基于 MS-1DCNN 的故障诊断:Pytorch 实战指南
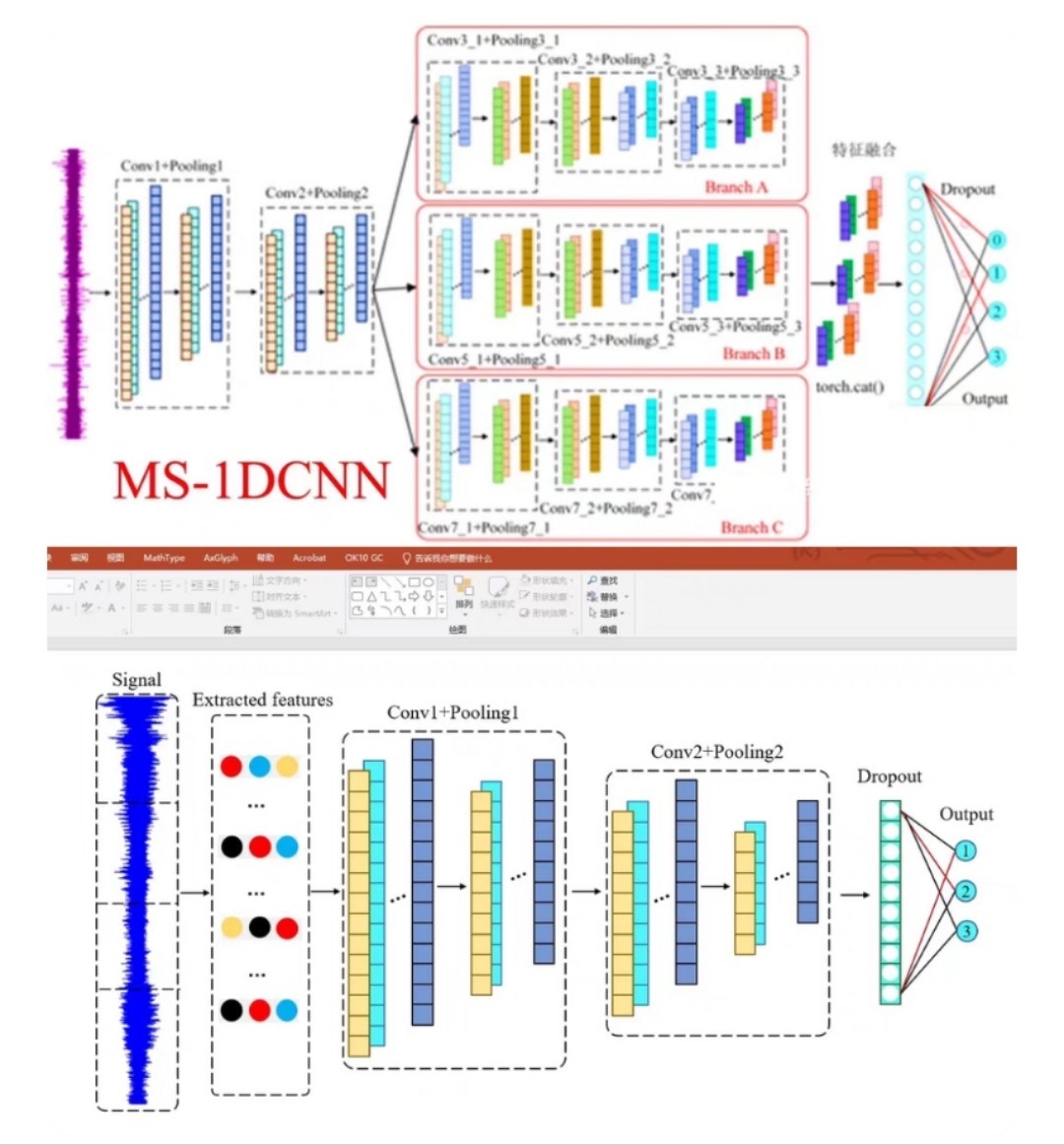
基于多尺度一维卷积神经网络(MS-1DCNN)的故障诊断方法|||研究,深度学习框架是pytorch。西储大学故障诊断识别率为97.5%(验证集)以上很好运行的适用于刚上手故障诊断的同学,就是从数据处理,到最后出图可视化完整一套流程,看完这个会对故障诊断流程有个清晰认识。数据集为凯斯西储大学轴承数据。嘿,刚上手故障诊断的同学们!今天咱来唠唠基于多尺度一维卷积神经网络(MS - 1DCNN)的故障诊
基于多尺度一维卷积神经网络(MS-1DCNN)的故障诊断方法|||研究,深度学习框架是pytorch。 西储大学故障诊断识别率为97.5%(验证集)以上很好运行的 适用于刚上手故障诊断的同学,就是从数据处理,到最后出图可视化完整一套流程,看完这个会对故障诊断流程有个清晰认识。 数据集为凯斯西储大学轴承数据。
嘿,刚上手故障诊断的同学们!今天咱来唠唠基于多尺度一维卷积神经网络(MS - 1DCNN)的故障诊断方法,用的深度学习框架是 Pytorch。咱会从数据处理一路讲到最后出图可视化,让你对整个故障诊断流程有个清晰的认识。数据集用的是经典的凯斯西储大学轴承数据,最后在西储大学故障诊断验证集上能达到 97.5%以上的识别率,效果杠杠的!
