深度学习项目训练环境企业实操:制造业缺陷检测项目从数据准备到上线部署
本文介绍了如何在星图GPU平台上自动化部署深度学习项目训练环境镜像,并以制造业缺陷检测为例,详细展示了从数据准备到模型部署的全流程。该预配置环境集成了PyTorch等核心框架,开箱即用,能有效解决环境配置难题,帮助企业快速构建并部署用于产品表面缺陷(如划痕、凹坑)自动识别的AI模型。
深度学习项目训练环境企业实操:制造业缺陷检测项目从数据准备到上线部署
你是不是也遇到过这样的场景?公司接了一个制造业的缺陷检测项目,客户要求用深度学习来做。你信心满满地打开电脑,准备大干一场,结果第一步“搭建训练环境”就卡住了。
“CUDA版本不匹配”、“torch安装失败”、“依赖库冲突”……这些问题就像拦路虎,让你还没开始写代码,就先花了两三天在环境配置上。更头疼的是,好不容易在自己电脑上跑通了,部署到服务器上又是一堆问题,同事的电脑环境又不一样,项目协作简直是一场灾难。
如果你正在为深度学习项目的环境问题头疼,那么今天这篇文章就是为你准备的。我将带你体验一个“开箱即用”的深度学习训练环境镜像,并以一个真实的制造业表面缺陷检测项目为例,手把手带你走完从数据准备、模型训练、验证优化到最终部署上线的全流程。你会发现,原来深度学习项目落地可以如此顺畅。
