【机器学习】—决策树原理与实现
注:软件可通过本文关联资源下载。
·
一、模型基本原理
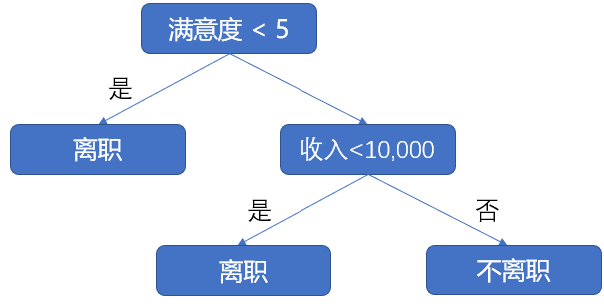
下图所示为一个典型的决策树模型:员工离职预测模型的简单演示。该决策树首先判断员工满意度是否小于5,答案为“是”则认为该员工会离职,答案为“否”则接着判断其收入是否小于10,000元,答案为“是”则认为该员工会离职,答案为“否”则认为该员工不会离职。
这里解释几个决策树模型的重要关键词:根节点、父节点、子节点和叶子节点
父节点和子节点是相对的,子节点由父节点根据某一规则分裂而来,然后子节点作为新的父亲节点继续分裂,直至不能分裂为止。
根节点是没有父节点的节点,即初始节点。
叶子节点则是没有子节点的节点,即最后的节点。
决策树模型的关键即是如何选择合适的节点进行分裂。在上图中,最上面的“满意度”就是根节点,其中“收入<10,000”则为其子节点,同时也是其下面两个节点的父节点,最后的“离职”及“不离职”则为叶子节点。




















