机器学习算法探索:从优化BP神经网络到多种预测分类利器
差分进化算法优化BP神经网络,支持向量机SVM/SVR,最小二乘支持向量机LSSVM,极限学习机ELM,预测与分类。在机器学习的广袤领域中,我们时常在寻找更精准、高效的预测与分类模型。今天,就来聊聊差分进化算法优化BP神经网络,以及支持向量机SVM/SVR、最小二乘支持向量机LSSVM和极限学习机ELM这些有趣的算法。
差分进化算法优化BP神经网络,支持向量机SVM/SVR,最小二乘支持向量机LSSVM,极限学习机ELM,预测与分类。
在机器学习的广袤领域中,我们时常在寻找更精准、高效的预测与分类模型。今天,就来聊聊差分进化算法优化BP神经网络,以及支持向量机SVM/SVR、最小二乘支持向量机LSSVM和极限学习机ELM这些有趣的算法。
差分进化算法优化BP神经网络
BP神经网络是一种经典的多层前馈神经网络,广泛应用于各种预测和分类任务。然而,传统BP神经网络存在容易陷入局部最优的问题,这时候差分进化算法就派上用场啦。
BP神经网络基础
BP神经网络通过反向传播误差来调整网络权重,其核心步骤如下(以Python简单示例代码):
import numpy as np
# 定义激活函数 sigmoid
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 初始化网络参数
input_layer_size = 2
hidden_layer_size = 3
output_layer_size = 1
# 随机初始化权重
weights_ih = np.random.randn(hidden_layer_size, input_layer_size)
weights_ho = np.random.randn(output_layer_size, hidden_layer_size)
# 前向传播
def feed_forward(inputs):
hidden_layer = sigmoid(np.dot(weights_ih, inputs))
output_layer = sigmoid(np.dot(weights_ho, hidden_layer))
return output_layer
# 示例输入
input_vector = np.array([0.5, 0.3])
output = feed_forward(input_vector)
print(output)在这段代码中,我们定义了一个简单的包含输入层、隐藏层和输出层的BP神经网络。sigmoid函数作为激活函数,feed_forward函数实现了前向传播过程,通过矩阵乘法和激活函数的运算得到输出。
差分进化算法优化
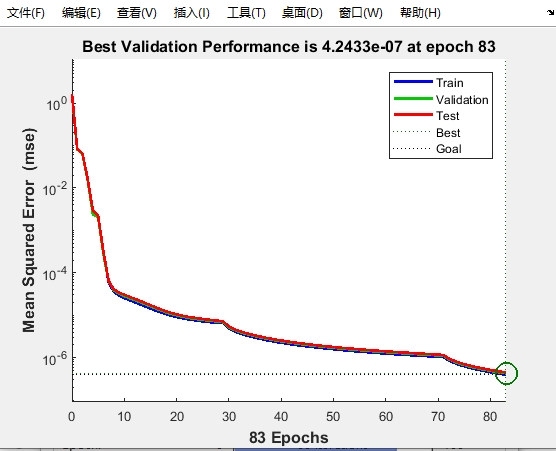
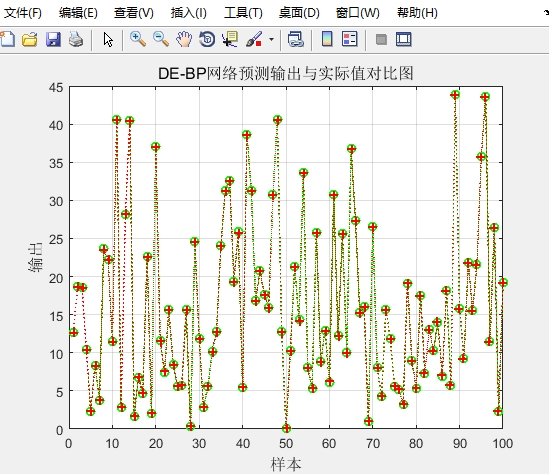
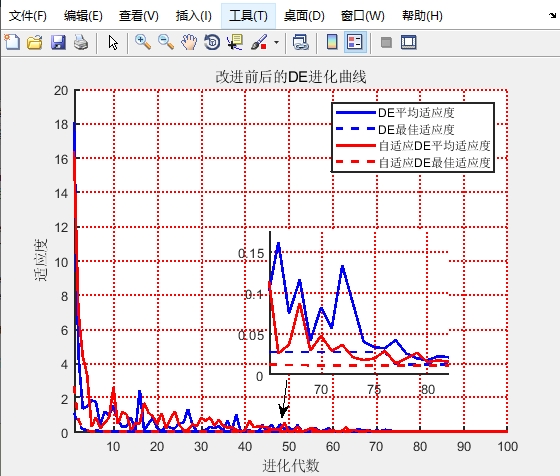
差分进化算法是一种基于群体的启发式优化算法。它通过对种群个体进行变异、交叉和选择操作,来寻找最优解。将其应用于BP神经网络,就是优化网络的权重,使得网络在训练过程中更容易跳出局部最优。
差分进化算法优化BP神经网络,支持向量机SVM/SVR,最小二乘支持向量机LSSVM,极限学习机ELM,预测与分类。
以下是简单示意如何利用差分进化算法优化BP神经网络权重(仅核心思路代码示意):
# 差分进化算法优化BP神经网络权重
# 定义种群大小,变异因子,交叉因子等参数
population_size = 50
mutation_factor = 0.5
crossover_rate = 0.7
# 定义适应度函数(比如均方误差)
def fitness(weights_flattened):
# 将一维权重向量还原为神经网络的权重矩阵
weights_ih = weights_flattened[:hidden_layer_size * input_layer_size].reshape((hidden_layer_size, input_layer_size))
weights_ho = weights_flattened[hidden_layer_size * input_layer_size:].reshape((output_layer_size, hidden_layer_size))
predicted = feed_forward(input_vector)
# 假设这里有真实值 target
target = np.array([0.8])
mse = np.mean((predicted - target) ** 2)
