matlab的基于遗传算法优化bp神经网络多输入多输出预测模型,有代码和EXCEL数据参考,精...
matlab的基于遗传算法优化bp神经网络多输入多输出预测模型,有代码和EXCEL数据参考,精度还可以,直接运行即可,换数据OK。这个程序是一个基于遗传算法优化的BP神经网络多输入两输出模型。下面我将对程序进行详细分析。首先,程序读取了一个名为“数据.xlsx”的Excel文件,其中包含了输入数据和输出数据。输入数据存储在名为“input”的矩阵中,输出数据存储在名为“output”的矩阵中。接下
matlab的基于遗传算法优化bp神经网络多输入多输出预测模型,有代码和EXCEL数据参考,精度还可以,直接运行即可,换数据OK。 这个程序是一个基于遗传算法优化的BP神经网络多输入两输出模型。下面我将对程序进行详细分析。 首先,程序读取了一个名为“数据.xlsx”的Excel文件,其中包含了输入数据和输出数据。输入数据存储在名为“input”的矩阵中,输出数据存储在名为“output”的矩阵中。 接下来,程序设置了训练数据和预测数据。训练数据包括前1900个样本,存储在名为“input_train”和“output_train”的矩阵中。预测数据包括剩余的样本,存储在名为“input_test”和“output_test”的矩阵中。 然后,程序对输入数据进行了归一化处理,将其归一化到[-1,1]的范围内。归一化后的数据存储在名为“inputn”和“outputn”的矩阵中,归一化的参数存储在名为“inputps”和“outputps”的结构体中。 接下来,程序定义了神经网络的节点个数。输入层节点个数为输入数据的列数,隐含层节点个数为10,输出层节点个数为输出数据的列数。 然后,程序构建了一个BP神经网络模型。模型使用了tansig和purelin两个传递函数,采用梯度下降法进行训练。网络的训练参数包括训练次数、学习速率、训练目标最小误差、显示频率、动量因子、最小性能梯度和最高失败次数。 接下来,程序使用遗传算法求解最佳参数。遗传算法的参数包括进化代数、种群规模、交叉概率和变异概率。程序首先初始化一个种群,然后进行进化操作,包括选择、交叉和变异。每一代种群中的染色体根据其适应度值进行排序,然后根据轮盘赌法选择新个体。选择后的种群经过交叉和变异操作得到下一代种群。最后,程序输出遗传算法的结果,包括适应度曲线和最佳个体的权值和阈值。 最后,程序使用优化后的BP神经网络进行训练和预测。训练数据经过归一化处理后,使用train函数进行训练。然后,程序对测试数据进行归一化处理,并使用sim函数进行预测。预测结果经过反归一化处理后,计算了预测误差,并绘制了预测结果的图形。 这个程序主要是用于解决多输入两输出的问题,应用在神经网络领域。它使用遗传算法优化了BP神经网络的参数,包括权值和阈值,以提高神经网络的性能。程序涉及到的知识点包括神经网络的构建、训练和预测,遗传算法的基本原理和操作。
一、模型整体架构与核心目标
