【CUDA和cuDNN】到底是干嘛的?
摘要 CUDA与cuDNN是NVIDIA提供的GPU计算工具,但定位不同。CUDA是通用并行计算平台,提供编程模型和运行时环境,允许开发者直接编写GPU加速程序。cuDNN是基于CUDA的深度学习专用加速库,为神经网络操作提供高度优化的实现。实际开发中,深度学习框架通过cuDNN间接使用CUDA,而开发者仅在自定义算子时需要直接使用CUDA。两者版本需严格匹配,典型配置如CUDA 11.8+cuD
从命令输出说起
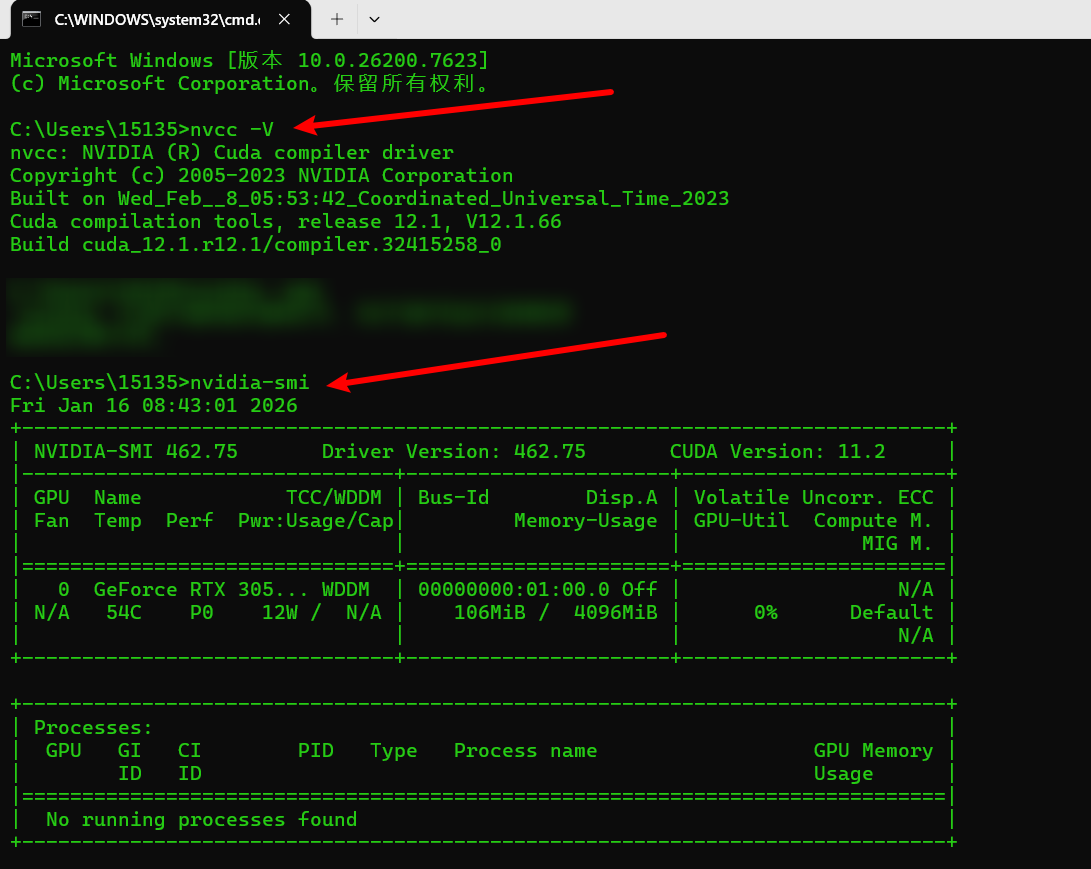
我们首先解释下这两个命令输出为何不同:
nvcc -V 输出
Cuda compilation tools, release 12.1, V12.1.66
- 这显示你安装的CUDA Toolkit版本是12.1
nvcc是NVIDIA的CUDA编译器- 这个版本表示你能编写和编译基于CUDA 12.1的代码
CUDA 是什么?
