计算机毕设答辩|大数据深度学习|计算机毕设项目|+Vue 基于深度学习的微博情感分析系统设计与实现
本文设计并实现了一个基于Django+Vue框架的微博情感分析系统。系统采用Scrapy爬虫技术获取微博热搜和评论数据,通过MySQL存储海量数据,并利用深度学习模型进行情感分析。前端使用Vue+ECharts实现数据可视化展示,后台采用Django框架构建。系统具备舆情预警功能,可分析用户言论情感倾向,计算积极消极言论比值,为舆情监测提供参考。测试表明系统能有效实现微博数据采集、存储、分析和可视

标题:Django+Vue 基于深度学习的微博情感分析系统设计与实现
文档介绍:
1.1研究背景与意义
随着互联网的普及和社交媒体的兴起,微博作为一种重要的信息传播和公众舆论敏感话题平台,已经成为人们获取信息、表达观点和交流思想的重要渠道。然而,微博的快速发展也带来了一系列问题,其中之一就是舆情的管理和预警。在大数据时代,如何有效地利用微博数据,进行舆情检查与预警,成为了当前社会的一个重要课题。这不仅关系到社会的稳定和公共安全,也关系到企业和个人的形象和利益。
基于深度学习的微博情感分析系统,就是利用大数据技术对微博数据进行采集、存储、处理和分析,实现对潜在舆情风险的预测和控制。通过建立这样的系统,可以及时发现和处理负面舆情,避免或减少其对社会稳定和公共安全的影响。同时,我们也可以通过对微博数据的分析和挖掘,发现潜在的舆情风险,为决策者提供有力的参考和支持。
1.2系统的特点
(1)大数据处理能力:该系统使用MySQL进行存储,具备强大的大数据处理能力,能够快速处理海量的微博热搜、评论数据,保证系统的稳定性和效率。
(2)可扩展性强:该系统设计时考虑到未来可能的需求和发展,具备可扩展性,能够根据用户需求进行功能扩展和升级。
(3)情感分析准确度高:该系统采用先进的文本挖掘技术,能够准确识别评论与热搜中的情感倾向、情感强度以及高频词汇和主题,从而为舆论检查与预警相关部门提供重要的市场反馈和参考。
(4)系统前台使用vue脚手架和Echart技术实现了数据可视化,方便用户的查看,及时了解需要的信息。
1.3研究内容
基于深度学习的微博情感分析系统的研究内容主要包括以下几个方面:
(1)爬虫程序:该系统首先需要设计并实现一个高效的爬虫程序,能够自动爬取微博平台的热搜、微博评论等数据。爬虫程序需要能够识别和下载各类微博的同时要考虑到用户隐私和法律法规的要求,避免过度收集用户数据。
(2) 数据存储:爬虫程序爬取的数据需要存储在合适的数据存储系统中,以便后续的数据处理和分析。该系统采用MySQL进行存储,来处理海量的评论数据,同时保证数据的安全性和可靠性。
(3)可视化界面显示:该系统需要设计一个友好的可视化界面,方便用户查看和分析评论数据。可视化界面可以包括数据表格、柱状图、折线图等,以便用户能够直观地看到情感分析和用户行为分析的结果。
(4)情感分析算法:系统可以对评论数据进行获取,并通过与情感分析模型进行对比,准确识别出博文与评论中的积极和消极情感,并生成对应的舆论检测与预警预测结果。
1.4论文结构
图1.1论文结构图
本文的结构如上图所示,相关技术介绍主要介绍了系统的开发工具和前后台框架,爬虫技术、分布式架构理论等,系统设计包括流程设计与数据库设计等。
系统是服务器端采用python编写的Web企业级项目,前台开发工具通过HBuilder开发,后台使用pycharm集成环境开发。根据web项目的一般性技术要求主要包括,前台技术,后台数据处理,爬虫数据获取技术等。前台技术主要是通过vue脚手架结合Echart实现可视化界面,通过axios异步与后台沟通获取数据库数据,后台数据存储mysql框架,数据的获取使用python的第三方插件scrapy框架进行网页的获取,并使用xpath进行网页的数据的解析,通过pandas进行文本数据的存储。以下介绍主要的技术。
2.1 大数据与分布式架构理论介绍
