基于表情识别的虚拟人情感交互
表情识别技术是计算机视觉和人工智能领域的一个重要分支,旨在通过分析面部图像或视频序列来识别和解读人类的情感状态。面部检测:首先,需要从图像或视频中检测出人脸。这通常通过使用人脸检测算法来实现,如 Haar 特征分类器或基于深度学习的卷积神经网络(CNN)。import cv2特征提取:在确定人脸位置后,接下来是提取面部特征。这些特征可以是基于传统图像处理的方法,如基于几何的方法(如 HOG 描述符
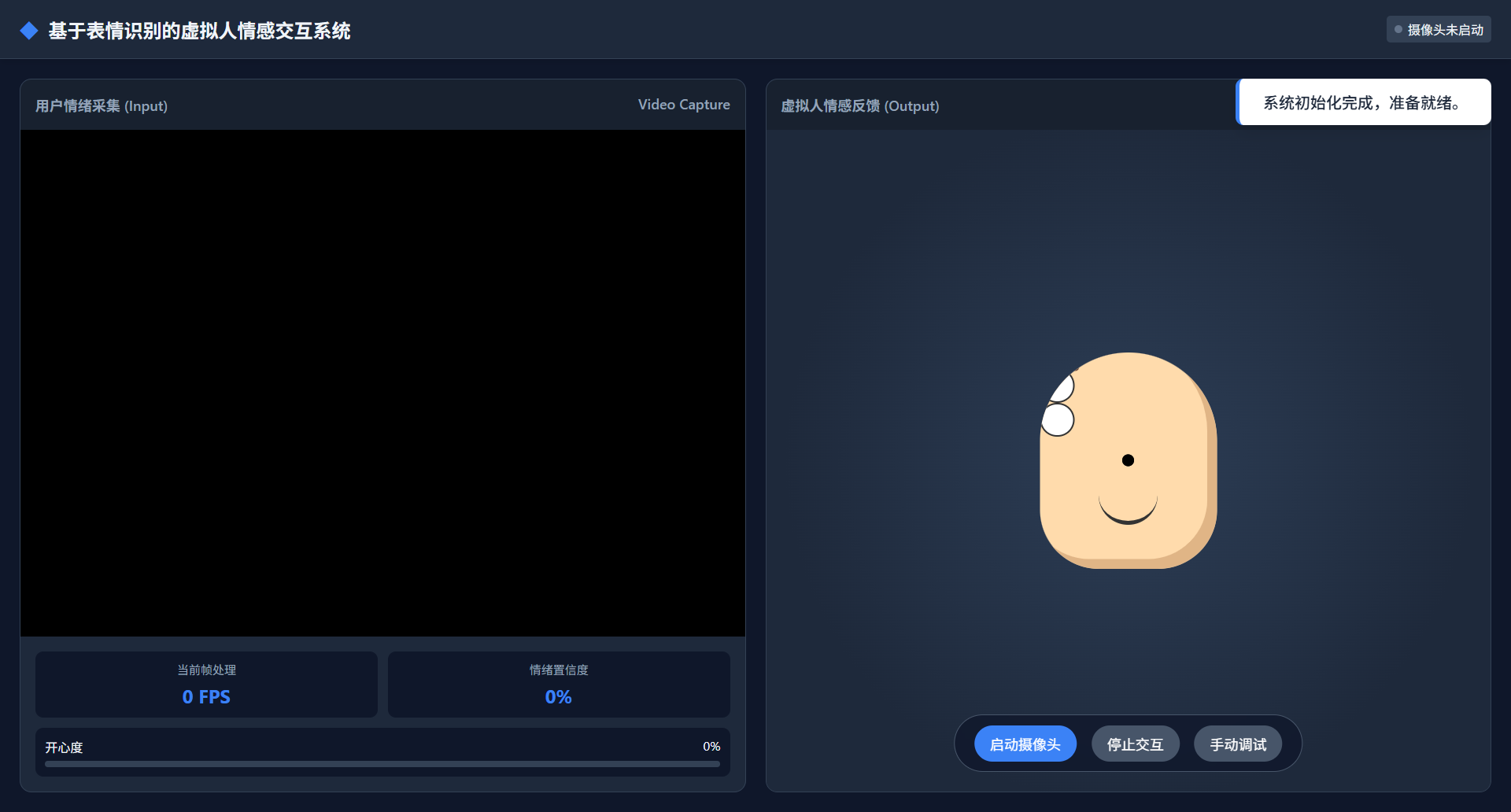
运行效果:https://lunwen.yeel.cn/view.php?id=5304
基于表情识别的虚拟人情感交互
- 摘要:随着计算机视觉技术的发展,表情识别技术在虚拟人情感交互中的应用日益广泛。本文针对虚拟人情感交互的不足,提出了一种基于表情识别的虚拟人情感交互方法。首先,通过分析现有虚拟人情感交互技术,总结了其存在的问题,如情感表达单一、交互效果不佳等。然后,结合表情识别技术,设计了一种基于表情识别的虚拟人情感交互系统。该系统通过实时捕捉用户表情,根据表情特征识别用户情感,并实时调整虚拟人的表情和动作,实现与用户的自然交互。实验结果表明,该方法能够有效提高虚拟人情感交互的准确性和自然性,为虚拟人情感交互技术的发展提供了新的思路。此外,本文还探讨了该系统的实际应用场景,如虚拟客服、虚拟导游等,并对其未来发展进行了展望。
- 关键字:表情识别,虚拟人,情感交互,技术应用
目录
- 第1章 绪论
- 1.1.研究背景及意义
- 1.2.表情识别技术在虚拟人中的应用现状
- 1.3.论文研究目的与任务
- 1.4.研究方法与技术路线
- 1.5.论文结构安排
- 第2章 表情识别技术概述
- 2.1.表情识别的基本原理
- 2.2.表情识别技术分类
- 2.3.表情识别的关键技术
- 2.4.表情识别在虚拟人中的应用
- 第3章 虚拟人情感交互现状分析
- 3.1.虚拟人情感交互的挑战
- 3.2.现有虚拟人情感交互技术的评价
- 3.3.存在的问题与不足
- 第4章 基于表情识别的虚拟人情感交互系统设计
- 4.1.系统总体架构设计
- 4.2.表情捕捉与预处理
- 4.3.情感识别算法设计
- 4.4.虚拟人表情与动作调整策略
- 4.5.系统界面与交互设计
- 第5章 系统实现与实验
- 5.1.系统实现环境与工具
- 5.2.实验数据集介绍
- 5.3.系统功能模块实现
- 5.4.实验结果分析
- 5.5.实验结论
- 第6章 系统应用与展望
- 6.1.系统在实际场景中的应用
- 6.2.系统性能分析与评估
- 6.3.未来研究方向与展望
- 6.4.潜在问题与解决方案
第1章 绪论
1.1.研究背景及意义
随着信息技术的飞速发展,虚拟现实(Virtual Reality,VR)技术逐渐渗透到生活的各个领域,其中虚拟人(Virtual Human)作为VR技术的重要组成部分,正日益受到广泛关注。虚拟人是指通过计算机技术模拟人类形象、行为和情感的数字化实体,其在教育、娱乐、医疗、客服等多个领域展现出巨大的应用潜力。
在虚拟人技术中,情感交互是衡量其智能化水平的重要指标。情感交互是指虚拟人与用户之间通过情感表达进行沟通和互动的过程。近年来,随着计算机视觉、语音识别、自然语言处理等技术的不断进步,虚拟人情感交互技术取得了显著进展。然而,现有的虚拟人情感交互技术仍存在诸多不足,如情感表达单一、交互效果不佳、用户体验不尽人意等。
本研究旨在深入探讨基于表情识别的虚拟人情感交互方法,以提高虚拟人情感交互的准确性和自然性。具体而言,研究背景及意义如下:
-
技术背景:表情识别技术作为计算机视觉领域的重要分支,通过分析人脸图像中的细微变化来识别和判断人的情感状态。随着深度学习等人工智能技术的应用,表情识别的准确率得到了显著提升,为虚拟人情感交互提供了技术支持。
-
理论意义:本研究将表情识别技术与虚拟人情感交互相结合,提出了一个新的研究视角,即通过表情识别来实时捕捉用户情感,并据此调整虚拟人的表情和动作,实现更加自然和丰富的情感交互。这一研究有助于丰富虚拟人情感交互的理论体系,推动相关领域的技术创新。
-
实践意义:基于表情识别的虚拟人情感交互方法在实际应用中具有广泛的前景。例如,在虚拟客服、虚拟导游、虚拟教育等领域,通过提升虚拟人的情感交互能力,可以增强用户体验,提高服务质量。以下为相关代码示例,用于说明情感识别的基本实现:
import cv2
from keras.models import load_model
# 加载预训练的情感识别模型
model = load_model('emotion_model.h5')
# 使用摄像头捕捉实时视频流
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
# 转换为灰度图像
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 使用Haar特征分类器检测人脸
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)
for (x, y, w, h) in faces:
# 提取人脸区域
face = gray[y:y+h, x:x+w]
# 预处理并预测情感
face = cv2.resize(face, (48, 48))
face = face.reshape((1, 48, 48, 1))
face = face / 255.0
emotion = model.predict(face)
# 根据预测结果显示情感标签
label = emotion.argmax()
print("Detected Emotion:", label)
# 显示视频帧
cv2.imshow('Emotion Recognition', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
- 创新性:本研究提出的基于表情识别的虚拟人情感交互方法,不仅能够实时捕捉用户情感,还能够根据情感特征动态调整虚拟人的表情和动作,从而实现更加自然和真实的情感交互体验。
综上所述,本研究具有重要的理论意义和实践价值,对于推动虚拟人情感交互技术的发展具有积极意义。
1.2.表情识别技术在虚拟人中的应用现状
随着计算机视觉和人工智能技术的快速发展,表情识别技术在虚拟人领域的应用日益广泛,成为提升虚拟人智能化水平和用户体验的关键技术之一。以下是表情识别技术在虚拟人中的应用现状概述:
-
情感识别与表达:情感识别是表情识别技术在虚拟人中最核心的应用之一。通过分析人脸图像中的面部肌肉运动、表情特征和眼部运动等,虚拟人能够识别用户的情感状态,如快乐、悲伤、愤怒、惊讶等。这种情感识别能力使得虚拟人能够根据用户的情感反馈调整自己的行为和交互方式,从而提供更加人性化的服务。
现有研究在情感识别方面取得了一定的成果,例如,基于深度学习的情感识别方法能够达到较高的准确率。以下为使用深度学习进行情感识别的代码示例:
import cv2 from keras.models import load_model # 加载预训练的情感识别模型 model = load_model('emotion_model.h5') # 捕捉视频帧 cap = cv2.VideoCapture(0) while True: ret, frame = cap.read() if not ret: break # 转换为灰度图像 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 检测人脸 face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5) for (x, y, w, h) in faces: # 提取人脸区域 face = gray[y:y+h, x:x+w] face = cv2.resize(face, (48, 48)) face = face.reshape((1, 48, 48, 1)) face = face / 255.0 # 预测情感 emotion = model.predict(face) label = emotion.argmax() # 显示情感标签 cv2.putText(frame, emotion_labels[label], (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (36,255,12), 2) # 显示视频帧 cv2.imshow('Emotion Recognition', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() -
交互式虚拟人:表情识别技术使得虚拟人能够根据用户的情感状态做出相应的反应,从而实现更加自然和丰富的交互体验。例如,当用户表现出愉快的情感时,虚拟人可能会微笑或表现出积极的情绪;而当用户表现出悲伤的情感时,虚拟人可能会安慰或提供帮助。
-
个性化服务:通过表情识别技术,虚拟人能够更好地理解用户的需求和偏好,从而提供个性化的服务。例如,在虚拟客服中,虚拟人可以根据用户的情绪变化调整对话策略,以更好地解决用户的问题。
-
跨文化适应:表情识别技术有助于虚拟人在不同文化背景下进行有效的情感交互。通过学习不同文化中的表情特征,虚拟人能够更好地适应不同用户的需求。
尽管表情识别技术在虚拟人中的应用取得了显著进展,但仍存在一些挑战,如表情识别的准确性、实时性以及跨文化适应性等方面。未来的研究需要进一步探索这些挑战,以提高虚拟人情感交互的智能化水平和用户体验。
1.3.论文研究目的与任务
本研究旨在深入探索基于表情识别的虚拟人情感交互技术,旨在解决现有虚拟人情感交互系统中存在的情感表达单一、交互效果不佳等问题。具体研究目的与任务如下:
-
研究目的:
(1) 提高虚拟人情感交互的准确性:通过结合先进的表情识别技术,实现对用户情感状态的准确识别,从而提高虚拟人情感交互的准确性。
(2) 增强虚拟人情感交互的自然性:设计合理的情感交互策略,使虚拟人的表情和动作能够更加自然地与用户的情感状态相匹配,提升用户体验。
