pytorch深度学习笔记20
本篇文章继续学习尚硅谷深度学习教程,学习内容是。
摘要
本篇文章继续学习尚硅谷深度学习教程,学习内容是
1.参数初始化和正则化
全连接层(nn.Linear)
在神经网络中,参数主要位于全连接层(仿射层Affine)中。
PyTorch提供了torch.nn模块,专门用于神经网络的构建和训练。其中全连接层被实现为Linear类,内部有两个属性:权重 weight和偏置bias;这就是神经网络的主要参数。
import torch.nn as nn
linear = nn.Linear(5, 2)上面代码定义了一个有5个输入神经元、2个输出神经元的全连接层。
常数初始化
所有权重参数初始化为一个常数。
import torch.nn as nn
linear = nn.Linear(5, 2)
# 全部参数初始化为0
nn.init.zeros_(linear.weight)
print(linear.weight)
# 全部参数初始化为1
nn.init.ones_(linear.weight)
print(linear.weight)
# 全部参数初始化为一个常数
nn.init.constant_(linear.weight, 10)
print(linear.weight)将权重初始值设为0将无法正确进行学习。严格地说,不能将权重初始值设成一样的值。因为这意味着反向传播时权重全部都会进行相同的更新,被更新为相同的值(对称的值)。这使得神经网络拥有许多不同的权重的意义丧失了。为了防止“权重均一化”(瓦解权重的对称结构),必须随机生成初始值。
秩初始化
权重参数初始化为单位矩阵。
import torch.nn as nn
linear = nn.Linear(5, 2)
# 参数初始化为单位矩阵
nn.init.eye_(linear.weight)
print(linear.weight)正态分布初始化
权重参数按指定均值与标准差正态分布初始化。
import torch.nn as nn
linear = nn.Linear(5, 2)
# 参数初始化为按指定均值与标准差正态分布
nn.init.normal_(linear.weight, mean=0.0, std=1.0)
print(linear.weight)均匀分布初始化
权重参数在指定区间内均匀分布初始化
import torch.nn as nn
linear = nn.Linear(5, 2)
# 参数初始化为在区间内均匀分布
nn.init.uniform_(linear.weight, a=0, b=10)
print(linear.weight)Xavier初始化(Glorot初始化)
Xavier初始化根据输入和输出的神经元数量调整权重的初始范围,确保每一层的输出方差与输入方差相近。适用于Sigmoid和Tanh等激活函数,能有效缓解梯度消失或爆炸问题。
Xavier正态分布初始化:均值为0,标准差为的正态分布
Xavier均匀分布初始化:区间[,
]内均匀分布
其中表示输入数,
表示输出数
import torch.nn as nn
linear = nn.Linear(5, 2)
# Xavier正态分布初始化
nn.init.xavier_normal_(linear.weight)
print(linear.weight)
# Xavier均匀分布初始化
nn.init.xavier_uniform_(linear.weight)
print(linear.weight)He初始化(Kaiming初始化)
He初始化根据输入的神经元数量调整权重的初始范围。
He正态分布初始化:均值为0,标准差为的正态分布。
He均匀分布初始化:区间[,
]内均匀分布。
其中表示输入数。
import torch.nn as nn
linear = nn.Linear(5, 2)
# Kaiming正态分布初始化
nn.init.kaiming_normal_(linear.weight)
print(linear.weight)
# Kaiming均匀分布初始化
nn.init.kaiming_uniform_(linear.weight)
print(linear.weight)Dropout随机失活
Dropout(随机失活,暂退法)是一种在学习的过程中随机关闭神经元的方法。
可以通过torch.nn.Dropout(p)来使用Dropout,并通过参数p来设置失活概率。
import torch
dropout = torch.nn.Dropout(p=0.5)
x = torch.randint(1, 10, (10,), dtype=torch.float32)
print("Dropout前:", x)
print("Dropout后:", dropout(x))2.搭建神经网络
自定义模型
在神经网络框架中,由多个层组成的组件称之为 模块(Module)。
在PyTorch中模型就是一个Module,各网络层、模块也是Module。Module是所有神经网络的基类。
在定义一个Module时,我们需要继承torch.nn.Module并主要实现两个方法:
- __init__:定义网络各层的结构,并初始化参数。
- forward:根据输入进行前向传播,并返回输出。计算其输出关于输入的梯度,可通过其反向传播函数进行访问(通常自动发生)。forward方法是每次调用的具体实现。
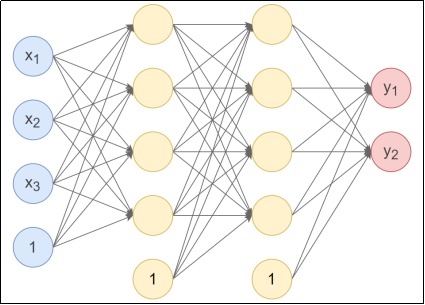
接下来使用PyTorch实现下图的神经网络:
第1个隐藏层:使用Xavier正态分布初始化权重,激活函数使用Tanh。
