基于Kolmogorov-Arnold网络的可解释齿轮箱故障诊断和特征剪枝验证(PyTorch)
本文提出了一种基于Kolmogorov-Arnold Network(KAN)的齿轮箱故障诊断方法。通过滑动窗口从振动信号中提取40维统计特征,利用KAN网络进行故障分类。与传统神经网络不同,KAN将可学习的B样条激活函数置于网络边上,实现了更好的可解释性。实验结果表明,KAN在短窗口数据下表现最优,并能直观展示各特征对诊断结果的影响。通过特征重要性分析和剪枝验证,KAN能有效识别关键故障特征,为
在工业设备故障诊断中,我们通常从振动信号里提取一堆统计特征(比如均值、峰值、峭度等),然后扔给一个分类器判断设备是好是坏。传统的分类器要么是黑盒(如神经网络),要么虽然解释性强但性能有限(如决策树)。这两年冒出来一种叫 Kolmogorov-Arnold Network(KAN) 的新网络,它和普通神经网络不一样:普通网络在节点上做固定的激活(比如ReLU),而KAN把可学习的激活函数放在边上,用B样条曲线来表示。这样一来,训练结束后,你就能直接看到每个输入特征对输出是怎么影响的——画出来就是一条曲线,能看出它是阈值型的、S型的还是平的,这比看一堆权重系数直观得多。本文拿KAN去干齿轮箱故障诊断的活,先把振动信号切成一段段,每段提取40个统计特征(4个传感器×10个指标),然后用KAN区分健康还是断齿。同时还跟7种传统机器学习模型和普通MLP做了对比,结果发现KAN在短窗口(数据少、波动大)时效果最好,而且它自带的解释能力让工程师能一眼看出哪些传感器、哪些统计量真正管用。最后,还根据KAN的权重把不重要的特征剪掉,发现剪完后模型性能几乎没变,说明KAN能帮我们找到最核心的故障特征。

算法步骤
数据准备与检查先确保齿轮箱振动数据按“Healthy”和“Broken Tooth”两个文件夹放好,每个文件夹里各有10个CSV文件(对应不同负载),总共20个。脚本会统计文件数量,确认结构正确。