数据处理
首先,咱得把凯斯西储大学轴承数据请进来。这个数据集一般包含不同工况下的轴承振动数据等。在 Pytorch 里,我们可以这么来加载数据:
import torch
from torch.utils.data import Dataset, DataLoader
import pandas as pd
class BearingDataset(Dataset):
def __init__(self, data_path, transform=None):
self.data = pd.read_csv(data_path)
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data.iloc[idx]
if self.transform:
sample = self.transform(sample)
return torch.tensor(sample['features'].values, dtype=torch.float32), \
torch.tensor(sample['label'], dtype=torch.long)
# 假设数据路径
data_path = 'bearing_data.csv'
bearing_dataset = BearingDataset(data_path)
data_loader = DataLoader(bearing_dataset, batch_size=32, shuffle=True)这里我们定义了一个 BearingDataset 类来加载数据,继承自 torch.utils.data.Dataset。init 方法里读取了数据文件,len 方法返回数据集的长度,getitem 方法返回每个样本及其标签。然后通过 DataLoader 来批量加载数据,方便后续训练。
构建 MS - 1DCNN 模型
接下来就是构建我们的多尺度一维卷积神经网络啦。
import torch.nn as nn
class MS1DCNN(nn.Module):
def __init__(self):
super(MS1DCNN, self).__init__()
self.conv1 = nn.Conv1d(in_channels=1, out_channels=32, kernel_size=3)
self.conv2 = nn.Conv1d(in_channels=32, out_channels=64, kernel_size=5)
self.conv3 = nn.Conv1d(in_channels=64, out_channels=128, kernel_size=7)
self.pool = nn.MaxPool1d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(128 * 10, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(nn.functional.relu(self.conv1(x)))
x = self.pool(nn.functional.relu(self.conv2(x)))
x = self.pool(nn.functional.relu(self.conv3(x)))
x = x.view(-1, 128 * 10)
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
model = MS1DCNN()在这个模型里,我们定义了三个不同尺度的一维卷积层 conv1、conv2、conv3,卷积核大小分别为 3、5、7,这样可以捕捉不同尺度的特征。然后通过 MaxPool1d 进行池化操作,减少数据维度。接着是两个全连接层 fc1 和 fc2,最后输出分类结果。
训练模型
模型有了,数据也准备好了,那就开始训练吧!
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(data_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(data_loader)}')这里我们选择了交叉熵损失函数 CrossEntropyLoss,优化器用的是 Adam,学习率设为 0.001。在每个 epoch 里,遍历数据加载器,前向传播得到输出,计算损失,反向传播更新参数,最后打印每个 epoch 的平均损失。
模型评估与可视化
训练完了,咱得看看模型表现咋样。
correct = 0
total = 0
with torch.no_grad():
for data in data_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the test images: {100 * correct / total}%')这里计算了模型在测试集上的准确率。要是想更直观地看看模型预测情况,我们可以用一些可视化工具,比如 Matplotlib。
import matplotlib.pyplot as plt
import numpy as np
# 假设已经得到预测结果和真实标签
predicted_labels = []
true_labels = []
with torch.no_grad():
for data in data_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
predicted_labels.extend(predicted.tolist())
true_labels.extend(labels.tolist())
confusion_matrix = np.zeros((10, 10))
for i in range(len(predicted_labels)):
confusion_matrix[true_labels[i]][predicted_labels[i]] += 1
plt.imshow(confusion_matrix, cmap='Blues')
plt.title('Confusion Matrix')
plt.colorbar()
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()上面这段代码生成了混淆矩阵并可视化出来,能让我们清楚地看到模型在不同类别上的预测情况。
基于多尺度一维卷积神经网络(MS-1DCNN)的故障诊断方法|||研究,深度学习框架是pytorch。 西储大学故障诊断识别率为97.5%(验证集)以上很好运行的 适用于刚上手故障诊断的同学,就是从数据处理,到最后出图可视化完整一套流程,看完这个会对故障诊断流程有个清晰认识。 数据集为凯斯西储大学轴承数据。
好啦,通过这一套流程,从数据处理到模型构建、训练、评估和可视化,你对基于 MS - 1DCNN 的故障诊断流程是不是有了清晰的认识呀?赶紧动手试试吧!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)