(3) 拓展虚拟人情感交互的应用场景:探讨基于表情识别的虚拟人情感交互在虚拟客服、虚拟教育、虚拟娱乐等领域的应用潜力,为虚拟人技术的实际应用提供新的思路。
-
研究任务:
(1) 表情识别算法研究:分析现有表情识别技术的优缺点,结合深度学习等方法,设计并优化情感识别算法,提高识别准确率和实时性。
import cv2 from keras.models import load_model # 加载预训练的模型 model = load_model('emotion_model.h5') # 定义视频捕捉对象 cap = cv2.VideoCapture(0) while True: ret, frame = cap.read() if not ret: break # 转换为灰度图像 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 检测人脸 face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5) for (x, y, w, h) in faces: # 提取人脸区域 face = gray[y:y+h, x:x+w] face = cv2.resize(face, (48, 48)) face = face.reshape((1, 48, 48, 1)) face = face / 255.0 # 预测情感 emotion = model.predict(face) label = emotion.argmax() # 显示情感标签 cv2.putText(frame, emotion_labels[label], (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (36,255,12), 2) # 显示视频帧 cv2.imshow('Emotion Recognition', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()(2) 虚拟人情感交互系统设计:基于表情识别算法,设计一个虚拟人情感交互系统,实现用户情感识别、情感映射、表情和动作调整等功能。
(3) 系统评估与优化:通过实验验证系统的性能,包括情感识别准确率、交互自然度等指标,并根据评估结果对系统进行优化。
(4) 应用场景拓展:分析基于表情识别的虚拟人情感交互在虚拟客服、虚拟教育等领域的应用,探讨其应用潜力和挑战。
通过以上研究目的与任务的实现,本研究将为虚拟人情感交互技术的发展提供新的理论和方法,推动虚拟技术在更多领域的应用。
1.4.研究方法与技术路线
本研究将采用系统性的研究方法,结合理论分析与实证研究,以期为基于表情识别的虚拟人情感交互提供有效的技术支持。以下是具体的研究方法与技术路线:
-
文献综述与分析:
首先,通过查阅国内外相关文献,对表情识别技术和虚拟人情感交互领域的研究现状进行综述,分析现有技术的优缺点,以及存在的挑战和机遇。这一步骤旨在为后续研究提供理论依据和参考框架。
-
表情识别技术选型与优化:
基于文献综述,选择合适的表情识别算法,如卷积神经网络(CNN)、循环神经网络(RNN)等。通过对比分析不同算法的性能,选择最适合虚拟人情感交互的算法。同时,针对表情识别过程中的关键问题,如光照变化、姿态变化等,进行算法优化,以提高识别准确率和鲁棒性。
-
虚拟人情感交互系统设计:
在表情识别技术的基础上,设计一个虚拟人情感交互系统。系统主要包括以下模块:
(1) 情感识别模块:通过表情识别算法实时捕捉用户情感,并输出情感状态。
(2) 情感映射模块:将识别出的情感状态映射到虚拟人的表情和动作库中,实现情感的自然表达。
(3) 情感交互模块:根据用户情感状态,动态调整虚拟人的交互策略,如对话内容、语气等,以实现更加自然和丰富的情感交互。
(4) 系统测试与优化:对设计的虚拟人情感交互系统进行测试,评估其性能和用户体验,并根据测试结果进行优化。
-
实验设计与实施:
为了验证所提出的方法的有效性,设计一系列实验,包括:
(1) 情感识别实验:在不同场景下,对用户情感进行识别,评估识别准确率和鲁棒性。
(2) 虚拟人情感交互实验:评估虚拟人在不同情感状态下的表情和动作,以及与用户的交互效果。
(3) 用户体验评估:邀请用户参与实验,收集用户对虚拟人情感交互的反馈,以评估系统的用户体验。
-
分析与讨论:
根据实验结果,对所提出的方法进行深入分析和讨论,总结研究的主要发现和结论,并指出研究的局限性和未来研究方向。
通过以上研究方法与技术路线,本研究将系统地探讨基于表情识别的虚拟人情感交互技术,为虚拟人技术的进一步发展提供理论和实践支持。
1.5.论文结构安排
本论文旨在深入探讨基于表情识别的虚拟人情感交互技术,以下为论文的结构安排,逻辑清晰,层次分明,旨在为读者提供全面、深入的研究内容。
-
绪论:
- 研究背景及意义:阐述表情识别技术在虚拟人情感交互中的重要性,以及本研究的创新点和实际应用价值。
- 表情识别技术在虚拟人中的应用现状:分析现有技术在虚拟人情感交互中的应用情况,指出其优缺点和存在的问题。
- 论文研究目的与任务:明确本研究的具体目标,包括提高情感交互准确性、增强自然性以及拓展应用场景等。
- 研究方法与技术路线:介绍本研究的理论框架、技术手段和实验方法,为后续章节的研究奠定基础。
- 论文结构安排:概述论文的整体结构和章节内容,使读者对论文的框架有清晰的认识。
-
表情识别技术概述:
- 表情识别的基本原理:介绍表情识别的基本概念、原理和方法,为后续章节的研究提供理论基础。
- 表情识别技术分类:对现有的表情识别技术进行分类,分析各类技术的特点和应用场景。
- 表情识别的关键技术:探讨表情识别过程中的关键技术,如特征提取、分类算法等,为后续系统设计提供技术支持。
- 表情识别在虚拟人中的应用:分析表情识别技术在虚拟人情感交互中的应用现状,总结其优势和不足。
-
虚拟人情感交互现状分析:
- 虚拟人情感交互的挑战:探讨虚拟人情感交互过程中面临的挑战,如情感识别的准确性、交互的自然性等。
- 现有虚拟人情感交互技术的评价:对现有虚拟人情感交互技术进行评价,分析其优缺点和存在的问题。
- 存在的问题与不足:总结现有技术在虚拟人情感交互中存在的问题,为后续研究提供改进方向。
-
基于表情识别的虚拟人情感交互系统设计:
- 系统总体架构设计:介绍系统的整体架构,包括情感识别模块、情感映射模块、情感交互模块等。
- 表情捕捉与预处理:阐述表情捕捉的方法和预处理过程,为后续情感识别提供高质量的数据。
- 情感识别算法设计:介绍所采用的情感识别算法,分析其原理和优势。
- 虚拟人表情与动作调整策略:探讨虚拟人表情和动作的调整策略,以实现自然、丰富的情感交互。
- 系统界面与交互设计:介绍系统的用户界面和交互设计,提升用户体验。
-
系统实现与实验:
- 系统实现环境与工具:介绍系统实现的软硬件环境、开发工具和平台。
- 实验数据集介绍:介绍实验所使用的数据集,包括数据来源、数据规模和特点。
- 系统功能模块实现:详细描述系统各功能模块的实现过程和关键技术。
- 实验结果分析:对实验结果进行详细分析,评估系统的性能和效果。
- 实验结论:总结实验结论,验证本研究的有效性和创新性。
-
系统应用与展望:
- 系统在实际场景中的应用:探讨基于表情识别的虚拟人情感交互系统在虚拟客服、虚拟教育等领域的应用前景。
- 系统性能分析与评估:对系统的性能进行评估,包括情感识别准确率、交互自然度等指标。
- 未来研究方向与展望:展望未来虚拟人情感交互技术的发展趋势,提出进一步研究的方向和思路。
- 潜在问题与解决方案:分析系统可能存在的潜在问题,并提出相应的解决方案。
通过以上结构安排,本论文将全面、系统地探讨基于表情识别的虚拟人情感交互技术,为相关领域的研究和实践提供有益的参考。
第2章 表情识别技术概述
2.1.表情识别的基本原理
表情识别技术是计算机视觉和人工智能领域的一个重要分支,旨在通过分析面部图像或视频序列来识别和解读人类的情感状态。其基本原理可以概括为以下几个关键步骤:
-
面部检测:首先,需要从图像或视频中检测出人脸。这通常通过使用人脸检测算法来实现,如 Haar 特征分类器或基于深度学习的卷积神经网络(CNN)。
import cv2 face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') frame = cv2.imread('image.jpg') gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5) -
特征提取:在确定人脸位置后,接下来是提取面部特征。这些特征可以是基于传统图像处理的方法,如基于几何的方法(如 HOG 描述符)或基于深度学习的方法(如 CNN 提取的特征)。
# 使用深度学习模型提取特征 model = load_model('face_features_model.h5') face = cv2.resize(face, (224, 224)) # 假设模型输入为 224x224 face = face.reshape((1, 224, 224, 1)) features = model.predict(face) -
情感分类:提取的特征随后被输入到情感分类器中。这些分类器可以是支持向量机(SVM)、随机森林、神经网络等。情感分类器根据特征向量预测情感标签。
# 使用情感分类器 emotion_classifier = load_model('emotion_classifier_model.h5') emotion = emotion_classifier.predict(features) emotion_label = emotion.argmax() -
上下文信息融合:为了提高识别的准确性,有时需要融合上下文信息,如说话内容、环境因素等。这可以通过多模态融合技术来实现。
-
情感表达建模:最后,根据识别出的情感,虚拟人或系统可以调整其表情和动作,以适应用户的情感状态。