滑动窗口特征提取对每个CSV文件,按不重叠的窗口(窗口长度分别为300、400、500、600、700、800个采样点)滑动,每个窗口内对4个传感器分别计算10个统计特征(均值、均方根、标准差、方差、偏度、峭度、峰峰值、波形因子、脉冲因子、裕度因子),这样每个窗口就变成一个40维的向量。再配上该窗口对应的负载值和健康/故障标签,保存成CSV文件,供后面所有模型使用。
传统机器学习模型基准测试用7种常见分类器(决策树、随机森林、SVM、朴素贝叶斯、K近邻、梯度提升、逻辑回归)对每个窗口大小的数据集做5折交叉验证,记录准确率、精确率、召回率,作为性能下限。
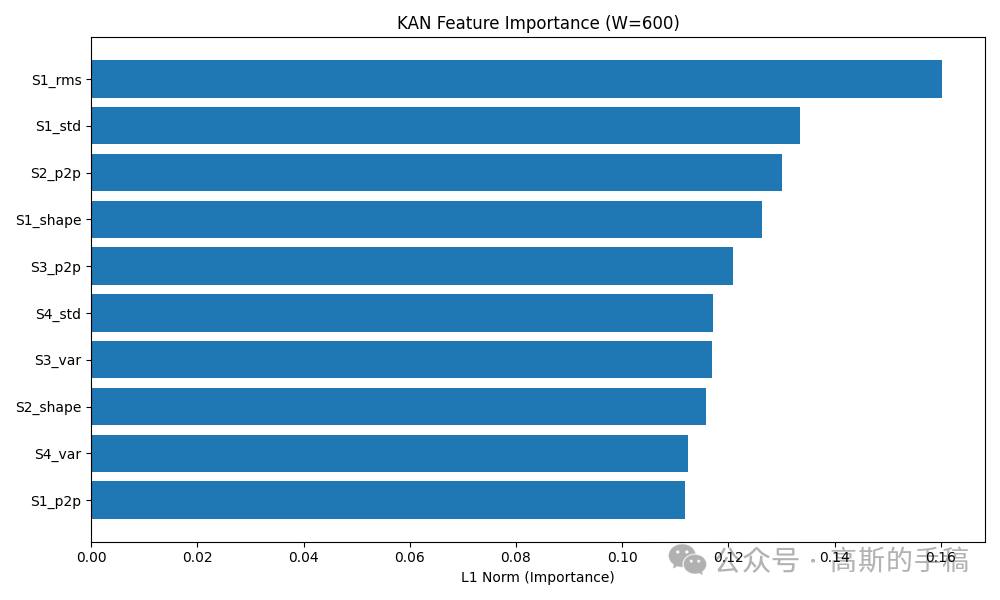
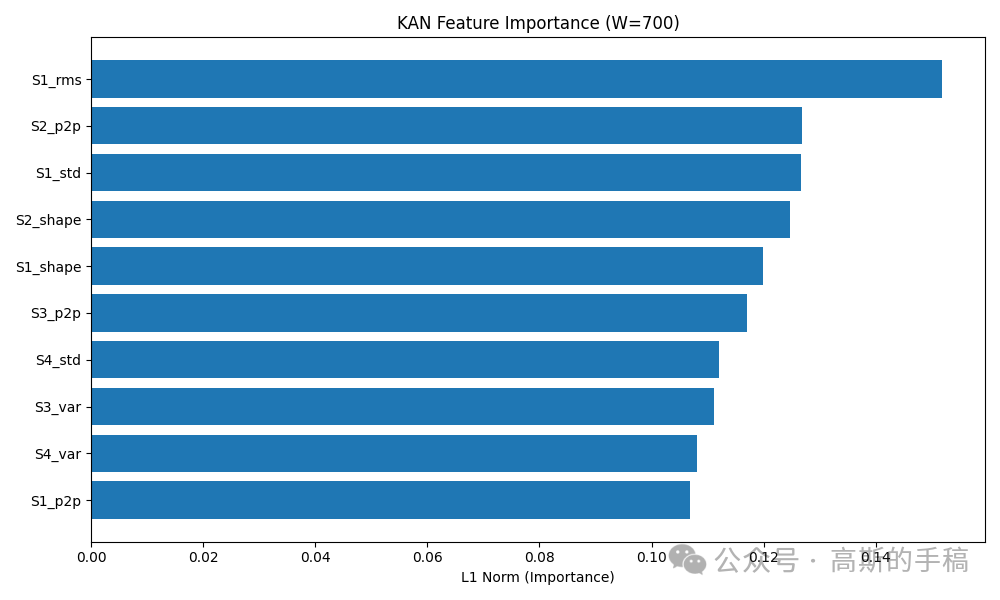
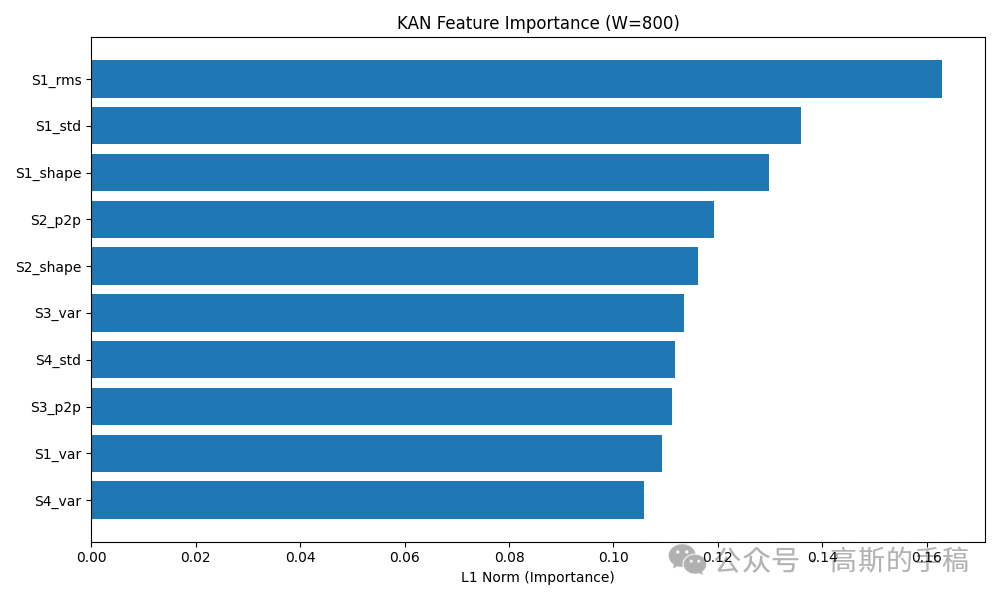
KAN与MLP训练与对比构建两个结构相同的网络:KAN(40→20→2)和MLP(40→20→2)。在相同的数据划分、随机种子、训练超参数下,分别做5折交叉验证。记录每个折的准确率、精确率、召回率和F1,并取平均。同时保存性能最好的KAN模型(通常是W=600窗口)供后续解释用。
可解释性分析
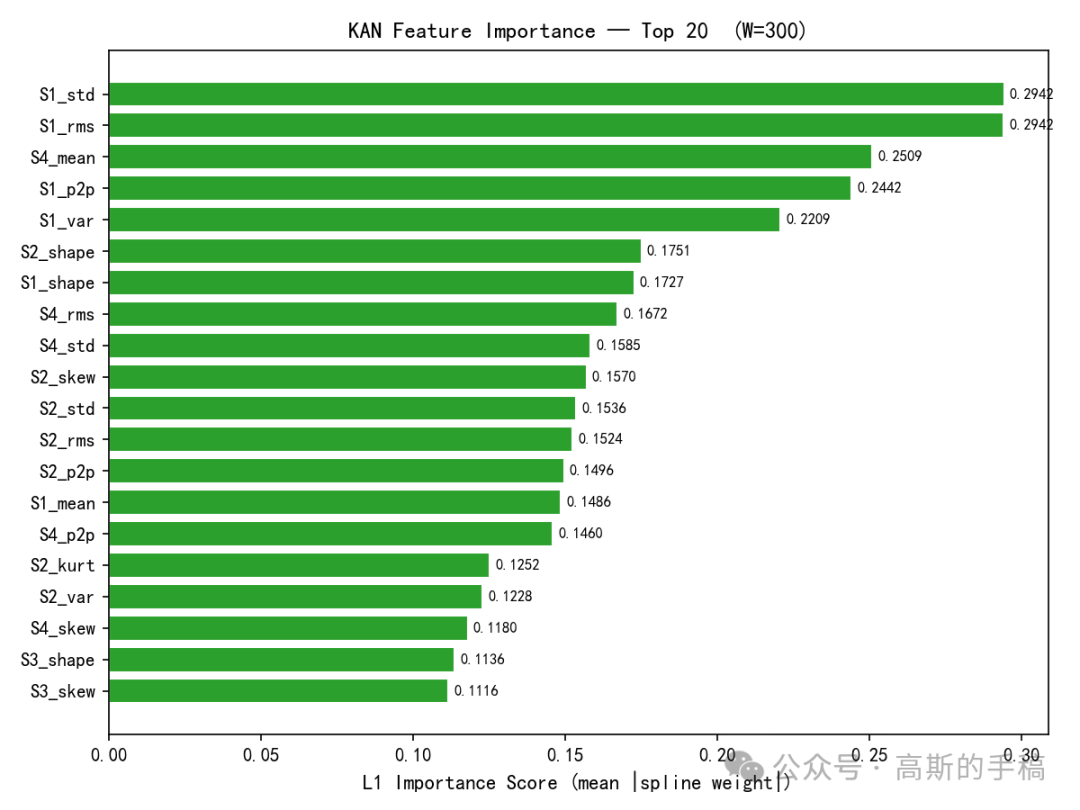
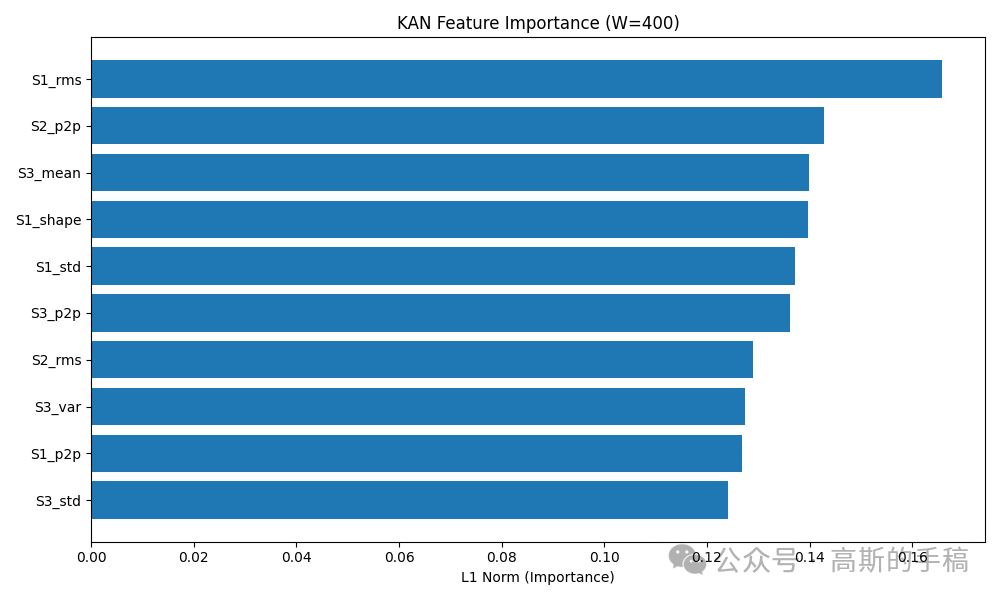
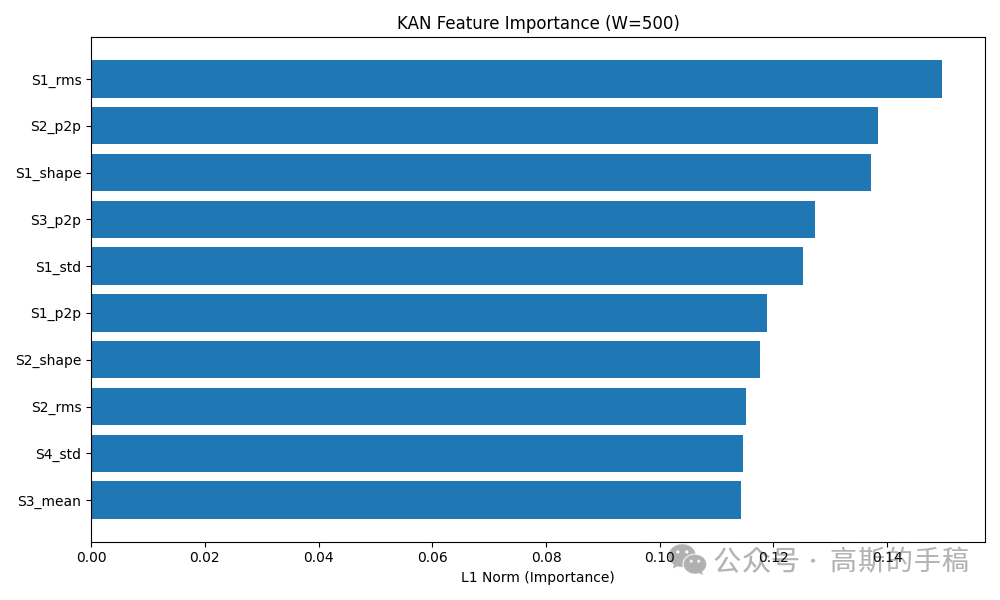
特征重要性排序:取KAN第一层每个输入特征对应的所有样条权重的绝对值之和,作为该特征的重要性分数。分数越高说明该特征对故障判断越关键。
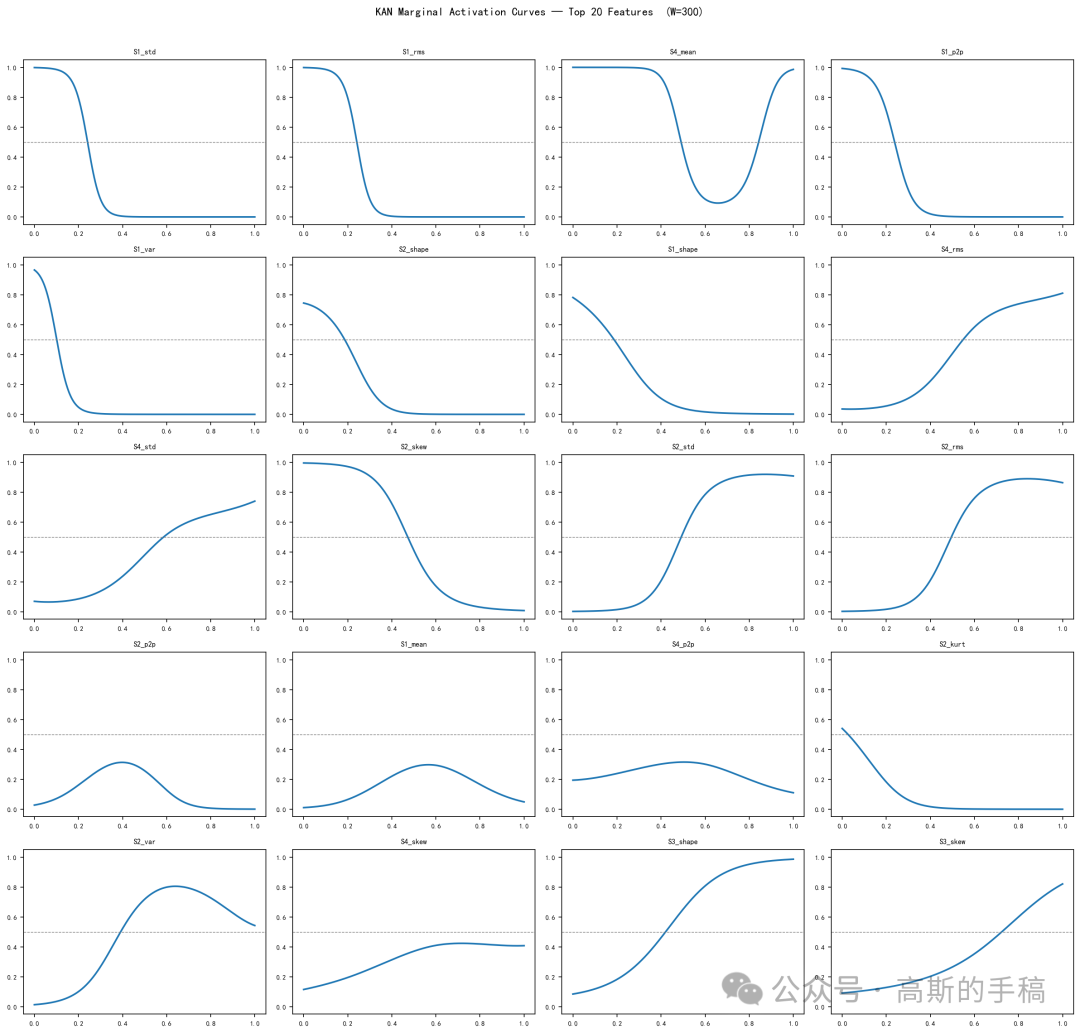
边际激活曲线:固定其他39个特征为平均值,只改变某一个特征的值(从最小到最大),看KAN输出的故障概率变化。画出的曲线能直观看出该特征是如何影响决策的:陡峭上升表示有明确阈值,平缓表示线性相关,几乎不动表示无关。
剪枝验证:按重要性分数去掉那些重要性低于最高分数5%的特征,然后用剩下的特征重新训练所有7个传统模型和KAN,比较剪枝前后性能变化。如果剪枝后性能几乎不降,说明KAN找到的特征子集确实抓住了故障的本质。
