Zap. Args: zap_id (str): The unique identifier for the Zap to be triggered. payload (dict): The data to send to the Zapier webhook. Returns: str: Confirmation message upon successful triggering of the Zap. Raises: ValueError: If the API request fails or returns an error. """ zapier_webhook_url = f"https://hooks.zapier.com/hooks/catch/{zap_id}/" try: response = requests.post(zapier_webhook_url, json=payload) if response.status_code == 200: return f"Zapier webhook '{zap_id}' successfully triggered." else: raise ValueError(f'''Zapier API Error: {response.status_code} - {response.text}''') except requests.exceptions.RequestException as e: raise ValueError(f"Failed to trigger Zapier webhook '{zap_id}': {e}")
这是另一个你可能想要注册到智能体的工具示例,用于在任务完成或需要“人在环路 (human-in-the-loop)”模式下的关注时通知特定频道:
@tooldef send_slack_message(channel: str, message: str) -> str: """ Send a message to a specified Slack channel. Args: channel (str): The Slack channel ID or name where the message will be sent. message (str): The content of the message to send. Returns: str: Confirmation message upon successful sending of the Slack message. Raises: ValueError: If the API request fails or returns an error. """ api_url = "https://slack.com/api/chat.postMessage" headers = { "Authorization": "Bearer YOUR_SLACK_BOT_TOKEN", "Content-Type": "application/json" } payload = { "channel": channel, "text": message } try: response = requests.post(api_url, headers=headers, json=payload) response_data = response.json() if response.status_code == 200 and response_data.get("ok"): return f"Message successfully sent to Slack channel '{channel}'." else: error_msg = response_data.get("error", "Unknown error") raise ValueError(f"Slack API Error: {error_msg}") except requests.exceptions.RequestException as e: raise ValueError(f'''Failed to send message to Slack channel "{channel}": {e}''')
现在我们已经定义了工具,我们将它们绑定到模型客户端,并允许模型挑选调用哪些工具以最好地处理输入:
# Initialize the LLM with GPT-4o and bind the toolsllm = ChatOpenAI(model_name="gpt-4o")llm_with_tools = llm.bind_tools([get_stock_price, send_slack_message, query_wolfram_alpha])messages = [HumanMessage("What is the stock price of Apple?")]ai_msg = llm_with_tools.invoke(messages)messages.append(ai_msg)for tool_call in ai_msg.tool_calls: tool_msg = get_stock_price.invoke(tool_call)final_response = llm_with_tools.invoke(messages)print(final_response.content)
总之,标准工具选择提供了一种快速、直观的方式将工具集成到你的智能体系统中,无需额外的基础设施或训练开销。虽然它对于小型工具集具有良好的扩展性,但随着工具库增长,认真的描述工程对于保持准确性和避免错误选择变得至关重要。通过结合深思熟虑的描述和迭代提示测试,你可以使用这种简单而强大的方法实现稳健的性能。
语义工具选择 (Semantic Tool Selection)
另一种方法,语义工具选择,使用语义表示来索引所有可用工具,并使用语义搜索来检索最相关的工具。这减少了需要从中选择的工具数量,然后依靠基础模型从这个更小的集合中选择正确的工具和参数。在前期,每个工具的定义和描述都使用仅编码器模型(如 OpenAI 的 Ada 模型、Amazon 的 Titan 模型、Cohere 的 Embed 模型、ModernBERT 等)进行嵌入 (embedding),该模型将工具名称和描述表示为数字向量。这个过程如图 5-2 所示,展示了每个工具如何被嵌入到向量表示中,以便基于与任务查询的语义相似性进行高效检索。
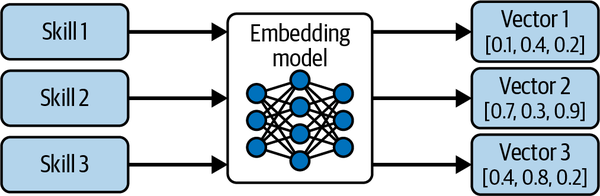
图 5-2. 用于基于检索的选择的语义工具嵌入。 每个工具或技能都使用嵌入模型编码为密集的向量表示。然后存储这些向量以进行高效的语义搜索,使系统能够根据任务查询检索最相关的工具。
然后将这些工具索引在一个轻量级的向量数据库中。在运行时,使用相同的嵌入模型嵌入当前的上下文,在数据库上执行搜索,并选择和检索排名靠前的工具。然后将这些工具传递给基础模型,基础模型随后可以选择调用工具并选择参数。工具被调用,其响应被用于组合给用户的回复。这个过程如图 5-3 所示。
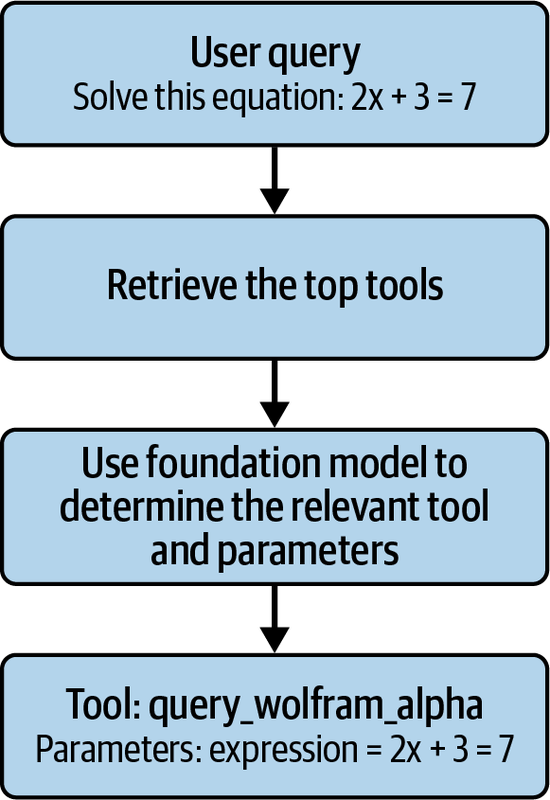