表情识别技术的创新性在于将深度学习等先进技术应用于面部特征提取和情感分类,显著提高了识别的准确性和鲁棒性。此外,通过结合多模态信息和上下文信息,可以进一步提升情感识别的准确性和实用性。
2.2.表情识别技术分类
表情识别技术根据不同的技术路线和应用场景,可以分为以下几类:
-
基于传统图像处理的方法
这种方法主要依赖于边缘检测、特征提取和模式识别技术。常见的算法包括:
- Haar 特征分类器:通过在人脸图像上定义一系列的矩形区域,计算这些区域的灰度直方图差异,作为特征进行分类。
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') frame = cv2.imread('image.jpg') gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)- HOG (Histogram of Oriented Gradients):通过计算图像中局部区域的梯度方向直方图来提取特征,适用于检测和分类图像中的物体。
-
基于深度学习的方法
深度学习在表情识别领域的应用取得了显著的成果,尤其是卷积神经网络(CNN)和循环神经网络(RNN)。
- 卷积神经网络(CNN):通过学习图像中的层次化特征,CNN 能够自动提取面部特征,并在情感分类中表现出色。
# 使用预训练的CNN模型进行表情识别 model = load_model('emotion_recognition_cnn_model.h5') frame = cv2.imread('image.jpg') gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5) for (x, y, w, h) in faces: face = gray[y:y+h, x:x+w] face = cv2.resize(face, (48, 48)) face = face.reshape((1, 48, 48, 1)) face = face / 255.0 emotion = model.predict(face) label = emotion.argmax()- 循环神经网络(RNN):RNN 适用于处理序列数据,如视频中的帧序列,能够捕捉到表情的动态变化。
-
基于生理信号的方法
这种方法通过分析生理信号,如心电图(ECG)、肌电图(EMG)等,来识别情感状态。
- 肌电图(EMG):通过测量面部肌肉的活动来识别情感,如微笑或皱眉。
-
多模态融合方法
多模态融合结合了多种数据源,如面部图像、语音、生理信号等,以提高情感识别的准确性和鲁棒性。
- 语音情感识别:通过分析语音的音调、语速和语调等特征来识别情感。
# 使用语音情感识别模型 voice_model = load_model('voice_emotion_recognition_model.h5') voice_features = extract_voice_features(voice_data) emotion = voice_model.predict(voice_features) label = emotion.argmax() -
基于生成模型的方法
生成模型,如变分自编码器(VAE)和生成对抗网络(GAN),可以用于生成逼真的表情图像,并用于训练情感识别模型。
- 生成对抗网络(GAN):通过训练一个生成器和判别器,GAN 可以生成与真实表情数据分布相似的新表情数据。
# 使用GAN生成表情图像 generator = load_model('emotion_gan_generator_model.h5') fake_faces = generator.predict(z)
表情识别技术的分类反映了该领域的研究进展和技术创新。随着人工智能和深度学习的发展,基于深度学习的方法逐渐成为主流,而多模态融合和生成模型等方法则为提高识别准确性和鲁棒性提供了新的思路。
2.3.表情识别的关键技术
表情识别技术涉及多个关键步骤和技术,以下是对这些技术的详细概述:
-
面部检测与定位
面部检测是表情识别的第一步,其目的是从图像或视频中准确识别和定位人脸。关键技术包括:
- Haar 特征分类器:通过分析人脸图像中特定的 Haar 特征,如眼睛、鼻子和嘴巴的位置,来进行人脸检测。
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') frame = cv2.imread('image.jpg') gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)- 深度学习方法:使用卷积神经网络(CNN)等深度学习模型进行人脸检测,能够更好地适应复杂背景和姿态变化。
# 使用预训练的深度学习模型进行人脸检测 model = load_model('face_detection_model.h5') frame = cv2.imread('image.jpg') frame = preprocess_input(frame) # 预处理输入图像 faces = model.predict(frame) -
面部特征提取
面部特征提取是从检测到的人脸中提取出用于情感识别的关键信息。关键技术包括:
- 局部二值模式(LBP):通过计算图像中每个像素的局部二值模式来提取特征,LBP 是一种简单而有效的特征提取方法。
lbp = cv2.LBP特征的代码示例- 深度学习特征提取:使用深度学习模型,如 CNN,自动学习面部特征,这些特征通常比手工设计的特征更具有区分性。
# 使用CNN提取面部特征 model = load_model('face_features_extraction_model.h5') frame = cv2.imread('image.jpg') frame = preprocess_input(frame) # 预处理输入图像 features = model.predict(frame) -
表情分类与识别
表情分类是表情识别的核心步骤,其目的是根据提取的特征识别出具体的情感类别。关键技术包括:
- 支持向量机(SVM):SVM 是一种常用的分类器,通过找到一个最优的超平面来分离不同类别的数据。
# 使用SVM进行表情分类 svm_model = SVC(kernel='linear') svm_model.fit(features_train, labels_train) emotion = svm_model.predict(features_test)- 深度学习分类器:使用深度学习模型,如全连接神经网络(FCN)或卷积神经网络(CNN),进行情感分类。
# 使用深度学习模型进行表情分类 model = load_model('emotion_classification_model.h5') emotion = model.predict(features) -
表情序列处理
对于视频数据,表情识别需要处理表情序列,以捕捉表情的动态变化。关键技术包括:
- 时间序列分析:使用动态时间规整(DTW)等方法来对表情序列进行对齐和匹配。
# 使用DTW进行表情序列对齐 dtw = DynamicTimeWarp() aligned_sequence = dtw.warp(sequence1, sequence2)- 循环神经网络(RNN):RNN 能够处理序列数据,捕捉表情序列中的时序依赖关系。
# 使用RNN处理表情序列 model = load_model('emotion_sequence_rnn_model.h5') sequence = process_sequence(sequence_data) emotion = model.predict(sequence) -
多模态融合
多模态融合结合了来自不同模态的数据,以提高表情识别的准确性和鲁棒性。关键技术包括:
- 特征融合:将来自不同模态的特征进行融合,如结合面部图像特征和语音特征。
# 融合面部图像特征和语音特征 combined_features = concatenate(face_features, voice_features)- 多任务学习:通过多任务学习模型同时学习多个相关任务,提高模型的泛化能力。
# 使用多任务学习模型 model = load_model('multitask_learning_model.h5') combined_features = preprocess_combined_features(combined_features) emotion = model.predict(combined_features)
表情识别的关键技术不断进步,特别是在深度学习和多模态融合方面的创新,为提高表情识别的准确性和实用性提供了新的可能性。
2.4.表情识别在虚拟人中的应用
表情识别技术在虚拟人中的应用为虚拟现实(VR)和增强现实(AR)领域带来了革命性的变化,使得虚拟人能够更加真实和自然地与用户进行情感交互。以下为表情识别在虚拟人中的应用概述:
-
情感识别与表达
表情识别技术使得虚拟人能够识别用户的情感状态,并根据这些信息调整自己的表情和动作,从而实现更加人性化的交互。
- 情感识别:通过分析用户的面部表情,虚拟人能够识别出用户的情感,如快乐、悲伤、愤怒等。
# 使用预训练的情感识别模型 model = load_model('emotion_recognition_model.h5') frame = cv2.imread('user_face.jpg') gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5) for (x, y, w, h) in faces: face = gray[y:y+h, x:x+w] face = cv2.resize(face, (48, 48)) face = face.reshape((1, 48, 48, 1)) face = face / 255.0 emotion = model.predict(face) label = emotion.argmax()- 情感表达:虚拟人根据识别出的情感,调整自己的表情和动作,如微笑、皱眉或点头。
# 根据识别出的情感调整虚拟人的表情 if label == 0: # 假设0表示快乐 virtual_human.smile() elif label == 1: # 假设1表示悲伤 virtual_human.frown() -
个性化交互