结果保存与可视化所有实验结果(准确率表、特征重要性排名、每条特征的激活曲线图、剪枝验证表)自动存入results/文件夹,方便论文使用。
def evaluate_window(filepath: str, save_kan_model: bool = False):
"""
对一个窗口大小的数据集进行KAN和MLP的5折交叉验证。
参数:
filepath: 特征CSV文件路径
save_kan_model: 是否保存该窗口下的最佳KAN模型(仅对W=600生效)
返回:
kan_avg, mlp_avg: 包含平均准确率、精确率、召回率、F1的字典
"""
df = pd.read_csv(filepath)
X = df.drop(columns=["label", "load"]).values # 40维特征
y = df["label"].values # 标签:0健康,1断齿
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# 存放每折的指标
kan_buf = {k: [] for k in ("acc", "prec", "rec", "f1")}
mlp_buf = {k: [] for k in ("acc", "prec", "rec", "f1")}
best_kan_acc = -1
best_kan_model = None
best_scaler = None
for fold, (tr_idx, te_idx) in enumerate(skf.split(X, y), 1):
# 划分训练集和测试集
X_tr_full, X_te = X[tr_idx], X[te_idx]
y_tr_full, y_te = y[tr_idx], y[te_idx]
# 再从训练集中分出15%作为验证集(用于早停)
X_tr, X_val, y_tr, y_val = train_test_split(
X_tr_full, y_tr_full,
