深度学习笔记2-机器学习基础
在1000次预测中,假若算法预测有5次发生地震,结果只发生了1次,但是这1次是准确的,那么灵敏度则为1/1=100%,因为实际只有发生一次,输入为正的的样本数量P=1,正确率由99.9%降为99.6%是可接受的,全连接神经网络(Full Connected Net,FCN)为例,全连接层是指第N层的每个神经元和第N-1层的神经元相连,第N-1层神经元的输出就是第N层神经元的输入,中间还包含有中间层
机器学习结和了多个学科,如概率论、优化理论、统计学等,最终在计算机上实现了自我获取新知识,学习改善自己。机器学习时人工自能的一个子集,目前已经发展出了许多有用的方法,比如支持向量机、回归、决策树、自动化、自动决策、最优化等初步替代脑力的任务。
2.1 基本概念
机器学习:通过从经验中学习,能够让计算机通过算法够提取数据中所蕴含的规律,并利用这些规律来做出预测、决策或执行任务,就叫机器学习(Machine Leaning,ML)。如果输入机器的数据是带标签的,就称为监督学习;如果数据是不带标签的,就称为无监督学习。
神经网络:就是按照一定规则将多个神经元连接起来的网络,也就是一个网络中的数据受前一个网络中的一个或多个神经元(数据)影响。不同的神经网络,具有不同的连接规则。
全连接神经网络(Full Connected Net,FCN)为例,全连接层是指第N层的每个神经元和第N-1层的神经元相连,第N-1层神经元的输出就是第N层神经元的输入,中间还包含有中间层,对于卷积神经网络来说,中间层就是各种卷积核,可以是一层或者多层。
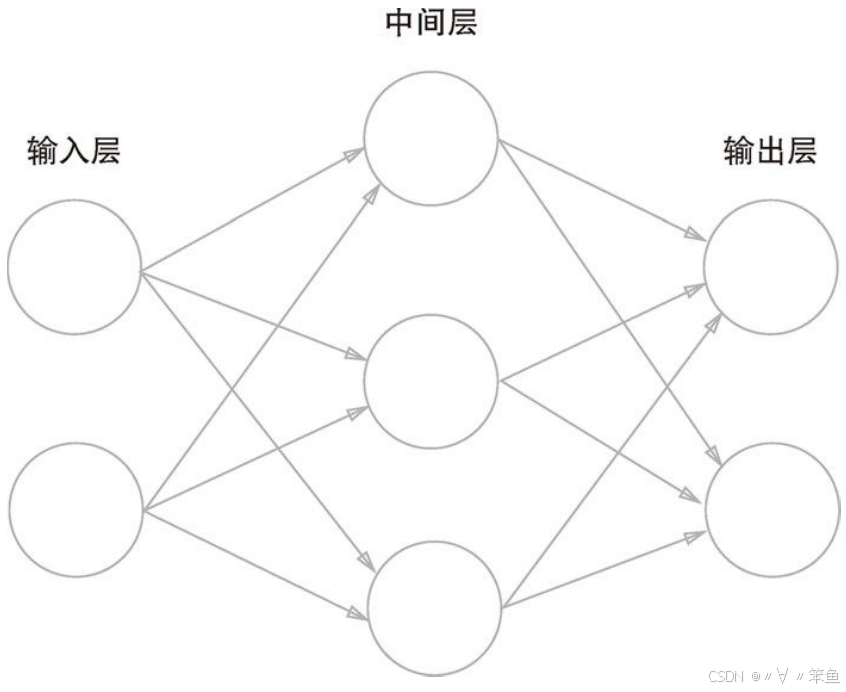
以图片识别中猫狗识别为例,在图1中输入猫狗图片,通过中间层的各种信息判断后,输出层输出猫和狗的概率,选择输出概率高的结果。
2.2 机器学习方式
依据不同的学习方式和输入数据,机器学习主要分为监督学习、非监督学习、半监督学习和弱监督学习。输入数据带有标签的,为监督学习;不带标签的为非监督学习;部分带标签,并对不带标签的进行预测,为半监督学习。标签数据不可靠的,这里不可靠指标记不正确、不充分、多种标签、局部标记等。
知道有这几种分类就行,没有明确分界线,比如图像识别中输入带猫狗标识的图片,如果只需要输出猫狗的类型的,就是监督学习;如果还想要猫狗在图片中的位置信息,则变成了弱监督学习,因为需要输出多种类型,而输入的标签只有名称,而没有对位置信息的标记。
2.3 监督学习模型和搭建步骤
1)数据集的创建和分类:对猫狗图片分别进行标注,可以是图片名称来分类。将所有图片分为训练集和验证集,验证集不参与训练,只是为了验证训练结果能否识别训练集中的图片,以及图片识别准确率,一般训练集和数据集采用不同的图片。
2)数据增强:在原始数据采集和标注完毕后,进行训练之前,对图片进行裁剪、旋转、拉伸、颜色变换等操作,获得更多的训练数据。也可以加入随机噪声。
3)特征工程:一般来讲,特征工程包含特征提取和特征选择。由于手工特征是启发式的,其算法设计背后的出发点不同,将这些特征组合在一起的时候有可能会产生冲突,因此将组合特征的效能发挥出来,是原始数据在特征空间中的判别性能更大化,就需要特征选择方法。在深度学习大获成功之后,对特征工程本质概念的关注度就明显降低了。因为最常用的卷积神经网络(Convolutional Neural Network,CNN)本身就是一种特征提取和选择的引擎。研究者提出不同的网络结构、正则化、归一化方法实际上就是深度学习背景下的特征工程。
4)构建预测模型和损失函数:为保证模型的输出和输入的一致性,就需要构建模型预测和标签之间的损失函数,常见的损失函数(Loss Function)有交叉熵、均方差等。通过优化方法不断迭代,使模型的输出结果逐渐向标记的结果靠近,实际上就是一个学习(拟合)的过程。
5)训练:选择合适的模型和超参数进行初始化,通过合适的优化方法不断缩小输出与标签之间的差距,但迭代结果满足截止条件,就可以得到训练好的模型。优化方法常见的就是梯度下降法及其各种变种。
6)模型验证:用测试集数据来进行模型测试,看训练好的模型能否准确地输出对应的标签信息。
7)测试及应用:部署到应用中,并进行测试后发布API(Application Programming Interface,应用程序编程接口)调用。
2.3 分类算法
