51c深度学习~合集5
Google DeepMind 通过优化和推出改进的排序和哈希算法,供世界各地的开发人员使用,AlphaDev 展示了其概括和发现具有现实影响的新算法的能力。AlphaDev 可被视为开发通用 AI 工具的一步,它可以帮助优化整个计算生态系统并解决其他造福社会的问题。虽然在低级汇编指令空间中进行优化非常强大,但随着算法的增长, AlphaDev 仍存在局限性,团队目前正在探索其直接在高级语言(如
我自己的原文哦~ https://blog.51cto.com/whaosoft/12328844
#多尺度特征融合
论文先行 论文地址:https://arxiv.org/pdf/2112.13082.pdf
此为一种基于单模态语义分割的新型坑洼检测方法。它首先使用卷积神经网络从输入图像中提取视觉特征,然后通道注意力模块重新加权通道特征以增强不同特征图的一致性。随后,研究者采用了一个空洞空间金字塔池化模块(由串联的空洞卷积组成,具有渐进的扩张率)来整合空间上下文信息。
这有助于更好地区分坑洼和未损坏的道路区域。最后,使用研究者提出的多尺度特征融合模块融合相邻层中的特征图,这进一步减少了不同特征通道层之间的语义差距。在Pothole-600数据集上进行了大量实验,以证明提出的方法的有效性。定量比较表明,新提出的方法在RGB图像和转换后的视差图像上均达到了最先进的 (SoTA) 性能,优于三个SoTA单模态语义分割网络。
在最先进的(SoTA)语义分割CNN中,全卷积网络(FCN)用卷积层替换了传统分类网络中使用的全连接层,以获得更好的分割结果。上下文信息融合已被证明是一种有效的工具,可用于提高分割精度。ParseNet通过连接全局池化特征来捕获全局上下文。PSPNet引入了空间金字塔池化(SPP)模块来收集不同尺度的上下文信息。Atrous SPP(ASPP)应用不同的空洞卷积来捕获多尺度上下文信息,而不会引入额外的参数。
是又一个新框架...
给定道路图像,坑洼可以具有不同的形状和尺度。我们可以通过一系列的卷积和池化操作获得顶层的特征图。虽然特征图具有丰富的语义信息,但其分辨率不足以提供准确的语义预测。不幸的是,直接结合低级特征图只能带来非常有限的改进。为了克服这个缺点,研究者设计了一个有效的特征融合模块。
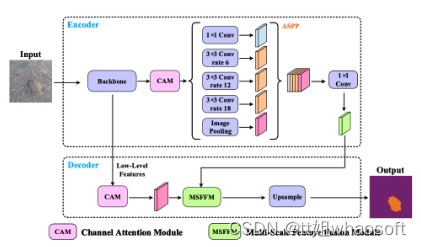
研究者提出的道路坑洼检测网络的架构如上图所示。首先,采用预训练的dilated ResNet-101作为主干来提取视觉特征,还在最后两个ResNet-101块中用空洞卷积替换下采样操作,因此最终特征图的大小是输入图像的1/8。
该模块有助于在不引入额外参数的情况下保留更多细节。此外,采用Deeplabv3中使用的ASPP模块来收集顶层特征图中的上下文信息。然后,采用CAM重新加权不同通道中的特征图。它可以突出一些特征,从而产生更好的语义预测。最后,将不同级别的特征图输入到MSFFM中,以提高坑洼轮廓附近的分割性能。
Multi-scale feature fusion
顶部特征图具有丰富的语义信息,但其分辨率较低,尤其是在坑洼边界附近。另一方面,较低的特征图具有低级语义信息但分辨率更高。为了解决这个问题,一些框架直接将不同层的特征图组合起来。然而,由于不同尺度的特征图之间的语义差距,他们取得的改进非常有限。
注意模块已广泛应用于许多工作中。受一些成功应用的空间注意力机制的启发,研究者引入了MSFFM,它基于空间注意力来有效地融合不同尺度的特征图。语义差距是特征融合的关键挑战之一。
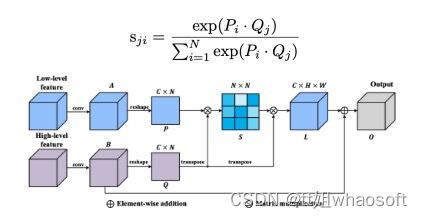
为了解决这个问题,MSFFM通过矩阵乘法计算不同特征图中像素之间的相关性,然后将相关性用作更高级别特征图的权重向量。
总之,研究者利用矩阵乘法来测量来自不同层的特征图中像素的相关性,将来自较低特征图的详细信息整合到最终输出中,从而提高了坑洞边界的语义分割性能。在最后两层之间应用这个模块。
Channel-wise feature reweighing
众所周知,高级特征具有丰富的语义信息,每个通道图都可以看作是一个特定类别的响应。每个响应都会在不同程度上影响最终的语义预测。因此,研究者利用CAM,如下图所示,通过改变每个通道中的特征权重来增强每一层中特征图的一致性。
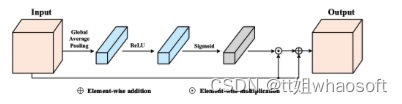
CAM旨在根据每个特征图的整体像素重新加权每个通道。首先采用全局平均池化层来压缩空间信息。随后,使用修正线性单元(ReLU)和sigmoid函数生成权重向量,最终通过逐元素乘法运算将权重向量与输入特征图组合以生成输出特征图。整体信息被整合到权重向量中,使得特征图更可靠,坑洼检测结果更接近GT实况。在最终的实验中,在第4层和第5层使用了CAM。
实验结果验证
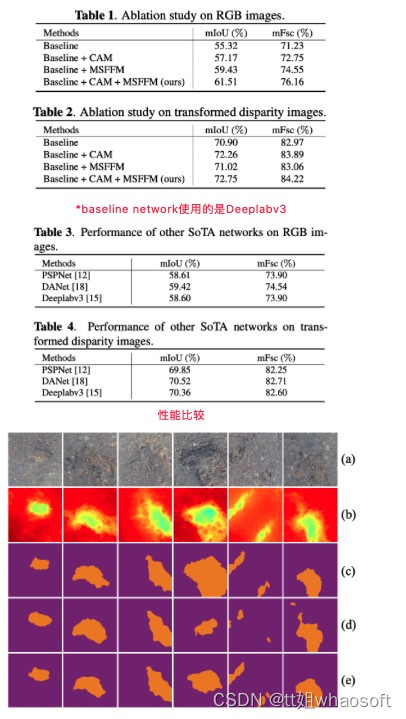
坑洼检测结果示例:(a) RGB图像;(b)转换后的视差图像;(c)坑洼地面真相;(d)语义RGB图像分割结果;(e)语义变换视差图像分割结果。
在上图中提供了提出的道路坑洼检测方法的一些定性结果,其中可以观察到CNN在转换后的视差图像上取得了准确的结果。从综合实验评估中获得的结果证明了新提出的方法与其他SoTA技术相比的有效性和优越性。由于提出了CAM和MSFFM,新方法在RGB和转换后的视差图像上实现了更好的坑洼检测性能。
...
#xxx
...
#xxx
...
#xxx
...
#SFT的本质,其实是在优化RL目标的下界...
TL;DR:本文推导出在稀疏奖励的情况下, 标准 SFT 的训练目标其实是 RL 目标的一个(松的)下界,为了收紧这个下界同时保持训练稳定,作者引入了一个桥梁分布 来进行调节。最终在形式上得到了一个重要性加权版本的 SFT 目标。
论文链接:https://arxiv.org/abs/2507.12856SFT 的优化目标是 RL 的下界
首先,我们通过目标函数的推导,将 SFT 和 RL 联系起来。
RL 策略梯度算法中,训练策略模型 的目标函数为:
其中 是一条采样轨迹,是轨迹的 的累积奖励, 是参数化模型 采样得到轨迹 的概率, 是一组轨迹的集合。
我们知道,RL 和 SFT 最主要的差异就是训练数据的分布。SFT 中,我们是有一组固定的标注数据,比如人类手写的回复或者预训练大模型生成的回复,SFT 在这些标注数据上进行模仿学习的训练。从 RL 的视角来看,相当于离线地从某个参考分布 中采样轨迹 ,然后过滤出其中优质的样本。RL 的数据则是在线地采样当前模型的回复,根据奖励函数给出的奖励值优化策略模型,提升高奖励值的样本被采样出的概率。
为了将 RL 和 SFT 联系起来,我们首先对 RL 训练目标 (式 1)应用重要性采样, 将期望的分布从在线采样的 (其实写作 更方便对比理解?)转换为离线采样的 :
接下来一步是关键,对重要性采样的系数
应用不等式 :
这里绿色部分都是与参数 无关的,可以把他们都放在一个常数项中。
在 SFT 的设定下,我们只有 “好的” 回复数据。从 RL 的视角来看,这可以理解为我们有一个打分函数 能够区分出好的回复和差的回复,并据此构建一个奖励函数 ,只对打分值为正的样本给出奖励值 1,其他样本奖励值均为 0。这个稀疏的奖励函数可以从完整采样空间 中 过滤出 “好的” 回复数据 。这里的 就是 SFT 设定下的标注数据集,从而有:
上式右侧就是标准的 SFT 目标函数,至此我们推导出结论:在稀疏奖励的设定下,SFT 的优化目标是 RL 的一个下界。
从 RL 的视角来看,这个结论说明标准的 SFT 训练确实是会有一定效果的,因为它真的在优化 RL 策略梯度目标的一个下界。但是,SFT 目标作为一个下界,影响性能的另一个关键点在于这个下界够不够 “紧”。
遗憾的是,标准 SFT 情况下,这个下界可能不够紧,并且在训练过程中,随着 与 的差异越来越大,这个下界会越来越松,即离真正的 RL 目标越来越远。更遗憾的是,在标准的 SFT 中,我们无法调整和优化这个下界紧的程度,因为在式 2 中,没有任何可以由我们自主调整的项。
引入桥梁分布 q
现在我们已经推导出 SFT 的优化目标是 RL 的一个下界,但是也发现随着训练的进行这个下界越来越松。那么我们应该如何调整 SFT 的训练目标才能改进这一点呢?
iw SFT 的方案是:引入一个辅助分布 ,作为一个可调整的项,选择合适的 ,在收紧这个下界的同时,保持训练的稳定,从而优化 SFT 的训练。
具体来说,我们引入一个辅助分布 ,这个分布的形式可以随便选,具体怎么选,涉及到稳定训练与收紧下界的权衡,后面会讨论。现在有了这个辅助分布,我们可以将 RL 的训练目标 重写为:
对 应用同样的不等式,得到:
这样就得到了一个重要性加权(Importance Weighted) 的 SFT 形式 iw SFT:
这个形式相比于原来的 SFT 目标,多了一个权重系数 ,其中 是固定的,但是 是我们可以自由设置的,通过调整辅助分布 ,我们就可以收紧这个下界。接下来的关键问题就是:如何选择分布 的形式呢?
如何选择 q
我们先来看一下 iw sft 的性质。不等式 当且仅当 时取得等号,当 趋近于 时, 趋近于 1,从而趋近于 RL 目标 。也就是说分布 越接近于 ,iw sft 作为 的下界越紧,这是我们想要的。
但是如果简单地取 ,那么随着训练的进行 又会离 越来越远,方差越来越大,重要性采样变得不稳定,最终导致训练不稳定。因此,我们在追求更紧下界的同时, 还要保证 和 差异不要太大,即 ,以稳定训练。这是基于重要性采样的这类方法要面临的经典问题。
总之,分布 具体形式的选择,既要尽可能接近 ,从而保证下界足够紧,又不能离 太远,从而保证方差比较小,来稳定训练。最终,作者采用了如下的形式:
其中 是策略模型参数 的一个时间滞后(可以直接更新也可以 EMA 更新)的版本,这样就能保证训练过程中 与 比较接近,从而有比较紧的下界。同时,在训练过程中,还需要约束重要性权重来控制 的迭代(从而间接地控制 ),从而保证训练的稳定性。具体如何约束呢?作者提出了两种不同的方案。
第一种方案是每步裁剪重要性权重。要将重要性权重控制在一个范围内,直接裁剪是最直接的方式,在 token 维度裁剪:
然后对轨迹维度的重要性权重进行一个整体的裁剪:
第二种方案是平滑重要性权重。通过在轨迹维度对重要性权重进行平滑,来保证其方差较低。具体来说,取:
其中 是轨迹 中 token 的索引, 是一个单调递减函数。
这两种约束方法的细节可以在原文实验部分查看。iw SFT 的具体算法如下所示,其中关键就是权重系数 的计算。
例子
思考一个多臂老虎机的例子,有两个选项:拉左杆和拉右杆,奖励函数是:对于拉右杆一定给出 1 的奖励值,而对于拉左杆则有 50% 概率奖励值为 1,50% 的概率奖励值为 0:
显然,上帝视角下,最优的策略是一直拉右杆。
假设我们的参考策略是等概率地选择拉左杆和拉右杆 ,那么在 SFT 的设定下,我们从 过滤出好的()动作组成数据集 。在这种均匀分布的参考策略下, 的数据中,拉右杆的次数会是拉左杆的两倍,即 1/3 拉左杆和 2/3 拉右杆。
接下来,如果我们在数据集 上进行标准的 SFT 训练,最终学习到的模型 会有 1/3 的概率拉左杆,2/3 的概率拉右杆,这样最终得到的期望奖励值为 5/6。虽然相较于参考策略好了不少,但离最优策略还有差距。这里 SFT 学习不到最优策略的的原因很明显:SFT 无法有效地利用(被过滤掉的)负样本的信息。所以说虽然 SFT 目标是在优化 RL 目标的一个下界,并且可以在参考策略的基础上进一步提升,但最终还是无法通向最优的策略。
而如果我们引入重要性加权的 iw sft,就会在目标函数中自适应地给拉右杆分配更高的权重,直到最终策略收敛到每次都是拉右杆。在这个例子中,iw sft 一定程度上隐式地恢复并利用了负样本的信息。
个人理解,从输入的角度来看,iw sft 的优势在于用到了 的信息。
总结
本文从 RL 和 SFT 各自的目标函数形式入手,推导出了在稀疏奖励的情况下,SFT 的目标是 RL 的一个下界。并提出通过引入桥梁分布 来收紧这个下界,同时约束重要性权重的范围,维持训练稳定。本文对于我们深入理解 SFT 和 RL 训练的本质和区别很有帮助。
...
#Mamba~2
Mamba综述
Mamba是一种新的选择性结构状态空间模型,在长序列建模任务中表现出色。Mamba通过全局感受野和动态加权,缓解了卷积神经网络的建模约束,并提供了类似于Transformers的高级建模能力。至关重要的是,它实现了这一点,而不会产生通常与Transformer相关的二次计算复杂性。由于其相对于前两种主流基础模型的优势,曼巴展示了其作为视觉基础模型的巨大潜力。研究人员正在积极地将曼巴应用于各种计算机视觉任务,导致了许多新兴的工作。为了跟上计算机视觉的快速发展,本文旨在对视觉曼巴方法进行全面综述。本文首先描述了原始曼巴模型的公式。随后,我们对视觉曼巴的综述深入研究了几个具有代表性的骨干网络,以阐明视觉曼巴中的核心见解。然后,我们使用不同的模式对相关作品进行分类,包括图像、视频、点云、多模态等。具体来说,对于图像应用程序,我们将它们进一步组织成不同的任务,以促进更结构化的讨论。最后,我们讨论了视觉曼巴的挑战和未来的研究方向,为这个快速发展的领域的未来研究提供了见解。
开源链接:https://github.com/Ruixxxx/Awesome-Vision-Mamba-Models
总结来说,本文的主要贡献如下:
- 曼巴的形成:本文提供了曼巴和状态空间模型的操作原理的介绍性概述。
- 主干网络:我们提供了几个具有代表性的视觉曼巴骨干网络的详细检查。本分析旨在阐明支撑Visual Mamba框架的核心原则和创新。
- 应用:我们根据不同的模态对曼巴的其他应用进行分类,如图像、视频、点云、多模态数据等。深入探讨了每个类别,以突出曼巴框架如何适应每种模态并使其受益。对于涉及图像的应用,我们进一步将其划分为各种任务,包括但不限于分类、检测和分割。
- 挑战:我们通过分析视觉数据的独特特征、算法的潜在机制以及现实世界应用程序的实际问题,来研究与CV相关的挑战。
- 未来方向:我们探索视觉曼巴的未来研究方向,重点关注数据利用和算法开发方面的潜在进展。
Mamba公式
Mamba是最近的一个序列模型,旨在通过简单地将其参数作为输入的函数来提高SSM基于上下文的推理能力。这里的SSM特别指的是结构化状态空间序列模型(S4)中使用的序列变换,它可以被纳入深度神经网络。Mamba简化了常用的SSM块,形成了简化的SSM架构。在下文中,我们将详细阐述曼巴的核心概念。
SSM
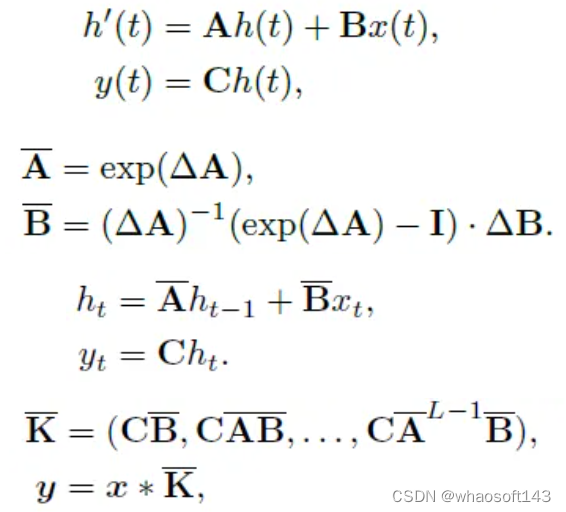
Selective SSM
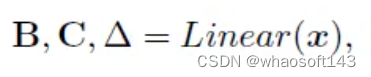
Mamba结构
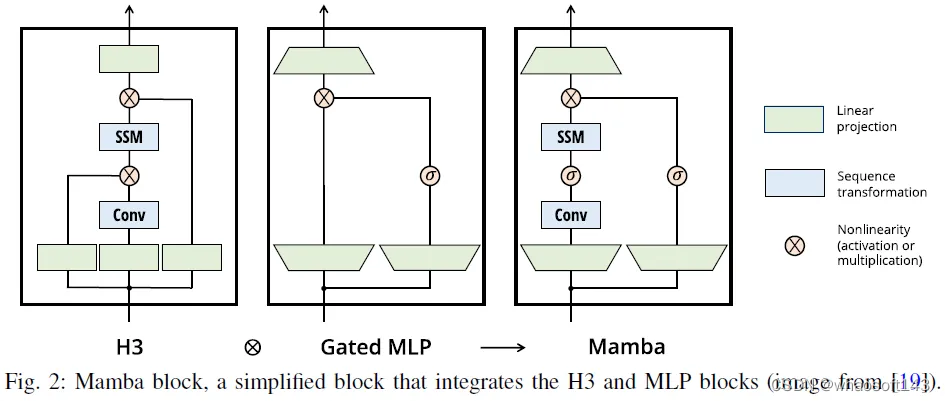
Mamba是一种简化的SSM架构。与通常使用的SSM架构不同,后者将类似线性注意力的块和多层感知器(MLP)块堆叠为Transformer,Mamba将这两个基本块集成起来构建Mamba块。如图2所示,曼巴区块可以从两个不同的角度进行观察。首先,它用激活函数代替线性类注意力或H3块中的乘法门。其次,它将SSM转化纳入MLP阻断的主要途径。Mamba的总体架构由重复的Mamba块组成,这些块与标准规范化层和残差连接交织在一起。
Mamba继承了状态空间模型序列长度的线性可伸缩性,同时实现了Transformer的建模能力。Mamba结合了CV中两种主要类型的基础模型(即CNN和Transformer)的显著优势,使其成为一种很有前途的CV基础模型。与依赖于显式存储整个上下文进行基于上下文的推理的Transformer相比,Mamba利用了一种选择机制。因此,这种选择机制的1D和因果特征成为研究人员将曼巴应用于CV的焦点。
表征学习的主干
Pure Mamba
1)Vim:Vim是一种基于Mamba的架构,直接在类似于ViT的图像补丁序列上操作。首先将输入图像转换为平坦的2D块,然后使用线性投影层对其进行矢量化,并添加位置嵌入以保留空间信息。在ViT和BERT之后,将类令牌附加到补丁令牌序列。然后将整个令牌序列馈送到Vim编码器,该编码器由相同的Vim块组成。如图6所示,如图3(b)所示,Vim块是一个Mamba块,它将后向SSM路径与前向路径集成在一起。
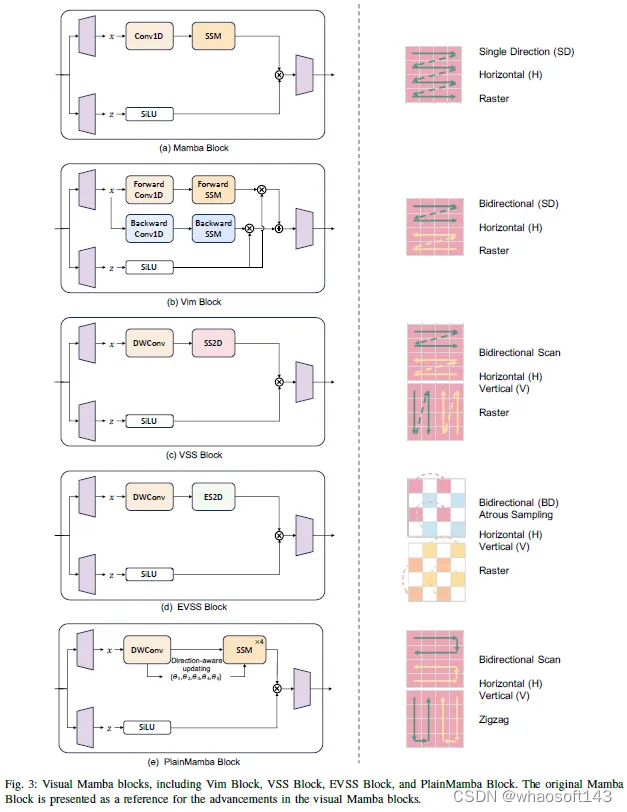
2)VMamba:VMamba确定了将曼巴应用于2D图像的两个挑战,这是由曼巴中选择机制的1D和因果属性引起的。对输入数据的因果处理使曼巴无法吸收来自未扫描数据部分的信息。此外,1D扫描对于涉及在局部和全局尺度上相关的2D空间信息的图像来说不是最优的。
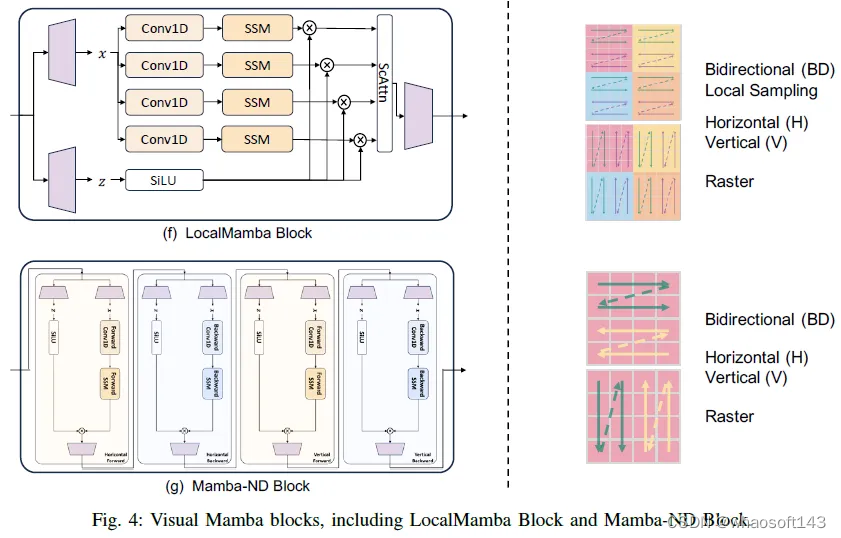
3)Mamba ND:Mamba ND旨在将Mamba扩展到包括图像和视频在内的多维数据。它将1D曼巴层视为一个黑匣子,并探索如何解开和排序多维数据。它主要解决数据缺乏预定义的排序,同时具有固有的空间维度所带来的挑战。考虑到将数据平坦化为1D序列的大量可能方式,Mamba ND仅包括通过沿其维度轴在向前或向后方向上平坦化数据的扫描排序。然后,它将作为1D曼巴层的组合的曼巴ND块以交替顺序应用于序列。作者进行了广泛的实验来探索排序的不同组合。此外,他们将输入数据的一维划分为多个排序,采用不同的曼巴层排列,并将序列分解为更小的序列。结果表明,曼巴层链和简单的交替方向排序实现了优越的性能。曼巴ND区块的最终设计如图4(g)所示。
4)PlainMamba:PlainMamba是一种非层次结构,旨在实现以下几个目标:(1)非层次结构有助于多层次特征融合,增强不同规模的集成;(2) 它支持多模态数据的有效融合;(3) 其更简单的体系结构往往提供更好的泛化能力;(4) 它适用于硬件加速的优化。
Hybrid Mamba
1)LocalMamba:LocalMamba解决了在Vim和VMamba模型中观察到的一个显著限制,即在单个扫描过程中空间局部令牌之间的依赖性被破坏。为了克服这个问题,如图5所示的局部采样,LocalMamba将输入图像划分为多个局部窗口,以在不同方向上执行SSM,如VMamba所示,同时还保持全局SSM操作。此外,LocalMamba在补丁合并之前实现了空间和通道注意力模块,以增强方向特征的集成,减少冗余。LocalMamba区块如图4(f)所示。此外,它还采用了为每层选择最有效扫描方向的策略,从而优化了计算效率。
2)EfficientVMamba:EfficientVMamba引入了高效二维扫描(ES2D)技术,该技术采用对特征图上的斑块进行异步采样来减少计算负担。萎缩采样如图5所示。ES2D用于提取全局特征,而并行卷积分支用于提取局部特征。机器人特征类型然后由挤压和激励(SE)块单独处理。ES2D、卷积分支和SE块共同构成了有效视觉状态空间(EVSS)块的核心组件。EVSS块的输出是调制的全局和局部特征的总和。EVSS块如图3(d)所示。EVSS块形成EfficientVMamba的早期阶段,而EfficientNet块反过来形成后期阶段。
3)SiMBA:SiMBA旨在解决Mamba在视觉数据集上扩展到大型网络的不稳定性问题。它提出了一种新的信道建模技术,称为EinFFT,并使用Mamba进行序列建模。换言之,SiMBA块由Mamba块和EinFFT块组成,两者都与LN层、丢弃和残差连接交织。
关键提升
1)主干:为了处理2D图像,首先通过主干模块将其转换为视觉标记序列,主干模块通常包括卷积层和线性投影层。位置嵌入的添加是可选的,因为SSM操作固有地具有因果特性。包含类标记也是可选的。现有方法通过将图像序列视为用于基于曼巴的块中的SSM变换和卷积运算的1D或2D结构来处理图像序列。鉴于扫描技术在这些过程中的整体作用,我们将在下一节中对这些方法进行系统分类和更详细的研究。在本节中,我们将区分基于Mamba的层次结构和非层次结构。
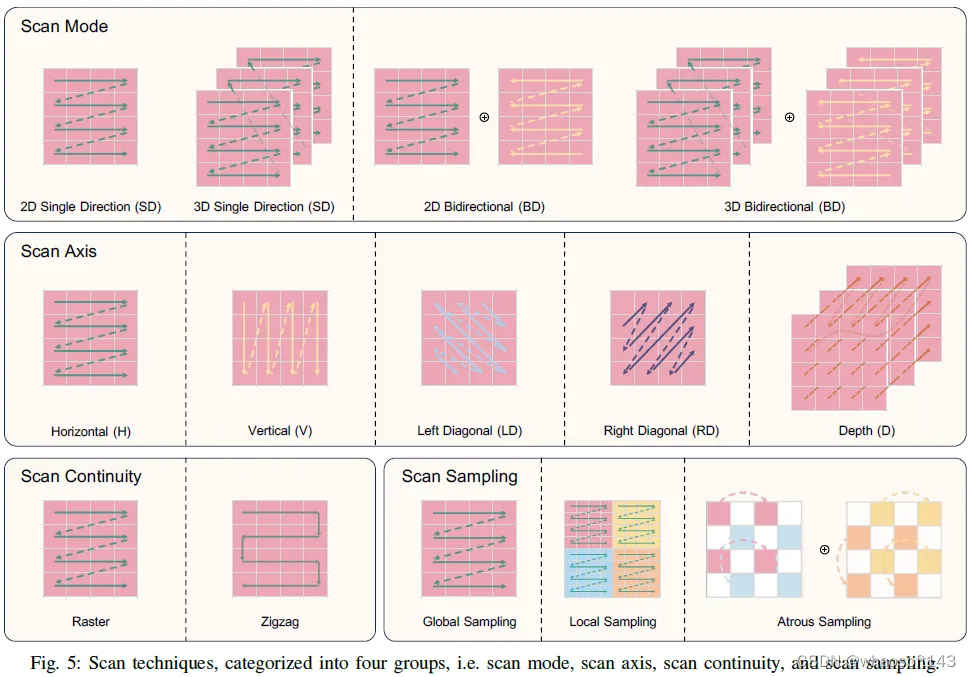
2)扫描:选择性扫描机制是曼巴的关键组成部分。然而,其针对1D因果序列的原始设计在将其适应2D非因果图像时带来了挑战。为应对这些挑战,进行了大量的研究工作。在下一节中,我们将这些工作分类并讨论为三个主要组,扫描模式、扫描轴和扫描连续性。这种分类是基于扫描技术的目标。扫描模式处理视觉数据的非因果特性;扫描轴处理视觉数据中固有的高维度;扫描连续性考虑了贴片沿着扫描路径的空间连续性;扫描采样将整个图像划分为子图像。这四组的图示如图5所示。
3)Block:前面提到的扫描技术和选择性SSM变换的不同组合形成了各种块,这些块是基于Mambab的架构的组成部分。在讨论视觉曼巴骨干网络时,我们对这些区块进行了概述,并在相应的图中给出了详细的说明。这些数字也验证了我们对扫描技术进行分类背后的逻辑。这些块在应用方法中被广泛使用,将在下一节中详细介绍。为了清楚起见,最初的曼巴区块简称为曼巴。代表性块由诸如VSS和Vim之类的名称表示。对这些块的修改由星号(*)表示,并且诸如+CNN之类的标签表示类CNN特征的集成。图3和图4说明了一套视觉Mamba区块,包括Vim区块、VSS区块、EVSS区块、PlainMamba区块、LocalMamba区块和Mamba ND区块。曼巴区块也包括在内,以便于直接比较,突出这些区块在视觉领域的进化设计。
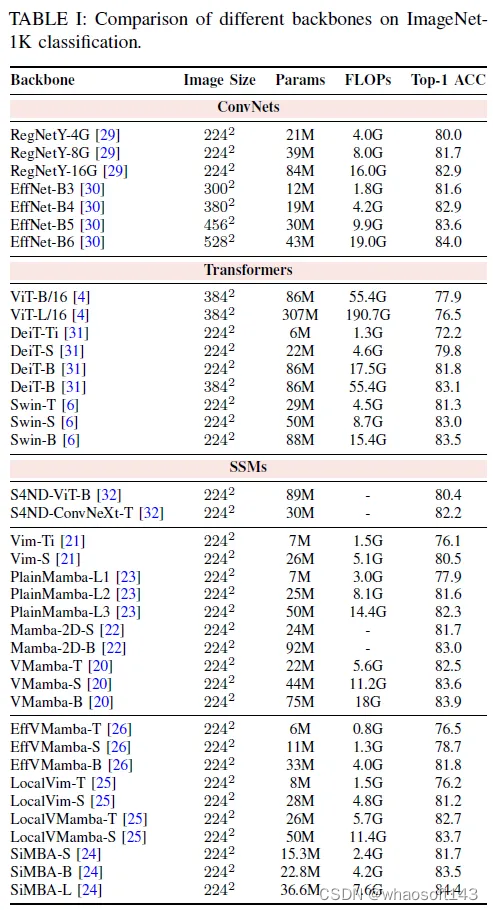
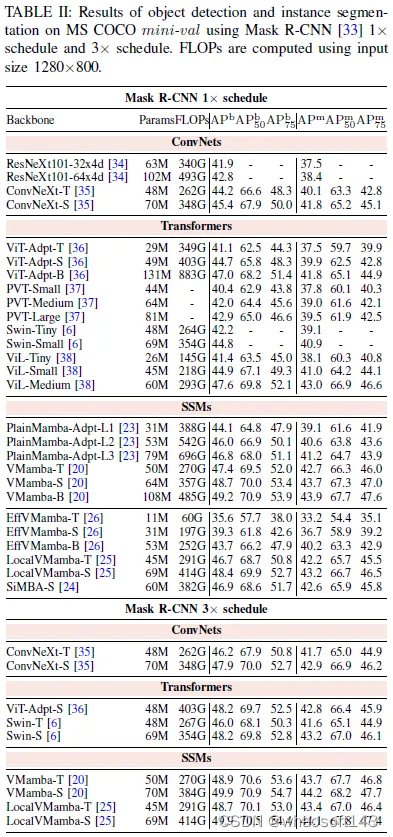
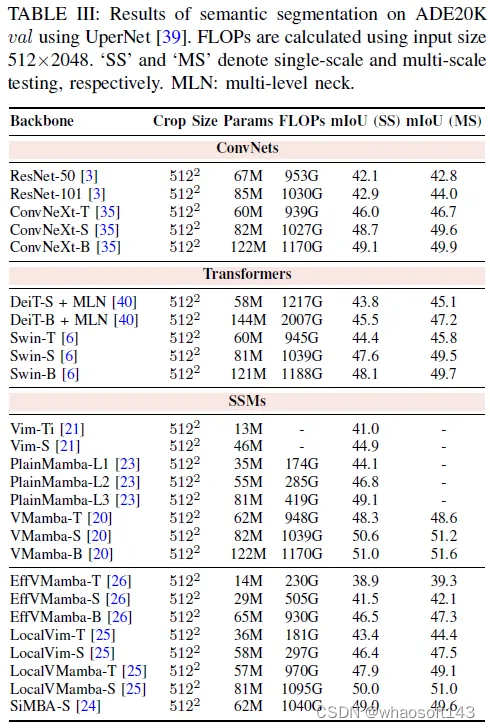
在本节中,我们在表中的标准基准上展示了各种可视曼巴骨干网络的性能。表I、表II和表III:ImageNet-1K上的分类,通过Mask R-CNN在MS COCO上的目标检测和实例分割,以及利用UperNet在ADE20K上的语义分割。
应用
本节系统地对曼巴在计算机视觉领域的各种应用进行了分类和讨论。分类方案以及本次调查中回顾的相关文献概述如图6所示。
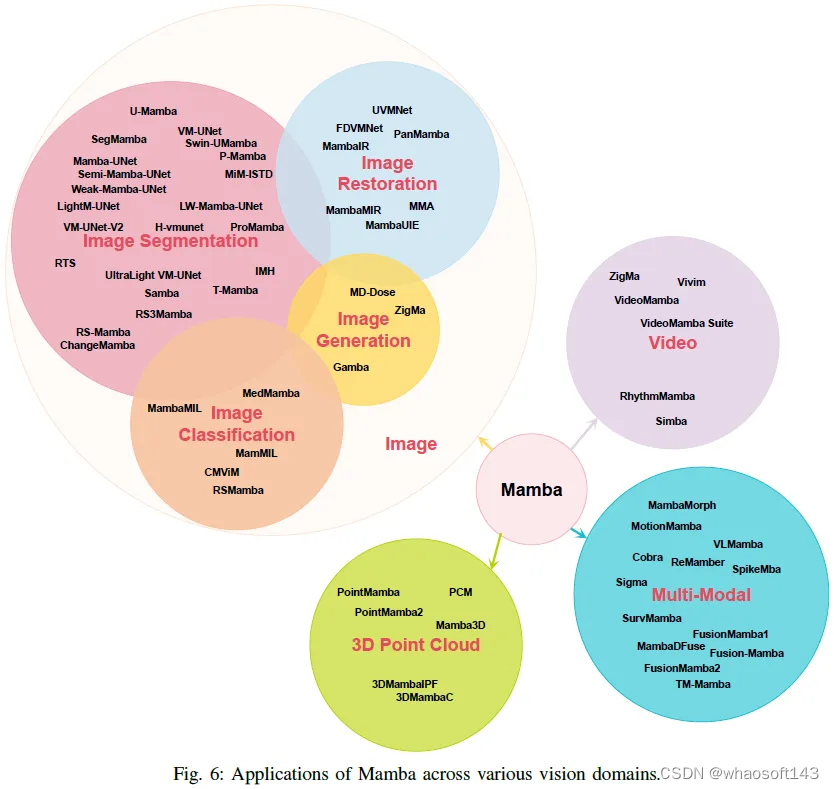
A.图像
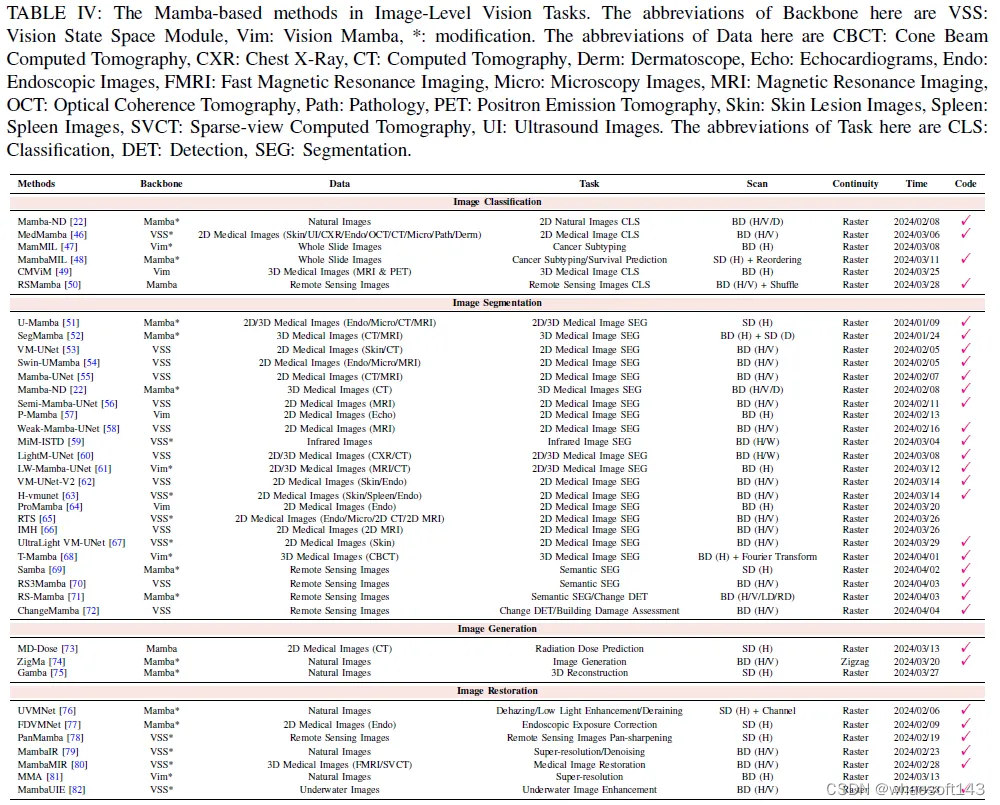
1)分类:除了主干进行图像分类以进行表示学习外,Mamba ND还引入了一种处理多维数据的新方法,通过按照行主顺序交替分解不同维度的输入数据。在自然图像分类的背景下,与基于Transformer的方法相比,该技术以显著更少的参数展示了优越的性能。同时,Mamba ND可以很容易地扩展到涉及多维数据的视频动作识别和3D分割等多项任务。基于Mamba的架构对更大补丁序列的可扩展性导致它们被用于高分辨率图像(例如,全幻灯片图像和遥感图像)和高维图像(例如3D医学图像)的分析以用于识别目的。
2)分割:分割仍然是计算机视觉领域的一个重要和突出的研究领域,对不同的现实世界应用具有巨大的价值。通过使用基于CNN的模型和基于transformer的模型,分割技术的最新进展取得了显著成就。基于细胞神经网络的方法擅长通过卷积运算捕捉局部特征,而基于变换器的方法则通过利用自注意机制来理解全局上下文,表现出非凡的能力。然而,基于变换器的方法的一个局限性是,随着输入大小的增加,自注意的计算复杂度呈二次增长。特别是对于高分辨率图像或高纬度图像,Transformer架构及其整体注意力层对有限窗口之外的任何事物进行建模的能力有限,并表现出二次复杂性,导致性能次优。
3) 生成:直观地说,将Mamba架构应用于一系列生成任务,以实现足够的长序列交互,有可能实现令人印象深刻的性能。
4) 图像恢复:最近,曼巴架构也被广泛应用于几个低级别的任务,包括图像去雾、曝光校正、泛锐化、超分辨率、去噪、医学图像重建和水下图像增强。
B.视频
视频理解是计算机视觉研究的基本方向之一。视频理解的主要目标是有效地掌握长上下文中的时空表示。Mamba凭借其选择性状态空间模型在这一领域表现出色,在保持线性复杂性和实现有效的长期动态建模之间实现了平衡。这种创新方法促进了其在各种视频分析任务中的广泛采用,如视频目标分割、视频动作识别、视频生成和表示学习。
C.多模态
多莫泰任务在CV领域发挥着至关重要的作用,因为它们有助于整合各种信息源,丰富视觉数据的理解和分析。这些任务的目标是聚合多种模态,包括文本和视觉信息、具有附加组件(如深度或热图像)的RGB图像以及各种形式的医学成像数据。然而,实现多模式目标的一个重大挑战在于有效地捕捉不同模式之间的相关性。最近,有几种方法将Mamba架构用于许多多模式任务,包括多模式大语言模型、多模态配准、参考图像分割、时间视频基础、语义分割、运动生成和医学应用。
D.点云
点云是一种基本的三维表示,它提供具有三维坐标的连续空间位置信息。点云的内在无序性和不规则性一直是三维视觉中的一个挑战。受Mamba的线性复杂性和全局建模能力的启发,在点云处理领域研究了几种基于SSM的通用主干。
PointMamba直接使用VSS块作为编码器,并提出了一种重新排序策略,通过提供更符合逻辑的几何扫描顺序来增强SSM的全局建模能力。PCM结合了几何仿射块和Vim块作为基本块,并提出了一致遍历串行化(CTS)将点云串行化为1D点序列,同时确保空间连续性。具体而言,CTS通过排列3D坐标的顺序产生六种变体,从而全面观测点云数据。PointMamba采用Vim进行长序列建模,并引入了基于八叉树的排序机制来生成输入序列,以获得原始输入点的因果关系。3DMamba IPF结合了Mamba架构,以顺序处理来自大型场景的大量点云,并集成了稳健且快速可微分的渲染损失,以约束曲面周围的噪声点。3DMambaC引入了一个超点生成模块来生成新的形状表示超点,其中包括用于增强采样点特征和预测超点的Mamba编码器。Mamba3D采用了具有通道翻转的双向SSM,并引入了局部范数池(LNP)块来提取局部几何特征。
挑战
A. Algorithm
1)可扩展性和稳定性:目前,Mamba架构在应用于ImageNet等大规模数据集时表现出稳定性挑战。曼巴在扩展到更广泛的网络配置时不稳定的根本原因尚不清楚。这种不稳定性经常导致曼巴框架内的梯度消失或爆炸,这阻碍了其在大规模视觉任务中的部署。
2)因果关系问题:鉴于曼巴模型最初是为因果序列数据设计的,将其选择性扫描技术应用于非因果视觉数据带来了重大挑战。目前的方法通过采用双向扫描等扫描技术来解决这一问题,其中向前和向后扫描都被用来相互补偿感受野中单向扫描的固有限制。然而,这仍然是一个悬而未决的问题,继续带来挑战。
3)空间信息:曼巴选择性扫描技术固有的1D特性在应用于2D或更高维度的视觉数据时带来了挑战,因为它可能导致关键空间信息的丢失。为了解决这一限制,当前的方法通常从各个方向展开图像块,从而允许跨多个维度的空间信息的集成。然而,这个问题仍然是一个悬而未决的问题,需要进一步调查。
4)冗余和计算:如前所述,双向扫描方法和多个扫描方向的使用会导致显著的信息冗余和计算需求的增加。这些可能会降低模型性能,并降低曼巴线性复杂度的优势。根据研究结果,与Transformer模型相比,Mamba模型的GPU消耗并不一致。这是一个重要挑战,需要进一步调查。
B. 应用
1)可解释性:一些研究提供了实验证据来阐明曼巴模型在NLP中的潜在机制,重点是其上下文学习能力、和事实回忆能力。此外,其他工作为曼巴在NLP中的应用奠定了理论基础。尽管取得了这些进步,但解释为什么曼巴能有效地完成视觉任务仍然具有挑战性。然而,视觉曼巴的独特学习特征及其与其他基础模型(如RNN、CNNs和ViTs)的相似之处仍然需要更深入的解释。
2)泛化和鲁棒性:Mamba中的隐藏状态可能会积累甚至放大特定领域的信息,这可能会对其泛化性能产生不利影响。此外,模型固有的1D扫描策略可能会无意中捕捉到特定领域的偏差,而当前的扫描技术往往无法满足对领域不可知信息处理的需求。[118]中的研究证明了VMamba在对抗性弹性和总体稳健性方面的优势。然而,在处理这些任务时,它也指出了可扩展性方面的局限性。该研究包括对VMamba的白盒攻击,以检查其新组件在对抗性条件下的行为。研究结果表明,虽然参数Δ表现出鲁棒性,但参数B和C容易受到攻击。参数之间的这种差异漏洞导致了VMamba在保持健壮性方面的可扩展性挑战。此外,结果表明,VMamba对其扫描轨迹的连续性和空间信息的完整性的中断表现出特别的敏感性。增强视觉曼巴的泛化能力和鲁棒性仍然是该领域尚未解决的挑战。
未来方向
A.数据
1)数据效率:考虑到Mamba的计算成本与CNN相当,即使不依赖大规模数据集,它也具有提供最佳性能的巨大潜力。这一属性将曼巴定位为各种下游任务/多任务和涉及预训练模型自适应的任务的有前途的候选者。
2)高分辨率数据:由于SSM的架构在理论上简化了计算复杂性,因此其有效处理高分辨率数据(如遥感和全切片图像)或长期序列数据(如长期视频帧)的潜力具有相当大的价值。
3)多模态数据:正如Transformer架构已经证明了其在统一框架内对自然语言和图像进行建模的能力一样,Mamba模型在处理扩展序列方面的熟练程度大大拓宽了其在多模式学习中的适用性。
4)上下文学习:在深度学习的动态环境中,上下文学习已经发展到包含越来越复杂和新颖的方法,以解决NLP、CV和多模式领域的复杂任务。这种方法上的进步对于突破现有深度学习框架的极限至关重要。Mamba模型凭借其精通上下文建模能力和捕获长程依赖关系的能力,在上下文学习应用程序中显示出更深入的语义理解和增强性能的潜力。
B.算法
1)扫描技术:选择性扫描机制是曼巴模型的核心组成部分,最初针对1D因果序列数据进行了优化。为了解决视觉数据固有的非因果性质,许多现有方法采用双向扫描。此外,为了捕获2D或高维视觉数据中固有的空间信息,当前的方法通常扩展扫描方向。尽管有这些调整,但迫切需要更具创新性的扫描方案,以更有效地利用高维非因果视觉数据的全部潜力。
2)融合技术:使曼巴模型适应视觉任务往往会引入冗余,使扫描输出特征的有效融合成为进一步探索的重要领域。此外,计算机视觉的基础模型各有其独特的优势;例如,细胞神经网络固有地捕捉归纳偏差,如翻译等变,而ViT以其强大的建模能力而闻名。探索融合这些不同网络架构提取的特征以最大限度地发挥其优势的方法是一个宝贵的研究机会。
3)计算效率:Mamba在序列长度方面实现了线性可扩展性,但由于需要在多个路径中扫描,将其用于视觉任务会导致计算需求增加。因此,在开发更高效、更有效的视觉曼巴模型方面有着重要的研究机会。此外,Mamba模型在计算效率方面并不总是优于Transformer,这突出了为视觉任务量身定制的优化、硬件感知的Mamba算法的必要性。这为研究提供了一条很有前途的途径,特别是在开发减少计算开销同时保持或提高性能的方法方面。提高视觉曼巴模型的计算效率可以极大地提高其在现实世界场景中的适用性。
结论
Mamba已迅速成为一种变革性的长序列建模架构,以其卓越的性能和高效的计算实现而闻名。随着它在计算机视觉领域的不断发展,本文对视觉曼巴方法进行了全面的综述。我们首先对Mamba架构进行深入概述,然后详细检查具有代表性的可视化Mamba骨干网络及其在各个可视化领域的广泛应用。这些应用程序按不同的模式进行系统分类,包括图像、视频、点云和多模式数据等。最后,我们批判性地分析了与视觉曼巴相关的挑战,强调了这种架构在推进计算机视觉方面尚未开发的潜力。根据这一分析,我们描绘了视觉曼巴未来的研究方向,提供了有价值的见解,可能会影响这一动态发展领域的持续和未来发展。
...
#NeRF~相机参数与坐标系变换
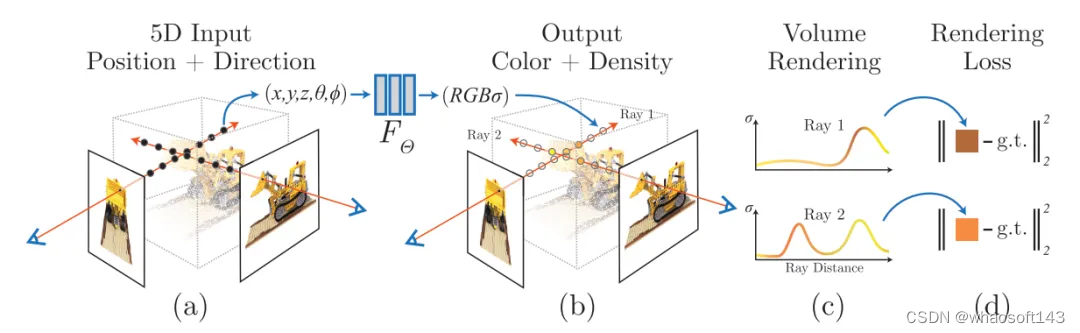
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 是一篇获得ECCV2020 Best Paper Honorable Mention的论文。给定一个场景的多视角的图像,神经辐射场(NeRF)通过图像重建误差优化一个神经场景表征。优化后可以实现逼真的新视角合成效果。被其逼真的图像合成效果所吸引,很多研究人员开始跟进该方向,并在最近的一两年时间里产生了大量的(好几百篇!)改进和拓展工作。
为什么写这篇文章
网上已经有不少介绍NeRF的文章,这些文章很好地介绍了NeRF论文的核心思想,体素渲染的细节,网络结构,优化策略等等。我这里主要介绍代码实现中关于相机参数以及坐标系变换相关的内容,这个地方是我觉得初学者容易困惑的地方,特别是没有3D知识基础的读者。
本文的代码讲解以pytorch版本的实现为例:https://github.com/yenchenlin/nerf-pytorch。这里假设读者已经看过NeRF论文,并且简单浏览过NeRF的代码。
总体概览
NeRF的技术其实很简洁,并不复杂。但与2D视觉里考虑的2维图像不同,NeRF考虑的是一个3D空间。下面列的是NeRF实现的几个关键部分:
- 有一个3D空间,用一个连续的场表示
- 空间里存在一个感兴趣的物体区域
- 处于不同位置和朝向的相机拍摄多视角图像
- 对于一张图像,根据相机中心和图像平面的一个像素点,两点确定一条射线穿过3D空间
- 在射线上采样多个离散的3D点并利用体素渲染像素的颜色。
这里面涉及到3D空间、物体区域、相机位置和朝向、图像、射线、以及3D采样点等。要想优化NeRF,我们需要能够表达刚刚提到的这些东西。
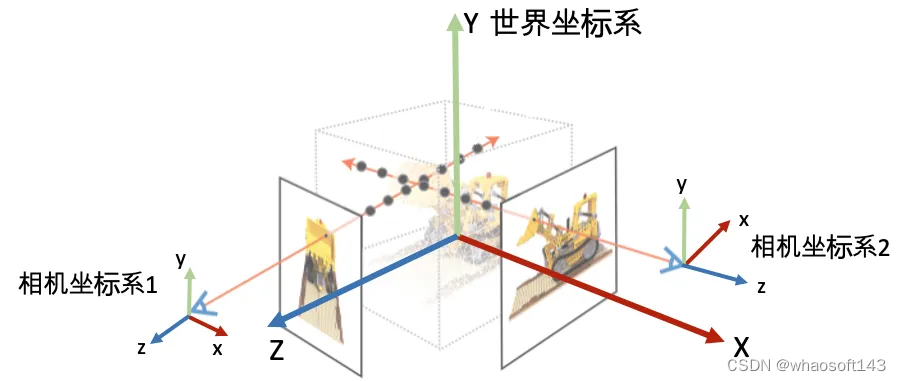
坐标系定义: 为了唯一地描述每一个空间点的坐标,以及相机的位置和朝向,我们需要先定义一个世界坐标系。一个坐标系其实就是由原点的位置与XYZ轴的方向决定。接着,为了建立3D空间点到相机平面的映射关系以及多个相机之间的相对关系,我们会对每一个相机定义一个局部的相机坐标系。下图为常见的坐标系定义习惯。
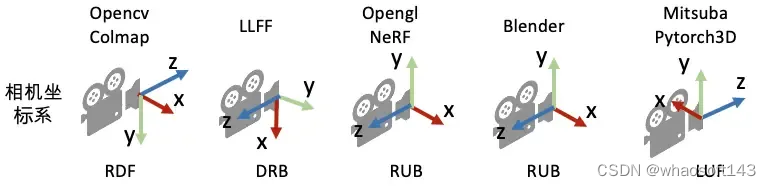
常见的相机坐标系定义习惯(右手坐标系)。注意:在OpenCV/COLMAP的相机坐标系里相机朝向+z轴,在LLFF/NeRF的相机坐标系中里相机朝向-z轴。有时我们会按坐标系的xyz朝向描述坐标系,如OpenCV/COLMAP里使用的RDF表述X轴指向right,Y轴指向Down,Z轴指向Foward。
相机的内外参数
相机的位置和朝向由相机的外参(extrinsic matrix)决定,投影属性由相机的内参(intrinsic matrix)决定。
注意:接下来的介绍假设矩阵是列矩阵(column-major matrix),变换矩阵左乘坐标向量实现坐标变换(这也是OpenCV/OpenGL/NeRF里使用的形式)。
相机外参
相机外参是一个4x4矩阵,其作用是将世界坐标系的点变换到相机坐标系下。我们也把相机外参叫做world-to-camera (w2c)矩阵。(注意用的是4维的齐次坐标,如果不了解齐次坐标系请自行查阅相关资料。)
相机外参的逆矩阵被称为camera-to-world (c2w)矩阵,其作用是把相机坐标系的点变换到世界坐标系。因为NeRF主要使用c2w,这里详细介绍一下c2w的含义。c2w矩阵是一个4x4的矩阵,左上角3x3是旋转矩阵R,右上角的3x1向量是平移向量T。有时写的时候可以忽略最后一行[0,0,0,1]。

