解决 Fish Speech 在 PyTorch 2.10.0+cu130 中的 torchaudio.list_audio_backends AttributeError
摘要:FishSpeech在PyTorch 2.10.0+cu130环境中运行时出现torchaudio.list_audio_backends属性错误,原因是该函数在PyTorch 2.9.0+版本中已被移除。解决方案包括降级PyTorch或修改代码:在reference_loader.py中使用try-except捕获异常,并默认使用稳定的soundfile后端。建议开发者锁定依赖版本并采用防
解决 Fish Speech 在 PyTorch 2.10.0+cu130 中的 torchaudio.list_audio_backends AttributeError
https://docs.pytorch.ac.cn/audio/stable/generated/torchaudio.list_audio_backends.html
目录
解决 Fish Speech 在 PyTorch 2.10.0+cu130 中的 torchaudio.list_audio_backends AttributeError
问题背景
在 Windows 11 + RTX 3090 + CUDA 13.0 环境下,使用 torch==2.10.0+cu130运行 Fish Speech 的 WebUI (python tools/run_webui.py) 时,程序在加载音频后端时崩溃,报错如下:
AttributeError: module 'torchaudio' has no attribute 'list_audio_backends'
根本原因:torchaudio.list_audio_backends()函数在 PyTorch 2.9.0 及更高版本中已被官方彻底移除。Fish Speech 项目代码(reference_loader.py)直接调用了这个已废弃的 API。
权威引用:为什么这个函数消失了?
根据 PyTorch Audio 官方文档和源码,这是一个有计划的 API 废弃,属于从“Legacy Backend Mode”向“Dispatcher Mode”迁移的一部分。
|
版本 |
状态 |
官方说明 |
|---|---|---|
|
PyTorch 2.8.x |
Deprecated |
函数存在但发出警告,提示将在 2.9 中移除。 |
|
PyTorch 2.9.0+ |
Removed |
函数已从 |
官方文档证据:
PyTorch 2.9.0 Docs: torchaudio.list_audio_backends页面顶部明确标注 "DEPRECATED" 和 "Warning: This function has been deprecated. It will be removed from 2.9 release."。
Migration Guide: 官方建议使用新的 Dispatcher Mode,即直接调用
torchaudio.load()而不需要手动设置全局后端。
解决方案一(降级 PyTorch)
解决方案二(无需降级 PyTorch)
核心思路:使用 try-except捕获 AttributeError,在新版本中直接回退到默认且稳定的 soundfile后端。
1. 定位文件
打开导致报错的文件:fish_speech/inference_engine/reference_loader.py
2. 修改代码(约第 34 行)
找到 __init__方法中定义后端的代码块。
修改前(报错代码):
# Define the torchaudio backend
backends = torchaudio.list_audio_backends() # <-- 这行在 2.10.0 会爆炸