1. 为什么你需要一个标准化的训练环境?
在开始实操之前,我们先聊聊为什么环境问题这么让人头疼。
想象一下,你是一个工厂的质量检测工程师。你的任务是开发一个系统,自动检测生产线上的产品表面是否有划痕、凹坑、污渍等缺陷。这个项目有几个特点:
- 数据敏感:工厂的生产数据通常涉密,不能随意上传到公有云
- 环境复杂:可能需要在内网服务器、工控机等多种设备上部署
- 协作需求:算法工程师、软件工程师、测试工程师需要共用同一套环境
- 可复现性:三个月后客户要求优化模型,你必须能复现当时的训练环境
传统的手动配置环境方式,几乎无法满足这些要求。每个人电脑上的Python版本、CUDA版本、库版本稍有不同,就可能导致程序运行结果不一致,这就是所谓的“在我的电脑上能跑”问题。
而今天我们要使用的这个深度学习训练环境镜像,就是为了解决这些问题而生的。它基于我的深度学习项目改进与实战专栏预配置,包含了从数据预处理到模型部署所需的所有核心依赖,真正做到了“开箱即用”。
2. 环境一览:你的深度学习“工具箱”里有什么?
这个镜像环境就像是一个精心准备的工具箱,里面已经装好了所有你可能用到的工具。让我们看看里面都有什么:
- 核心框架:
pytorch == 1.13.0(工业界最稳定的版本之一) - CUDA版本:
11.6(兼容大多数显卡) - Python版本:
3.10.0(平衡了新特性和稳定性) - 主要依赖:
torchvision==0.14.0(图像处理)torchaudio==0.13.0(音频处理,虽然我们这次用不到)cudatoolkit=11.6(GPU加速)numpy(数值计算)opencv-python(图像处理)pandas(数据处理)matplotlib、seaborn(可视化)tqdm(进度条)
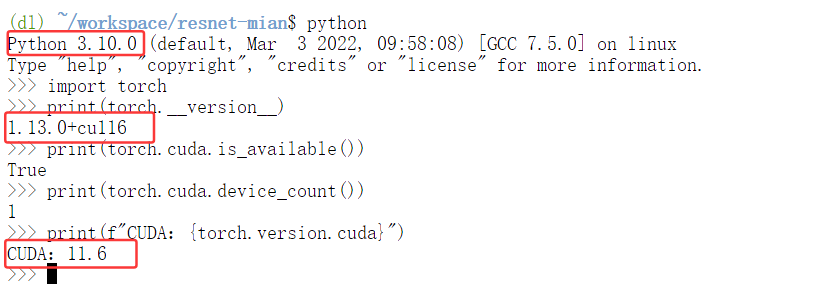
这意味着什么?意味着你拿到这个镜像后,不需要再花时间一个个安装这些库,不需要担心版本冲突,直接就可以开始你的项目。
3. 实战开始:缺陷检测项目全流程演练
现在,让我们进入正题。假设我们接到一个任务:为一家电子厂开发PCB板(电路板)缺陷检测系统。PCB板在生产过程中可能会出现短路、断路、焊点不良等缺陷,我们需要用深度学习来自动识别这些缺陷。
3.1 第一步:启动环境与准备工作
当你启动镜像后,会看到这样的界面:
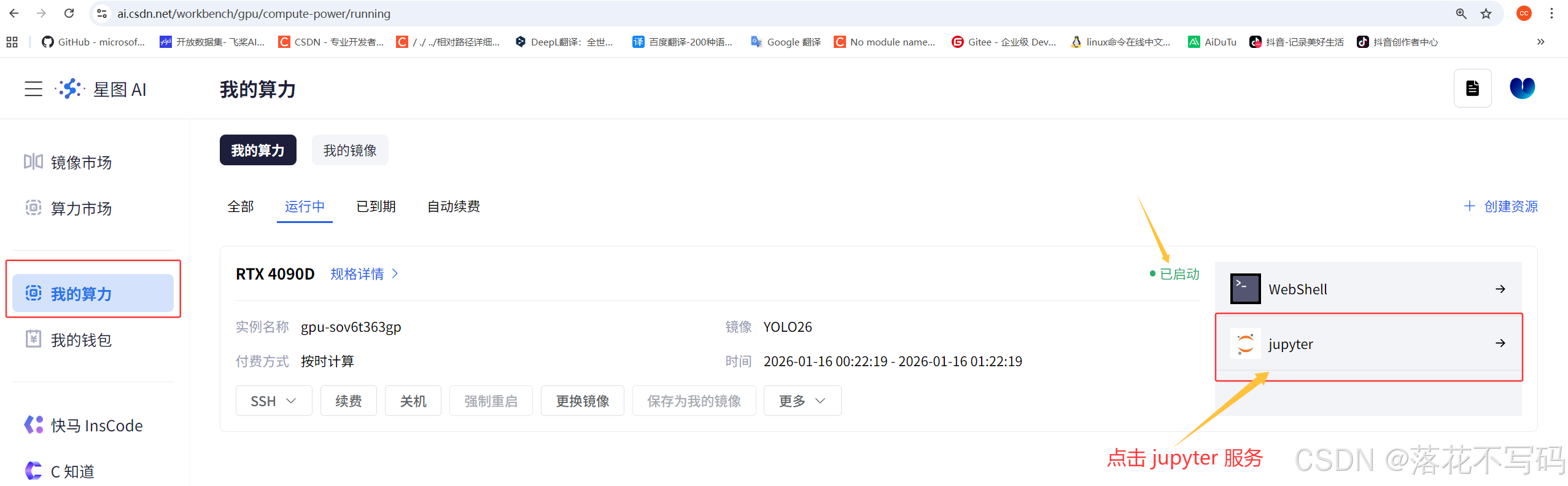
启动完成后,界面是这样的:
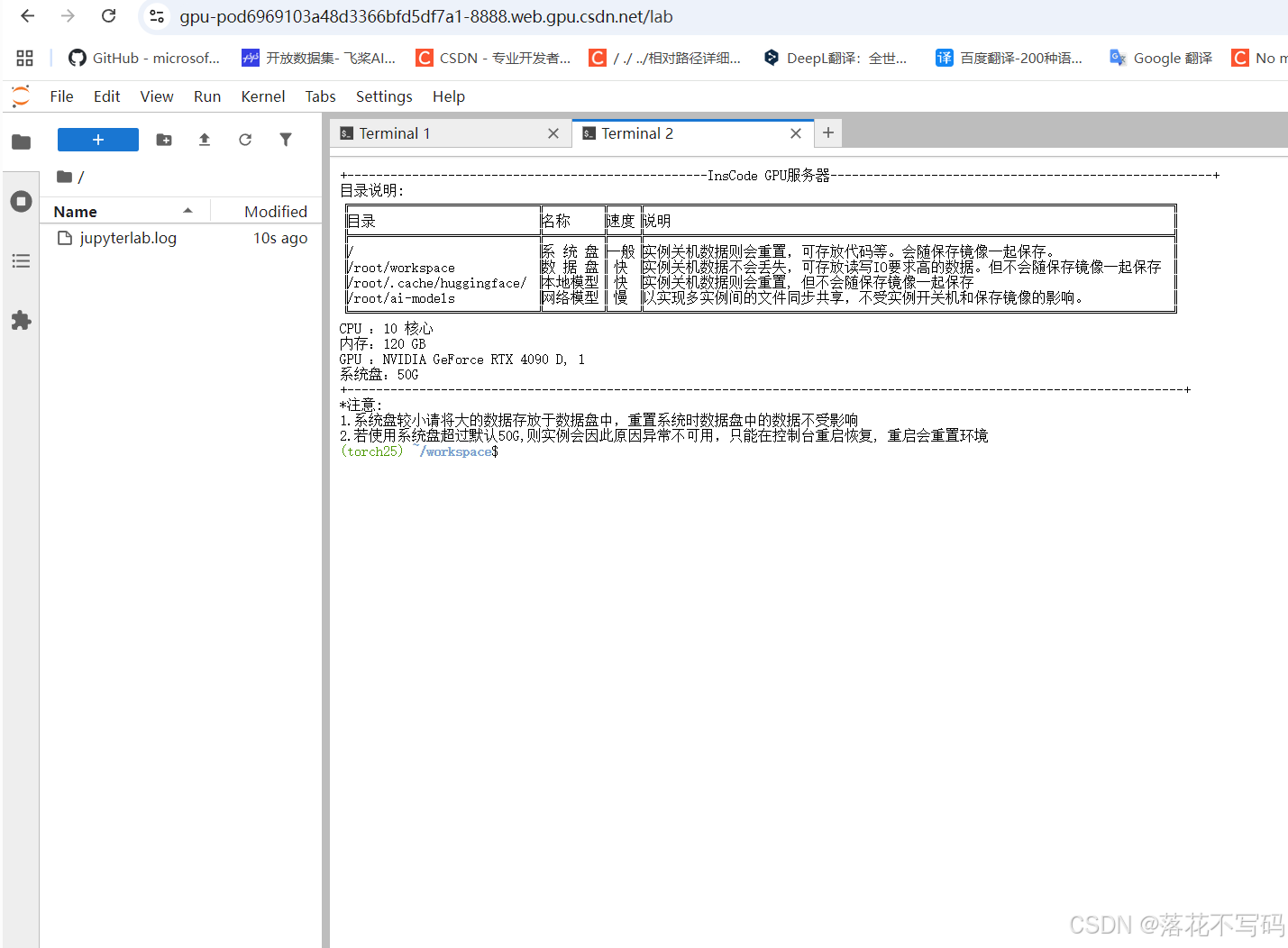