如今是一个大数据的年代,大数据(big data)有重要的5个特点(5V)包括:多样性(Variety)、体量(Volume)、速度(Velocity)、准确性(Veracity)和价值(Value)。多样性是指大数据包含多种类型和来源的数据,包括结构化、半结构化和非结构化数据。体量是指大数据具有大规模的数据集,通常在PB级别甚至更大。速度是指大数据需要在合理的时间内处理和分析数据,以产生有价值的洞察。准确性是指大数据的真实性和可信度,需要通过数据清洗和验证等手段来保证数据的准确性。价值是指大数据可以为企业和组织带来更高的商业价值,通过优化决策、提高效率和降低成本等方式实现。
然而要处理这巨大的数据涉及到数据的存储和计算,这样就产生了分布式架构理论。分布式理论表面很简单,就是通过增加服务器的数量来处理庞大的数据。首先对数据或者计算进行有效的切割,然后再对这些数据或者计算进行多个服务器的存储和计算,通过这样的方式来增加数据存储和计算的效能,提升数据的处理能力。
2.2 Spider爬虫技术
爬虫技术是一种自动化数据采集技术,通过编写程序模拟人类访问网站的行为,可以快速、准确地获取大量数据。在大数据时代,爬虫技术得到了广泛的应用和推广。爬虫技术是一种自动化数据采集技术,通过编写程序来模拟人类访问网站的行为,自动抓取网站上的信息。爬虫技术可以用于各种场景,例如数据挖掘、竞争情报、用户行为分析等。爬虫的工作原理通常是从一个或多个初始页面开始,根据一定的规则(如链接、关键字等)遍历网站上的所有页面,提取其中的数据并按照一定的格式进行存储。在提取数据的过程中,爬虫需要遵循网站的robots.txt协议和反爬虫策略,以确保采集数据的合法性和安全性。简单的信息的爬取可以使用python的第三方库比如request,urllib等,然而随着越来越多网站设置了反扒,数据的爬取也变得困难。本系统使用的scrapy爬虫框架,通过修改配置以及模拟浏览器发出请求,一般是可以不被反扒机制所阻止,然后再xpath技术读取到页面中需要的数据,最后通过pandas技术实现csv文本格式的存储。
2.3 Django框架
Django简单来说就是python的应用的web框架,它拥有和springMVC类似的工作原理,提供MVT框架模式以提高系统的开发效率。M层就是模型层,在java应用中需要mybatis这样的ORM(对象模型映射)框架,但是Django内置了ORM框架的类库,这样就省去了额外的配置,减少了使用上的困难。另外,值得一提的是,框架对controller控制层进一步进行了封装,成为了更符合开发模式的路由,由路由来分发具体的操作请求,主要通过在相应的配置文件中进行配置,所以通过使用Django就能快速搭建一个web系统服务器。
2.4 Vue和Echart
Vue和ECharts在可视化系统中的应用是一个非常有趣且实用的工具。Vue是一个流行的JavaScript框架,它提供了丰富的工具和组件,使得开发者可以轻松地构建用户界面。而ECharts则是一个使用JavaScript实现的,开源的可视化库,它提供了大量强大的图表类型和配置选项,可以帮助开发者创建出丰富而直观的数据可视化效果。在可视化系统中,Vue和ECharts的结合可以带来许多优势。首先,Vue提供了强大的组件系统,可以轻松地创建复杂的用户界面,而ECharts则可以用来创建各种数据可视化图表。通过将这两个工具结合起来,开发者可以创建一个功能丰富、交互性强、用户体验良好的可视化系统。
具体来说,Vue和Echart可以在以下几个方面帮助开发者实现可视化系统:
(1)创建复杂的用户界面:Vue提供了大量的组件和布局选项,可以帮助开发者创建各种复杂的用户界面。通过使用Vue,开发者可以轻松地实现数据可视化的各种功能,如数据展示、交互操作、动态更新等。
(2)高效的数据处理:Vue提供了强大的数据绑定和响应式系统,可以帮助开发者高效地处理数据。通过将ECharts图表与Vue的数据绑定起来,开发者可以轻松地实现数据的实时更新和动态交互。
(3)易于扩展和维护:Vue的组件化和模块化架构使得代码易于扩展和维护。开发者可以通过使用第三方插件和组件库来扩展ECharts的功能,同时也可以轻松地管理和维护整个系统的代码。
