NIPS2021 | LTP | 学习可迁移的对抗性扰动
本文 “Learning Transferable Adversarial Perturbations” 主要研究生成对抗扰动的可转移性,提出利用深度神经网络(DNN)的中层特征训练扰动生成器,以提高对抗扰动在不同目标架构、数据和任务之间的可转移性,实验表明该方法优于现有攻击策略。
Learning Transferable Adversarial Perturbations
本文 “Learning Transferable Adversarial Perturbations” 主要研究生成对抗扰动的可迁移性,提出利用深度神经网络(DNN)的中层特征训练扰动生成器,以提高对抗扰动在不同目标架构、数据和任务之间的可迁移性,实验表明该方法优于现有攻击策略。
摘要-Abstract
While effective, deep neural networks (DNNs) are vulnerable to adversarial attacks. In particular, recent work has shown that such attacks could be generated by another deep network, leading to significant speedups over optimization-based perturbations. However, the ability of such generative methods to generalize to different test-time situations has not been systematically studied. In this paper, we therefore investigate the transferability of generated perturbations when the conditions at inference time differ from the training ones in terms of target architecture, target data, and target task. Specifically, we identify the mid-level features extracted by the intermediate layers of DNNs as common ground across different architectures, datasets, and tasks. This lets us introduce a loss function based on such mid-level features to learn an effective, transferable perturbation generator. Our experiments demonstrate that our approach outperforms the state-of-the-art universal and transferable attack strategies.
尽管深度神经网络(DNNs)很有效,但它们容易受到对抗攻击。特别是,最近的研究表明,这种攻击可以由另一个深度网络生成,与基于优化的扰动相比,能显著提高攻击速度。然而,这种生成方法在不同测试场景下的泛化能力尚未得到系统研究。因此,在本文中,我们研究了在推理时的条件与训练时在目标架构、目标数据和目标任务方面存在差异的情况下,生成的扰动的可迁移性。具体来说,我们将深度神经网络中间层提取的中层特征确定为跨越不同架构、数据集和任务的共同基础。这使我们能够引入一种基于此类中层特征的损失函数,来学习一个有效的、可迁移的扰动生成器。我们的实验表明,我们的方法优于当前最先进的通用且可迁移攻击策略。
引言-Introduction
该部分主要介绍研究背景、问题和贡献,旨在说明研究生成对抗扰动可迁移性的重要性和创新性,具体内容如下:
- 研究背景:深度神经网络(DNNs)在众多应用领域取得显著成果,但面临对抗攻击的安全隐患。目前对抗攻击主要分为两类,迭代算法计算成本高昂,而生成方法通过训练深度网络生成扰动,攻击时只需前向传播,速度优势明显。
- 研究问题:生成方法在速度上有优势,但在不同测试场景下的泛化能力缺乏系统研究。本文聚焦于探究生成扰动在目标架构、目标数据和目标任务与训练时不同的情况下的可迁移性。此前仅有研究涉及生成方法在不同架构和数据上的泛化,而本文首次尝试研究其跨任务的可迁移性。
- 研究方法与思路:发现不同架构、数据和任务下,DNN中间层提取的中层特征具有很强的相似性。基于此,通过最大化样本正常特征与对抗特征在预训练分类器中间层的距离,训练扰动生成器。这种方式生成的扰动可对目标模型的中层特征产生类似影响,进而传递到网络顶层,导致预测错误。