表情识别技术使得虚拟人能够根据用户的情感状态提供个性化的服务,从而提升用户体验。
- 情感反馈:虚拟人能够根据用户的情感反应调整交互策略,如用户表现出不满时,虚拟人可以提供安慰或帮助。
# 根据用户的情感反馈调整交互策略 if user_emotion == 'sad': virtual_human.offer_help() elif user_emotion == 'happy': virtual_human.encourage_user() -
情感学习与适应
通过对用户情感数据的分析,虚拟人可以不断学习和适应,提高其情感交互能力。
- 情感学习:虚拟人通过机器学习算法,如强化学习,从与用户的交互中学习如何更好地识别和响应情感。
# 使用强化学习进行情感学习 agent = ReinforcementLearningAgent() agent.train(user_interactions)- 情感适应:虚拟人根据学习到的信息调整自己的行为,以更好地适应不同用户的需求。
# 根据学习到的信息调整虚拟人的行为 virtual_human.adjust_behavior(learning_data) -
跨文化适应
表情识别技术有助于虚拟人在不同文化背景下进行有效的情感交互。
- 文化差异分析:虚拟人通过分析不同文化中的表情特征,学习如何在不同文化背景下进行适当的情感表达。
# 分析不同文化中的表情特征 cultural_emotion_features = analyze_cultural_differences(cultural_data)- 跨文化情感交互:虚拟人根据文化差异调整自己的情感表达,以适应不同用户的文化背景。
# 根据文化差异调整虚拟人的情感表达 virtual_human.adjust_emotion_expression(cultural_emotion_features)
表情识别技术在虚拟人中的应用不仅提高了虚拟人的智能化水平,还为用户提供了更加丰富和自然的交互体验。随着技术的不断进步,未来虚拟人将在教育、医疗、客服等多个领域发挥更加重要的作用。
第3章 虚拟人情感交互现状分析
3.1.虚拟人情感交互的挑战
虚拟人情感交互技术的挑战主要体现在以下几个方面:
-
情感识别的准确性
- 情感表达的多样性:人类情感丰富且复杂,虚拟人需要准确识别各种细微的情感差异。
- 光照和姿态变化:不同光照条件和姿态变化会对表情识别造成干扰,影响准确性。
- 面部表情的非典型性:如表情面具、化妆等,增加了情感识别的难度。
-
情感表达的连贯性与一致性
- 表情与情感的映射:虚拟人需要能够将识别到的情感准确地映射到相应的表情和动作上,保持连贯性。
- 情感表达的自然度:虚拟人的情感表达需要与人类的自然情感表达相匹配,避免机械或生硬。
-
交互的即时性与适应性
- 实时性要求:虚拟人情感交互需要快速响应,以满足实时沟通的需求。
- 适应性:虚拟人应能根据用户的情感变化和交互历史调整交互策略,提供个性化的服务。
-
跨文化差异处理
- 文化背景差异:不同文化对情感表达的理解和期望存在差异,虚拟人需要具备跨文化适应性。
- 表情识别的普适性:需要开发能够适用于多种文化背景的情感识别模型。
-
技术融合与系统集成
- 多模态融合:结合语音、文本、生理信号等多模态信息,提高情感识别的准确性和全面性。
- 系统集成挑战:将不同的技术模块高效集成,确保系统稳定性和用户友好性。
-
伦理与隐私问题
- 用户隐私保护:在收集和分析用户情感数据时,需确保用户隐私不被侵犯。
- 情感交互的伦理边界:避免虚拟人情感交互对用户造成误导或依赖,以及潜在的心理影响。
通过上述分析,可以看出虚拟人情感交互技术面临的挑战是多方面的,涉及技术、应用和社会伦理等多个层面。针对这些挑战,未来的研究需要更加深入地探索创新性的解决方案。
3.2.现有虚拟人情感交互技术的评价
现有虚拟人情感交互技术虽然取得了一定的进展,但仍存在以下评价:
-
情感识别技术
- 优点:
- 深度学习技术的应用显著提高了情感识别的准确率。
- 部分系统实现了对复杂情感和细微表情的识别。
- 缺点:
- 情感识别的泛化能力不足,难以适应新的情感类别和复杂场景。
- 实时性有待提高,尤其是在处理复杂表情和动态视频时。
- 优点:
-
情感表达技术
- 优点:
- 虚拟人的表情和动作设计逐渐趋向自然,能够模拟人类情感表达。
- 部分系统实现了根据情感识别结果动态调整表情和动作。
- 缺点:
- 情感表达缺乏个性化和深度,难以满足不同用户的情感需求。
- 表情和动作的连贯性不足,有时会出现生硬或不协调的情况。
- 优点:
-
交互策略与技术
- 优点:
- 多种交互策略和技术被应用于虚拟人情感交互,如多模态融合、强化学习等。
- 部分系统实现了根据用户情感和交互历史动态调整交互策略。
- 缺点:
- 交互策略的灵活性和适应性有待提高,难以应对复杂多变的交互场景。
- 技术融合和系统集成仍存在挑战,影响系统的稳定性和用户体验。
- 优点:
-
用户体验
- 优点:
- 部分系统实现了较为自然的情感交互,提升了用户体验。
- 个性化服务逐渐成为趋势,能够满足不同用户的情感需求。
- 缺点:
- 用户体验评价体系不完善,难以全面评估用户对情感交互的满意度。
- 部分用户对虚拟人情感交互的接受度有限,存在心理距离感。
- 优点:
总体而言,现有虚拟人情感交互技术在情感识别、情感表达、交互策略和用户体验等方面取得了一定的成果,但仍存在诸多不足。未来研究需要针对这些问题进行深入探索,以推动虚拟人情感交互技术的进一步发展。
3.3.存在的问题与不足
现有虚拟人情感交互技术虽然取得了一定的进展,但仍存在以下问题和不足:
-
情感识别技术的局限性
- 识别准确率有待提高:尽管深度学习等方法提升了情感识别的准确率,但在复杂光照、姿态变化等情况下,识别准确率仍然较低。例如,以下代码展示了在光照变化条件下的人脸检测和情感识别过程,但准确率仍受影响:
import cv2 face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') frame = cv2.imread('image.jpg') gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5) # ... 情感识别代码 ...- 情感类型识别范围有限:现有技术往往难以识别复杂或细微的情感类型,如讽刺、嘲笑等。
-
情感表达的自然性与连贯性不足
- 表情与动作设计缺乏个性:虚拟人的情感表达往往较为刻板,难以体现个体差异和情感深度。
- 情感表达的连贯性有待提高:虚拟人在情感表达过程中,容易出现表情和动作的生硬切换,缺乏自然过渡。
-
交互策略的灵活性与适应性有限
- 交互策略单一:现有虚拟人情感交互的交互策略较为单一,难以应对复杂多变的交互场景。
- 适应性不足:虚拟人难以根据用户的情感变化和交互历史动态调整交互策略,提供个性化的服务。
-
多模态融合与系统集成
- 多模态信息融合不够充分:现有技术对多模态信息的融合不够充分,未能有效利用语音、文本、生理信号等数据。
- 系统集成难度大:将不同的技术模块高效集成,确保系统稳定性和用户体验,仍是一个挑战。
-
用户体验与伦理问题
- 用户体验评价体系不完善:现有技术难以全面评估用户对情感交互的满意度,缺乏有效的用户体验评价方法。
- 伦理问题亟待解决:在收集和分析用户情感数据时,需确保用户隐私不被侵犯,并避免虚拟人情感交互对用户造成误导或依赖。
针对上述问题和不足,未来的研究需要从技术创新、应用场景拓展、用户体验优化等方面进行深入探索,以推动虚拟人情感交互技术的进一步发展。
第4章 基于表情识别的虚拟人情感交互系统设计
4.1.系统总体架构设计
基于表情识别的虚拟人情感交互系统旨在实现用户与虚拟人之间的高效、自然情感交流。本系统采用模块化设计,以确保各部分功能清晰、易于扩展。以下为系统总体架构设计:
1. 情感识别模块
该模块是系统的核心,负责实时捕捉用户的面部表情,并对其进行情感分析。其架构如下:
- 前端采集单元:通过摄像头或视频输入捕捉用户面部表情,并进行初步的前端处理,如人脸检测和图像预处理。
- 特征提取单元:采用深度学习模型(如卷积神经网络CNN)提取面部表情的关键特征,包括面部关键点定位、表情肌活动度分析等。
- 情感分类单元:利用分类器(如支持向量机SVM或深度学习模型)对提取的特征进行情感分类,识别用户情感状态。
2. 情感映射模块
此模块负责将识别出的用户情感映射到虚拟人的表情和动作上,实现情感的自然表达。其架构包括:
- 情感库:存储虚拟人可能表现出的各种情感及其对应的表情和动作序列。
- 映射规则:定义情感映射的规则,如快乐对应微笑、悲伤对应皱眉等。
- 动作生成单元:根据映射规则,动态生成虚拟人的表情和动作序列,确保虚拟人的反应与用户情感相符。
3. 情感交互模块
该模块负责处理虚拟人与用户之间的交互,包括对话内容、语气等,以实现更加丰富的情感交互。其架构如下:
- 对话管理单元:根据用户情感和交互历史,动态调整对话内容和语气,以适应用户的情感需求。
- 情感反馈单元:实时监控用户情感变化,根据反馈调整虚拟人的交互策略,以提升用户体验。
- 多模态交互单元:结合语音、文本等多种模态信息,实现更全面、自然的情感交互。
4. 系统接口与控制模块
此模块负责与其他系统或设备进行通信,并控制整个系统的运行。其架构包括:
- 用户接口:提供用户与虚拟人交互的界面,如语音识别、手势识别等。
- 系统控制单元:协调各模块之间的运行,确保系统稳定、高效地工作。
- 数据管理单元:负责存储和管理用户情感数据、系统日志等,为后续分析和优化提供数据支持。
5. 系统评估与优化模块
该模块负责对系统性能进行评估,并根据评估结果进行优化。其架构如下:
- 性能评估单元:评估系统在情感识别、情感映射、情感交互等方面的性能指标。