CUDA是Compute Unified Device Architecture(统一计算设备架构)的缩写。它是NVIDIA开发的并行计算平台和编程模型,允许开发者使用C/C++/Python等语言直接调用GPU进行通用计算。CUDA提供硬件抽象层、运行时API和编译器工具(nvcc),将GPU的强大并行处理能力扩展到科学计算、深度学习、图像处理等领域,实现数十至数百倍的性能加速。nvcc 是什么?
nvcc(NVIDIA CUDA Compiler)是 NVIDIA CUDA 编程工具链中的编译器驱动程序。它负责将基于 CUDA C/C++ 编写的代码编译成能够在 NVIDIA GPU 上执行的程序。nvcc 会将 CUDA 内核代码 和普通 C/C++ 代码 编译在一起,生成最终的可执行文件或对象文件,供 CPU 和 GPU 协同运行。
nvidia-smi 输出
Driver Version: 462.75 CUDA Version: 11.2
- 这显示你显卡驱动支持的CUDA运行时版本是11.2
nvidia-smi显示的是驱动层信息- 这个版本表示你的系统能运行最高到CUDA 11.2的程序
关键点:只要你的CUDA Toolkit版本不高于驱动支持的版本,大部分情况下都能工作。但为了最佳兼容性,建议保持版本一致或接近。
显卡驱动升级过程图
CUDA vs cuDNN:核心区别详解
CUDA:通用并行计算平台
┌─────────────────────────────────────┐
│ CUDA 架构 │
├─────────────────────────────────────┤
│ 1. 并行计算模型 │
│ 2. 编程语言扩展 (C/C++/Python) │
│ 3. 运行时API和驱动 │
│ 4. GPU硬件抽象层 │
└─────────────────────────────────────┘
CUDA是什么?
- 全称:Compute Unified Device Architecture
- 本质:一种让GPU进行通用计算的平台和编程模型
- 作用:让你能用类C语言编写在GPU上运行的程序
CUDA的组成:
- 编程模型:线程、块、网格的层次结构
- 硬件抽象:通过SM(流多处理器)管理计算资源
- 内存模型:全局内存、共享内存、常量内存等
- 运行时API:管理GPU设备、内存、执行等
// 典型的CUDA核函数示例
__global__ void vectorAdd(float* A, float* B, float* C, int n) {
int i = threadIdx.x + blockIdx.x * blockDim.x;
if (i < n) {
C[i] = A[i] + B[i];
}
}
cuDNN:深度学习加速库
┌─────────────────────────────────────┐
│ cuDNN 角色 │
├─────────────────────────────────────┤
│ 1. 深度神经网络原语 │
│ 2. 高度优化的GPU内核 │
│ 3. 框架接口层 │
│ 4. 版本兼容管理器 │
└─────────────────────────────────────┘
cuDNN是什么?
- 全称:CUDA Deep Neural Network library
- 本质:基于CUDA的深度学习专用加速库
- 作用:为深度学习框架提供高度优化的底层实现
cuDNN的组成:
- 张量操作:卷积、池化、归一化等
- 激活函数:ReLU、sigmoid、tanh等
- 循环神经网络:LSTM、GRU等
- 多GPU支持:数据并行和模型并行
形象比喻:建筑工人视角
CUDA 就像是…
建筑工地和基础工具
- 提供场地(GPU硬件)
- 基础工具(编程语言、编译器)
- 施工规则(编程模型)
- 你可以用这些建造任何东西
cuDNN 就像是…
预制构件和特种设备
- 预制墙板(卷积操作)
- 快速楼梯模块(池化层)
- 标准门窗(激活函数)
- 专门为建"神经网络大楼"设计
实际工作流程
# 1. PyTorch调用cuDNN
import torch
conv = torch.nn.Conv2d(3, 64, kernel_size=3)
# 底层发生的事:
# PyTorch -> cuDNN -> CUDA Runtime -> GPU硬件
# ↑ ↑ ↑ ↑
# 框架层 加速库 运行时 硬件
实际开发中的角色分工
CUDA(你需要直接使用的情况)
- 自定义算子开发
# 当现有框架无法满足需求时
class CustomConvFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, input, weight):
# 这里调用你自己写的CUDA内核
output = custom_cuda_conv(input, weight)
return output
- 性能优化
// 优化内存访问模式
__global__ void optimized_conv(
float* input, float* output,
float* kernel, int width, int height) {
// 使用共享内存减少全局内存访问
__shared__ float tile[TILE_SIZE][TILE_SIZE];
// ... 优化实现
}
cuDNN(你间接使用的情况)
- 框架自动调用
# PyTorch/TensorFlow自动选择最优实现
model = models.resnet50(pretrained=True)
model.cuda() # 自动使用cuDNN加速
- 手动选择算法
import torch.backends.cudnn as cudnn
cudnn.benchmark = True # 让cuDNN自动寻找最快算法
cudnn.deterministic = False # 允许非确定性算法
版本兼容性矩阵
| CUDA版本 | cuDNN版本 | PyTorch版本 |
|---|---|---|
| 11.x | 8.x | 1.9+ |
| 10.2 | 7.6+ | 1.5-1.8 |
| 9.2 | 7.1+ | 1.1-1.4 |
重要规则:
- cuDNN版本必须与CUDA版本匹配
- 深度学习框架版本必须与两者兼容
- 驱动版本必须支持CUDA版本
安装和配置指南
推荐配置(2024年)
# 1. 检查驱动
nvidia-smi
# 2. 安装CUDA Toolkit 11.8
# 3. 安装cuDNN for CUDA 11.x
# 4. 安装PyTorch
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118
# 5. 验证安装
python -c "import torch; print(torch.cuda.is_available())"