而ECharts在可视化系统中的作用则主要体现在以下几个方面:
(1)提供丰富的图表类型和配置选项:ECharts提供了大量的图表类型和配置选项,如折线图、柱状图、饼图、散点图等,可以帮助开发者根据不同的数据需求创建出各种直观的数据可视化效果。
(2)高度定制化:ECharts提供了丰富的配置选项,可以帮助开发者根据具体需求对图表进行高度定制化。例如,可以通过调整颜色、字体、动画效果等来增强图表的可视化效果。
总的来说,Vue和ECharts的结合可以为可视化系统带来许多优势,包括创建复杂的用户界面、高效的数据处理、易于扩展和维护以及提供丰富的图表类型和配置选项等。这种结合对于数据分析和数据可视化的应用场景非常有用,可以帮助开发者更好地理解和呈现数据,提高数据的使用效率和用户体验。。
本章主要首先对系统开发的可行性进行分析,然后再对整体的系统开发流程和用户注册登录流程以及舆情预警流程进行分析。
3.1可行性分析
基于深度学习的微博情感分析系统具有可行性,具体分析如下:
(1)技术可行性:现代自然语言处理(NLP)技术已经非常成熟,可以实现对海量文本数据的自动分类、情感分析、主题提取等任务。微博的评论,博文等数据可以通过爬虫技术获取,并通过文本挖掘技术进行情感分析。其次其它的技术包括有vue、django、python语言等都是学校学习过的,如果不懂也是可以通过网络或者查看文献的方式解决。
(2)经济可行性:系统的开发使用的基本都是开源的软件,花费主要是个人的精力,不需要额外开支。另外随着互联网的普及和社交媒体的兴起,微博已经成为人们获取信息、表达观点和交流思想的重要渠道,因此,基于深度学习的微博情感分析系统的市场需求较大。
(3)操作可行性:开发该系统的应具有丰富的计算机前后端技术,和大数据领域知识,能够实现系统的开发、测试和部署。但是对于用户来说,使用则非常的简单,只需要注册之后便能登录,查看对应的可视化界面,填入相关的博主信息,给出预警分析预测。
综上所述,基于深度学习的微博情感分析系统具有可行性,能够为用户提供有价值的舆情检测与预警服务。但同时也要注意,系统涉及的功能较多,需要耐心开发。
3.2 非功能性需求分析
基于深度学习的微博情感分析系统的非功能性需求分析如下:
(1)性能需求:系统应具有较高的处理速度和稳定性,能够实时或接近实时地处理海量的音乐评论等数据。
(2)容量需求:系统应具有可扩展性,能够应对音乐平台用户数量的增长和评论数据的增加。
(3)安全性需求:系统应采用多种安全措施,如数据加密、访问控制、防病毒等,以保护用户数据和隐私。
(4)用户界面需求:系统应提供直观、易用的用户界面,方便用户查看各类评论和博文热搜数据。
(5)法律合规性需求:系统应遵守相关法律法规,确保爬虫爬取的数据要正当,数据的使用和处理符合相关法规要求。
3.3主要流程分析
(1)系统整体开发流程图分析
系统开发流程如下图所示,首先需要使用scrapy爬虫技术从微博中获取到相应的网页,并且通过xpath提取需要的相关数据,然后通过pandas写入到csv文本文件中,然后再利用算法进行话题情感预测,最后通过前台的vue和Echart进行数据可视化展示。
图3.1系统整体开发流程图
(2)用户注册与登录流程分析
浏览人员进入网站之后,如果不是会员则需要先注册。即填写信息,在数据库中添加用户信息,注册成功。注册用户登录之后,可以跳转到主页面,并且对评论进行情感分析,流程图如3.2所示。
图3.2用户注册与登录流程图
(3) 舆情预警流程分析
用户在预测栏中输入博主账户,后台会获取到对应的发布评论与热搜等相关数据信息,并通过后台的情感分析模型做出分析预测,最后显示到舆情预警栏上,如图3.3所示。
图3.3舆情预警流程图
3.4本章小结
本章首先对系统开发的可行性进行了分析,然后对系统的非功能性需求进行了分析,并对系统开发的整体流程以及主要流程操作进行了介绍。
系统设计是系统开发之前需要做的总体设计,这里主要从系统的架构设计,后台的包架构设计以及前台页面结构设计,模块设计等进行阐述.