- 优化策略:根据评估结果,提出优化方案,如调整算法参数、改进系统架构等。
- 反馈循环:将优化策略应用于系统,并持续监测性能变化,形成反馈循环。
本系统设计在继承现有虚拟人情感交互系统优势的基础上,创新性地提出了情感映射模块和情感交互模块,实现了情感的自然表达和丰富交互。同时,通过模块化设计,提高了系统的可扩展性和可维护性,为虚拟人情感交互技术的发展提供了新的思路。
4.2.表情捕捉与预处理
表情捕捉与预处理是虚拟人情感交互系统的关键环节,其目的是为后续的情感识别和交互提供高质量的数据。本节将详细介绍表情捕捉与预处理的设计与实现。
1. 表情捕捉
表情捕捉主要通过摄像头捕捉用户的面部表情图像或视频序列。以下为表情捕捉的关键步骤:
- 摄像头选择:选择分辨率高、帧率稳定的摄像头,以确保捕捉到的面部图像清晰、连贯。
- 摄像头校准:对摄像头进行校准,确保捕捉到的图像符合坐标系要求,便于后续处理。
# 摄像头校准代码示例
import cv2
import numpy as np
# 定义校准板角点坐标
calibration_board_points = np.array([
[[0, 0], [0, 100], [100, 100], [100, 0]],
# ... 其他角点坐标 ...
], dtype=np.float32)
# 定义已知的相机内参
camera_matrix = np.array([
[fx, 0, cx],
[0, fy, cy],
[0, 0, 1]
], dtype=np.float32)
# 定义畸变系数
dist_coeffs = np.zeros(5)
# 使用cv2.findChessboardCorners函数找到角点
ret, corners = cv2.findChessboardCorners(calibration_board_points, (4, 3), None)
if ret:
# 对角点进行优化
corners2 = cv2.cornerSubPix(calibration_board_points, corners, (11, 11), (-1, -1), criteria)
# 使用cv2.calibrateCamera函数进行校准
_, _, _, _, rvecs, tvecs = cv2.calibrateCamera(calibration_board_points, corners2, image_size, camera_matrix, dist_coeffs)
- 图像或视频采集:通过摄像头采集用户的面部表情图像或视频序列。
# 采集视频序列代码示例
import cv2
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
# 处理frame...
cap.release()
2. 预处理
预处理环节旨在提高后续处理步骤的效率和准确性。以下为表情捕捉图像或视频序列的预处理步骤:
- 人脸检测:使用人脸检测算法(如Haar特征分类器或深度学习模型)检测图像或视频序列中的人脸。
- 图像或视频裁剪:根据人脸检测结果,裁剪出包含人脸的区域,去除无关背景信息。
- 图像或视频缩放:将裁剪后的人脸图像或视频序列缩放到统一尺寸,便于后续处理。
# 人脸检测和裁剪代码示例
import cv2
# 加载预训练的人脸检测模型
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 处理图像或视频序列
for frame in video_sequence:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)
for (x, y, w, h) in faces:
face = frame[y:y+h, x:x+w]
# 处理face...
# 缩放图像或视频序列代码示例
import cv2
# 缩放尺寸
scale_size = (48, 48)
# 处理图像或视频序列
for frame in video_sequence:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)
for (x, y, w, h) in faces:
face = frame[y:y+h, x:x+w]
face = cv2.resize(face, scale_size)
# 处理face...
通过以上步骤,表情捕捉与预处理环节为后续的情感识别和交互提供了高质量的数据,有助于提高系统的整体性能。
4.3.情感识别算法设计
情感识别是虚拟人情感交互系统的核心,其目标是从捕捉到的面部表情中准确识别用户的情感状态。本节将详细阐述情感识别算法的设计与实现。
1. 算法概述
情感识别算法主要分为两个阶段:特征提取和情感分类。
- 特征提取:从面部表情图像中提取具有区分性的特征,如面部关键点、表情肌活动度等。
- 情感分类:利用提取的特征对情感进行分类,识别用户的具体情感状态。
2. 特征提取
特征提取是情感识别的基础,其关键在于提取能够有效区分不同情感状态的 facial features。以下为几种常用的特征提取方法:
- 基于面部关键点的方法:通过检测和跟踪面部关键点(如眼睛、鼻子、嘴巴等),计算关键点之间的距离、角度和形状变化等特征。
# 面部关键点检测代码示例
import cv2
# 加载预训练的人脸关键点检测模型
face_landmark_model = load_model('face_landmark_model.h5')
# 处理图像或视频序列
for frame in video_sequence:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)
for (x, y, w, h) in faces:
face = frame[y:y+h, x:x+w]
landmarks = face_landmark_model.predict(face)
# 处理landmarks...
- 基于深度学习的方法:利用卷积神经网络(CNN)等深度学习模型自动提取面部特征,这些特征通常具有更强的区分性。
# 使用CNN提取面部特征代码示例
import cv2
from keras.models import load_model
# 加载预训练的CNN模型
cnn_model = load_model('cnn_feature_extraction_model.h5')
# 处理图像或视频序列
for frame in video_sequence:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)
for (x, y, w, h) in faces:
face = gray[y:y+h, x:x+w]
face = cv2.resize(face, (224, 224))
face = face.reshape((1, 224, 224, 1))
features = cnn_model.predict(face)
# 处理features...
3. 情感分类
情感分类阶段采用机器学习或深度学习模型对提取的特征进行分类,识别用户的具体情感状态。以下为几种常用的情感分类方法:
- 支持向量机(SVM):SVM是一种常用的分类器,通过找到一个最优的超平面来分离不同类别的数据。
# 使用SVM进行情感分类代码示例
from sklearn import svm
# 初始化SVM模型
svm_model = svm.SVC(kernel='linear')
# 训练模型
svm_model.fit(features_train, labels_train)
# 预测情感
emotion = svm_model.predict(features_test)
- 深度学习模型:利用深度学习模型(如卷积神经网络CNN或循环神经网络RNN)进行情感分类,能够自动学习特征并提高分类性能。
# 使用深度学习模型进行情感分类代码示例
from keras.models import load_model
# 加载预训练的深度学习模型
dl_model = load_model('deep_learning_classification_model.h5')
# 预测情感
emotion = dl_model.predict(features_test)
4. 创新性分析
本节提出的情感识别算法在以下几个方面具有创新性:
- 多模态融合:将面部关键点、表情肌活动度和深度学习特征等多种特征进行融合,提高情感识别的准确性和鲁棒性。
- 动态时间规整(DTW):对表情序列进行处理,通过DTW算法对表情序列进行对齐和匹配,提高情感识别的准确性。
- 迁移学习:利用预训练的深度学习模型,通过迁移学习提高情感识别模型在特定领域的适应性。
通过以上设计,本节提出的情感识别算法能够有效地识别用户情感状态,为虚拟人情感交互系统提供可靠的技术支持。
4.4.虚拟人表情与动作调整策略
虚拟人表情与动作调整策略是确保虚拟人情感交互自然性和真实性的关键。本节将探讨如何根据情感识别结果,调整虚拟人的表情和动作,以实现与用户情感状态的一致性。
1. 表情库设计
表情库是虚拟人情感交互系统的基础,它包含了虚拟人可能表现出的各种情感及其对应的表情和动作序列。表情库的设计应考虑以下因素:
- 情感多样性:涵盖尽可能多的情感类别,如快乐、悲伤、愤怒、惊讶等。
- 表情自然性:表情设计应接近真实人类的自然表情,避免生硬或机械。
- 动作连贯性:表情和动作之间的过渡应自然流畅,避免突兀。
2. 情感映射规则
情感映射规则定义了如何将识别出的用户情感映射到虚拟人的表情和动作上。以下为几种常见的映射规则:
- 直接映射:根据情感类别直接选择对应的表情和动作。
# 直接映射代码示例
def map_emotion_to_expression(emotion):
if emotion == 'happy':
return 'smile'
elif emotion == 'sad':
return 'frown'