Camera-to-world (c2w) 矩阵
刚刚接触的时候,对这个c2w矩阵的值可能会比较陌生。其实c2w矩阵的值直接描述了相机坐标系的朝向和原点:
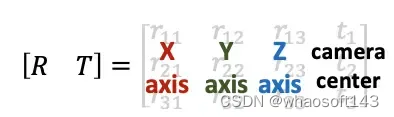
理解Camera-to-world (c2w)矩阵
具体的,旋转矩阵的第一列到第三列分别表示了相机坐标系的X, Y, Z轴在世界坐标系下对应的方向;平移向量表示的是相机原点在世界坐标系的对应位置。
如果这段描述还是有点抽象,可以尝试进行下列计算帮助自己理解。刚刚讲到c2w是将相机坐标系的向量变换到世界坐标系下,那我们如果将c2w作用到(即左乘)相机坐标系下的X轴[1,0,0,0],Y轴[0,1,0,0], Z轴[0,0,1,0],以及原点[0,0,0,1](注意方向向量的齐次坐标第四维等于0,点坐标第四维等于1),我们会得到它们在世界坐标系的坐标表示:
[R, T][1, 0, 0, 0]^T = [r11, r21, r31]^T # X轴对应的是c2w矩阵的第一列
[R, T][0, 1, 0, 0]^T = [r12, r22, r32]^T # Y轴对应的是c2w矩阵的第二列
[R, T][0, 0, 1, 0]^T = [r13, r23, r33]^T # Y轴对应的是c2w矩阵的第三列
[R, T][0, 0, 0, 1]^T = [t1, t2, t3]^T # 原点对应的是c2w矩阵的第四列从上面可以看到可以看到,将c2w作用到相机坐标系下的X轴、Y轴、 Z轴、以及原点我们会依次得到c2w的四列向量。
相机内参
刚刚介绍了相机的外参,现在简单介绍一下相机的内参。
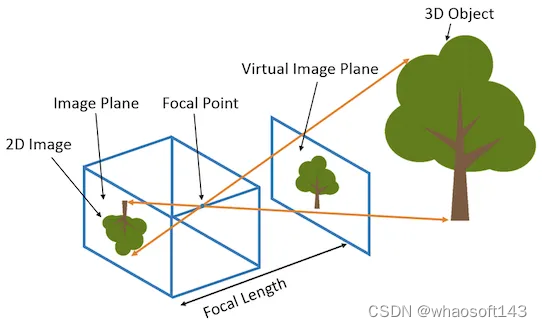
相机的内参矩阵将相机坐标系下的3D坐标映射到2D的图像平面,这里以针孔相机(Pinhole camera)为例介绍相机的内参矩阵K:
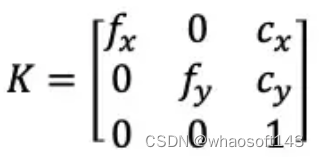
针孔相机的内参矩阵
内参矩阵K包含4个值,其中fx和fy是相机的水平和垂直焦距(对于理想的针孔相机,fx=fy)。焦距的物理含义是相机中心到成像平面的距离,长度以像素为单位。cx和cy是图像原点相对于相机光心的水平和垂直偏移量。cx,cy有时候可以用图像宽和高的1/2近似:
# NeRF run_nerf.py有这么一段构造K的代码
if K is None:
K = np.array([
[focal, 0, 0.5*W],
[0, focal, 0.5*H],
[0, 0, 1]
])如何获得相机参数
NeRF算法假设相机的内外参数是提供的,那么怎么得到所需要的相机参数呢?这里分合成数据集和真实数据集两种情况。
合成数据
对于合成数据集,我们需要通过指定相机参数来渲染图像,所以得到图像的时候已经知道对应的相机参数,比如像NeRF用到的Blender Lego数据集。常用的渲染软件还有Mitsuba、OpenGL、PyTorch3D、Pyrender等。渲染数据比较简单,但是把得到的相机数据转到NeRF代码坐标系牵扯到坐标系之间的变换,有时候会比较麻烦。
真实数据
对于真实场景,比如我们用手机拍摄了一组图像,怎么获得相机位姿?目前常用的方法是利用运动恢复结构(structure-from-motion, SFM)技术估计几个相机间的相对位姿。这个技术比较成熟了,现在学术界里用的比较多的开源软件包是COLMAP: https://colmap.github.io/。输入多张图像,COLMAP可以估计出相机的内参和外参(也就是sparse model)。
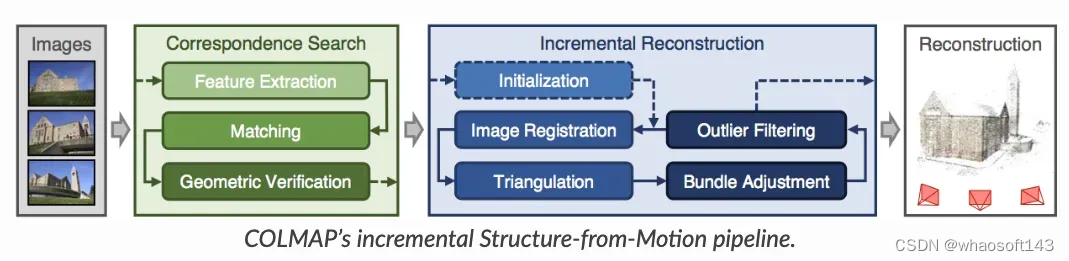
下面是COLMAP官网教程给的三个命令行操作步骤,简单来说:第一步是对所有的图像进行特征点检测与提取,第二步是进行特征点匹配,第三步是进行SFM恢复相机位姿和稀疏的3D特征点。具体的使用方法和原理还请阅读其官方文档。其实COLMAP也集成了multiview stereo (MVS)算法用于重建场景完整的三维结构(也称为dense model)。不过NeRF本身是一种新颖的场景表征和重建算法,我们只需要相机的位姿信息,所以我们不需要跑MVS进行dense重建。注意:如果没有标定信息,基于单目的SFM无法获得场景的绝对尺度。
# The project folder must contain a folder "images" with all the images.
$ DATASET_PATH=/path/to/dataset
$ colmap feature_extractor \
--database_path $DATASET_PATH/database.db \
--image_path $DATASET_PATH/images
$ colmap exhaustive_matcher \
--database_path $DATASET_PATH/database.db
$ mkdir $DATASET_PATH/sparse
$ colmap mapper \
--database_path $DATASET_PATH/database.db \
--image_path $DATASET_PATH/images \
--output_path $DATASET_PATH/sparse使用COLMAP得到相机参数后只需要转成NeRF可以读取的格式即可以用于模型训练了。那这里面需要做什么操作?
LLFF真实数据格式
NeRF代码里用load_llff.py这个文件来读取真实的数据,第一次看到LLFF这个词可能不知道是什么意思。其实LLFF GitHub - Fyusion/LLFF: Code release for Local Light Field Fusion at SIGGRAPH 2019 是NeRF作者的上一篇做新视角合成的工作。为了和LLFF方法保持一致的数据格式,NeRF使用load_llff.py读取LLFF格式的真实数据,并建议大家使用LLFF提供的的imgs2poses.py文件获取所需相机参数。
COLMAP到LLFF数据格式
imgs2poses.py这个文件其实很简单,就干了两件事。
- 第一件事是调用colmap软件估计相机的参数,在sparse/0/文件夹下生成一些二进制文件:cameras.bin, images.bin, points3D.bin, project.ini。
- 第二件事是读取上一步得到的二进制文件,保存成一个poses_bounds.npy文件。
这里有一个细节需要注意,就是在pose_utils.py文件里load_colmap_data()函数的倒数第二行,有一个操作将colmap得到的c2w旋转矩阵中的第一列和第二列互换,第三列乘以负号:
# LLFF/llff/poses/pose_utils.py
def load_colmap_data(realdir):
...
# must switch to [-u, r, -t] from [r, -u, t], NOT [r, u, -t]
poses = np.concatenate([poses[:, 1:2, :], poses[:, 0:1, :], -poses[:, 2:3, :], poses[:, 3:4, :], poses[:, 4:5, :]], 1)
return poses, pts3d, perm还记得刚刚提到c2w旋转矩阵的三列向量分别代表XYZ轴的朝向,上述操作实际上就是把相机坐标系轴的朝向进行了变换:X和Y轴调换,Z轴取反,如下图所示:

从Colmap的坐标系转到LLFF的坐标系
poses_bounds.npy里有什么
load_llff.py会直接读取poses_bounds.npy文件获得相机参数。poses_bounds.npy是一个Nx17的矩阵,其中N是图像的数量,即每一张图像有17个参数。其中前面15个参数可以重排成3x5的矩阵形式:
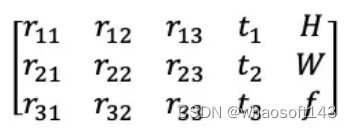
poses_bounds.npy的前15维参数。左边3x3矩阵是c2w的旋转矩阵,第四列是c2w的平移向量,第五列分别是图像的高H、宽W和相机的焦距f
最后两个参数用于表示场景的范围Bounds (bds),是该相机视角下场景点离相机中心最近(near)和最远(far)的距离,所以near/far肯定是大于0的。
- 这两个值是怎么得到的?是在imgs2poses.py中,计算colmap重建的3D稀疏点在各个相机视角下最近和最远的距离得到的。
- 这两个值有什么用?之前提到体素渲染需要在一条射线上采样3D点,这就需要一个采样区间,而near和far就是定义了采样区间的最近点和最远点。贴近场景边界的near/far可以使采样点分布更加密集,从而有效地提升收敛速度和渲染质量。
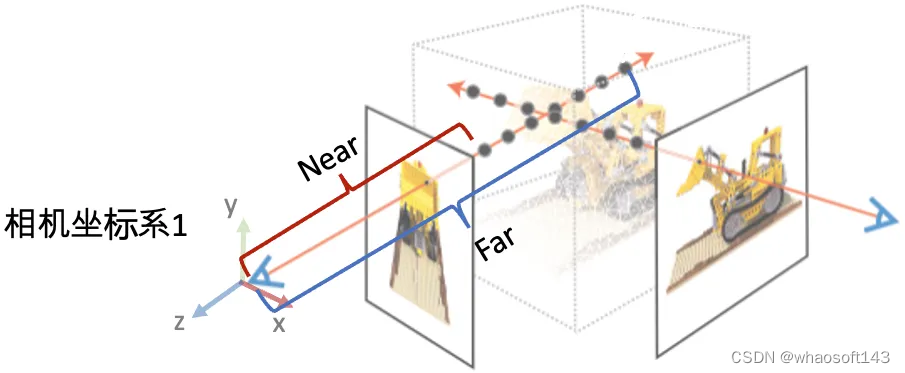
poses_bounds.npy里最后两个参数(near/far)的作用示意图
load_llff.py代码解读
接着,我们介绍NeRF代码里load_llff.py代码里的一些细节。对三维视觉不熟悉的读者,早期读代码的时候可能会有不少困惑。
DRB到RUB的变换
第一个疑问是,为什么读进poses_bounds.npy里的c2w矩阵之后,对c2w的旋转矩阵又做了一些列变换?
# load_llff.py文件
def load_llff_data(basedir, factor=8, recenter=True, bd_factor=.75, spherify=False, path_zflat=False):
poses, bds, imgs = _load_data(basedir, factor=factor) # factor=8 downsamples original imgs by 8x
print('Loaded', basedir, bds.min(), bds.max())
# Correct rotation matrix ordering and move variable dim to axis 0
poses = np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1)
...上面的代码段的最后一行实际上是把旋转矩阵的第一列(X轴)和第二列(Y轴)互换,并且对第二列(Y轴)做了一个反向。这样做的目的是将LLFF的相机坐标系变成OpenGL/NeRF的相机坐标系,如下图所示。
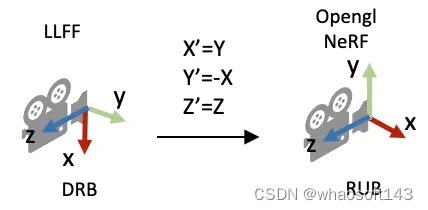
poses = np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1)
缩放图像需要修改什么相机参数?
在_load_data()函数里,有一个用于图像缩放的factor比例参数,将HxW的图像缩放成(H/factor)x(W/factor)。这里面有一个问题是如果缩放了图像尺寸,相机的参数需要相应的做什么变化?
- 做法是:外参(位置和朝向)不变,相机的焦距f,cx, 和cy等比例缩放。下图的示意图展示了当相机位置不变,相机视野(Field of view, FOV)不变的情况下,图像的高和焦距长短的关系。
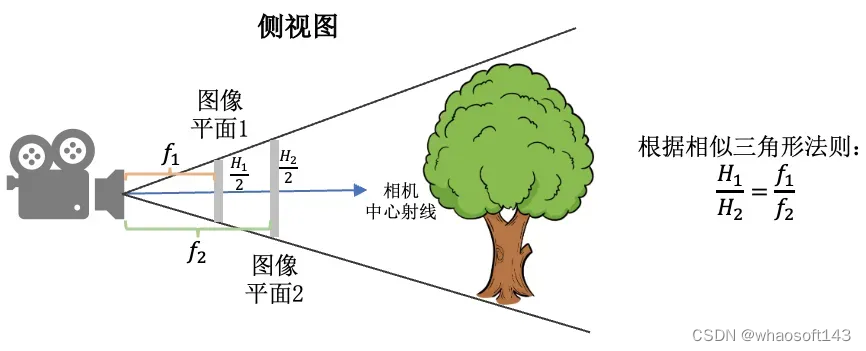
图像平面1与图像平面2拍摄的图像内容是一样的,只是分辨率不同
viewmatrix()
view_matrix是一个构造相机矩阵的的函数,输入是相机的Z轴朝向、up轴的朝向(即相机平面朝上的方向Y)、以及相机中心。输出下图所示的camera-to-world (c2w)矩阵。因为Z轴朝向,Y轴朝向,和相机中心都已经给定,所以只需求X轴的方向即可。又由于X轴同时和Z轴和Y轴垂直,我们可以用Y轴与Z轴的叉乘得到X轴方向。
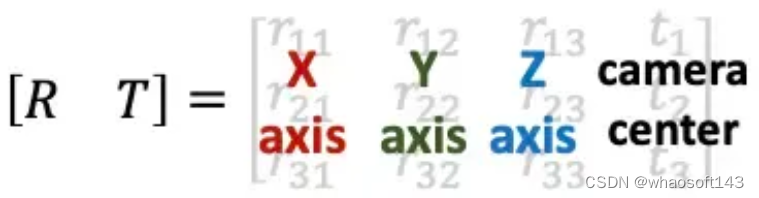
camera-to-world matrix
下面是load_llff.py里关于view_matrix()的定义,看起来复杂一些。其实就是比刚刚的描述比多了一步:在用Y轴与Z轴叉乘得到X轴后,再次用Z轴与X轴叉乘得到新的Y轴。为什么这么做呢?这是因为传入的up(Y)轴是通过一些计算得到的,不一定和Z轴垂直,所以多这么一步。
# load_llff.py
def viewmatrix(z, up, pos):
vec2 = normalize(z)
vec1_avg = up
vec0 = normalize(np.cross(vec1_avg, vec2))
vec1 = normalize(np.cross(vec2, vec0))
m = np.stack([vec0, vec1, vec2, pos], 1)
return mposes_avg()
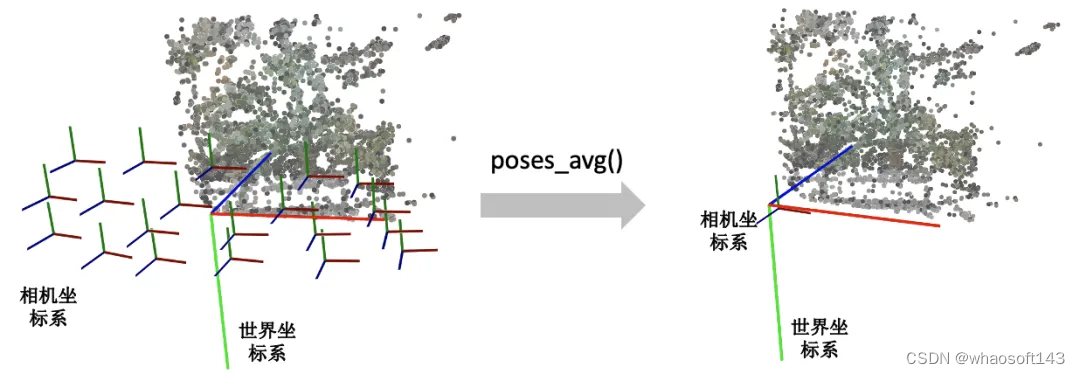
这个函数其实很简单,顾名思义就是多个相机的平均位姿(包括位置和朝向)。输入是多个相机的位姿。
- 第一步对多个相机的中心进行求均值得到center。
- 第二步对所有相机的Z轴求平均得到vec2向量(方向向量相加其实等效于平均方向向量)。
- 第三步对所有的相机的Y轴求平均得到up向量。
- 最后将vec2, up, 和center输入到刚刚介绍的viewmatrix()函数就可以得到平均的相机位姿了。
def poses_avg(poses):
hwf = poses[0, :3, -1:]
center = poses[:, :3, 3].mean(0)
vec2 = normalize(poses[:, :3, 2].sum(0))
up = poses[:, :3, 1].sum(0)
c2w = np.concatenate([viewmatrix(vec2, up, center), hwf], 1)
return c2w下图展示了一个poses_avg()函数的例子。左边是多个输入相机的位姿,右边是返回的平均相机姿态。可以看出平均相机位姿的位置和朝向是之前所有相机的均值。
中间大的坐标系是世界坐标系,每一个小的坐标系对应一个相机的局部坐标系。红绿蓝(RGB)轴分别代表XYZ轴
recenter_poses()
recenter_poses()函数的名字听起来是中心化相机位姿(同样包括位置和朝向)的意思。输入N个相机位姿,会返回N个相机位姿。
具体的操作了解起来可能有点跳跃。第一步先用刚刚介绍的poses_avg(poses)得到多个输入相机的平均位姿c2w,接着用这个平均位姿c2w的逆左乘到输入的相机位姿上就完成了归一化。
def recenter_poses(poses):
poses_ = poses+0
bottom = np.reshape([0,0,0,1.], [1,4])
c2w = poses_avg(poses)
c2w = np.concatenate([c2w[:3,:4], bottom], -2)
bottom = np.tile(np.reshape(bottom, [1,1,4]), [poses.shape[0],1,1])
poses = np.concatenate([poses[:,:3,:4], bottom], -2)
poses = np.linalg.inv(c2w) @ poses
poses_[:,:3,:4] = poses[:,:3,:4]
poses = poses_
return poses首先我们要知道利用同一个旋转平移变换矩阵左乘所有的相机位姿是对所有的相机位姿做一个全局的旋转平移变换,那下一个问题就是这些相机会被变到什么样的一个位置?我们可以用平均相机位姿作为支点理解,如果把平均位姿的逆c2w^-1左乘平均相机位姿c2w,返回的相机位姿中旋转矩阵为单位矩阵,平移量为零向量。也就是变换后的平均相机位姿的位置处在世界坐标系的原点,XYZ轴朝向和世界坐标系的向一致。
下图我们用一个例子帮助理解。左边和右边分别是输入和输出的相机位姿示意图。我们可以看到变换后的多个相机的平均位姿处在世界坐标系的原点,并且相机坐标系的XYZ轴与世界坐标系保持一致了。
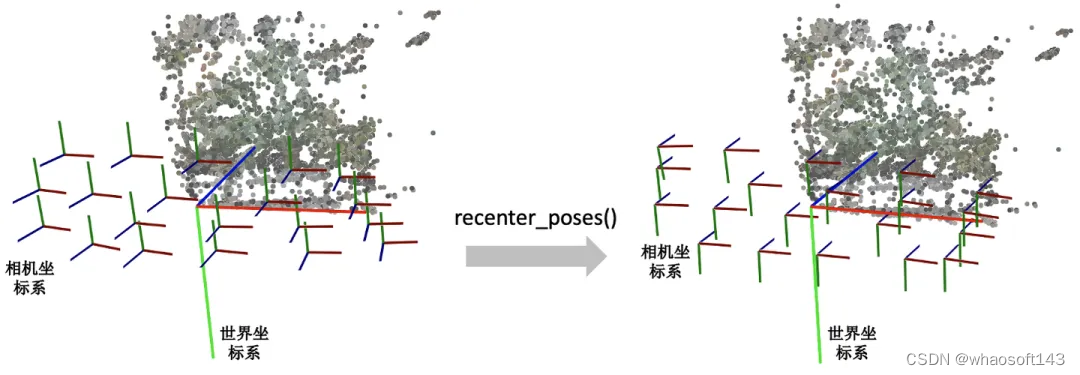
中间大的坐标系是世界坐标系,每一个小的坐标系对应一个相机的局部坐标系。红绿蓝(RGB)轴分别代表XYZ轴
render_path_spiral()
这个函数写的有点复杂,它和模型训练没有关系,主要是用来生成一个相机轨迹用于新视角的合成:
下面只放了render_path_spiral()函数的定义,NeRF代码
def render_path_spiral(c2w, up, rads, focal, zdelta, zrate, rots, N):
render_poses = []
rads = np.array(list(rads) + [1.])
hwf = c2w[:,4:5]
for theta in np.linspace(0., 2. * np.pi * rots, N+1)[:-1]:
c = np.dot(c2w[:3,:4], np.array([np.cos(theta), -np.sin(theta), -np.sin(theta*zrate), 1.]) * rads)
z = normalize(c - np.dot(c2w[:3,:4], np.array([0,0,-focal, 1.])))
render_poses.append(np.concatenate([viewmatrix(z, up, c), hwf], 1))
return render_poses需要知道这个函数它是想生成一段螺旋式的相机轨迹,相机绕着一个轴旋转,其中相机始终注视着一个焦点,相机的up轴保持不变。简单说一下上面的代码:
首先是一个for循环,每一迭代生成一个新的相机位置。c是当前迭代的相机在世界坐标系的位置,np.dot(c2w[:3,:4], np.array([0,0,-focal, 1.])是焦点在世界坐标系的位置,z是相机z轴在世界坐标系的朝向。接着使用介绍的viewmatrix(z, up, c)构造当前相机的矩阵。
下面这个图可视化了 render_path_spiral()生成的轨迹。
中间大的坐标系是世界坐标系,每一个小的坐标系对应一个相机的局部坐标系。红绿蓝(RGB)轴分别代表XYZ轴
spherify_poses()
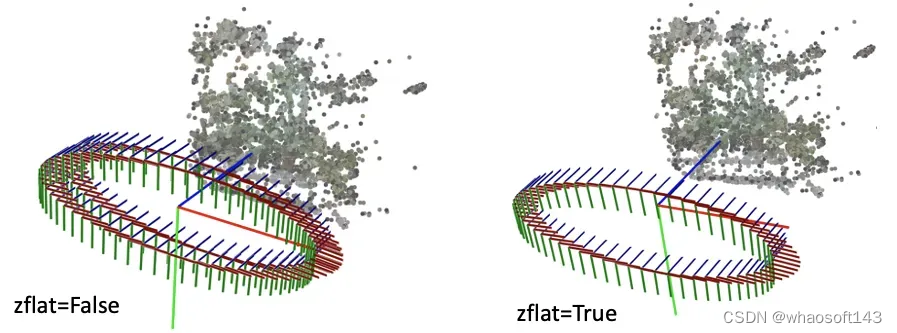
刚刚介绍的render_path_spiral()假设所有相机都朝向某一个方向,也就是所谓的faceforward场景。对于相机围绕着一个物体拍摄的360度场景,NeRF代码提供了一个spherify_poses()的函数用于"球面化"相机分布并返回一个环绕的相机轨迹用于新视角合成。这里插一句,在训练360度场景的时候,需要配合"--no_ndc --spherify --lindisp"三个参数以得到好的结果,具体原理这里不展开介绍。
if spherify:
poses, render_poses, bds = spherify_poses(poses, bds)这个函数也比较复杂,前半部分是在将输入的相机参数进行归一化,后半部分是生成一段相机轨迹用于合成新视角。对输入相机参数进行归一化时,思路是:
- 用 pt_mindist = min_line_dist(rays_o, rays_d)找到离所有相机中心射线距离之和最短的点(可以先简单理解成场景的中心位置)
rays_d = poses[:,:3,2:3]
rays_o = poses[:,:3,3:4]
def min_line_dist(rays_o, rays_d):
A_i = np.eye(3) - rays_d * np.transpose(rays_d, [0,2,1])
b_i = -A_i @ rays_o
pt_mindist = np.squeeze(-np.linalg.inv((np.transpose(A_i, [0,2,1]) @ A_i).mean(0)) @ (b_i).mean(0))
return pt_mindist
pt_mindist = min_line_dist(rays_o, rays_d)将得到的场景中心位置移到世界坐标系的原点,同时将所有相机z轴的平均方向转到和世界坐标系的z轴相同
center = pt_mindist
up = (poses[:,:3,3] - center).mean(0)
vec0 = normalize(up)
vec1 = normalize(np.cross([.1,.2,.3], vec0))
vec2 = normalize(np.cross(vec0, vec1))
pos = center
c2w = np.stack([vec1, vec2, vec0, pos], 1)
poses_reset = np.linalg.inv(p34_to_44(c2w[None])) @ p34_to_44(poses[:,:3,:4])- 最后将相机的位置缩放到单位圆内
rad = np.sqrt(np.mean(np.sum(np.square(poses_reset[:,:3,3]), -1)))
sc = 1./rad
poses_reset[:,:3,3] *= sc下面这个图可视化了spherify_poses()返回的结果。
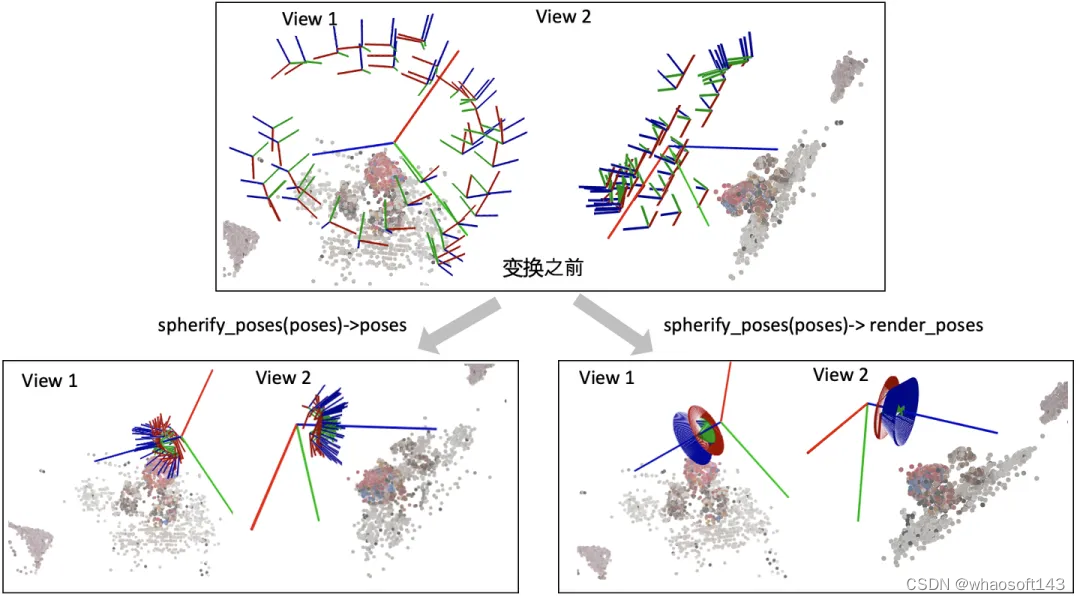
中间大的坐标系是世界坐标系,每一个小的坐标系对应一个相机的局部坐标系。红绿蓝(RGB)轴分别代表XYZ轴
3D空间射线怎么构造
最后我们看一下这个射线是怎么构造的。给定一张图像的一个像素点,我们的目标是构造以相机中心为起始点,经过相机中心和像素点的射线。
首先,明确两件事:
- 一条射线包括一个起始点和一个方向,起点的话就是相机中心。对于射线方向,我们都知道两点确定一条直线,所以除了相机中心我们还需另一个点,而这个点就是成像平面的像素点。
- NeRF代码是在相机坐标系下构建射线,然后再通过camera-to-world (c2w)矩阵将射线变换到世界坐标系。
通过上述的讨论,我们第一步是要先写出相机中心和像素点在相机坐标系的3D坐标。下面我们以OpenCV/Colmap的相机坐标系为例介绍。相机中心的坐标很明显就是[0,0,0]了。像素点的坐标可能复杂一点:首先3D像素点的x和y坐标是2D的图像坐标 (i, j)减去光心坐标 (cx,cy),然后z坐标其实就是焦距f (因为图像平面距离相机中心的距离就是焦距f)。
所以我们就可以得到射线的方向向量是 (𝑖−𝑐𝑥,𝑗−𝑐𝑦,𝑓)−(0,0,0)=(𝑖−𝑐𝑥,𝑗−𝑐𝑦,𝑓) 。因为是向量,我们可以把整个向量除以焦距f归一化z坐标,得到 (𝑖−𝑐𝑥𝑓,𝑗−𝑐𝑦𝑓,1) 。
接着只需要用c2w矩阵把相机坐标系下的相机中心和射线方向变换到世界坐标系就搞定了。
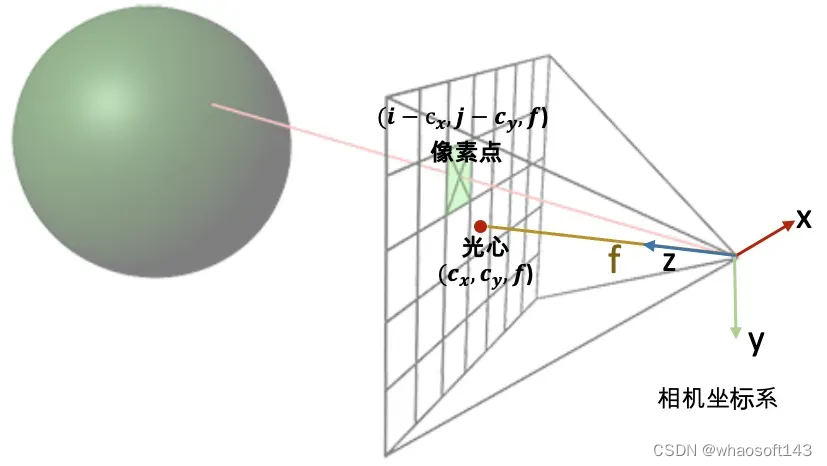
OpenCV/Colmap相机坐标系下射线的构造示意图
下面是NeRF的实现代码。但关于这里面有一个细节需要注意一下:为什么函数的第二行中dirs的y和z的方向值需要乘以负号,和我们刚刚推导的的 (𝑖−𝑐𝑥𝑓,𝑗−𝑐𝑦𝑓,1) 不太一样呢?
def get_rays_np(H, W, K, c2w):
i, j = np.meshgrid(np.arange(W, dtype=np.float32), np.arange(H, dtype=np.float32), indexing='xy')
dirs = np.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -np.ones_like(i)], -1)
# Rotate ray directions from camera frame to the world frame
rays_d = np.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1) # dot product, equals to: [c2w.dot(dir) for dir in dirs]
# Translate camera frame's origin to the world frame. It is the origin of all rays.
rays_o = np.broadcast_to(c2w[:3,-1], np.shape(rays_d))
return rays_o, rays_d这是因为OpenCV/Colmap的相机坐标系里相机的Up/Y朝下, 相机光心朝向+Z轴,而NeRF/OpenGL相机坐标系里相机的Up/朝上,相机光心朝向-Z轴,所以这里代码在方向向量dir的第二和第三项乘了个负号。
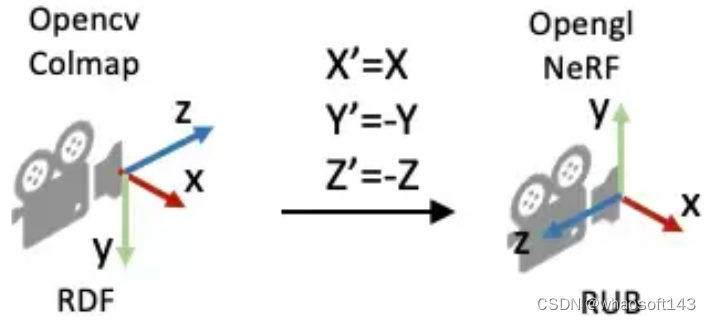
更多阅读材料:
前面简单地介绍了下NeRF代码中关于相机参数和坐标系变换的内容,这里面有很多细节没有展开介绍,如果有错误还请批评指正。另外,如果初学者希望进一步学习3D、图形学渲染相关的知识,可以浏览下面的一些网站(不全面,仅供参考):
- Scratchapixel系列:https://www.scratchapixel.com/
- 很棒的一个网站,这个网站里介绍了很多关于计算机图形学渲染的知识。可以从头开始学习或者直接先看 Computing the Pixel Coordinates of a 3D Point
- The Perspective Camera - An Interactive Tour:https://ksimek.github.io/2012/08/13/introduction/
- 这个网站介绍了相机的内外参数和分解,Dissecting the Camera Matrix part1/part2/part3
- 一篇很详细的关于体素渲染和NDC空间的博客:A Surge in NeRF | Will
下面是关于NeRF研究方向的一些文章(不全面,仅供参考):
- Frank Dellaert-NeRF Explosion 2020
- Frank Dellaert-NeRF at ICCV 2021
- NeRF at CVPR 2022
- 每周分类神经辐射场: https://github.com/sjtuytc/LargeScaleNeRFPytorch/blob/main/docs/weekly_nerf_cn.md
...
#如何用一个统一的视角,分析RLHF下的各种算法?
本文探讨了如何用一个统一的视角来分析强化学习从人类反馈(RLHF)中的不同算法,包括DPO和PPO,以及它们在实现RLHF优化目标时面临的挑战和潜在的改进方法。文章还讨论了如何通过在线(online)和在策略(on-policy)的训练方法来缩小实际操作和RLHF原始优化目标之间的差距。
写这篇文章的起因是,上周读了https://zhuanlan.zhihu.com/p/1082394115这篇知乎文章,文中探讨了关于DPO的局限性。在我之前写DPO的推导过程时(https://zhuanlan.zhihu.com/p/721073733),我就一直有一个主观感觉,rlhf算法的优化效果和客观世界的真值比起来,误差主要分布在【奖励函数误差】【prompt x】和【response y】上,其中我认为后两者是至关重要的(和数据集密切相关),他们也间接决定了【奖励函数的误差】。我认为诸如dpo这类off-policy的方法,和ppo这类on-policy的方法比较起来,误差也就在后两者上,相关的分析我回复在佬的评论区里。
但是总觉得对自己目前的理解,还是不够尽兴,我想用一个更有逻辑的视角来看待这个问题。即我想先不考虑任何具体的优化算法,仅从rlhf最原始的优化目标出发,来分析这个目标下暗藏的前提,而探索这些前提的目的是:
这些前提决定了rlhf的上限,也就是它和客观世界真值间的误差。
这些前提可以解释rlhf各种实现算法(例如dpo,ppo等)间存在的差异性。
这种前提也为我提供了一个统一的视角,它能帮助我分析各种rlhf变种算法是怎么在理论设计或实操中违背这种前提,又是怎么尽力去修复和这个前提间的差距的。
所以在上个周末,我开始搜罗一些大家常见的rlhf训练问题,同时大量阅读和rlhf理论分析的相关文章,我选择的这些文章的主要特点就是,有充分的数学推理和实验结论。虽然各个作者的分析角度都不一样,但神奇的是,我发现这些不一样的视角都可以渐渐收敛到我想找的那个【前提】上来,于是进行了一次自我训练,来optimize target。
但同时也由于我这个模型的参数量有限,收敛的结果不一定特别好,也许还有一些幻觉(主观解读),所以也请大家选择性阅读~在这篇文章里,不会涉及太复杂的数学推导(需要涉及的部分我都尽量用简明的语言+举例的方式展示出来),可以放心食用。文章里也贴出了我参考的资料,如果大家对哪篇感兴趣,我看看后面能不能再单独出个详解(这些文章确实不好读,因为结论都在数学推导中,很少显式给出)。
(最后,由于我现在特别想赶紧赶回家吃俄式大甜筒冰淇淋😁,所以文中有一点部分没有详细展开,后面我会在知乎里补充,也会加一些图辅助理解)。
一、RLHF优化目标的隐藏前提
rlhf最初的公式:
:一个固定的奖励函数。我们先假设这是一个最优的奖励函数 , 也即它具有完美的泛化能力和评估性能,可以准确衡量任意 的得分。
KL散度:用于衡量 和 之间的相似度, KL散度越大, 相似度越小。
1.1 穷举法
这个公式具体在做什么:
现在, 先假设我们不使用任何特定的算法或者神经网络, 在这个前提下我们来讨论如何找到最优的 ,我们记这个最优的 为 。
我们先理解某个 的含义:它表示给定一个prompt ,它的输出 所服从的一种分布。
现在对于某个prompt x , 我们在头脑里想象出若干条分布曲线, 每条曲线表示一种可能的 , 所有曲线代表组成的这个集合П就代表给定某个prompt 的前提下,其输出 的分布的所有可能。 而我们现在要做的,就是从这个集合中,找到最符合人类偏好的真值曲线,记其为 。
既然有了这个集合 ,那我们就可以用穷举法找到 :把集合中的每一种分布都带入到上面的总优化目标中进行计算。在总优化目标中, 都是固定的,只有 在变。
现在, 我们再回过头, 看总优化目标下面的限定条件 , 这个条件意味着, 当你在检验某条分布曲线时,你用到的 就来自这条分布曲线,同样,当你检验到那条最优的分布曲线 时,你用的 就来自这条分布曲线。也就是说,你正在检验哪个分布,你的 就产自哪个分布。
1.2 显式解
现在, 再让我们向现实靠近一点:在实际操作中, 我们根本不可能穷举出固定 下所有 的具体表达式, 如果还是不考虑任何神经网络算法, 我们应该怎么办呢? 那就尝试直接通过数学推导, 求出 的显示解吧。在文章开头我写的dpo推导那篇链接中, 我们给出了求显示解的过程, 这里不再赘述, 直接给出结果:
其中, 是一个配分函数(partition function), 它被定义为 , 之所以这样定义,是为了做归一化,即我们要让 可以成为一种概率分布,其值限制在 范围内。
当我们仔细端详这个显式解等式右侧时候, 我们发现 和 (假设这是完美的奖励函数)都是固定的, 这意味着:
- 虽然我们不知道 的具体表达式,但是我们知道另外一个分布 的具体表达式。那么我只需要把ref模型取出来,喂它吃一个 ,然后穷举(或抽取足够多的 ),我就能估算出 的分布了!
现在让我们再贴近现实一点,上述这个方法可能存在2个问题:
- 穷举的成本是昂贵的。
- 穷举是低效的。
第1个问题显而易见,我们来仔细看第2个问题:什么叫【低效】?
- 首先, 我们是从已知分布 里采样, 去估计最优分布 的具体形式。通俗一点来说, 这里的 y 来自
- 那么, 如果我们从全知的上帝视角来看, 如果最优分布 在吃这条 的情况下, 几乎不可能产出 ,也就是 ,那这样的采样点对我们估计 是没有意义的。 我们来具象化地解释这点,如果你想估计出真值曲线的分布,那么你至少需要保证有足够多的观测点恰好落在分布曲线内,你才能做拟合。如果你的采样的观测点都落在曲线外,那就没有意义了。我们再举一个例子,假设一个袋子里有若干黑球和白球,现在需要你估计球的颜色分布。正常来说,我们可以通过放回取样法去估计 (蒙特卡洛模拟)。但是如果你每次伸进袋子里,啥也不取,只是在把手抽出来的时候,记录"取到红球的次数为 ,那这个采样就对我们估计分布没有意义了。
1.3 拒绝采样
到这一步为止, 虽然我们找到了显式解 。但是我们却面临着穷举昂贵和采样效率低效的问题, 那么, 有什么办法可以提升采样效率呢?
我们前面谈到, 之所以采样低效是因为我们从 中采样的结果可能很难命中 的分布空间(简直就是一种无方向的采样)。那么我们自然而然想到,如果可以把采样的范围做一些限制,是不是就能一定程度上提升采样效率,如下图所示,如果我们可以通过调整 的分布曲线,让它【刚好】把 的分布曲线包裹起来, 我们在这个范围做采样, 就能提升采样的命中率了。读到这里有些朋友可能已经回想起来了, 这种采样方法, 就是我们常说的拒绝采样(rejection sampling), 如下图所示:

(TODO:关于拒绝采样的展开细节,我留在后面更新在我的知乎上,因为我现在想赶紧回家吃俄式大甜筒冰淇淋,所以只好先鸽在这里)。
1.4 隐藏前提
到目前为止, 我们完全不谈诸如DPO, PPO, 各种O的优化方法, 我们只从最原始的总优化目标 出发, 通过一些分析, 【来明确这个优化目标里暗藏了一些什么样的前提】, 我们在这里做个小结。
(1)前提1:数据的采集与分布
- 在这个前提下,我们假设奖励函数r是完美的。
- 我们应该做到, 正在检验哪个 , 我们就从这个 中进行采样 (暗藏着on-policy的假设)。
- 我们至少应该保证, 有充足的观测数据对 是落在真值分布 的分布曲线内的。这一点和上述第2点存在某些交集之处:也就是说如果我们做不到第 2 点,那么至少保证这一点可以实现。
(2)前提2:奖励函数的泛化性
- 但是在实际训练时,奖励函数很难达到完美,主要原因如下:
- 奖励函数可能是有偏的。 我们至少希望这个奖励函数能够很好衡量服从 的观测数据。但实际上它的训练数据可能存在bias(比如极端一点, 它用的都是 低概率处的观测点来训练的), 再加上其泛化能力的不足(这个问题比较玄学一些, 目前我还给不出很好的解释), 最终造成了它的偏差性。
- BT偏好模型本身的缺陷。在RLHF这一步,现在一般默认使用BT模型做成对偏好数据的建模,作为一个先验性质的“标准答案”,它不一定能很好反映人类偏好的复杂程度。
- 正是因为奖励函数的不完美,原始优化目标中的KL散度和值就非常重要:
- 由于我们不能完全信任奖励函数, 所以我们通过 项控制 的迭代步伐, 用 控制对奖励函数的信任程度。
- 如果 设置不当,就可能产生reward hacking的问题: 即最终策略模型拟合了有偏的奖励模型,产生了高奖励但"不符合逻辑"的生成结果。
- 而KL散度这一项也说明了原始目标设计中隐藏的一个前提:我们有一个初始模型(ref),也有某条 prompt ,我们其实是在初始模型最可能产生的那些回复 里,增加人类所喜欢的那些 的概率,降低人类所不喜欢的 y 的概率。 所以理论上 不是任意形式的, 它在 缩放下被 控制住。对于那些在初始模型低概率处的y, 即使我们因为它的r比较高想给他一个较高的 时, 它最终的reward也会被KL项所抵消。
以上对奖励模型的这些讨论,以及reward hacking的问题,可以在openAI的这篇关于reward model scaling law的文章中找到更多细节(https://arxiv.org/pdf/2210.10760)
二、DPO存在的问题
在分析完这些前提的基础上,现在我们可以来一些我们所关心的,具体的优化算法了,我们先来看DPO。
- DPO从 显式解这一步出发, 先推出最优 下奖励函数 的表达
- 根据先验知识, 我们认为BT模型能较好衡量人类的偏好, 我们将 带入这个先验的模型里进行建模。进而构造出了DPO loss,见下图公式(7)。
整体过程如下(具体推导可以看我之前写dpo的文章):