图 5-3. 语义工具检索和调用工作流。 在运行时,用户查询被嵌入并用于从向量数据库中检索最相关的工具。然后,基础模型选择适当的工具并确定其参数,调用该工具,并整合工具的输出以生成最终的用户响应。
这是最常见的模式,推荐用于大多数用例。它通常比标准工具选择更快,性能好,并且具有相当的可扩展性。首先,通过嵌入工具描述来设置工具数据库:
import osimport requestsimport loggingfrom langchain_core.tools import toolfrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langchain_core.messages import HumanMessage, AIMessage, ToolMessagefrom langchain.vectorstores import FAISSimport faissimport numpy as np# Initialize OpenAI embeddingsembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)# Tool descriptionstool_descriptions = { "query_wolfram_alpha": '''Use Wolfram Alpha to compute mathematical expressions or retrieve information.''', "trigger_zapier_webhook": '''Trigger a Zapier webhook to execute predefined automated workflows.''', "send_slack_message": '''Send messages to specific Slack channels to communicate with team members.'''}# Create embeddings for each tool descriptiontool_embeddings = []tool_names = []for tool_name, description in tool_descriptions.items(): embedding = embeddings.embed_text(description) tool_embeddings.append(embedding) tool_names.append(tool_name)# Initialize FAISS vector storedimension = len(tool_embeddings[0]) index = faiss.IndexFlatL2(dimension)# Normalize embeddings for cosine similarityfaiss.normalize_L2(np.array(tool_embeddings).astype('float32'))# Convert list to FAISS-compatible formattool_embeddings_np = np.array(tool_embeddings).astype('float32')index.add(tool_embeddings_np)# Map index to tool functionsindex_to_tool = { 0: query_wolfram_alpha, 1: trigger_zapier_webhook, 2: send_slack_message}
你的工具目录的嵌入只需计算一次,现在它们已准备好被快速检索。要选择你的工具,使用相同的嵌入模型嵌入你的查询,执行快速数据库查找,选择参数,然后调用我们的工具:
def select_tool(query: str, top_k: int = 1) -> list: """ Select the most relevant tool(s) based on the user's query using vector-based retrieval. """ query_embedding = embeddings.embed_text(query).astype('float32') faiss.normalize_L2(query_embedding.reshape(1, -1)) D, I = index.search(query_embedding.reshape(1, -1), top_k) selected_tools = [index_to_tool[idx] for idx in I[0] if idx in index_to_tool] return selected_toolsdef determine_parameters(query: str, tool_name: str) -> dict: """ Use the LLM to analyze the query and determine the parameters for the tool to be invoked. """ messages = [ HumanMessage(content=f'''Based on the user's query: '{query}', what parameters should be used for the tool '{tool_name}'?''') ] # Call the LLM to extract parameters response = llm(messages) # Example logic to parse response from LLM (simplified) parameters = {} # ... (parameter parsing logic) ... return parameters# Example user queryuser_query = "Solve this equation: 2x + 3 = 7"# Select the top toolselected_tools = select_tool(user_query, top_k=1)tool_name = selected_tools[0] if selected_tools else Noneif tool_name: # Use LLM to determine the parameters args = determine_parameters(user_query, tool_name) # Invoke the selected tool try: tool_result = globals()[tool_name].invoke(args) print(f"Tool '{tool_name}' Result: {tool_result}") except ValueError as e: print(f"Error invoking tool '{tool_name}': {e}")else: print("No tool was selected.")
