一文吃透贝叶斯算法:从数学原理到 Python 代码实战(附完整可运行案例)
本文系统介绍了贝叶斯算法及其工程化应用。首先阐述了贝叶斯定理的核心思想,通过正向概率与逆向概率的对比,说明了贝叶斯算法在解决逆向概率问题上的优势。详细推导了贝叶斯公式,并通过穿长裤学生、色盲检测等案例进行直观解释。重点介绍了朴素贝叶斯分类器的特征条件独立假设及其三种常见实现。最后基于鸢尾花数据集,使用Python实现了完整的朴素贝叶斯分类流程,包括模型训练、预测评估和可视化分析。文章还总结了朴素贝
目录
五、Python 代码实战:基于鸢尾花数据集的朴素贝叶斯分类
前言
在机器学习领域,贝叶斯算法是绕不开的经典概率型算法,它以贝叶斯定理为核心,构建了一套完整的「从结果反推原因」的概率推理体系。不同于传统频率学派的固定概率思维,贝叶斯算法引入了先验概率与后验概率的概念,能很好地解决现实中大量的逆向概率问题。
无论是入门机器学习的分类任务,还是工业界的垃圾邮件识别、文本情感分析、医疗辅助诊断、风控反欺诈等场景,贝叶斯算法(尤其是朴素贝叶斯)都凭借简单高效、可解释性强的特点,成为了首选方案之一。
本文将从贝叶斯算法的核心思想出发,拆解数学原理与公式推导,再通过经典案例巩固理解,最终基于 Python 实现朴素贝叶斯分类器的完整实战,带你从零到一彻底掌握贝叶斯算法。
一、贝叶斯算法的核心:从正向概率到逆概思维的突破
1.1 贝叶斯算法的起源
贝叶斯算法得名于英国数学家托马斯・贝叶斯(Thomas Bayes,1702-1761),其核心理论在他去世后发表的论文《机遇理论中一个问题的解》中被正式提出。这套理论最核心的贡献,是颠覆了当时主流的概率计算思维,提出了逆概问题的解决方案,为后续的贝叶斯统计学派奠定了基础。
1.2 正向概率 vs 逆向概率
要理解贝叶斯算法,首先要分清两个核心概念:正向概率与逆向概率,我们用一个最直观的例子来解释:
正向概率:已知事物的整体分布,计算某个事件发生的概率。例子:假设袋子里有 10 个白球、90 个黑球,球的总数为 100 个。随机从袋子里摸出一个球,问摸出白球的概率是多少?计算非常简单:P(摸出白球)=总球数量/白球数量=10/100=10%
- 逆向概率:事先不知道事物的整体分布,只通过多次试验的结果,反推整体的分布情况。
例子:我们事先不知道袋子里白球和黑球的比例,只通过多次有放回的摸球试验,根据摸出球的颜色结果,推测袋子里白球和黑球的比例。而贝叶斯算法,正是为了解决这类逆向概率问题而生,它能让我们在信息有限的情况下,通过先验知识和观测结果,不断修正对事件概率的判断。
二、贝叶斯定理:数学公式与核心推导
2.1 贝叶斯公式的标准形式
贝叶斯定理的核心公式如下,这也是整个贝叶斯算法的基石:
公式中每个符号的含义:
P(A∣B):后验概率,在事件 B 发生的条件下,事件 A 发生的概率,也是我们最终想要求解的结果。
P(B∣A):似然概率,在事件 A 发生的条件下,事件 B 发生的概率。
P(A):先验概率,事件 A 本身发生的概率,不依赖于事件 B 的结果。
P(B):全概率,事件 B 发生的总概率,与事件 A 的分布无关。
2.2 经典场景推导:穿长裤的学生是女生的概率?