我们拿上文整理出的“原始优化目标的2个前提”,来仔细端详一下dpo loss。
2.1 数据的采集与分布
(1)“意料之外”的数据分布偏移
不难发现, dpo的优化过程并没有尝试去遍历 , 取而代之的是, 它使用的是用观测数据去拟合真值 的做法。所以这里,我们自然而然提出一个问题:
- dpo所使用的数据对 有多少是真得采样自真值分布?
由于dpo的训练数据不采样自我们待训练的策略模型,而是来自别的分布(人类标注, sft模型,其余开源模型的合成数据等,属于off-policy类型),那么我们无法保证这批训练数据能有效覆盖到我们要拟合的真值分布 ,比如,你的数据都是从 曲线外的地方采集到的,那拟合出 自然很难。
我把这些不是我们刻意为之的数据采样称为“意料之外的数据偏移”。解决它的办法之一就是通过前文所说的【拒绝采样】,其中,RSO就是基于这个思想开发的DPO的变种,详细的细节可以参见https://arxiv.org/pdf/2309.06657这篇文章,这里我们只给出RSO的大致改进思路:
- 首先,假设有一批多样性的离线偏好数据集D,它来自各个源,可以认为覆盖比较全面。
- 借助这些数据集,我们先训练一个奖励模型r,可以认为它的性能比较强大。
- 利用这个奖励模型, 我们从 显式解出发, 从已知分布 中通过拒绝采样, 从D中找到最可能落在 分布内的数据点。
- 使用奖励模型,对这些数据点重新进行打分,重新组装偏好对
- 再用这批新的数据做dpo训练。
- 做拒绝采样的过程,其实就是在把off-policy转变为on-policy的过程,整体示例如下:
(2)“意料之内”的数据分布偏移
但此时, 你肯定有这样的疑惑: 在实际训练中, 大部分情况下, 我肯定是先设想我要的 长什么样子, 然后根据这个方向去搜索我要的训练数据, 如果是这样, 那就不存在训练数据在 之外的问题了, 可是我还是经常发生模型崩溃, 或者偏好根本没有注入模型的情况, 这是怎么回事呢?
假设现在我们又一个sft模型,我们想训练它对齐人类的安全偏好,比如 可能是用户提的敏感问题, 句简短的拒绝回答, 一个详实的泄露机密的方案:
- 我们在之前对原始优化目标的分析中,我们还得出过一个前提: 原始优化目标里的KL散度一项保证了 其实是在 最可能产生的那些 里,增加人类喜欢的 yw 的生成概率,降低人类不喜欢的 的概率。也就是说这个 其实是受 的约束的,并不是我们任意想要的任何形式。
- 那么假设你的sft模型在训练时很少见过拒绝的数据, 或者是很少给出简短的回答。那么理论上它能得到的 也大致如此。
- 那么你构造的这批数据, 其实在无意间变成了低概率区域有偏数据, 所以最终, 你没能把知识注入 。
所以此时, 比起在继续rlhf, 更应该回到sft阶段上做继续训练, 对 stt 模型灌入类似于rlhf阶段的分布数据, 先改变 的分布。
2.2 奖励函数/loss的限制:为何chosen与reject的reward会同时下降
虽然说DPO没有显式训练一个奖励模型,但其实我们是可以从dpo loss(上图公式(7))中找到yw和yl的奖励值的,也就是.内的两项。
我们来讨论在dpo训练中一个常见的现象:chosen和reject的reward/prob都同时发生下降。
我们回想前文对rlhf整体优化目标的分析,其中有一条是由于BT模型存在局限性,奖励函数可能并不完美。这个局限性是指:BT模型只能期望发生chosen打败reject的概率要尽量大,但是它不能保证chosen本身尽量大。有了这个前提,我们继续讨论这里的问题。
我们回想一下rlhf阶段偏好对是如何构建的: 一种常用的方法是,在一个/多个sft模型上,对prompt收集多条响应结果,然后让人类/AI labeler进行偏好排序。尽管我们可以通过调整温度系数等参数对 进行采样,但是大多数的chosen和reject响应都采样自 概率的中部处。 也就是这样采样出来的 和 , 其产出的概率基本一致, 序列本身的内容可能也很相近, 这里的相近是指:response的表达方式、语义或者个别关键词等比较相似。对人类标注者来说, 也是需要细致区分的样本。但是, 我们依然不排除训练数据中可能存在序列内容区分显著的 对。
有了这样的认知,我们先不做任何严谨的理论分析,我们可以大致想象一下,什么情况可能造成chosen和reject的reward/prob同时下降:
- 当chosen和reject都采样自的中部处时,它们在序列内容上可能也比较相近。dpo要做的事情是,尽量拉开chosen和reject的距离。所以在训练一开始,它可能接收到标注信号,能拉开一段距离。这时我们应该观察到chosen的reward是上升的。但是在训练后期,当模型已经知道reject表示不好的回复时,它可能也会降低对内容相似的chosen的概率。但这还不够,因为模型对chosen本身也是会向上提的。所以什么时候chosen也会开始出现下降呢:必然存在某个【力】,它拉动chosen上升的力量小于把chosen往下拉的力量,所以导致了chosen下降。在模型训练中,什么东西和【力】相关?自然是【梯度】。
- 当chosen和reject分别采样自分布较远的两个点时,也就是他们在序列内容上的区分已经比较显著时,我们依然会发现chosen在训练阶段可能出现下降的情况。一种可能的原因是:模型在训练过程中,也许找到了一条捷径,例如它可能发现,努力学习什么是不好的,比努力学习什么是好的对优化整个loss更有效。因此它只学到自己不能产出什么,却不知道人们喜欢什么,它对所有的response都保持比较谨慎的态度,因此就可能造成chosen的reward/prob下降。
在这样感性的认知下,我们来看一些理论上的研究工作:
- DPO的训练中,loss对reject的梯度/loss对chosen的梯度 = chosen的概率/reject的概率。这意味着,在对dpo loss landscape做梯度下降的过程中,随着chosen和reject概率间的拉大,把reject向下拉的力 > 把chosen向上拉的力。此时如果两者的序列上存在一定相似性,那么最终会把chosen向下拉。这里的结论来自这篇文章https://arxiv.org/pdf/2404.04626的Corollary 1。文章比较难读,我尽量用通俗的语言描述这里的数学推导相证明的内容。
- DPO的训练中,模型侧重于对reject部分降低loss时,可以更快收敛。这个结论其实和上面的有相似性,这个分析在https://arxiv.org/pdf/2404.04626和Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.这里都有提及。针对这一点,一个经过实验论证的有效的解决办法是,在DPO训练中对reject的reward/prob做clip,使其不至于降得太低,这样就能避免模型走了降低loss的捷径,而没有学到什么是好的。
- 一旦我们对这些实验现象有了初步的感知之后,我们就不难理解一些在loss上对DPO进行处理的变种,比如有些变种选择在loss中增加baseline,或者yw对yl的好坏程度衡量之类的正则项,来使得整个训练过程更加稳定。
2.3 小结
我们简单回顾下这部分的内容。
- 从理论上看,DPO在寻找最优策略分布的过程中,使用的是通过尽可能多的来自的观测数据进行分布拟合的方法。它用这个方法来代替1.1中所说的穷举法(核心是验证哪个分布,就从哪个分布采样)。后者是一种on-policy的策略,而对于前者,如果能做得非常完美,其实它也是一种on-policy的策略。
- 从实践上看,由于【意料之外】或者【意料之内】的一些原因,我们总是不能很好找到能在分布内的数据,所以实践上我们把dpo做成了一种off-policy的方法,从这时开始,它已经和我们最原始的rlhf目标产生了误差。
- 所以接着,我们又提出了一些可行的改进方法,来减小off-policy训练策略上的误差。
- 再从实践上看,基于BT偏好建模(这是一个先验知识,是人们认为它可以用来做偏好建模,所以才选了它)构造出来的奖励/loss形式,在偏好的训练上天然存在一些缺陷,造成模型学不好chosen和reject的信息,特别表现在模型倾向于去学习什么是不好的,而不明白什么才是好的。
- 所以接着,我们又提出了一些可行的改进方法,来探讨如何优化dpo loss或者训练过程。
三、PPO存在的问题
**和dpo不一样,我们在使用ppo优化rlhf的总目标时,我们天然满足“验证哪个分布,就从哪个分布中采样y”的大前提。只是ppo不是完全的on-policy方法(因为它在ppo_steps中重复利用了经验数据),但anyway,它比原生的DPO更加接近原始rlhf优化目标。
PPO的整个训练过程可以概括为:对于 所有可能的分布集合川(理解成这个分布集合里有若干分布曲线),ppo从最原始的代表 的曲线出发,每次通过on-policy的方式进行自我验证,然后根据这个验证结果去找到下一个最可能贴近 的分布曲线,一步步逼近真值。可以理解成是在朴素穷举法上的进一步提效。
所以,总结起来:
- **实践上为off-policy的dpo,更注重利用(expolit)**,这个利用是指对标注的偏好数据对的内容+偏好标签的利用。在不经过任何改进的情况下,原生dpo非常注重训练数据集的分布(又分成意料之外和意料之外的分布,参见2.1节)。
- 实践上为on-policy的ppo,更注重探索(explore)。它的这个探索的性质来自奖励模型和策略模型的分开,在这种情况下,它可以按照自身的分布去探索某个x下可能的y,而不是限制在偏好数据对的标签之下。它天然比原生DPO更符合rlhf优化目标的设计。
不过此时,你应该也发现一个重要的问题了:即使ppo比原生dpo更贴近rlhf优化目标,即使它采用了自生产的数据来减少数据bias的问题,但他依然也依赖奖励函数的性能,因为奖励函数给了ppo探索的反馈。一个最直接的问题就是:策略是on-policy的,但是奖励函数却是固定的,我们如何能保证这个固定的奖励函数的性能?换句话说,如果奖励函数是用在分布之外的数据训练的,那么它最终还是会给策略模型错误的反馈信号。
四、online + on-policy
在上面的分析中,你可能会发现:
- 对原生DPO的改进思路之一是将其转为类on-policy(对应rlhf优化目标中的大前提1)
- 对原生PPO的重要担忧之一是奖励模型的不完备性(对应rlhf优化目标的大前提2,同时由于奖励模型训练和数据分布也有关,所以也对应1)
所以,如果有一种方法,它不仅能on-policy的获取训练数据,它还可以用这些新鲜的on-policy数据,通过人工/ai labeler进行标注,然后将其视为训练数据的一部分,继续进行训练,是不是就可以缩小【实际操作】和【rlhf原始优化】目标之间的gap了?我们做如下定义:
- 当我们使用策略模型自己产生的数据去训练策略模型自己时,我们称on-policy。
- 当我们在训练过程中,尝试让奖励模型也去逼近真值奖励模型时,我们称online。
这就是https://arxiv.org/pdf/2312.11456这篇论文所谈论的总体优化方法(也是比较难读,基本是满满的数学分析)。在这个定义下,我们目前大部分的框架,其实用的都是offline + on-policy。
而沿着这个框架的一个难点就是,我们的标注资源(不管是人工还是自动化)是有限的,如果我们想做online,那么我们需要对要送去重新做标注的数据做一定的筛选,也就是,当我们新增哪些标注数据时,可以保证让我们的策略朝着更好的方向发展?
这篇论文通过数学推论,得出的一个总论点就是:我们应该选择那些与历史数据相比,具有最大不确定性的数据进行再评估。这样说来可能有点抽象,我们举一些具体的例子:
- 当我们当前的奖励模型对一个数据点打分特别高,或者特别低时,那么它就可能是一个会拉偏分布的数据点,我们需要对它进行再度审视。
- 如果对于一个prompt x,它在本轮迭代中的得到的输出分布和上一轮迭代中得到的输出分布相差较多时,那么它就值得重新被审视。相关的细节如果后面有时间,再慢慢展开,这篇文章还是很值得一读的,只是所有的结论都隐藏在它的数学推导中,比较难提取出,这里我就只写一些比较关键的部分了。
...
#RESSL
标题只是缩写啊 这个ssl 不是openssl加解密那个哈
自监督学习(SSL)在最近几年取得了很大的进展,在许多下游任务上几乎已经达到监督学习方法的水平。但是,由于模型的复杂性以及缺乏有标注训练数据集,我们还一直难以理解学习到的表征及其底层的工作机制。此外,自监督学习中使用的 pretext 任务通常与特定下游任务的直接关系不大,这就进一步增大了解释所学习到的表征的复杂性。而在监督式分类中,所学到的表征的结构往往很简单。
相比于传统的分类任务(目标是准确将样本归入特定类别),现代 SSL 算法的目标通常是最小化包含两大成分的损失函数:一是对增强过的样本进行聚类(不变性约束),二是防止表征坍缩(正则化约束)。举个例子,对于同一样本经过不同增强之后的数据,对比式学习方法的目标是让这些样本的分类结果一样,同时又要能区分经过增强之后的不同样本。另一方面,非对比式方法要使用正则化器(regularizer)来避免表征坍缩。
自监督学习可以利用辅助任务(pretext)无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。近日,图灵奖得主 Yann LeCun 在内的多位研究者发布了一项研究,宣称对自监督学习进行了逆向工程,让我们得以了解其训练过程的内部行为。
Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的
论文地址:https://arxiv.org/abs/2305.15614v2
这篇论文通过一系列精心设计的实验对使用 SLL 的表征学习进行了深度分析,帮助人们理解训练期间的聚类过程。具体来说,研究揭示出增强过的样本会表现出高度聚类的行为,这会围绕共享同一图像的增强样本的含义嵌入形成质心。更出人意料的是,研究者观察到:即便缺乏有关目标任务的明确信息,样本也会根据语义标签发生聚类。这表明 SSL 有能力根据语义相似性对样本进行分组。
问题设置
由于自监督学习(SSL)通常用于预训练,让模型做好准备适应下游任务,这带来了一个关键问题:SSL 训练会对所学到的表征产生什么影响?具体来说,训练期间 SSL 的底层工作机制是怎样的,这些表征函数能学到什么类别?
为了调查这些问题,研究者在多种设置上训练了 SSL 网络并使用不同的技术分析了它们的行为。
数据和增强:本文提到的所有实验都使用了 CIFAR100 图像分类数据集。为了训练模型,研究者使用了 SimCLR 中提出的图像增强协议。每一个 SSL 训练 session 都执行 1000 epoch,使用了带动量的 SGD 优化器。
骨干架构:所有的实验都使用了 RES-L-H 架构作为骨干,再加上了两层多层感知器(MLP)投射头。
线性探测(linear probing):为了评估从表征函数中提取给定离散函数(例如类别)的有效性,这里使用的方法是线性探测。这需要基于该表征训练一个线性分类器(也称为线性探针),这需要用到一些训练样本。
样本层面的分类:为了评估样本层面的可分离性,研究者创建了一个专门的新数据集。
其中训练数据集包含来自 CIFAR-100 训练集的 500 张随机图像。每张图像都代表一个特定类别并会进行 100 种不同的增强。因此,训练数据集包含 500 个类别的共计 50000 个样本。测试集依然是用这 500 张图像,但要使用 20 种不同的增强,这些增强都来自同一分布。因此,测试集中的结果由 10000 个样本构成。为了在样本层面衡量给定表征函数的线性或 NCC(nearest class-center / 最近类别中心)准确度,这里采用的方法是先使用训练数据计算出一个相关的分类器,然后再在相应测试集上评估其准确率。
揭示自监督学习的聚类过程
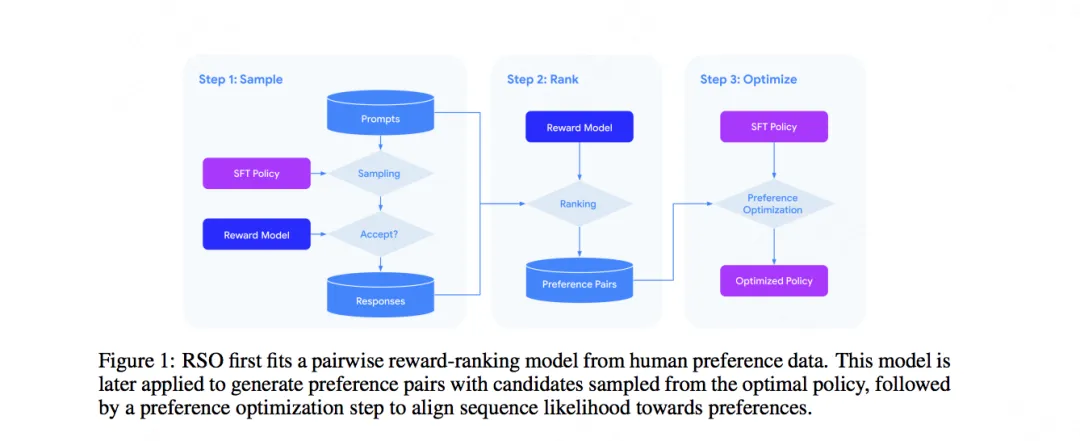
在帮助分析深度学习模型方面,聚类过程一直以来都发挥着重要作用。为了直观地理解 SSL 训练,图 1 通过 UMAP 可视化展示了网络的训练样本的嵌入空间,其中包含训练前后的情况并分了不同层级。
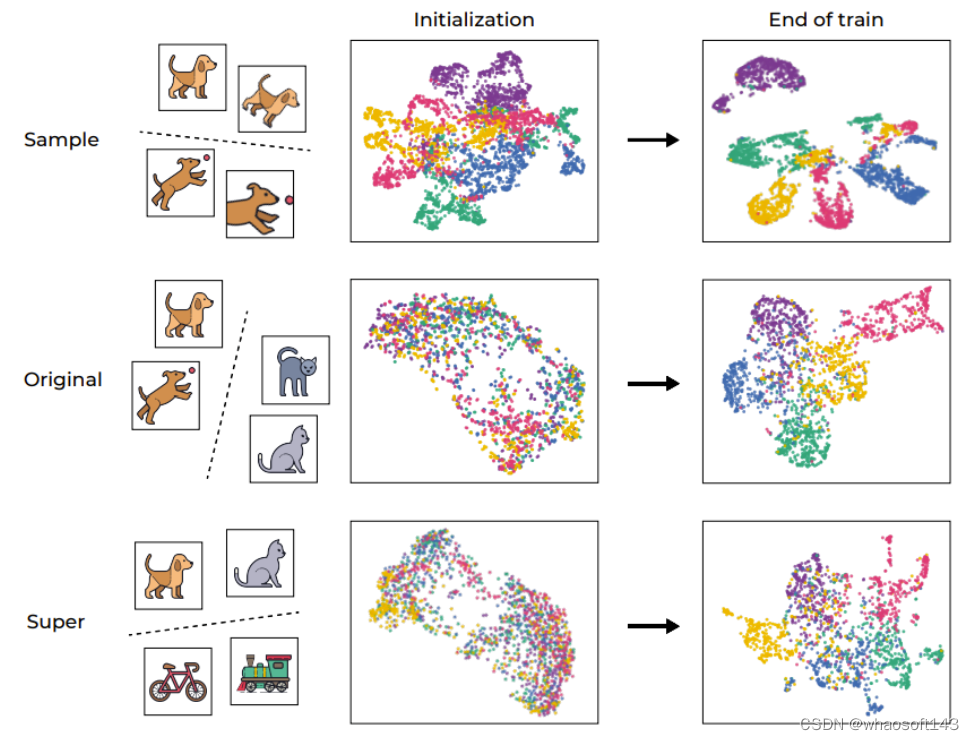
图 1:SSL 训练引起的语义聚类
正如预期的那样,训练过程成功地在样本层面上对样本进行了聚类,映射了同一图像的不同增强(如第一行图示)。考虑到目标函数本身就会鼓励这种行为(通过不变性损失项),因此这样的结果倒是不意外。然而,更值得注意的是,该训练过程还会根据标准 CIFAR-100 数据集的原始「语义类别」进行聚类,即便该训练过程期间缺乏标签。有趣的是,更高的层级(超类别)也能被有效聚类。这个例子表明,尽管训练流程直接鼓励的是样本层面的聚类,但 SSL 训练的数据表征还会在不同层面上根据语义类别来进行聚类。
为了进一步量化这个聚类过程,研究者使用 VICReg 训练了一个 RES-10-250。研究者衡量的是 NCC 训练准确度,既有样本层面的,也有基于原始类别的。值得注意的是,SSL 训练的表征在样本层面上展现出了神经坍缩(neural collapse,即 NCC 训练准确度接近于 1.0),然而在语义类别方面的聚类也很显著(在原始目标上约为 0.41)。
如图 2 左图所示,涉及增强(网络直接基于其训练的)的聚类过程大部分都发生在训练过程初期,然后陷入停滞;而在语义类别方面的聚类(训练目标中并未指定)则会在训练过程中持续提升。
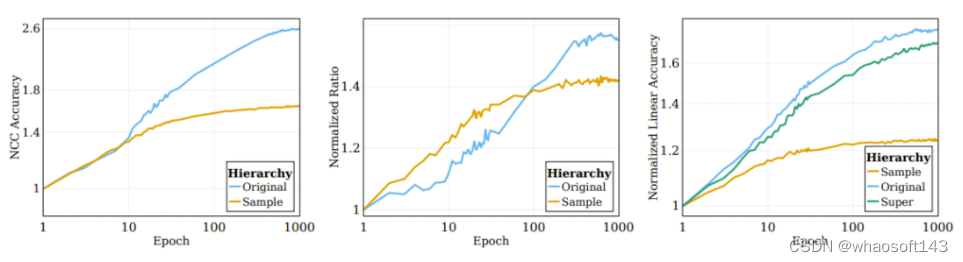
图 2:SSL 算法根据语义目标对对数据的聚类
之前有研究者观察到,监督式训练样本的顶层嵌入会逐渐向一个类质心的结构收敛。为了更好地理解 SSL 训练的表征函数的聚类性质,研究者调查了 SSL 过程中的类似情况。其 NCC 分类器是一种线性分类器,其表现不会超过最佳的线性分类器。通过评估 NCC 分类器与同样数据上训练的线性分类器的准确度之比,能够在不同粒度层级上研究数据聚类。图 2 的中图给出了样本层面类别和原始目标类别上的这一比值的变化情况,其值根据初始化的值进行了归一化。随着 SSL 训练的进行,NCC 准确度和线性准确度之间的差距会变小,这说明增强后的样本会根据其样本身份和语义属性逐渐提升聚类水平。
此外,该图还说明,样本层面的比值起初会高一些,这说明增强后的样本会根据它们的身份进行聚类,直到收敛至质心(NCC 准确度和线性准确度的比值在 100 epoch 时 ≥ 0.9)。但是,随着训练继续,样本层面的比值会饱和,而类别层面的比值会继续增长并收敛至 0.75 左右。这说明增强后的样本首先会根据样本身份进行聚类,实现之后,再根据高层面的语义类别进行聚类。
SSL 训练中隐含的信息压缩
如果能有效进行压缩,那么就能得到有益又有用的表征。但 SSL 训练过程中是否会出现那样的压缩却仍是少有人研究的课题。
为了了解这一点,研究者使用了互信息神经估计(Mutual Information Neural Estimation/MINE),这种方法可以估计训练过程中输入与其对应嵌入表征之间的互信息。这个度量可用于有效衡量表征的复杂度水平,其做法是展现其编码的信息量(比特数量)。
图 3 的中图报告了在 5 个不同的 MINE 初始化种子上计算得到的平均互信息。如图所示,训练过程会有显著的压缩,最终形成高度紧凑的训练表征。
图 3:(左)一个 SSL 训练的模型在训练期间的正则化和不变性损失以及原始目标线性测试准确度。(中)训练期间输入和表征之间的互信息的压缩。(右)SSL 训练学习聚类的表征。
正则化损失的作用
目标函数包含两项:不变性和正则化。不变性项的主要功能是强化同一样本的不同增强的表征之间的相似性。而正则化项的目标是帮助防止表征坍缩。
为了探究这些分量对聚类过程的作用,研究者将目标函数分解为了不变性项和正则化项,并观察它们在训练过程中的行为。比较结果见图 3 左图,其中给出了原始语义目标上的损失项的演变以及线性测试准确度。不同于普遍流行的想法,不变性损失项在训练过程中并不会显著改善。相反,损失(以及下游的语义准确度)的改善是通过降低正则化损失实现的。
由此可以得出结论:SSL 的大部分训练过程都是为了提升语义准确度和所学表征的聚类,而非样本层面的分类准确度和聚类。
从本质上讲,这里的发现表明:尽管自监督学习的直接目标是样本层面的分类,但其实大部分训练时间都用于不同层级上基于语义类别的数据聚类。这一观察结果表明 SSL 方法有能力通过聚类生成有语义含义的表征,这也让我们得以了解其底层机制。
监督学习和 SSL 聚类的比较
深度网络分类器往往是基于训练样本的类别将它们聚类到各个质心。但学习得到的函数要能真正聚类,必须要求这一性质对测试样本依然有效;这是我们期望得到的效果,但效果会差一点。
这里有一个有趣的问题:相比于监督学习的聚类,SSL 能在多大程度上根据样本的语义类别来执行聚类?图 3 右图报告了在不同场景(使用和不使用增强的监督学习以及 SSL)的训练结束时的 NCC 训练和测试准确度比率。
尽管监督式分类器的 NCC 训练准确度为 1.0,显著高于 SSL 训练的模型的 NCC 训练准确度,但 SSL 模型的 NCC 测试准确度却略高于监督式模型的 NCC 测试准确度。这说明两种模型根据语义类别的聚类行为具有相似的程度。有意思的是,使用增强样本训练监督式模型会稍微降低 NCC 训练准确度,却会大幅提升 NCC 测试准确度。
探索语义类别学习和随机性的影响
语义类别是根据输入的内在模式来定义输入和目标的关系。另一方面,如果将输入映射到随机目标,则会看到缺乏可辨别的模式,这会导致输入和目标之间的连接看起来很任意。
研究者还探究了随机性对模型学习所需目标的熟练程度的影响。为此,他们构建了一系列具有不同随机度的目标系统,然后检查了随机度对所学表征的影响。他们在用于分类的同一数据集上训练了一个神经网络分类器,然后使用其不同 epoch 的目标预测作为具有不同随机度的目标。在 epoch 0 时,网络是完全随机的,会得到确定的但看似任意的标签。随着训练进行,其函数的随机性下降,最终得到与基本真值目标对齐的目标(可认为是完全不随机)。这里将随机度归一化到 0(完全不随机,训练结束时)到 1(完全随机,初始化时)之间。
图 4 左图展示了不同随机度目标的线性测试准确度。每条线都对应于不同随机度的 SSL 不同训练阶段的准确度。可以看到,在训练过程中,模型会更高效地捕获与「语义」目标(更低随机度)更接近的类别,同时在高随机度的目标上没有表现出显著的性能改进。
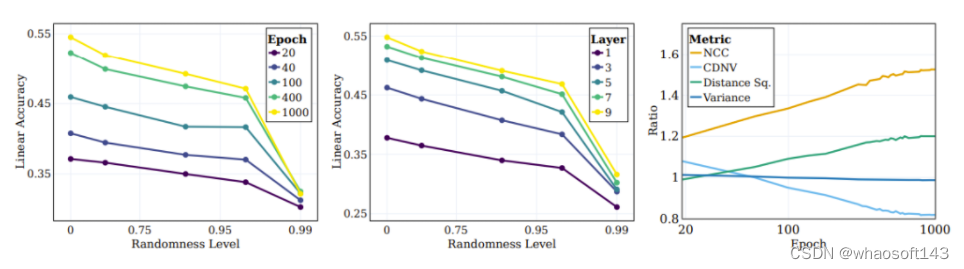
图 4:SSL 持续学习语义目标,而非随机目标
深度学习的一个关键问题是理解中间层对分类不同类型类别的作用和影响。比如,不同的层会学到不同类型的类别吗?研究者也探索了这个问题,其做法是在训练结束时不同目标随机度下评估不同层表征的线性测试准确度。如图 4 中图所示,随着随机度下降,线性测试准确度持续提升,更深度的层在所有类别类型上都表现更优,而对于接近语义类别的分类,性能差距会更大。
研究者还使用了其它一些度量来评估聚类的质量:NCC 准确度、CDNV、平均每类方差、类别均值之间的平均平方距离。为了衡量表征随训练进行的改进情况,研究者为语义目标和随机目标计算了这些指标的比率。图 4 右图展示了这些比率,结果表明相比于随机目标,表征会更加偏向根据语义目标来聚类数据。有趣的是,可以看到 CDNV(方差除以平方距离)会降低,其原因仅仅是平方距离的下降。方差比率在训练期间相当稳定。这会鼓励聚类之间的间距拉大,这一现象已被证明能带来性能提升。
了解类别层级结构和中间层
之前的研究已经证明,在监督学习中,中间层会逐渐捕获不同抽象层级的特征。初始的层倾向于低层级的特征,而更深的层会捕获更抽象的特征。接下来,研究者探究了 SSL 网络能否学习更高层面的层次属性以及哪些层面与这些属性的关联性更好。
在实验中,他们计算了三个层级的线性测试准确度:样本层级、原始的 100 个类别、20 个超类别。图 2 右图给出了为这三个不同类别集计算的数量。可以观察到,在训练过程中,相较于样本层级的类别,在原始类别和超类别层级上的表现的提升更显著。
接下来是 SSL 训练的模型的中间层的行为以及它们捕获不同层级的目标的能力。图 5 左和中图给出了不同训练阶段在所有中间层上的线性测试准确度,这里度量了原始目标和超目标。图 5 右图给出超类别和原始类别之间的比率。
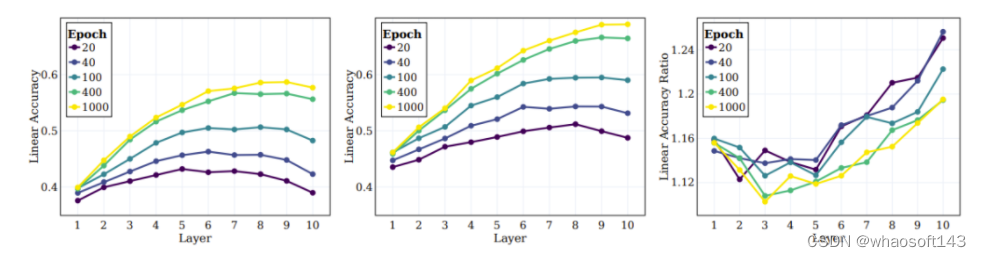
图 5:SSL 能在整体中间层中有效学习语义类别
研究者基于这些结果得到了几个结论。首先,可以观察到随着层的深入,聚类效果会持续提升。此外,与监督学习情况类似,研究者发现在 SSL 训练期间,网络每一层的线性准确度都有提升。值得注意的是,他们发现对于原始类别,最终层并不是最佳层。近期的一些 SSL 研究表明:下游任务能高度影响不同算法的性能。本文的研究拓展了这一观察结果,并且表明网络的不同部分可能适合不同的下游任务与任务层级。根据图 5 右图,可以看出,在网络的更深层,超类别的准确度的提升幅度超过原始类别。
...
#AlphaDev
「通过交换和复制移动,AlphaDev 跳过了一个步骤,以一种看似错误,但实际上是捷径的方式连接项目。」这种前所未见、违反直觉的思想不禁让人回忆起 2016 年那个春天。计算的基础就此改变了。
七年前,AlphaGo 在围棋上击败人类世界冠军,如今 AI 又在编程上给我们上了一课。
今天凌晨,Google DeepMind CEO 哈萨比斯的两句话引爆了计算机领域:「AlphaDev 发现了一种全新且更快的排序算法,我们已将其开源到主要 C++ 库中供开发人员使用。这只是 AI 提升代码效率进步的开始。」
这一次,Google DeepMind 的全新强化学习系统 AlphaDev 发现了一种比以往更快的哈希算法,这是计算机科学领域中的一种基本算法,AI 的成果现已被纳入 LLVM 标准 C++ 库 Abseil 并开源。
这个成果有多重要?AlphaDev 的主要作者之一,Google DeepMind 研究科学家 Daniel J. Mankowitz 表示:「我们估计它发现的排序和哈希算法每天会在全世界被调用数万亿次。」
AI 似乎从算法层面加速了世界的运转。
这些算法改进了 LLVM libc++ 排序库,对于较短的序列,排序库的速度提高了 70%,对于超过 25 万个元素的序列,速度也能提高约 1.7%。Google DeepMind 表示,这是十多年来排序库这部分的第一次变化。看起来,现在 AI 不仅可以帮人写代码,而且可以帮我们写出更好的代码。
在最新的博客中,新系统的作者们对 AlphaDev 进行了详细介绍。
新的算法将改变计算基础
数字社会推动了对计算和能源日益增长的需求。过去五十年里,数字时代依靠硬件的改进来跟上需求。但是随着微芯片接近其物理极限,改进在其上运行的代码变得至关重要。对于每天运行数万亿次的代码所包含的算法来说,这尤其重要。
Google DeepMind 的这项研究就是因此产生的,相关论文已发表在《Nature》上,AlphaDev 是一个 AI 系统,它使用强化学习来发现算法,甚至超越了科学家和工程师们几十年来打磨出来的成果。
论文地址:https://www.nature.com/articles/s41586-023-06004-9
总体来说,AlphaDev 发现了一种更快的排序算法。虽然数十亿人每天都在使用这些算法,但却没有人意识到这一算法还存在优化空间。排序算法应用范围广泛,从在线搜索结果、社交帖子排序,到计算机以及手机上的各种数据处理,都离不开排序算法。利用 AI 生成更好的算法将改变人类编程计算机的方式,对日益数字化的社会将产生重大影响。
通过在主要的 C++ 库中开源新排序算法,全球数百万开发人员和公司现在可以在云计算、在线购物和供应链管理等各行各业的人工智能应用中使用它。这是十多年来对排序库的首次更改,也是通过强化学习设计的算法首次被添加到该库中。这将这视为使用人工智能逐步优化世界代码的重要里程碑。
关于排序
排序算法是一种按照特定顺序对某些任务进行排列的方法。例如,按字母先后顺序排列三个字母,从大到小排列五个数字,或者对数百万条记录的数据库进行排序。
这种算法由来已久,并得到了很好的演进。其中关于排序的最早一个示例可追溯到公元 2 世纪和 3 世纪,当时学者们在亚历山大图书馆的书架上手工按字母顺序排列了数千本书。随着工业革命的到来,出现了可以帮助人们进行排序的机器,其中制表机使用打孔卡片存储信息,这些卡片被用于收集美国 1890 年的人口普查结果。
随着上世纪 50 年代商用计算机的兴起,最早用于排序算法的计算机科学算法开始发展。如今,在全球的代码库中有许多不同的排序技术和算法被用于处理海量的在线数据。
将一系列未排序的数字输入到算法中,输出已排序的数字。
经过计算机科学家和程序员们几十年的研究,目前的排序算法已经非常高效,以至于很难再实现进一步的改进,这有点类似于试图找到一种新的节省电力或更高效的数学方法,而这些算法也是计算机科学的基石。
探索新算法:汇编指令
AlphaDev 从头开始探索更快的算法,而不是基于现有算法之上,除此以外,AlphaDev 还能用于寻找大多数人所不涉足的领域:计算机汇编指令。
汇编指令可用于创建计算机执行的二进制代码。开发人员使用诸如 C++ 之类的高级语言编写代码,但必须将其转换为计算机能够理解的「低级」汇编指令。
Google DeepMind 认为这个层次存在许多改进的空间,而这些改进在更高级的编程语言中可能很难被发现。在这个层次上,计算机的存储和操作更加灵活,这意味着存在更多潜在的改进可能性,这些改进可能对速度和能源使用产生更大的影响。
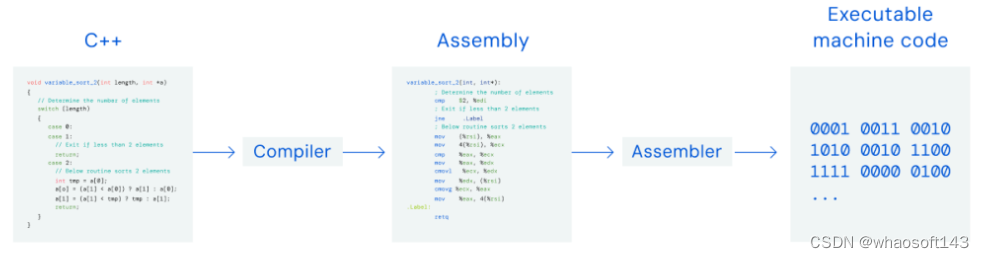
代码通常是用高级编程语言(如 C++)编写的。然后,编译器将其转换为低级 CPU 指令,称为汇编指令。汇编器将汇编指令转换为可执行的机器码,以便计算机可以运行。

图 A:C++ 算法示例,该算法可对最多两个元素进行排序;图 B:相应的汇编表示形式。
用 AlphaGo 的方法寻找最佳算法
AlphaDev 基于 Google DeepMind 此前的一项成果:在围棋、国际象棋和象棋等游戏中打败世界冠军的强化学习模型 AlphaZero。而 AlphaDev 展示了这个模型如何从游戏转移到科学挑战,以及从模拟到现实世界的应用。
为了训练 AlphaDev 发现新的算法,团队将排序变成了一个单人的「组装游戏」。在每个回合中,AlphaDev 观察它所产生的算法和 CPU 中包含的信息,然后通过选择一条指令添加到算法中来下一步棋。
汇编游戏是非常困难的,因为 AlphaDev 必须在大量可能的指令组合中进行高效搜索,以找到一个可以排序的算法,并且比当前的最佳算法更快。指令的可能组合数量类似于宇宙中的粒子数量,或者国际象棋(10^120 局)和围棋(10^700 局)中可能的动作组合的数量,而一个错误的动作就可以使整个算法失效。
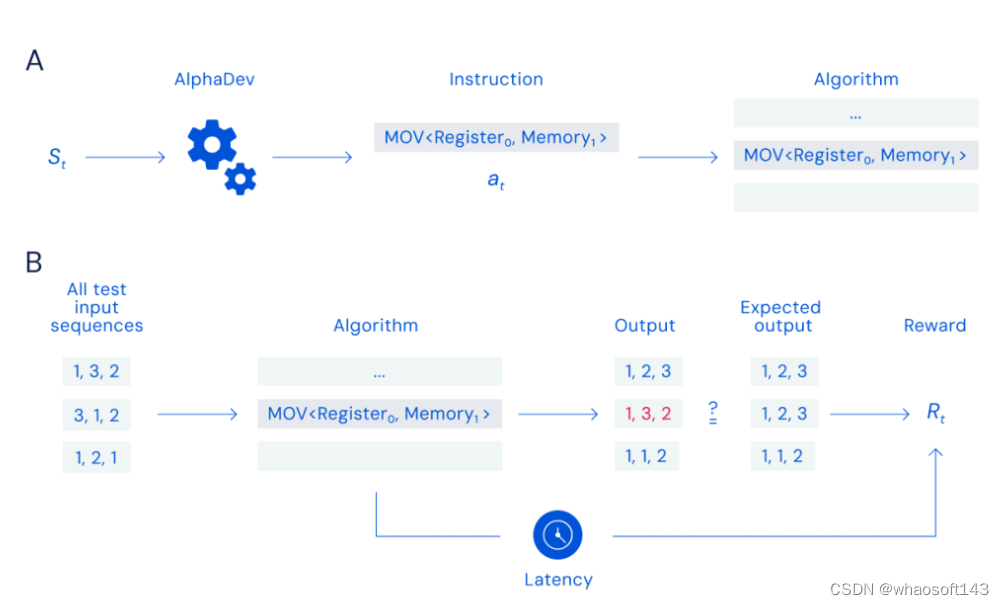
图 A:组装游戏。玩家 AlphaDev 接收系统 st 的状态作为输入,并通过选择一条汇编指令添加到目前已生成的算法中来下棋。图 B:奖励计算。每次移动后,生成的算法都会输入测试输入序列 —— 对于 sort3,这对应于三个元素序列的所有组合。该算法然后生成一个输出,将其与排序情况下排序序列的预期输出进行比较。智能体根据算法的正确性和延迟获得奖励。
在构建算法时,对于每次的一条指令,AlphaDev 通过将算法的输出与预期结果进行比较来检查它是否正确。对于排序算法,这意味着无序数字进入,正确排序的数字出来。团队会奖励 AlphaDev 对数字的正确排序以及排序的速度和效率,然后 AlphaDev 通过发现正确、更快的程序来赢得比赛。
它发现了更快的排序算法
AlphaDev 发现了新的排序算法,这些算法导致 LLVM libc++ 排序库得到改进:对于较短的序列,排序库的速度提高了 70%,对于超过 25 万个元素的序列,速度提高了约 1.7%。
其中,Google DeepMind 团队更专注于改进三到五个元素的短序列排序算法。这些算法是使用最广泛的算法之一,因为它们通常作为更大排序函数的一部分被多次调用,改进这些算法可以提高对任意数量项目进行排序的整体速度。
为了让新的排序算法对人们更有用,团队对算法进行了逆向工程并将它们翻译成 C++,这是开发人员使用的最流行的编程语言之一。
目前,这些算法已在 LLVM libc++ 标准排序库(https://reviews.llvm.org/D118029)中提供,被全球数百万开发人员和公司使用。
「交换和复制动作」,神之一手重现?
事实上,AlphaDev 不仅发现了更快的算法,而且还发现了新的方法。它的排序算法包含新的指令序列,每次应用时都会节省一条指令 —— 这显然会产生巨大的影响,因为这些算法每天都要使用数万亿次。他们把这些称为「AlphaDev 交换和复制动作」。
这种新颖的方法让人联想到 AlphaGo 的「第 37 步」—— 当时这这种反直觉的下法让围观者目瞪口呆,并导致李世石这位传奇围棋选手被打败。通过交换和复制动作,AlphaDev 跳过了一个步骤,以一种看起来像错误但实际上是捷径的方式连接项目。这表明 AlphaDev 有能力发掘出原创性的解决方案,并挑战人类对如何改进计算机科学算法的思考方式。

左图:min (A,B,C) 原始的 sort3 实现;右图:AlphaDev 交换移动 ——AlphaDev 发现你只需要 min (A,B)。

左图:在一个更大的排序算法中使用 max(B,min(A,C,D))的原始实现,用于排序八个元素;右图:AlphaDev 发现,使用其复制动作时,只需要 max(B,min(A,C))。
扩展能力测验:从「排序」到「哈希」
在发现更快的排序算法后,团队测试了 AlphaDev 是否可以概括和改进不同的计算机科学算法:哈希。
哈希是计算中用于检索、存储和压缩数据的基本算法。就像使用分类系统来定位某本书的图书管理员一样,哈希算法可以帮助用户知道他们正在寻找什么以及在哪里可以找到它。这些算法获取特定密钥的数据(例如用户名 “Jane Doe”)并对其进行哈希处理 —— 这是一个将原始数据转换为唯一字符串(例如 1234ghfty)的过程。计算机使用此哈希来快速检索与密钥相关的数据,而不是搜索所有数据。
团队将 AlphaDev 应用于数据结构中最常用的哈希算法之一,尝试发现更快的算法。当将其应用于 9-16 字节范围的哈希函数时,AlphaDev 发现的算法速度提高了 30%。
今年,AlphaDev 的新哈希算法已被发布到开源 Abseil 库中,可供全球数百万开发人员使用,它现在大概每天被使用数万亿次。
开源地址:https://github.com/abseil/abseil-cpp/commit/74eee2aff683cc7dcd2dbaa69b2c654596d8024e
结语
Google DeepMind 通过优化和推出改进的排序和哈希算法,供世界各地的开发人员使用,AlphaDev 展示了其概括和发现具有现实影响的新算法的能力。AlphaDev 可被视为开发通用 AI 工具的一步,它可以帮助优化整个计算生态系统并解决其他造福社会的问题。
虽然在低级汇编指令空间中进行优化非常强大,但随着算法的增长, AlphaDev 仍存在局限性,团队目前正在探索其直接在高级语言(如 C++)中优化算法的能力,这对开发人员来说更加有用。
AlphaDev 的发现,例如交换和复制动作,不仅表明它可以改进算法,还可以找到新的解决方案。这些发现或许能够激励研究人员和开发人员创建可以进一步优化基础算法的技术和方法,以创建更强大和可持续的计算生态系统。
...
#Spatio-temporal-Diffusion-Point-Processes
清华大学电子工程系城市科学与计算研究中心最新提出时空扩散点过程,突破已有方法建模时空点过程的受限概率形式和高采样成本等缺陷,实现了灵活、高效且易于计算的时空点过程模型,可广泛用于城市自然灾害、突发事故和居民活动等时空事件的建模与预测,促进城市规划和管理的智能化发展。扩散模型还能预测地震和犯罪
时空点过程是具有时间和空间属性的随机事件集合,相关研究方法主要是对随机事件在时间和空间上的分布和演化规律进行建模,这对于许多领域都至关重要,包括地震学、疾病传播、城市流动、环境监测等。然而,以往的研究在建模时通常将时间和空间视为条件独立,无法准确捕捉事件时空之间的复杂相互作用,且计算对数似然需要使用蒙特卡罗来近似积分,这导致对时空点过程的理解和预测存在很大的局限性。
清华大学电子工程系城市科学与计算研究中心近日在 KDD2023 发表论文《Spatio-temporal Diffusion Point Processes》,提出时空扩散点过程(DSTPP)模型,率先实现了对复杂时空联合分布的灵活精准建模。由于不对概率密度函数的参数形式施加任何限制,这种基于扩散模型的点过程方法解决了当前时空建模的一系列困难问题,在捕捉复杂时空动态性方面具有很大潜力。该方法建立了新的生成式时空建模范式,为该领域的研究和应用带来了新的可能性。
- 论文链接:https://arxiv.org/abs/2305.12403
- 开源代码及数据:https://github.com/tsinghua-fib-lab/Spatio-temporal-Diffusion-Point-Processes
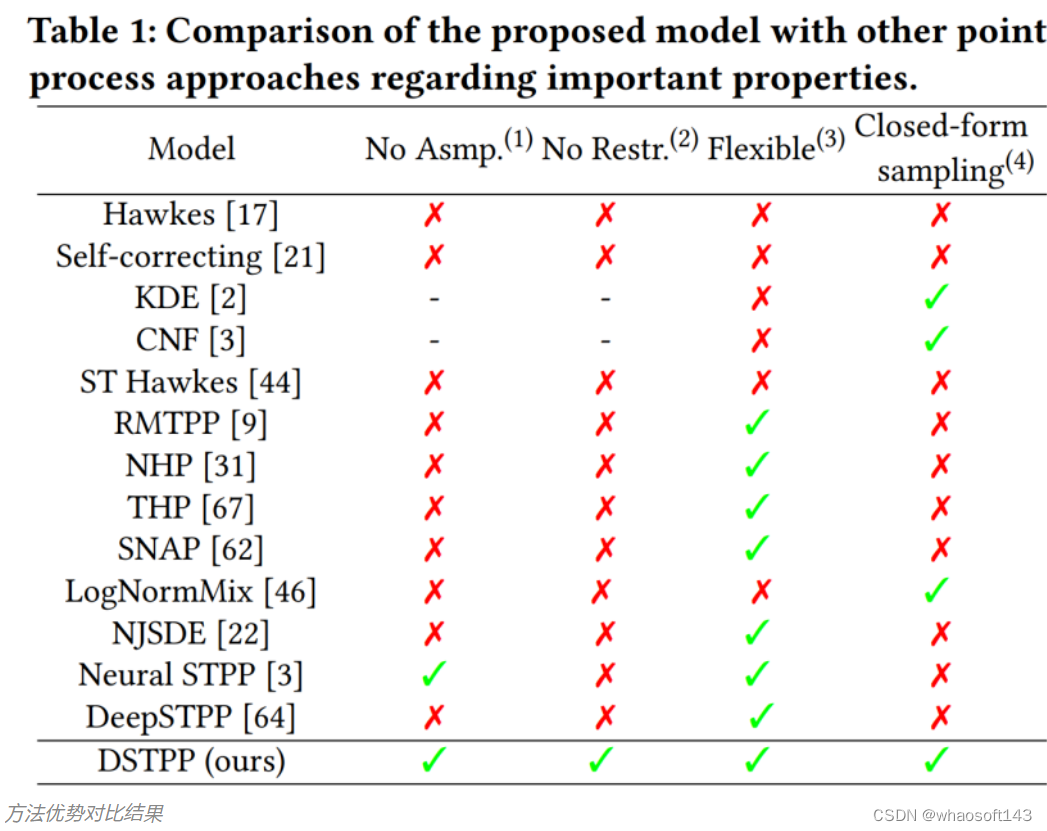
针对时空点过程,研究团队提出了全新的参数化框架,利用扩散模型学习复杂的时空联合分布。该框架将目标联合分布的学习分解为多个步骤,每个步骤可由高斯分布准确描述。为了增强每个步骤的学习能力,研究团队在去噪网络中嵌入时空共注意力机制,使其能自适应地捕捉时间和空间复杂的依赖耦合关系。通过这一创新模型,研究团队首次突破了现有解决方案对时空依赖关系的建模限制,为时空点过程提供了新的建模范式。下表展示了 DSTPP 相比已有点过程解决方案的优势。
大量来自流行病学、地震学、犯罪学和城市流动等各领域的实验表明,DSTPP 在性能上显著超越现有解决方案,平均提升幅度超过 50%。进一步深入分析验证了该模型适应不同场景下复杂时空耦合关系的能力。
这一创新研究成果为时空点过程建模提供了全新的思路和方法,具有重要的理论和应用价值。该模型的成功应用将为地震预测、疾病控制和城市规划等领域带来更准确的分析和预测能力,助力城市发展和人类福祉。
值得注意的是,该项目的论文、代码和数据集均已开源:
开源地址:https://github.com/tsinghua-fib-lab/Spatio-temporal-Diffusion-Point-Processes
效果展示
下面展示了不同数据集(地震,高斯霍克斯过程,流行病传播)的去噪过程。

日本地震分布去噪

混合高斯霍克斯过程去噪

美国新泽西州疫情分布去噪

日本地震密度图

混合高斯霍克斯过程密度图

方法概览
扩散去噪建模框架
该框架首先设计时空编码器学习历史时空事件的表征,以该表征作为条件,DSTPP 旨在学习未来事件的时空联合分布模型。具体而言,对于序列中的每个事件,该方法将扩散过程建模为在空间和时间域上的马尔科夫过程,逐步向空间和时间值添加微小高斯噪声,直到它们被破坏城纯高斯噪声。在时空场景下,向时间和空间域添加噪声的过程类似于图像场景(噪声独立地应用于每个像素),DSTPP 通过以下方式在空间和时间域上分别进行独立扩散:
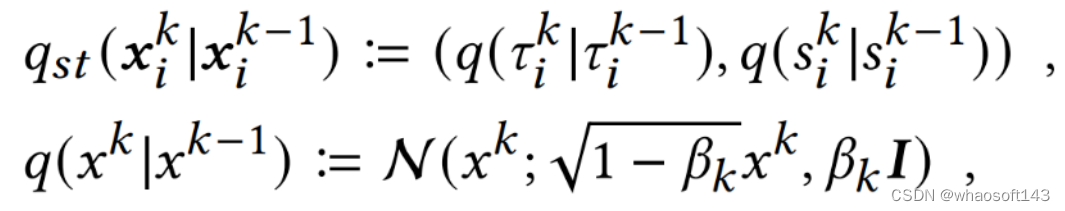
时空扩散过程
相反地,DSTPP 将下一步事件的预测建模为从第 K 步到第 0 步的逆向去噪迭代过程。时间和空间的去噪过程依赖于前一步中获得的彼此之间的信息,而下一步的预测值以时间和空间条件独立的方式进行建模,具体公式如下:
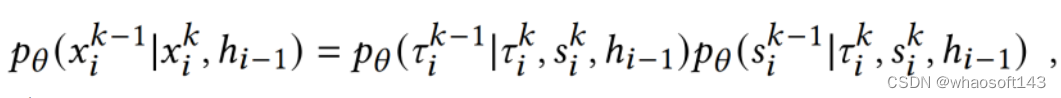
时空去噪过程
通过这种方式,DSTPP 成功将时空联合分布的建模分解为单步条件独立建模,而组合起来是联合建模的形式,实现了对时空联合分布的有效建模。下面罗列了 DSTPP 的训练和采样算法,这些算法训练稳定,易于实现。