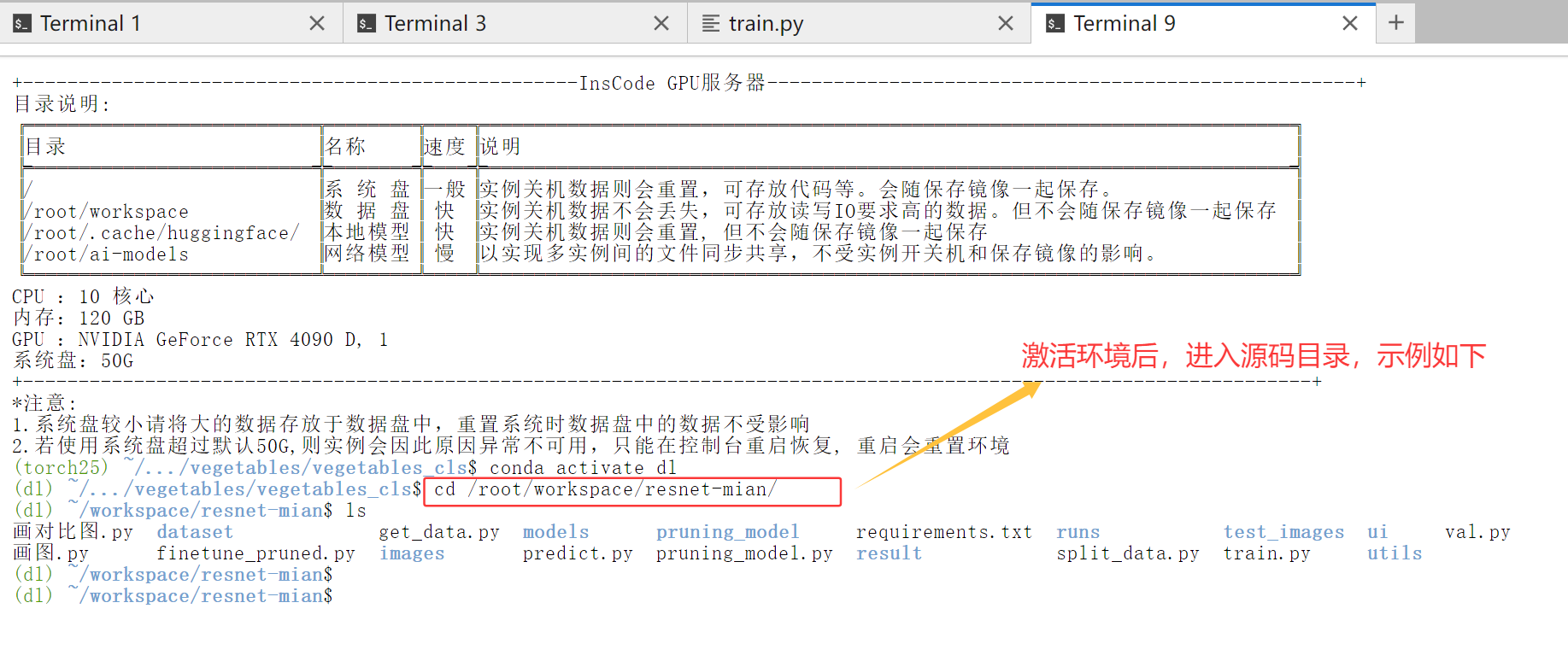
激活环境与切换工作目录
在使用前,我们需要先激活配置好的Conda环境。我配置的环境名称叫dl,激活命令很简单:
conda activate dl
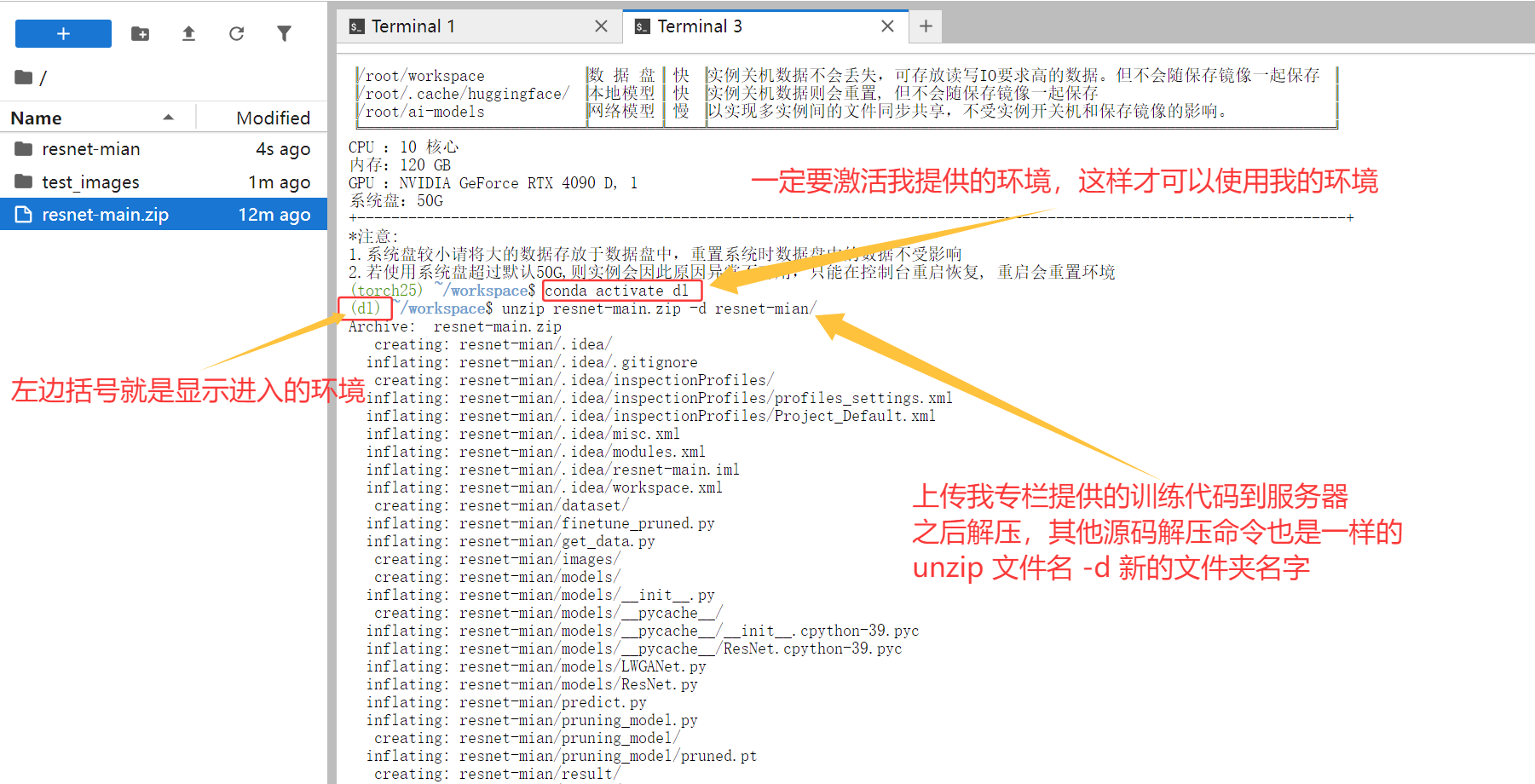
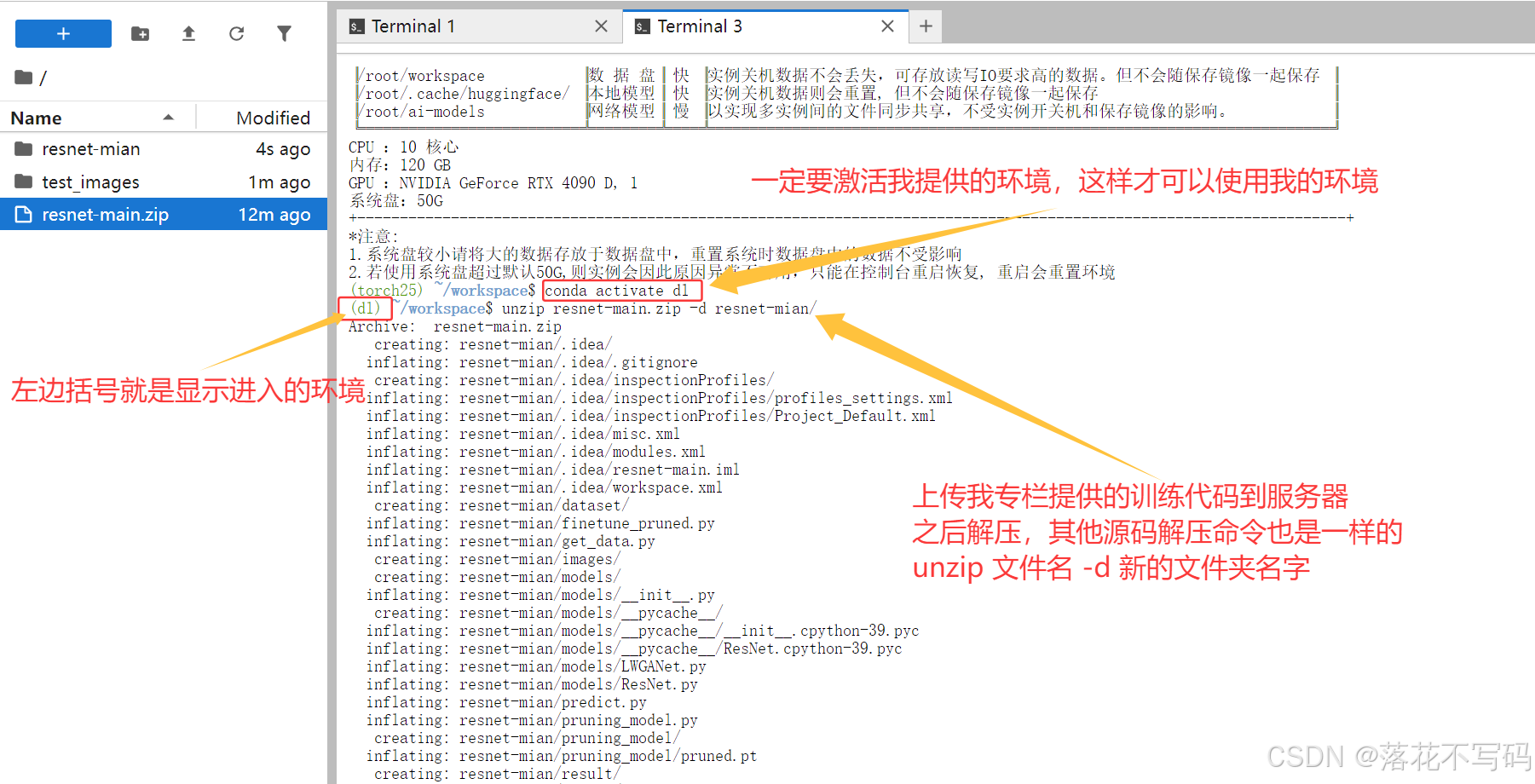
激活环境后,我们需要上传代码和数据。这里有个小技巧:为了便于修改代码,建议将代码和数据都放在数据盘。你可以使用Xftp等工具上传文件。
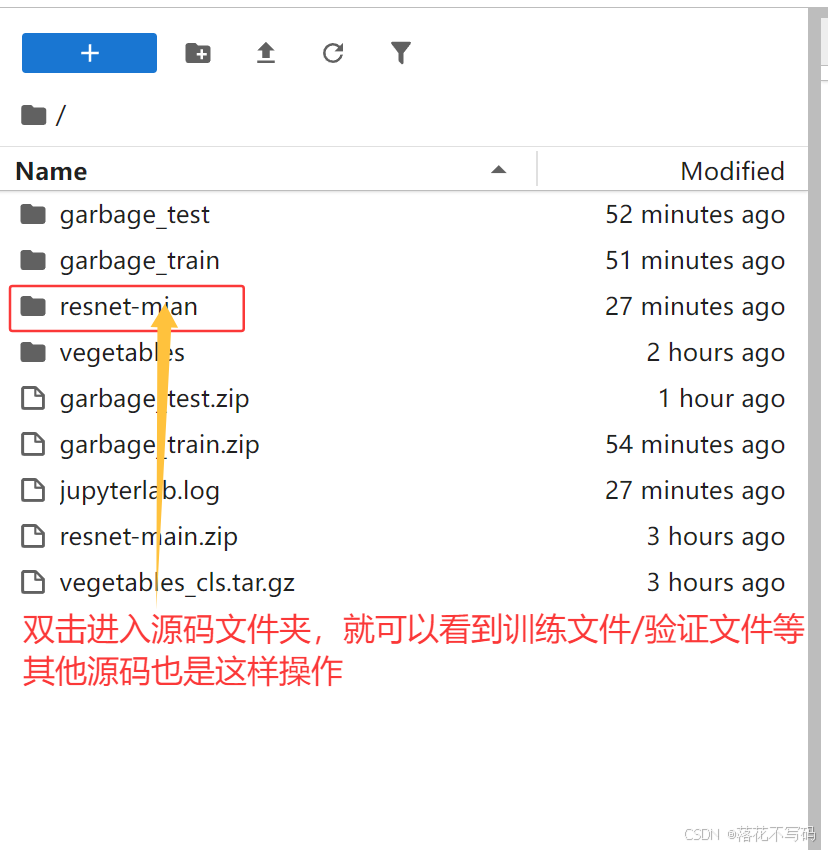
假设我从专栏中下载了PCB缺陷检测的训练代码,上传后进入代码目录:
cd /root/workspace/pcb_defect_detection
3.2 第二步:准备你的数据集
对于制造业缺陷检测项目,数据准备是最关键的一步。通常,工厂会提供一批标注好的缺陷图片。我们需要将这些数据整理成模型能够识别的格式。
数据集结构示例:
pcb_defect_dataset/
├── train/
│ ├── normal/ # 正常PCB图片
│ │ ├── 001.jpg
│ │ ├── 002.jpg
│ │ └── ...