第2个隐藏层:使用He正态分布初始化权重,激活函数使用ReLU。
输出层:按默认方式初始化,激活函数使用Softmax。
import torch
import torch.nn as nn
class Model(nn.Module):
# 初始化
def __init__(self):
super(Model, self).__init__() # 调用父类初始化
self.linear1 = nn.Linear(3, 4) # 第1个隐藏层,3个输入,4个输出
nn.init.xavier_normal_(self.linear1.weight) # 初始化权重参数
self.linear2 = nn.Linear(4, 4) # 第2个隐藏层,4个输入,4个输出
nn.init.kaiming_normal_(self.linear2.weight) # 初始化权重参数
self.out = nn.Linear(4, 2) # 输出层,4个输入,2个输出,默认使用He均匀分布初始化
# 前向传播
def forward(self, x):
x = self.linear1(x) # 经过第1个隐藏层
x = torch.tanh(x) # 激活函数
x = self.linear2(x) # 经过第2个隐藏层
x = torch.relu(x) # 激活函数
x = self.out(x) # 经过输出层
x = torch.softmax(x, dim=1) # 激活函数
return x
model = Model()
output = model(torch.randn(10, 3))
print("输出:\n", output)
print()
# 使用named_parameters()查看各层参数
print("模型参数:")
for name, param in model.named_parameters():
print(name, param)
print()
# 使用state_dict()查看各层参数
print("模型参数:\n", model.state_dict())查看模型结构和参数数量
可使用torchsummary.summary来查看模型结构与参数数量。需要先安装torchsummary库:pip install torchsummary。
from torchsummary import summary
# input_size:特征数,batch_size:样本数
summary(model, input_size=(3,), batch_size=10, device="cpu")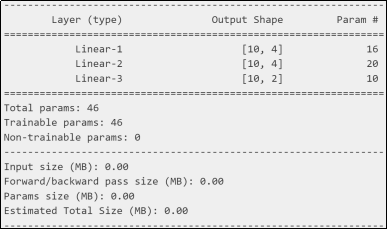
以第1个隐藏层为例:每个节点有3个权重与1个偏置,计4个参数,4个节点共计16个参数。
使用Sequential构建模型
可以通过torch.nn.Sequential来构建模型,将各层按顺序传入。
# 构建模型
model = nn.Sequential(
nn.Linear(3, 4),
nn.Tanh(),
nn.Linear(4, 4),
nn.ReLU(),
nn.Linear(4, 2),
nn.Softmax(dim=1),
)
# 初始化参数
def init_weights(m):
# 对Linear层进行初始化
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
model.apply(init_weights) # apply会遍历所有子模块并依次调用函数
output = model(torch.randn(10, 3))
print("输出:\n", output)Sequential类使模型构造变得简单,不必自定义类就可以组合新的架构。然而并不是所有的架构都是简单的顺序架构,当需要更强的灵活性时还是需要自定义模型。
3.损失函数
二分类任务损失函数
二分类任务常用二元交叉熵损失函数(Binary Cross-Entropy Loss)
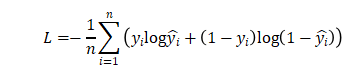
其中:
为真实值(通常为0或1)
为预测值(表示样本i为1的概率)
在PyTorch中可使用torch.nn.BCELoss实现:
import torch
import torch.nn as nn
# 真实值
target = torch.tensor([[1], [0], [0]], dtype=torch.float32)
# 预测值
input = torch.randn((3, 1))
prediction = torch.sigmoid(input)
# 实例化损失函数
loss = nn.BCELoss()
print(loss(prediction, target))多分类任务损失函数
多分类任务常用多类交叉熵损失函数(Categorical Cross-Entropy Loss)。它是对每个类别的预测概率与真实标签之间差异的加权平均。
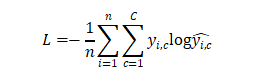
其中:
- C是类别数
为真实值(表示
为预测值(表示样本i为类别c的概率)
在PyTorch中可使用torch.nn.CrossEntropyLoss 实现:
import torch
import torch.nn as nn
# 真实值为标签
target = torch.tensor([1, 0, 3, 2, 5, 4]) # 真实值
input = torch.randn((6, 8)) # 预测值
loss = nn.CrossEntropyLoss() # 实例化损失函数