光看公式很难理解,我们用一个经典的校园场景,一步步推导出贝叶斯公式,彻底搞懂每个部分的含义。
场景设定:
某学校里,男生占总人数的 60%,女生占总人数的 40%;
男生全部穿长裤(100%),女生中有 50% 穿长裤,50% 穿裙子;
此时迎面走来一个穿长裤的学生,我们无法看清性别,求这个学生是女生的概率。
第一步:定义事件
事件 B:学生是女生,事件 C:学生穿长裤,我们要求解的目标:P(B∣C)(穿长裤的条件下,是女生的概率)
第二步:具象化计算(假设全校总人数 1000 人)
- 男生中穿长裤的人数:总人数×P(男生)×P(穿长裤∣男生)=1000×60%×100%=600人
- 女生中穿长裤的人数:总人数×P(女生)×P(穿长裤∣女生)=1000×40%×50%=200人
- 全校穿长裤的总人数:600+200=800人
- 穿长裤的学生是女生的概率:P(女生∣穿长裤)=女生中穿长裤的人数/穿长裤的总人数=200/800=25%
第三步:抽象为贝叶斯公式
我们把上面的计算过程去掉总人数,转化为概率形式:
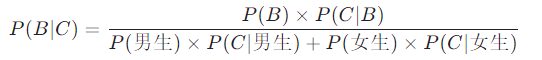
分母部分,正是穿长裤这件事的全概率P(C),因此公式就简化为标准的贝叶斯形式:
通过这个例子,我们能清晰地看到:贝叶斯公式本质上就是「目标事件的联合概率 / 观测事件的全概率」,完美解决了逆向概率的计算问题。
三、贝叶斯定理的实战应用:两个经典计算案例
为了巩固对贝叶斯公式的理解,我们再通过两个工业界高频的经典案例,完成纯数学层面的实战计算。
3.1 案例 1:色盲检测中的性别概率计算
问题设定:已知所有男子中有 5% 患色盲,所有女子中有 0.25% 患色盲;假设人群中男子和女子的人数相等,现在随机抽一个人,发现是色盲患者,求这个人是男子的概率。
解题过程:
定义事件:
- A:抽到男子;B:抽到女子;C:抽到色盲患者
- 目标:求解P(A∣C)(色盲条件下,是男子的概率)
已知概率:
- 先验概率:P(A)=P(B)=50%=0.5
- 似然概率:P(C∣A)=5%=0.05;P(C∣B)=0.25%=0.0025
代入贝叶斯公式计算:
结论:随机抽到的色盲患者,是男性的概率约为 95.24%。
3.2 案例 2:工厂次品溯源的概率计算
问题设定:某工厂有甲、乙、丙三个车间生产同一种产品,三个车间的产量分别占全厂总产量的 25%、35%、40%,对应的次品率依次为 5%、4%、2%。现在从待出厂的产品中查出一个次品,求这个次品是甲车间生产的概率。
解题过程:
定义事件:
- A1:甲车间生产;A2:乙车间生产;A3:丙车间生产;B:产品是次品
- 目标:求解P(A1∣B)(次品条件下,是甲车间生产的概率)
已知概率:
- 先验概率:P(A1)=25%=0.25;P(A2)=35%=0.35;P(A3)=40%=0.4
- 似然概率:P(B∣A1)=5%=0.05;P(B∣A2)=4%=0.04;P(B∣A3)=2%=0.02