- 研究贡献:一是确定CNN中间层特征可作为不同架构、数据分布和任务的共同基础;二是提出利用这些特征学习有效且可迁移的扰动生成器的方法;三是系统研究目标架构和数据分布对对抗攻击可迁移性的影响。实验证明该方法在愚弄率上优于现有通用和可迁移攻击策略,代码也已开源。
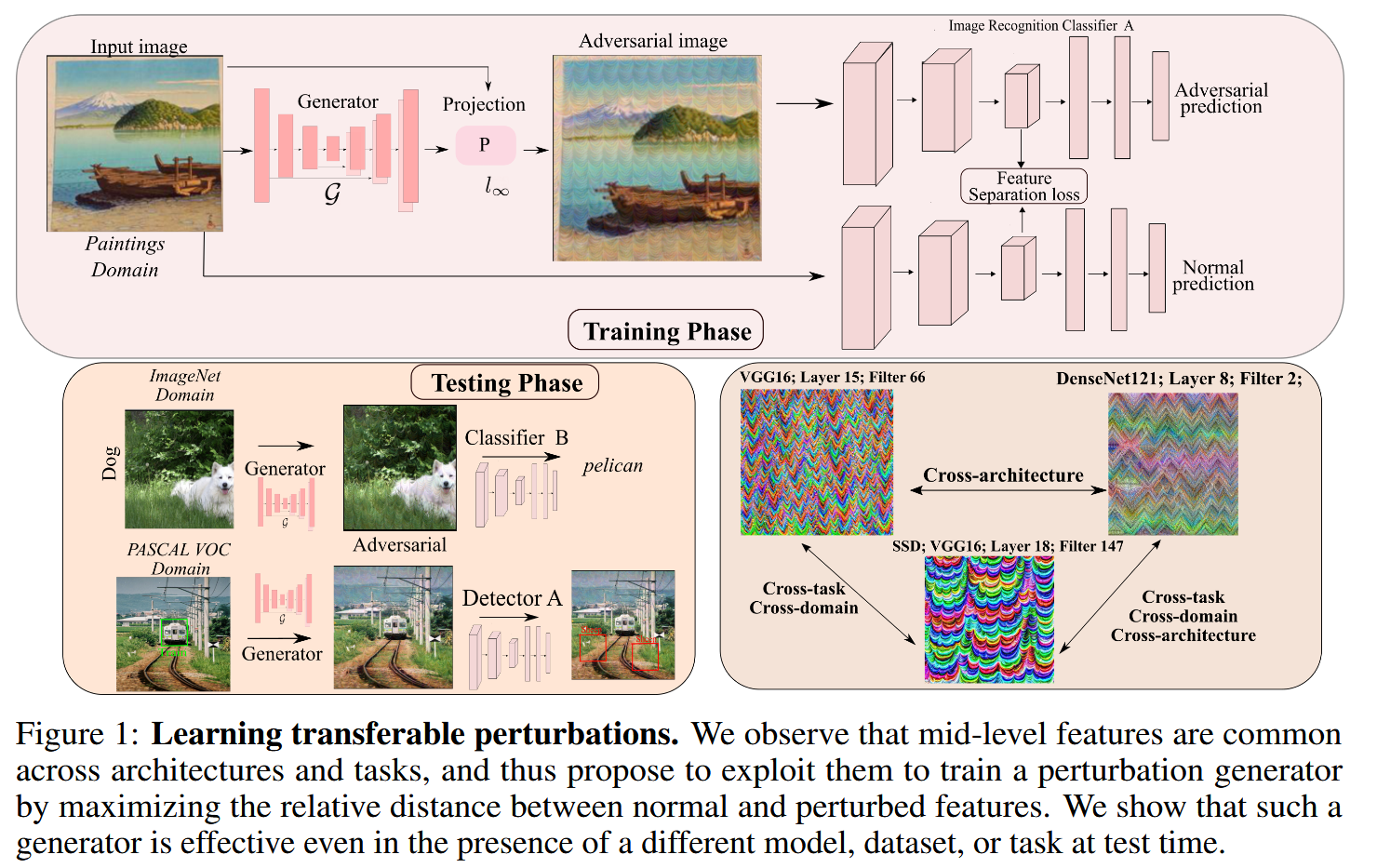
图1:学习可迁移的扰动。我们观察到中层特征在不同架构和任务之间具有共性,因此提议利用这些特征来训练一个扰动生成器,具体做法是最大化正常特征和受扰动特征之间的相对距离。我们证明了即使在测试时面对不同的模型、数据集或任务,这样的生成器依然有效。
相关工作-Related Work
该部分主要回顾了对抗攻击相关研究,重点介绍基于生成器的攻击方法,通过对比分析突出本文研究的改进方向,具体内容如下:
- 对抗攻击研究综述:对抗攻击旨在揭示深度网络对不可察觉扰动的脆弱性。早期研究提出单步快速梯度下降、基于优化的攻击方法(如CW、JSMA 等) ,这些方法依赖于具体图像。之后出现了通用对抗扰动(UAP),试图学习一个能独立于输入图像愚弄分类器的单一扰动,相关研究通过迭代更新或计算特征图雅可比矩阵的奇异向量来生成UAP。同时,也有研究探索迭代对抗攻击策略在不同架构间的迁移,但这些方法存在推理时计算成本高或迁移率低的问题,且大多依赖目标域数据。
- 基于生成器的攻击方法:生成对抗扰动(GAP)开创了利用生成器网络生成UAP的先河,advGAN框架进一步引入蒸馏技术进行黑盒攻击。然而,这些方法高度依赖目标域数据。为解决这一问题,有研究提出相对交叉熵损失,提升了跨数据集的泛化能力,还有研究通过区域范数层生成UAP以增强扰动均匀性。但上述方法都依赖被攻击模型的分类边界,容易导致对源数据的过拟合。相比之下,本文将中层特征视为更鲁棒的共享信号,跨越不同架构、数据集甚至任务,实验将证明利用该信息训练可迁移扰动生成器的优越性。
方法-Methodology
该部分主要介绍了利用深度神经网络(DNN)中层特征训练可迁移对抗扰动生成器的方法,具体如下:
- 符号定义与目标设定:定义彩色图像 x i x_{i} xi、真实标签 y i y_{i} yi、卷积神经网络 f f f 及其在 l ˉ \bar{l} lˉ 层提取的特征图 f ℓ ( x i ) f_{\ell}(x_{i}) fℓ(xi) 。目标是训练生成器 G G G,使其产生的扰动 δ i \delta_{i} δi 添加到 x i x_{i} xi 后能改变预测标签。