本模型采用“遗传算法(GA)+BP神经网络”的混合架构,针对多输入两输出的预测场景,通过遗传算法优化BP神经网络的初始权值与阈值,解决传统BP神经网络易陷入局部最优、收敛速度慢的问题,最终实现更精准、稳定的双指标预测。
matlab的基于遗传算法优化bp神经网络多输入多输出预测模型,有代码和EXCEL数据参考,精度还可以,直接运行即可,换数据OK。 这个程序是一个基于遗传算法优化的BP神经网络多输入两输出模型。下面我将对程序进行详细分析。 首先,程序读取了一个名为“数据.xlsx”的Excel文件,其中包含了输入数据和输出数据。输入数据存储在名为“input”的矩阵中,输出数据存储在名为“output”的矩阵中。 接下来,程序设置了训练数据和预测数据。训练数据包括前1900个样本,存储在名为“input_train”和“output_train”的矩阵中。预测数据包括剩余的样本,存储在名为“input_test”和“output_test”的矩阵中。 然后,程序对输入数据进行了归一化处理,将其归一化到[-1,1]的范围内。归一化后的数据存储在名为“inputn”和“outputn”的矩阵中,归一化的参数存储在名为“inputps”和“outputps”的结构体中。 接下来,程序定义了神经网络的节点个数。输入层节点个数为输入数据的列数,隐含层节点个数为10,输出层节点个数为输出数据的列数。 然后,程序构建了一个BP神经网络模型。模型使用了tansig和purelin两个传递函数,采用梯度下降法进行训练。网络的训练参数包括训练次数、学习速率、训练目标最小误差、显示频率、动量因子、最小性能梯度和最高失败次数。 接下来,程序使用遗传算法求解最佳参数。遗传算法的参数包括进化代数、种群规模、交叉概率和变异概率。程序首先初始化一个种群,然后进行进化操作,包括选择、交叉和变异。每一代种群中的染色体根据其适应度值进行排序,然后根据轮盘赌法选择新个体。选择后的种群经过交叉和变异操作得到下一代种群。最后,程序输出遗传算法的结果,包括适应度曲线和最佳个体的权值和阈值。 最后,程序使用优化后的BP神经网络进行训练和预测。训练数据经过归一化处理后,使用train函数进行训练。然后,程序对测试数据进行归一化处理,并使用sim函数进行预测。预测结果经过反归一化处理后,计算了预测误差,并绘制了预测结果的图形。 这个程序主要是用于解决多输入两输出的问题,应用在神经网络领域。它使用遗传算法优化了BP神经网络的参数,包括权值和阈值,以提高神经网络的性能。程序涉及到的知识点包括神经网络的构建、训练和预测,遗传算法的基本原理和操作。
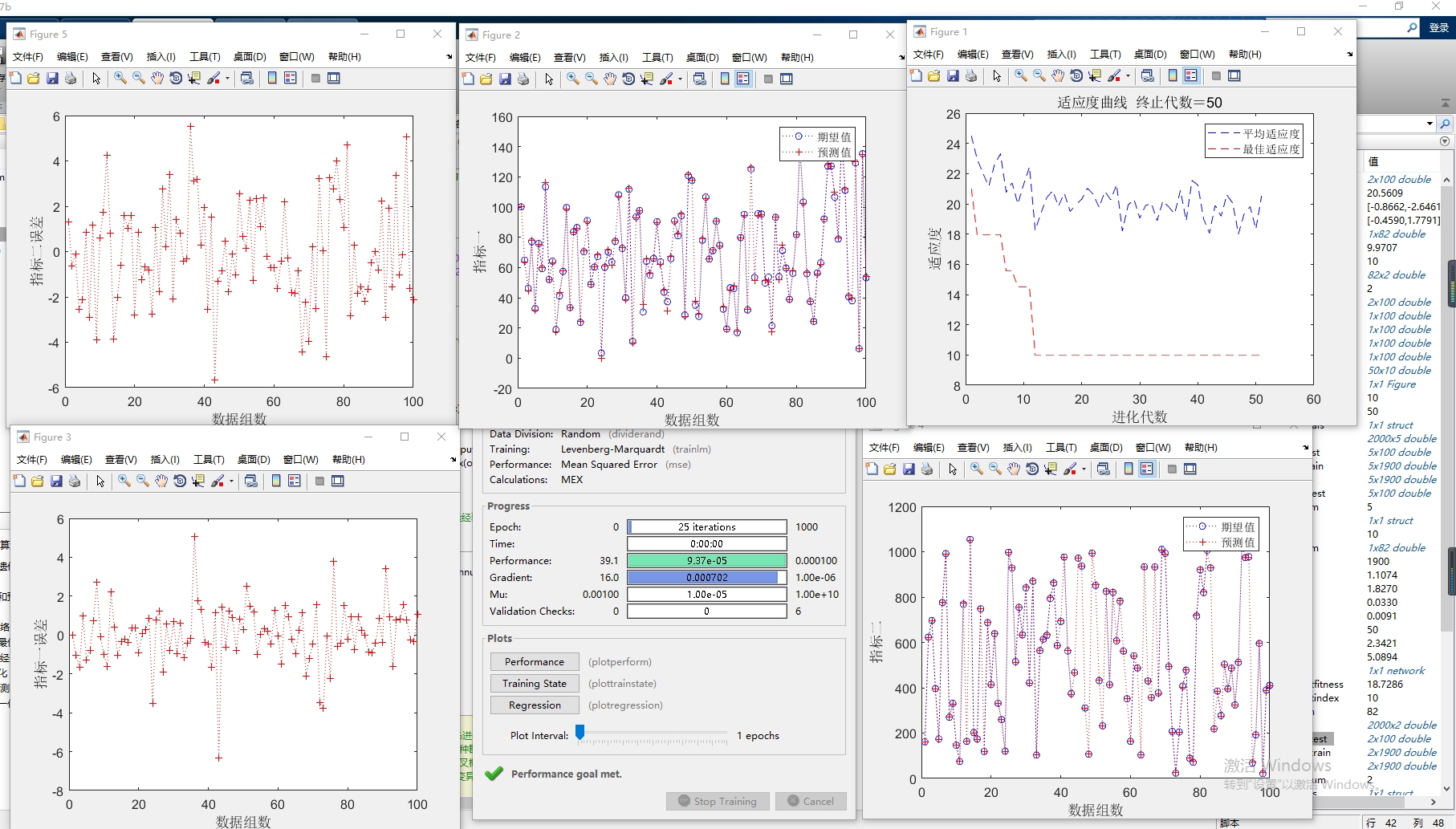
模型整体流程分为三大阶段:数据预处理阶段(数据读取、划分与归一化)、参数优化阶段(遗传算法迭代优化BP初始参数)、预测与评估阶段(优化后BP网络训练、预测及误差分析),各阶段环环相扣,形成完整的预测闭环。
二、核心模块功能解析
(一)数据预处理模块