4.1 系统总体架构设计
本系统的是基于B/S架构的,前台通过浏览器进行访问,web服务器会对访问进行解析,然后通过HTTP协议于后台Django框架进行沟通。Django框架是基于MTV(模型、模板和视图层)的,视图层层会接收到路由分发的请求,进而调用业务逻辑层代码,业务逻辑层代码再进一步调用模型层代码对数据库进行操作了,操作结束后,数据库数据发生改变。其次,服务器再调取数据的操作时候,由于数据发生了变化,所以相应的发送到前台的客户端的数据也相应的变化。具体如下图4.1所示。
图4.1 系统工作原理示意图
4.2 系统模块设计
-
-
- 系统功能介绍
-
系统的功能主要包括三个方面。首先是需要从微博网站爬取到相应的数据,这些数据包括有博文信息,热搜信息、博文评论、转发信息等。其次是将这些数据存储到服务器的mysql中,经过算法对话题进行情感预测。最后通过django搭建的web页面进行数据的可视化展示,在页面中对博主账户发布的评论以及博文等信息进行情感分析的,查看其消极言论与积极言论的占比,最后给出该用户的舆情预警信息。
-
-
- 系统主要模块设计
-
根据以上的功能需求情况可知,整体的功能模块包括有前台vue项目模块,后台django后台项目模块和爬虫模块。前台vue的页面主要页面包括注册与登录页面,数据可视化展示页面,爬虫模块主要用来爬取微博的数据信息的,通过使用MySQL进行数据的存储,django后台用来提供前台所用的json数据。
图4.2系统功能模块图
系统前台页面包括有注册于登录,考虑到本系统主要的功能设定是数据的爬取以及大数据可视化展示和情感分析,所以注册与登录页面设计相对简单,可视化主页面展示分为7块区域,顶部是系统的名称,下面划分为6个区域,分别是热度排行榜区域,热搜榜展示区域等,具体如图。
图4.3主页面布局图
4.4 数据库设计
数据库是系统的数据源,根据需要展示可视化表格的要求,需要确定爬取数据的对象和属性,然后封装到数据库中,以下是主要需要爬取和储存的数据信息。
表4-1账户名数据信息表(nickname_count)
|
列名 |
注释 |
数据类型 |
|
id |
主键 |
Interger |
|
nickname |
账户名 |
Text |
|
count |
数量 |
Integer |
表4-2热搜信息表(reshout)
|
列名 |
注释 |
数据类型 |
|
id |
主键 |
Interger |
|
time |
时间 |
Text |
|
rank |
级别 |
Text |
|
content |
内容 |
Text |
|
link |
链接 |
Text |
|
hot |
是否热搜 |
Interger |
|
tags |
标签 |
Text |
表4-3微博分享评论点赞信息表(topic_avg)
|
列名 |
注释 |
数据类型 |
|
id |
主键 |
Interger |
|
topic |
主题 |
Text |
|
share |
分享数 |
Text |
|
comment |
评论数 |
Text |
|
like |
点赞数 |
Text |
表4-4微博信息表(weibo)
|
列名 |
注释 |
数据类型 |
|
id |
主键 |
Interger |
|
topic |
主题 |
Text |
|
share |
分享数 |
Text |
|
comment |
评论数 |
Text |
|
like |
点赞数 |
Text |
|
nickname |
账户名 |
Text |
|
content |
内容 |
Text |
4.5 本章小结
本章首先介绍了系统的整体框架,其次对系统的主要页面和模块进行了分析和设计;最后根据前台需要展示的数据列出来需要爬取的实体类和数据信息,这些数据是先通过pandas存储为csv文本格式的。
5.1 系统的配置和部署
系统后台使用python书写,采用django框架搭建。以下是需要配置的一些插件,包括pyMysql,django,pip等,系统的虚拟环境采用python3.8,具体如下图所示。另外就是还需要配置JDK环境。
图5.1系统的配置图片
后台程序需要连接数据库,在settings.py文件中进行相应的配置,以下是配置内容。
|
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', # 数据库引擎 'NAME': ' hz_project_webo ', # 数据库名称 'HOST': '127.0.0.1', # 数据库地址,本机 ip 地址 127.0.0.1 'PORT': 3306, # 端口 'USER': 'root', # 数据库用户名 'PASSWORD': 'root', # 数据库密码 } } |
5.2 数据爬取与存储功能实现
-
-
- 微博平台爬取页面分析
-
微博平台是一种基于用户关系信息分享、传播以及获取的社交媒体、网络平台。它允许用户通过多种移动终端接入,以文字、图片、视频等多媒体形式,实现信息的即时分享、传播互动。微博基于公开平台架构,提供简单的方式使用户能够公开实时发表内容,通过裂变式传播,让用户与他人互动并与世界紧密相连。作为继门户、搜索之后的互联网新入口,微博改变了信息传播的方式,实现了信息的即时分享。从这个平台可以爬取到大量用户发布的博文和评论信息,以此为基础做出舆情检测与预警。
图5.2爬取网站主页面图片
-
-
- 微博平台数据爬取
-
微博平台数据做了反扒出来,这里采用了scrapy框架进行网页的爬取,以爬取https://s.weibo.com/top/summary?cate=realtimehot网页为例,部分相关爬取代码如下。
|