print(loss(input, target))
# 真实值为概率
target = torch.randn(6, 8).softmax(dim=1) # 真实值
input = torch.randn((6, 8)) # 预测值
loss = nn.CrossEntropyLoss() # 实例化损失函数
print(loss(input, target))注意:调用torch.nn.CrossEntropyLoss相当于调用了torch.nn.LogSoftmax之后再调用torch.nn.NLLLoss。即使用CrossEntropyLoss时上一层的输出不需要Softmax激活函数,因为该损失函数内会自动处理。
回归任务损失函数
MAE
平均绝对误差(Mean Absolute Error,MAE),也称L1 Loss:
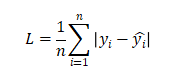
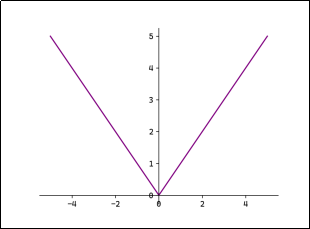
L1 Loss对异常值鲁棒,但在0点处不可导。
MSE
均方误差(Mean Squared Error ,MSE),也称L2 Loss:
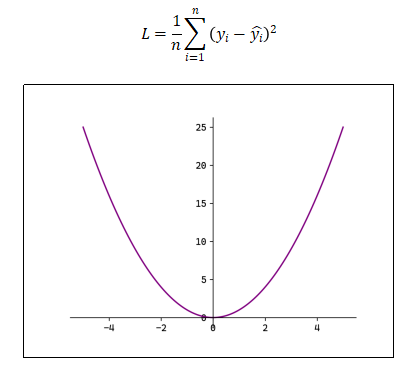
L2 Loss对异常值敏感,遇到异常值时易发生梯度爆炸。
Smooth L1
平滑L1:
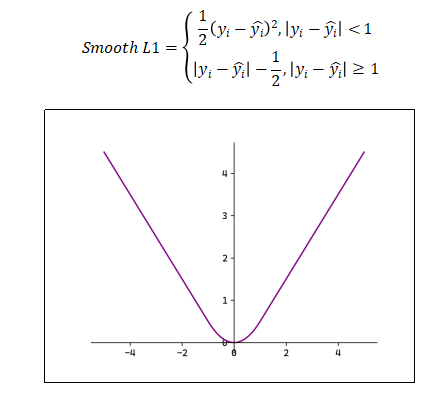
当误差较小时()使用L2 Loss,使得损失函数平滑可导。当误差较大时(
)使用L1 Loss降低异常值的影响。
mport torch
from torch import nn, optim
class Model(nn.Module):
# 初始化
def __init__(self):
# 调用父类初始化
super(Model, self).__init__()
# 全连接层
self.linear1 = nn.Linear(5, 3)
# 初始化权重
self.linear1.weight.data = torch.tensor(
[
[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6],
[0.7, 0.8, 0.9],
[0.10, 1.1, 1.2],
[1.3, 1.4, 1.5],
]
).T
# 初始化偏置
self.linear1.bias.data = torch.tensor([1.0, 2.0, 3.0])
# 前向传播
def forward(self, x):
x = self.linear1(x)
return x
# 实例化模型
model = Model()
# 输入值
X = torch.tensor([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]], dtype=torch.float)
# 目标值
target = torch.tensor([[0, 0, 0], [0, 0, 0]], dtype=torch.float)
# 计算出输出值
output = model(X)
# 损失函数
loss = nn.MSELoss()
# 反向传播
loss(output, target).backward()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=1)
# 更新参数
optimizer.step()
# 清空梯度
optimizer.zero_grad()
# 打印参数
for i in model.state_dict():
print(i)
print(model.state_dict()[i])
print()4.参数更新方法
Momentum
原始的梯度下降法直接使用当前梯度来更新参数: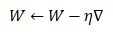
而Momentum(动量法)会保存历史梯度并给予一定的权重,使其也参与到参数更新中:
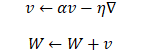
:历史(负)梯度的加权和
:历史梯度的权重
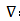 :当前梯度,即
:当前梯度,即:学习率
可以通过torch.optim.SGD() 并设置momentum历史梯度权重参数来使用动量法。
以寻找的最小值为例
import torch
import numpy as np
import matplotlib.pyplot as plt
def gradient_descent(X, optimizer, n_iters):
X_arr = X.detach().numpy().copy() # 拷贝,用于记录优化过程
for epoch in range(n_iters):
y = X**2 @ w
y.backward() # 反向传播
optimizer.step() # 更新参数
optimizer.zero_grad() # 清空梯度
X_arr = np.vstack([X_arr, X.detach().numpy()]) # 记录优化过程
return X_arr
# 从(-7, 2)出发
X = torch.tensor([-7, 2], dtype=torch.float32, requires_grad=True)
w = torch.tensor([[0.05], [1.0]], requires_grad=True)
lr = 1e-2 # 学习率
n_iters = 500 # 迭代次数
