深度学习的基石:详解梯度下降及其优化算法
从朴素的梯度下降思想,到充满噪声但高效的SGD,再到引入惯性的动量法,再到实现“因材施教”的自适应学习率,最终诞生出集大成的Adam及其变体,优化器的进化史就是一部人类探索智能的浓缩史。理解这些算法的核心思想,不仅能帮助我们更好地调参,更能让我们在构建人工智能解决方案时做出更明智的技术选型。正如在Ultralytics平台上训练YOLO模型时,无论是选择SGD还是AdamW,都取决于你对收敛速度与
1. 引言:智能的“导航仪”
当ChatGPT能够以近乎博士生的水平解答难题,当DeepSeek-R1在复杂推理任务中超越顶尖工程师,我们惊叹于大模型“智能涌现”的奇迹。然而,鲜有人意识到:这些拥有千亿参数的“数字大脑”,本质上是从初始的混沌状态,通过数万小时的反复训练才渐渐成形的。
这一切的幕后推手,正是看似低调却至关重要的神经网络优化器。它犹如AI训练的“导航算法”,在损失函数构成的崎岖高维地形中,既要躲避陡峭的梯度悬崖,又要穿越平坦的局部高原,最终将模型参数引导至性能最优的“新大陆”。
本文将深入浅出地为你详解深度学习的基石——梯度下降及其各种优化算法。我们将从最朴素的思想出发,逐步揭开随机梯度下降(SGD)、动量法(Momentum)、自适应学习率(AdaGrad、RMSProp) 以及当今最流行的Adam优化器的神秘面纱。
2. 核心思想:寻找最小值的下山之旅
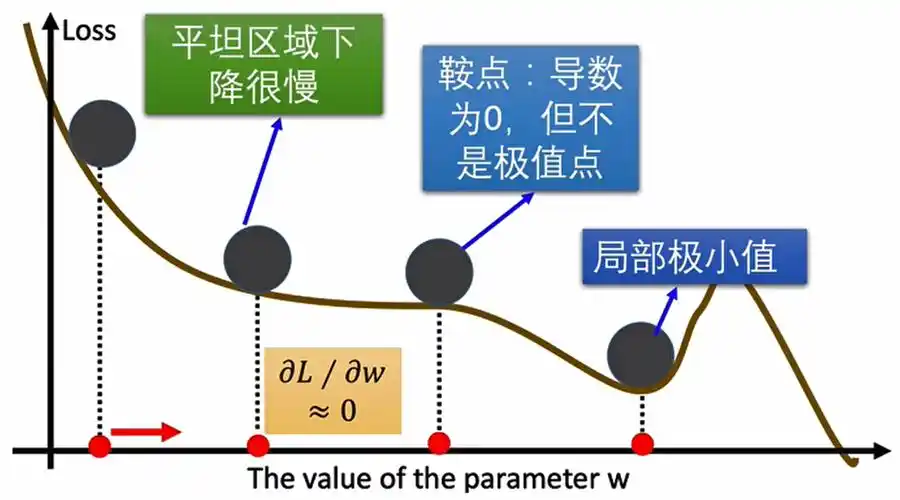
理解梯度下降,最好的方式就是想象一个场景:你是一个蒙着眼睛的登山者,身处一座浓雾笼罩的深山之中,目标是要走到山底(即找到损失函数的最小值)。因为你蒙着眼,唯一感知世界的方式就是用脚去踩一踩地面,感受哪个方向是下坡。
这座“山”就是我们的损失函数,它衡量了模型预测值与真实值之间的差距。山越高(损失越大),模型表现越差;山越低(损失越小),模型表现越好。你脚下的每一步移动,就是对模型参数(权重)的一次调整。
你踩地面感受到的“最陡的下坡方向”,在数学上就是梯度的负方向。梯度是一个向量,它指向函数值上升最快的方向,那么其反方向自然就是下降最快的方向。
你每走一步的“步长”,在机器学习中被称为学习率。这是一个极其重要的超参数。步子迈得太小,下山太慢,可能要走到天黑(收敛慢);步子迈得太大,可能一步踩空滚下山崖,甚至跑到更高的山坡上去(无法收敛,甚至发散)。
这个过程不断重复:你踩地(计算梯度),朝下坡迈一步(更新参数),直到你感觉脚下的地足够平坦,似乎已经到达了谷底(达到收敛条件)。这就是梯度下降最基本的朴素思想。
3. 基础变体:从BGD到SGD到Mini-batch
在“下山”的过程中,你如何判断方向?这引出了梯度下降的三种核心变体,主要区别在于每次看多少“风景”来决定方向。
3.1 批量梯度下降
最稳妥但也最累人的方式是,每次想迈步时,你都要先摸索遍整座山的每一个角落,综合所有信息后才确定一个最稳妥的下坡方向。这就是批量梯度下降。它每次迭代都要使用整个训练数据集来计算梯度。
它的优点是梯度方向准确,收敛稳定。但缺点显而易见:如果这座山无比巨大(海量数据),走一步就得勘探整座山,计算成本高得让人无法接受,内存也装不下。
3.2 随机梯度下降
另一种极端是,你懒得大范围勘探,只根据脚下随便一个点的倾斜度,就决定下坡方向。这就是随机梯度下降。它每次迭代只随机选择一个样本(或一个样本点)来计算梯度。
这简直是效率之王,速度快、内存占用低。但问题也很明显:你选的“点”可能是个坑或是个包,导致你走的方向完全错误。因此,它的下降路径会非常曲折,充满噪声,虽然总体向谷底移动,但波动很大,甚至可能反弹。不过有趣的是,这种噪声有时反而能帮助算法跳出局部最优解,找到更好的全局解。