if "ffmpeg" in backends:
self.backend = "ffmpeg"
else:
self.backend = "soundfile"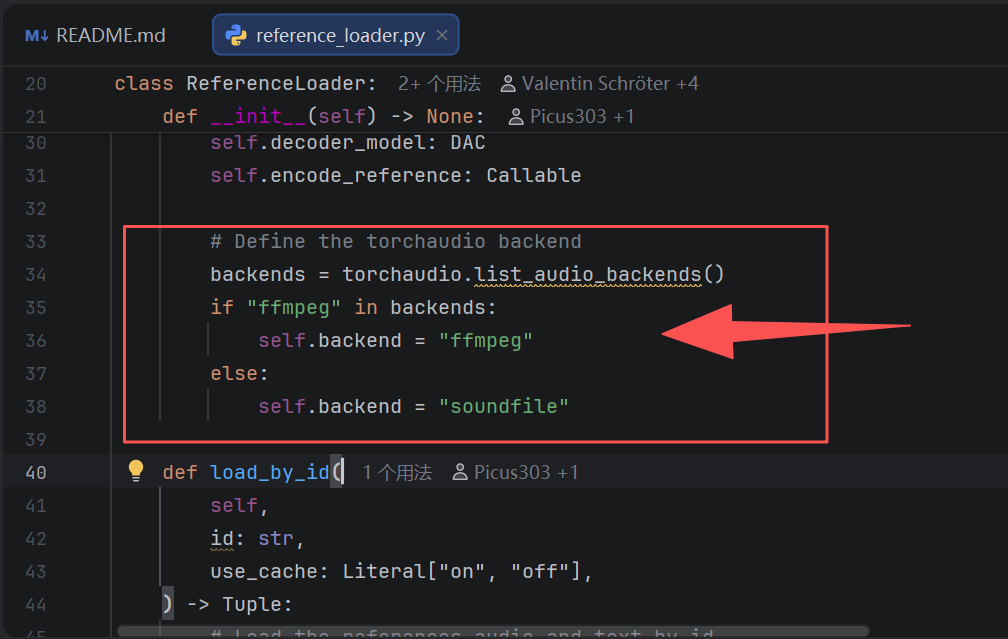
修改后(兼容代码):
# Define the torchaudio backend
# 处理 torchaudio 版本差异 (>=2.9 移除了 list_audio_backends)
try:
# 尝试旧版 API (torchaudio < 2.9)
backends = torchaudio.list_audio_backends()
if "ffmpeg" in backends:
self.backend = "ffmpeg"
else:
self.backend = "soundfile"
except AttributeError:
# 新版 torchaudio (>=2.9) 已移除该函数
# 在 Windows + PyTorch 2.10 环境下,soundfile 是安全且高效的默认值
self.backend = "soundfile"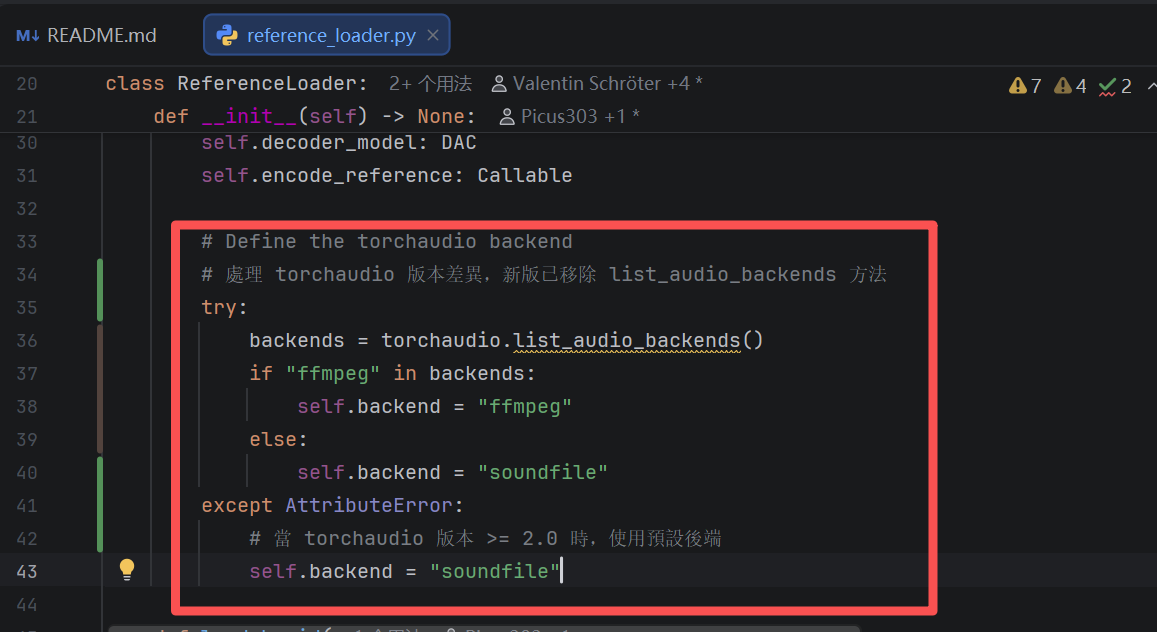
3. 验证
重新运行 python tools/run_webui.py。如果日志显示 Warming up done, launching the web UI...且无报错,则修复成功。

技术细节:为什么选择 soundfile作为回退?
-
Windows 原生支持:
soundfile后端在 Windows 上对 WAV 格式的支持最稳定,无需额外安装 FFmpeg 系统库。 -
Fish Speech 需求:项目主要处理的是训练和推理用的标准音频文件(WAV),
soundfile完全够用。 -
性能无损:对于 RTX 3090 的推理流水线,I/O 后端对 GPU 计算速度几乎没有影响。
预防措施与给开发者的建议
1. 依赖锁定(Prevention)
在 requirements.txt或项目文档中明确指定 torchaudio版本,避免用户自动安装最新版导致 API 断裂。
# 如果项目尚未适配 2.9+,应锁定在 2.8.x
torchaudio<2.9.02. 代码健壮性(Best Practice)
在调用可能被废弃的第三方库 API 时,永远使用防御性编程:
# 好习惯:检查属性是否存在
if hasattr(torchaudio, 'list_audio_backends'):
# 使用旧版逻辑
else:
# 使用新版逻辑或默认值3. 环境诊断脚本
创建一个 check_env.py来快速诊断兼容性问题:
import torch, torchaudio
print(f"PyTorch: {torch.__version__}")
print(f"torchaudio: {torchaudio.__version__}")
print(f"Has list_audio_backends: {hasattr(torchaudio, 'list_audio_backends')}")总结思考
这是一个典型的深度学习生态快速迭代导致的“下游项目滞后”问题。PyTorch 为了性能(Dispatcher Mode)移除了旧的全局状态管理 API,但像 Fish Speech 这样的优秀开源项目可能因为维护周期原因未能即时跟进。
对于用户而言,不降级 PyTorch(保持 CUDA 13.0 高性能) 而是手动 Patch 项目代码,是在享受新硬件算力与使用社区模型之间最好的平衡点。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)