训练及采样算法
网络架构
针对网络架构,研究团队在时空编码器部分提出使用基于 Transformer 的架构来学习历史时空表征,在时空扩散部分提出时空共注意力网络来参数化噪声预测网络。在每个去噪步骤中,时空共注意力网络同时执行空间和时间注意力,以捕捉二者之间的细粒度交互。不同去噪步骤共享相同的网络结构,都是基于历史表征,上一步预测得到的时空结果和去噪步数 k 的位置编码,来预测下一步的时空噪声。
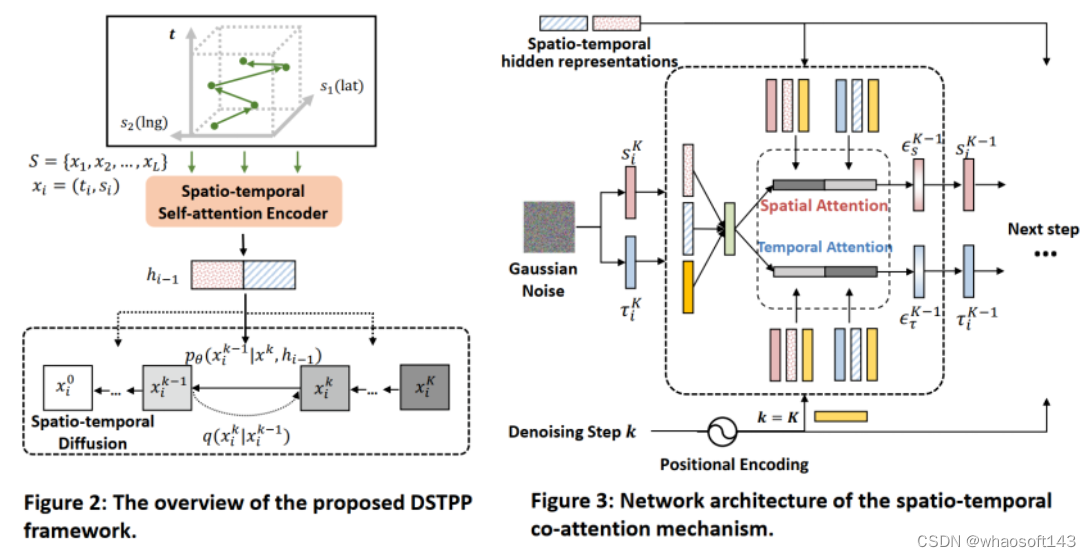
网络结构图
实验结果
研究团队将 DSTPP 与最先进的时空点过程方法进行比较,并在 8 个数据集(所有数据集均已开源)进行了大量的实验。在连续空间情形下中,论文使用了两个仿真数据集和四个真实世界数据集,涵盖了广泛的领域,包括地震学,人类移动、流行病传播、城市单车使用,以及模拟的霍克斯高斯混合过程和风车结构数据。此外,论文还使用了两个真实世界的离散数据集,包括犯罪数据和出租车数据,它们的空间标签是离散的街区。
研究团队将所提的 DSTPP 与一系列最先进的建模方法进行对比,这些方法可以分为三类:空间点过程模型,时间点过程模型,时空点过程模型。针对时空点过程,可以自由组合已有的空间点过程和时间点过程来进行建模。结果显示,DSTPP 在所有数据集上的多个评估指标上均取得了最佳表现,相比最佳基线模型平均提升超过 50%。
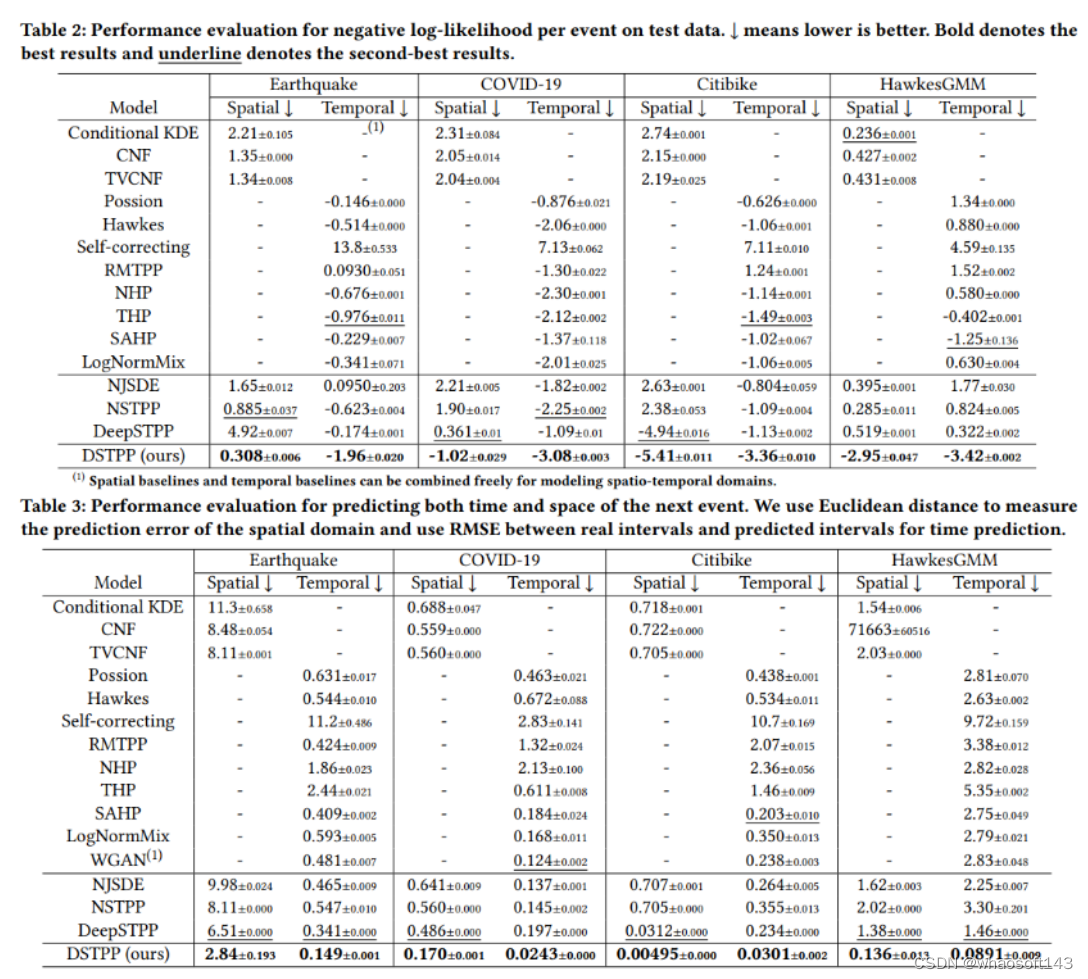
似然和预测误差结果
为了更深入地理解去噪过程中的时空相互依赖关系,研究团队对共同注意力权重进行了深入分析。并构造一个新的的仿真数据集,该数据的时空两个维度是完全独立的,因此可以验证所设计的时空共同注意力机制是否可以学习不同的时空相互依赖关系。下图展示了在去噪过程中时间和空间维度在彼此和自身上的注意力权重变化情况。在时空耦合数据集上,随着去噪过程的进行,时间和空间维度逐渐向彼此分配注意力;而在时空独立数据集上,两个维度几乎没有相互分配注意力权重。这表明 DSTPP 可以自适应地学习时间和空间之间的各种相互作用机制。
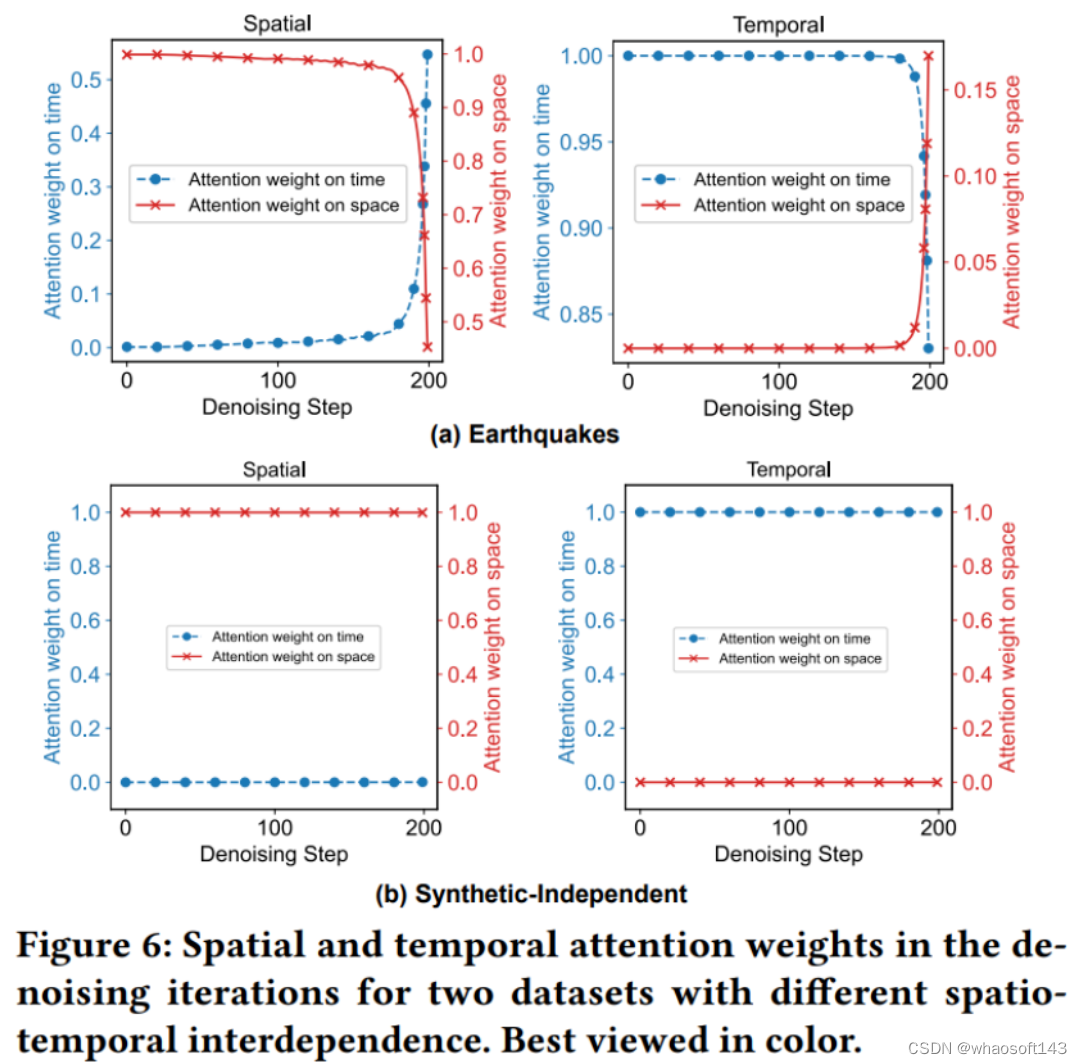
时空注意力权重变化
...
#机器学习~回归
搬来的基础贴哦
7种回归技术,这里帮助我们对回归方法的广度有所了解,以及如何在不同的数据条件下选择合适的回归技术,而不是将线性和逻辑回归应用于遇到的每个机器学习问题。
机器学习者对线性回归和逻辑回归这两种分析方法一定不陌生,可以说它们是最重要的回归分析技术,但千万不要认为回归分析仅限于这两种方法。事实上,有无数种形式的回归,每种形式都有其自身的重要性和最适合应用的特定条件。在本文中,我们将简单地介绍7种最常用的回归类型,一起来看看吧~
什么是回归分析?
回归分析是一种预测建模技术,它研究的是因变量(目标)和自变量(预测因子)之间的关系。通常将这种技术用于预测分析、时间序列建模以及发现变量间的因果关系。例如,我们要研究司机的鲁莽驾驶和其交通事故数量之间的关系,最好的方法就是回归分析。
回归分析是建模和分析数据的重要工具。其核心思想是,通过将曲线或直线拟合到数据点,以使各数据点到曲线或直线的距离差最小化。太抽象?没关系,我们将在下文中详细解释这一点。
为什么要使用回归分析?
如前所述,回归分析通常用于估计两个或多个变量间的关系。举一个简单的例子,假设你要根据当前的经济状况估算一家公司的销售额增长情况,你手中的公司最新数据显示,销售额增长约为经济增长的2.5倍,那么,使用回归分析,我们就可以根据当前和过去的数据预测公司未来的销售情况。
使用回归分析主要有以下优点:
① 它可以表明自变量和因变量之间的显著关系
② 它可以表明多个自变量对一个因变量的不同影响强度
③ 回归分析还允许我们去比较用不同尺度衡量的变量之间的相互影响,如价格变化与促销活动数量之间的联系
这些优点都有助于我们排除无关变量,并评估出一组用于构建预测模型的最佳变量。
七种常见的回归模型
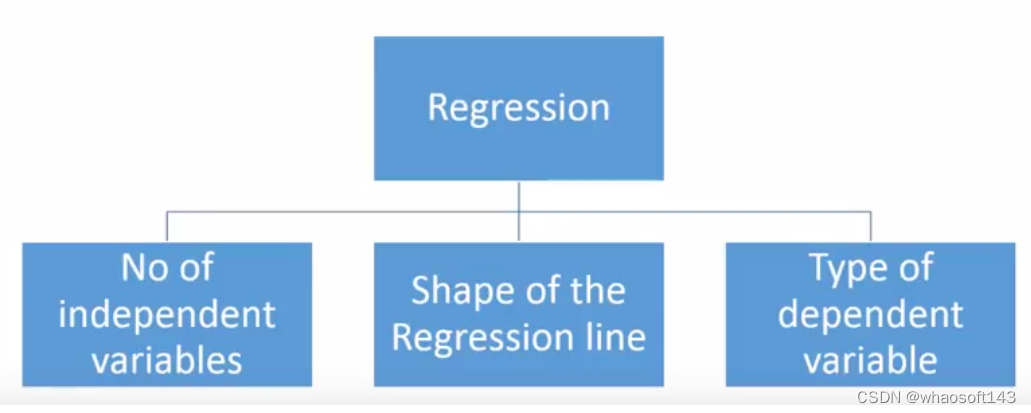
有各种各样的回归技术可用于进行预测分析,这些技术主要从自变量个数、因变量类型、回归线形状这三个方面度量。
使用这些参数的组合,我们甚至可以创造出一个从未被使用过的回归模型。但现在,让我们先来了解一下最常见的回归方法吧~
1. 线性回归(Linear Regression)
线性回归通常是人们在学习预测建模时首选的技术之一。它的因变量是连续的,自变量可以是连续的也可以是离散的,并且回归线是线性的。
线性回归使用最佳拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。它由方程式Y=a+b*X+e表示,其中a表示截距,b表示直线的斜率,e是误差项。这个方程可用于根据给定的预测变量来预测目标变量的值。
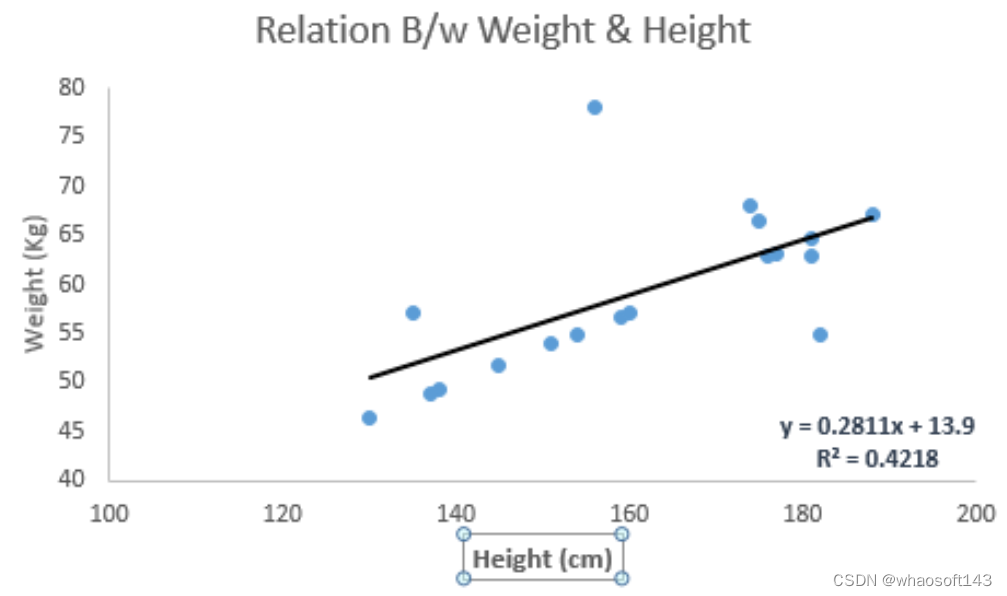
一元线性回归和多元线性回归的区别在于,多元线性回归有(>1)个自变量,而一元线性回归通常只有1个自变量。
那么,我们如何得到一个最佳的拟合线呢?使用最小二乘法可以轻松完成。最小二乘法也是用于拟合回归线最常用的方法。它通过最小化每个数据点到线的垂直偏差的平方和来计算观测数据的最佳拟合线。由于偏差先平方再相加,所以正值和负值之间不会抵消。
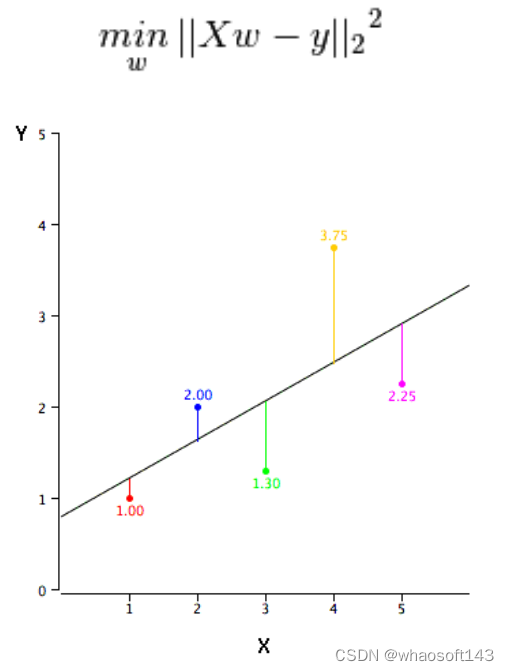
我们可以使用R-square指标来评估模型性能。在使用线性回归时,我们需要注意:
① 自变量和因变量之间必须要有线性关系
② 多元线性回归存在多重共线性,自相关性和异方差性
③ 线性回归对异常值非常敏感,它会严重影响回归线,并最终影响预测值
④ 多重共线性会增加系数估计值的方差,并使得估计对模型的轻微变化也非常敏感,从而导致系数估计值不稳定
⑤ 在有多个自变量的情况下,我们可以使用向前选择法,向后剔除法和逐步筛选法来选择最重要的自变量
2. 逻辑回归(Logistic Regression)
逻辑回归用于计算“事件=Success”和“事件=Failure”的概率。当因变量是二元变量(1/0,真/假,是/否)时,我们应该使用逻辑回归。其中,Y的取值范围是0到1,可以用以下等式表示:
odds=p/(1-p)=事件发生的概率/事件不发生的概率
ln(odds) = ln(p/(1-p))
logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk
在上式中,p表示具有某个特征的概率。你可能会问,为什么要在公式中使用对数log呢?因为在这里我们对因变量使用的是二项分布,就需要选择一个对这个分布来说最佳的连结函数——Logit函数。在上述方程中,通过观测样本的极大似然估计值来选择参数,而不是最小化平方误差的总和(在普通回归中使用的)。
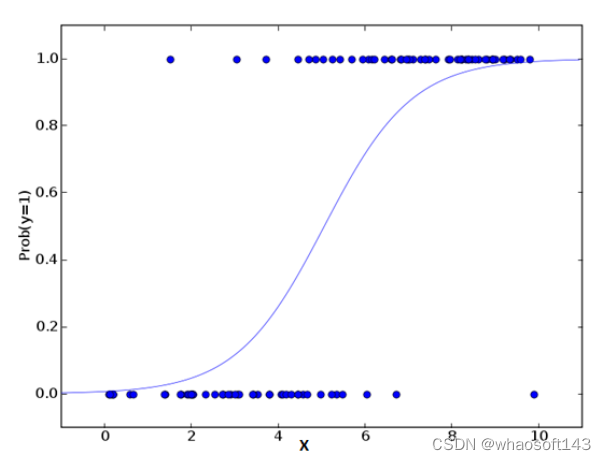
划重点:
① 逻辑回归被广泛用于分类问题
② 逻辑回归不要求自变量和因变量间具有线性关系,它甚至可以处理各种类型的关系,因为它对预测的相对风险指数OR使用了一个非线性的log转换
③ 为了避免过拟合和欠拟合,我们应该使用所有重要的变量。确保这一点的一个很好的方法是,使用逐步筛选来估计逻辑回归
④ 逻辑回归需要很大的样本量,因为在样本数量较少的情况下,极大似然估计的效果还不如普通的最小二乘法
⑤ 使用的自变量不应该是相互关联的,即不具有多重共线性。然而,在分析和建模时,我们可以选择包含分类变量相互作用的影响
⑥ 如果因变量的值是序数,则称它为序逻辑回归
⑦ 如果因变量是多类的,则称它为多元逻辑回归
3. 多项式回归(Polynomial Regression)
如果一个回归方程的自变量的指数大于1,那么它就是多项式回归方程。可表示为:
y = a + b * x ^ 2
在这种回归技术中,最佳拟合线不是直线,而是一条用于拟合数据点的曲线(如下图所示)
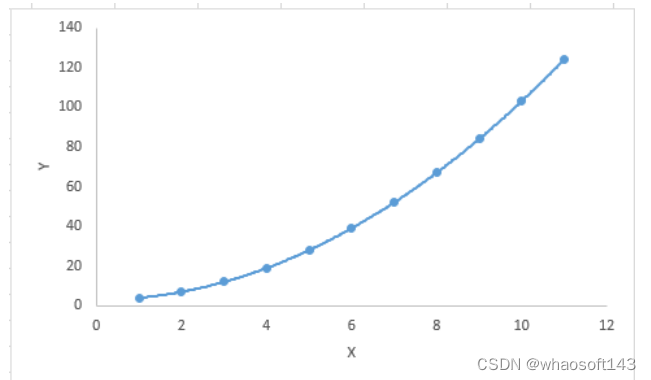
划重点:
虽然可以尝试拟合一个更高阶的多项式以获得较低的误差,但这可能会导致过拟合。你需要经常画出关系图来查看拟合情况,并确保既没有过拟合又没有欠拟合。下面是一个图例,可以帮助理解:
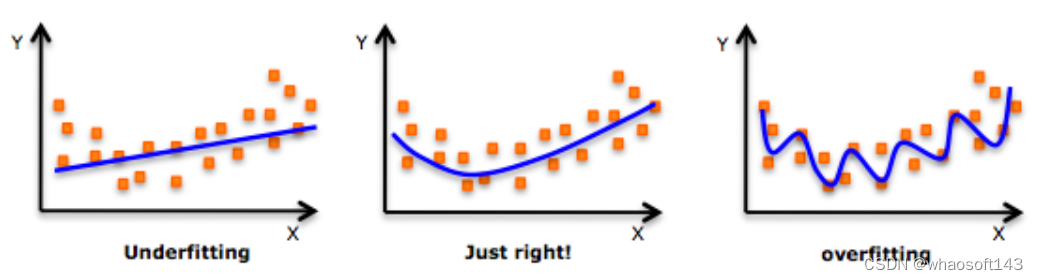
尤其要注意向两端寻找曲线点,看看这些形状和趋势是否有意义,高阶多项式最终可能会产生奇怪的结果。
4.逐步回归(Stepwise Regression)
当要处理多个自变量时,我们可以使用这种形式的回归。在这种技术中,自变量的选择是在一个自动的过程中完成的,该过程无需人工干预。具体实现是通过观察R-square,t-stats和AIC指标等统计值来识别重要变量。
逐步回归可以通过基于指定条件一次添加或删除一个协变量来拟合回归模型。下面是一些最常用的逐步回归方法:
① 标准逐步回归,根据每个步骤的需要添加和删除预测变量
② 向前选择法,从模型中最重要的预测变量开始,然后在每一步中添加变量
③ 向后剔除法,从模型中的所有预测变量开始,然后在每一步中去除最低有效变量
逐步回归建模技术的目的是,使用最少的预测变量来最大化预测能力。这也是处理高维数据集的方法之一。
5.岭回归(Ridge Regression)
岭回归分析用于当数据存在多重共线性(自变量高度相关)时。在多重共线的情况下,即使最小二乘法(OLS)对每个变量是无偏的,它们的方差也很大,这使得观测值偏离了真实值。岭回归通过在回归估计中增加一个偏差度,来降低标准误差。
你还记得我们在上面提到的线性回归方程吗?它可以表示为:
y = a + b * x
添加误差项后,等式变为:
y = a + b * x + e
当有多个自变量时可写为:
y = a + b1x1 + b2x2 + .... + e
其中,e是误差项,即校正观测值和预测值间的误差所需的值
在线性方程中,预测误差可以分解为两部分:偏差和方差。它们中的一个或两个都可能会导致预测错误。在这里,我们将讨论由方差引起的误差。
岭回归通过收缩参数λ解决多重共线性问题。看下面的公式
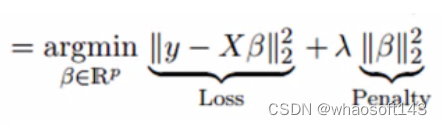
这个公式有两个组成部分,第一个是最小二乘项,第二个是相关系数β平方和的λ倍,把它添加到最小二乘项以缩小参数,从而得到一个非常低的方差。
划重点:
① 除常数项外,岭回归的假设与最小二乘回归类似;
② 岭回归缩小了相关系数的值,但不会达到零,这表明它没有特征选择功能
③ 这是一个正则化方法,并且使用的是L2正则化。
6. 套索回归(Lasso Regression)
类似于岭回归,“套索”(Lasso,最小绝对收缩和选择算子)也会惩罚回归系数的绝对值大小。此外,它能够减少变化程度并提高线性回归模型的精度。看看下面的公式:
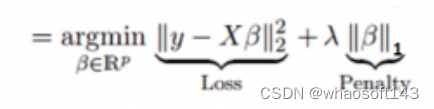
套索回归与岭回归的区别之处在于,它使用的惩罚函数是绝对值而不是平方。这导致惩罚值(或等于约束估计的绝对值之和)使一些参数估计结果等于零。使用的惩罚值越大,进一步估计会使得缩小值趋近于零。这将导致我们要从给定的n个变量中选择变量。
划重点:
① 除常数项以外,这种回归的假设与最小二乘回归类似
② 套索回归将系数缩小至接近零(等于零),将有助于特征选择
③ 这是一个正则化方法,使用的是L1正则化;
④ 如果一组预测变量是高度相关的,套索回归会选出其中一个并将其它变量收缩为零
7. ElasticNet回归
ElasticNet回归是套索回归和岭回归的结合,它使用L1和L2正则化器进行训练。当有多个相互关联的特征时,ElasticNet回归是很有用的,套索回归会随机挑选这些特征中的一个,而ElasticNet回归会都选
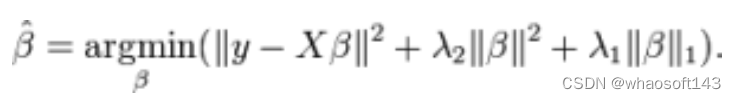
在套索回归和岭回归之间进行折中的一个优点是,它允许ElasticNet回归继承循环状态下岭回归的某些稳定性。
划重点:
① 在变量高度相关的情况下,它会产生群体效应
② 选择变量的数目没有限制
③ 它可以承受双重收缩
除了这7种最常用的回归方法,还有一些其他的回归模型,如Bayesian、Ecological和Robust回归。
如何选择正确的回归模型?
此前,你可能会有这样的结论:如果结果是连续的,就使用线性回归;如果是二元的,就使用逻辑回归。然而,在了解了另外5种回归方法后,在回归建模时你可能会有“选择困难症“。
别担心!还记得我们在前面提到的吗?在多种类型的回归模型中,我们需要根据自变量和因变量的类型、数据的维数以及数据的其它基本特征,来选择最合适的方法。以下列出了一些在选择时需考虑的关键因素:
① 数据探索是预测建模必不可少的一部分。在选择合适的模型之前,比如确定变量的关系和影响时,它应该是你进行的第一步
② 我们可以通过分析不同指标参数,如R-square、调整后的 R-square、AIC、BIC以及误差项等,来比较不同模型的拟合程度。另外也可以使用Mallows’ Cp准则,通过将模型与所有可能的子模型进行对比,检查在你的模型中可能出现的偏差
③ 交叉验证是评估预测模型的最佳方法。将数据集分成训练集和验证集,使用观测值和预测值之间的一个简单均方差可以衡量你的模型的预测精度
④ 如果数据集中有多个混合变量,那么就不应该使用自动模型选择方法,毕竟你应该不想同时把所有变量放在一个模型中
⑤ 取决于你的目的,与具有高度统计学意义的模型相比,功能较弱的模型更易于实现
⑥ 在高维数据集,以及数据集变量间有多重共线性的情况下,回归正则化方法(套索回归、岭回归和ElasticNet回归)效果很好
...
#LayerNorm
手推公式之“层归一化(LayerNorm)”梯度
昨天推导了一下交叉熵的反向传播梯度,今天再来推导一下层归一化(LayerNorm),这是一种常见的归一化方法。
前向传播

反向传播

推导过程


均值和标准差的梯度

这次内容较少就是一些图哦~~
...
#SGLang DP MLA 特性解读
本文详细解读了SGLang v0.4版本中针对DeepSeek模型引入的MLA Data Parallelism Attention优化。该优化通过数据并行(DP)方式共享KV Head,避免了在每个TP Worker中重复计算KV Head,从而减少了KV缓存的冗余和内存占用,提高了推理吞吐量,并支持更大的批量大小。
课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda
这里简要解析了一下SGLang v0.4版本中针对DeepSeek模型引入的MLA Data Parallelism Attention优化。这个优化可以通过Data Parallelism的方式共享KV Head来避免在每个TP Worker中都重复计算KV Head,这对于DeepSeek 系列模型来说非常有用,因为它的MLA KV Head无法使用TP的方式正常切分多个GPU中,所以只能在不同RANK上复制,但是因为启用了TP就会导致KV Cache的占用比MLA Data Parallelism Attention高TP倍,因为要计算TP次。大家如果对多节点的MLA Data Parallelism Attention实现感兴趣可以看 https://github.com/sgl-project/sglang/pull/2925 。
前言
SGLang 在 v0.4 版本中针对 DeepSeek V2/V3/R1 引入了一个 Data Parallelism Attention 优化,这里尝试解读一下。原始的介绍见:https://lmsys.org/blog/2024-12-04-sglang-v0-4/#data-parallelism-attention-for-deepseek-models ,翻译一下这里的描述:
我们最常用的并行策略是张量并行。但是,对于某些模型,这可能不是最有效的策略。例如,DeepSeek 模型使用 MLA 机制,只有一个 KV 头。如果我们在 8 个 GPU 上使用张量并行,它将导致 KV 缓存的冗余和不必要的内存使用。
为了克服这个问题,我们为 DeepSeek 模型实现了数据并行 (DP) 的多头潜在注意 (MLA) 机制,以提高推理的吞吐量。通过对注意力组件采用 DP,我们可以大大减少 KV 缓存,从而允许使用更大的批量大小。在我们的 DP 注意力实现中,每个 DP worker都独立处理不同类型的批处理 (prefill、decode、idle),然后将注意力处理后的数据在所有worker之间 all-gather,以便在 Mixture-of-Experts (MoE) 层中使用。最后,在 MoE 层中处理完毕后,数据将被重新分配回每个worker。下图展示了这个想法。

如果你看这个描述还没有理解到或者不太清楚怎么实现,你可以继续阅读本文的剩下部分。MLA Data Parallelism Attention 在单节点上的的核心实现由 https://github.com/sgl-project/sglang/pull/1970 这个PR完成,我下面就以高到低的视角来理解下这个feature对应的工程实现。
1. 模型实现上的改动
我这里把SGLang DeepSeek 的模型实现精简了一下,只留下和使用MLA DP Attention相关的逻辑,这样可以快速看出MLA DP Attention相比于普通的张量并行模式的核心改动。
class DeepseekV2AttentionMLA(nn.Module):
"""DeepSeek V2模型的多头注意力层,支持MLA(Memory-Latency-Aware)优化和数据并行。
该模块实现了两种并行策略:
1. Data Parallel (DP): 使用ReplicatedLinear层,每个设备都有完整的参数副本
2. Tensor Parallel (TP): 使用ColumnParallelLinear和RowParallelLinear层,在设备间分片参数
"""
def __init__(
self,
config: PretrainedConfig,
hidden_size: int, # 隐藏层维度
num_heads: int, # 注意力头数量
qk_nope_head_dim: int, # 不使用旋转位置编码的Q/K头维度
qk_rope_head_dim: int, # 使用旋转位置编码的Q/K头维度
v_head_dim: int, # V头维度
q_lora_rank: int, # Q矩阵的LoRA秩
kv_lora_rank: int, # KV矩阵的LoRA秩
rope_theta: float = 10000, # RoPE位置编码的theta参数
rope_scaling: Optional[Dict[str, Any]] = None, # RoPE缩放配置
max_position_embeddings: int = 8192, # 最大位置编码长度
quant_config: Optional[QuantizationConfig] = None, # 量化配置
layer_id=None, # 层ID
use_dp=False, # 是否使用数据并行
) -> None:
super().__init__()
self.layer_id = layer_id
self.hidden_size = hidden_size
self.qk_nope_head_dim = qk_nope_head_dim
self.qk_rope_head_dim = qk_rope_head_dim
self.qk_head_dim = qk_nope_head_dim + qk_rope_head_dim
self.v_head_dim = v_head_dim
self.q_lora_rank = q_lora_rank
self.kv_lora_rank = kv_lora_rank
self.num_heads = num_heads
# 获取张量并行的世界大小
tp_size = get_tensor_model_parallel_world_size()
assert num_heads % tp_size == 0
# 如果使用DP,则每个设备使用所有头;否则在设备间分片
self.num_local_heads = num_heads if use_dp else num_heads // tp_size
if use_dp:
# 数据并行模式:使用ReplicatedLinear,每个设备都有完整的参数副本
if self.q_lora_rank is not None:
# 使用LoRA时的Q投影
self.q_a_proj = ReplicatedLinear(
self.hidden_size,
self.q_lora_rank,
bias=False,
quant_cnotallow=quant_config,
)
self.q_a_layernorm = RMSNorm(self.q_lora_rank, eps=config.rms_norm_eps)
self.q_b_proj = ReplicatedLinear(
q_lora_rank,
self.num_heads * self.qk_head_dim,
bias=False,
quant_cnotallow=quant_config,
)
else:
# 不使用LoRA时的Q投影
self.q_proj = ReplicatedLinear(
self.hidden_size,
self.num_heads * self.qk_head_dim,
bias=False,
quant_cnotallow=quant_config,
)
# KV和输出投影
self.kv_b_proj = ReplicatedLinear(
self.kv_lora_rank,
self.num_heads * (self.qk_nope_head_dim + self.v_head_dim),
bias=False,
quant_cnotallow=quant_config,
)
self.o_proj = ReplicatedLinear(
self.num_heads * self.v_head_dim,
self.hidden_size,
bias=False,
quant_cnotallow=quant_config,
)
else:
# 张量并行模式:使用ColumnParallelLinear和RowParallelLinear在设备间分片参数
if self.q_lora_rank is not None:
self.q_a_proj = ReplicatedLinear(
self.hidden_size,
self.q_lora_rank,
bias=False,
quant_cnotallow=quant_config,
)
self.q_a_layernorm = RMSNorm(self.q_lora_rank, eps=config.rms_norm_eps)
self.q_b_proj = ColumnParallelLinear(
q_lora_rank,
self.num_heads * self.qk_head_dim,
bias=False,
quant_cnotallow=quant_config,
)
else:
self.q_proj = ColumnParallelLinear(
self.hidden_size,
self.num_heads * self.qk_head_dim,
bias=False,
quant_cnotallow=quant_config,
)
self.kv_b_proj = ColumnParallelLinear(
self.kv_lora_rank,
self.num_heads * (self.qk_nope_head_dim + self.v_head_dim),
bias=False,
quant_cnotallow=quant_config,
)
self.o_proj = RowParallelLinear(
self.num_heads * self.v_head_dim,
self.hidden_size,
bias=False,
quant_cnotallow=quant_config,
)
def all_gather(
input_tensor: torch.Tensor, forward_batch: ForwardBatch, rank, world_size, group
):
"""在数据并行模式下收集并同步各个设备上的张量。
Args:
input_tensor: 输入张量
forward_batch: 前向计算批次信息
rank: 当前设备的rank
world_size: 并行设备总数
group: 通信组
Returns:
tuple: (gathered_tensors, start_index, end_index)
- gathered_tensors: 收集到的所有设备的张量
- start_index: 当前设备数据的起始索引
- end_index: 当前设备数据的结束索引
"""
if world_size == 1:
return input_tensor
# 获取每个设备的token数量
all_lens = forward_batch.global_num_tokens
max_len = max(forward_batch.global_num_tokens)
# 对输入张量进行填充,使其长度达到max_len
padded_tensor = torch.nn.functional.pad(
input_tensor, (0, 0, 0, max_len - input_tensor.shape[0])
)
# 使用all_gather收集所有设备的张量
torch.distributed.all_gather_into_tensor(
forward_batch.gathered_buffer, padded_tensor, group=group
)
# 将收集到的张量按实际长度拼接
gathered_tensors = torch.concat(
[
forward_batch.gathered_buffer[i * max_len : i * max_len + all_lens[i]]
for i in range(world_size)
]
)
# 计算当前设备数据的起始和结束索引
start_index = 0 if rank == 0 else sum(all_lens[:rank])
end_index = start_index + all_lens[rank]
return gathered_tensors, start_index, end_index
class DeepseekV2DecoderLayer(nn.Module):
"""DeepSeek V2模型的解码器层,支持数据并行注意力机制。"""
def __init__(
self,
config: PretrainedConfig,
layer_id: int,
quant_config: Optional[QuantizationConfig] = None,
) -> None:
super().__init__()
self.hidden_size = config.hidden_size
# 根据配置决定是否启用数据并行注意力
self.enable_dp_attention = (
not global_server_args_dict["disable_mla"]
and global_server_args_dict["enable_dp_attention"]
)
if self.enable_dp_attention:
# 初始化数据并行相关的参数
self.tp_rank = get_tensor_model_parallel_rank()
self.tp_size = get_tensor_model_parallel_world_size()
self.tp_group = get_tp_group().device_group
def forward(
self,
positions: torch.Tensor,
hidden_states: torch.Tensor,
forward_batch: ForwardBatch,
residual: Optional[torch.Tensor],
) -> torch.Tensor:
# 数据并行模式下的前向计算
if self.enable_dp_attention:
# 收集所有设备的隐藏状态
hidden_states, start_idx, end_idx = all_gather(
hidden_states, forward_batch, self.tp_rank, self.tp_size, self.tp_group
)
# 执行Fused MoE MLP计算
hidden_states = self.mlp(hidden_states)
# 提取当前设备对应的部分
hidden_states = hidden_states[start_idx:end_idx]
return hidden_states, residual
class DeepseekV2ForCausalLM(nn.Module):
"""DeepSeek V2因果语言模型,支持数据并行和张量并行两种模式。"""
def __init__(
self,
config: PretrainedConfig,
quant_config: Optional[QuantizationConfig] = None,
) -> None:
super().__init__()
self.config = config
self.quant_config = quant_config
self.model = DeepseekV2Model(config, quant_config)
if global_server_args_dict["enable_dp_attention"]:
# 数据并行模式:使用ReplicatedLinear作为语言模型头
self.lm_head = ReplicatedLinear(
config.hidden_size,
config.vocab_size,
bias=False,
)
# 跳过all_gather操作的LogitsProcessor
self.logits_processor = LogitsProcessor(config, skip_all_gather=True)
else:
# 张量并行模式:使用ParallelLMHead
self.lm_head = ParallelLMHead(
config.vocab_size, config.hidden_size, quant_cnotallow=quant_config
)
self.logits_processor = LogitsProcessor(config)从这个模型实现代码可以看到SGLang中针对DeepSeek模型的Data Parallelism Attention优化主要解决了模型在使用MLA Attention时KV缓存冗余的问题。该优化通过将传统的张量并行(TP)改为数据并行(DP)的方式来实现:在DeepseekV2AttentionMLA类中支持使用ReplicatedLinear层进行完整参数复制的DP模式和使用ColumnParallelLinear/RowParallelLinear层进行参数分片的TP模式;通过all_gather函数实现DP worker间的数据同步,使得每个worker可以独立处理不同类型的批处理,然后在MoE层处理完后重新分配数据。这种并行策略的改变不仅减少了KV缓存的内存占用,还支持了更大的批处理大小,从而提高了模型的推理吞吐量。
在上面的all_gather实现中,我们发现forward_batch(ForwardBatch类型)维护了global_num_tokens和gathered_buffer两个成员变量来辅助我们在Fused MoE Layer之前做allgather以及计算完Fused MoE之后再Split。
接下来就关注一下和Data Parallelism Attention优化相关的更底层的改动,包括managers 和 model_executor 两大方面。实际上涉及到的改动包括SGLang的TPModelWorker(https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/managers/tp_worker.py) 和 ModelRunner(https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/model_executor/model_runner.py) 两个部分,当然还有负责TpModelWorker调度相关的Scheduler部分也做了对应修改,但改的东西其实不多,下面分点看一下。
对SGLang组件没有了解的读者可以阅读一下这个仓库SGLang相关的优秀材料:https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/tree/main/sglang/sglang-worker ,会对理解组件之间的关系以及定位自己想看的功能的位置有帮助。
2. model_executor 的改动
python/sglang/srt/model_executor/forward_batch_info.py 的改动
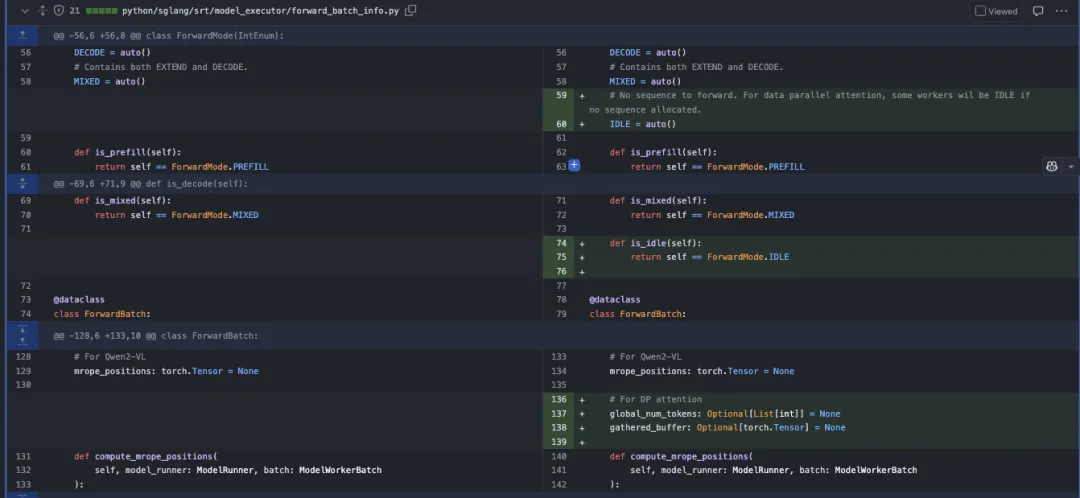