该模块是模型运行的基础,负责将原始数据转化为符合神经网络输入要求的格式,主要包含数据读取、样本划分、归一化3个子功能,对应main.m中的初始化环节。
- 数据读取:从Excel文件中读取两类数据——输入特征数据(如环境因子、工况参数等)与输出预测数据(待预测的两个目标指标),默认读取2000组样本,确保数据量满足模型训练需求。
- 样本划分:按照“训练集占比高、测试集占比低”的原则,将数据划分为训练集(前1900组)与测试集(后100组)。训练集用于模型参数学习,测试集用于验证模型泛化能力,避免过拟合。
- 数据归一化:采用
mapminmax函数将输入、输出数据归一化到[-1,1]区间。此操作可消除不同特征间量纲差异(如“温度(℃)”与“压力(MPa)”)对模型训练的影响,同时提升BP神经网络的收敛速度,归一化参数(inputps、outputps)将用于后续测试数据的同标准处理与预测结果的反归一化。
(二)BP神经网络基础构建模块
该模块在main.m中实现,负责搭建多输入两输出的BP神经网络基础结构,为后续遗传算法优化提供“待优化框架”。
- 网络结构定义:根据输入特征数量(
inputnum,由输入数据维度自动确定)、隐含层节点数(hiddennum,默认设为10,可根据“经验公式:隐含层节点数=√(输入节点数+输出节点数)+常数”调整)、输出节点数(outputnum=2,对应两个预测指标),构建三层BP神经网络。
- 激活函数:隐含层采用tansig函数(双曲正切S型函数,将输出映射到[-1,1],增强非线性拟合能力),输出层采用purelin函数(线性函数,适配连续值预测场景)。
- 训练算法:采用trainlm算法(Levenberg-Marquardt算法),兼顾收敛速度与训练精度,适用于中大规模样本的神经网络训练。 - 训练参数配置:设置BP网络的核心训练参数,确保训练过程稳定高效,关键参数包括:
- 训练次数(epochs=1000):最大迭代训练轮次,防止训练不充分;
- 学习速率(lr=0.01):控制每轮训练中参数更新的步长,避免步长过大导致震荡或步长过小导致收敛缓慢;
- 训练目标(goal=0.0001):训练终止的误差阈值,当网络误差低于该值时提前停止训练;
- 失败次数(max_fail=6):若连续6轮训练误差未下降,则终止训练,防止无效迭代。
(三)遗传算法优化模块
该模块是模型的核心创新点,通过Code.m(编码)、Cross.m(交叉)、Mutation.m(变异)、Select.m(选择)、fun.m(适应度计算)5个函数协同工作,实现对BP神经网络初始权值与阈值的全局寻优,对应main.m中的迭代优化环节。
1. 核心概念与参数设置
- 优化目标:BP神经网络的初始权值(输入层-隐含层、隐含层-输出层)与阈值(隐含层、输出层),这些参数的初始值直接影响BP网络的训练结果,传统随机初始化易陷入局部最优。
- 遗传算法参数:进化代数(
maxgen=50,控制寻优迭代次数)、种群规模(sizepop=10,每代参与进化的“参数组合个体”数量)、交叉概率(pcross=0.2,控制个体间基因交换的概率)、变异概率(pmutation=0.1,控制个体基因变异的概率),参数取值平衡寻优效率与全局搜索能力。