name = 'ReSouSpiders' allowed_domains = ['weibo.com'] url = 'https://s.weibo.com/top/summary?cate=realtimehot' # 搜索链接 search_url = 'https://s.weibo.com/weibo?q={}' # TODO 打开cmd,输入: start chrome --flag-switches-begin --flag-switches-end --remote-debugging-port=9887 def start_requests(self): yield scrapy.Request(url=self.url, callback=self.parse) |
爬取到指定的网友之后需要对网页需要的信息进行提取,这里使用xpath进行提取,部分相关代码如下。
|
def parse(self, response): # 获取当天的日期,格式年/月/日 time = datetime.datetime.now().strftime('%Y-%m-%d') # 定位到 id="pl_top_realtimehot" 的div标签 div = response.xpath('//div[@id="pl_top_realtimehot"]') # 定位到div标签下的所有的tr标签 trs = div.xpath('./table/tbody/tr') for tr in trs[1:]: # 获取热搜的排名,第一个td标签 rank = tr.xpath('./td[1]/text()').extract_first() # 获取热搜的内容 content = tr.xpath('./td[@class="td-02"]/a/text()').extract_first() # 获取热搜的链接 link = 'https://s.weibo.com'+tr.xpath('./td[@class="td-02"]/a/@href').extract_first() # 获取热搜的热度 hot = tr.xpath('./td[@class="td-02"]/span/text()').extract_first() # 获取热搜的标签 tags = tr.xpath('./td[@class="td-03"]/i/text()').extract() item = ReSouItem() item['time'] = time item['rank'] = rank item['content'] = content item['link'] = link item['hot'] = hot item['tags'] = tags yield item yield scrapy.Request(url=link, callback=self.parse_detail, meta={'item': item,'page': 1}) pass |
然后将爬取的内容通过scrapy的管道文件存储到该路径下dataset/ reshou.csv文件和dataset/weibo.csv中,
|
def open_spider(self, spider): if not os.path.exists('dataset'): os.mkdir('dataset') if not os.path.exists('dataset/reshou.csv'): reshous = pd.DataFrame(columns=['time', 'rank', 'content', 'link', 'hot', 'tags']) reshous.to_csv('dataset/reshou.csv', index=False, encoding='utf-8') if not os.path.exists('dataset/weibo.csv'): weibos = pd.DataFrame(columns=['topic', 'nickname', 'content', 'share', 'comment', 'like']) weibos.to_csv('dataset/weibo.csv', index=False, encoding='utf-8') |
-
-
- 将数据写入到MySQL中
-
系统使用MySQL对数据进行保存和处理,获取的数据需要上传到MySQL中,部分代码如下。
|
import pandas as pd import os import pymysql from sqlalchemy import create_engine mysql_config = { 'host': 'localhost', 'user': 'root', # 改为正确的用户名以及密码 'password': 'root', 'database': 'hz_project_webo', 'port': 3306 } conn = pymysql.connect(**mysql_config) cursor = conn.cursor() engine = create_engine(f"mysql+pymysql://{mysql_config['user']}:{mysql_config['password']}@{mysql_config['host']}:{mysql_config['port']}/{mysql_config['database']}") create_tables_sql = """ CREATE TABLE IF NOT EXISTS topic_count ( id INT AUTO_INCREMENT PRIMARY KEY, topic VARCHAR(255), count INT ); CREATE TABLE IF NOT EXISTS nickname_count ( id INT AUTO_INCREMENT PRIMARY KEY, nickname VARCHAR(255), count INT ); CREATE