│ ├── short_circuit/ # 短路缺陷
│ ├── open_circuit/ # 断路缺陷
│ └── bad_solder/ # 焊点不良
└── val/
├── normal/
├── short_circuit/
├── open_circuit/
└── bad_solder/
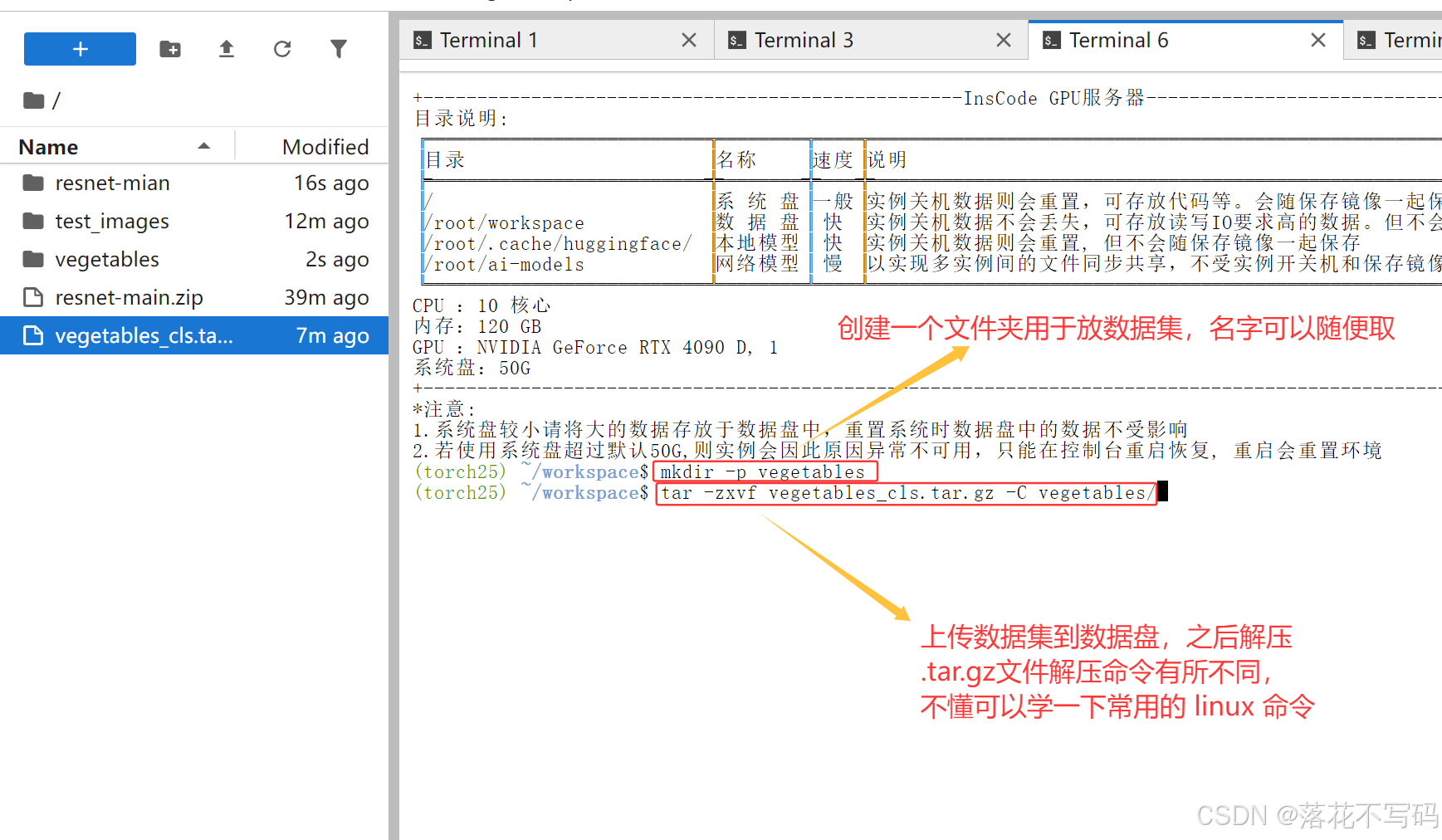
如果你的数据是压缩包,需要先解压。这里提供两种常见压缩格式的解压命令:
对于.zip文件:
unzip pcb_defect_dataset.zip -d pcb_data
对于.tar.gz文件:
# 解压到当前目录
tar -zxvf pcb_defect_dataset.tar.gz
# 解压到指定目录
tar -zxvf pcb_defect_dataset.tar.gz -C /root/workspace/data/
3.3 第三步:训练你的第一个缺陷检测模型
数据准备好后,我们就可以开始训练了。在我的训练代码中,train.py文件已经配置好了基本的训练流程,你只需要修改几个关键参数:
关键参数说明:
# 数据集路径
data_dir = '/root/workspace/data/pcb_defect_dataset'
# 模型选择(支持ResNet, EfficientNet, MobileNet等)
model_name = 'resnet50'
# 训练参数
batch_size = 32
num_epochs = 50
learning_rate = 0.001