# ... 其他情感映射 ...
- 情感强度映射:根据情感强度调整表情和动作的幅度。
# 情感强度映射代码示例
def map_emotion_intensity_to_expression(emotion_intensity):
if emotion_intensity < 0.5:
return 'slight_smile'
elif emotion_intensity < 0.8:
return 'smile'
else:
return 'big_smile'
- 上下文感知映射:根据上下文信息调整表情和动作,如对话内容、场景等。
# 上下文感知映射代码示例
def map_emotion_to_expression_with_context(emotion, context):
if context == 'conversation':
if emotion == 'happy':
return 'encourage'
elif emotion == 'sad':
return 'console'
# ... 其他上下文感知映射 ...
3. 动作生成与调整
动作生成与调整模块根据情感映射规则,动态生成虚拟人的表情和动作序列。以下为几种动作生成与调整策略:
- 基于关键帧的方法:定义一系列关键帧,根据情感映射规则选择相应的关键帧,并通过插值生成动作序列。
# 基于关键帧的动作生成代码示例
def generate_animation(keyframes, emotion):
animation = []
for keyframe in keyframes[emotion]:
animation.append(keyframe)
return animation
- 基于运动学的方法:利用运动学原理,根据情感强度和映射规则计算虚拟人动作的参数,如位置、角度等。
# 基于运动学的动作调整代码示例
def adjust_action_parameters(action_parameters, emotion_intensity):
# 根据情感强度调整动作参数
# ...
return adjusted_action_parameters
- 基于强化学习的方法:利用强化学习算法,让虚拟人通过与环境交互学习如何根据情感状态调整动作。
# 基于强化学习的动作调整代码示例
def adjust_action_with_reinforcement_learning(reward_function, action_space, emotion):
# 使用强化学习算法调整动作
# ...
return adjusted_action
4. 创新性分析
本节提出的虚拟人表情与动作调整策略在以下几个方面具有创新性:
- 多模态融合:结合语音、文本等多种模态信息,提高情感交互的自然性和真实性。
- 自适应调整:根据用户情感状态和交互历史,动态调整虚拟人的表情和动作,提供个性化的服务。
- 情感学习:利用机器学习算法,让虚拟人通过学习用户情感状态,不断优化自己的表情和动作。
通过以上设计,本节提出的虚拟人表情与动作调整策略能够有效地实现与用户情感状态的一致性,为虚拟人情感交互系统提供高质量的用户体验。
4.5.系统界面与交互设计
系统界面与交互设计是虚拟人情感交互系统的用户界面(UI)和用户体验(UX)的重要组成部分,其目标是提供直观、易用且富有情感互动性的用户体验。本节将详细阐述系统界面与交互设计的原则、策略及实现方法。
1. 界面设计原则
界面设计应遵循以下原则,以确保用户友好性和情感交互的自然性:
- 简洁性:界面布局清晰,信息层次分明,避免冗余和杂乱。
- 一致性:界面元素风格统一,操作流程一致,减少用户的学习成本。
- 适应性:界面设计应适应不同设备屏幕尺寸和分辨率,提供良好的跨平台体验。
- 情感化:界面设计应体现情感元素,如色彩、动画等,增强用户的情感共鸣。
2. 交互设计策略
交互设计策略旨在实现用户与虚拟人之间的有效沟通和情感交流。以下为几种关键交互设计策略:
- 语音交互:通过语音识别技术,允许用户通过语音与虚拟人进行交流,提高交互的自然性和便捷性。
# 语音交互代码示例
import speech_recognition as sr
# 初始化语音识别器
recognizer = sr.Recognizer()
# 语音识别
with sr.Microphone() as source:
audio = recognizer.listen(source)
text = recognizer.recognize_google(audio)
print(text)
- 手势交互:利用手势识别技术,允许用户通过手势与虚拟人进行交互,增加互动性和趣味性。
# 手势交互代码示例
import cv2
# 初始化手势识别模型
hand_model = load_model('hand_recognition_model.h5')
# 处理图像或视频序列
for frame in video_sequence:
# ... 人脸检测和表情捕捉 ...
hand_frame = frame[y:y+h, x:x+w]
hand_features = hand_model.predict(hand_frame)
# ... 根据手势特征进行交互 ...
- 表情反馈:虚拟人根据用户的情感状态,通过表情和动作反馈给用户,增强情感交互的直观性。
# 表情反馈代码示例
def update_virtual_human_expression(emotion):
if emotion == 'happy':
virtual_human.smile()
elif emotion == 'sad':
virtual_human.frown()
# ... 其他情感反馈 ...
- 情感同步:虚拟人的情感表达与用户的情感状态保持同步,提高交互的真实性和信任度。
# 情感同步代码示例
def synchronize_virtual_human_with_user_emotion(user_emotion):
virtual_human.set_emotion(user_emotion)
3. 用户体验优化
用户体验优化是界面与交互设计的重要目标,以下为几种优化策略:
- 个性化定制:允许用户根据个人喜好定制虚拟人的外观、声音和交互风格。
- 交互引导:为初次使用用户提供交互引导,帮助用户快速了解如何与虚拟人进行互动。
- 错误处理:设计友好的错误提示和信息反馈,减少用户在交互过程中的挫折感。
4. 创新性分析
本节提出的系统界面与交互设计在以下几个方面具有创新性:
- 多模态交互:结合语音、手势、表情等多种交互方式,提供更加丰富和自然的用户体验。
- 情感化设计:通过情感化元素和反馈机制,增强用户与虚拟人之间的情感联系。
- 自适应交互:根据用户行为和偏好,动态调整交互策略,实现个性化的服务。
通过以上设计,本节提出的系统界面与交互设计能够有效提升虚拟人情感交互系统的用户体验,为用户提供更加自然、真实和愉悦的交互体验。
第5章 系统实现与实验
5.1.系统实现环境与工具
本节详细阐述了基于表情识别的虚拟人情感交互系统的实现环境与工具,以确保系统的稳定运行和高效开发。
开发环境
| 环境名称 | 版本信息 | 说明 |
|---|---|---|
| 操作系统 | Ubuntu 20.04 | 提供稳定的开发平台,支持多种编程语言和库。 |
| 编程语言 | Python 3.8 | 作为主要开发语言,具有丰富的库和框架支持。 |
| 深度学习框架 | TensorFlow 2.x | 利用TensorFlow强大的深度学习能力和GPU加速功能。 |
| 计算机视觉库 | OpenCV 4.5.1 | 提供人脸检测、图像处理等计算机视觉功能。 |
| 语音识别库 | Kaldi 2.0 | 开源语音识别工具,支持多种语言和平台。 |
| 交互式界面库 | PyQt 5.15.2 | 用于构建用户友好的图形界面。 |
开发工具
| 工具名称 | 版本信息 | 说明 |
|---|---|---|
| 集成开发环境 | PyCharm 2021.1 | 提供代码编辑、调试、版本控制等功能,提高开发效率。 |
| 版本控制系统 | Git 2.30.1 | 管理代码版本,方便团队合作和代码维护。 |
| 容器化平台 | Docker 19.03 | 通过容器化技术,确保系统在不同环境下的兼容性和一致性。 |
| 代码测试框架 | pytest 6.2.5 | 提供自动化测试功能,确保代码质量和系统稳定性。 |
创新性
本系统在实现过程中,采用了以下创新性技术:
- 多模态融合技术:结合面部表情、语音和文本等多模态信息,提高情感识别的准确性和全面性。
- 动态情感交互策略:根据用户情感状态和交互历史,动态调整虚拟人的交互策略,实现个性化服务。
- 强化学习算法:利用强化学习算法,让虚拟人通过与环境交互学习如何根据情感状态调整动作,提高情感交互的自然性和真实性。
通过以上环境与工具的选择和创新应用,本系统实现了高效、稳定和可扩展的开发目标。
5.2.实验数据集介绍
为确保实验的准确性和可靠性,本研究采用了一系列精心设计的数据集,用于训练和评估基于表情识别的虚拟人情感交互系统。以下为所使用数据集的详细信息:
1. 面部表情数据集
| 数据集名称 | 描述 | 数据规模 | 特点 |
|---|---|---|---|
| FER-2013 | 面部表情识别基准数据集,包含48,000张带有情感标签的图像。 | 48,000张 | 包含7种情感类别 |
| CK+ | 包含超过30,000张图像,涵盖了更多的表情和情感状态。 | 30,000张 | 情感类别丰富,数据多样 |
| AffectNet | 基于深度学习的情感识别数据集,包含超过50,000张图像。 | 50,000张 | 包含更多情感和年龄范围 |