TABLE IF NOT EXISTS topic_sum ( id INT AUTO_INCREMENT PRIMARY KEY, topic VARCHAR(255), share INT, comment INT, `like` INT ); CREATE TABLE IF NOT EXISTS topic_avg ( id INT AUTO_INCREMENT PRIMARY KEY, topic VARCHAR(255), share FLOAT, comment FLOAT, `like` FLOAT ); CREATE TABLE IF NOT EXISTS topic_max ( id INT AUTO_INCREMENT PRIMARY KEY, topic VARCHAR(255), share INT, comment INT, `like` INT ); CREATE TABLE IF NOT EXISTS topic_min ( id INT AUTO_INCREMENT PRIMARY KEY, topic VARCHAR(255), share INT, comment INT, `like` INT ); CREATE TABLE IF NOT EXISTS weibo ( id INT AUTO_INCREMENT PRIMARY KEY, topic VARCHAR(255), nickname VARCHAR(255), content TEXT, share INT, comment INT, `like` INT, tag VARCHAR(255), score FLOAT ); CREATE TABLE IF NOT EXISTS reshou ( id INT AUTO_INCREMENT PRIMARY KEY, time DATETIME, `rank` INT, content TEXT, link VARCHAR(255), hot INT, tags VARCHAR(255), bili FLOAT ); """ with conn.cursor() as cursor: for statement in create_tables_sql.split(';'): if statement.strip(): cursor.execute(statement) conn.commit() weibo = pd.read_csv('./dataset/weibo.csv') reshou = pd.read_csv('./dataset/reshou.csv') import re # 去掉中文 def remove_chinese(text): rex = re.compile(r'[\u4e00-\u9fa5]') return rex.sub('', text) # 去掉特殊字符,空格,单引号,双引号,中括号,大括号,小括号 def remove_special_character(text): rex = re.compile(r'[\s\'\"\[\]\{\}\(\)\【\】\n\r\t]') return rex.sub('', text) # 去掉假的转义字符 def remove_escape_character(text): rex = text.replace(r'\n', '').replace('\\u3000', '') rex = rex.replace(r'\u200b', '') return rex # 处理tags reshou['tags'] = reshou['tags'].apply(remove_special_character) # 处理hot reshou['hot'] = reshou['hot'].apply(remove_special_character) reshou['hot'] = reshou['hot'].apply(remove_chinese) # 处理content weibo['content'] = weibo['content'].apply(remove_special_character) weibo['content'] = weibo['content'].apply(remove_escape_character) # 将英文标点转换为中文标点 weibo['content'] = weibo['content'].str.replace(r'!', '!') weibo['content'] = weibo['content'].str.replace(r'?', '?') weibo['content'] = weibo['content'].str.replace(r',', ',') weibo['content'] = weibo['content'].str.replace(r';', ';') weibo['content'] = weibo['content'].str.replace(r':', ':') weibo['content'] = weibo['content'].str.replace(r'~', '~') weibo['content'] = weibo['content'].str.replace(r'`', '·') # 替换所有的空值为0 weibo = weibo.fillna(0) # 保存数据 weibo['share'] = weibo['share'].astype(int) weibo['comment'] = weibo['comment'].astype(int) weibo['like'] = weibo['like'].astype(int) weibo['tag'] = None weibo['score'] = None reshou['bili'] = None