代入贝叶斯公式计算:
结论:查出的次品,由甲车间生产的概率约为 36.23%。
四、朴素贝叶斯分类器:贝叶斯定理的工程化落地
理解了贝叶斯定理的核心,我们就可以进入工程化应用环节 ——朴素贝叶斯分类器,这是贝叶斯定理在机器学习中最常用的实现形式。
4.1 为什么是 “朴素”?特征条件独立假设
贝叶斯定理本身很简单,但在实际的分类任务中,样本往往有多个特征。比如判断一封邮件是不是垃圾邮件,可能有上百个词作为特征,此时如果直接用贝叶斯公式,多个特征的联合概率计算会变得极其复杂,甚至无法实现。而「朴素」的核心,就是引入了特征条件独立假设:假设样本的所有特征之间,在类别确定的条件下是相互独立的。
这个假设让复杂的联合概率计算,简化为多个单特征概率的乘积,极大降低了计算量,让贝叶斯定理能够真正落地到多特征的分类任务中。虽然这个假设在现实场景中不一定完全成立,但朴素贝叶斯分类器在绝大多数场景下,依然能给出非常不错的分类效果。
4.2 常用的朴素贝叶斯模型
根据特征分布的不同,sklearn 中提供了 3 种常用的朴素贝叶斯实现,适配不同的业务场景:
MultinomialNB(多项式朴素贝叶斯):本文实战所用的模型,适用于离散特征的分类任务,比如文本分类、词频统计类场景,对整数型特征适配性最好。
GaussianNB(高斯朴素贝叶斯):适用于连续型特征,假设特征符合高斯正态分布,比如鸢尾花数据集的花瓣、花萼长度等连续数值特征。
BernoulliNB(伯努利朴素贝叶斯):适用于布尔型 / 二值特征,只关注特征是否出现,不关注出现次数,适合二值化的文本分类场景。
五、Python 代码实战:基于鸢尾花数据集的朴素贝叶斯分类
接下来我们基于 Python 的 sklearn 机器学习库,用经典的鸢尾花数据集,完成朴素贝叶斯分类器的完整实现,包括模型训练、预测、混淆矩阵可视化、模型效果评估全流程。
5.1 环境准备
首先确保你的环境安装了所需的依赖库,执行以下安装命令:
pip install scikit-learn matplotlib numpy5.2 完整代码实现与逐行解析
# 1. 导入所需库
# 导入sklearn自带的鸢尾花数据集
from sklearn.datasets import load_iris
# 导入多项式朴素贝叶斯分类器
from sklearn.naive_bayes import MultinomialNB
# 导入模型评估指标
from sklearn import metrics
# 导入可视化库
import matplotlib.pyplot as plt
# 2. 定义混淆矩阵可视化函数
def cm_plot(y_true, y_pred):
"""
绘制分类结果的混淆矩阵
:param y_true: 真实标签
:param y_pred: 预测标签
:return: plt对象
"""