- 训练方法与损失函数:将 x i x_{i} xi 输入生成器 G G G 得到无界对抗图像 G ( x i ) G(x_{i}) G(xi),经裁剪使其在 ℓ ∞ \ell_{\infty} ℓ∞ 范数下与 x i x_{i} xi 的距离不超过 ϵ \epsilon ϵ,得到 x ^ i \hat{x}_{i} x^i 。与以往依赖网络 f f f 最终分类边界训练生成器的方法不同,本文利用 f f f 的中层特征,通过最大化正常特征图 f ℓ ( x i ) f_{\ell}(x_{i}) fℓ(xi) 和对抗特征图 f ℓ ( x ^ i ) f_{\ell}(\hat{x}_{i}) fℓ(x^i) 在 l l l 层的 L 2 L_{2} L2 距离来训练生成器,采用的特征分离损失项为 L f e a t ( x i , x ^ i ) = ∥ f ℓ ( x i ) − f ℓ ( x ^ i ) ∥ F 2 \mathcal{L}_{feat }\left(x_{i}, \hat{x}_{i}\right)=\left\| f_{\ell}\left(x_{i}\right)-f_{\ell}\left(\hat{x}_{i}\right)\right\| _{F}^{2} Lfeat(xi,x^i)=∥fℓ(xi)−fℓ(x^i)∥F2 ,其中 ∥ ⋅ ∥ F \|\cdot\|_{F} ∥⋅∥F 是Frobenius范数。
- 扰动可迁移性的原因
- CNN各层特征特点:CNN底层滤波器提取颜色和边缘信息,顶层滤波器关注对象表示,具有较强的任务特异性;中层滤波器学习纹理等更细致的特征,在不同架构、数据集和任务间相似性较高。攻击底层特征需较大扰动强度,攻击顶层特征在不同数据或架构间迁移性差,而攻击中层特征可产生高度可迁移的扰动。

图2:滤波器可视化。不同卷积神经网络中层的滤波器遵循相似的激活模式,这种模式在不同任务中也普遍存在,而靠近分类层的滤波器则专注于对象级别的特征,因此具有更强的任务特异性。
图3:特征可视化。我们使用t-SNE对DenseNet121不同层针对不同数据集提取的特征进行可视化。 - 数据相似性的影响:当攻击者无法获取目标数据时,数据相似性会影响扰动的有效性。如Comics或Paintings数据集与ImageNet数据集的特征接近,用其训练的生成器对ImageNet训练的网络更有效;ChestX数据集与ImageNet差异大,但利用中层特征训练的生成器在ImageNet上仍有一定效果。