分类算法(离散模型)和回归算法(连续模型)是对真实模型的不同方法,取决于任务的分析和理解。
常见的分类算法有:贝叶斯分类法(Bayes)、决策树(Decision Tree)、支持向量机(SVM)、K近邻(KNN)、逻辑回归(Logistic Regression)、神经网络(Neural Network)、自适应增强算法(Adaptive Boosting Algorithm)
分类算法的评估,常见的模型评价术语(以两分类为例,正和负两类):
1)True Positives(TP):分类结果正确(True),实际(输入)为正,划分(输出)为正。
2)False Positives(FP):分类结果不正确(False),实际(输入)为负,划分(输出)为正。
3)True Negatives(TN):分类结果正确(True),实际(输入)为负,划分(输出)为负。
4)False Negatives(FN):分类结果不正确(False),实际(输入)为正,划分(输出)为负。
从上面可以看出,T/F判断分类是否正确(对错),Positives/Negatives是输出的分类正负(类别)。TP+FN表示实际(输入)为正的样本数量P,同理FP+TN为实际(输入)为负的样本数量N,加起来就是样本总数(P+N)。
正确率(accuracy)=(TP+TN)/(P+N),错误率(error rate)=(FP+FN)/(P+N),正确率+错误率=1,为互斥事件。
灵敏度(sensitivity)=TP/(TP+FN)=TP/P,表示输入为正的结果中分类正确的比例;特异性(specificity)=TN/(FP+TN)=TN/N,表示输入为负的结果中分类正确的比例。
精度(precision)=TP/(TP+FP),表示输出结果为正中分类正确的比例。
召回率(recall)=TP/P=灵敏度,表示有多少个输入为正的,在输出时分类为正。
其他评价指标:计算速度(包含训练和预测所需要的时间)、鲁棒性(处理缺失值和异常值的能力,稳定性)、可扩展性(处理大数据集的能力)、可解释性(预测标准的可理解性,或者可视化程度)
举个例子来说明各种评估指标:
假如对某个地区进行地震预测,1代表发生地震,0代表不发生地震。如果以正确率来作为评估指标的话,那么分类算法就会无脑地输出不发生,也可以保持很高的正确率,因为地震不发生的概率是很大的,这就是在概率分布极不均衡的情况下,考虑准确率的弊端。若使用灵敏度(召回率)来评估的话,也就是在准确率不会降低很多的前提下,允许一定程度的误报。在1000次预测中,假若算法预测有5次发生地震,结果只发生了1次,但是这1次是准确的,那么灵敏度则为1/1=100%,因为实际只有发生一次,输入为正的的样本数量P=1,正确率由99.9%降为99.6%是可接受的,宁愿犯错也不愿什么都不做。如果是大概率为1(正例),而小概率为0(负例)的情况,则考虑用特异性来评估,例如将地震发生和不发生调换一下。同样以地震是否发生来进行预测,精度代表着分类算法关注的是输出结果的准确性,可以漏报,但是不能错报,宁愿错过也不犯错。
2.4 逻辑回归
如果服从二项分布,就是逻辑回归,逻辑回归的因变量可以是二分类的,也可以是多分类的,但是二分类更常用,也更容易理解。主要用于一下几个方面:
1)概率预测:也就是最大似然估计,用实际数据来估计事件发生的概率,比如统计抛硬币正反面数量,当然这是很简单的模型,一般用来处理多参数情况下的概率估计。
2)用于分类:实际上也是概率预测,例如预测猫狗分类,实际就是预测图片是猫还是狗哪个概率更大。
3)缺陷检测:寻找缺陷、疾病等,用于工程检测、医学图像等。
4)仅能用于线性问题:也就是目标和特征线性关系,特征变化量和目标变化量成固定比例,而不随着位置变化。
逻辑回归和朴素贝叶斯都是常用的分类算法,但它们的原理和应用场景不同。逻辑回归是判别式模型,直接学习特征与标签之间的决策边界,适合处理特征相关且数据量大的问题,但计算复杂度较高;朴素贝叶斯是生成式模型,基于特征条件独立的假设,通过概率估计进行分类,适合特征独立或数据量小的场景,计算简单高效。选择哪种算法取决于数据特性和问题需求。
线性回归和逻辑回归是两种常用的回归分析方法,但它们的应用场景和模型形式不同。线性回归用于预测连续值(如房价、温度),模型是线性函数,输出没有范围限制;逻辑回归用于分类问题(如是否患病、邮件是否为垃圾邮件),模型通过逻辑函数输出概率值(范围在0到1之间),通常用于二分类或多分类任务。选择哪种方法取决于问题是回归还是分类。