# 计算混淆矩阵
cm = metrics.confusion_matrix(y_true, y_pred)
# 绘制混淆矩阵热力图
plt.matshow(cm, cmap=plt.cm.Blues)
# 添加颜色条
plt.colorbar()
# 在矩阵中标注数值
for x in range(len(cm)):
for y in range(len(cm[x])):
plt.annotate(
cm[x][y],
xy=(y, x),
horizontalalignment="center",
verticalalignment="center",
color="white" if cm[x][y] > cm.max()/2 else "black"
)
# 设置坐标轴标签
plt.ylabel('True label(真实标签)')
plt.xlabel('Predicted label(预测标签)')
plt.title('朴素贝叶斯分类结果混淆矩阵', pad=20)
return plt
# 3. 加载数据集
# 加载鸢尾花数据集
iris = load_iris()
# 特征数据:花萼长度、花萼宽度、花瓣长度、花瓣宽度
X = iris.data
# 标签数据:鸢尾花的3个分类(山鸢尾、变色鸢尾、维吉尼亚鸢尾)
y = iris.target
# 查看数据集基本信息
print("数据集特征维度:", X.shape)
print("数据集标签类别:", iris.target_names)
# 4. 实例化并训练朴素贝叶斯分类器
# alpha=1 为拉普拉斯平滑,防止出现概率为0的情况
classifier = MultinomialNB(alpha=1)
# 用训练数据拟合模型
classifier.fit(X, y)
# 5. 模型预测
# 对数据集进行预测
y_pred = classifier.predict(X)
# 6. 混淆矩阵可视化
cm_plot(y, y_pred).show()
# 7. 输出模型分类结果报告
print("="*50)
print("朴素贝叶斯分类器性能评估报告")
print("="*50)
print(metrics.classification_report(y, y_pred, target_names=iris.target_names))核心代码说明:
拉普拉斯平滑(alpha=1):解决了训练集中某个特征没有出现时,概率为 0 导致整个后验概率为 0 的问题,是朴素贝叶斯工程化中必不可少的优化。
混淆矩阵:直观展示模型对每个类别的分类正确数和错误数,能清晰看到模型的分类偏差。
分类报告:包含精确率(Precision)、召回率(Recall)、F1-score、支持数(Support)四大核心指标,全面评估模型性能。
5.3 模型结果可视化与评估
运行上述代码后,会得到两个核心输出:
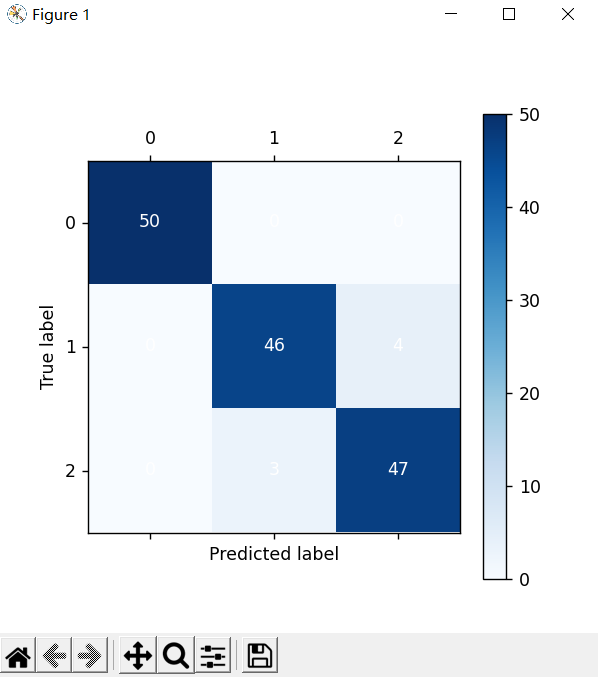
1.混淆矩阵可视化图
图中对角线的数值为分类正确的样本数,非对角线为分类错误的样本数。可以看到朴素贝叶斯分类器在鸢尾花数据集上,对大部分样本都实现了正确分类。
2.分类性能评估报告
典型的输出结果如下:
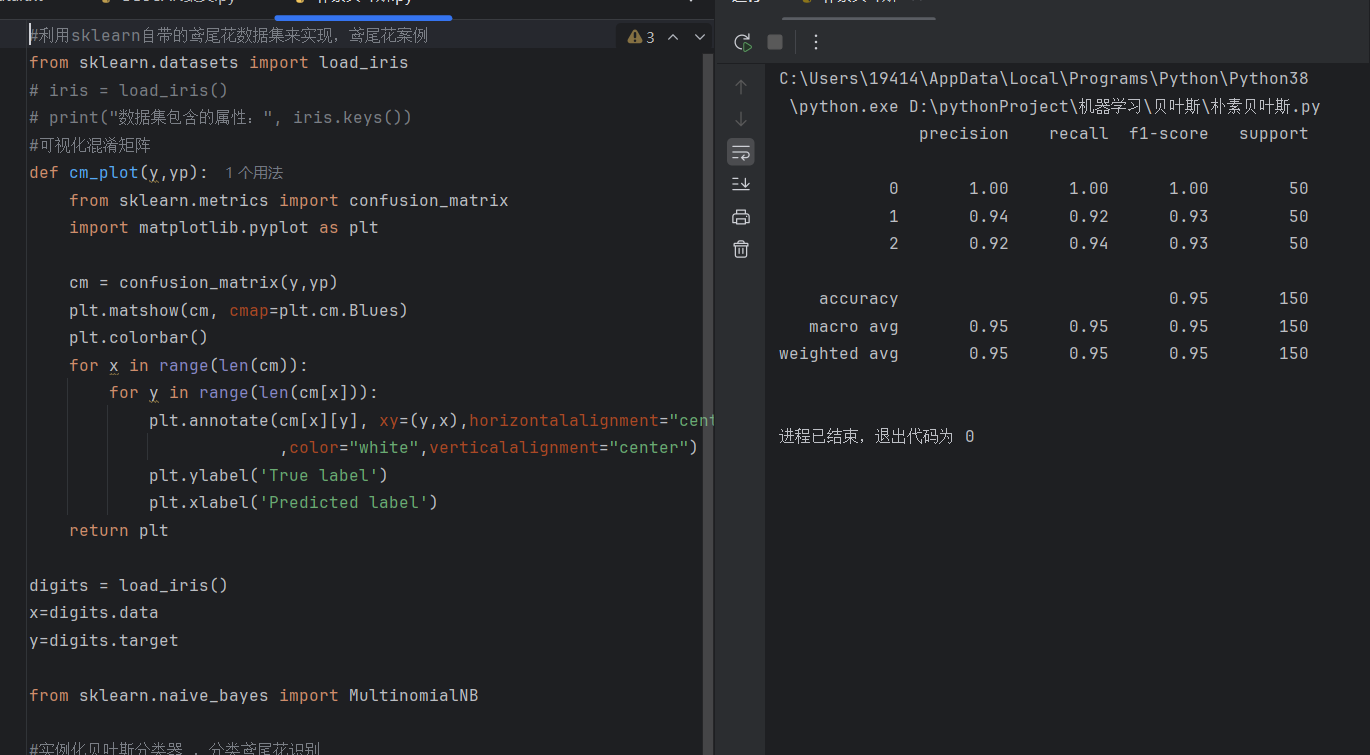
从报告中可以看到:
- 山鸢尾(setosa)类别实现了 100% 的完美分类;
- 模型整体准确率达到95%,对于简单的多项式朴素贝叶斯模型,在未做任何特征工程的情况下,已经实现了不错的分类效果;
六、朴素贝叶斯算法的优缺点与适用场景
6.1 核心优势
算法简单,训练和预测速度极快:仅需计算特征的概率分布,无需复杂的迭代优化,在高维稀疏数据上优势尤为明显。
对小数据集友好:在样本量较少的场景下,依然能保持不错的分类效果,泛化能力稳定。
对缺失数据不敏感:即使部分特征缺失,也能通过概率计算完成分类,鲁棒性强。
可解释性极强:分类结果完全基于概率推导,每一步都可以拆解和解释,符合风控、医疗等强解释性场景的要求。
支持增量训练:可以随时新增样本更新模型,无需重新全量训练,适合流式数据场景。
6.2 局限性
特征独立假设的限制:现实中很多特征存在相关性,此时朴素贝叶斯的分类效果会有所下降。
对先验概率依赖较强:先验概率的设定会直接影响后验概率的结果,如果先验分布不符合实际,会导致分类偏差。
对连续型特征的分布假设敏感:高斯朴素贝叶斯假设特征符合正态分布,如果实际数据分布不符,会影响分类精度。
6.3 主流应用场景
文本分类 / 垃圾邮件识别:这是朴素贝叶斯最经典的应用场景,基于词频特征实现邮件、评论的分类。
文本情感分析:对电商评论、社交媒体内容进行正面 / 负面情感判断。
推荐系统:结合协同过滤,通过用户行为的概率分布,实现个性化内容推荐。
医疗辅助诊断:基于患者的症状、检查指标,计算患病的概率,辅助医生诊断。
金融风控反欺诈:通过用户的交易行为、身份信息,判断欺诈风险的概率。
新闻主题分类:对海量新闻文本进行自动化的主题归类。
七、总结与延伸
贝叶斯算法的核心魅力,在于它提供了一套「用已知推未知」的概率推理框架,把我们对世界的先验认知,和观测到的实际结果结合起来,不断修正对事件的判断。而朴素贝叶斯分类器,正是这套框架最简洁、最高效的工程化实现,也是机器学习入门的必学算法。
当然,贝叶斯体系远不止朴素贝叶斯这一种实现,还有更复杂的贝叶斯网络、贝叶斯优化、隐马尔可夫模型(HMM)等进阶内容,它们在深度学习、强化学习、自然语言处理等领域都有广泛的应用。
本文从原理到实战,完整讲解了贝叶斯算法的核心内容,你可以基于本文的代码,尝试更换数据集(比如新闻文本数据集)、更换不同的朴素贝叶斯模型,进一步感受贝叶斯算法的强大之处。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)