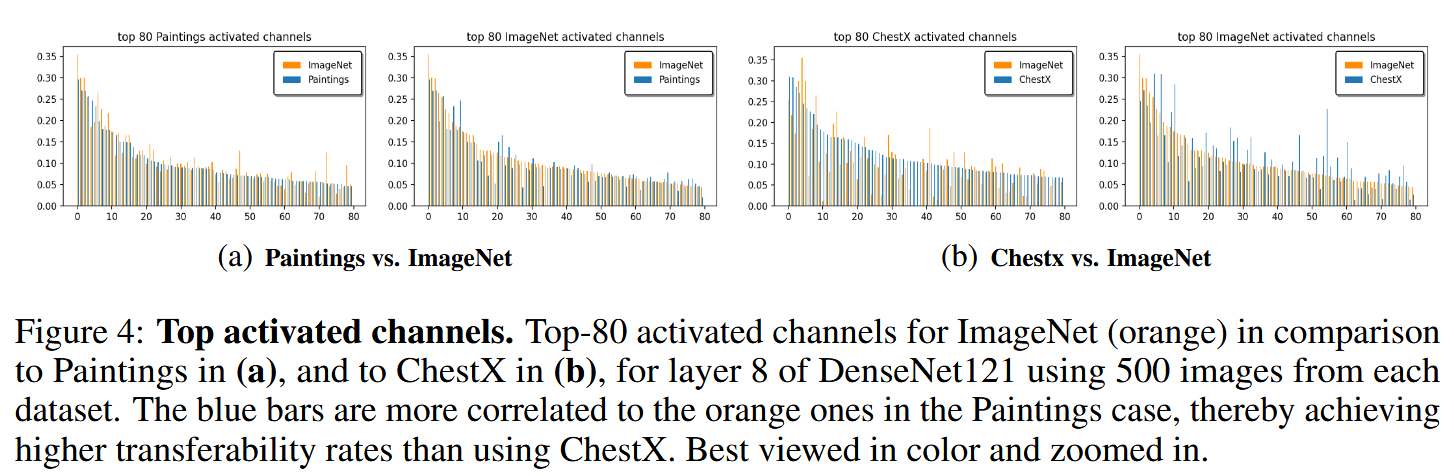
图4:顶级激活通道。图(a)展示了DenseNet121第8层中,ImageNet(橙色)与Paintings数据集相比的前80个激活通道;图(b)展示了ImageNet与ChestX数据集相比的前80个激活通道,每个数据集均使用500张图像。在与Paintings数据集对比的情况下,蓝色柱状图与橙色柱状图的相关性更强,因此与使用ChestX数据集相比,能实现更高的迁移率。建议以彩色并放大查看。
- CNN各层特征特点:CNN底层滤波器提取颜色和边缘信息,顶层滤波器关注对象表示,具有较强的任务特异性;中层滤波器学习纹理等更细致的特征,在不同架构、数据集和任务间相似性较高。攻击底层特征需较大扰动强度,攻击顶层特征在不同数据或架构间迁移性差,而攻击中层特征可产生高度可迁移的扰动。
- 训练算法流程:详细介绍了训练可迁移对抗扰动生成器的算法流程。输入干净图像 x i x_{i} xi、预训练分类器 f f f 和扰动 ℓ ∞ \ell_{\infty} ℓ∞ 约束 ϵ \epsilon ϵ,初始化生成器,冻结 f f f 的参数。在训练循环中,获取 x i x_{i} xi 的正常特征图 f ℓ ( x i ) f_{\ell}(x_{i}) fℓ(xi) ,生成并裁剪对抗图像 x ^ i \hat{x}_{i} x^i ,计算其对抗特征图 f ℓ ( x ^ i ) f_{\ell}(\hat{x}_{i}) fℓ(x^i) 和特征分离损失 L f e a t L_{feat } Lfeat ,基于Adam算法更新生成器权重,直至收敛返回训练好的生成器 G ∗ G^{*} G∗。

实验-Experiment
该部分主要评估了所提攻击策略在多种场景下的有效性,通过与其他基于生成器的攻击方法对比,展示了该方法的优势,具体内容如下:
- 实验设置
- 数据集:使用ImageNet、Comics、Paintings、ChestX数据集训练生成器,从ImageNet验证集选5000张图像评估攻击迁移性,以愚弄率和攻击前后top-1错误率的绝对差值为指标。
- 模型:目标模型包括VGG16、ResNet152等多种在ImageNet上预训练的网络,以及在ChestX上预训练的ChestXNet;扰动生成器采用与对比方法相同的架构,用Adam优化器训练。