分层工具选择 (Hierarchical Tool Selection)
然而,如果你的场景涉及大量工具,可能需要考虑分层工具选择。如果其中许多工具在语义上相似,并且你希望以更高的延迟和复杂性为代价来提高工具选择的准确性,这一策略尤为适用。在这种模式下,你将工具组织成组,并为每个组提供描述。你的工具选择(生成式或语义式)首先选择一个组,然后仅在该组的工具中执行二次搜索。图 5-4 将此两阶段过程可视化。
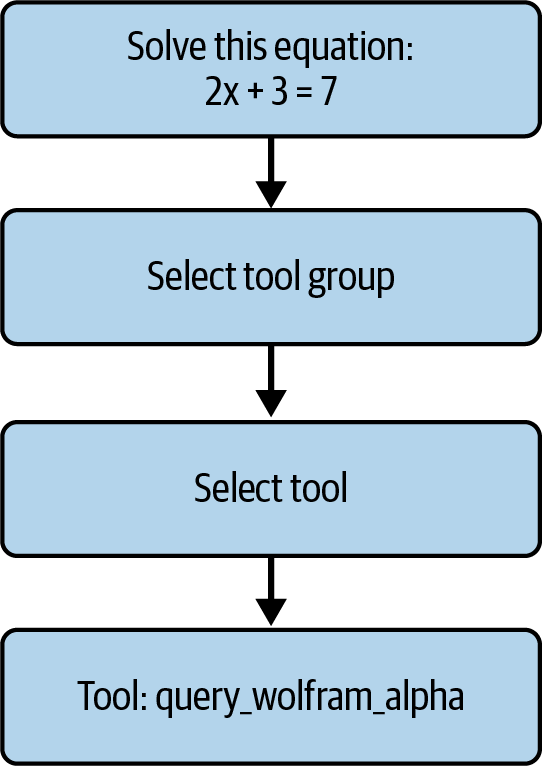
图 5-4. 分层工具选择工作流。 智能体首先为查询选择最相关的工具组,然后缩小搜索范围以在该组内选择单个工具——在此示例中,通过工具组路由数学问题并最终调用 query_wolfram_alpha。
虽然这种方法较慢且并行化成本较高,但它将工具选择任务的复杂性降低为两个较小的块,通常会带来更高的整体工具选择准确性。制作和维护这些工具组需要时间和精力,因此除非你有大量工具,否则不建议这样做。
import osimport requestsimport loggingimport numpy as npfrom langchain_core.tools import toolfrom langchain_openai import ChatOpenAIfrom langchain_core.messages import HumanMessage, AIMessage, ToolMessage# Initialize the LLMllm = ChatOpenAI(model_name="gpt-4", temperature=0)# Define tool groups with descriptionstool_groups = { "Computation": { "description": '''Tools related to mathematical computations and data analysis.''', "tools": [] }, "Automation": { "description": '''Tools that automate workflows and integrate different services.''', "tools": [] }, "Communication": { "description": "Tools that facilitate communication and messaging.", "tools": [] }}# Define Tools@tooldef query_wolfram_alpha(expression: str) -> str: api_url = f'''https://api.wolframalpha.com/v1/result?i= {requests.utils.quote(expression)}&appid={WOLFRAM_ALPHA_APP_ID}''' try: response = requests.get(api_url) if response.status_code == 200: return response.text else: raise ValueError(f'''Wolfram Alpha API Error: {response.status_code} - {response.text}''') except requests.exceptions.RequestException as e: raise ValueError(f"Failed to query Wolfram Alpha: {e}")@tooldef trigger_zapier_webhook(zap_id: str, payload: dict) -> str: zapier_webhook_url = f"https://hooks.zapier.com/hooks/catch/{zap_id}/" try: response = requests.post(zapier_webhook_url, json=payload) if response.status_code == 200: return f"Zapier webhook '{zap_id}' successfully triggered." else: raise ValueError(f'''Zapier API Error: {response.status_code} - {response.text}''') except requests.exceptions.RequestException as e: raise ValueError(f"Failed to trigger Zapier webhook '{zap_id}': {e}")@tooldef send_slack_message(channel: str, message: str) -> str: api_url = "https://slack.com/api/chat.postMessage" headers = { "Authorization": f"Bearer {SLACK_BOT_TOKEN}", "Content-Type": "application/json" } payload = { "channel": channel, "text": message } try: response = requests.post(api_url, headers=headers, json=payload) response_data = response.json() if response.status_code == 200 and response_data.get("ok"): return f"Message successfully sent to Slack channel '{channel}'." else: error_msg = response_data.get("error", "Unknown error") raise ValueError(f"Slack API Error: {error_msg}") except requests.exceptions.RequestException as e: raise