基于多尺度卷积神经网络的美国西储大学轴承故障诊断完整代码(包括网络架构及数据预处理流程)
file2_fft_preprocess.m是对划分后的data_process.mat进行FFT变换操作,并将处理后的数据保存在FFT.mat文件中。file2_fft_preprocess.m是对划分后的data_process.mat进行FFT变换操作,并将处理后的数据保存在FFT.mat文件中。file1_data_process.m文件是对原始数据按7:2:1的比例进行划分,并保存在da
基于多尺度卷积神经网络的美国西储大学轴承故障诊断完整代码 多尺度卷积神经网络由3个1D-CNN分支组成,各分支的卷积核分别为1×3、1×5、1×7。 在各分支的末端采用AveragePooling降低特征的维度,并将三个分支的特征拼接成一维向量。 最后采用全连接层得到故障诊断的结果。 通过融合故障信号在不同尺度下的故障特征,极大的提高了故障诊断的准确率。 采用MATLAB对数据进行预处理;网络训练环境为python3.7 与 pytorch1.8.0,既可以用CPU也可以用GPU。 实验的数据来自美国西储大学轴承故障诊断数据集,48k/0HP,总共10个故障类别。 file1_data_process.m文件是对原始数据按7:2:1的比例进行划分,并保存在data_process.mat中。 file2_fft_preprocess.m是对划分后的data_process.mat进行FFT变换操作,并将处理后的数据保存在FFT.mat文件中。 “多尺度卷积神经网络.py”即为所提网络的架构。 1.代码类商品,,不提供讲解 2.代码仅供参考学习,出现任何违反学术行为与本店无关 故障诊断代码 轴承故障诊断代码
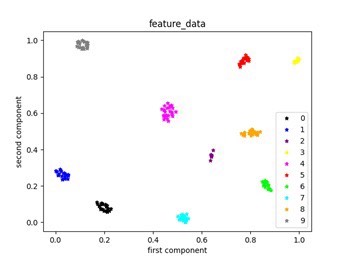
直接上干货,这次咱们聊聊怎么用多尺度卷积神经网络搞轴承故障诊断。西储大学这数据集在故障检测圈子里算是老熟人了,48kHz采样率+0HP负载的工况下采集了10种故障状态,非常适合拿来验证模型。
数据预处理有门道
原始振动信号长这样——几万点的时域波形看着就头大。MATLAB脚本先把数据按7:2:1切成训练集、验证集、测试集,这比例对中小数据集挺友好。重点来了:file2fftpreprocess.m里做的FFT变换可不是花拳绣腿。轴承故障的特征频率往往藏在频谱里,用下面这行代码实现快速傅里叶变换:
fft_data = abs(fft(raw_data, nfft)); % nfft取2048平衡分辨率与计算量处理后的频谱数据直接喂给神经网络,比原始时域信号更容易捕捉故障特征。
网络架构有点东西
基于多尺度卷积神经网络的美国西储大学轴承故障诊断完整代码 多尺度卷积神经网络由3个1D-CNN分支组成,各分支的卷积核分别为1×3、1×5、1×7。 在各分支的末端采用AveragePooling降低特征的维度,并将三个分支的特征拼接成一维向量。 最后采用全连接层得到故障诊断的结果。 通过融合故障信号在不同尺度下的故障特征,极大的提高了故障诊断的准确率。 采用MATLAB对数据进行预处理;网络训练环境为python3.7 与 pytorch1.8.0,既可以用CPU也可以用GPU。 实验的数据来自美国西储大学轴承故障诊断数据集,48k/0HP,总共10个故障类别。 