首先,这里在ForwardMode类新增了一个新的模式IDLE,用于数据并行注意力机制。注释说明当某些worker没有序列做forward时,worker将处于IDLE状态(可以看文章开头那个图)。
接着,在ForwardBatch中增加了数据并行注意力相关的成员变量:
- global_num_tokens: 类型为Optional[List[int]],初始值为None
- gathered_buffer: 类型为Optional[torch.Tensor],初始值为None
最后,是对于compute_erope_positions方法的改动:当global_num_tokens不为None时,计算最大长度max_len = max(ret.global_num_tokens);创建一个新的gathered_buffer张量,使用torch.zeros初始化设置张量的属性,包括size、dtype和device等。增加了对forward_mode.is_idle()的判断,如果是IDLE模式则直接返回ret。
python/sglang/srt/model_executor/model_runner.py 的改动

这里只是增加了对idel模式的判断。
3. managers 的改动
这里主要改动的地方就是scheduler相关和data_parallel_controller,分别浏览一下。
python/sglang/srt/managers/data_parallel_controller.py 的改动
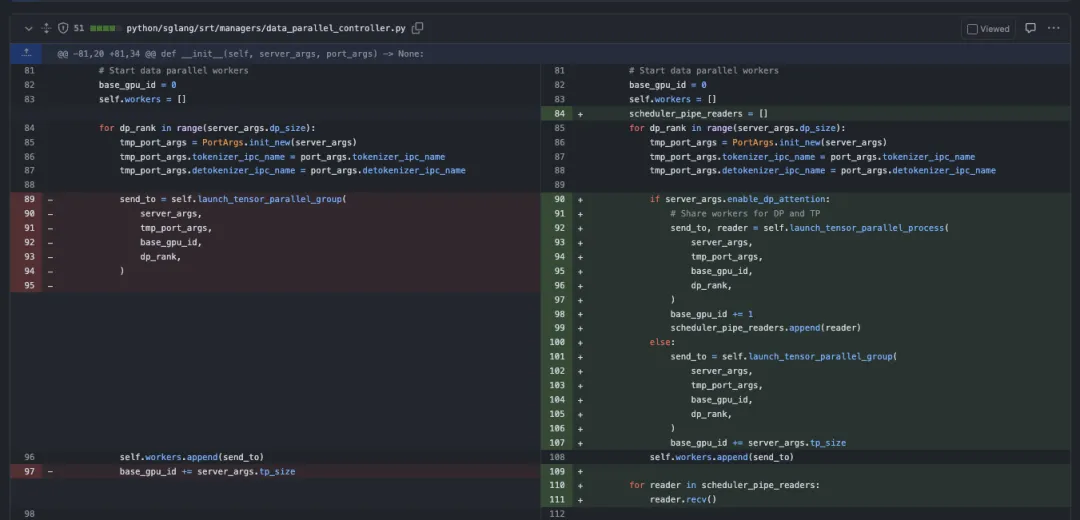
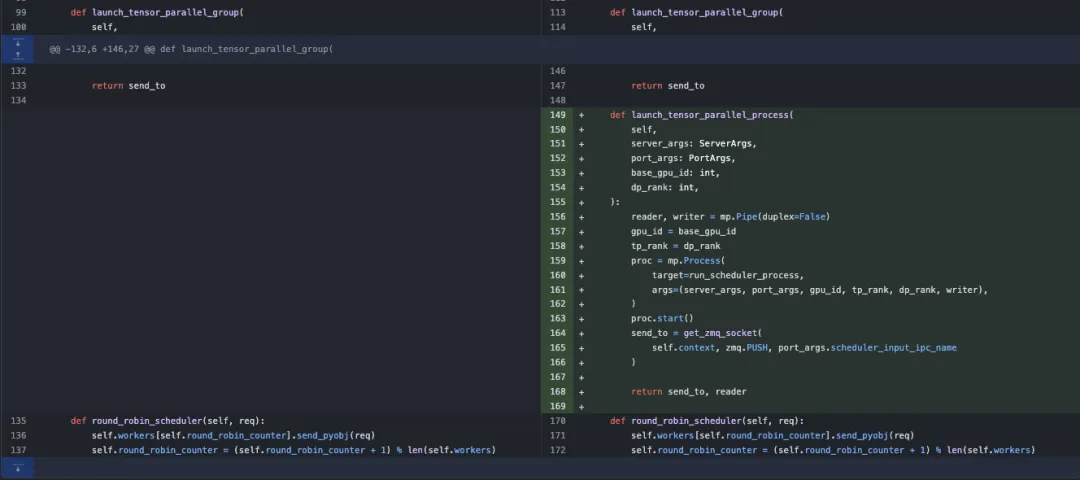
从修改的流程来看,首先最外面的循环为每个数据并行(DP)等级创建一个专门的进程,这些进程同时处理数据并行和张量并行的计算。然后,每个进程被分配一个唯一的GPU(通过base_gpu_id递增实现)确保不同的数据并行rank使用不同的GPU资源。在通信上,使用mp.Pipe建立进程间的通信管道,并使用ZMQ套接字进行消息传递,最后所有reader都被收集到scheduler_pipe_readers列表中,用于后续的通信。
python/sglang/srt/managers/scheduler.py 的改动



这里需要关注的是新增的prepare_dp_attn_batch函数,它用来对每个DP worker的local_num_tokens进行allgather通信获得global_num_tokens,最后这个信息将用于我们在第一节提到在Fused MoE层之后把数据重新split开。
def prepare_dp_attn_batch(self, local_batch: ScheduleBatch):
# Check if other DP workers have running batches
if local_batch is None:
num_tokens = 0
elif local_batch.forward_mode.is_decode():
num_tokens = local_batch.batch_size()
else:
num_tokens = local_batch.extend_num_tokens
local_num_tokens = torch.tensor(
num_tokens, dtype=torch.int64, device=self.device
)
global_num_tokens = torch.empty(
self.tp_size, dtype=torch.int64, device=self.device
)
torch.distributed.all_gather_into_tensor(
global_num_tokens,
local_num_tokens,
group=self.tp_worker.get_tp_device_group(),
)
if local_batch is None and global_num_tokens.max().item() > 0:
local_batch = self.get_idle_batch()
if local_batch is not None:
local_batch.global_num_tokens = global_num_tokens.tolist()
return local_batch4. 扩展
上面介绍的是单节点的原理和实现,如果要将这个Feature扩展到多个节点实现会比较复杂,x-AI的contributor在 https://github.com/sgl-project/sglang/pull/2925 实现了DP Attention的多节点扩展,目前在DeepSeek V3/R1等模型的多节点部署中都可以顺利开启这个优化。感兴趣的读者可以自行阅读和研究多节点实现这部分。
5. 总结
这里简要解析了一下SGLang v0.4版本中针对DeepSeek模型引入的MLA Data Parallelism Attention优化。这个优化可以通过Data Parallelism的方式共享KV Head来避免在每个TP Worker中都重复计算KV Head,这对于DeepSeek 系列模型来说非常有用,因为它的MLA KV Head无法使用TP的方式正常切分多个GPU中,所以只能在不同RANK上复制,但是因为启用了TP就会导致KV Cache的占用比MLA Data Parallelism Attention高TP倍,因为要计算TP次。大家如果对多节点的MLA Data Parallelism Attention实现感兴趣可以看 https://github.com/sgl-project/sglang/pull/2925 。
...
#微调篇「数据集构建」
本文详细介绍了从明确目标到数据收集、标注、清洗、增强和划分的完整流程,并以构建医学文本数据集为例,展示了如何利用开源数据和工具完成高质量数据集的构建。
这次是「数据集构建」保姆级教程第一篇,会持续更新。
一、开源数据网站下载
Kaggle: https://www.kaggle.com/
ModelScope: https://modelscope.cn/datasets
hugging face:https://huggingface.co
百度飞桨:https://aistudio.baidu.com/datasetoverview
二、构建数据集(大致步骤说明)
1. 明确目标
- 定义问题: 确定你要解决的问题或任务。(比如,你需要构建医疗领域的数据集,那么你应该搜索相关医疗的资料~有的时候问题不是很明确,这个时候就需要实际探究本质上你需要什么。)
- 确定数据类型: 明确需要的数据类型(文本、图像、音频等)。
(ps:强调!!!以及非常需要关注构建的数据集是否符合你要后训练模型的数据格式~)
2. 数据收集(这一步就是收集所有你能收集到的相关的数据)
- 内部数据:从现有数据库、日志等获取数据。【如果有条件】
- 外部数据:通过公开数据集、相关网站配合ai抽取等方式获取。
- 数据生成:如有必要,可通过模拟或合成数据。【非必须】
3. 数据标注
- 手动标注:人工标注数据。
- 自动标注:使用工具或预训练模型进行标注。
4. 数据清洗
- 处理缺失值:填充或删除缺失数据。
- 去重:删除重复数据。
- 格式统一:确保数据格式一致。
- 异常值处理:识别并处理异常值。
大批量数据处理步骤
第一步:依托传统大数据平台(如 Hive、HBase、Flink、MySQL 等),对数据进行初步清洗,剔除明显错误或异常的数据。 第二步:借助人工智能技术,对数据中的错别字、语法错误、逻辑问题等进行智能修复,并结合标准数据集进行校准,提升数据质量与准确性。 第三步:开展人工终审,通过随机抽查的方式,对经过前两级处理的数据进行最终审核,确保数据的完整性和可靠性。
5. 数据增强【非必须,具体看情况调节】
- 图像:旋转、裁剪等。
(1)旋转
细节: 旋转角度通常在一定范围内随机选择,如±30°或±45°,以模拟不同视角的图像。
操作步骤: 使用图像处理库(如OpenCV或Albumentations)对图像进行旋转操作。如果图像有标注框(如目标检测任务),标注框也需要同步旋转。
import albumentations as A
transform = A.RandomRotate90(p=0.5) # 随机旋转90度
augmented_image = transform(image=image)['image'](2)裁剪
细节:随机裁剪图像的一部分,裁剪区域可以是固定大小或随机大小。裁剪时需要注意保留关键信息。
操作步骤:使用随机裁剪函数,如Albumentations的RandomCrop。
transform = A.RandomCrop(width=400, height=400, p=0.3)
augmented_image = transform(image=image)['image'](3)其他增强
亮度调整:通过调整图像的亮度来模拟不同光照条件。
噪声添加:向图像添加随机噪声,增强模型的鲁棒性。
transform = A.Compose([
A.RandomBrightnessContrast(p=0.3),
A.GaussianBlur(blur_limit=3, p=0.2)
])
augmented_image = transform(image=image)['image']- 文本:同义词替换、回译等。(即增加噪声数据)
(1)同义词替换
细节:在句子中随机选择一些词语,用它们的同义词替换。注意替换后的句子语义应保持一致。
操作步骤:使用词典或词嵌入模型(如Word2Vec)找到同义词并替换
(2)回译(就是英翻中,中翻英,意......无限套娃中ing)
细节:将文本翻译成一种语言,再翻译回原语言,可能会引入一些语义变化。
操作步骤:使用机器翻译API(如Google Translate)进行翻译。
- 音频:变速、加噪声等。
(1)变速
细节:调整音频的播放速度,但保持音调不变。
操作步骤:使用音频处理库(如librosa)对音频进行变速处理。
(2)加噪声
细节:向音频中添加背景噪声,增强模型对噪声的鲁棒性。
操作步骤:从噪声库中选择噪声并叠加到音频上。
为什么添加噪声?(补充内容)
在数据集中添加噪声的主要目的是增强模型的鲁棒性。具体原因包括:
- 模拟真实场景:真实世界中的图像通常包含噪声(如传感器噪声、压缩噪声等)。通过在训练数据中添加噪声,模型能够更好地适应实际应用中的噪声环境。
- 防止过拟合:噪声可以作为一种正则化手段,防止模型过度依赖训练数据中的特定特征,从而提高泛化能力。
- 数据增强:噪声添加是数据增强的一种方式,能够增加数据的多样性,帮助模型学习更广泛的特征。
判断是否需要增加噪声
不需要添加噪声数据集的情况
- 数据质量高且任务明确:如果原始数据集已经足够丰富、多样且高质量,能够很好地覆盖模型需要学习的模式和特征,那么通常不需要额外添加噪声数据。
- 模型过拟合风险低:当数据集规模较大、数据分布均匀且模型架构相对简单时,模型过拟合的风险较低,此时也不需要通过添加噪声数据来增强模型的泛化能力。
需要添加噪声数据集的情况
- 过拟合问题严重:当模型在训练集上表现优异,但在验证集或测试集上表现显著下降时,说明模型可能过拟合了训练数据中的噪声和特定模式。此时可以通过添加噪声数据来增强模型的鲁棒性。
- 特定任务需求:在一些特定的任务中,如图像生成或语音识别,添加噪声数据可以帮助模型学习到更复杂的模式和特征,从而提升模型在实际应用中的表现。
数据集构建中的注意事项
- 平衡噪声与原始数据:
- 在数据集中,噪声图像应与原始图像保持一定的比例,避免噪声数据过多导致模型过度依赖噪声特征。
2. 多样性:
- 在添加噪声时,确保噪声类型和强度的多样性,以覆盖更多的实际场景。
3. 验证集和测试集:
- 在验证集和测试集中也应包含适量的噪声数据,以评估模型在噪声环境下的表现。
4. 数据增强的组合:
- 噪声添加可以与其他数据增强技术(如旋转、缩放、翻转等)结合使用,进一步提升模型的鲁棒性。
6. 数据划分
- 训练集:用于模型训练。
- 验证集:用于调参和模型选择。
- 测试集:用于最终评估。
三、具体示例(以DeepSeek-R1蒸馏模型为微调模型,构建的医学数据集为例)1.明确目标——医生文本类数据集构建
- 我需要让微调后的模型可以更擅长完成提供诊疗建议,为了增强可行度,它的口吻最好要更像是一位医生
- 确定我要收集的数据类型是文本类,所以我应该搜集更多与医疗相关的文本,最后能找到直接就是模拟医生的文本,在此基础上进行扩展加强!
- DeepSeek-R1蒸馏模型所需要的数据格式是:Question-Complex-CoT-Response。所以之后,在构建数据集的过程中我得注意到,一定要构建Complex-CoT。
2.数据收集
1.判断医学领域应该会有很多之前已经构建过的数据集,所以我先去开源网站modelscope进行寻找~

2.通过优质的开源数据集确认规范,尽可能在后续的构建过程中,倾向于构建类似优质开源数据集的方向。3.各大公开网站的医学资料收集~此处,笔者收集的是中华医学期刊网等等网站上公开的论文与指南【保存链接或者是下载】
3.数据标注
1.(1)利用一些数据标注辅助平台,帮助构建数据集。将抽取的文件,放入平台进行构建基础QA问答对。
(2)将构建的问答对放入大模型AI,让它帮忙补全,Complex_CoT的部分。[问答对也可以是自己简单想的一些问答,根据自己的需求,通过提示词让大模型AI达到我们想要的效果。]

[
{
"Question":"医生,我患有强直性脊柱炎(SpA),还伴有其他疾病,如果用生物制剂治疗,我需要注意些什么?",
"Complex-CoT":"对于伴有合并症的SpA患者,生物制剂的选择需要综合考虑患者的整体健康状况、合并症的种类和严重程度,以及生物制剂的潜在副作用。不同种类的生物制剂作用机制不同,可能对合并症产生不同的影响。因此,需要在专业医生的指导下,谨慎选择适合患者的生物制剂,并密切监测治疗过程中的反应。",
"Response":"针对伴有合并症的SpA患者,选用不同种类的生物制剂应慎重。我们需要综合评估你的整体健康状况,包括合并症的种类和严重程度,同时考虑生物制剂的潜在副作用。不同生物制剂的作用机制不同,可能会对合并症产生不同的影响。因此,在选择生物制剂时,我们会根据你的具体情况,权衡利弊,选择最适合你的治疗方案,并在治疗过程中密切监测你的反应。"
},
{
"Question":"医生,目前对于强直性脊柱炎(SpA)的研究进展如何?",
"Complex-CoT":"尽管目前在强直性脊柱炎(SpA)的研究中已经取得了一些成果,例如对疾病机制的初步了解、新的诊断方法和治疗方法的探索等,但仍然存在许多未解之谜。例如,SpA的发病机制尚未完全明确,部分患者对现有治疗的反应不佳,且疾病的长期预后仍需进一步研究。因此,SpA的研究仍在不断深入中。",
"Response":"尽管目前已有诸多研究成果,但SpA仍存在许多未解之谜。虽然我们在疾病机制、诊断方法和治疗手段上取得了一些进展,但仍然有许多问题需要进一步研究。例如,SpA的发病机制尚未完全明确,部分患者对现有治疗的反应不佳,且疾病的长期预后仍需深入探索。所以,SpA的研究仍在不断进行中,以期为患者提供更好的帮助。"
},
{
"Question":"医生,未来的研究应该如何开展,才能更好地提高强直性脊柱炎(SpA)患者的生活质量呢?",
"Complex-CoT":"未来的研究应该从多个方面入手,以提高SpA患者的生活质量。首先,探索新的生物标志物可以帮助我们更早、更准确地诊断疾病,实现个体化治疗。其次,开发新的药物和治疗方法可以为患者提供更多的选择,提高治疗效果。此外,新技术的应用可以优化治疗策略,减少治疗的副作用。通过这些综合措施,我们有望进一步改善SpA患者的生活质量。",
"Response":"未来的研究应继续探索新的生物标志物、新药物和新技术的应用,以进一步提高诊断的准确性、优化治疗策略,并最终改善SpA患者的生活质量。我们会从多个方面入手,包括寻找更准确的生物标志物来实现早期诊断和个体化治疗,开发更有效的药物和治疗方法,以及利用新技术优化治疗方案,减少副作用。通过这些努力,我们希望能够为SpA患者带来更好的生活质量。"
}
]2.同时也可以利用收集的链接,放入大模型AI让它构建数据集。

[
{
"Question":"医生,我是女性,最近感觉心脏不太舒服,有点胸闷,这是心脏病发作的迹象吗?",
"Complex-CoT":"女性心脏病发作的症状可能与男性不同,往往更不典型。除了胸闷,还可能伴有其他症状如呼吸急促、恶心、出汗等。在临床实践中,对于女性患者出现心脏相关症状,需要综合考虑多种因素,包括病史、体征以及辅助检查结果,以准确判断是否为心脏病发作,并及时采取相应的治疗措施。",
"Response":"女性心脏病发作的症状可能不太典型,除了胸闷,还可能有呼吸急促、恶心、出汗等。我们需要综合你的病史、体征以及辅助检查结果来判断是否为心脏病发作。如果有这些症状,建议尽快就医,我们会根据具体情况采取相应的治疗措施。"
},
{
"Question":"医生,我有哮喘,最近咳嗽得很厉害,是不是病情加重了?",
"Complex-CoT":"咳嗽是哮喘的常见症状之一,但咳嗽的严重程度并不一定直接反映哮喘的整体控制情况。在临床实践中,哮喘的评估需要综合考虑多个方面,包括症状频率、急性发作次数、肺功能检查结果等。对于咳嗽症状明显的患者,需要进一步评估是否存在其他诱因或合并症,并根据具体情况调整治疗方案。",
"Response":"哮喘患者咳嗽加重不一定意味着病情加重。我们需要综合评估你的症状频率、急性发作次数以及肺功能检查结果等。如果咳嗽很厉害,建议进一步检查,看看是否存在其他诱因或合并症,我们会根据具体情况调整治疗方案。"
},
{
"Question":"医生,我已经被诊断为哮喘,但感觉病情控制得不太好,我需要做哪些检查来全面评估我的病情呢?",
"Complex-CoT":"全面评估哮喘病情对于制定有效的治疗方案至关重要。通常需要进行肺功能检查,包括支气管激发试验和支气管舒张试验,以评估气道反应性和可逆性。此外,还需要评估患者的症状控制情况、急性发作频率、生活质量以及是否存在合并症等。通过这些综合评估,可以更准确地判断哮喘的控制水平,并调整治疗方案。",
"Response":"为了全面评估你的哮喘病情,我们需要进行一些检查,比如肺功能检查,包括支气管激发试验和支气管舒张试验,来评估气道反应性和可逆性。同时,我们还会评估你的症状控制情况、急性发作频率、生活质量以及是否存在合并症等。这些综合评估有助于我们更准确地判断病情,调整治疗方案。"
}
]此处数据集构建的时候也需要考虑到所构建的模型是哪家的~比如,通义千问系列的模型更适合找通义千文帮忙构建数据集,会更有利于模型微调训练哦~
4.数据清洗
其实主要是数据格式确认,确保数据格式一致。在这次构建过程中,整体构建数据质量较高。
import json
defvalidate_json_format(json_file_path):
"""
验证JSON文件是否符合指定格式。
参数:
json_file_path (str): JSON文件的路径。
返回:
bool: 如果符合格式返回True,否则返回False。
"""
try:
# 打开并加载JSON文件
withopen(json_file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
# 验证数据是否为列表
ifnotisinstance(data, list):
print("JSON数据必须是一个列表。")
returnFalse
# 验证每个条目
for item in data:
# 检查是否包含所有必需字段
required_fields = ["Question", "Complex-CoT", "Response"]
ifnotall(field in item for field in required_fields):
print(f"缺少字段:{required_fields}")
returnFalse
# 检查字段值是否为字符串
for field in required_fields:
ifnotisinstance(item[field], str):
print(f"字段'{field}'的值必须是字符串。")
returnFalse
print("JSON格式验证通过!")
returnTrue
except json.JSONDecodeError:
print("JSON文件格式错误。")
returnFalse
except FileNotFoundError:
print(f"文件未找到:{json_file_path}")
returnFalse
except Exception as e:
print(f"发生错误:{e}")
returnFalse
if __name__ == "__main__":
# 替换为你的JSON文件路径
json_file_path = "test.json"
validate_json_format(json_file_path)用于判断是否是["Question", "Complex-CoT", "Response"]的形式的json文件~
补充.测试数据集
在寻找优质数据集时,建议先抽取约1000条数据进行初步测试微调,以评估其效果是否符合需求。如果微调后的结果令人满意,再考虑将该数据集作为构建标准数据集的参考依据。
在后续构建自己的额外数据集时,应遵循循序渐进的原则。先构建少量数据并进行微调测试,观察效果。只有在确认效果达到预期后,才继续扩充数据集规模。
最后,将所有收集到的数据集整合在一起。在进行混合微调之前,先用其中的一部分数据进行测试微调。如果效果良好,则可以继续进行微调;若发现问题,则需要缩小数据集范围,仔细筛选可信数据,尽量避免脏数据对微调过程造成不良影响。
四、完结感言
非常感谢Deepseek官网满血版以及kimi在本章的代码修改、资料收集以及文章润色方面提供的宝贵帮助!
这是本系列的第一篇,中间还有很多需要完善的地方,我们非常期待各位小伙伴的宝贵建议和指正,让我们共同进步,一起在AI学习的道路上探索更多乐趣!
...
#RAG篇「数据集构建」
这篇文章是关于如何构建检索增强生成(RAG)模型的向量知识库的保姆级教程,详细介绍了在数据质量、场景匹配、安全合规、文本分块、向量化模型适配、索引结构优化以及问答对构建等方面的注意事项和具体操作方法。
一、构建属于自己的知识库
检索增强生成(Retrieval Augmented Generation),简称 RAG。在构建RAG(Retrieval-Augmented Generation)的向量知识库时,数据的处理方式直接影响系统的性能和可靠性。不能随意塞入未经处理的数据,否则可能导致检索效果差、生成结果不准确甚至安全隐患。
二、构建向量知识库数据集强调事项
构建向量知识库数据集的基本步骤与微调数据(见前篇)基本一致,但有以下注意强调事项。
数据质量直接影响结果(向量知识库数据集严禁噪声与微调不一样!!!)
- 问题:噪声、重复、低质数据会污染知识库,导致检索到无关内容。
- 解决方案:
- 清洗数据:去除HTML标签、特殊符号、乱码等噪声。
- 去重:合并相似内容,避免冗余数据干扰检索。
- 标准化:统一文本格式(如日期、单位)、大小写、标点符号。
- 质量筛选:优先保留权威来源、高可信度的内容。
数据与场景的匹配性
- 问题:知识库与应用场景偏离会导致检索失效。
- 解决方案:
- 场景过滤:仅保留与目标任务相关的数据(例如医疗场景需剔除无关行业内容)。
- 动态更新:定期增量更新数据,避免时效性内容过期。
- 冷启动优化:初期可引入人工标注的高质量种子数据。
安全与合规风险
- 问题:随意导入数据可能泄露敏感信息或引入偏见。
- 解决方案:
- 敏感信息过滤:使用NER识别并脱敏(如身份证号、电话号码)。
- 偏见检测:通过公平性评估工具(如Fairness Indicators)筛查歧视性内容。
- 权限控制:对知识库分级访问,限制敏感数据检索权限。
如果你不是使用Dify开源框架构建向量数据库,而是使用类似faiss向量数据库构建向量数据库还有以下注意事项:
1.文本分块(Chunking)需策略化
- 问题:随意分块可能导致语义不完整,影响向量表示。
- 解决方案:
- 按语义切分:使用句子边界检测、段落分割或基于语义相似度的算法(如BERT句间相似度)。
- 动态调整块大小:根据数据特性调整(例如技术文档适合较长的块,对话数据适合短块)。
- 重叠分块:相邻块保留部分重叠文本,避免关键信息被切分到边缘。
2.向量化模型的适配性
- 问题:直接使用通用模型可能无法捕捉领域语义。
- 解决方案:
- 领域微调:在领域数据上微调模型(如BERT、RoBERTa)以提升向量表征能力。
- 多模态支持:若包含图表、代码等,需选择支持多模态的模型(如CLIP、CodeBERT)。
- 轻量化部署:权衡精度与效率,可选择蒸馏后的模型(如MiniLM)。
3.索引结构与检索效率
- 问题:海量数据未经优化会导致检索延迟。
- 解决方案:
- 分层索引:对高频数据使用HNSW,长尾数据用IVF-PQ(Faiss或Milvus)。
- 元数据过滤:为数据添加标签(如时间、类别),加速粗筛过程。
- 分布式部署:按数据热度分片,结合缓存机制(如Redis)提升响应速度。
补充说明:向量知识库数据集也要是问答对?
将数据整理成问答对(QA Pair)形式是一种优化策略,而非必要步骤。但这种方式在特定场景下能显著提升检索和生成的效果。以下是其核心原因和适用场景的分析:
- 为什么问答对形式能优化RAG?
(1)精准对齐用户查询意图
- 问题:用户输入通常是自然语言问题(如“如何重置密码?”),而知识库若存储的是纯文本段落(如技术文档),检索时可能因语义差异导致匹配失败。
- 问答对的优势:
- 直接以“问题-答案”形式存储知识,检索时相似度计算更聚焦于“问题与问题”的匹配(Question-Question Similarity),而非“问题与段落”的匹配。
- 例如,若知识库中存有QA对 Q: 如何重置密码? → A: 进入设置页面,点击“忘记密码”...,当用户提问“密码忘了怎么办?”时,即使表述不同,向量模型也能捕捉到语义相似性。
(2)降低生成模型的负担
- 问题:若检索到的是长文本段落,生成模型(如GPT)需要从段落中提取关键信息并重组答案,可能导致信息冗余或遗漏。
- 问答对的优势:
- 答案部分已是对问题的直接回应,生成模型只需“改写”或“补充”答案,而非从头生成,降低幻觉风险。
- 例如,QA对中的答案已结构化(如步骤列表),生成结果更规范。
(3)提升检索效率与召回率
- 问题:传统分块检索可能因文本块过长或过短导致关键信息丢失(如答案分散在多个段落)。
- 问答对的优势:
- 每个QA对是自包含的语义单元,检索时直接返回完整答案,减少上下文碎片化问题。
- 可针对高频问题设计专用QA对,提高热门问题的响应速度和准确性。
2. 哪些场景适合问答对形式?
(1)任务型对话系统
- 适用场景:客服机器人、技术支持、医疗咨询等垂直领域。
- 原因:用户需求明确,答案通常简短且结构化(如操作步骤、诊断建议)。
- 案例:
- 用户问:“如何退订会员?” → 直接匹配QA对中的答案:“登录账号→进入订阅管理→点击取消”。
(2)FAQ(常见问题解答)库
- 适用场景:产品帮助文档、政策解读等。
- 原因:FAQ天然适合QA形式,直接覆盖高频问题。
- 案例:
- 知识库存储 Q: 保修期多久? → A: 本产品保修期为2年。
(3)知识密集型生成任务
- 适用场景:需要精确引用事实的场景(如法律咨询、学术问答)。
- 原因:QA对中的答案可作为“事实锚点”,减少生成模型的自由发挥。
- 案例:
- 用户问:“《民法典》规定离婚冷静期多久?” → 返回QA对中的法条原文。
问答对构建的注意事项
并非所有数据都适合QA形式
- 避免强制转换:
- 叙述性文本(如小说、新闻)或开放域知识(如百科条目)更适合以段落或实体为中心存储。
- 强行拆分为QA可能导致信息割裂(例如将“量子力学发展史”拆解为多个不连贯的问答)。
三、具体步骤示例(大学生求职不踩坑指南数据集——基于Dify向量知识库构建)1、明确目标
确定你要解决的问题或任务,然后就可以寻找优质的数据集以及构建自己的数据集了~
2、数据收集
原始文档格式转换
可以是pdf转word,也可以是ppt转word,pdf转tx,
经过测试,大模型对TXT格式文档的识别度较高,尤其是在中文语言编码的情况下。因此,建议使用第三方工具将原始文档转换为TXT格式,以提高大模型的识别效果。 以下是笔者用过的一些方式:
- 懒人办公(免费)
https://www.lanren.work/pdf/pdf-to-txt.html

2. 电脑自带的word
这个每个人的电脑都有,但是要看转换效果,感觉方法一可能效果会更好,要根据实际情况决定

3. wps(要会员)
这个方法适用于有wps的小伙伴,

3、数据标注和数据清洗
1、导入文件到大模型对话助手,进行初步格式调整
GPT可以进行转换,但不是所有ai助手的都可以进行格式转换
提示词模板:
帮我去除掉文档中所有空格,删除掉所有页码,同时删除掉“xx”相关字样,记住无需保留空行。
2、格式重新调整
把问题以QA形式罗列,格式如下,记住每个问答之间空格一行:
Q:问题
A:答案
原文本中问题格式为:
xxxxxxxxx
答案为下一个问题之前的所有文本

到这只需要人工再进行一些抽验~没问题的话,数据集就创建完成了!效果如下~

如果还有问题的话,可以再让GPT进行调整
3、导入Dify进行数据集训练



测试一下~构建一个agent

引用知识库~

这样数据集就构建好啦~

四、完结感言
首先,非常感谢合作小伙伴冬灵和我一起共创数据集构建系列二。
其次,非常感谢Deepseek官网满血版以及kimi在本章的代码修改、资料收集以及文章润色方面提供的宝贵帮助!
...
#【强化学习】RLHF的核心—PPO算法
通俗易懂讲解PPO算法。
只要花30分钟,你就能轻松入门ChatGPT的秘密武器RLHF中的核心——PPO算法。
首先我们用简短的篇幅复习一下强化学习的基本概念,后续的算法会基于这些概念进行讲解;接着学习Actor-Critic算法和A2C算法,学完这两个算法之后,我们就能够掌握PPO最本质的思想;最后我们来完成终极目标——学习PPO算法。
强化学习
强化学习是什么呢?
强化学习是一种解决控制(或决策)任务的框架,它从环境中试错并获得奖励(正或负),然后将其视作反馈从而进行学习。
其中,负责决策和试错的智能体被我们称为agent。可以简单地类比为监督学习中的机器学习或深度学习模型,是一个可学习的函数。
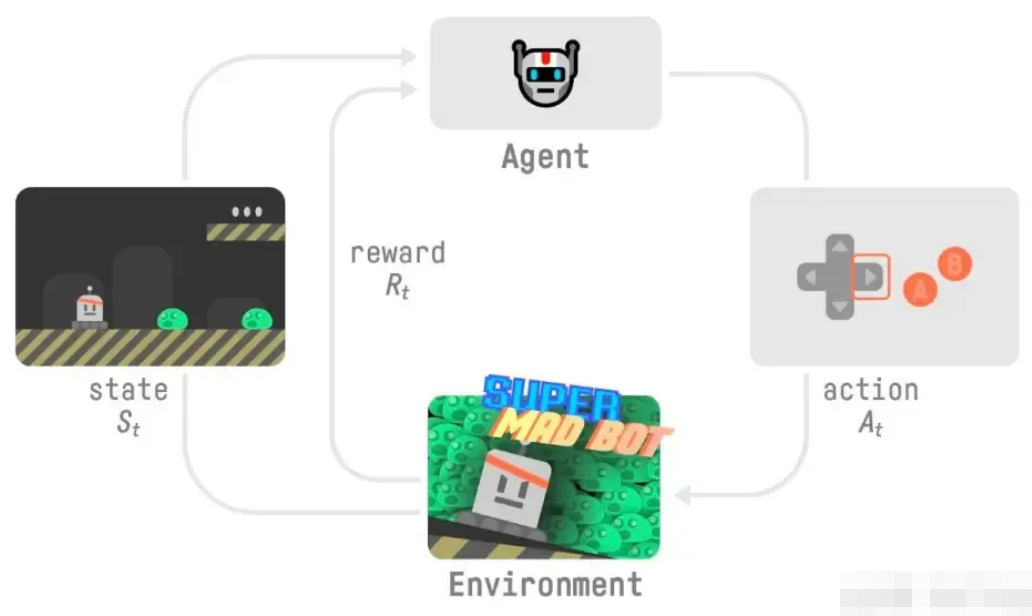
强化学习过程包含若干个episode,每个episode包含若干step。
例如,围棋的一局,超级马里奥游戏中从游戏开始到救出公主的过程,或者语言模型生成一个句子的过程,这些都是一个episode。围棋中某位棋手的一次落子,超级马里奥游戏中玩家的一次操作,或者语言模型生成句子中的一个token,这些都是一个step。
第t个step中,agent与环境交互包含以下步骤(如上图):
1.agent收到来自环境的状态
2.基于该状态 ,agent采取动作
3.环境进入新状态
4.环境会给agent带来一些奖励
如何理解状态、动作和奖励呢?
- 如果任务是下围棋,那么状态就是围棋中的局面(每个棋子的摆放位置和落子顺序),动作就是落子,奖励就是最终的输赢
- 如果任务是玩超级马里奥游戏,那么状态就是屏幕上所有元素(马里奥、怪物、管道等)的排列,动作就是按下手柄上的某个键,奖励就是吃到蘑菇或者赢得游戏
- 如果任务是语言模型的一次句子生成,那么状态就是当前已经生成的token,动作就是生成一个token,奖励就是最终人类对这个句子的喜好
我们希望一个episode中所有奖励之和能够越大越好。因此agent的目标是最大化一个episode中所有奖励之和的期望(之所以是期望而不是精确值,是因为采取动作后进入哪个新状态是环境说了算的,具有一定的随机性)。
如何做到呢?agent一遍遍地经历强化学习过程,一边收集数据,一边更新参数。最终就能够达成目标。
Actor-Critic算法
现在我们来学习Actor-Critic算法。在这部分我会花最多的篇幅,因为它是PPO算法的基础。
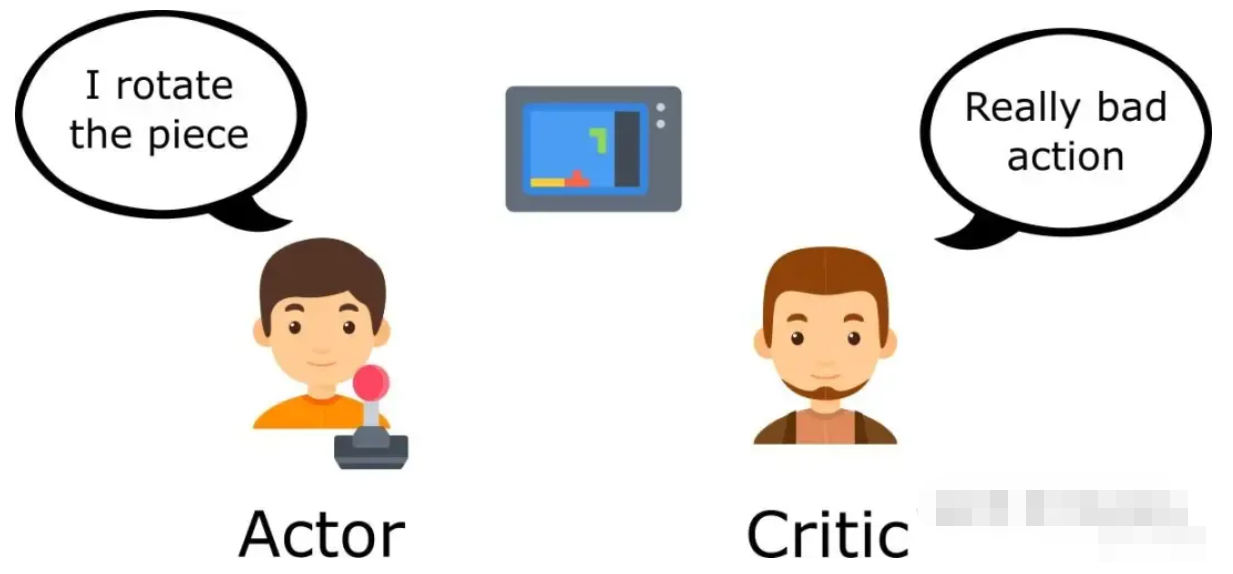
Actor-Critic算法包含两个模型——演员和评论家。
演员和评论家就好像是正在玩俄罗斯方块的你和正在看你玩游戏的朋友。你一开始不知道怎么玩,所以随机尝试一些动作。你朋友观察你的行为并提供反馈。你从这些反馈中学习,然后更新策略从而更好地玩游戏。另一方面,你朋友也会更新他提供反馈的方式,以便下次更好地给出反馈。
- 演员是我们最终需要的agent,负责选择动作。其内部有一个概率分布 ,指导演员在特定的状态 下选择动作 。这个概率分布又被称为"策略"。
- 评论家是一个辅助模型,负责预估该动作的收益,也就是状态 开始,选择动作 后,直到结束为止能够获得的奖励之和的期望 。这种收益又被称为"状态动作价值"。
问:评论家存在的意义是什么?
答:直观地说,如果没有评论家,你就无法提前得知当前动作的价值(必须得等到episode结束才行)。
顺带提一句,演员和评论家都可以用神经网络来建模
- 可以用输入一个向量 ,输出一个概率分布的神经网络来建模
- 可以用输入两个向量 ,输出一个标量的神经网络来建模
刚刚提到过,强化学习过程中的一个step要发生4件事。那么演员和评论家在一个step中,在这4件事发生的时候要做什么才能学到合适的参数呢?
- 演员收到来自环境的状态
- 演员生成动作 ,然后评论家估计状态动作价值 。演员用 loss 来更新参数
- 环境收到 之后给出 ,更新参数后的演员用 生成
- 环境给出 ,评论家用 loss 来更新参数
我们该怎么理解演员的loss呢?
说人话就是对状态 而言动作 的价值越大,演员就越要强化 ,否则就要弱化 。这有点像巴普洛夫的狗,演员会逐渐对需要强化的动作产生条件反射。
我们来分析一下:
- 当 大于0时: 的绝对值越高或者 越高,loss也就越低。此时演员必须更新参数来增大 ,更新的幅度受 的影响
- 当 小于0时: 的绝对值越高或者 越高,loss也就越高。此时演员必须更新参数来减小 ,更新的幅度受 的影响
我们又该怎么理解评论家的loss呢?
说人话就是评论家在得到新的信息后,需要改进自己预估的能力。例如,曾评论过梵高画作的评论家,如果“有幸”能够活到今天,就应该能通过梵高画作在如今的价值明白,自己的的评论能力已经跟不上这个时代了。
我们再来分析一下,评论家预估出的状态动作价值 可以分解为两部分: 。其中 是第 t 个step的预估奖励,是第 个step之后所有step的预估奖励之和。
现在,环境告诉我们第 t 个step的真实奖励是 ,我们用这个奖励替换掉预估奖励之后,这个等式就不成立了,也就是说 。所以才需要用不等号两边的数值的差来定义loss。在获得新的信息之后,通过loss更新参数,评论家的认知差就被抹平了。
总之,在强化学习过程中,演员逐渐形成条件反射,评论家的评论越来越准确。到最后我们就可以可以用演员来做决策了。
A2C算法