配置环境变量
# Windows
set PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin;%PATH%
set CUDA_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8
# Linux
export PATH=/usr/local/cuda-11.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH
图像算法工程师的实际应用
场景1:目标检测优化
import torch
import torchvision
class FasterRCNN_Optimized:
def __init__(self):
# cuDNN自动优化卷积
self.model = torchvision.models.detection.fasterrcnn_resnet50_fpn()
self.model.cuda()
# 启用自动调优
torch.backends.cudnn.benchmark = True
def inference(self, image_batch):
# 自动使用最优cuDNN算法
with torch.cuda.amp.autocast(): # 混合精度训练
return self.model(image_batch)
场景2:自定义图像处理层
// 编写CUDA内核实现自定义操作
__global__ void bilateral_filter_cuda(
float* input, float* output,
int width, int height,
float spatial_sigma, float range_sigma) {
// 双边滤波的CUDA实现
// 比CPU实现快50-100倍
}
// Python封装
class BilateralFilter(torch.nn.Module):
def forward(self, x):
return bilateral_filter_cuda_launcher(x, spatial_sigma, range_sigma)
场景3:多尺度特征融合
class MultiScaleFusion(nn.Module):
def __init__(self):
super().__init__()
# cuDNN优化的卷积层
self.conv1 = nn.Conv2d(256, 128, 3, padding=1)
self.conv2 = nn.Conv2d(128, 64, 3, padding=1)
def forward(self, features):
fused = []
for feat in features:
# 自动使用最优cuDNN卷积算法
x = F.relu(self.conv1(feat))
x = self.conv2(x)
fused.append(x)
return torch.cat(fused, dim=1)
常见问题解决
Q1:版本不匹配错误
# 错误:CUDA error: no kernel image is available for execution
# 原因:CUDA Toolkit版本太高,驱动不支持
# 解决方案:
# 1. 升级驱动
# 2. 或降级CUDA Toolkit到驱动支持的版本
Q2:内存不足
# 使用内存优化技巧
torch.cuda.empty_cache() # 清空缓存
torch.cuda.memory_summary() # 查看内存使用
# 混合精度训练节省内存
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
with autocast():
loss = model(input)
scaler.scale(loss).backward()
Q3:cuDNN找不到
# 设置正确的库路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export CUDNN_PATH=/usr/local/cuda/lib64/libcudnn.so
性能对比数据
| 操作类型 | CPU时间 | CUDA基础 | cuDNN优化 | 加速比 |
|---|---|---|---|---|
| 卷积 3x3 | 100ms | 5ms | 1ms | 100x |
| 批量归一化 | 50ms | 2ms | 0.5ms | 100x |
| 池化 2x2 | 20ms | 1ms | 0.2ms | 100x |
| ReLU激活 | 10ms | 0.1ms | 0.05ms | 200x |
最佳实践建议
1. 版本管理
# 使用conda管理环境
conda create -n pytorch_cuda118 python=3.9
conda install pytorch torchvision cudatoolkit=11.8 -c pytorch
2. 代码优化
# 启用所有优化
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.enabled = True
# 使用异步数据传输
data = data.cuda(non_blocking=True)
# 使用pinned memory加速数据传输
loader = DataLoader(dataset, pin_memory=True)
3. 监控和调试
import torch
# 监控GPU使用
print(torch.cuda.memory_allocated() / 1024**3, "GB used")
print(torch.cuda.memory_reserved() / 1024**3, "GB reserved")
# 使用nsight进行分析
# nvprof python train.py
总结
一句话概括:
- CUDA是让你能在GPU上编程的基础平台
- cuDNN是在CUDA基础上专门为深度学习优化的算法库
作为图像算法工程师:
- 大多数时候:你通过PyTorch/TensorFlow间接使用cuDNN
- 需要优化时:可能直接编写CUDA内核
- 关键技能:理解层次关系,能诊断版本兼容性问题
- 核心价值:知道如何选择最佳配置,最大化GPU利用率
行动建议:
- 统一你的环境版本(建议CUDA 11.8 + cuDNN 8.6)
- 理解你的模型具体调用了哪些cuDNN函数
- 学会使用性能分析工具(如nsight、torch.profiler)
- 在需要极致性能时,考虑自定义CUDA算子
这样,你就能充分利用GPU的强大算力,在图像算法开发中获得最优性能。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)