ValueError(f'''Failed to send message to Slack channel '{channel}': {e}''')# Assign tools to their respective groupstool_groups["Computation"]["tools"].append(query_wolfram_alpha)tool_groups["Automation"]["tools"].append(trigger_zapier_webhook)tool_groups["Communication"]["tools"].append(send_slack_message)# -------------------------------# LLM-Based Hierarchical Tool Selection# -------------------------------def select_group_llm(query: str) -> str: """ Use the LLM to determine the most appropriate tool group based on the user's query. Args: query (str): The user's input query. Returns: str: The name of the selected group. """ prompt = f'''Select the most appropriate tool group for the following query: '{query}'.\nOptions are: Computation, Automation, Communication.''' response = llm([HumanMessage(content=prompt)]) return response.content.strip()def select_tool_llm(query: str, group_name: str) -> str: """ Use the LLM to determine the most appropriate tool within a group based on the user's query. Args: query (str): The user's input query. group_name (str): The name of the selected tool group. Returns: str: The name of the selected tool function. """ prompt = f'''Based on the query: '{query}', select the most appropriate tool from the group '{group_name}'.''' response = llm([HumanMessage(content=prompt)]) return response.content.strip()# Example user queryuser_query = "Solve this equation: 2x + 3 = 7"# Step 1: Select the most relevant tool group using LLMselected_group_name = select_group_llm(user_query)if not selected_group_name: print("No relevant tool group found for your query.")else: logging.info(f"Selected Group: {selected_group_name}") print(f"Selected Tool Group: {selected_group_name}") # Step 2: Select the most relevant tool within the group using LLM selected_tool_name = select_tool_llm(user_query, selected_group_name) selected_tool = globals().get(selected_tool_name, None) if not selected_tool: print("No relevant tool found within the selected group.") else: logging.info(f"Selected Tool: {selected_tool.__name__}") print(f"Selected Tool: {selected_tool.__name__}") # Prepare arguments based on the tool args = {} if selected_tool == query_wolfram_alpha: # Assume the entire query is the expression args["expression"] = user_query elif selected_tool == trigger_zapier_webhook: # Use placeholders for demo args["zap_id"] = "123456" args["payload"] = {"message": user_query} elif selected_tool == send_slack_message: # Use placeholders for demo args["channel"] = "#general" args["message"] = user_query else: print("Selected tool is not recognized.") # Invoke the selected tool try: tool_result = selected_tool.invoke(args) print(f"Tool '{selected_tool.__name__}' Result: {tool_result}") except ValueError as e: print(f"Error: {e}")