- 攻击设置:涵盖白盒攻击、标准黑盒攻击、严格黑盒攻击和极端黑盒攻击四种场景。
- 实验结果与分析
- 对未知目标模型的迁移性:在标准白盒和黑盒设置下,该方法平均愚弄率比CDA和GAP分别高10.5和13.5个百分点,在同一家族网络内攻击迁移性表现也更优,且随着训练模型与目标模型深度差异增大,优势更明显,在训练样本较少时仍能保持较高愚弄率。
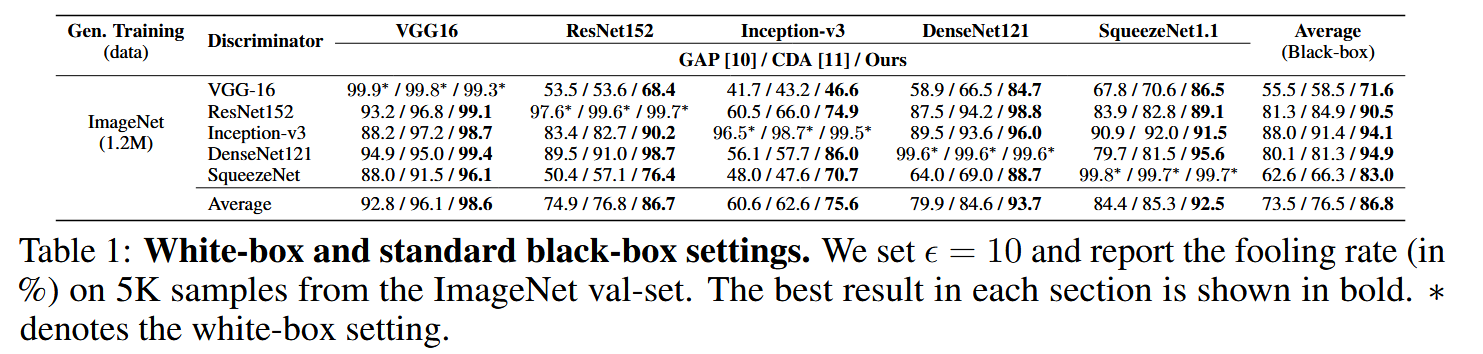
表1:白盒和标准黑盒设置。我们将 ϵ \epsilon ϵ 设为10,并报告在ImageNet验证集中5000个样本上的愚弄率(以百分比表示)。每部分的最佳结果以粗体显示。 ∗ ∗ ∗表示白盒设置。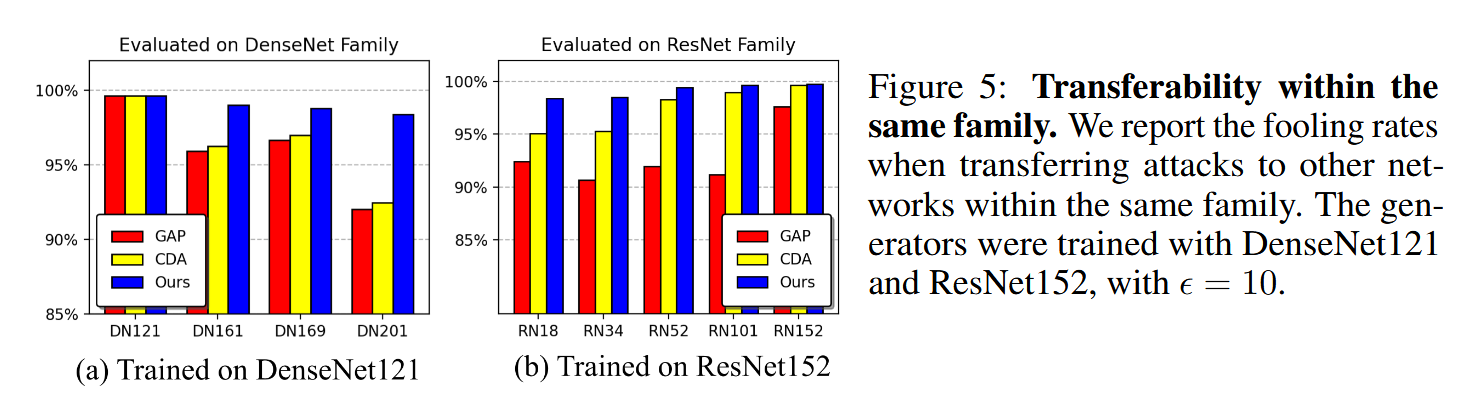
图5:同一家族内的迁移性。我们报告了将攻击迁移到同一家族内其他网络时的愚弄率。生成器是用DenseNet121和ResNet152进行训练的, ϵ \epsilon ϵ 的值为10。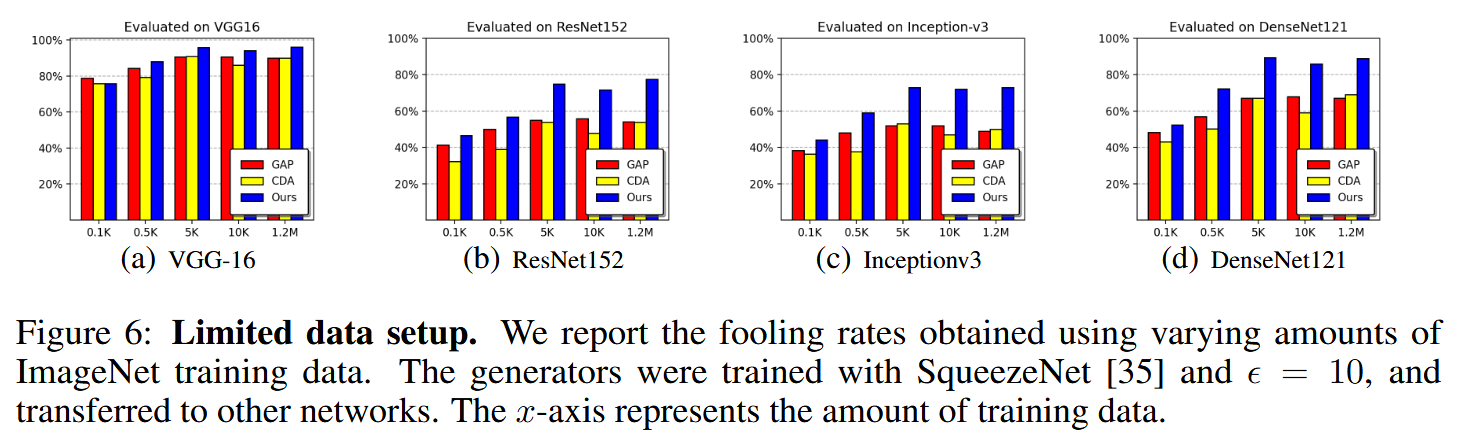
图6:有限数据设置。我们报告了使用不同数量的ImageNet训练数据所获得的愚弄率。生成器使用SqueezeNet [35]进行训练, ϵ \epsilon ϵ取值为10,并将其应用于其他网络。横轴表示训练数据的数量。 - 对未知目标数据的迁移性:在严格黑盒设置下,使用不同数据集训练生成器,该方法在Comics、Paintings和ChestX数据集上均优于基线方法,证明即使无目标数据,也能生成高愚弄率的对抗样本,且用所提特征分离损失训练的生成器泛化性更好。
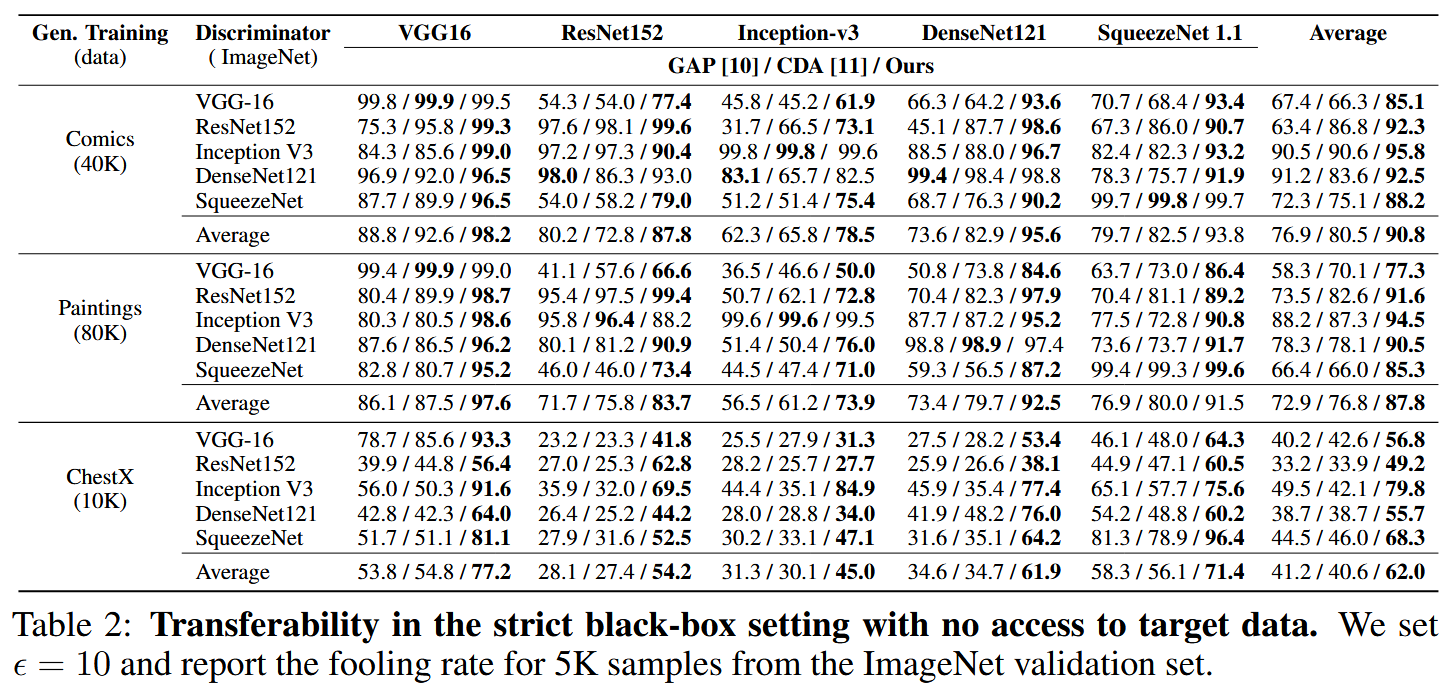
表2:在无法访问目标数据的严格黑盒设置下的可迁移性。我们将 ϵ \epsilon ϵ 设置为10,并报告ImageNet验证集中5000个样本的愚弄率。 - 极端跨域迁移性:在目标架构和数据均未知,且生成器训练所用分类器数据也不同的极端场景下,该方法平均愚弄率达68.5%,比CDA高18.5% 。
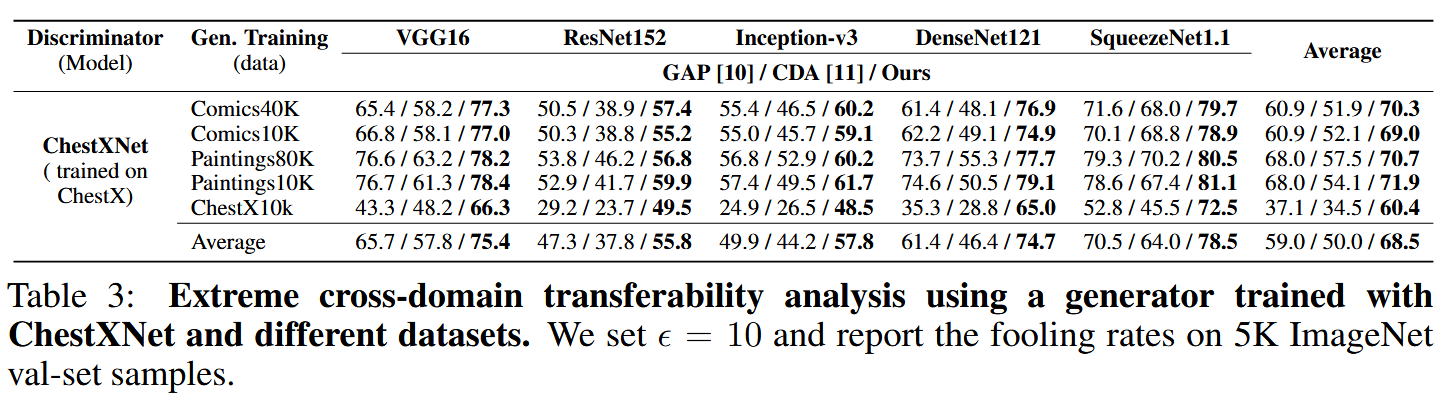
表3:使用在ChestXNet上训练且基于不同数据集的生成器进行的极端跨域迁移性分析。我们将 ϵ \epsilon ϵ 设为10,并报告在5000个ImageNet验证集样本上的愚弄率。 - 对鲁棒模型的迁移性:研究该方法对五种对抗训练防御模型的迁移性,结果显示在HGD、R&P和EnsembleAdv上性能最佳,但现有方法对Feature denoising和PGD防御均难以成功攻击。