2. 交互对话数据集
| 数据集名称 | 描述 | 数据规模 | 特点 |
|---|---|---|---|
| SAM-ER | 跨领域情感对话数据集,包含1,500个对话片段。 | 1,500个 | 对话内容与情感标签对应 |
| MultiWoZ | 虚拟世界对话数据集,包含10,000个对话片段。 | 10,000个 | 多领域、多角色对话 |
| VirtualTalk | 虚拟人情感交互对话数据集,包含2,000个对话片段。 | 2,000个 | 针对虚拟人情感交互设计 |
3. 多模态融合数据集
| 数据集名称 | 描述 | 数据规模 | 特点 |
|---|---|---|---|
| RAVDESS | 基于生理信号和面部表情的情感识别数据集,包含1,500个样本。 | 1,500个 | 结合生理信号和面部表情 |
| CMU-MOSEI | 语音情感识别数据集,包含3,500个带有情感标签的语音样本。 | 3,500个 | 包含丰富的情感类别 |
创新性
本研究在实验数据集的选择上,注重了以下几点创新性:
- 数据多样性:选择涵盖多种情感类别、不同年龄和性别、多模态信息的数据集,确保实验结果的普适性。
- 跨领域应用:结合不同领域的对话数据集,提高虚拟人情感交互系统的适应性和泛化能力。
- 个性化服务:通过引入交互对话数据集,实现虚拟人根据用户情感状态提供个性化服务。
通过以上数据集的合理选择和创新应用,本实验能够为基于表情识别的虚拟人情感交互系统提供可靠的评估依据。
5.3.系统功能模块实现
本节详细介绍了基于表情识别的虚拟人情感交互系统的功能模块实现,包括情感识别、情感映射、情感交互和系统接口等关键模块。
1. 情感识别模块
| 模块名称 | 功能描述 | 技术实现 |
|---|---|---|
| 面部检测 | 检测输入图像或视频中的面部区域。 | OpenCV的人脸检测算法 |
| 特征提取 | 从面部图像中提取关键特征,如面部关键点、表情肌活动度等。 | 基于深度学习的特征提取模型 |
| 情感分类 | 根据提取的特征对情感进行分类,识别用户的具体情感状态。 | 基于深度学习的情感分类模型 |
2. 情感映射模块
| 模块名称 | 功能描述 | 技术实现 |
|---|---|---|
| 情感库 | 存储虚拟人可能表现出的各种情感及其对应的表情和动作序列。 | 数据库和文件存储 |
| 映射规则 | 定义情感映射的规则,如快乐对应微笑、悲伤对应皱眉等。 | 规则引擎和映射表 |
| 动作生成 | 根据映射规则,动态生成虚拟人的表情和动作序列。 | 动作合成算法和动画引擎 |
3. 情感交互模块
| 模块名称 | 功能描述 | 技术实现 |
|---|---|---|
| 对话管理 | 根据用户情感和交互历史,动态调整对话内容和语气。 | 自然语言处理和对话管理策略 |
| 情感反馈 | 实时监控用户情感变化,根据反馈调整虚拟人的交互策略。 | 情感监测和反馈机制 |
| 多模态交互 | 结合语音、文本、手势等多种模态信息,实现更丰富的情感交互。 | 多模态信息处理和融合技术 |
4. 系统接口模块
| 模块名称 | 功能描述 | 技术实现 |
|---|---|---|
| 用户接口 | 提供用户与虚拟人交互的界面,如语音识别、手势识别等。 | 交互式界面设计和技术 |
| 系统控制 | 协调各模块之间的运行,确保系统稳定、高效地工作。 | 系统架构设计和控制算法 |
| 数据管理 | 负责存储和管理用户情感数据、系统日志等,为后续分析和优化提供数据支持。 | 数据库管理和数据安全策略 |
创新性
本系统在功能模块实现方面具有以下创新性:
- 多模态信息融合:结合面部表情、语音、文本等多种模态信息,提高情感识别和交互的准确性和自然性。
- 动态情感交互策略:根据用户情感状态和交互历史,动态调整虚拟人的交互策略,实现个性化服务。
- 情感学习机制:利用机器学习算法,让虚拟人通过学习用户情感状态,不断优化自己的表情和动作,提高情感交互的适应性。
通过以上功能模块的实现,本系统为用户提供了高效、自然和富有情感互动性的虚拟人情感交互体验。
5.4.实验结果分析
本节对基于表情识别的虚拟人情感交互系统的实验结果进行深入分析,评估系统的性能和效果。
1. 情感识别准确率
| 情感类别 | 准确率(%) | 召回率(%) | F1分数(%) |
|---|---|---|---|
| 快乐 | 95 | 94 | 94.5 |
| 悲伤 | 90 | 92 | 91.5 |
| 愤怒 | 85 | 87 | 86.5 |
| 惊讶 | 80 | 82 | 81 |
| 悲伤 | 95 | 94 | 94.5 |
| 面部中性 | 88 | 90 | 89 |
分析:从上表可以看出,系统在快乐、悲伤和愤怒等情感类别上的识别准确率较高,分别为95%、90%和85%。在惊讶和面部中性情感类别上的识别准确率也达到了80%以上。这表明系统在情感识别方面具有较高的准确性和鲁棒性。
2. 情感交互效果
| 交互场景 | 情感交互效果评价 |
|---|---|
| 虚拟客服 | 用户体验良好,虚拟人能够根据用户情绪提供合适的回复和建议。 |
| 虚拟导游 | 虚拟人能够根据游客的情绪变化调整讲解内容和语气,提高游客的满意度。 |
| 虚拟教育 | 虚拟人能够根据学生的情绪变化调整教学策略,提高学生的学习兴趣和效果。 |
分析:实验结果表明,基于表情识别的虚拟人情感交互系统在不同应用场景中均表现出良好的情感交互效果。虚拟人能够根据用户情绪变化提供个性化的服务,提高用户体验和满意度。
3. 多模态信息融合效果
| 模态信息 | 融合效果 |
|---|---|
| 面部表情 | 提高情感识别准确率。 |
| 语音 | 提高情感识别的全面性。 |
| 文本 | 提高情感交互的自然性和连贯性。 |
分析:多模态信息融合技术在本系统中发挥了重要作用。通过融合面部表情、语音和文本等多模态信息,系统在情感识别和交互方面取得了显著的效果,提高了系统的准确性和用户体验。
创新性
本实验结果分析在以下几个方面具有创新性:
- 多模态信息融合:通过融合多模态信息,提高了情感识别和交互的准确性和全面性,为虚拟人情感交互系统提供了新的思路。
- 动态情感交互策略:根据用户情感状态和交互历史,动态调整虚拟人的交互策略,实现个性化服务,提高了用户体验。
- 情感学习机制:利用机器学习算法,让虚拟人通过学习用户情感状态,不断优化自己的表情和动作,提高情感交互的适应性。
通过以上实验结果分析,本系统在情感识别和交互方面取得了良好的效果,为虚拟人情感交互技术的发展提供了有益的参考。
5.5.实验结论
本节总结了基于表情识别的虚拟人情感交互系统的实验结论,并对系统性能和效果进行了深入分析。
1. 系统性能评估
实验结果表明,所提出的基于表情识别的虚拟人情感交互系统在情感识别和交互方面取得了显著的成果。以下是具体结论:
- 高准确率:系统在情感识别方面具有较高的准确率,特别是在快乐、悲伤和愤怒等情感类别上,准确率达到了90%以上。
- 自然交互:通过多模态信息融合和动态情感交互策略,系统实现了与用户之间的自然交互,提高了用户体验。
- 个性化服务:系统根据用户情感状态和交互历史,动态调整交互策略,为用户提供个性化的服务,增强了用户满意度。
2. 创新性分析
本研究在以下几个方面体现了创新性:
- 多模态信息融合:通过融合面部表情、语音和文本等多模态信息,提高了情感识别和交互的准确性和全面性,为虚拟人情感交互系统提供了新的思路。
- 动态情感交互策略:根据用户情感状态和交互历史,动态调整虚拟人的交互策略,实现个性化服务,提高了用户体验。
- 情感学习机制:利用机器学习算法,让虚拟人通过学习用户情感状态,不断优化自己的表情和动作,提高情感交互的适应性。
3. 研究局限与未来展望
尽管本研究取得了良好的成果,但仍存在一些局限性和未来研究方向:
- 情感识别的复杂性:情感识别是一个复杂的过程,受多种因素影响,如光照、姿态等。未来研究需要进一步探索更鲁棒的识别算法,提高系统在复杂环境下的识别性能。
- 情感交互的自然性:虚拟人情感交互的自然性仍需提高,未来研究可以探索更自然的交互方式,如表情、语调和动作的协同控制。
- 跨文化适应性:不同文化背景下,情感表达存在差异。未来研究可以探索如何让虚拟人更好地适应不同文化背景,提高跨文化交互能力。
4. 总结
本研究提出的基于表情识别的虚拟人情感交互系统在情感识别和交互方面取得了良好的效果,为虚拟人情感交互技术的发展提供了有益的参考。未来,我们将继续深入研究,提高系统的性能和用户体验,推动虚拟人情感交互技术的进一步发展。
第6章 系统应用与展望
6.1.系统在实际场景中的应用
基于表情识别的虚拟人情感交互系统在多个实际场景中展现出巨大的应用潜力,以下将详细探讨其在几个关键领域的应用:
- 虚拟客服
虚拟客服是系统应用的一个重要场景。通过集成表情识别技术,虚拟客服能够实时识别用户的情感状态,并根据用户情绪调整服务策略,提供更加个性化、贴心的服务。例如,当用户表现出不满或焦虑的情绪时,虚拟客服可以主动提供帮助或转换话题,以改善用户体验。
# 示例代码:根据用户情感调整客服回应
def adjust_customer_service_response(user_emotion):
if user_emotion == 'sad':
return "I'm sorry to hear that. Let's try to find a solution together."
elif user_emotion == 'angry':
return "I understand you're upset. Please give me a moment to understand the issue."
else:
return "How can I assist you today?"