三、工具执行 (Tool Execution)
参数化 (Parametrization) 是在语言模型中定义和设置将指导工具执行的参数的过程。这个过程至关重要,因为它决定了模型如何解释任务并调整其响应以满足特定要求。参数由工具定义来定义(详见第四章)。智能体的当前状态(包括目前的进度)作为附加上下文包含在提示窗口中,并指示基础模型用适当的数据类型填充参数以匹配函数调用的预期输入。诸如当前时间或用户位置之类的附加上下文可以注入到上下文窗口中,以便为需要此类信息的函数提供额外指导。建议使用基本的解析器来验证输入是否符合数据类型的基本标准,并指示基础模型在未通过此检查时更正模式。
一旦参数被设置,工具执行阶段就开始了。其中一些工具可以很容易地在本地执行,而其他工具将通过 API 远程执行。在执行期间,模型可能会与各种 API、数据库或其他工具交互以收集信息、执行计算或执行完成任务所需的动作。外部数据源和工具的集成可以显着增强智能体输出的实用性和准确性。超时和重试逻辑将需要根据用例的延迟和性能要求进行调整。
四、工具拓扑结构 (Tool Topologies)
今天,大多数聊天机器人系统依赖于没有规划的单一工具执行。这很有道理:它更容易实施,且延迟更低。如果你的团队正在开发第一个基于智能体的系统,或者这足以满足你的场景需求,那么你可以在下一节“单一工具执行”之后停下来。然而,对于许多情况,我们希望我们的智能体能够执行需要多个工具的复杂任务。通过为智能体提供足够范围的工具,你可以让智能体灵活地安排这些工具,并按正确的顺序应用它们,以解决各种各样的问题。在传统的软件工程中,设计者必须实现步骤的精确控制流和顺序。现在,我们可以实现工具并定义智能体可以在其中操作的工具拓扑结构,然后允许根据手头的上下文和任务动态设计确切的组合。本节考虑了这一系列的工具拓扑结构并讨论了它们的权衡。
单一工具执行 (Single Tool Execution)
我们从只需要恰好一个工具的任务开始。在这种情况下,规划包括选择最适合解决任务的一个工具。一旦选择了工具,必须根据工具定义对其进行正确的参数化。然后执行该工具,其输出被用作组成用户最终响应时的输入,如图 5-5 所示。虽然这是一个规划的最小定义,但它是我们构建更复杂模式的基础。
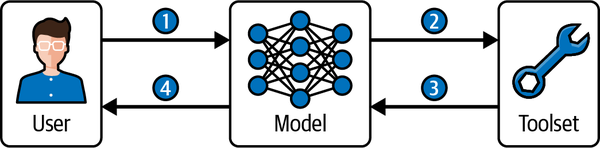
图 5-5. 单一工具执行工作流。 用户查询传递给模型(步骤 1),模型从工具集中选择适当的工具(步骤 2),接收工具输出(步骤 3),并为用户组成最终响应(步骤 4)。
为了使这个例子更具体,图 5-6 展示了这个相同的单一工具执行工作流,其中智能体检索并返回纽约市的当前天气。

图 5-6. 天气检索的单一工具执行示例。 用户询问纽约市的天气,模型选择并参数化天气工具,检索温度和天气状况作为 JSON 参数,并使用此信息为用户组装自然语言响应。
虽然这种单一工具执行模式很简单,但它构成了高级智能体系统中更复杂的多步规划和工具编排策略的基础。在下一节中,我们将看看如何在不牺牲延迟的情况下执行更多工具。
并行工具执行 (Parallel Tool Execution)
随着工具并行性的引入,复杂性首先增加。在某些情况下,对输入采取多个行动可能是值得的。例如,设想你需要查找患者的记录。如果工具集中包括多个访问多个数据源的工具,那么将需要执行多个操作以从每个源检索数据。这增加了问题的复杂性,因为不清楚需要执行多少个工具。一种常见的方法是使用语义工具选择检索可能被执行的最大数量的工具——比如五个。接下来,使用这五个工具中的每一个对基础模型进行第二次调用,并要求它选择问题所需的五个或更少的工具,过滤到任务所需的工具。类似地,可以通过已选工具的额外上下文重复调用基础模型,直到它选择不再添加工具。一旦选定,这些工具将被独立参数化并执行。所有工具完成后,它们的结果将传递给基础模型以编写用户的最终响应。图 5-7 说明了这种模式。
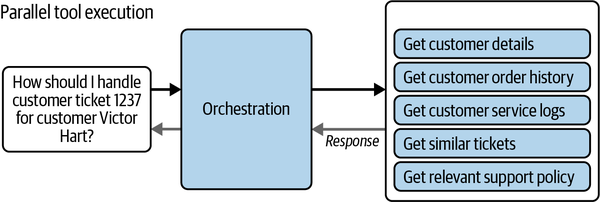
图 5-7. 并行工具执行模式。 在此示例中,用户询问如何处理客户工单。编排过程选择多个工具并行运行——例如检索客户详细信息、订单历史、服务日志、类似工单和相关支持策略——然后在整合它们的输出以生成最终响应之前。
这种并行工具执行模式使智能体能够在单一步骤中高效地从多个来源收集全面信息。通过在组成响应之前整合这些结果,智能体可以提供更丰富、更明智的输出,同时最大限度地减少整体延迟。
链 (Chains)
进一步的复杂性将我们带向了链。链是指一个接一个执行的动作序列,每个动作都依赖于前一个动作的成功完成。规划链涉及确定应执行动作的顺序以实现特定目标,同时确保每个动作不间断地导致下一个动作。链在涉及逐步过程或线性工作流的任务中很常见。
幸运的是,LangChain 提供了一种声明性语法,即 LangChain 表达式语言 (LCEL),通过组合现有的 Runnables 而不是手动连接 Chain 对象来构建链。在底层,LCEL 将每个链视为实现相同接口的 Runnable,因此可以像任何其他 Runnable 一样对任何 LCEL 链进行 invoke()、batch() 或 stream() 操作:
from langchain_core.runnables import RunnableLambdafrom langchain.chat_models import ChatOpenAIfrom langchain_core.prompts import PromptTemplate# Wrap a function or model call as a Runnablellm = RunnableLambda.from_callable(ChatOpenAI(model_name="gpt-4", temperature=0).generate)prompt = RunnableLambda.from_callable(lambda text: PromptTemplate.from_template(text).format_prompt({"input": text}).to_messages())# LCEL chain using pipes:chain = prompt | llm# Invoke the chainresult = chain.invoke("What is the capital of France?")