表4:对经过对抗训练模型的迁移性。我们按照文献[8]的方法,报告在 ϵ = 16 \epsilon = 16 ϵ=16 的情况下,对ImageNet验证集中5000个样本进行攻击时,top-1错误率的绝对百分比增加量。 - 跨任务迁移性分析:用图像分类器训练的扰动生成器攻击不同骨干网络的SSD目标检测器,该方法能显著降低检测器的mAP,且比基线方法效果更好,表明学习影响中层特征的扰动比关注分类边界更有效。
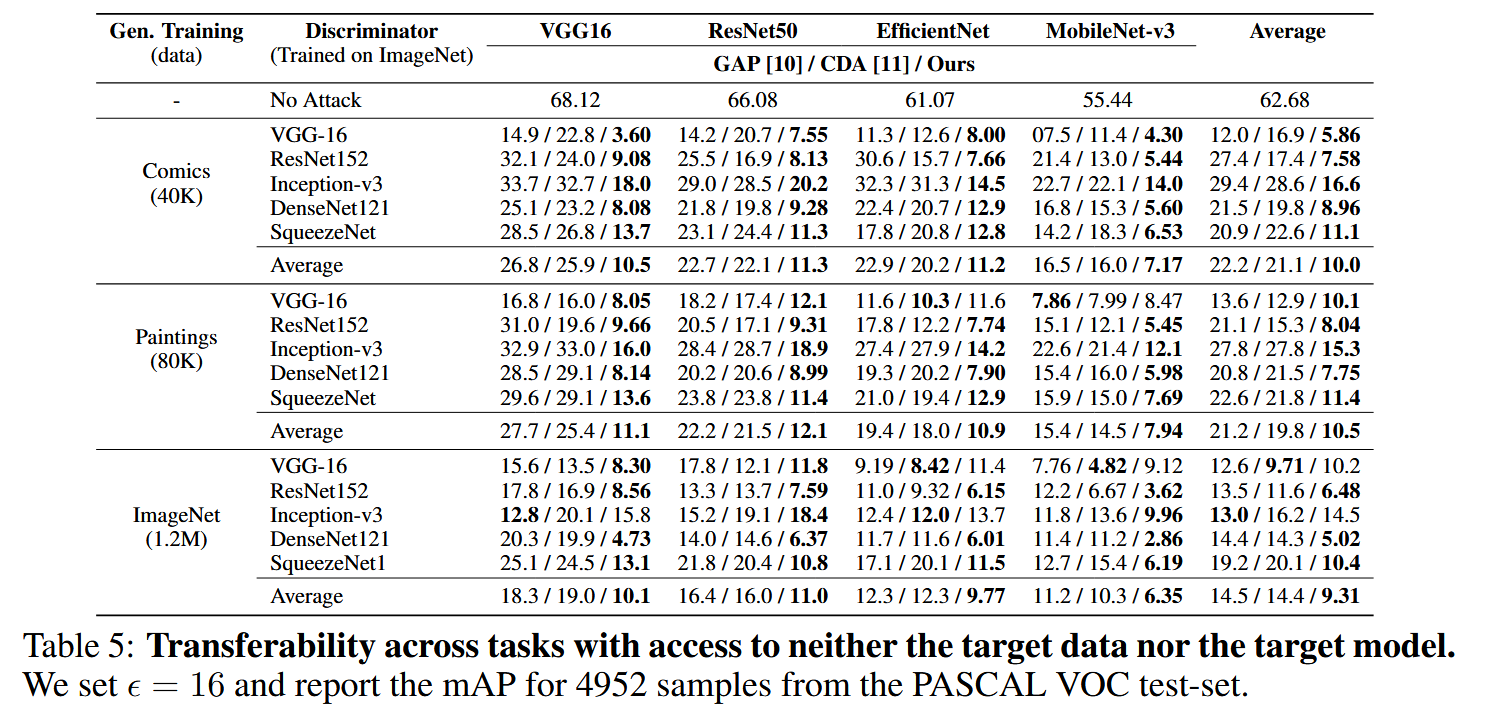
表5:在既无法访问目标数据也无法访问目标模型的情况下的跨任务迁移性。我们将 ϵ \epsilon ϵ设置为16,并报告来自PASCAL VOC测试集的4952个样本的平均精度均值(mAP)。 - 额外分析:通过t-SNE可视化发现该方法能明显区分正常和对抗图像特征,而CDA不行;可视化对抗图像可知,该方法生成的图像结构化更好,保留了原始图像内容,且扰动模式与受干扰最大的中层滤波器相关,攻击中层滤波器可提高迁移率。
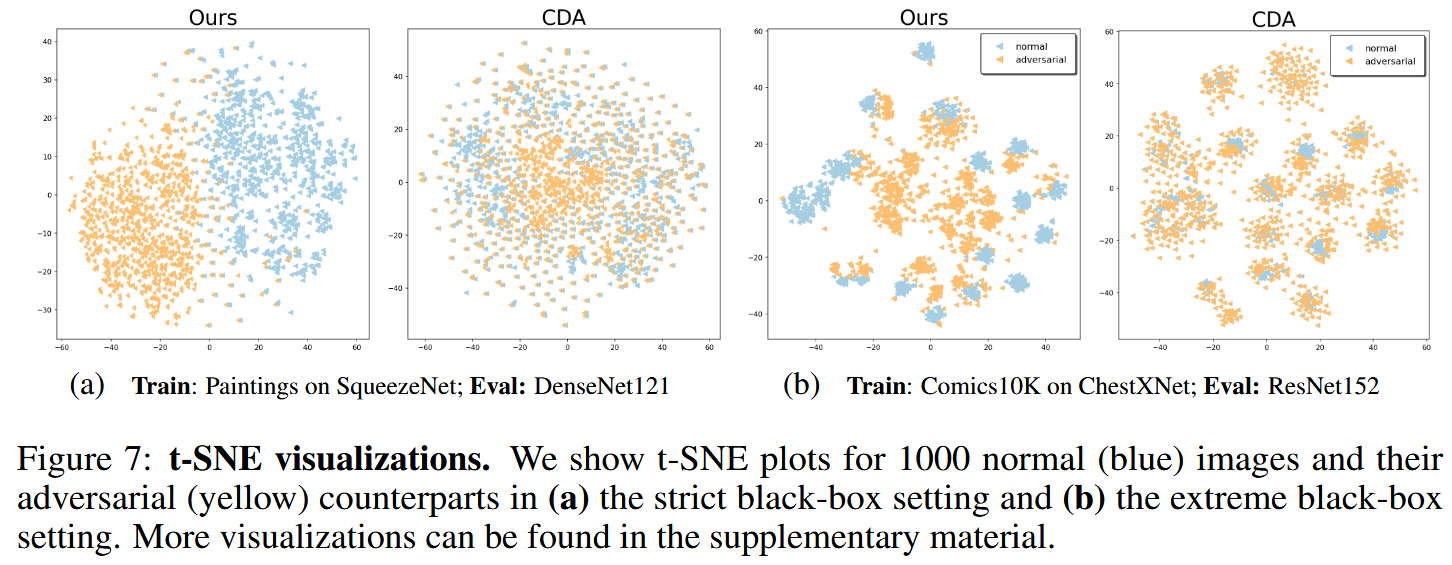
图7:t-SNE可视化。我们展示了(a)严格黑盒设置和(b)极端黑盒设置下1000张正常(蓝色)图像及其对抗(黄色)图像的t-SNE图。更多可视化内容可在补充材料中查看。
图8:定性结果。使用在ImageNet上训练的不同方法的生成器所获得的无界输出的可视化结果。与基线方法相比,我们的方法生成的图像更具结构性,并且能更好地保留原始图像的内容。建议以彩色并放大查看。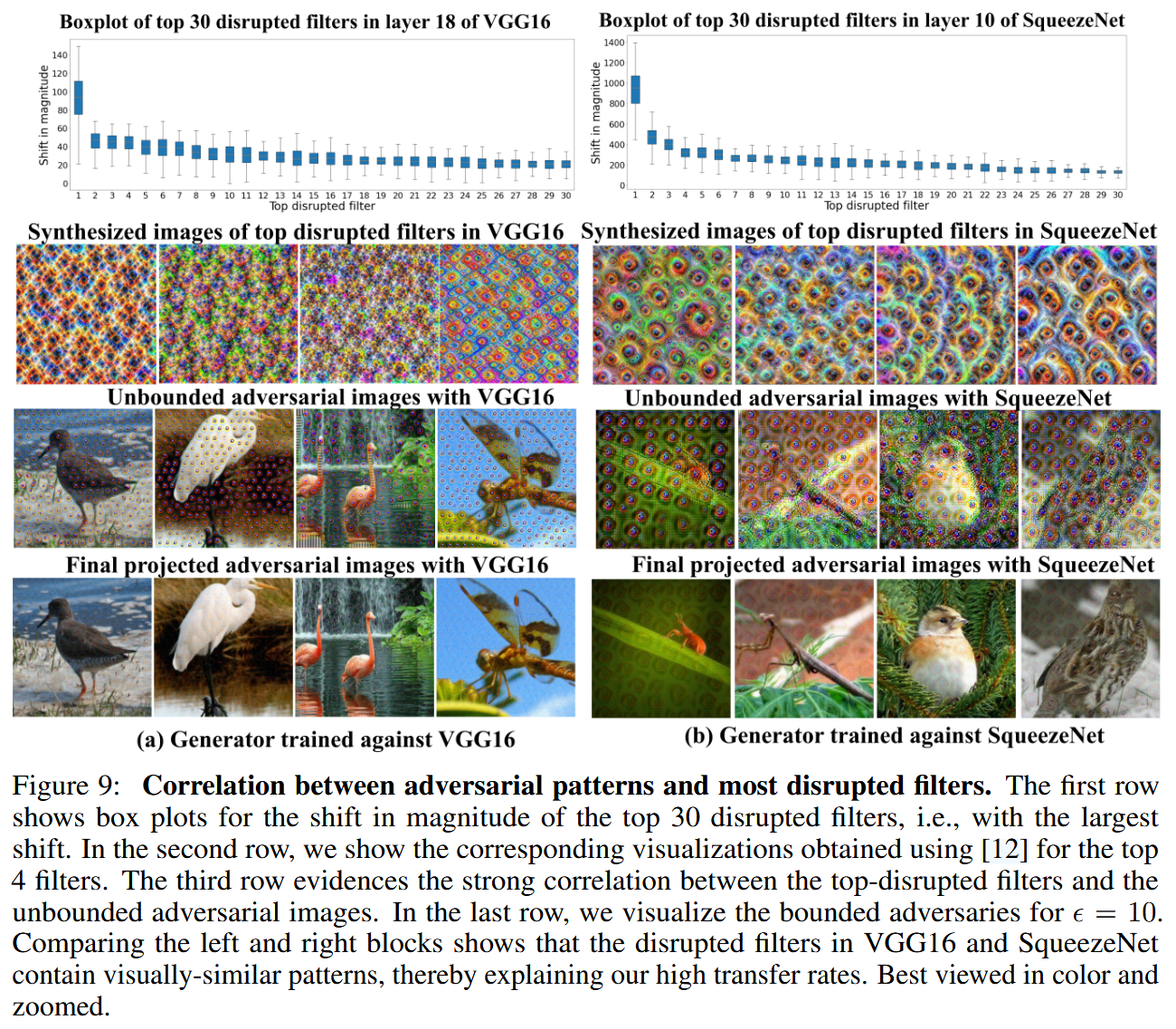
图9:对抗模式与受干扰最严重的滤波器之间的相关性。第一行展示了受干扰最严重的30个滤波器(即变化幅度最大的滤波器)的幅度变化箱线图。第二行展示了使用文献[12]中的方法对前4个滤波器进行的相应可视化。第三行证明了受干扰最严重的滤波器与无界对抗图像之间的强相关性。最后一行展示了 ϵ = 10 \epsilon = 10 ϵ=10 时的有界对抗样本的可视化。对比左右两组图可以发现,VGG16和SqueezeNet中受干扰的滤波器包含视觉上相似的模式,这也就解释了我们的方法具有较高迁移率的原因。建议以彩色并放大查看。