test_size=0.15, stratify=y_tr_full, random_state=42
)
# 特征归一化(MinMax),注意只用训练集拟合,然后转换验证集和测试集
scaler = MinMaxScaler()
X_tr = scaler.fit_transform(X_tr)
X_val = scaler.transform(X_val)
X_te_s = scaler.transform(X_te)
# ---------- KAN 训练 ----------
kan = KAN(layers_hidden=[40, 20, 2],
grid_size=5, spline_order=3)
# train_model 函数内部实现训练、早停、测试
acc_k, prec_k, rec_k, f1_k, kan = train_model(
kan, X_tr, y_tr, X_val, y_val, X_te_s, y_te, use_closure=True
)
# 保存当前折的结果
kan_buf["acc"].append(acc_k); kan_buf["prec"].append(prec_k)
kan_buf["rec"].append(rec_k); kan_buf["f1"].append(f1_k)
# 如果是W=600,且当前折准确率更高,则保存模型和归一化参数
if save_kan_model and acc_k > best_kan_acc:
best_kan_acc = acc_k
best_kan_model = copy.deepcopy(kan.state_dict())
best_scaler = (scaler.data_min_.copy(),
scaler.data_max_.copy(),
scaler.scale_.copy())
# ---------- MLP 训练 ----------
mlp = MLP([40, 20, 2]) # 普通多层感知机,激活函数ReLU
acc_m, prec_m, rec_m, f1_m, _ = train_model(