二、模型代码实现




注:软件可通过本文关联资源下载
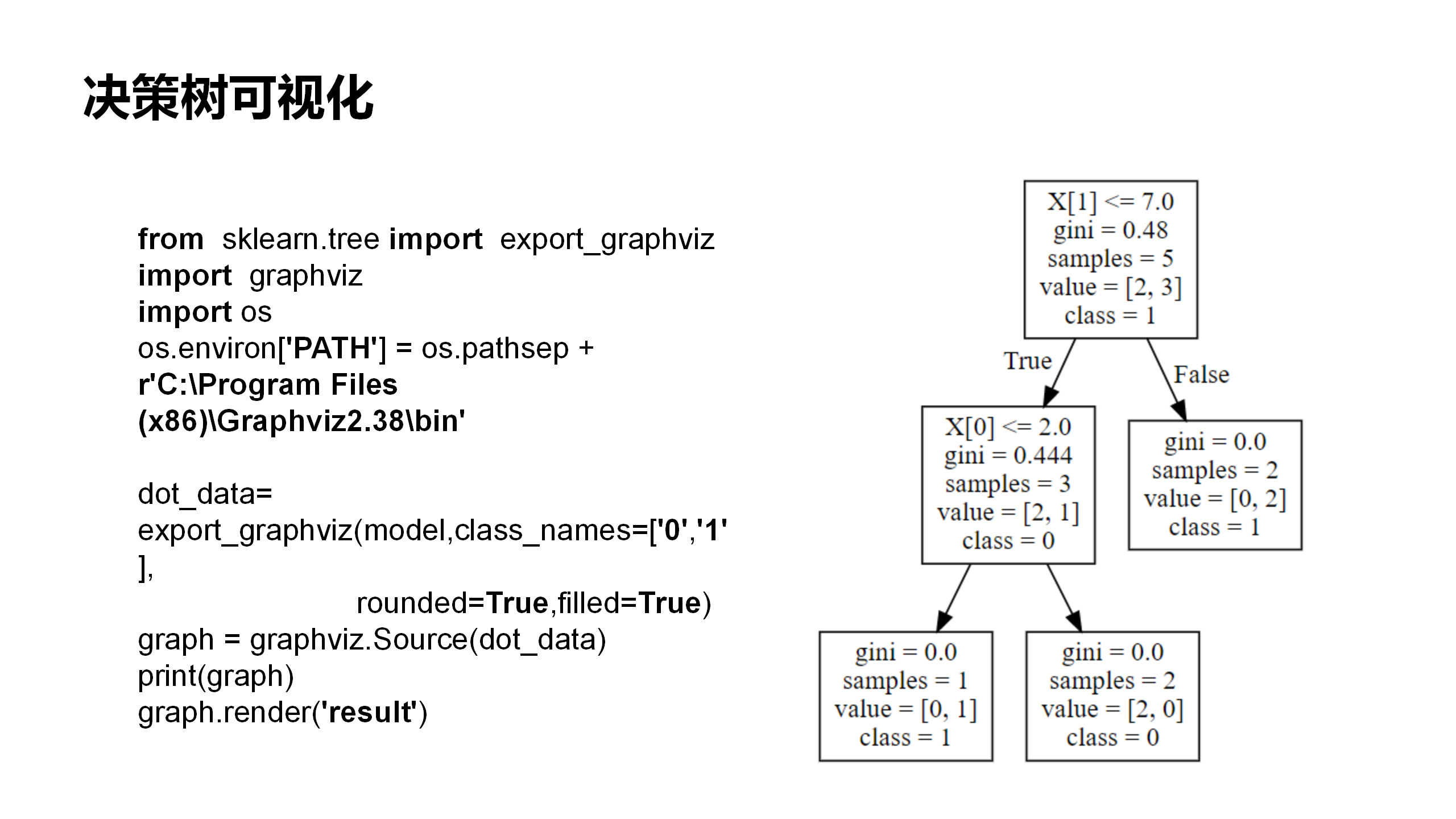






决策树分类模型代码
# 决策树分类模型代码实现
# 【1】导入资源包
from sklearn.tree import DecisionTreeClassifier
# 【2】加载样本数据
x = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
y = [0, 0, 1, 1, 0]
# 【3】模型搭建
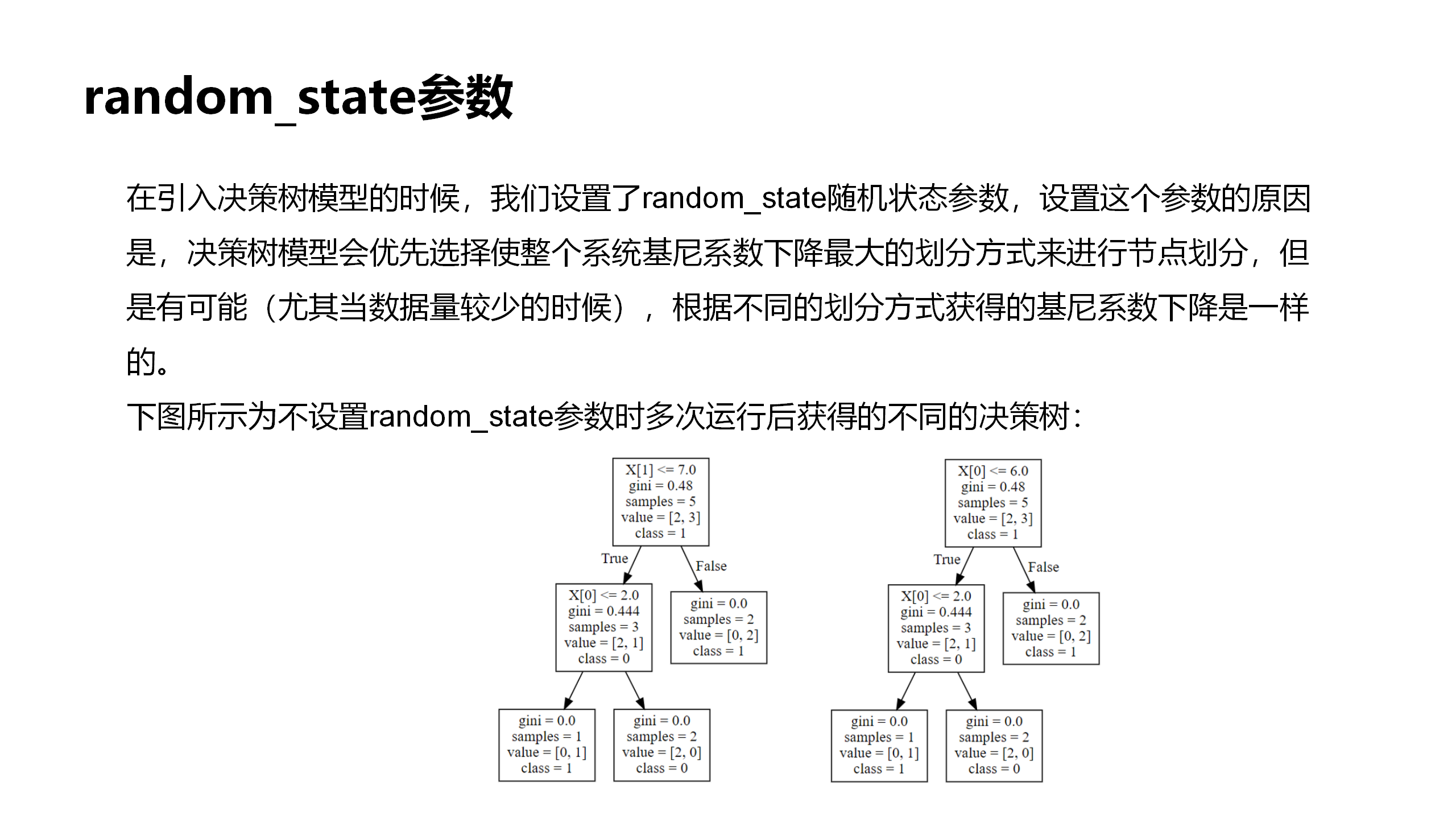
dtc = DecisionTreeClassifier(random_state=1)
# 【4】模型训练
dtc.fit(x, y)
# 【5】模型预测
y_pred = dtc.predict(x)
print(y_pred)
# 【6】输出预测的概率值
y_pred_proba = dtc.predict_proba(x)
import pandas as pd
df = pd.DataFrame(y_pred_proba, columns=['不离职概率', '离职概率'])
print(df)决策树回归模型代码
#决策树分类模型代码实现
#【1】导入资源包
from sklearn.tree import DecisionTreeRegressor
#【2】加载样本数据
x = [[1,2],[3,4],[5,6],[7,8],[9,10]]
y = [0,0,1,1,0]
#【3】模型搭建
dtc = DecisionTreeRegressor(random_state=1)
#【4】模型训练
dtc.fit(x,y)
#【5】模型预测
y_pred = dtc.predict(x)
print(y_pred)决策树可视化代码
from sklearn.tree import export_graphviz
import graphviz
import os
os.environ['PATH'] = os.pathsep + r'C:\Program Files (x86)\Graphviz2.38\bin'
dot_data= export_graphviz(model,class_names=['0','1'],
rounded=True,filled=True)
graph = graphviz.Source(dot_data)
print(graph)
graph.render('result')

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)