2. 各子函数功能
- 编码函数(Code.m):将BP网络的权值与阈值(共
inputnumhiddennum + hiddennum + hiddennumoutputnum + outputnum个参数)编码为“染色体”(实数向量)。通过线性插值生成[-3,3]区间内的随机参数,并调用test.m函数验证参数合法性(确保无超界值),生成初始种群的个体。 - 适应度计算函数(fun.m):作为遗传算法的“评价标准”,将染色体(参数组合)解码为BP网络的权值与阈值,代入BP网络进行训练后,计算网络预测值与真实值的绝对误差和,该误差和即为个体的适应度值——适应度值越小,说明参数组合越优。
- 选择函数(Select.m):采用“轮盘赌法”从当前种群中选择优秀个体进入下一代。首先将适应度值转换为选择概率(误差越小,选择概率越高),然后通过随机抽样选择个体,确保优秀个体有更高概率保留,同时保留部分普通个体维持种群多样性,避免早熟收敛。
- 交叉函数(Cross.m):模拟生物基因重组,随机选择两个个体及交叉位置,通过实数交叉公式(如
chrom(index(1),pos)=pickv2+(1-pick)v1)交换部分基因,生成新个体。交叉后需验证新个体的参数合法性,确保种群质量,该操作增加种群的基因多样性,拓展搜索空间。 - 变异函数(Mutation.m):模拟生物基因突变,随机选择个体及变异位置,根据当前进化代数动态调整变异幅度(进化后期变异幅度减小,避免破坏已找到的优解),对参数进行微调。变异后同样需验证合法性,该操作可帮助种群跳出局部最优,实现全局寻优。
3. 迭代优化流程
- 初始化种群:生成
sizepop个合法的参数组合个体,计算每个个体的适应度值; - 迭代进化:每代依次执行选择、交叉、变异操作,更新种群;
- 优解更新:每代结束后,对比当前种群最优个体与历史最优个体,保留更优的参数组合;
- 终止输出:迭代至
maxgen代后,输出历史最优个体(即BP网络的最优初始权值与阈值)。
(四)预测与评估模块
该模块在main.m中实现,基于遗传算法优化后的BP网络进行预测与结果分析,包含网络训练、测试预测、误差计算3个子功能。
- 优化后BP网络训练:将遗传算法得到的最优初始权值与阈值代入BP网络,使用训练集数据重新训练网络,使网络在优初始参数基础上进一步学习数据规律,提升预测精度。
- 测试预测:对测试集输入数据进行归一化(使用训练阶段的
inputps参数),代入训练好的BP网络得到预测值,再通过反归一化(使用outputps参数)将预测值还原为原始量纲,确保结果可解释。 - 误差计算与可视化:
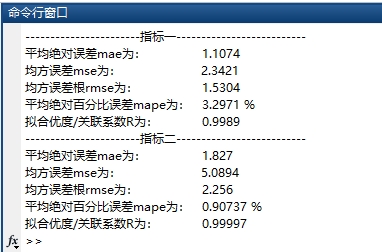