mlp, X_tr, y_tr, X_val, y_val, X_te_s, y_te, use_closure=False
)
mlp_buf["acc"].append(acc_m); mlp_buf["prec"].append(prec_m)
mlp_buf["rec"].append(rec_m); mlp_buf["f1"].append(f1_m)
print(f" Fold {fold}: KAN {acc_k*100:.2f}% | MLP {acc_m*100:.2f}%")
# 保存最佳KAN模型
if save_kan_model and best_kan_model is not None:
os.makedirs("model", exist_ok=True)
torch.save(best_kan_model,
os.path.join("model", f"kan_best_W{SAVE_MODEL_FOR_W}.pt"))
np.save(os.path.join("model",
f"kan_best_W{SAVE_MODEL_FOR_W}_scaler.npy"),
np.array(best_scaler, dtype=object))
print(f" [Saved] Best-fold KAN model → model/kan_best_W{SAVE_MODEL_FOR_W}.pt")
# 对5折结果取平均,并转换为百分比
kan_avg = {k: np.mean(v) * 100 for k, v in kan_buf.items()}
mlp_avg = {k: np.mean(v) * 100 for k, v in mlp_buf.items()}
return kan_avg, mlp_avg
def train_model(model, X_tr, y_tr, X_val, y_val, X_te, y_te, use_closure=False):
"""