接下来我们来学习A2C(Advantage Actor-Critic)算法。它是Actor-Critic算法的改良,只要再加一点小改动就是PPO算法了。
它的思想很简单。假如你和你的朋友都是学生,你平时考试考90分,他平时考试考60分。经过一个月的期末复习,在期末考试中你考了96分,他考了95分。你觉得谁的期末复习策略是成功的?
显然你朋友的期末复习策略是更成功的。虽然你考了更高的分数,但这个分数基于你平时的积累,相当于是正常发挥了。而你朋友却是超常发挥。因此单看期末,他的复习策略更值得他好好强化。
我们再来看A2C算法。在其中,演员不参考评论家预测的收益的大小来更新参数,而是根据实际收益超出评论家预期收益的程度来更新参数。这样比较合理,也训练过程也更加稳定。例如,你平时考90分,期末考96分,超出预期的程度是6;而你朋友平时考60分,期末考95分,超出预期的程度就是35。因此A2C算法也觉得你朋友的期末复习策略更值得强化。
这种“超出预期的程度”在A2C算法中被称为优势(Advantage)。优势为正数表示超出预期,否则表示低于预期。下面我们用Adv来表示。
A2C算法的步骤与Actor-Critic算法的差别不大,因此就直接给出了:
- 演员收到来自环境的状态 ,生成动作
- 环境收到 之后给出奖励 和新状态
- 评论家估计状态价值 并计算优势
- 演员用 更新参数
- 评论家用 loss 更新参数
其中的 V 是新东西,它是从状态 开始,直到结束为止能够获得的奖励之和的期望,也被称为"状态价值函数"。就是说A2C中我们不学 ,改学 。但其实它们建模的是差不多的东西。
值得一提的是,在A2C算法中,我们先可以收集多个episode的多个step的数据,再一次性做参数更新。
PPO算法
终于,我们要开始学习PPO算法了,简单来说,PPO可以看作是一种特殊的A2C算法。
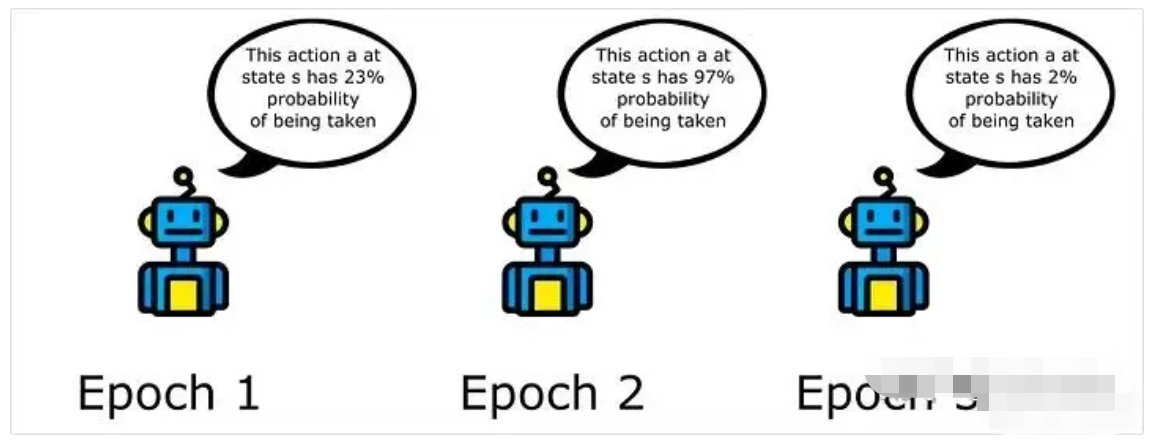
PPO 的思路是,为了维持训练的稳定性,想让策略 的更新幅度不要太大。怎么操作呢?可以找一个东西来限制p。
回顾一下,在A2C中,对于每个状态 下采取的动作 ,演员的loss是
而在PPO中,演员的loss则是:
其中 是本次参数更新前的策略, 是上一次参数更新前的策略(梯度是不会回传到 的),这个 '就是我们找来限制 的东西。
乍一看这个式子有点复杂,但其实有一种简单的理解方式。首先相比A2C的loss少了一个 ,因为 是单调函数,所以可以暂时忽略这个变化。其次相比A2C的loss多了一个 ,你可以把 以外的部分当成学习率(我们不让梯度经过 回传到参数上)。当 且 很大时,这个"学习率"就会变得很小。
意思是在 状态下,如果动作 能给你带来优势,但你预测 的概率已经很高了的话,为了维持训练的稳定性,就没必要再使劲更新参数了。
的情况可以自己分析一下。
现在,我们已经限制了策略 的更新幅度,但还缺少一个"熔断机制" 。什么意思呢?就是万一策略的更新幅度还是太大了,我们要停止策略的参数更新。
PPO的做法是什么呢?因为 衡量了旧策略和现行策略之间差异,所以可以为它设置两个阈值。为了方便描述,我们令 :
- 当Adv大于0时,若r大于1.2,则停止参数更新
- 当Adv小于0时,若r小于0.8,则停止参数更新
用一个式子就能描述这种“熔断机制”:
其中clip(r, 0.8, 1.2)表示:当r小于0.8时,clip函数值为0.8,当r大于1.2时,clip函数值为1.2,否则clip函数值为r。
来验证一下新的loss是否实现了“熔断机制”吧:
- Adv大于0:r大于1.2之后,min操作就会取右边的值;此时loss中就只剩常量了,不产生任何梯度;而r无论多小都还是会产生梯度
- Adv小于0:r小于0.8之后,min操作就会取右边的值,此时loss中就只剩常量了,不产生任何梯度;而r无论多大都还是会产生梯度
到此就全部结束了。最后,我们用一句简单的话来总结PPO算法:
根据优势决定是否强化动作的,限制更新幅度的,带有熔断机制的强化学习优化算法。
...
#读懂强化学习,去中心化强化学习又能否实现?
强化学习(RL)是当今 AI 领域最热门的词汇之一。近日,一篇长文梳理了新时代的强化学习范式对于模型提升的作用,同时还探索了强化学习对去中心化的意义。

原文地址:https://www.symbolic.capital/writing/the-worlds-rl-gym
「有时候几十年什么也不会发生;有时候几周时间仿佛过了几十年。」这句话形容当今的现代 AI 领域最为贴切。似乎每天都有新的突破性模型、训练方法或公司涌现,迫使我们重新思考 AI 世界的可能性。今年早些时候是 DeepSeek,接下来是星际之门项目,现在还有 Qwen、Manus、MCP 等。谁知道接下来会发生什么?
目前,在打造更好的模型方面,通过预训练以及最近的测试时间计算进行 scaling 是引领性方法。但最近,随着 DeepSeek-R1 和 R1-Zero 的发布,人们开始更加亲睐一种不同的模型 scaling 方法 —— 强化学习(RL)。本文的目标是探索基于 RL 的模型改进的含义,并会特别关注 RL 过程是否适合去中心化。
本文希望给读者带去三点收获:
- 了解 AI 模型改进技术的大致时间表以及不同方法如何随着时间的推移而发展。
- 通过强调用于后训练 DeepSeek-R1 和 R1-Zero 的技术,理解势头正盛的「RL 复兴」浪潮。
- 为什么强化学习后训练中的一些(但可能不是全部)组件可以受益于去中心化。
在深入探讨 DeepSeek 如何利用强化学习训练 R1 的细节之前,我们将先浏览一个(非常精简的)事件时间线,以了解我们如何走到了今天。
AI / 机器学习 scaling 简史
(极简版)
2020 年 - 2023 年初:预训练 Scaling Law,理解数据在训练中的重要性
2020 年,OpenAI 的研究者发表了《Scaling Laws for Neural Language Models》。这篇论文意义重大,因为它明确阐述了在 scaling LLM 时模型大小、数据和计算的权衡。后来到 2022 年时,DeepMind 的研究者通过《Training Compute-Optimal Large Language Models》对 Scaling Law 进行了扩展。
这篇论文明确了现在所称的「Chinchilla Scaling Law」,该定律表明:当时许多模型相对于其参数数量而言训练不足。也就是说,相对于用于训练模型的数据量,它们的参数太多。这项工作帮助研究者了解了数据与参数的最佳比率(每个参数大约 20 个 token)。之后,人们开始使用远远更多数据来训练模型。
最初的 Scaling Law 论文
随着 2022-23 年左右预训练 Scaling Law 的明确,「更多数据 + 更多计算 = 更好的模型」时代到来了。
只要我们能将足够的数据和计算投入到模型的预训练中,我们最终就会得到性能更高的模型。
OpenAI、Meta 和 Anthropics 等各路 AI 逐鹿者都高度关注如何确保大量数据和计算,以满足训练越来越大的前沿模型的需求。这样一来,他们就能不断发布越来越好的突破性模型。但随后,在 2024 年末,OpenAI 的推理模型引入了一种 scaling 模型性能的新方法。
2024 年:推理模型和测试时间计算 scaling
2024 年 9 月初,OpenAI 发布了 o1 模型。当时,它们是第一批向公众展示系统性思维链推理的模型之一。这些模型能使用刻意的逐步推理方法,在得出最终答案之前评估多种潜在解决方案。推理模型在抽象推理任务上的能力大幅提升 —— 在 ARC-AGI 推理任务得分的惊人提升就是明证:

Riley Goodside 制作的这张图展示了 OpenAI 推理模型发布后 ARC-AGI 得分的突破。
此外,随着这一模型的发布,人们认识到,通过增加测试时间计算(TTC,模型解决问题时使用的计算量),可以在模型训练后使模型表现更好。
具体来说,谷歌 DeepMind 的研究者在论文《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters》中表明,如果在推理时获得足够的计算,较小的模型可以可靠地胜过在预训练时获得更多计算的较大模型。想要一个模型给你一个更好的答案?给它更多的时间去思考问题就行,它就能推理出最好的解答。这标志着开发 scaling 测试时间计算的方法成为了新的重点。
2024 年末 - 2025 年初:预训练装甲的裂缝
通过 TTC scaling,我们现在有两个杠杆可以改善我们的模型。一个是在最初训练模型时,另一个是在模型训练之后。第二种方法来得正是时候 —— 随着 TTC Scaling Law 的形成,人们越来越担心我们即将耗尽继续推动预训练所需的数据……
2024 年 12 月,Ilya Sutskever 在 NeurIPS 2024 发表了一个主题演讲。他的 20 分钟演讲概述了过去十年的 AI 研究,并分享了他对该领域未来发展的看法。然而,他也给出了一个震惊 AI 行业的断言。在演讲开始后不久,Ilya 宣称:「我们所知的预训练无疑会终结。」
Ilya 认为,我们很快就耗尽了我们一直用作预训练「燃料」的互联网数据。「我们只有一个互联网,」他说。需要大量数据的模型已经消耗了所有可用的 token。
2025 年:对强化学习的全新认识和 DeepSeek 时刻
除非你过去几个月一直与世隔绝,否则你很可能在新闻中听说过一家名为 DeepSeek 的中国 AI 公司。随着他们发布 R1 模型,DeepSeek 证明了一种训练更好模型的新方法的可行性,并激发了人们通过强化学习探索模型改进的极大热情。
DeepSeek-R1 论文,其中一大贡献是带来了对基于强化学习改进 LLM 的全新认识。
我们大多数人可能都听说过 AlphaGo 使用的强化学习 —— 该 AI 模型掌握了复杂的围棋,并最终击败了世界顶级人类玩家。
AlphaGo 最初在一个包含 3000 万个人类棋盘下法的游戏数据库上进行训练,然后通过使用自我对弈强化学习,使性能更加出色。它被允许模拟成千上万场游戏,当它的落子可以导致胜利时,就能获得奖励。这个过程就被称为「强化」,可以让模型实现自我提升。
现在,LLM 使用强化学习已不鲜见。基于人类反馈的强化学习(RLHF)早已被 Anthropic 和 OpenAI 等领先公司广泛使用。DeepSeek 的新颖之处在于:他们的 R1-Zero 模型表明,可以在极其有限的人为干预下使用强化学习,并最终得到一个高性能的推理模型。
随着 DeepSeek 的出现,我们现在可能有三种可重叠使用的方式来改进模型:scaling 预训练、scaling TTC、在微调中 scaling RL。这些方法能让我们的模型变得更好。然而,第三种方法,即基于 RL 的微调,可能不仅仅是另一个旋钮,因为它可以解锁强大的自我改进反馈循环。
DeepSeek 的创新之处在于它能够使用模型生成自己的推理轨迹,使用轻量级 RL 对其进行改进,然后将这些改进的输出放回训练中。升级后的模型会生成更好的轨迹,并进一步完善,依此类推。循环的每一次转变都会增强模型在各个领域的推理能力。这种递归改进过程(合成数据不断改进生成它的模型)打破了对新的人类数据的传统依赖,推动了模型性能提升。
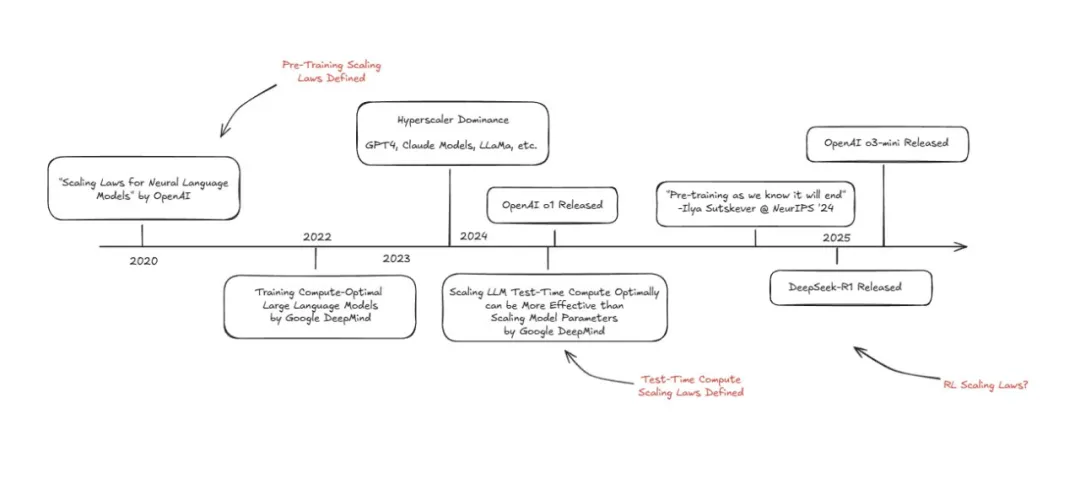
一份突出 LLM scaling 新方法诞生的关键时刻的粗略时间表
DeepSeek 系列模型
DeepSeek 发布的一系列模型推动了 LLM 世界的发展进步,而其中最激动人心的莫过于他们使用强化学习创造了 DeepSeek-R1-Zero。
下面将基于 DeepSeek R1 论文来深挖可以如何使用 RL 来训练模型,但在此之前,先要区分与本节内容相关的三个不同的 DeepSeek 模型:
- DeepSeek-V3:V3 是一个 671B 参数的稀疏混合专家(MoE) 模型,于 2024 年 12 月发布。与密集模型不同,MoE 模型的一部分参数(专家)会在处理不同类型的输入时激活。凭借低廉的训练成本,这个模型震惊了 AI 行业。
- DeepSeek-R1-Zero:R1-Zero 是 DeepSeek 使用 V3 作为基础模型训练的推理模型。重要的是,他们使用了 RL 对其进行微调,没有 SFT 或任何人类数据(这一概念后面将详细介绍)。它性能出色,但不适合日常使用,因为它在生成人类可读的输出方面存在问题,并且经常在输出中混用多种语言。尽管如此,它还是很有价值,展示了可以如何通过使用硬编码验证器的 RL 生成性能卓越的推理模型。
- DeepSeek-R1:R1 是 R1-Zero 的「清洁版」。它采用了与 R1-Zero 类似的训练过程,但还使用了有限的 SFT 来完善其输出并使其更适合日常使用。
V3、R1 和 R1-Zero 之间的关系图示
下面我们再来看看 DeepSeek 团队是如何使用 RL 创建 R1-Zero 的,然后再了解它可以如何转化为去中心化设置。
R1-Zero 是如何炼成的?
常见的 RL 后训练设置如下:
- 监督微调(SFT)——SFT 是在精心整编的高质量输入输出对数据集上训练模型,其中输出展示所需的行为,例如逐步推理或遵循特定指令。包括问题的稳健答案、指令集或要遵守的规则,和 / 或提示词和思维链示例。使用 SFT 的理念是:通过向模型提供一组极高质量的数据,它可以学习模仿这种类型的行为。
- 基于人类反馈的强化学习(RLHF)——RLHF 通常是在少量 SFT 之后。由于 SFT 需要高质量的人类数据,RLHF 能补充这个过程,方法是使用人类偏好来训练奖励模型,这反过来又能为模型创建一个框架,使其能够根据自己的响应进行自我训练。
但 DeepSeek-R1-Zero 在几个关键方面偏离了这个过程。
丢弃 SFT
DeepSeek 的研究团队没有采用先 SFT 然后 RL 的两步流程,而是完全放弃了 SFT 流程。本质上,DeepSeek 采用了 V3,并在有限的护栏设置下,为其尽可能地提供了足够的时间和计算能力,助其学习如何推理。
移除 SFT 步骤有几个有趣的好处,但也有一些缺点。
优点
- 通过移除一整个训练过程,减少了训练的计算需求。
- 由于模型之前没有受到基于人类的微调数据的影响,因此让模型在 RL 期间有更广泛的探索窗口。
缺点
- R1-Zero 的可读性较差,并且经常在答案中混合多种语言。它具有很强的推理能力,但本质上不适合与人类交互。也因此,DeepSeek 在训练 R1 时重新引入以人为中心的数据。
用 GRPO 代替 PPO
DeepSeek 训练方法的另一个主要区别是使用组相对策略优化(GRPO) 作为其 RL 框架,而不是更常见的近端策略优化(PPO)。同样,这让 RL 更简单且计算密集度更低了。下面简单介绍一下 GRPO 和 PPO 之间的区别:
近端策略优化(PPO)
使用 PPO 的 RL 有三个组件:
- 策略模型 - 「策略模型」是核心模型,是最终想要训练的模型。
- 奖励模型 - 奖励模型是根据人类偏好进行训练的模型,用于评估策略模型的输出。在实践中,人类会对 LLM 输出的一小部分进行评分,然后这些评分会被用于训练奖励模型以反映人类的偏好。奖励模型的作用是评估策略模型,以便策略模型可以学习优化以获得更好的响应。
- 价值模型 - 价值模型(或 critic)是一个神经网络,它的作用是估计给定状态下未来奖励的预期总和,通过提供部分完成的价值估计来帮助引导策略模型。
下面用一个比喻来说明这些组件协同工作的方式。想象一下你正在写一篇文章。价值模型就像有一个导师在监督你,他可以根据你到目前为止写的内容预测你的最终成绩。这很有用,因为你不想等到整篇文章完成后才知道你是否走在正确的轨道上。可以类比成这样的过程:

此示例说明了策略、价值和奖励模型协同工作的方式以分析和改进 LLM 的行为。
下面给出该过程的更清晰说明:
- 策略模型收到提示词后开始推理答案。
- 价值模型评估每一步的当前状态并预测预期的未来奖励,帮助指导策略在生成响应时的决策。
- 奖励模型评估完整响应,为最终结果分配分数,以便策略可以学习给出更好的输出。
- 对于给定的响应,将对价值模型的预测分数和奖励模型的实际分数进行比较。然后使用此信息来改进策略模型。

解释 PPO 过程的简版流程图
这里有个值得记住的要点。在 PPO 中,在奖励模型之外还使用价值模型曾被认为是很关键的,因为研究者认为需要能够评估中间模型推理才能训练最佳模型。由于 LLM 的核心能力是按顺序选择最佳的下一个 token(单词),因此如果能够理解响应的每个部分对最终结果的影响,就会很有意义。例如,句子「the cat ran」涉及三个决策(the、cat 和 ran)。如果奖励模型要给这个句子打高分,价值模型将使我们能够了解哪些特定单词是最优的,以及三个单词中是否有次优的。也许「the」和「cat」很棒,但选择「sat」会让整个响应获得更高的分数。它允许训练期间的反馈更加细粒度。这似乎合乎逻辑,对吧?确实如此,但 DeepSeek 对 GRPO 的表明情况可能并非如此。
GRPO
GRPO(Group Relative Policy Optimization)是一种与 PPO(Proximal Policy Optimization)不同的强化学习后训练方法。GRPO 的核心区别在于完全摒弃了价值模型。它主要包含两个组成部分:1)策略模型;2)奖励模型。
为了进一步简化强化学习过程,DeepSeek 的奖励模型并不是基于人类偏好的神经网络。相反,它采用了一个非常简单的奖励框架,专注于可验证的奖励(即某件事是对还是错,用 1 或 0 表示)。
GRPO 流程大致如下:
- 对于给定的单个提示,策略模型生成多个输出;
- 奖励模型对所有的响应进行打分;
- GRPO 会计算输出组的归一化平均分数,并根据每个单独响应的分数与平均值的比较来评估每个响应;
- 该模型使用得分最高的完整输出来了解哪种总体响应模式效果更好。
下图对比了 PPO 和 GRPO 方法:

GRPO 通过大幅简化奖励过程并完全去除评判模型(critic model),大幅减少了内存和计算开销。评判模型通常与策略模型大小相当,并且需要在整个强化学习(RL)过程中不断更新。DeepSeek 估计,仅此一项改进就使开销减少了大约 50%。
现在,我们已经了解了监督微调(SFT)以及 PPO 和 GRPO 之间的区别,可以更清晰地看到 DeepSeek 的 R1-Zero 训练过程实际上是多么简单。他们从一个性能良好的混合专家(MoE)基础模型(DeepSeek-V3)开始,实现了一个轻量级、硬编码的 GRPO 框架,然后基本上让模型通过试错来学习。
下图表明,随着时间的推移,R1-Zero 学会了思考更长时间,并得出更准确的答案。这一进步并非源自人工标注数据或精选数据集,而是通过一个闭环学习过程实现的:生成推理路径→评估效果→强化最优路径→循环迭代。这种自我反馈机制推动模型持续进化,无需依赖外部新增数据,恰好规避了 Ilya 所指出的预训练数据收集难题。

DeepSeek-R1 论文图表显示:随着训练推进,模型学会了进行更长时间的思考(左图),同时回答准确率也不断提升(右图)。
尽管这一方法看似简化,却最终造就了一个强大的推理模型。更重要的是,它指明了一条全新的能力扩展路径:模型可以通过自我输出的学习、自主生成合成数据来实现自我提升。这才是最关键的突破 —— 它正在开启模型进化的全新范式。
一张极其简明的示意图,展示了 GRPO 式强化学习开启的模型自我提升良性循环。
尽管这一成果意义重大,但必须指出:R1-Zero 并非适合日常使用的成熟模型 —— 其输出常混杂多种语言,导致人类难以阅读。为解决这些问题,DeepSeek 团队通过更精细的调优流程,最终开发出实用性更强的推理模型 R1。
R1
对于 R1, DeepSeek 没有在 V3 上直接进行 GRPO RL,而是将微调分为四个阶段:
阶段 1:冷启动 SFT
为确保最终获得人类可读的模型, DeepSeek 团队采用了冷启动监督微调(SFT)方案。其核心是为模型提供定向数据集,以引导其形成预期的推理模式。虽然该数据的完整细节尚未公开,但研究人员透露:他们收集了数千条冷启动数据,形式包括:附带长思维链(CoT)的小样本提示、经过 DeepSeek-R1-Zero 的可读输出。同时团队还引入了人工标注员进行后期处理。
这一过程至少明确揭示:人类干预在关键阶段仍不可或缺。
阶段 2:使用 GRPO
这与训练 R1-Zero 的 GRPO RL 步骤相同。
阶段 3:拒绝采样 SFT
在此场景下,拒绝采样是指通过奖励模型的筛选机制对模型输出进行评分排序,仅选取最高分的样本用于后续微调。 DeepSeek 团队采用两轮筛选机制处理了 80 万条数据样本,其构成包含:60 万条推理相关样本(涵盖数学、逻辑等任务),20 万条非推理样本(如文本创作、自我认知等)。
阶段 4:RL
在这轮强化学习中,重点在于提示和学习,以使模型更具人类一致性。具体来说,DeepSeek 的目标是增加模型的有用性和无害性。DeepSeek 报告称,他们使用了多个奖励模型来鼓励他们所期望的全面的人类一致性行为。
R1-Zero 与 R1
如果你把所有这些放在一起,并将其与 R1-Zero 方法进行对比,你会得到一个看起来像这样的过程:
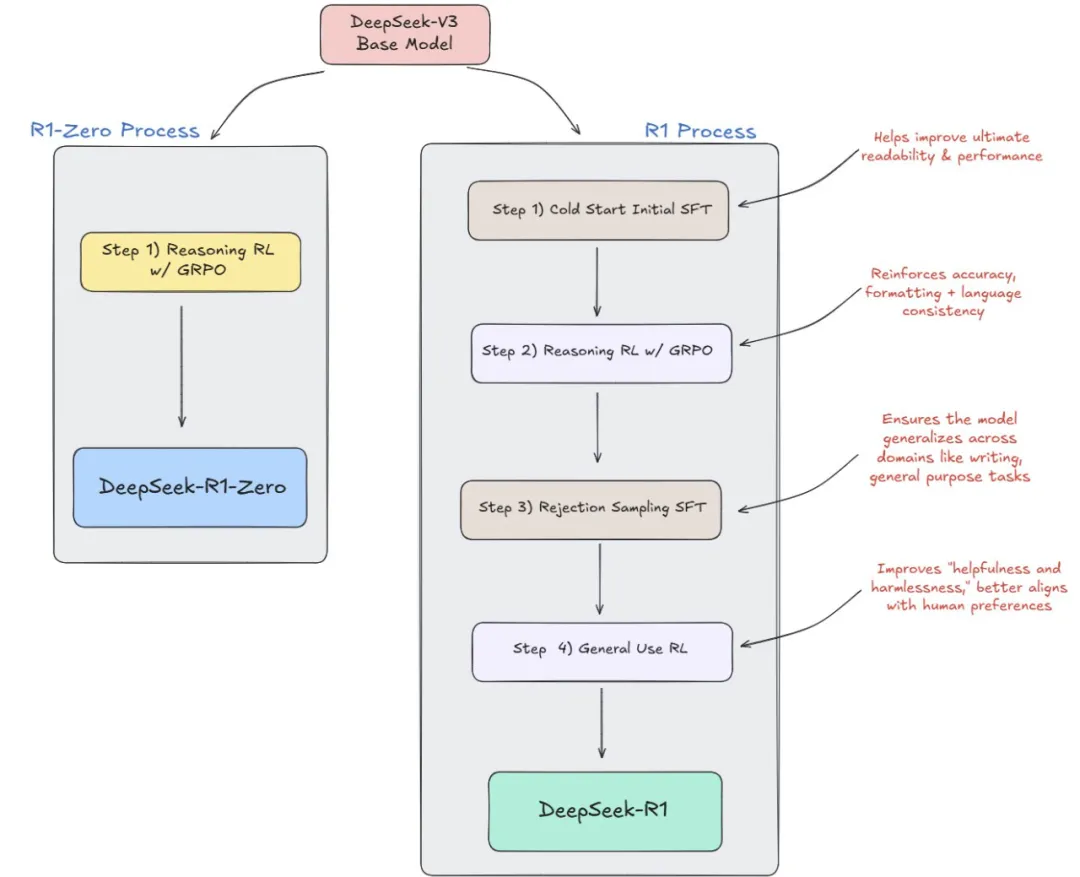
这张图对比了 DeepSeek 如何使用 V3 作为他们的初始模型,然后使用不同的微调方法来到达 R1- zero(左)和 R1(右)。
DeepSeek 的几个关键要点:
- 极其简单的强化学习可以激发标准 LLM 中的复杂且高效的推理行为;
- 这种强化学习过程在很大程度上依赖于推理时间计算来生成推理痕迹;
- 该强化学习过程得益于为给定提示并行生成许多推理跟踪;
- 这种强化学习风格严重依赖于可靠且稳健地验证输出以塑造模型的行为。
构建去中心化强化学习网络
DeepSeek 不仅通过 GRPO 验证了纯强化学习的价值,更揭示了两个关键需求:海量推理数据,以及生成这些数据所需的训练环境。这一观点随后得到两位 AI 大佬的证明 —— 就在 R1 发布后不久,Andrej Karpathy 在推文中直言:
其次,Yann LeCun 进一步强调了 Andrej Karpathy 的观点:
去中心化 RL 组成部分
这里提供了三个主要组件,并把各干组件用俏皮的名字命名。
A) 基础 — 基础模型 + 用于训练它们的去中心化网络;
B) 训练场 — 用于生成多样化、高质量推理数据的环境 + 协调贡献的去中心化网络;
C) 优化器 — 执行微调的去中心化网络。
基本组件如下所示:
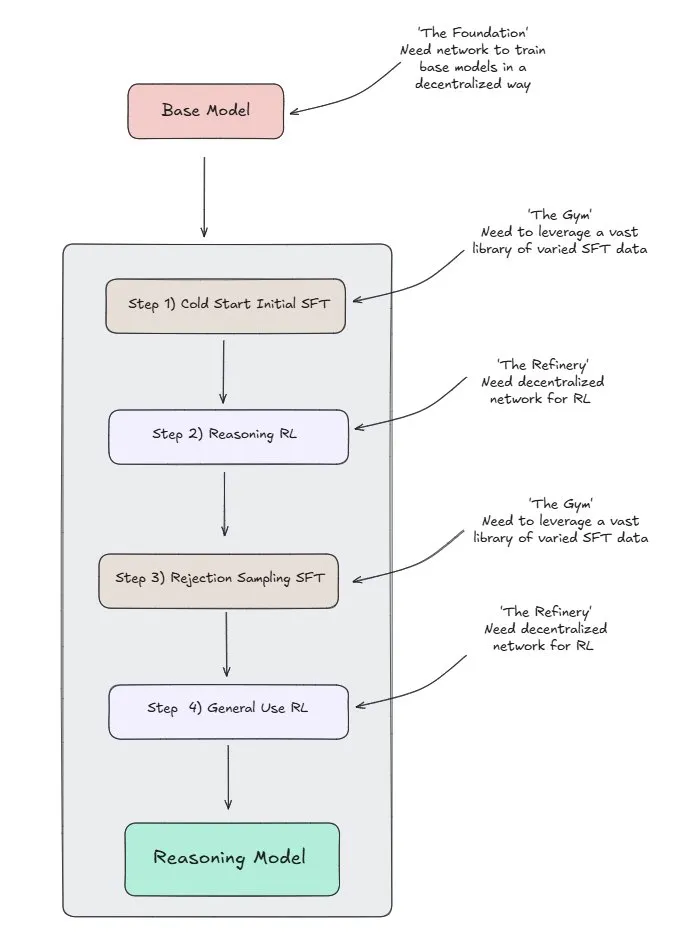
A) 基础:预训练基础模型
关于 DeepSeek 生成 R1 模型的过程,关键点在于他们需要从一个高性能基础模型(V3)起步,才能使其精妙的强化学习流程发挥作用。正是基于这个拥有 6730 亿参数的 MoE 模型,他们才能充分受益于 GRPO 的简洁性。如果从 V3 的蒸馏版本或更差的模型开始,将无法获得同等效果。因此,尽管 DeepSeek 让更多人关注到通过精简强化学习实现扩展的可行性,但这不应掩盖一个关键事实:预训练出越来越好的模型仍然至关重要。正如 Anthropic 团队讨论中 Dario 所言,他们必须将模型扩展到足够规模,因为早期较小的模型还不够智能,无法在其基础上进行 RLHF。
需要强调的是,以去中心化方式预训练顶尖基础模型,无疑是整个体系中最困难的环节。预训练过程中巨大的通信开销,以及应对计算力或内存受限节点的技术方案,都极为稀缺。
最简易的实现路径,是采用中心化训练的基础模型(如 DeepSeek-V3、最新 LLaMa 或 Qwen 模型等),仅在微调阶段引入去中心化。这虽能大幅降低难度,却违背了构建端到端去信任化流程以产出前沿模型的初衷。
这看似哲学层面的讨论,但若仍依赖中心化机构提供基础模型,去中心化强化学习的意义将大打折扣。因此,我们必须建立去中心化的预训练网络。
B) 训练场:生成推理数据
微调 R1 需要海量数据 —— 既需要冷启动数据开启微调流程,又需要超过 80 万条中间阶段数据点来提升模型泛化能力。现在的问题是:我们能否去中心化地生成这些数据?答案是肯定的。事实上,分布式环境非常适合这类任务。
环境与轨迹
回顾 Karpathy 的推文,开放分布式是实现海量数据目标的理想方式。为此我们需要构建一个框架,允许任何人为多样化任务贡献推理样本(称为轨迹)。贡献者不仅能够提交轨迹,还能创建标准化环境来生成不同类型的数据。也就是说,我们需要标准化的环境来生成数学推理、物理、医学、工程、写作等各领域的轨迹。构建这样一个能生成和收集轨迹的多样化环境体系,将形成庞大的数据库供所有人用于模型微调。
这种方法本身并不一定新颖,但随着 DeepSeek 展示了其方法的有效性,它现在获得了新的重要性。早在 OpenAI 的早期,该公司发布了一个名为 OpenAI Gym 的平台,为开发者提供了一个环境,用于测试不同的强化学习算法以完成基本任务。类似地,SWE-Gym 是测试智能体软件工程能力的流行环境,CARLA 用于自动驾驶车辆,Pybullet 用于物理仿真。
当然,还需要有可靠的方法来评估这种推理数据的正确性。在 DeepSeek 中,当无法通过程序化方式验证输出(例如数学问题)时,他们采用了基于 LLM(大语言模型)的评估方法,即将样本输入 DeepSeek-V3,让其进行评判(例如评估写作样本的质量)。对于我们的训练场,不仅要有环境,还需要为许多不同类型的数据配备验证器 —— 如果不能可靠且一致地验证正确答案,推理数据又有什么用呢?强化学习扩展所需的稳健验证如此重要,以至于 AI/ML 领域的先驱、《苦涩的教训》的作者 Rich Sutton 早在 2001 年就写过这一概念。

推理数据示例:
来自开源项目 General Reasoning 的完整推理数据示例。
为了进一步探讨开发稳健验证器的需求,我们需要在 DeepSeek R1 和 R1-Zero 所实现的基础上进行创新。他们的 GRPO(Group Relative Policy Optimization)设置之所以效果显著,是因为许多问题都有简单的二元验证(例如,数学问题的正确答案为 1 或 0)。但如何处理更复杂、更微妙的场景呢?如何处理跨领域的请求奖励?在编码任务中,我们如何为不完美的输出分配分数,例如奖励正确的语法?如果领域本身含糊不清,我们没有一个适合它的奖励策略,该怎么办?模型在数学和编码等更客观领域的熟练程度,能否推广到写作和语言等主观领域?
展望未来,随着对设计最佳推理环境的进一步探索,一定会有很多创新。去中心化网络所固有的协作和开放实验精神将是推动这一领域进步的关键。
总结
如果你以怀疑的眼光来看待去中心化 AI,也没有关系 —— 这个领域正需要更多质疑的声音。
但即便你持怀疑态度,也请特别关注训练场模块 —— 在整个强化学习体系中,这是最明确、最直接受益于去中心化的环节。与预训练或微调过程不同,去中心化在此不会引发相同的性能挑战。
不过,正如 Karpathy 所说,创建多种经过验证的环境以生成强化学习策略的任务是高度可并行化的。
从高层次来看,基于 GRPO 的去中心化强化学习应该比去中心化预训练更容易实现。
最后,去中心化 RL 的一些注意事项包括:
通信量:在预训练场景中,整个训练过程中需要计算和通信的信息量远远高于微调阶段。对于预训练,基于每个 token,你需要为每一个可能的下一个 token 计算分数,并计算梯度。而在强化学习(RL)中,你只需要更简单地为一组完整的字符串响应计算优势分数 —— 不需要在每个 token 步骤上都进行评分。这使得整个过程对内存的需求大大减少。
GRPO 的效率:随着 DeepSeek 展示了 GRPO 的可行性,我们拥有一种比 PPO(Proximal Policy Optimization,近端策略优化)更适合去中心化的强化学习方法。我们不仅看到 GRPO 大幅减少了强化学习中所需的计算能力,还应记住 DeepSeek 也摒弃了评判模型(critic model),转而使用一个非常轻量级的奖励系统。这使得强化学习过程在去中心化过程中需要的协调工作大大减少。没有评判模型意味着我们不需要一个去中心化网络在运行过程中同时更新策略和评判模型。而轻量级的奖励模型也意味着我们在训练该模型时需要投入的计算资源更少。
量化:量化是一种用于减小模型大小以便于部署的过程。鉴于这一部分比前面的内容稍显技术性和复杂,本文把它分成三个小节来帮助解释。
概述:量化通过使用较低精度的数据类型(如 8 位整数或 16 位浮点数)来表示模型的权重和激活值,而不是使用 32 位浮点数。
为了借助一个比喻来解释量化,如果你把模型想象成画作,那么全精度模型就像是用艺术家完整的颜料系列(每一种色调和色相)创作的画作。而量化模型就像是试图用更受限的颜色集合来创作同一幅画,比如说,仅用黑白两色。你仍然可以得到一幅能够清晰代表原作的作品,但最终结果的保真度较低,且丢失了一些细节。