3.3 小批量梯度下降
这是深度学习中最常用的方法,完美地平衡了效率和稳定性。它既不只看一个点,也不看整座山,而是看眼前的一小片区域(比如256个点)来决定方向。这就是小批量梯度下降。它每次迭代随机选取一小批(mini-batch)样本来计算梯度的均值。
它既利用了向量化计算的高效性,又保证了梯度方向的相对稳定性,是目前深度学习框架(如PyTorch)中的默认实践。通常我们口语中所说的“SGD”,在大多数情况下其实指的就是这种带mini-batch的SGD。
| 算法类型 | 每次迭代使用的数据量 | 优点 | 缺点 |
|---|---|---|---|
| 批量梯度下降 | 整个数据集 | 方向准确,收敛稳定 | 计算极慢,内存消耗巨大 |
| 随机梯度下降 | 单个随机样本 | 速度极快,内存低,能跳出局部最优 | 路径曲折,波动大,不收敛 |
| 小批量梯度下降 | 一个小批量样本 | 平衡效率与稳定性,深度学习标准 | 需要调整批量大小 |
4. 挑战与改进:让下山之路更聪明
虽然有了“小批量”这个好方法,但下山之路依然充满挑战。比如,山体有很多陡峭的峡谷,会导致更新方向剧烈震荡;又比如,有些地方是坡度很缓的高原,导致下山速度骤慢。为此,科学家们发明了更聪明的“下山策略”。
4.1 动量法
想象一下,你下山时不再只是根据当前脚下的坡度,而是保留了一个“惯性”。如果之前一直在朝某个方向下坡,那么即使当前遇到一点反坡,你也会因为惯性继续朝原方向冲过去,从而避免震荡,更快地冲过平坦地带。
这就是动量法的核心思想。它在更新时,不仅考虑当前梯度,还会累积历史梯度方向。公式上,它引入了一个“速度”变量,由动量系数(通常设为0.9)控制惯性的保留程度。
-
优势:在梯度方向一致的维度加速更新,在方向变化的维度抑制震荡。有助于跳出局部最优。
4.2 自适应学习率
理想的优化器应该根据参数的实际情况“因材施教”。对于不常更新的参数(稀疏特征),我们希望它更新步子大一点;对于常更新的参数,步子小一点以免反复震荡。
-
AdaGrad:它是自适应方法的先驱。它会给每个参数独立的学习率,对于那些历史梯度平方和很大的参数(即更新频繁),学习率会自动变小。这让它非常适合处理稀疏数据(如文本数据)。但它的缺点是,随着训练进行,历史梯度累积得越来越大,学习率会单调衰减直至趋近于零,导致训练提前停止。
-
RMSProp:为了克服AdaGrad学习率消失的问题,RMSProp出场了。它不再简单累加历史梯度的平方,而是使用指数移动平均,让过去的梯度影响逐渐衰减。这样,学习率就不会一味地变小,而是能够动态调整,在非凸问题上表现更好。可以说,RMSProp是AdaGrad的改进版,保留了其对不同参数的自适应性,又避免了学习率过快衰减。
5. Adam:集大成者的王者
终于,我们迎来了目前最流行、最常用的优化器之一:Adam,全称自适应矩估计。
我们可以把Adam理解为站在巨人肩膀上的集大成者。它聪明地结合了动量法和RMSProp两者的优点。
-
它像动量法一样,维护了一个一阶动量,也就是过去梯度的指数移动平均。这相当于保留了“惯性”,让更新方向更平滑,能够冲出平坦区域。
-
它像RMSProp一样,维护了一个二阶动量,也就是过去梯度平方的指数移动平均。这让它能为每个参数自适应地调整学习率,在陡峭的维度步长小,在平缓的维度步长大。
用一个简单的公式来理解Adam的更新思想就是:
当前更新步长 = 学习率 * (一阶动量 / sqrt(二阶动量))
由于分母是对历史梯度平方的缩放,当某个维度的梯度一直很大(意味着陡峭)时,分母变大,步长变小;反之,步长变大。