topic_count = weibo['topic'].value_counts().reset_index() topic_count.columns = ['topic', 'count'] nickname_count = weibo['nickname'].value_counts().reset_index() nickname_count.columns = ['nickname', 'count'] topic_sum = weibo.groupby('topic').agg({ 'share': 'sum', 'comment': 'sum', 'like': 'sum' }).reset_index() topic_avg = weibo.groupby('topic').agg({ 'share': 'mean', 'comment': 'mean', 'like': 'mean' }).reset_index() topic_max = weibo.groupby('topic').agg({ 'share': 'max', 'comment': 'max', 'like': 'max' }).reset_index() topic_min = weibo.groupby('topic').agg({ 'share': 'min', 'comment': 'min', 'like': 'min' }).reset_index() # 只为原始数据表添加id列 weibo = weibo.reset_index(drop=True) weibo.insert(0, 'id', range(1, len(weibo) + 1)) reshou = reshou.reset_index(drop=True) reshou.insert(0, 'id', range(1, len(reshou) + 1)) try: # 统计表使用数据库自动生成的id topic_count.to_sql('topic_count', engine, if_exists='replace', index=True, index_label='id') print("已写入topic_count表") nickname_count.to_sql('nickname_count', engine, if_exists='replace', index=True, index_label='id') print("已写入nickname_count表") topic_sum.to_sql('topic_sum', engine, if_exists='replace', index=True, index_label='id') print("已写入topic_sum表") topic_avg.to_sql('topic_avg', engine, if_exists='replace', index=True, index_label='id') print("已写入topic_avg表") topic_max.to_sql('topic_max', engine, if_exists='replace', index=True, index_label='id') print("已写入topic_max表") topic_min.to_sql('topic_min', engine, if_exists='replace', index=True, index_label='id') print("已写入topic_min表") # 原始数据表保留手动添加的id列 weibo.to_sql('weibo', engine, if_exists='replace', index=False) print("已写入weibo表") reshou.to_sql('reshou', engine, if_exists='replace', index=False) print("已写入reshou表") except Exception as e: print(f"写入数据库时发生错误: {str(e)}") finally: conn.close() print("数据库连接已关闭") |
5.3 首页功能实现
通过以上步骤完成了数据的爬取和存储,接下来就是系统可视化页面展示阶段了。系统前台页面通过vue框架结合element-ui等插件实现,采用了Django web框架,后台使用python进行代码的书写。在用户输入网址后进入系统首页系统的首页需要展示的内容是最多的,如下图是首页信息展示流程图,首页在展示数据之前肯定是需要先从数据库调取相应的数据,经过web服务器的解析,然后进行展示,具体如下图5.2所示。
图5.3系统页面数据访问流程
用户进入本系统可查看系统主页信息,根据主页设计将主页分为上下两个部分,上部门主要就是放置了系统的名字,下部分分为6块,分别是热度排行榜区域,热搜榜展示区域等,具体如图。主页中的图标数据主要是通过Echart框架的功能,只需要创建对应的实体类变可以获取对应的展示信息。
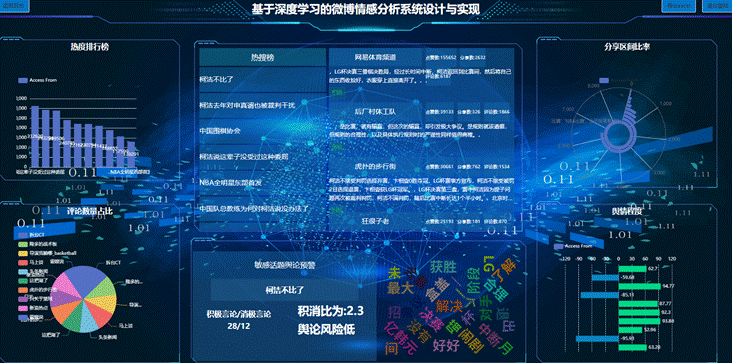 图5.4系统主界面图
图5.4系统主界面图
用户注册流程图和实现界面展示如图5.5所示。注册的本质是后台拿到前台的数据,如图所示用户注册流程图,游客可以通过系统注册功能成功系统用户,成为用户后可以进行在线购买商品等操作。注册需要用户填写相关的注册资料,其中用户名是全站唯一,在注册用户信息时候需要先对用户名进行一个校验,如果用户出现相同的则提示用户已存在,请勿重复注册。

图5.5用户注册界流程图与面图
用户要想进行查看主页等操作,必须登录系统。登录的操作是先获取到输入的用户名、密码,然后再和数据库中的用户表进行一一的比较,如果用户名和密码都存在与数据库,那么就可以登录成功,登录成功之后通过session把用户的信息进行保存,如果用户名或者密码错误,则登录失败并给出提示。用户登录流程图和实现界面展示如图5.6所示。