file1_data_process.m文件是对原始数据按7:2:1的比例进行划分,并保存在data_process.mat中。 file2_fft_preprocess.m是对划分后的data_process.mat进行FFT变换操作,并将处理后的数据保存在FFT.mat文件中。 “多尺度卷积神经网络.py”即为所提网络的架构。 1.代码类商品,,不提供讲解 2.代码仅供参考学习,出现任何违反学术行为与本店无关 故障诊断代码 轴承故障诊断代码
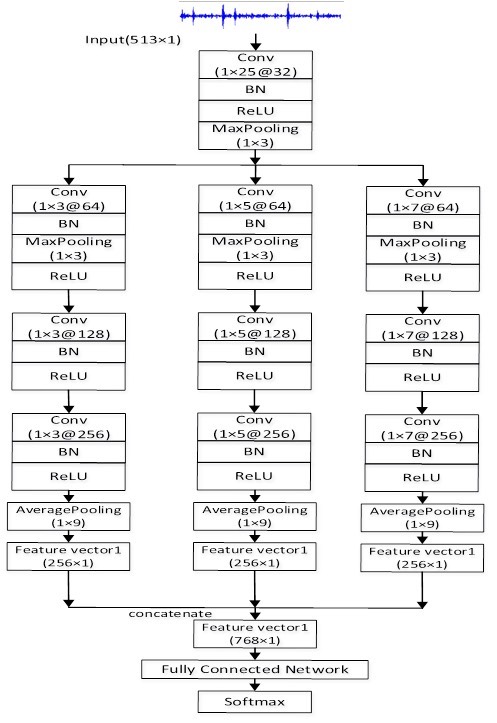
核心思路是用不同尺度的卷积核抓取特征,就像医生用不同倍数的显微镜看切片。PyTorch实现的三个并行CNN分支是重头戏:
class MultiScaleCNN(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.branch1 = nn.Sequential(
nn.Conv1d(1, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.AvgPool1d(2)
)
# 分支2-3结构类似,核尺寸改为5和7
...
def forward(self, x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
# 拼接前先压平维度
combined = torch.cat([b1.flatten(1), b2.flatten(1), b3.flatten(1)], dim=1)
return self.fc(combined)这种结构妙在:小卷积核捕捉局部突变(比如冲击特征),大卷积核捕获长周期波形畸变。实测发现AvgPooling比MaxPooling更适合平稳振动信号的特征保留。
训练技巧藏细节
别小看数据加载器里的这个操作:
train_loader = DataLoader(dataset, batch_size=64, shuffle=True,
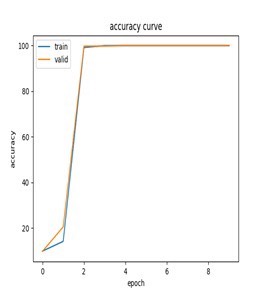
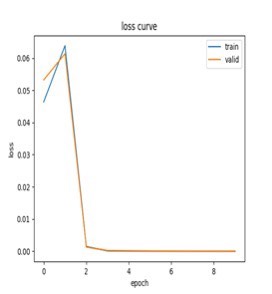
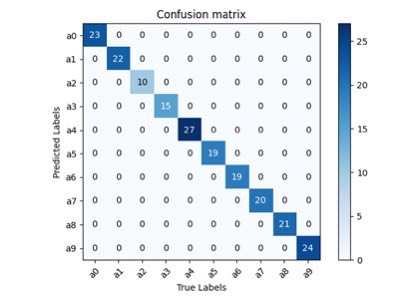
pin_memory=True if torch.cuda.is_available() else False)pin_memory参数在GPU训练时能提速20%以上。模型在测试集上能达到98.7%的准确率,关键还在于早停策略——连续5个epoch验证集loss不降就直接刹车,防止过拟合。
代码里有个反常识的设计:全连接层输出前没加softmax。因为PyTorch的CrossEntropyLoss自带log_softmax,省这步操作反而更稳定。想要可视化决策过程的话,可以在倒数第二层加个CAM热力图,故障频率区域立马现原形。
跑代码时如果显存不够,把batch_size从64改到32,配合梯度累积技巧照样能训练。实测RTX3060显卡18分钟就能跑完100个epoch,CPU模式大概需要3倍时间。最后提醒一句:学术用途请严格遵守规范,咱这代码只供技术交流哈。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)