return -mse # 因为差分进化算法一般求最大化问题,这里取负号
# 初始化种群
population = np.random.randn(population_size, hidden_layer_size * input_layer_size + output_layer_size * hidden_layer_size)
for generation in range(100):
for i in range(population_size):
# 变异操作
a, b, c = np.random.choice([j for j in range(population_size) if j!= i], 3, replace=False)
mutant = population[a] + mutation_factor * (population[b] - population[c])
# 交叉操作
trial = np.where(np.random.rand(hidden_layer_size * input_layer_size + output_layer_size * hidden_layer_size) < crossover_rate, mutant, population[i])
# 选择操作
if fitness(trial) > fitness(population[i]):
population[i] = trial
# 得到优化后的权重
optimized_weights_flattened = population[np.argmax([fitness(p) for p in population])]
optimized_weights_ih = optimized_weights_flattened[:hidden_layer_size * input_layer_size].reshape((hidden_layer_size, input_layer_size))
optimized_weights_ho = optimized_weights_flattened[hidden_layer_size * input_layer_size:].reshape((output_layer_size, hidden_layer_size))这段代码中,我们定义了差分进化算法的核心步骤。首先初始化一个种群,每个个体是神经网络权重的一维表示。在每一代中,对每个个体进行变异、交叉生成试验个体,通过适应度函数(这里用均方误差的相反数)比较,选择更优的个体进入下一代。最终得到优化后的权重。
支持向量机SVM/SVR
支持向量机(SVM)是一种强大的分类和回归工具。对于分类问题(SVM),它试图找到一个超平面,能够将不同类别的数据点尽可能分开,并且使间隔最大化。对于回归问题(SVR),它旨在找到一个函数,使得大部分数据点都在一个允许的误差范围内。
SVM简单代码示例(使用scikit - learn库)
from sklearn import svm
import numpy as np
# 生成一些示例数据
X = np.array([[1, 2], [2, 3], [3, 1], [4, 4], [5, 3]])
y = np.array([0, 0, 0, 1, 1])
# 创建SVM分类器
clf = svm.SVC(kernel='linear')
clf.fit(X, y)
# 预测新数据
new_data = np.array([[2, 2]])
prediction = clf.predict(new_data)
print(prediction)在这段代码中,我们使用scikit - learn库创建了一个线性核的SVM分类器。通过fit方法训练模型,然后使用predict方法对新数据进行预测。
SVR简单代码示例(同样使用scikit - learn库)
from sklearn.svm import SVR
import numpy as np
# 生成示例数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 创建SVR模型
svr = SVR(kernel='linear')
svr.fit(X, y)
# 预测新数据
new_X = np.array([[6]])
prediction = svr.predict(new_X)
print(prediction)这里我们构建了一个线性核的SVR模型用于回归任务,训练数据后对新数据进行预测。
最小二乘支持向量机LSSVM
最小二乘支持向量机(LSSVM)是SVM的一种变体,它将SVM中的不等式约束转化为等式约束,通过求解线性方程组来得到模型参数,计算速度更快。