# 缺陷类别
num_classes = 4 # normal, short_circuit, open_circuit, bad_solder
修改完参数后,在终端执行训练命令:
python train.py
训练过程会实时显示损失值和准确率:

训练完成后,模型会自动保存在指定目录。你可以使用提供的可视化代码来查看训练效果:

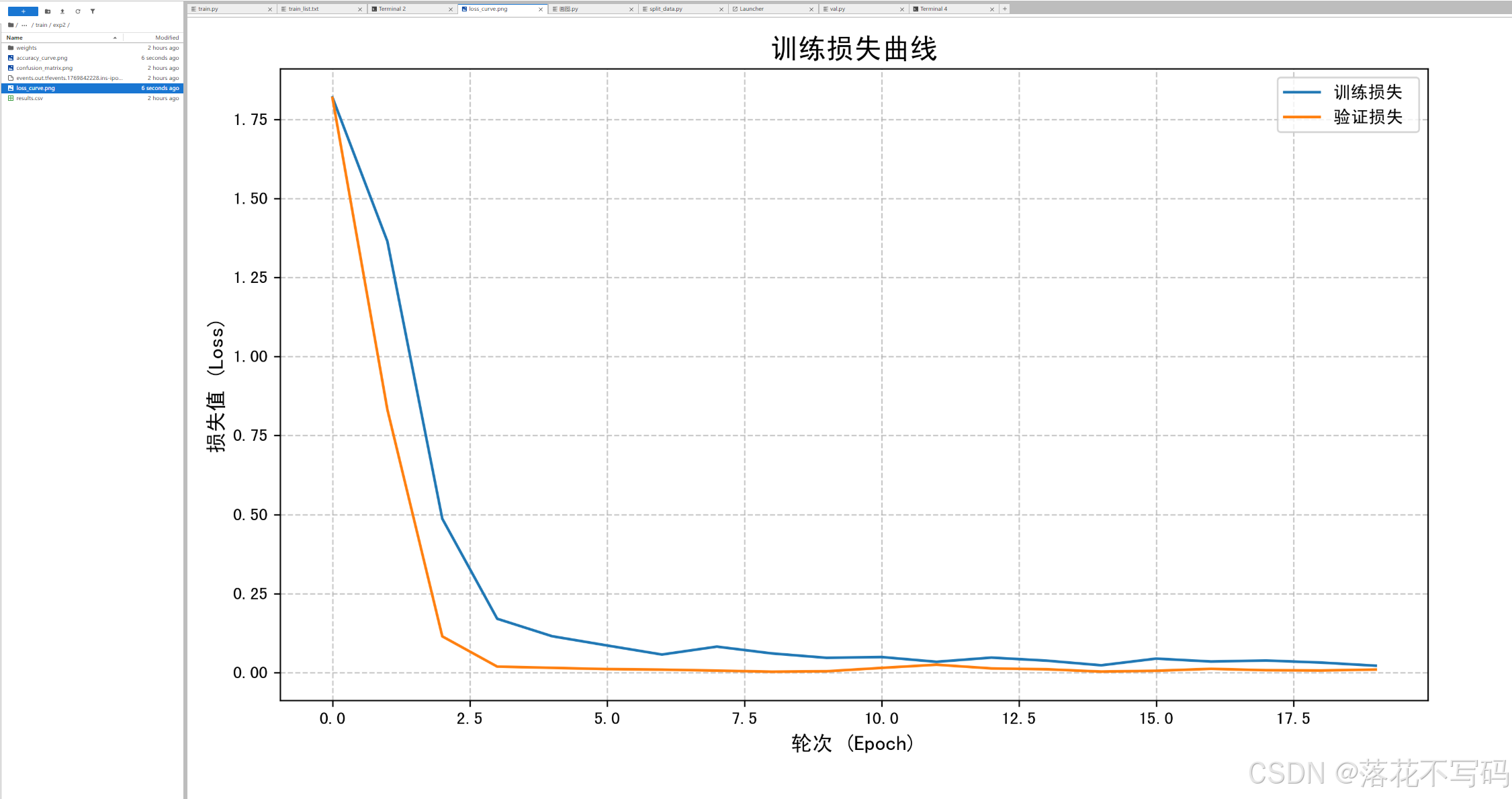
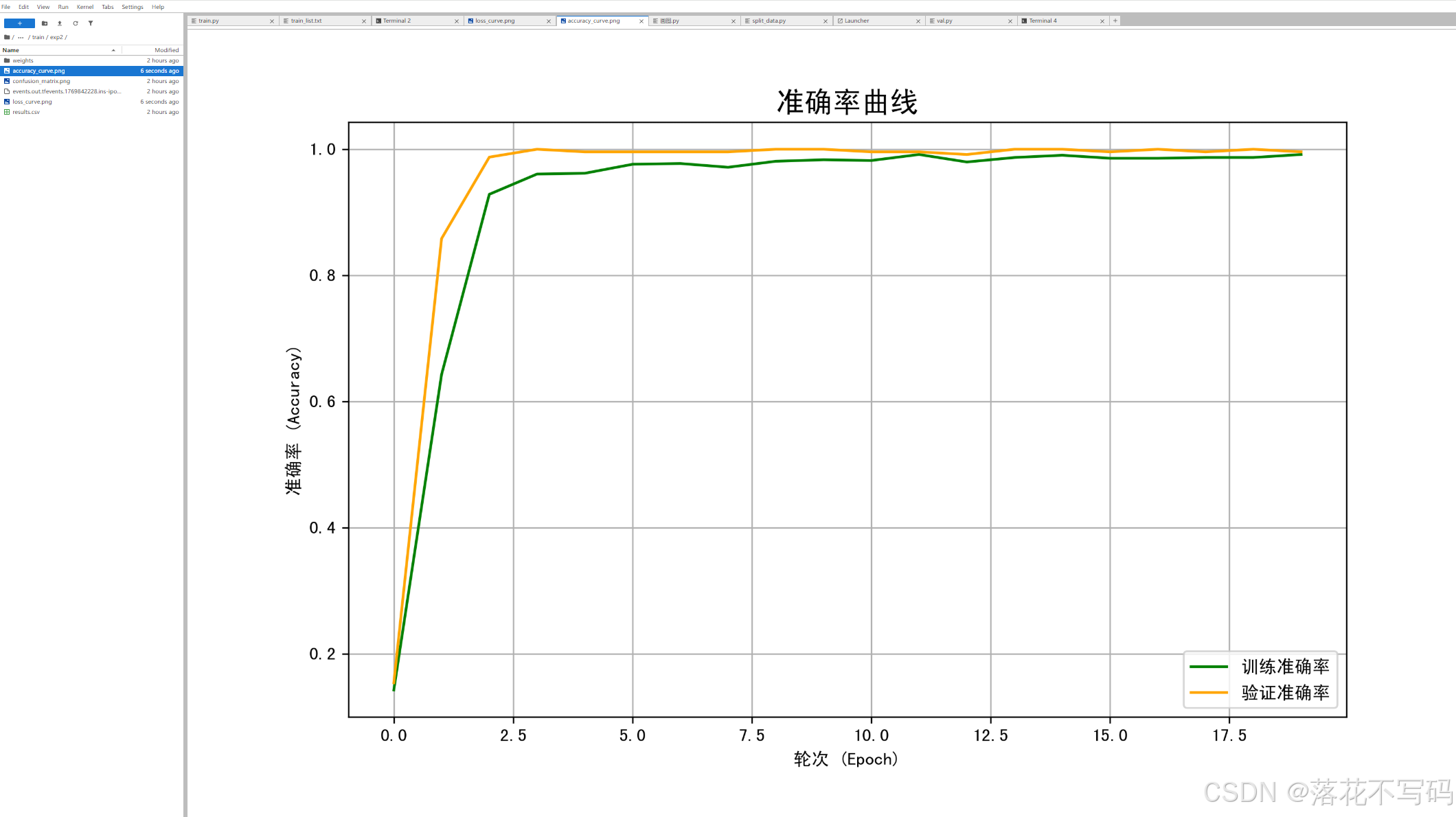
这些图表能帮你直观地了解模型的学习情况。比如,从混淆矩阵可以看出模型在哪些类别上容易混淆,从而指导你后续的数据增强或模型调整。
3.4 第四步:验证模型效果
训练好的模型需要在验证集上测试效果。修改val.py文件中的模型路径和数据集路径:

然后运行验证命令:
python val.py
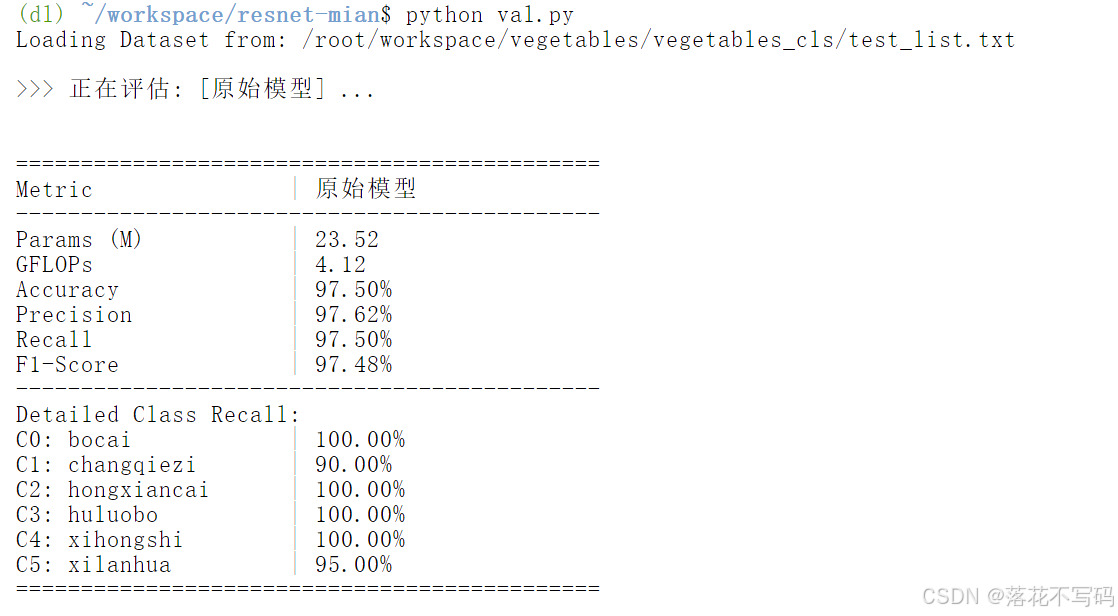
验证结果会显示每个类别的准确率、召回率、F1分数等指标,帮助你全面评估模型性能。
验证结果解读小技巧: 对于缺陷检测项目,我们通常更关注召回率(Recall),因为漏检缺陷(将缺陷品判为正常品)的代价往往比误检(将正常品判为缺陷品)更高。一个缺陷品流出工厂,可能会导致客户投诉甚至安全事故。
3.5 第五步:模型优化与轻量化(进阶)
在实际工业场景中,我们往往需要在模型精度和推理速度之间做权衡。生产线上的检测系统需要实时处理图像,因此模型不能太大、不能太慢。
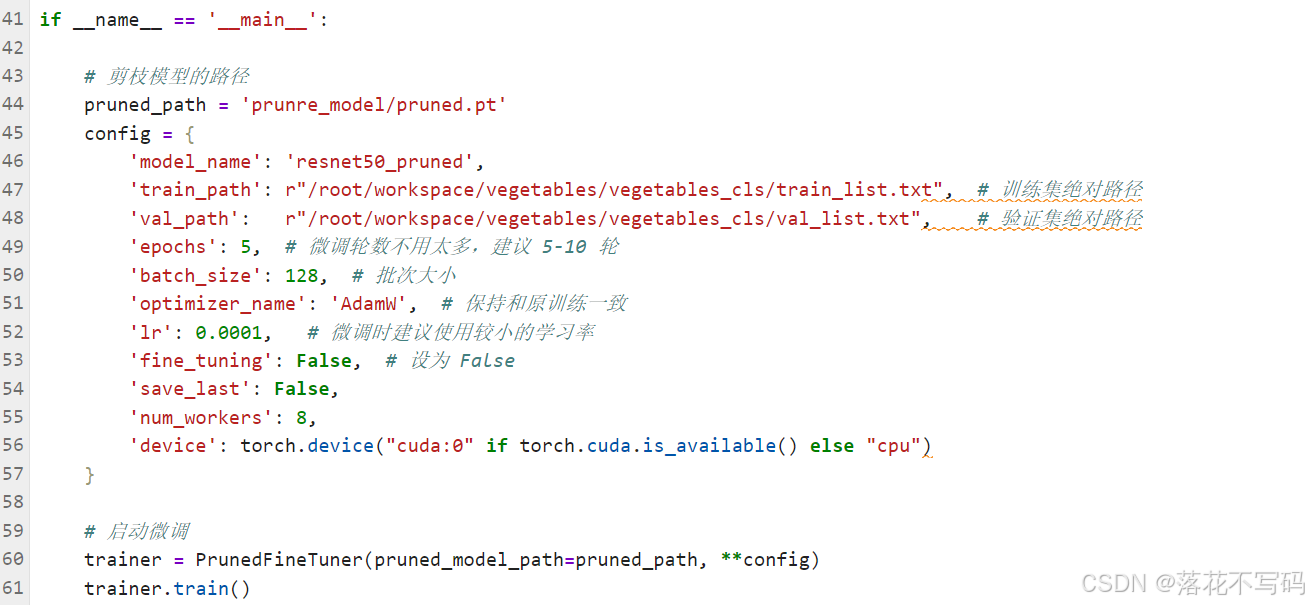
模型剪枝示例:

剪枝可以移除模型中不重要的权重,减少模型大小,提升推理速度,同时尽量保持精度。
