麻雀算法优化核极限学习机:回归与分类预测的强大武器
SSA_KELM 麻雀算法优化核极限学习机回归预测算法以及分类预测算法麻雀算法 优化 哈里斯鹰优化 粒子群优化 海鸥优化,黏菌优化,狼群优化,阿基米德算法优化,秃鹰搜索优化 核极限学习机回归算法分类算法matlab代码。可代做在机器学习领域,优化算法和预测模型的结合总是能带来意想不到的惊喜。今天咱们就来唠唠 SSA_KELM,也就是麻雀算法优化核极限学习机,它在回归预测算法以及分类预测算法中都有着
SSA_KELM 麻雀算法优化核极限学习机回归预测算法以及分类预测算法 麻雀算法 优化 哈里斯鹰优化 粒子群优化 海鸥优化,黏菌优化,狼群优化,阿基米德算法优化,秃鹰搜索优化 核极限学习机 回归算法 分类算法 matlab代码。 可代做
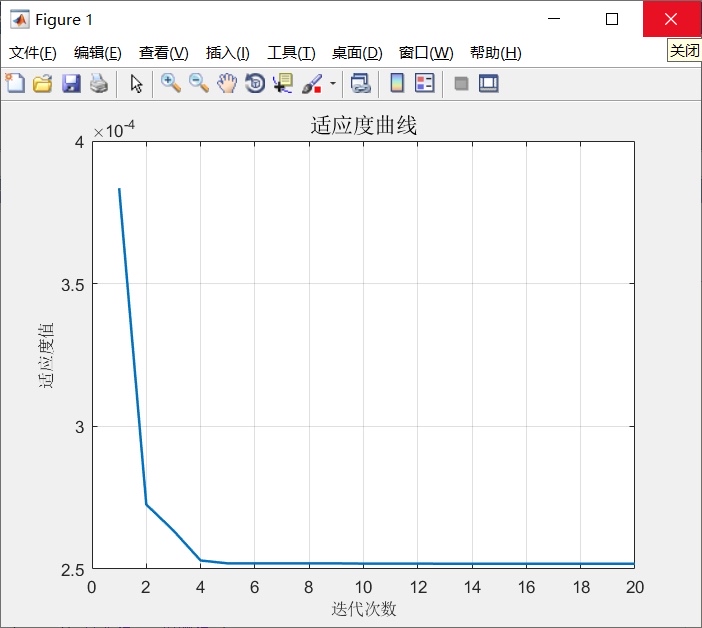
在机器学习领域,优化算法和预测模型的结合总是能带来意想不到的惊喜。今天咱们就来唠唠 SSA_KELM,也就是麻雀算法优化核极限学习机,它在回归预测算法以及分类预测算法中都有着出色表现。
麻雀算法及各类优化算法的魅力
麻雀算法(SSA)是一种受麻雀觅食行为启发的智能优化算法。想象一下,一群麻雀在觅食,它们会不断地寻找食物多且安全的地方。这个过程中,有些麻雀负责侦查,有些跟着大部队。这种行为通过数学模型抽象出来,就成了麻雀算法,在寻找最优解的过程中发挥着独特作用。

SSA_KELM 麻雀算法优化核极限学习机回归预测算法以及分类预测算法 麻雀算法 优化 哈里斯鹰优化 粒子群优化 海鸥优化,黏菌优化,狼群优化,阿基米德算法优化,秃鹰搜索优化 核极限学习机 回归算法 分类算法 matlab代码。 可代做
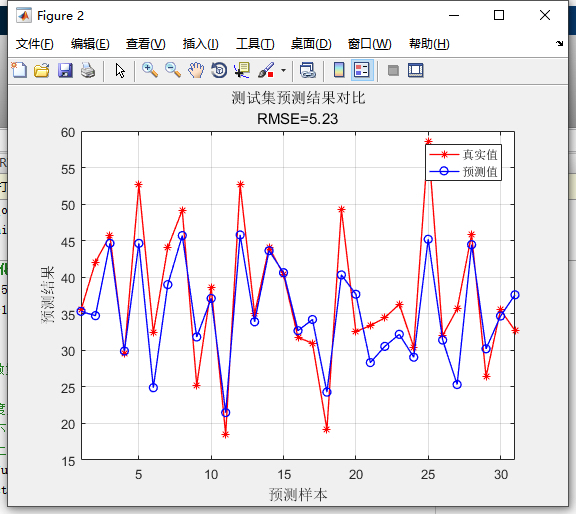
与它类似的还有哈里斯鹰优化、粒子群优化、海鸥优化、黏菌优化、狼群优化、阿基米德算法优化、秃鹰搜索优化等算法。这些算法各有千秋,它们从不同的自然现象或生物行为中获取灵感,比如粒子群优化就像一群鸟在空间中寻找食物,每只鸟根据自己和同伴的经验调整飞行方向,以此来寻找最优解。
核极限学习机
核极限学习机(KELM)是极限学习机(ELM)的一种改进,它引入了核函数,使得ELM能够处理非线性问题。传统的神经网络在训练时,需要反复调整权重,计算量巨大且耗时。而ELM在训练单隐层前馈神经网络时,随机生成输入层到隐含层的权重和隐含层的偏置,只需要计算输出权重,大大提高了训练速度。KELM在此基础上,利用核函数将低维空间映射到高维空间,从而更好地处理复杂的非线性关系。
SSA_KELM 回归与分类预测算法
- 回归算法:在回归问题中,比如预测房价、股票价格等连续性数值。SSA_KELM通过麻雀算法优化KELM的参数,让模型能够更精准地拟合数据的变化趋势。
- 分类算法:对于分类任务,像是图像分类、疾病诊断分类等,SSA_KELM能优化KELM的决策边界,提高分类的准确率。
Matlab代码示例与分析
下面咱们来看一段简单的Matlab代码示例,以SSA优化KELM的回归算法为例:
% 加载数据
load data.mat; % 假设data.mat中包含训练数据X和对应的标签Y
% 初始化参数
hidden_neurons = 50; % 隐含层神经元数量