通过切换到 LCEL,可以减少脚手架代码,获得高级执行功能,并保持链的简洁和可维护性。图 5-8 说明了作为许多 LCEL 工作流基础的通用智能体链模式。

图 5-8. 智能体链执行模式。 用户提示传递给模型,模型进行推理并调用工具与环境交互。产生的观察结果被循环回模型以进行进一步推理,直到任务完成。
链的规划需要仔细考虑动作之间的依赖关系,旨在编排一个连续的事件流以实现预期结果。强烈建议为工具链设置最大长度,因为错误可能会沿着链的长度堆积。只要预期任务不会分散到多个分支子任务,链就在为多个具有依赖关系的工具添加规划和保持相对较低的复杂性之间提供了极好的权衡。
图 (Graphs)
对于具有多个决策点的支持场景,图拓扑结构比链或树更具表现力地模拟复杂的、非线性的流程。与线性链或严格分支的树不同,图结构允许你定义条件边 (conditional edges) 和合并边 (consolidation edges),以便并行路径可以合并回共享节点。
图中的每个节点代表一个离散的工具调用(或逻辑步骤),而边——包括 add_conditional_edges——声明了智能体可以在步骤之间转换的确切条件。通过将多个分支的输出合并到单个下游节点(例如 summarize_response),你可以将来自不同处理程序的发现拼接成统一的客户回复。
然而,全图执行通常比链产生更多的基础模型调用——增加了延迟和成本——因此限制深度和分支因子至关重要。此外,循环、不可达节点或冲突的状态合并引入了必须通过严格验证和测试来管理的新类别的错误。以下是如何在 LangGraph 中实现图的示例:
from langgraph.graph import StateGraph, START, ENDfrom langchain.chat_models import ChatOpenAI# Initialize LLMllm = ChatOpenAI(model_name="gpt-4", temperature=0)# 1. Node definitionsdef categorize_issue(state: dict) -> dict: prompt = ( f"Classify this support request as 'billing' or 'technical'.\n\n" f"Message: {state['user_message']}" ) generations = llm.generate([{"role":"user","content":prompt}]).generations kind = generations[0][0].text.strip().lower() return {**state, "issue_type": kind}def handle_invoice(state: dict) -> dict: # Fetch invoice details... return {**state, "step_result": f"Invoice details for {state['user_id']}"}def handle_refund(state: dict) -> dict: # Initiate refund workflow... return {**state, "step_result": "Refund process initiated"}def handle_login(state: dict) -> dict: # Troubleshoot login... return {**state, "step_result": "Password reset link sent"}def handle_performance(state: dict) -> dict: # Check performance metrics... return {**state, "step_result": "Performance metrics analyzed"}def summarize_response(state: dict) -> dict: # Consolidate previous step_result into a user-facing message details = state.get("step_result", "") summary = llm.generate([{"role":"user","content": f"Write a concise customer reply based on: {details}" }]).generations[0][0].text.strip() return {**state, "response": summary}