图5.6用户登录流程图与界面图
在预测栏中用户输入相应账户名信息,系统会分析该用户发布的微博和评论等信息,先确认其积极言论与消极言论的比值。这主要是使用了情感分析模型进行比对,获取的积极和消极言论,然后给出积消比,如果越靠近0,那么该账户的舆论风险越高,则管理部分就可以查看到了。

图5.7评论情感分析界面图
相关代码如下
|
def get(self, request): #topic topic = request.GET.get('topic') item = Weibo.objects.filter(topic=topic).order_by('-comment')[:10] yuce_list = [] #将content存入列表 content_list = [] for i in item: content_list.append(i.content) for i in content_list: # 加载模型 estimator = joblib.load('static\model\情感分析模型.pkl') transfer = joblib.load('static\model\情感分析转换器.pkl') stopwords = [line.strip() for line in open('static\model\stopwords.txt', encoding='utf-8').readlines()] …. if y_predict[0] == 0: print('负面,概率为:', round(y_predict_proba[0][0] * 100, 2), '%') dict_yuce['name'] = '消极' …. |
5.6本章小结
本章主要介绍了项目开发的MTV模式,然后着手代码的书写,介绍了系统的具体实现的一些功能,包括数据的爬取与储存,主页的实现,舆情预计分析等。
6.1 系统测试目的
系统由于是个人开发的,开发过程中当然避免不了出现各类的问题,包括个人代码的问题以及兼容性等问题。正是在这样的背景下,需要进行测试,测试包括兼容性测试和典型测试用例的功能性测试两类。
6.2 系统兼容性测试
浏览器兼容性问题:随着ES6标准的制定,目前主流的浏览器都是符合ES6标准的,尤其是以谷歌为核心的内核,然后IE浏览器的早期版本使用的是微软自己的内容,对信息的兼容性产生影响。测试结果表明,目前的主要浏览器包括谷歌,IE,360,火狐浏览器最近的版本的运行都是没有问题的,状态良好,就是使用IE的早期版本有会有图片展示问题,通过对代码的修改,进行了改善,所以总的来说浏览器兼容性是没有问题的。其它兼容性问题:具体的比如Django框架版本的使用上需要使用2.0.13以上的版本,mysql需要安装5.5版本,python需要使用3.8版本等。
6.3 功能性测试
通过对系统的管理员和注册用户的具体操作进行典型的测试用例,测试主要的功能是否都能够正常使用。具体如下表
表6.1登录测试
|
用例名 |
登录测试 |
|
目的 |
测试登录功能 |
|
前提 |
未登录的情况下 |
|
测试流程 |
1) 进入登录页面 2) 输入用户名和密码 3)提交 |
|
测试结果 |
1)当密码或者用户名错误的时候,提示用户名或者密码错误,页面不跳转; 2)当密码或者用户名都正确的时候,页面跳转到主页面; |
|
是否符合预期 |
是 |
表6.2舆情预警测试用例
|
用例名 |
舆情预警测试用例 |
|
目的 |
测试舆情预警功能 |
|
前提 |
用户登录系统 |
|
测试流程 |
在舆情预警栏中填写微博账户名 |
|
测试结果 |
1)当该用户言论积消比较高的时候,预测结果显示舆情风险低; 2)当该用户言论积消比较低的时候,预测结果显示舆情风险高; |
|
是否符合预期 |
是 |
表6.3数据爬取测试用例
|
用例名 |
数据爬取测试用例 |
|
目的 |
测试数据爬取信息功能 |
|
前提 |
爬虫文件书写完成 |
|
测试流程 |
运行爬虫程序 |
|
测试结果 |
爬取的文本信息,存储到dataset目录下对应的csv文件中 |
|
是否符合预期 |
是 |
6.4 本章小结
本章主要介绍了先对系统进行了兼容性的测试,然后在针对系统的主要功能进行了用例测试,测试结果表明,系统符合既定的功能需求目标。
结 论
在系统的开发中,前台主要使用的vue.js来开发页面。Vue如今非常的流行,这样更方便前台系统的维护和扩展。在后台的技术使用上,为伴随着人工智能的兴起,越来越多的人投入到python的学习当中,python语言结合Django框架,可以大幅度减少系统的配置,让开发者能够更多的把精力致力于系统逻辑上。
正是考虑到微博作为一款受欢迎的社交媒体平台,拥有大量的博文和用户评论信息。为了更好地利用这些信息,开发了一个基于深度学习的微博情感分析系统。考虑到微博是一个较大平台并且设定了反扒机制,所以采用了scrapy技术配置模拟浏览器进行数据的访问,然后通过xpath进行数据分析,最后通过panda保存到本地csv文件中,最后通过MySQL进行数据存储。最后由于本系统是一个web网站,所以也设定了注册和登录功能,python的web框架采用Django,Django的使用可以极大的增加系统开发的效率,方便对数据的保存和使用。
系统开发虽然结束,但是也是存在有一些问题的,比如在前台技术的使用上,用了vue脚手架和Echart联合开发,这样总体来说效率还是偏低的,主要是为了训练vue和echart的使用,因为现在也有BI大数据分析框架直接可以生产简单的数据分析图。另外,考虑到系统开发以训练为主,系统的主要功能还是相对简单的,未来可以进一步丰富。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)