# 普通梯度下降
X_clone = X.clone().detach().requires_grad_(True)
X_arr1 = gradient_descent(X_clone, torch.optim.SGD([X_clone], lr=lr), n_iters=n_iters)
plt.plot(X_arr1[:, 0], X_arr1[:, 1], "r")
# 动量法
X_clone = X.clone().detach().requires_grad_(True)
X_arr2 = gradient_descent(X_clone, torch.optim.SGD([X_clone], lr=lr, momentum=0.9), n_iters=n_iters)
plt.plot(X_arr2[:, 0], X_arr2[:, 1], "b")
# 绘制等高线图
x1_grid, x2_grid = np.meshgrid(np.linspace(-7, 7, 100), np.linspace(-2, 2, 100))
y_grid = w.detach().numpy()[0, 0] * x1_grid**2 + w.detach().numpy()[1, 0] * x2_grid**2
plt.contour(x1_grid, x2_grid, y_grid, levels=30, colors="gray")
plt.legend(["SGD", "Momentum"])
plt.show()学习率衰减
等间隔衰减
可以通过torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma)来实现学习率的等间隔衰减。
- optimizer:要实现学习率衰减的优化器
- step_size:间隔
- gamma:衰减的比例
例如,使学习率每隔20 epoch衰减为之前的0.7:
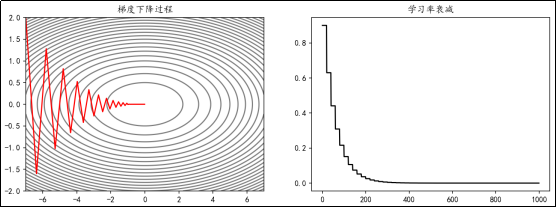
import torch
import numpy as np
import matplotlib.pyplot as plt
# 从(-7, 2)出发
X = torch.tensor([-7, 2], dtype=torch.float32, requires_grad=True)
w = torch.tensor([[0.05], [1.0]], requires_grad=True)
lr = 0.9 # 初始学习率
n_iters = 1000 # 迭代次数
optimizer = torch.optim.SGD([X], lr=lr)
scheduler_lr = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.7) # 学习率衰减
X_arr = X.detach().numpy().copy() # 拷贝,用于记录优化过程
lr_list = [] # 记录学习率变化
for epoch in range(n_iters):
y = X**2 @ w
y.backward() # 反向传播
optimizer.step() # 更新参数
optimizer.zero_grad() # 清空梯度
X_arr = np.vstack([X_arr, X.detach().numpy()]) # 记录优化过程
lr_list.append(optimizer.param_groups[0]["lr"]) # 记录学习率变化
scheduler_lr.step() # 学习率衰减
plt.rcParams["font.sans-serif"] = ["KaiTi"]
plt.rcParams["axes.unicode_minus"] = False
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
x1_grid, x2_grid = np.meshgrid(np.linspace(-7, 7, 100), np.linspace(-2, 2, 100))
y_grid = w.detach().numpy()[0, 0] * x1_grid**2 + w.detach().numpy()[1, 0] * x2_grid**2
ax[0].contour(x1_grid, x2_grid, y_grid, levels=30, colors="gray")
ax[0].plot(X_arr[:, 0], X_arr[:, 1], "r")
ax[0].set_title("梯度下降过程")
ax[1].plot(lr_list, "k")
ax[1].set_title("学习率衰减")
plt.show()指定间隔衰减
可以通过torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma)来实现学习率的指定间隔衰减。
- optimizer:要实现学习率衰减的优化器
- milestones:指定衰减的间隔
- gamma:衰减的比例
例如,使学习率在epoch达到[10,50,200]时衰减为之前的0.7:
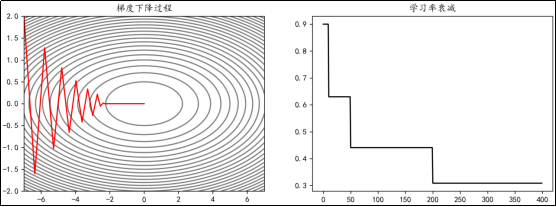
import torch
import numpy as np
import matplotlib.pyplot as plt
# 从(-7, 2)出发
X = torch.tensor([-7, 2], dtype=torch.float32, requires_grad=True)