接下来的部分将每个节点中的逻辑流连接成实际的执行图。通过创建一个新的 StateGraph,我们建立了起点 START → categorize_issue,这确保每个请求首先通过分类步骤。然后,使用 add_conditional_edges,编码核心业务规则:分类后,计费问题路由到发票/退款处理程序,技术问题路由到登录/性能处理程序。这种方法保持决策逻辑显式,强制执行正确的工具调用顺序,并防止无效转换。
# 2. Build the graphgraph = StateGraph()# Start → categorize_issuegraph.add_edge(START, categorize_issue)# categorize_issue → billing or technicaldef top_router(state): return "billing" if state["issue_type"] == "billing" else "technical"graph.add_conditional_edges( categorize_issue, top_router, mapping={"billing": handle_invoice, "technical": handle_login})# Billing sub-branches: invoice vs. refunddef billing_router(state): msg = state["user_message"].lower() return "invoice" if "invoice" in msg else "refund"graph.add_conditional_edges( handle_invoice, billing_router, mapping={"invoice": handle_invoice, "refund": handle_refund})# Technical sub-branches: login vs. performancedef tech_router(state): msg = state["user_message"].lower() return "login" if "login" in msg else "performance"graph.add_conditional_edges( handle_login, tech_router, mapping={"login": handle_login, "performance": handle_performance})
最后的这步连线添加了合并边 (consolidation edges),这样无论采取了哪条子路径——无论用户是需要发票查询、退款、登录故障排查,还是性能检查——它们的结果都会汇入到唯一的 summarize_response 节点。通过将每一个处理程序节点(handle_refund、handle_performance、handle_invoice 和 handle_login)连接到 summarize_response,我们确保了所有不同的输出结果都能被统一成一条连贯的客户回复。最后,将 summarize_response 连接到 END 可以整洁地终止工作流,保证在图运行结束前,每一条执行路径最终都能汇聚成一个完善的响应:
# Consolidation: both refund and performance (and invoice/login) lead heregraph.add_edge(handle_refund, summarize_response)graph.add_edge(handle_performance, summarize_response)# Also cover paths where invoice or login directly go to summarygraph.add_edge(handle_invoice, summarize_response)graph.add_edge(handle_login, summarize_response)# Final: summary → ENDgraph.add_edge(summarize_response, END)# 3. Execute the graphinitial_state = { "user_message": "Hi, I need help with my invoice and possibly a refund.", "user_id": "U1234"}result = graph.run(initial_state, max_depth=5)print(result["response"])
图 (Graphs) 为建模复杂的、非线性工作流提供了终极的灵活性——使你能够将多个工具的执行进行分支、合并和整合到一个统一的过程中。然而,这种表现力伴随着额外的开销:更多的 LLM 调用、更深层的路由逻辑,以及循环或不可达路径的潜在可能性。为了有效地利用图,始终将你的设计锚定在特定用例的需求上,并抵制过度复杂的诱惑。