通用训练函数:支持KAN(需要closure)和MLP(标准梯度下降)。
返回测试集上的准确率、精确率、召回率、F1以及训练好的模型。
"""
# 转为PyTorch张量
X_tr_t = torch.tensor(X_tr, dtype=torch.float32)
y_tr_t = torch.tensor(y_tr, dtype=torch.long)
X_val_t = torch.tensor(X_val, dtype=torch.float32)
y_val_t = torch.tensor(y_val, dtype=torch.long)
X_te_t = torch.tensor(X_te, dtype=torch.float32)
# 数据加载器
loader = DataLoader(TensorDataset(X_tr_t, y_tr_t),
batch_size=512, shuffle=True)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
best_val_loss = float("inf")
best_state = None
patience = 0
for epoch in range(50):
model.train()
for bx, by in loader:
if use_closure:
# KAN需要closure函数,因为它内部可能使用二次优化
def closure():
optimizer.zero_grad()
loss = criterion(model(bx), by)
loss.backward()
return loss
optimizer.step(closure)
else:
optimizer.zero_grad()
loss = criterion(model(bx), by)
loss.backward()
optimizer.step()
# 验证集损失
model.eval()
with torch.no_grad():
val_loss = criterion(model(X_val_t), y_val_t).item()
# 早停:如果验证损失没有降低,就减少耐心
if val_loss < best_val_loss:
best_val_loss = val_loss
best_state = copy.deepcopy(model.state_dict())
patience = 0
else:
patience += 1
if patience >= 10:
break
# 加载最佳模型
if best_state:
model.load_state_dict(best_state)
# 在测试集上预测
model.eval()
with torch.no_grad():
preds = torch.argmax(model(X_te_t), dim=1).numpy()
# 计算指标
acc = accuracy_score(y_te, preds)
prec = precision_score(y_te, preds, average="macro", zero_division=0)
rec = recall_score(y_te, preds, average="macro", zero_division=0)
f1 = f1_score(y_te, preds, average="macro", zero_division=0)
return acc, prec, rec, f1, model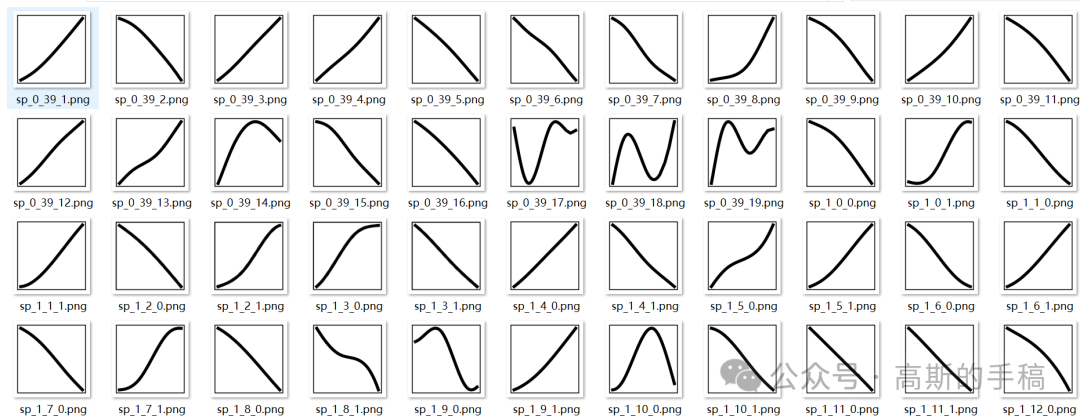
如果你对信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测有疑问,或者需要论文思路上的建议,欢迎咨询
担任《MSSP》《中国电机工程学报》《宇航学报》《控制与决策》等期刊审稿专家,擅长领域:信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 37
37 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)