人工智能基础知识笔记三:假设检验
P值(P-value)是假设检验中用于判断原假设是否成立的一个概率值。它表示在原假设成立的前提下,观察到当前数据或更极端数据的概率。如果P值小于预先设定的显著性水平α(通常为0.05),则拒绝零假设。
1、假设检验的基本思想
假设检验问题就是在原假设H0和与原假设对立的备择假设H1中作出拒绝一个、接受哪一个的判断,是统计理论中基于“概率反证法”和“小概率原理”提出的假设检验方法。
1.1小概率原理
概率很小的事件一般在一次试验中不会发生,如果小概率事件在一次试验中竟然发生了,则事属反常,有理由怀疑原假设条件不成立。
1.2 概率反证法
概率反证法的思想:首先对总体的参数或分布函数的表达式作出某种假设,然后找出一个假设成立条件下出现可能性甚小的小概率事件A,如果在一次试验或抽样的结果中小概率事件发生,这与小概率原理相违背,表明假设H0不成立,拒绝,接受备择假设H1。若小率事件A没有发生,表明试验或抽样结果支持这个假设,这时称假设H0与实验结果是相容的,或者说,可以接受原假设 H。
概率反证法的依据是“小概率原理”。那么多小的概率才算小概率呢?显然,“小概率事件”的概率越小,拒绝原假设就越有说服力,常记这个概率值为α,称为检验的显著性水平,该检验称为显著性检验。
对于不同的问题,检验的显著性水平α不一定相同,但一般应取较小的值,如0.1、0.05或 0.01等,例如 α=0.05 时,表示有 95%的把握拒绝原假设 H0。显著性水平a越小,拒绝原假设就越有说服力。当检验统计量落入某个区域C中时,拒绝原假设H0,则称区域C为拒绝域拒绝域的边界称为该假设检验的临界点。
1.3 决策原则
- 拒绝零假设(Reject H0):当有足够的证据表明零假设不成立时,选择拒绝零假设,接受备择假设。
- 不拒绝零假设(Fail to Reject H0):如果没有足够的证据否定零假设,则选择不拒绝零假设。注意这里不是说接受零假设,而是没有足够证据去否定它。
2、假设检验的类型
根据拒绝域在接受域的两侧或者单侧,分为:双侧检验,左侧检验和右侧检验。
2.1 左侧检验
H0:μ>μ0 H1:μ<μ0
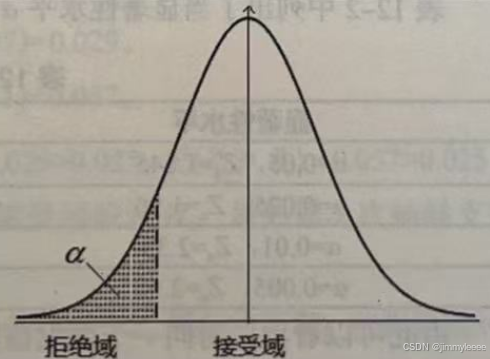
考虑左侧检验H0:μ≥μ0,H1:μ<μ0时,H0代表接受域,H1代表拒绝域,这里拒绝域的全部μ值都要比接受域中的μ值要小,因此拒绝域的形式为X≤k。
2.2 右侧检验
H0:μ<μ0 H1:μ>μ0
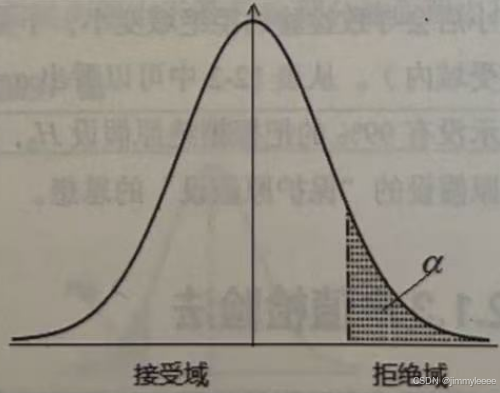
考虑左侧检验H0:μ<=μ0,H1:μ>μ0时,H0代表接受域,H1代表拒绝域,这里拒绝域的全部μ值都要比接受域中的μ值要大,因此拒绝域的形式为X>=k。
2.3 双侧检验
H0:μ=μ0,H1:μ≠μ0
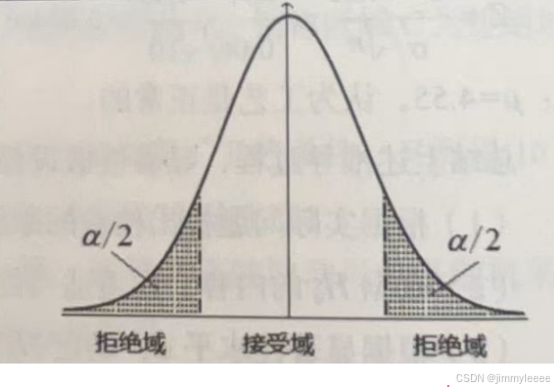
H0:μ=μ0,H1:μ≠μ0时,H0代表接受域,H1代表拒绝域。
3、检验的类型
3.1 p值检验
定义:
P值(P-value)是假设检验中用于判断原假设是否成立的一个概率值。它表示在原假设成立的前提下,观察到当前数据或更极端数据的概率。如果P值小于预先设定的显著性水平α(通常为0.05),则拒绝零假设。