模型微调示例:
如果你的数据量不够大,或者想针对特定类型的缺陷进行优化,可以使用微调:
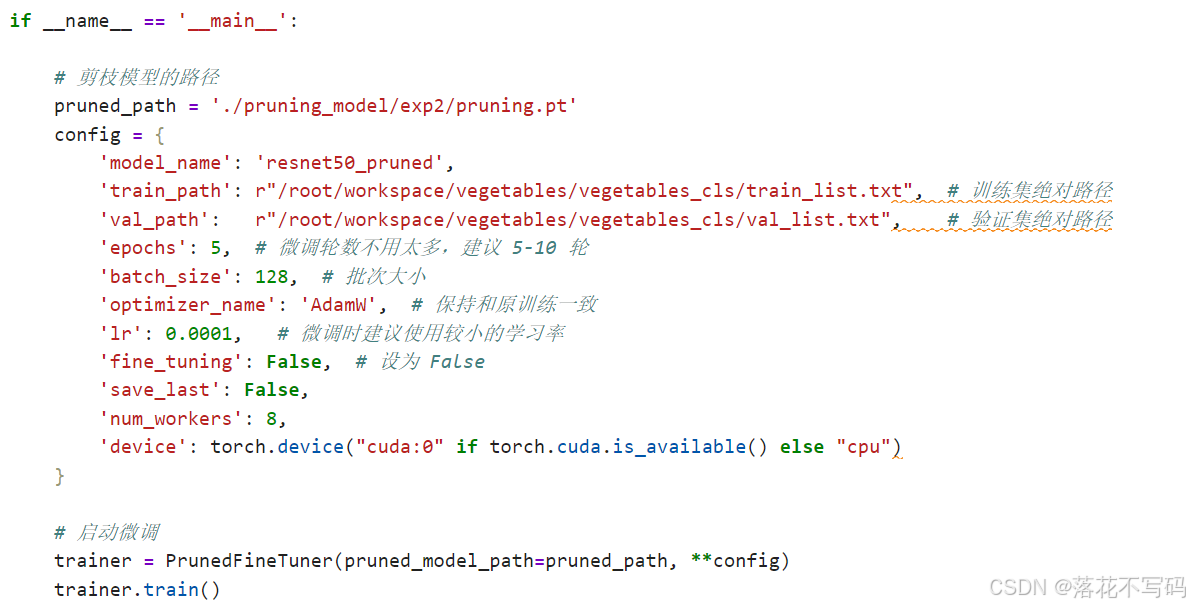

微调允许你在预训练模型的基础上,用少量数据快速适应新任务。这对于数据稀缺的工业场景特别有用。
3.6 第六步:部署上线与模型下载
模型训练和优化完成后,最后一步就是部署到生产环境。在部署之前,我们需要将训练好的模型从服务器下载到本地。
使用Xftp下载模型:
- 连接服务器后,找到模型保存的目录
- 将模型文件从右侧服务器窗口拖拽到左侧本地窗口
- 对于大文件,建议先压缩再下载,可以节省时间
下载的模型可以用于:
- 部署到工厂的工控机进行实时检测
- 集成到Web系统中,供质检员使用
- 封装成API服务,供其他系统调用
4. 企业级项目实操建议
通过上面的流程,你已经完成了一个完整的缺陷检测项目。但在实际企业项目中,还有一些经验值得分享:
1. 数据质量决定上限
- 制造业数据往往存在类别不平衡问题(正常品远多于缺陷品)
- 建议使用数据增强技术,如旋转、翻转、颜色抖动等,增加缺陷样本的多样性
- 对于难以获取的缺陷类型,可以考虑使用生成对抗网络(GAN)生成合成数据
2. 模型选择要务实
- 不要盲目追求最先进的模型,要考虑部署环境的计算能力
- 对于实时检测场景,MobileNet、ShuffleNet等轻量级网络往往是更好的选择
- 可以训练多个不同复杂度的模型,根据实际需求选择
3. 部署考虑要周全
- 工业环境可能没有互联网,所有依赖必须离线可用
- 考虑使用ONNX或TensorRT等格式优化推理速度