2.5 代价函数
代价函数(Cost Function)和目标函数(Objective Function)在机器学习和优化问题中密切相关,但侧重点不同。代价函数用于衡量模型预测值与真实值之间的误差(如均方误差或交叉熵损失),是模型性能的直接度量;而目标函数是优化问题的总体目标,通常包括代价函数以及其他附加项(如正则化项),用于在优化过程中同时考虑模型性能和复杂度控制。简单来说,代价函数是目标函数的核心组成部分,但目标函数可能包含更多优化目标(如防止过拟合)。
二次代价函数(添加了L2正则化项):
对权值和偏置
求偏导:
采用梯度下降更新和
:
其中和
表示学习率和正则化系数。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
# 生成数据
np.random.seed(42)
X = np.random.rand(100, 1)
y = 3 * X + 4 + np.random.randn(100, 1) * 0.5 # y = 3x + 4 + 噪声
# 初始化参数
w = np.random.randn(1)
b = np.random.randn(1)
learning_rate = 0.1
lambda_reg = 0.1 # 正则化系数
n_epochs = 200 # 训练轮数
# 创建画布
fig, ax = plt.subplots(figsize=(8, 6))
ax.scatter(X, y, color='blue', label='Data points')
line, = ax.plot(X, w * X + b, color='red', label='Fitted line')
ax.set_xlabel('X')
ax.set_ylabel('y')
ax.set_title('Dynamic Fitting Line')
ax.legend()
# 添加文本标签显示训练轮数
epoch_text = ax.text(0.02, 0.95, '', transform=ax.transAxes, fontsize=12, color='black')
# 更新函数
def update(epoch):
global w, b
# 更新训练轮数文本
epoch_text.set_text(f'Epoch: {epoch + 1}/{n_epochs}')
# 预测值
y_pred = w * X + b
# 计算梯度
dw = (-1/len(X)) * np.sum(X * (y - y_pred)) + lambda_reg * w
db = (-1/len(X)) * np.sum(y - y_pred) + lambda_reg * b
# 更新参数
w -= learning_rate * dw
b -= learning_rate * db
# 更新拟合直线
y_pred = w * X + b
line.set_ydata(y_pred)
# 返回需要更新的对象
return line,epoch_text
# 创建动画
ani = FuncAnimation(fig, update, frames=n_epochs, interval=50, blit=True, repeat=False)
# 显示动画
plt.tight_layout()
plt.show()如果要添加激活函数,例如Sigmoid函数,模型的预测值为:
代价函数(带L2正则化)为:
其他还有交叉熵代价函数、对数似然代价函数等。
损失函数 (Loss Function)计算的是单个样本的误差,代价函数计算的是整个训练集上所有样本的误差的平均误差。常见的损失函数有0-1损失函数、绝对值损失函数、平方损失函数、对数损失函数、指数损失函数、Hinge损失函数等。
2.6 梯度下降法
梯度下降法(Gradient Descent,GD)是一个最优化算法,常见于机器学习和人工智能中递归性逼近最小偏差模型。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 51
51 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)