- 对未知目标模型的迁移性:在标准白盒和黑盒设置下,该方法平均愚弄率比CDA和GAP分别高10.5和13.5个百分点,在同一家族网络内攻击迁移性表现也更优,且随着训练模型与目标模型深度差异增大,优势更明显,在训练样本较少时仍能保持较高愚弄率。
- 研究局限性:实验每次仅选择单个攻击层,虽经实验确定了各模型的较好攻击层,但无法保证其最优,同时攻击多个层的组合可能效果更好,但需要进一步调整组合方式。
结论-Conclusion
这部分内容总结了研究成果,指出研究局限并对未来研究方向提出展望,具体如下:
- 研究成果总结:本文探索结合中层特征与生成网络来学习可迁移的扰动。研究表明,利用特征分离损失训练的生成器,能够成功欺骗不同架构和任务的模型。并且,即使使用来自不同领域的代理数据集,也可以学习到有效的扰动。通过大量实验对比,证实了该方法在广泛的架构和任务上,性能优于当前最先进的攻击策略。
- 研究局限性:实验仅针对未防御的模型展开,主要原因是缺乏跨架构的公开可用的鲁棒模型。这意味着在面对防御机制时,该方法的有效性尚未得到充分验证。
- 未来研究展望:后续研究将着重探索该方法在面对防御机制时的表现。同时,深入分析随着架构变化,学习到的滤波器组的变化情况,有望为构建更强大的黑盒模型提供理论支持和技术指导。
更广泛的影响-Borader Impact
这部分主要阐述了研究对抗攻击的重要意义,以及该研究结果对社会潜在的影响,并对未来研究方向提出期望,具体内容如下:
- 研究对抗攻击的重要性:深入理解对抗攻击的强度,对于未来构建强大的防御机制起着关键作用。在像自动驾驶、生物识别等安全关键型应用领域,对抗样本的潜在影响是巨大的。一旦这些系统遭受对抗攻击,可能引发严重的安全事故,危及生命和财产安全。
- 研究结果的社会影响:通过一系列广泛的实验,研究发现现代网络在极端黑盒攻击场景下依然存在较高的脆弱性。这一发现揭示了当前神经网络安全防护的不足,可能会引发公众对相关技术安全性的担忧,同时也凸显了加强网络安全研究的紧迫性。
- 对未来研究的期望:希望该研究成果能够激发研究社区进一步探索神经网络在对抗攻击环境下的内部运行机制。通过对这些机制的深入分析,能够设计出更加有效的防御策略,提高神经网络系统的安全性和可靠性,从而降低对抗攻击对社会的潜在威胁。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 29
29 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)