w = torch.tensor([[0.05], [1.0]], requires_grad=True)
lr = 0.9 # 初始学习率
n_iters = 400 # 迭代次数
optimizer = torch.optim.SGD([X], lr=lr)
scheduler_lr = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[10, 50, 200], gamma=0.7) # 学习率衰减
X_arr = X.detach().numpy().copy() # 拷贝,用于记录优化过程
lr_list = [] # 记录学习率变化
for epoch in range(n_iters):
y = X**2 @ w
y.backward() # 反向传播
optimizer.step() # 更新参数
optimizer.zero_grad() # 清空梯度
X_arr = np.vstack([X_arr, X.detach().numpy()]) # 记录优化过程
lr_list.append(optimizer.param_groups[0]["lr"]) # 记录学习率变化
scheduler_lr.step() # 学习率衰减
plt.rcParams["font.sans-serif"] = ["KaiTi"]
plt.rcParams["axes.unicode_minus"] = False
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
x1_grid, x2_grid = np.meshgrid(np.linspace(-7, 7, 100), np.linspace(-2, 2, 100))
y_grid = w.detach().numpy()[0, 0] * x1_grid**2 + w.detach().numpy()[1, 0] * x2_grid**2
ax[0].contour(x1_grid, x2_grid, y_grid, levels=30, colors="gray")
ax[0].plot(X_arr[:, 0], X_arr[:, 1], "r")
ax[0].set_title("梯度下降过程")
ax[1].plot(lr_list, "k")
ax[1].set_title("学习率衰减")
plt.show()指数衰减
可以通过torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma)来实现学习率的指数衰减。
- optimizer:要实现学习率衰减的优化器
- gamma:底数,学习率<=学习率
例如,使学习率以0.99为底数,epoch为指数衰减:
import torch
import numpy as np
import matplotlib.pyplot as plt
# 从(-7, 2)出发
X = torch.tensor([-7, 2], dtype=torch.float32, requires_grad=True)
w = torch.tensor([[0.05], [1.0]], requires_grad=True)
lr = 0.9 # 初始学习率
n_iters = 400 # 迭代次数
optimizer = torch.optim.SGD([X], lr=lr)
scheduler_lr = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.99) # 学习率衰减
X_arr = X.detach().numpy().copy() # 拷贝,用于记录优化过程
lr_list = [] # 记录学习率变化
for epoch in range(n_iters):
y = X**2 @ w
y.backward() # 反向传播
optimizer.step() # 更新参数
optimizer.zero_grad() # 清空梯度
X_arr = np.vstack([X_arr, X.detach().numpy()]) # 记录优化过程
lr_list.append(optimizer.param_groups[0]["lr"]) # 记录学习率变化
scheduler_lr.step() # 学习率衰减
plt.rcParams["font.sans-serif"] = ["KaiTi"]
plt.rcParams["axes.unicode_minus"] = False
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
x1_grid, x2_grid = np.meshgrid(np.linspace(-7, 7, 100), np.linspace(-2, 2, 100))
y_grid = w.detach().numpy()[0, 0] * x1_grid**2 + w.detach().numpy()[1, 0] * x2_grid**2
ax[0].contour(x1_grid, x2_grid, y_grid, levels=30, colors="gray")
ax[0].plot(X_arr[:, 0], X_arr[:, 1], "r")
ax[0].set_title("梯度下降过程")
ax[1].plot(lr_list, "k")
ax[1].set_title("学习率衰减")
plt.show()

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)