如果你的任务是严格线性的(例如,提示 → 模型 → 解析器),请从链 (Chain) 开始。链易于推理和调试。只有当你必须既要分支又要随后整合多个信息流时(例如,为单个摘要提供输入的并行分析步骤),才采用图。
在实践中,先在纸上画出你的拓扑结构:用工具或逻辑步骤标记每个节点,画出允许转换的箭头,并突出显示分支重新汇合的地方。然后增量实现——限制你的深度和分支因子,为每个路由器编写单元测试,并利用 LangGraph 内置的追踪功能来验证每条路径都通向一个终点节点。
最重要的是,保持尽可能简单。每一个额外的节点或边都会倍增潜在的执行路径和错误模式。如果更简单的链或树能满足你的需求,请将图模式保留给真正复杂的场景。通过从简单开始并仅在需求要求时进行迭代,你将构建出稳健、可维护且能自信扩展的编排系统。
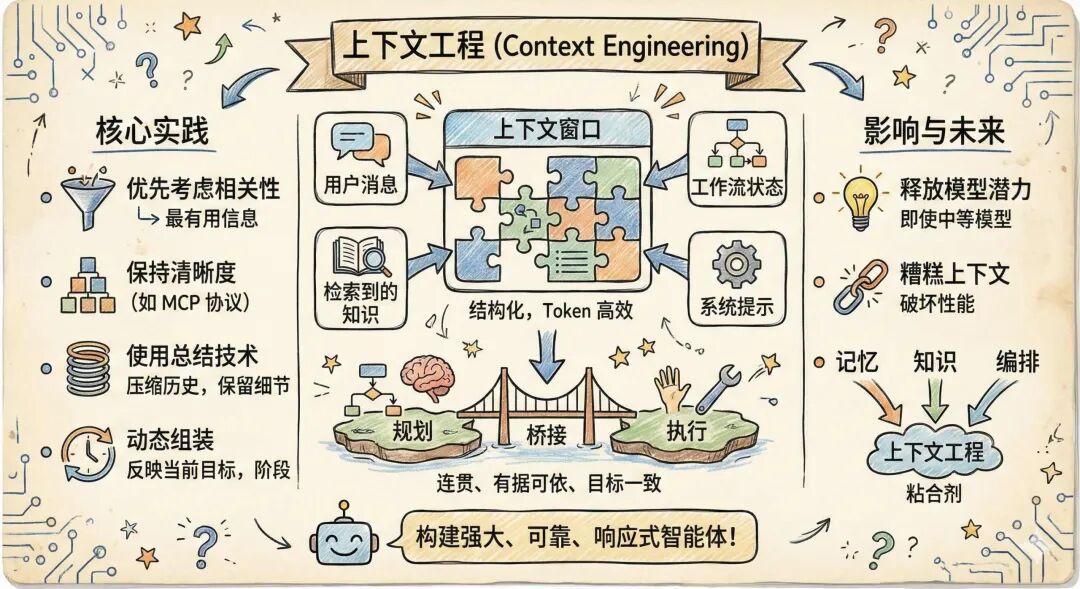
五、上下文工程 (Context Engineering)
上下文工程是编排的核心组件。它确保智能体计划中的每一步都拥有有效执行所需的正确信息和指令。虽然提示工程专注于编写有效的指令,但上下文工程涉及将所有输入——用户消息、检索到的知识、工作流状态和系统提示——动态组装成结构化的、Token 高效的上下文窗口,以最大化任务性能。例如,规划-执行智能体依赖于将清晰的计划输出作为上下文传递给执行者步骤,而 ReAct 智能体需要将相关的工具结果清晰地嵌入提示中,通知其下一个推理周期。因此,上下文工程桥接了规划和执行,使智能体工作流保持连贯、有据可依并与用户目标一致。
本质上,上下文工程涉及决定包含哪些信息,如何构建这些信息以获得最大的清晰度和相关性,以及如何在 Token 限制内高效地容纳这些信息。这包括当前的用户输入、从记忆或外部知识库中检索到的相关片段、先前对话的摘要、定义智能体角色的系统指令,以及手头任务所需的任何工作流状态。在简单的系统中,上下文可能仅由系统提示和最新的用户查询组成。但是,随着智能体处理更复杂的任务——如编排多步工作流或根据过去的交互进行个性化推荐——动态上下文构建对于保持连贯性、准确性和实用性变得至关重要。
例如,处理电子商务支持的智能体可能会通过结合定义其允许操作的系统提示、用户的当前消息、检索到的订单记录摘要以及任何适用的政策摘要来构建其上下文。在更高级的系统中,上下文可能还包括先前相关对话的摘要或工作流中较早的工具调用结果。每一个额外的元素都可以提高任务性能,但前提是经过深思熟虑后包含的;不相关或结构不良的上下文可能会分散模型的注意力或在没有益处的情况下超出 Token 预算。
有效的上下文工程需要几个核心实践。首先,优先考虑相关性,仅从记忆或知识库中检索最有用的信息,而不是不加选择地附加大量文本块。其次,通过结构化格式或模式(如模型上下文协议 MCP)保持清晰度,这些格式或模式以可预测、可解释的方式将状态和检索到的知识传递给模型。第三,使用总结技术将较长的历史压缩成简洁的表示,在不浪费 Token 的情况下保留关键细节。最后,确保在每个推理步骤动态组装上下文,以反映智能体当前的目标、工作流阶段和用户输入。
上下文工程位于记忆、知识和编排的交汇处。虽然编排决定了工作流中要采取哪些步骤,但上下文工程确保每一步都有正确的信息来有效执行。随着基础模型的不断改进,智能体系统设计的前沿正在从模型架构转移到我们提供的上下文质量上。本质上,精心设计的上下文可以释放即便是中等模型的全部潜力,而糟糕的上下文可能会破坏最先进系统的性能。
通过掌握上下文工程,开发人员可以创建不仅在技术上强大,而且可靠、有据可依并能响应用户和环境需求的智能体。在未来几年,随着记忆系统、检索架构和编排框架的发展,上下文工程将仍然是将这些组件结合成无缝、有效体验的粘合剂。
六、结论 (Conclusion)
智能体的成功在很大程度上依赖于编排方法,因此对于有兴趣构建智能体系统的组织来说,投入时间和精力为用例设计适当的规划策略非常重要。以下是设计规划系统的一些最佳实践:
- 仔细考虑系统的延迟和准确性要求,因为这两个因素之间存在明显的权衡。
- 确定你的场景用例所需的典型动作数量。这个数字越大,你可能需要的规划方法就越复杂。
- 评估计划需要根据先前动作的结果进行多少更改。如果需要大量的适配,请考虑允许增量计划调整的技术。
- 设计一组具有代表性的测试用例,以评估不同的规划方法并确定最适合用例的方法。
- 选择能满足用例要求的最简单的规划方法。
有了适合场景的编排方法,我们现在将进入工作流的下一部分:记忆 (Memory)。从设计良好的场景和较简单的编排方法开始,然后根据用例需要逐渐提升复杂性规模是值得的。在下一章中,我们将探索记忆如何进一步增强智能体的能力——使它们能够回忆知识、跨交互保持上下文,并以更高的智能和个性化执行任务。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)