一张简单的图像展示了量化的效果
这个比喻指出了量化中存在的一种权衡。虽然量化可以使模型变得更轻量级,但你最终得到的模型可能会不够准确。如果模型的每个参数包含的信息较少,那么它执行的数学计算自然会不够精确。
当前创新现状:量化在推理中被广泛使用,通常被认为不适合预训练场景,并且在强化学习(RL)中的应用还相对较少。然而,哈佛大学和谷歌 DeepMind 的研究人员进行的一项合作研究表明,在基于 PPO(近端策略优化)的强化学习中,使用 8 位量化能够显著加快训练时间。他们的基本设置是让量化的 actor 模型生成输出,而全精度的 learner 模型负责更新。通过这种设置,他们报告的训练速度比全精度训练快 1.5 到 2.5 倍。
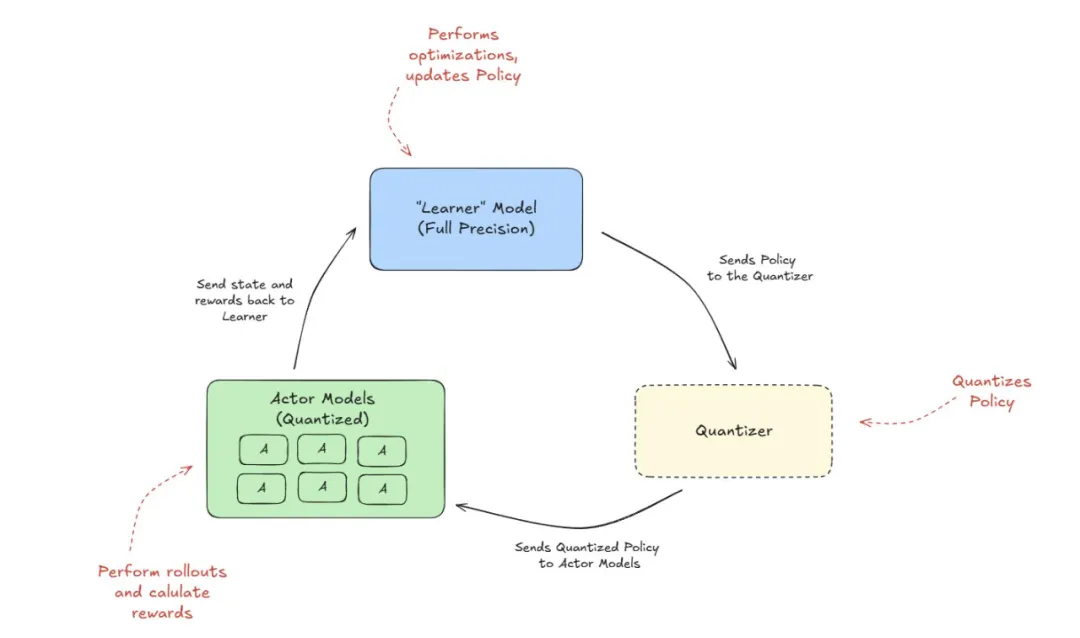
QuaRL 中的学习器、量化器、参与者的设置。
除此之外,DeepSeek 实际上在 FP8 精度上训练了 V3 的大部分内容,表明并非所有预训练操作都需要完全精度。要讨论他们如何做到这一点可以写成一大篇文章,但本质上,DeepSeek 隔离了预训练的组件,其中 FP32 或 BF16 至关重要,而 FP8 的准确度下降则没问题。
虽然有一些令人兴奋的研究正在更好地将量化纳入完整的 AI/ML 堆栈,但当前的硬件限制仍然是进步的障碍。目前,只有 4000 系列和更新的英伟达 AI 卡原生支持 FP8 量化。这意味着只有更高端的消费卡才能利用量化。不过,随着时间的推移和消费卡中量化支持的普及,我们可以预期量化将得到更常规的利用。
要点:虽然需要在该领域进行更多研究,但早期的进展迹象预示着去中心化将取得良好进展。为什么?将计算分散到多样化、异构的计算网络中通常意味着并非计算网络中的每个参与者都会拥有多个 GPU 集群,也不必是最先进的单个 GPU。在这里,内存限制会发挥作用,那些硬件有限的人可能会被排除在网络参与之外。然而,有了量化的能力,我们可以实现更快的性能,同时还可以将模型缩小到更小的尺寸,更好地促进内存受限硬件的个体参与研究。
分布式通信技术
与预训练相比,RL 具有更轻量的特性,因此分散微调过程应该是完全有可能的。
在非常高的层次上,在分散的 RL 训练网络中,你可以拥有非常轻量级的「推理节点」,然后与更强大的「工作节点」进行协作。如果实施模型并行方法,推理节点可以是在本地下载小型量化模型的单个参与者,甚至可以下载模型的片段。这些节点可以运行推理并计算奖励,然后以不频繁的间隔将结果发送回训练模型,然后训练模型将进行更多计算密集型梯度更新。在处理跨庞大的并行工作器网络的部署时,大部分工作将集中在隔离如何以及何时协调策略更新。
为了实现这一点,一个有效的路由方案对于将请求路由到全球各地的推理节点至关重要。一种现有的方法是 Ryabinin 等人提出的 SWARM 并行框架,在预训练环境中,该框架能够在为地理分散的 GPU 提供训练工作时考虑地理距离和特定节点的计算效率。
同样,关键是设计一种极其高效的路由算法,该算法可以确保不会使特定工作者超载,调整以平衡工作者完成时间,处理容错,当然还有一种同步算法,可以大大减少优势和梯度同步的频率。这绝不是一个简单的挑战,但它比预训练更容易解决。
以下是针对微调设置量身定制的三种方法:
PETALS
PETALS 提出了一种有趣的方法,通过协作推理和微调使大型语言模型的访问变得平民化。该系统的开发是为了解决 LLM 领域的一个关键挑战:虽然已有高性能的开源模型可供下载,但通常推理内存(以及用于微调的内存)使大多数研究人员和从业者望而却步。
PETALS 通过将计算分布在多个参与者之间来实现大型模型的协作使用。在这个系统中,有两个主要参与者:服务器和客户端。每个服务器存储模型层的子集(通常是连续的转换器块)并处理来自客户端的请求。

PETALS 中的图表显示了模型在各个服务器上的拆分情况。
客户端可以调用管道并行服务器链来对整个模型进行推理,每个服务器仅保存其可用 GPU 内存允许的块数。

来自客户端的请求通过一系列服务器进行路由。
该系统的架构在处理推理和训练方面特别巧妙。在推理过程中,客户端仅在本地存储模型的标记嵌入(占总参数的一小部分),并依靠服务器来处理转换器块。当客户端启动推理会话时,它首先建立一个服务器链,这些服务器共同保存所有模型层。然后,客户端使用其本地嵌入层来处理输入标记,通过服务器链发送结果向量,并接收最终输出表示以计算下一个标记概率。
PETALS 的一项关键创新是其微调方法。PETALS 不需要完整的模型实现,而是支持分布式参数高效训练,其中客户端「拥有」其训练过的参数,而服务器托管原始的预训练层。服务器可以通过其层执行反向传播并返回与激活相关的梯度,但它们不会更新服务器端参数。这样,多个客户端就可以在同一组服务器上同时运行不同的训练任务,而不会相互干扰。
为了提高效率,PETALS 采用了多项优化措施。它使用动态分块量化将管道阶段之间的通信缓冲区压缩为 8 位,从而降低带宽要求,而不会明显影响生成质量。该系统还采用了复杂的路由算法,帮助客户端找到最佳服务器链,同时考虑了网络延迟和服务器负载等因素。
在实践中,PETALS 在交互式使用方面取得了令人印象深刻的性能 - 在消费者 GPU 上以每秒约 1 步(前向传递)的速度运行 176B 模型的推理。这使得它适用于许多交互式应用程序,同时保持了研究人员访问模型内部和试验微调方法所需的灵活性。
DiPaCo
另一种与 MoE 模型特别相关的有前途的方法是 Google DeepMind 研究人员提出的分布式路径组合 DiPaCo。它引入了一种分发和微调 MoE 模型的新方法,这对去中心化网络尤其有价值。传统的 MoE 训练要求每个节点将整个模型存储在内存中 - 对于参与者资源有限的去中心化网络来说,这是一个重大障碍。DiPaCo 采取了不同的方法,将模型分解为 “路径”。每条路径代表一条精心构建的网络路线,其中包括来自每个 MoE 层的专家模块子集,以及相应的路由组件和必要的层规范化组件。
DiPaCo 的关键创新在于它如何处理训练和推理。在训练期间,数据会按路径预先分片和分发,这意味着每个工作者只需要通过其特定的路径配置处理数据。这是通过在文档级别而不是每个标记上做出路由决策来实现的,允许对序列的所有标记进行批处理计算,而无需交换模块。每条路径都设计得足够小(大约 150M 个参数),以适应中等规模的 GPU 硬件,从而可以更广泛地参与去中心化网络。
DiPaCo 的图表显示了数据分片通过地理上分散的 GPU 上托管的相关路径进行路由。
在 DeepMind 的实验中,DiPaCo 表现出了卓越的效率 - 一个由 256 条路径和 1.5 亿参数组成的网络能够匹配密集的 13 亿参数模型的性能,同时所需的训练时间减少了 45%。然而,另一方面,这种方法被证明是极其低效的 FLOP;DiPaCo 需要更多的计算才能实现与相同密集模型相似的困惑度分数。
不过,DiPaCo 对分散实施有着有趣的影响。在 DiPaCo 中,无论是在训练期间还是在评估时,整个网络都不需要在一个地方实现。完整模型仅作为分散硬件上路径的虚拟组合而存在,每条路径都可以独立提供服务。此外,DiPaCo 的架构自然支持异构硬件(实验中使用了美国、日本和英国的 A100 和 TPU 的混合体),允许弹性资源利用,并通过路径冗余提供内置容错能力。按路径分配计算的基本原理对于分散式网络可能很有价值,因为在分散式网络中,以有限的硬件资源和最小的通信开销参与的能力至关重要。
Gensyn AI 团队开发的 RL Swarm
RL Swarm 由领先的去中心化 AI 公司 Gensyn 的研究人员开发,是一种分布式强化学习的协作方法,直接建立在 DeepSeek 的 R1 GRPO 流程之上,目前已在 Gensyn 的测试网上上线。我们已经强调 DeepSeek 展示了模型可以在没有 SFT 或批评模型的情况下通过强化学习进行自我改进,但 RL Swarm 通过使多个策略模型能够在分布式环境中协作学习,进一步推进了这一概念。
RL Swarm 的关键创新在于其点对点学习结构,其中模型不仅可以自我评估,还可以评估和学习彼此的推理过程。这使 RL 动态从一项单独的努力转变为一项协作努力,其中模型受益于同行的探索和见解。
Gensyn 为 RL Swarm 设置的实验利用了较小的 Qwen-2.5b-1.5B 模型,并在数学推理数据集 (GMS8K) 上进行了训练。其遵循一个三步流程,正如 Gensyn 团队所强调的那样,该流程反映了一个协作研究小组:
- 回答阶段:将多个策略模型加载到单独的硬件中,然后这些模型独立生成对给定提示的多个响应(通常每个问题有八个答案),计算奖励,确定优势,计算损失,并按照 GRPO 方法执行梯度更新。完成这些单独的工作后,每个模型都会与群中的其他模型分享其最佳答案。
- 批评阶段:模型检查同行提供的答案并提供结构化反馈。这创造了一种动态,激励模型既能提供高质量的答案,又能培养评估他人回答的技能。
- 解决阶段:每个模型都会投票选出最佳答案。然后基于这种集体评估,模型会针对原始提示生成最终的修订答案。
RL Swarm 的三步流程。
与单独训练的模型相比,RL Swarm 方法展示了几项改进。首先,实验表明,在 RL Swarm 中训练的模型通常比单独训练的模型获得更高的奖励(例如,它们始终产生更优的输出)。其次,同行评审过程始终产生更多人性化的输出,正如 swarm 训练的模型所证明的那样,它们产生的响应更具人性化,推理更深入。具体而言,Swarm 模型产生了更长、更结构化的响应,格式更好,包括正确使用项目符号、间距和 LaTeX 进行数学符号表示。这表明协作评审过程创造了一种新行为,其中模型不仅针对正确性进行优化,还针对清晰度和可理解性进行优化。
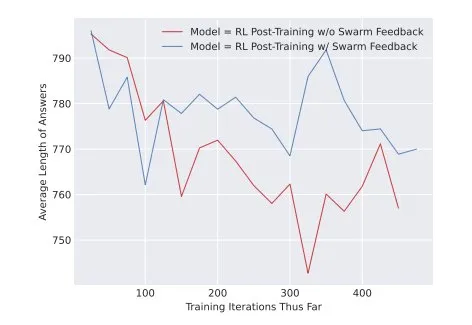
RL Swarm 论文中的一张图表显示了 RL Swarm 训练模型和单独训练模型之间的响应长度差距。
鉴于模型之间所需的通信轻量级特性以及消除复杂的批评网络,RL Swarm 代表了一种有前途的方法,可以在保持训练效率的同时扩展分布式强化学习。同伴学习框架是开源的并且已经上线,利用 Ryabinin 等人的 Hivemind 库来处理跨节点通信。虽然 RL Swarm 还处于发展初期,但它对于领域内来说已相当令人兴奋 —— 它是我们今天拥有的最具体的分布式 RL 框架。
未来的探索领域
在最近一次 Dwarkesh Patel 播客中,谷歌传奇程序员 Jeff Dean 和 Noam Shazeer 推测了未来构建高度模块化模型的方法。他们的一些想法对于分散训练和微调的应用非常有吸引力。而且由于分散训练领域还很年轻,我想将其中一些推测纳入本报告,它或许可以作为我们想构建哪种类型的网络的有用指南。
在谈话的最后,Dean 和 Shazeer 讨论了 AI/ML 发展的未来状态。似乎受到他们在 Pathways 上工作的影响,他们想象了一个世界,其中稀疏的 MoE LLM 可以分成专家的模块化细分,每个部分都可以单独进行训练和改进。然后可以将这些部分交换到更大的模型中以扩展其功能。
虽然这在今天绝对不可能实现,但它描绘了一个令人兴奋的未来,你可以将一个模型拆分成更小的专家部分,使用强化学习使这些专家块更好地完成一项任务,然后将它们重新组合成一个更大的模型。这个过程将是高度可并行的,因为世界各地的人们可以同时致力于改进和更新模块。这显然可以很好地转化为大规模的分散强化学习。
Gensyn 朝着实现这一未来迈出了一步。在他们最近的论文《HDEE: Heterogeneous Domain Expert Ensemble》中,他们展示了你可以并行训练小型、异构和模块化专家模型,然后通过一种名为 ELMForest 的技术将它们连接到一个集成中。研究人员表明,这些集成虽然推理效率较低,但优于用较少异构性训练的模型。
这并不是 Dean 和 Shazeer 梦想的实现 —— 最终的集成不是一个单一的模型,而是产生独立输出的独立网络,这些输出在推理后组合成统一的答案。虽然全面深入探讨差异和未来方向超出了本文的范围,但这是一个相当令人兴奋的发展,并且引出了一个问题,即它是否可以与 RL Swarm 合并以创建更高效的领域专家。我非常期待想看到这项研究随着时间的推移将如何发展。
展望未来
虽然围绕去中心化强化学习的某些工作似乎有些牵强,但令人兴奋的探索已经开始。Hugging Face 正在开发 Open R1,这是一个旨在构建完全开源版本 R1、数据集、训练程序等的项目。Prime Intellect 已经在努力通过他们的 SYNTHETIC-1 运行以半分布式方式复制 DeepSeek-R1 的训练。他们已经完成了分布式数据收集并正在进入训练阶段。
本文的开头讨论了 DeepSeek 如何引起人们对基于 GRPO 的强化学习中一种新的扩展方法的关注。虽然有一些开创性的论文为训练和 TTC 的特定、普遍认可的扩展原则奠定了基础,但我们仍不知道扩展强化学习的局限性。需要多少数据和什么类型的数据才能获得最有效的 SFT?可以将基于 GRPO 的强化学习扩展到多大规模以将模型性能推向极限?基础模型的性能必须有多好才能获得强化学习的好处?我们尚不确定这些问题的答案,但我们已在进入人工智能创新的新阶段,这将在 LLM 扩展中对 RL 进行测试。
而去中心化、众包激励的网络将在其中发挥作用。
...
#浅析主流 Alignment 算法与 NeMo-Aligner 框架
文章详细分析了NeMo-Aligner在PPO流程中的优化策略,包括推理加速、显存优化以及不同引擎之间的协同工作,同时探讨了其在训练效率和可扩展性方面的表现。
今年 10 月在费城开 COLM 的时候,我有幸见到了 NVDA 两篇工作的 post,一篇是 RULER,现在已经是 long context 几乎必测的 benchmark;另一篇便是今天要讨论的工作——NeMo-Aligner。
https://github.com/NVIDIA/RULER
https://github.com/NVIDIA/NeMo-Aligner
Aligner 这个名字自然是非常恰当,毕竟“Aligner 并不试图贡献新的 Alignment 算法,而是专注于如何集成更多的 Alignment 算法”。所以,我姑且就用 Aligner 这一名字称呼这一系列的工作:
- DeepSpeed-Chat——微软;
- NeMo-Aligner——NVDA;
- OpenRLHF——开源社区;
- veRL——字节;
https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/README.md
https://github.com/NVIDIA/NeMo-Aligner
https://github.com/OpenRLHF/OpenRLHF
https://github.com/volcengine/veRL
虽然 Aligner 是为了各类基于 RL 的 Alignment training 而生的,然而这些算法会有相当一部分时间用于推理(rollout),所以推理引擎社区也乐于关注 Aligner 工作的进展和需求。在下文中,我也会尽力从我的认知水平出发,讨论 Aligner 对于 Inference Engine 的需求。
Introduction
- Nemo-Aligner 是一套集成了主流对齐算法的 toolkit,涵盖 RLHF / DPO / SteerLM 和 SPIN。能够有效调度千卡规模的计算资源,完成 Llama 4.1 405B 这种规模模型的训练。此外,toolkit 也支持 PEFT。作者希望这一框架足够 extenable,不过考虑到 RLHF / DPO 的差距已经非常大了,能复用的部分有限。个人感觉想要 support 一个新的算法还是比较困难。
- 当前的 Alignment 算法基本还是地主的赛场,需要显著的计算资源。譬如 PPO 算法的计算流中,需要同时有四个模型进行复杂的交互。如果用 405B 的模型同时充当这四个模型的 base,在不进行优化的情况下,动用的资源可以简单算一算。
70B 模型用 FP16:140GB
4 个彼此交互的模型:140GB * 4 = 560GB
Adam:每个参数需要 8 个字节(两个动量):70B * 8bytes = 560GB
Critic 和 Policy 同时都需要训练,所以需要两个优化器 = 1120GB
激活值和梯度:保守估计是模型大小的 1.5 倍,大概 210GB
KL 散度和其他各类开销:保守估计 200GB
大概 2100GB,也即 3 台 80G A100 ???- 基于我不严谨的计算,可以发现运行这样的 aligner 框架的开销非常恐怖。据此,Nemo-Aligner 需要在系统上下大功夫。首先,在 Megatron-LM 上 continue,支持 distributed 3D (data, tensor, pipeline) parallelism training。再者,在 rollout(可以理解为 sampling 阶段)使用 TensorRT-LLM 来做 inference,毕竟目前 trt-LLM 的推理效率确实是 SOTA。(而且也是英伟达自家的产品 )
Model Alignment BackgroundSFT
pre-trained / base model 通过 Supervised Fine-Tuning 的方式来迫使模型基于 cross-entropy mimic 人类期望的回答。SFT 对于 DPO / RLHF 是必须的,因为不做 SFT,模型几乎无法 follow 人类指令。这一过程也被称为 behavior cloning。
RLHF
- 这是今天的主角。RLHF 避免了显式为 RL 定义 reward function,转而通过 reward model 给出的 judgement 作为 reward。reward 模型从一组 pairwise dataset 中训练得到,一个 instruct 给出两个 response,其中一个标为 chosen,另一个标为 rejected。reward model 的 loss 基于 Bradley-Terry 模型得到,尝试让 Reward(chosen) > Reward(reject) 的概率尽可能大。RLHF 有两大主流方法,一种是 REINFOCE(1992),相对古老;而 NeMo-Aligner 更倾向于 PPO(2022)。
- 下图一定程度表示了 PPO 的过程,这里尤其需要注意到模型参数是否会被训练。事实上,如前文所述,SFT Model、Policy / Actor、Reward Model、Value / Critic 这四个模型都会在计算流中被使用。其中 SFT 和 Reward 是 inference only 的,而 Policy 和 Value 会被更新。
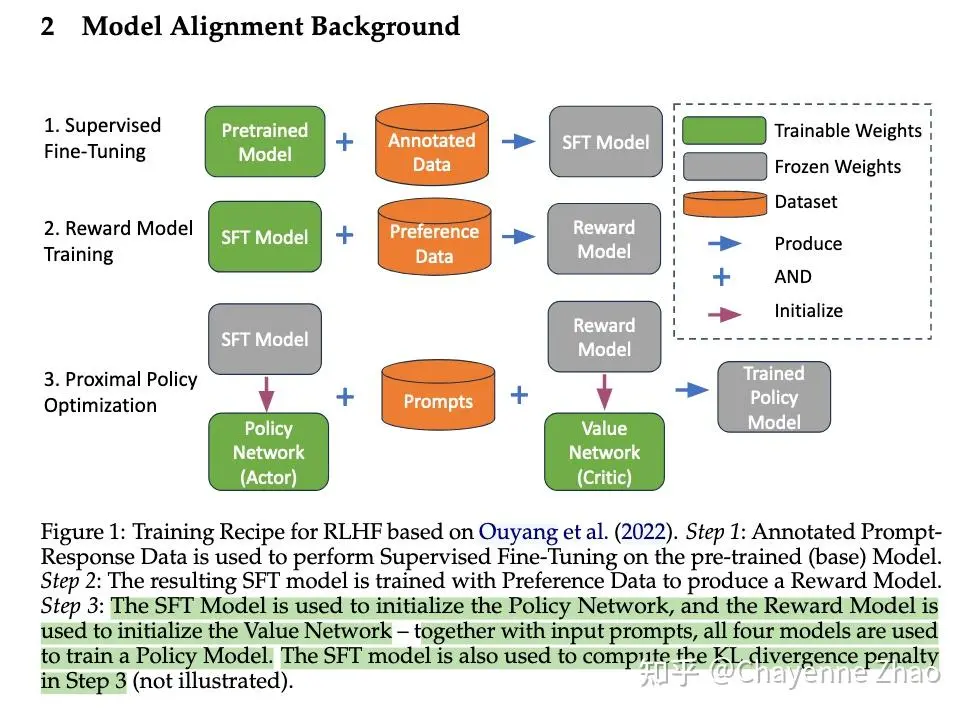
- SFT 已经论述过了,简单提一下 Reward Model Training。一般而言,reward model 会在 SFT model 基础上加上一层 linear layer,然后连同这个 linear layer 训练,将 linear layer 的 final project value 作为 reward。(在 SGLang 中体现为 classify 接口)
https://sgl-project.github.io/backend/native_api.html#Classify-(reward-model)
- 计算流可以如下概括:
1. 初始化:SFT model 初始化 Actor,Reward Model 初始化 Critic;
2. Rollout / 生成输出:Actor 对输入的 Prompts 生成相应 / responses。
3. Reward Compute / 计算奖励:Reward Model 对生成的 responses 进行评分,提供 reward 得分。
4. 价值评估与更新:Critic 计算当前 responses 的价值(注意是 value 而非 reward),然后基于 value
和 reward 计算优势函数(advantage function),最终确定 Actor 的更新方向和幅度。此外,Critic
也会在这一步进行更新,减少其预测的 value 和实际奖励之间的误差,从而提高下个状态 value 的精度。
5. Advantage funciton 的值最红会用于优化 Actor,同时这步更新需要基于 SFT Model 的 logits 计算
KL 散度并且加以惩戒,避免 Actor 相较于 SFT model 偏离太远,走到了 Reward Model 的盲点 / blind
spots 上。DPO
- DPO 是和 PPO 同样声名大噪的对齐方法,这是一种 offline, off-policy 的对齐方法。试图直接将模型对齐成为符合偏好的最佳 policy 而避开了显式需要一个 reward model。这也是其名字的由来:Your Language Model is Secretly a Reward Model。(PS:最近发现有好几个给论文起名的新 pattern,譬如 XXX is All You Need,XXX is Secretly a YYY,XXX Empowers XXX,最后还有 Make XXX Great Again )
- 相较于使用隐式的 reward model,DPO 更为激进地选择使用 reference policy 通过 Bradley-Terry Mdel 隐式推导出 chosen / reject pair 之间的 reward。具体来说,通过计算 chosen/ reject pair 之间的对数概率差值来得到 reward,而该差值又由 optimal and reference policies 共同计算。这样的差值又通过 scaling 并且经过 sigmoid 得到最终的 loss。训练过程中,reference policy 固定不动,仅用于构造 chosen / rejected responses。
SteerLM
- SteerLM 和 DPO 类似,避免复杂的 RL 方式,仅仅是 supervised finetuning。
- 计算流如下:
1. 训练属性属性预测模型 / Attribute Prediction Model(APM),用于给定一个输入 prompt,给出多个语义评分。
譬如对 correctness、toxicity 分别打 0 ~ 4 分。
2. 利用 APM 标标注 prompt-response pair,得到属性分。
3. 做 SFT:输入是 prompt + 属性分字符串,模型学习对给定 prompt 和属性分目标生成相应的 response。
4. 推理的时候,在 prompt 结尾加上需要的属性分即可。- 听上去真的是比其他方法简单多了,避免了 Reward Model 和 PPO 训练的复杂性,将属性对齐问题转为了显式的条件对齐。不过,猜测效果不是那么好
Self-Play Fine-Tuning
这是我们组的工作 ,不由得说影响力真不错。SPIN 和 DPO 类似,绕开了显式使用 reward model(注意到 reward model 的意义在于绕开了显式使用 reward function )。SPIN 方法中,strong model 会从一个 weak model 的自我博弈中迭代而来。具体而言,给定一个 prompt / response pairs,让 weak model 对 prompt 进行一次新的标注,得到 prompt / (response, generated response) 这样的 preference data。然后,policy 在这样自我合成了一般数据的 preference pair 上训练,使其对于给定的 prompt,其偏向 response 的概率高于偏向先前自我构造的 generated response。这里需要用到 preference loss function,而这样的 preference loss function 和 DPO 中使用的 loss function 一模一样。
Online / Offline vs On-policy / Off-policy
作为强化学习白纸,这里记录下自己理解的概念。
1.On-Policy vs Off-Policy:用于收集经验的策略(behavior policy)和被优化的策略(target policy)是否是同一个。 On-Policy 使用当前正在学习的 policy 收集数据,数据只能使用一次,用后即弃,更加稳定容易收敛;但是数据利用率低,构造数据成本高昂,典型算法有 PPO 和 SARSA。而 Off-Policy 可以使用任意的 policy 来构造数据,可以复用历史数据,可以使用外部策略(如人类)的数据,数据利用率高,但是训练可能不稳定,需要复杂的重要性采样,典型算法如 Q-Learning,DQN,SAC。
2.Online vs Offline:算法是否需要在训练过程中与环境交互。 Online 算法在训练过程中不断与环境交互,实时收集数据,动态调整策略,可以更适应环境变化,然而实时访问的风险和成本较高。典型场景有实时控制、在线决策。Offline 算法又称为 Batch RL,只使用预先收集的数据集,训练过程不与环境交互,类似于监督学习。安全,不需要实时环境,但是受限于数据质量,难以处理分布外的情况。
3.PPO 是 online on-policy 的;但是对于 Online 而言,我和组里的同学讨论,这个定义可能没那么严格。Online 的特点可能是小批量大轮次,比如 SPIN 中一轮 1w 个 preference data 然后 train 3 个 epoch,而典型的 PPO 可能是 64 个 preference data train 成百上千轮,所以 SPIN 可能不是典型的 Online。
4.【from 我们组的学长】从 RL 的角度来看,是否从当前 policy 采样决定是否是 on policy;而是否和环境交互决定是否是 on line。这种界限并不清晰,没必要纠结,知道在描述什么即可。
NeMo-Aigner For RLHF / PPO
- 讨论了非常久的 alignment background,现在我们回到 NeMo-Aligner 上。之后的解析(对 OpenRLHF 和 veRL)应该不会涉及 RL 背景了。RLHF 的流程如本文第一张图所示,而主要的开销还是在 PPO 流程中,具体而言是 rollout。

- 如前文所述,PPO 过程需要 4 个模型组件参与整个流程。
a. PPO Actor:训练且推理,由 SFT Model 初始化而来,是 PPO 最终希望得到的微调结果。
b. Reference Policy:仅推理,一般设置为 SFT Model 本身,不进行任何修改。在 PPO 过程中,Actor 会
Reference Policy 同时计算 logits【这里会在后文论述】,然后计算 KL 散度,防止模型过度偏移。
c. PPO Critic:训练且推理,从 reward model 初始化而来,在 PPO 中计算 value【并非 reward】。
d. Reward Model:仅推理,对 Actor 产生的 rollout data 提供 rewards。
- 上述四种 model 都可以任意大小,因此 NeMo-Aligner 实现了分布式训练,通过 PyTriton 启动 server 和 client,从而不再要求 critic 和 actor 在同一个节点上。
- 直观上,可以启动四个模型 server 来同时 host 四个组件。然而,注意到 PPO Actor 和 Reference Policy 实际上是同一架构同一参数量的模型,不过参数会有所更新。因此,NeMo-Aligner 将二者组合在同一个 job 上。二者不同时使用,所以可以将其中不用的一个 offload 到 DRAM 上,推理时再异步 swap 回来。【这里也有很深的文章可以做,后文分析】这种 offload and swap 的策略在 PPO Critic 和 Reward Model 上也同样适用。
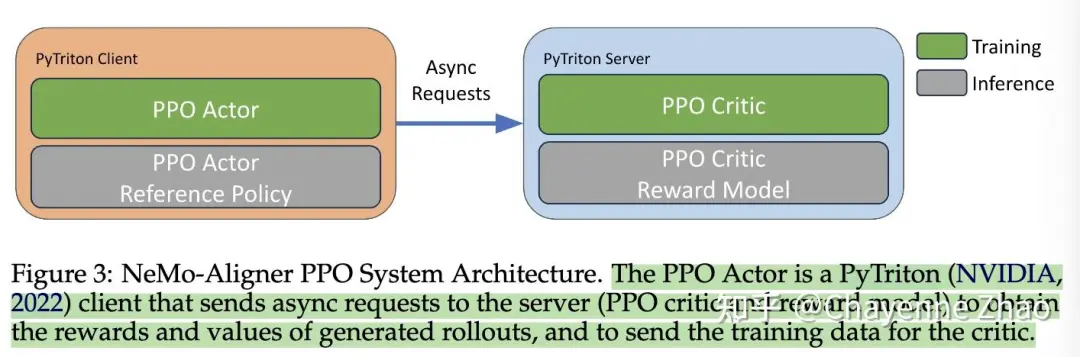
- Response generation 占据了 PPO 全流程的主要时间。显然,我们可以采用 inference engine 来加速这样的 generation。为什么不可以用 training engine 的 forward 来进行 generation 呢?这个问题问的看似愚蠢,仔细想想,为什么我们没有用 training engine 来做 inference,比如直接拿着 deepspeed 的 forward 来做推理,反而要单独设计推理引擎呢?其实还是推理的计算特性所致。
https://zhuanlan.zhihu.com/p/4148050391
- 在之前的文章(上方链接到的文章)中有提到,inference(或者说占据主要时间的 decode)是 autoregressvie 的,每个 token 依赖于前序所有 token,所以无法单个 sequence 的 decode 是无法并行的(能组起的 batch 都是多个 sequence 的 continuous batching),从而计算密度并不高。另一方面,decode 阶段需要进行大量的内存读取和数据传输,对通讯要求较高。总归,inference engine 是主要被 memory bounded 的。 而 training engine 则不然,training engine 的 batch size 可以开的非常大,直到打满 engine 的计算能力,从而使 compute bounded 的。 因此,用 training engine 来做 inference 并不科学。(尽管我的本科写过的作业从不考虑这个问题 )
- 如上所述,我们已经发现,对于 PPO 中的四个 components,我们分别需要 inference engine 和 trainning engine,彼此优化各自的计算目标。现在考虑这个问题:为了计算 KL 散度需要得到 reference policy 和 actor 分别的 logits,这个 logits 该由什么 engine 得到?显然,inference engine 得到 logits 快很多,而且现代引擎都支持这个请求。然而,目前 inference engine 得到的 logits 精度是更低的,不应该来计算 KL 散度。更科学的方法是用 trainning engine 得到二者的 logits 来计算 KL 散度。
- 至于为什么 inference engine 的 logits 精度更低,这也是为了 inference 速度做出的牺牲。直观上来说,continuous batching 组的 batch 越大,精度”飘“的更厉害。即便 batch size 写死为 1,也不够准确。
- 考虑到 engine 启动的开销很大,PPO 过程中任意 engine 都不应该被关掉。这无疑带来了更大的显存压力,为此 NeMo-Aligner 在反向传播时重新计算 training 阶段的激活值,减少了峰值显存压力。此外,inference 需要的显存小于 training,所以在单个节点的显存允许时,NeMo-Aligner 在 inference 时只采用 tensor parallelism,避免了 pipeline parallelism 带来的跨节点通讯开销。
- 在随后的迭代训练过程中,inference 的 engine 需要与 training engine 更新过的参数进行同步。【这里有很大文章】为了实现这样的同步,inference engine 使用了 Tensor RT Refitter 来进行 in-place update,而不是关掉 engine 重启新的(我在开会的时候就觉得这个优化非常重要,尽管当时我并不理解其重要性,但是最近越发理解这个接口几乎是 dominate 的)。最后,rollout 阶段不同 inference engine 的 latency 也不尽相同,所以 NeMo-Aigner 又为此设置了一个 router,真是工程量可怕。
训练实际表现与 Scalability
- 这张图很有意思。首先,纵向比较,显然我们发现 Rollout 阶段的 response generation 占据了过半数的时间。另一方面,横向观察第二行,我们注意到当计算资源线性增长时,不同阶段的效率增长不尽然相同。Response generation 近乎是超线性的 ,而 logits 计算显然是亚线性的。
- 具体而言,training 开销是亚线性的,因为随着节点增加,每个 data parallel rank 的 micro-batch size 减少,计算利用率降低。而在 pipeline parallelism 中,流水段必须在 optimizer 调用之前完成,由此带来了填充和清空流水线的开销,且这一开销和 mirco batch 大小无关。所以 mirco batch 减小,流水线的计算用时减小,填充和清空开销增大,所以计算利用率降低,增长亚线性。计算 logits 也是类似的。(原文这里其实也暗含了 logits 是 trainning engine 得到的,然而没有明示 )
- generation 的开销是线性的,一方面是 router 做的足够好,response 近乎被等分给了每个 engine,这是线性的。此外,inference 的开销可能会稍微增大,毕竟 KV Cache 被复用的次数少了,然而整体上影响很小【感觉自己有点扯淡了 】。0generation 随着更大计算资源的投入,几乎是线性增长的。
- 当然,engine 的 weight update 开销并不能降低,原因显然。至于 actor 和 critic 之间,由于是异步通讯的,actor 几乎不需要等待 critic 的上一轮相应,也不存在开销了。
- 如下图所示,为了进一步说明每个 feature 带来的加速,作者做了分 component 的 ablation。去除 Trt-LLM 集成后,PPO 每一步的开销增加了 7 倍。接着,在推理阶段使用 pipeline parallelism 导致开销增长 4 倍,inference engine 不断重启带来了 3 倍开销,而不使用异步请求会导致 1.5 倍开销。反过来,router 看上去并不重要,可能这和 PPO rollout 的样本量有关。一轮就 128 个 sample,router 的优化似乎弥补不了其开销 【但我相信对于 SPIN 而言不是这样的,因为 PPO 是小批量多批次,而 SPIN 是大批量小批次】

- 剩下的部分就快速写过了。作者在 trainning SteerLM 的时候用了 LoRA,惊奇发现 LoRA 带来的损失几乎没有超过 benchmark 的误差范围。
- 作者在 SPIN 中,仅进行了一个 epoch 的训练,并且不将先前轮次的 sample 使用到下一轮,避免了 datset size 每次都翻倍。
Remain Question
之所以来学习以 NeMo-Aligner 为代表的 Aligner 框架,是因为有收到 OpenRLHF 团队的反馈,希望能够将 SGLang 集成到他们的框架中去。前文已经提到了,有一些地方可以做文章的。
- 如何从 actor 和 reference policy 拿到更准的 logits?目前需要通过 training engine 而非 inference engine。不过,对于 inference engine 而言,有什么是我们能做的呢?
- 如何提供 Reward Model 的通用接口?直接在 SFT model 的 last layer 加上一个 linear head 再训练一番即可作为 reward model。推理引擎能为此提供更好的接口么?
- 如何做更好的 weight update?四个模型需要两套 engine,如何从 Training Engine 上调用鲁棒的 Inference Engine Weigtht Update 接口呢?目前 OpenRLHF 集成 deepspeed 和 vllm,经常因为二者的 depedency 和更新带来很大的问题,我们能做些什么?
...

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 31
31 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)