- 误差计算:调用calc_error.m函数,计算两个预测指标的5项核心误差指标——平均绝对误差(MAE,反映误差实际大小)、均方误差(MSE,放大较大误差的影响)、均方根误差(RMSE,与原始数据量纲一致,便于直观理解)、平均绝对百分比误差(MAPE,消除量纲,便于不同指标间误差对比)、拟合优度(R,衡量预测值与真实值的线性相关程度,越接近1越好)。
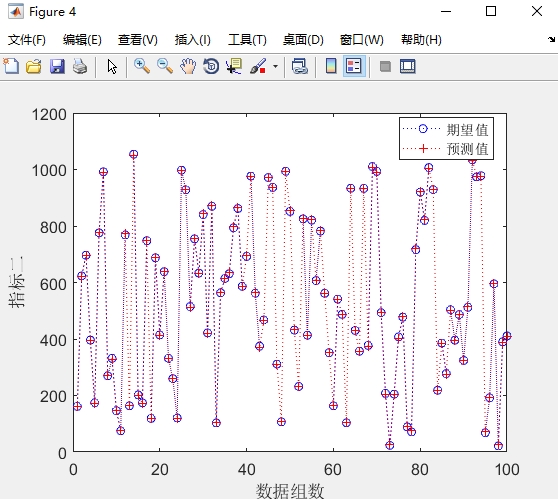
- 可视化分析:生成两类图表——预测值与真实值对比图(直观展示预测效果)、误差变化图(展示误差分布规律),同时输出误差指标的文字结果,全面评估模型性能。
(五)辅助验证函数(test.m)
作为模型的“参数合法性检测器”,在编码、交叉、变异操作后调用,检查参数是否超出[-3,3]区间。若存在超界参数,返回“不合法”信号,触发重新生成/调整参数的操作;若参数全部合法,返回“合法”信号,确保种群中所有个体的参数均符合BP网络的运行要求,避免因参数异常导致网络训练失败。
三、模型运行流程总览
- 初始化阶段:读取Excel数据,划分训练/测试集,对数据进行归一化处理;
- BP网络搭建:定义网络结构(输入/隐含/输出层节点数),配置训练参数;
- 遗传算法优化:
- 生成初始种群,计算个体适应度;
- 迭代执行选择、交叉、变异操作,更新种群与历史最优个体;
- 迭代结束,输出最优初始权值与阈值; - 预测与评估阶段:
- 代入最优初始参数,训练BP网络;
- 测试集预测与结果反归一化;
- 计算误差指标,生成可视化图表,输出评估结果。
四、模型核心优势与适用场景
(一)核心优势
- 全局寻优能力强:通过遗传算法的选择、交叉、变异操作,有效避免传统BP网络初始参数随机化导致的局部最优问题,提升模型预测精度;
- 适应性好:支持多输入特征(输入维度可根据数据自动调整),固定两输出指标,可灵活适配不同领域的双指标预测需求;
- 结果可解释性高:通过误差指标(MAE、RMSE、MAPE、R)与可视化图表,直观展示模型性能,便于结果分析与优化方向判断。
(二)适用场景
- 工业过程预测:如化工生产中“反应温度、压力→产品纯度、产量”的双指标预测;
- 环境监测预测:如“PM2.5、温度、湿度→臭氧浓度、AQI指数”的双指标预测;
- 能源负荷预测:如“历史负荷、天气、节假日→短期电力负荷、燃气负荷”的双指标预测。
五、模型使用注意事项
- 数据准备:确保Excel数据格式正确(输入特征在A-E列,输出指标在F-G列),样本量建议不低于1000组,避免因数据量不足导致模型过拟合;
- 参数调整:
- 隐含层节点数(hiddennum)可根据实际数据复杂度调整(建议范围2-13),复杂数据可适当增加节点数;
- 遗传算法参数(如种群规模、进化代数)可根据寻优效率调整,数据复杂时可增大种群规模或进化代数; - 结果解读:重点关注MAPE(建议低于10%)与R(建议高于0.9)指标,若指标不佳,可检查数据质量(如异常值处理)或调整网络/遗传算法参数。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)