- 设计好日志系统和报警机制,当检测到连续缺陷时及时通知工作人员
4. 持续迭代很重要
- 收集生产线上的误检和漏检案例,用于模型迭代
- 定期用新数据重新训练模型,适应生产线的变化
- 建立模型版本管理系统,确保可追溯和可回滚
5. 常见问题与解决方案
在实际操作中,你可能会遇到这些问题:
- 数据集路径错误:确保在训练文件中正确指定了数据集路径,路径中不要有中文或特殊字符
- 环境激活失败:镜像启动后默认可能不在
dl环境,记得执行conda activate dl - 显存不足:减小
batch_size,或者使用梯度累积技术 - 训练过拟合:增加数据增强,使用Dropout,或提前停止训练
- 推理速度慢:尝试模型剪枝、量化,或使用更轻量的模型结构
如果遇到镜像本身的问题,可以联系作者获取技术支持。这个镜像经过大量项目验证,稳定性有保障。
6. 总结
通过这个完整的缺陷检测项目实操,你应该已经感受到了标准化训练环境带来的便利。从数据准备到模型部署,整个流程顺畅无阻,你可以把精力真正花在解决业务问题上,而不是折腾环境。
这个深度学习训练环境镜像的价值在于:
- 开箱即用:无需配置环境,直接开始项目
- 环境统一:团队协作不再有“环境差异”问题
- 快速迭代:从想法到原型的时间大大缩短
- 易于部署:训练环境和部署环境保持一致,减少适配成本
对于制造业企业来说,深度学习不再是遥不可及的黑科技。有了这样的工具链,即使是没有深厚AI背景的工程师,也能快速开发出可用的缺陷检测系统。这不仅仅是技术的进步,更是生产效率和质量控制的革命。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)