kernel_type = 'rbf'; % 核函数类型,这里用径向基函数
sigma = 2; % 核函数参数
% 初始化麻雀算法参数
pop = 30; % 种群数量
Max_iter = 100; % 最大迭代次数
dim = 2; % 待优化参数维度,这里假设优化KELM的两个参数
lb = [0.1, 1]; % 下限
ub = [10, 100]; % 上限
% 执行麻雀算法优化KELM
[Best_score,Best_pos,SSA_curve]=SSA(@(x)KELM_train_test(x,X,Y,hidden_neurons,kernel_type,sigma),pop,dim,lb,ub,Max_iter);
% KELM_train_test函数实现
function [error]=KELM_train_test(x,X,Y,hidden_neurons,kernel_type,sigma)
% 假设x(1)是惩罚因子,x(2)是核函数参数的调整因子
C = x(1);
new_sigma = x(2)*sigma;
% 训练KELM模型
model = trainKELM(X,Y,hidden_neurons,kernel_type,new_sigma,C);
% 预测
Y_pred = predictKELM(model,X);
% 计算误差
error = mean((Y - Y_pred).^2);
end代码分析
- 数据加载:
load data.mat加载训练数据和对应的标签,这里假设数据存储在data.mat文件中。 - 参数初始化:设置了隐含层神经元数量
hiddenneurons、核函数类型kerneltype以及核函数参数sigma。同时初始化了麻雀算法的参数,包括种群数量pop、最大迭代次数Max_iter、待优化参数维度dim以及参数的上下限lb和ub。 - 执行优化:
[Bestscore,Bestpos,SSAcurve]=SSA(@(x)KELMtraintest(x,X,Y,hiddenneurons,kerneltype,sigma),pop,dim,lb,ub,Maxiter);这行代码调用麻雀算法SSA,对KELMtraintest函数进行优化。KELMtraintest函数根据传入的参数x(这里是待优化的KELM参数)来训练和测试KELM模型,并返回预测误差。 - KELMtraintest函数:函数接收参数
x,将其解析为惩罚因子C和核函数参数的调整因子,进而得到新的核函数参数newsigma。然后用这些参数训练KELM模型model = trainKELM(X,Y,hiddenneurons,kerneltype,newsigma,C);,并进行预测Ypred = predictKELM(model,X);,最后计算预测误差error = mean((Y - Ypred).^2);。
如果有小伙伴在实现过程中遇到困难,本人可代做相关项目,欢迎交流沟通。希望大家都能在这个有趣的算法领域中探索出自己的成果!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 38
38 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)