公式:
P值本身没有固定公式,通常通过统计检验(如Z检验、t检验等)计算得出。
适用范围:
- 用于判断统计显著性。
- 通常与显著性水平(如0.05)比较,若P值小于显著性水平,则拒绝原假设。
3.2 Z检验
定义:
Z检验用于检验样本均值与总体均值是否存在显著差异。
公式:
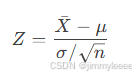
其中:
Xˉ是样本均值,
μ是总体均值,
σ是总体标准差,
n是样本量。
适用范围:
- 适用于大样本(通常样本量 n≥30)
- 总体方差已知
- 数据近似正态分布
3.3 t检验
定义:
t检验用于检验样本均值与总体均值是否存在显著差异。
公式:
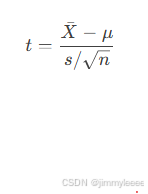
其中:
Xˉ是样本均值,
μ是总体均值,
s是样本标准差,
n是样本量。
适用范围:
- 适用于小样本(通常样本量 n<30)
- 总体方差未知
- 数据近似正态分布
3.4 卡方检验
定义:
卡方检验用于检验分类变量的独立性或拟合优度,适用于分类数据。
公式:
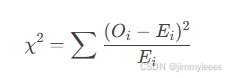
其中:
Oi 是观测频数,
Ei 是期望频数。
适用范围:
- 检验分类变量的独立性(如列联表分析)
- 检验样本分布是否符合某种理论分布(拟合优度检验)
3.5 总结
|
检验方法 |
适用场景 |
样本量要求 |
总体方差要求 |
数据类型 |
|
P值检验法 |
判断统计显著性 |
无特定要求 |
无特定要求 |
多种类型 |
|
Z检验 |
大样本均值检验 |
n≥30 |
已知 |
连续型数据 |
|
t检验 |
小样本均值检验 |
n<30 |
未知 |
连续型数据 |
|
卡方检验 |
分类变量独立性或拟合优度检验 |
无特定要求 |
无特定要求 |
分类数据 |
4、检验的两类错误
第一类错误是“弃真”:当假设H0正确时,小概率事件也有可能发生,此时拒绝假设,就犯了“弃真”的错误,称此为第一类错误。犯第一类错误是“小概率事件不会发生”的假定所引起的,犯错概率恰好就是“小概率事件”的发生概率,即显著性水平α。
P{拒绝H0 | H0为真 }=α
第二类错误是“取伪”:若假设H0 不正确,但在一次抽样检验结果中未发生不合理结果,这时接受H0,就犯了“取伪”的错误,称此为第二类错误。记β为犯第二类错误的概率,即
P{接受H0 | H0不真}=β
理论上自然希望犯这两类错误的概率都很小,但是当样本容量n固定时,拒绝和接受H0的不能同时小,即α和β不能同时都小,α和β的关系就像跷跷板,即α变小时,β就变大;β变时,α就变大。一般只有当样本容量n增大时,才有可能使两者变小。
第一类错误“弃真”出现原因:从总体中抽取样本时,存在多个样本平均值,由于样本抽样的随机性,恰好抽到的样本均值把本来真实的原假设拒绝了,这就是“弃真”错误出现的原因。
第二类错误“取伪”出现原因:如果原假设 H0是错误的,随机抽取的样本有可能落人接受域,导致假设检验的结果是接受原假设 H0,造成“取伪”错误。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)