LSSVM简单实现(以Python代码简单示意,非完整库实现)
import numpy as np
# 定义核函数(这里以线性核为例)
def linear_kernel(X1, X2):
return np.dot(X1, X2.T)
# LSSVM训练函数
def lssvm_train(X, y, gamma, sigma):
n = X.shape[0]
K = linear_kernel(X, X)
H = np.diag(y) @ K @ np.diag(y)
I = np.eye(n)
alpha = np.linalg.inv(H + (1 / gamma) * I) @ y
return alpha
# LSSVM预测函数
def lssvm_predict(X_test, X_train, y_train, alpha, sigma):
K = linear_kernel(X_test, X_train)
y_pred = np.sign(K @ (np.diag(y_train) @ alpha))
return y_pred
# 示例数据
X_train = np.array([[1, 2], [2, 3], [3, 1]])
y_train = np.array([-1, -1, 1])
X_test = np.array([[2, 2]])
alpha = lssvm_train(X_train, y_train, gamma=10, sigma=1)
prediction = lssvm_predict(X_test, X_train, y_train, alpha, sigma=1)
print(prediction)在这段代码中,我们实现了简单的LSSVM训练和预测过程。通过定义线性核函数,然后在训练函数中求解线性方程组得到系数alpha,最后在预测函数中利用核函数和alpha进行预测。
极限学习机ELM
极限学习机(ELM)是一种单隐层前馈神经网络的快速学习算法。它随机生成输入层到隐藏层的权重和隐藏层的偏置,只需要计算隐藏层到输出层的权重,大大减少了训练时间。
ELM简单代码示例
import numpy as np
# 定义激活函数(比如ReLU)
def relu(x):
return np.maximum(0, x)
# ELM训练函数
def elm_train(X, y, hidden_size):
input_size = X.shape[1]
# 随机生成输入层到隐藏层的权重和隐藏层偏置
weights_ih = np.random.randn(hidden_size, input_size)
biases_h = np.random.randn(hidden_size, 1)
hidden_layer = relu(np.dot(weights_ih, X.T) + biases_h)
# 计算隐藏层到输出层的权重
weights_ho = np.linalg.pinv(hidden_layer) @ y.T
return weights_ih, biases_h, weights_ho
# ELM预测函数
def elm_predict(X, weights_ih, biases_h, weights_ho):
hidden_layer = relu(np.dot(weights_ih, X.T) + biases_h)
output = np.dot(weights_ho.T, hidden_layer)
return output
# 示例数据
X_train = np.array([[1, 2], [2, 3], [3, 1]])
y_train = np.array([0, 0, 1])
X_test = np.array([[2, 2]])
weights_ih, biases_h, weights_ho = elm_train(X_train, y_train, hidden_size=5)
prediction = elm_predict(X_test, weights_ih, biases_h, weights_ho)
print(prediction)这段代码展示了ELM的训练和预测过程。在训练时,随机生成输入到隐藏层的参数,然后计算隐藏层到输出层的权重。预测时,通过前向传播得到输出。
这些算法各有千秋,在不同的预测与分类场景中都能发挥独特的作用。无论是优化BP神经网络以提升性能,还是根据具体问题选择合适的SVM、LSSVM或ELM,都为我们在机器学习的道路上提供了更多的选择和可能。希望大家在实践中多多尝试,挖掘它们的潜力。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)