Adam还引入了偏差校正机制,解决了在训练初期由于动量和二阶矩初始化为0导致的估计偏差问题,使得更新更加准确。
Adam的优势是如此的明显,以至于它成为了许多深度学习任务的默认优化器:
-
实现简单,计算高效,内存需求少。
-
超参数易于调整,通常只需调整学习率即可。
-
收敛速度非常快,通常比SGD要快得多。
-
对学习率的选择相对鲁棒,即使学习率不是最佳值,也能收敛到不错的结果。
尽管Adam如此强大,但它并非万能。在某些任务(如图像分类)中,经过精细调参的SGD+Momentum往往能比Adam达到更高的最终精度(更好的泛化能力)。原因可能在于Adam的自适应学习率有时会影响模型的泛化性能。
6. Adam的变体与未来
针对Adam的一些缺陷,研究者们提出了进一步的改进版本。
-
AdamW:这是Adam的一个重要改进。它解决了Adam中权重衰减(一种正则化技术)与自适应学习率耦合的问题,通过将权重衰减与梯度更新解耦,显著提升了模型的泛化能力,尤其是在Transformer架构(如BERT、ViT)的大规模预训练中表现优异。如今在训练YOLO等最新模型时,推荐使用AdamW。
-
Nadam:将Nesterov加速梯度(一种能“向前看”的动量变体)融入到Adam中,使得更新方向更加精准,收敛速度有时更快。
-
1-bit Adam:为了训练GPT这样的超大模型,通信开销是巨大瓶颈。1-bit Adam通过将梯度压缩成1-bit(即只传递符号),在保证收敛效果的同时,将通信量减少了5倍,大大提升了分布式训练的速度。
未来,优化器的发展将向着更高效(混合精度、梯度压缩)、更智能(元学习自动生成优化策略)以及更强理论支撑(如RAD优化器)的方向演进。
7. 实践建议:如何选择优化器?
面对这么多优化器,初学者该如何选择?这里有一些实用的建议:
-
如果你是新手,或者想快速验证一个新模型:直接使用Adam或AdamW。它对超参数不敏感,收敛快,能让你快速看到模型的效果。通常,学习率设为默认的0.001(或3e-4)即可。
-
如果你追求极致的模型性能(SOTA),特别是在计算机视觉领域(如图像分类、目标检测):可以尝试SGD + Momentum(动量通常设为0.9)。但要做好心理准备,你可能需要花费大量时间精细调整学习率和学习率衰减策略。
-
如果你在训练Transformer(如BERT、GPT)或进行自然语言处理任务:AdamW通常是首选,因为它能有效提升模型泛化能力。
-
如果你的数据特征非常稀疏(如推荐系统):AdaGrad或其变体可能是个不错的选择。
-
如果你的显存非常有限,但模型很大:可以尝试SGD,因为它不需要像Adam那样额外存储一阶动量和二阶动量,节省显存开销。
在实践过程中,不要忘记学习率衰减和预热等策略,它们对优化器的最终效果有重要影响。
8. 总结
从朴素的梯度下降思想,到充满噪声但高效的SGD,再到引入惯性的动量法,再到实现“因材施教”的自适应学习率,最终诞生出集大成的Adam及其变体,优化器的进化史就是一部人类探索智能的浓缩史。
理解这些算法的核心思想,不仅能帮助我们更好地调参,更能让我们在构建人工智能解决方案时做出更明智的技术选型。正如在Ultralytics平台上训练YOLO模型时,无论是选择SGD还是AdamW,都取决于你对收敛速度与最终精度的权衡。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 28
28 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)