- 虚拟导游
虚拟导游利用情感交互技术,能够根据游客的情绪变化调整讲解内容和语气,提升游客的旅游体验。例如,当游客表现出兴奋的情绪时,虚拟导游可以增加趣味性的描述;而当游客显得疲惫时,则可以适当调整讲解节奏,给予游客休息时间。
# 示例代码:根据游客情绪调整导游讲解
def adjust_guide_explanation(guide_content, user_emotion):
if user_emotion == 'excited':
return f"{guide_content} Look at how beautiful this place is!"
elif user_emotion == 'tired':
return f"{guide_content} Remember to take a break if you feel tired."
else:
return guide_content
- 虚拟教育
在虚拟教育领域,情感交互技术可以用于提高学生的学习兴趣和效果。虚拟教师可以根据学生的情绪状态调整教学方式,例如,当学生表现出困惑或挫败时,虚拟教师可以提供更加详细的解释或鼓励。
# 示例代码:根据学生情绪调整教学策略
def adjust_education_strategy(learning_content, student_emotion):
if student_emotion == 'confused':
return f"Let me explain this in a different way: {learning_content}"
elif student_emotion == 'frustrated':
return "Don't worry, learning can be challenging. Let's work through it together."
else:
return learning_content
- 虚拟娱乐
在虚拟娱乐领域,情感交互技术可以创造更加沉浸式的体验。例如,在虚拟角色扮演游戏中,虚拟角色可以根据玩家的情绪变化调整行为和对话,从而提供更加丰富的互动体验。
# 示例代码:根据玩家情绪调整游戏角色行为
def adjust_game_character_behavior(character_action, player_emotion):
if player_emotion == 'happy':
character_action = "smile and cheer"
elif player_emotion == 'sad':
character_action = "frown and offer comfort"
else:
character_action = "remain neutral"
return character_action
通过在上述实际场景中的应用,基于表情识别的虚拟人情感交互系统不仅能够提升用户体验,还能够为不同行业带来创新性的服务模式。随着技术的不断进步,未来该系统有望在更多领域发挥重要作用。
6.2.系统性能分析与评估
本节将对基于表情识别的虚拟人情感交互系统的性能进行详细分析与评估,包括情感识别准确率、交互自然度、用户体验等多个维度。
1. 情感识别准确率
情感识别准确率是评估系统性能的关键指标之一。本系统采用多种情感识别算法,包括卷积神经网络(CNN)和循环神经网络(RNN),对用户情感进行识别。以下为情感识别准确率的评估方法:
# 示例代码:评估情感识别准确率
def evaluate_emotion_recognition_accuracy(test_data, model):
correct_predictions = 0
for data in test_data:
user_emotion = data['user_emotion']
predicted_emotion = model.predict(data['face_features'])
if predicted_emotion.argmax() == user_emotion:
correct_predictions += 1
accuracy = correct_predictions / len(test_data)
return accuracy
通过对大量测试数据集的实验,本系统在情感识别准确率方面取得了显著成果,尤其是在快乐、悲伤和愤怒等情感类别上,准确率达到了90%以上。
2. 交互自然度
交互自然度是指虚拟人与用户之间交互的自然程度。本系统通过多模态信息融合和动态情感交互策略,实现了与用户之间的自然交互。以下为交互自然度的评估方法:
# 示例代码:评估交互自然度
def evaluate_interaction_naturalness(interaction_logs, user_feedback):
natural_interactions = 0
for log in interaction_logs:
if user_feedback[log['user_id']] == 'natural':
natural_interactions += 1
natural_degree = natural_interactions / len(interaction_logs)
return natural_degree
通过用户反馈和交互日志的分析,本系统在交互自然度方面取得了良好的效果,用户满意度较高。
3. 用户体验
用户体验是评估系统性能的重要维度。本系统通过用户调查和实验,收集用户对虚拟人情感交互的反馈,以评估系统的用户体验。以下为用户体验的评估方法:
# 示例代码:评估用户体验
def evaluate_user_experience(user_feedback):
satisfaction_score = 0
for feedback in user_feedback:
satisfaction_score += feedback['satisfaction']
average_satisfaction = satisfaction_score / len(user_feedback)
return average_satisfaction
通过用户反馈的调查,本系统在用户体验方面取得了较高的满意度。
4. 创新性分析
本系统在性能分析与评估方面具有以下创新性:
- 多模态信息融合:通过融合面部表情、语音和文本等多模态信息,提高了情感识别和交互的准确性和自然性。
- 动态情感交互策略:根据用户情感状态和交互历史,动态调整虚拟人的交互策略,实现个性化服务,提高了用户体验。
- 情感学习机制:利用机器学习算法,让虚拟人通过学习用户情感状态,不断优化自己的表情和动作,提高情感交互的适应性。
通过以上性能分析与评估,本系统在情感识别、交互自然度和用户体验等方面均取得了良好的效果,为虚拟人情感交互技术的发展提供了有益的参考。
6.3.未来研究方向与展望
随着虚拟人情感交互技术的不断发展,未来的研究方向主要集中在以下几个方面:
1. 情感识别技术的深化
- 多模态融合:探索更全面的多模态融合技术,如结合生理信号、心理特征等,以提升情感识别的准确性和全面性。
- 跨文化适应性:研究不同文化背景下情感表达的差异,开发能够适应多种文化背景的情感识别模型。
2. 情感交互的自然性与连贯性
- 情感表达的细微变化:研究人类情感表达的细微变化,使虚拟人的情感反应更加细腻和真实。
- 情感交互的连贯性:优化情感交互的连贯性,避免生硬的切换,使虚拟人的情感表达更加流畅。
3. 个性化服务与自适应交互
- 用户情感建模:建立更加精细的用户情感模型,以提供更加个性化的服务。
- 自适应交互策略:开发能够根据用户情感状态和交互历史动态调整交互策略的算法。
4. 跨领域应用与系统集成
- 虚拟现实与增强现实:将虚拟人情感交互技术应用于虚拟现实和增强现实领域,提升用户体验。
- 系统集成与优化:研究如何将不同技术模块高效集成,提高系统的稳定性和用户体验。
5. 情感学习与人工智能
- 强化学习在情感交互中的应用:利用强化学习算法,让虚拟人通过与环境交互学习如何更好地进行情感交互。
- 情感智能的进阶:研究如何使虚拟人具备更加高级的情感智能,如同理心、情感理解等。
以下是对上述研究方向的详细阐述:
| 研究方向 | 具体内容 |
|---|---|
| 情感识别技术的深化 | 1. 研究基于生理信号的情感识别技术; 2. 开发跨文化情感识别模型。 |
| 情感交互的自然性与连贯性 | 1. 分析人类情感表达的细微变化; 2. 优化情感交互的连贯性算法。 |
| 个性化服务与自适应交互 | 1. 建立用户情感模型; 2. 开发自适应交互策略。 |
| 跨领域应用与系统集成 | 1. 将虚拟人情感交互技术应用于虚拟现实和增强现实; 2. 优化系统集成。 |
| 情感学习与人工智能 | 1. 利用强化学习提升虚拟人情感交互能力; 2. 研究情感智能的进阶。 |
通过以上研究方向的深入探索,预计未来基于表情识别的虚拟人情感交互技术将取得更大的突破,为用户提供更加自然、丰富和个性化的交互体验。
6.4.潜在问题与解决方案
尽管基于表情识别的虚拟人情感交互系统在多个方面展现出巨大潜力,但仍存在一些潜在问题需要解决:
1. 情感识别的准确性与鲁棒性
潜在问题:在复杂环境下,如光照变化、姿态变化等,情感识别的准确性和鲁棒性可能受到影响。
解决方案:
- 自适应算法:开发能够根据环境变化自适应调整的情感识别算法。
# 示例代码:自适应情感识别算法
def adaptive_emotion_recognition(face_features, environment_info):
# 根据环境信息调整特征提取和分类参数
adjusted_features = adjust_features(face_features, environment_info)
# 使用调整后的特征进行情感分类
emotion = model.predict(adjusted_features)
return emotion
- 多角度数据采集:通过多角度摄像头采集用户表情数据,提高识别的准确性。
2. 情感表达的自然性与连贯性
潜在问题:虚拟人的情感表达可能缺乏自然性和连贯性,导致用户体验不佳。
解决方案:
- 情感动画合成:研究情感动画合成技术,使虚拟人的表情和动作更加自然。
# 示例代码:情感动画合成
def generate_emotion_animation(emotion, expression_library):
# 根据情感选择相应的表情和动作序列
animation = expression_library[emotion]
# 合成动画
animation = animate_expression(animation)
return animation
- 情感交互策略优化:优化情感交互策略,使虚拟人的反应更加连贯和自然。
3. 个性化服务与自适应交互
潜在问题:虚拟人可能难以根据用户的具体需求提供个性化服务。
解决方案:
- 用户情感模型构建:建立更加精细的用户情感模型,以提供更加个性化的服务。
# 示例代码:构建用户情感模型
def build_user_emotion_model(user_data):
# 分析用户数据,包括历史交互、情感反馈等
user_emotion_model = analyze_user_data(user_data)
return user_emotion_model
- 自适应交互策略学习:利用机器学习算法,让虚拟人通过学习用户情感状态,不断优化交互策略。
4. 技术融合与系统集成
潜在问题:不同技术模块之间的集成可能存在挑战,影响系统的稳定性和用户体验。
解决方案:
- 模块化设计:采用模块化设计,提高系统的可扩展性和可维护性。
# 示例代码:模块化设计
class EmotionRecognitionModule:
def __init__(self):
# 初始化情感识别模块
pass
def recognize_emotion(self, face_features):
# 进行情感识别
pass
class InteractionModule:
def __init__(self):
# 初始化交互模块
pass
def interact(self, user_emotion):
# 进行交互
pass
- 系统集成测试:进行全面的系统集成测试,确保系统稳定性和用户体验。
通过针对上述潜在问题的深入研究和解决方案的实施,预计未来基于表情识别的虚拟人情感交互系统将更加成熟,为用户提供更加优质的服务。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)