聚类算法综述以及主流算法对比的研究课程作业【课程设计】
为聚类是知识发现中的一个重要内容,聚类是遵循“物以类聚、人以群分”的自然界规律,以现实数据为基础,依据一定的规律和策略,对数据进行聚集并最终形成簇的一种技术,从机器学习的角度来讲,聚类属于机器学习中的无师学习,也称为非监督学习或无监督学习,聚类算法是无师学习种的最重要的一类学习算法。
聚类算法综述以及主流算法对比的研究课程作业
今天分享几个课程设计,这是第一个。
摘要:为聚类是知识发现中的一个重要内容,聚类是遵循“物以类聚、人以群分”的自然界规律,以现实数据为基础,依据一定的规律和策略,对数据进行聚集并最终形成簇的一种技术,从机器学习的角度来讲,聚类属于机器学习中的无师学习,也称为非监督学习或无监督学习,聚类算法是无师学习种的最重要的一类学习算法。
本文首先通过阅读国内外关于聚类技术的相关文献,对相关那年和理论进行细致阐述和说明,在此基础之上从统计学和机器学习两个路径分别对聚类理论展开讨论,并分别选取原型聚类算法、密度聚类算法和层次聚类算法中的代表算法k-means算法、DBSCAN算法和AGNES算法,并对这些算法的算法思想和思路进行了汇总和阐述。最后,利用Anconda平台对这些算法基于iris数据集进行算法实验,实验表明,在iris数据集上进行聚类算法,k-means表现优于其他两个算法。
关键词:聚类分析;聚类;k-means;DBSCAN;AGNES
课程设计下载
一、前言
近年随着国家对信息产业尤其是人工智能和大数据相关产业的扶持力度加大,使得机器学习焕发新姿,机器学习有别于传统软件设计,传统软件设计是基于特定的输入,得到确定的输出,而机器学习则具备自我学习和持续学习能力。知识发现是机器学习中重要的一个分支,也是其他学科比如数据挖掘和统计学的研究内容,知识发现是基于已有的数据,通常是高纬度和大数量的数据,发现数据内在客观规律,并可以为人们的生成决策提供辅助信息,或者直接具备决策能力的一种新兴机器学习技术。
聚类是知识发现中的一个重要内容,聚类是遵循“物以类聚、人以群分”的自然界规律,以现实数据为基础,依据一定的规律和策略,对数据进行聚集并最终形成簇的一种技术,从机器学习的角度来讲,聚类属于机器学习中的无师学习,也称为非监督学习,相应地,借助于数据本身地标签来完成学习目的的学习过程叫做有师学习或者监督学习,介于有师学习和无师学习之间的称为半监督学习。
另一方面,统计学和多元统计中,聚类分析也是一门重要的统计方法和技术,聚类分析和回归分析、主成分分析、因子分析等统计技术构成了多元统计的组成部分。因此,聚类分析既是机器学习的重要组成,也是统计学必不可少的构成部分。
聚类在人们认识客观世界的过程中有分成重要的作用,聚类可以使得人们对食物的认识提高到一个更高的层次,可以方便对事物按照类别区别对待,有助于将事物既有区分,又有联系的来看待和研究,是人们认识客观世界的重要手段和方法,聚类分析技术在医疗诊断、多元统计、生物识别、图形图像等学科和领域都有重要作用,因此对聚类分析的研究和应用都现实意义。
二、文献综述
一直以来国内外对聚类方法的研究较多,主要是基于两大学术流派开展研究的,一个是基于统计方法,另一个是基于机器学习方法,但两个学术流派之间互相借鉴,互相融合,基本上这两个流派对聚类方法的划分和分类也趋于一致,主流的划分方式是原型聚类、密度聚类和层次聚类,此外还有一些其他聚类方法,比如有些学者基于网格进行聚类,另一些学者则提出了基于最小支撑树的思想进行聚类。
K-means算法思想是给定原始数据集若干个中心,然后不断迭代,对原始给定的中心进行变换,而每次迭代的时候,数据集中的数据可能会被重新划分到新的中心,从而被划分到新的“数据簇”中,这样一直到前后两次迭代效果相同,或者迭代次数到达阈值而停止迭代。K-means算法可以堪称是高斯混合聚类算法的简单形式,高斯混合聚类方式是基于高斯概率密度曲线,从利用高斯概率密度曲线逼近多维空间的数据集而构建的一种聚类方法。自从1955年第一次提出K-means的算法至今已有六十多年历史,这个算法层多次在历史上被不同领域的学者重新改善并不断应用,如Steinhaus、Lloyd和McQueen分别在上世纪五十年代到六十年代之间不断创新推出新的算法,k-means有大量变体,比如Kaufman等在1987年提出的k-medoids算法可以处理离散值,Bezdek在1981年提出的Fuzzy C-means(简称FCM)则是“软聚类”算法,可以容忍每个样本归属于不同的原型。
密度聚类是基于密度高低进行聚类的,高维空间中的高密度样本被低密度样本隔离,把这些高密度样本聚集为一个个“簇”。王鹏基于Alex Rodriguez等在2014年提出的一种CFSFDP算法进行改进,通过加入构建子簇的局部密度分布图,解决了原始算法的两个缺陷,一个是最初的中心要人为指定,另一个无法处理稀疏地方的数据集的难题。王鹏提出的新算法的实验表明,该改进算法有效解决了前述两个难题,并在算法的简易程度尚有所降低。李伟雄在DBSCAN(Density-Based Spatial Clustering of Applications with Noise)的基础上,使用稠密网格聚类的方式,研究了一种基于网格的聚类算法,该算法通过使用一个新的映射函数将原始数据和网格联系起来,使用特殊技术进行网格分割,在划分的网格上面不断聚类连通图,最终生成了新的聚类方法,实验表明,该算法有很强的容错性,可以对任何形式的数据进行聚类,在聚类过程中的计算相对简便而且计算量也较少,此外,实验还表明,以DBSCAN为基础的基于网格的聚类算法,在引入了新的函数对密度进行计算之后,对任意形式的数据集的聚类比其传统的DBSCAN有更好的效果,ARI值也明显提升。
层次聚类算法是将原始样本点都单独视为一个簇,然后两两进行归并,对距离最小的样本两两聚类,然后将这些已经聚类的簇视为一个样本,再次进行层次聚类,直到最后形成一个簇。这些自底向上形成的簇依据形成的先后顺序可以形成谱系图。针对层次聚类中的不一致问题,缪元武提出了一种基于层次分析法(AHP)法的聚类技术,这个聚类技术可以人为是EM的一种改进,这个算法在尽量保持原来的专业领域人士知识的情况下,对那些存在不一致问题的矩阵进行合理的修正和调整,并采用实验的方式提出层次聚类和分析方法的有机结合使用,改善了只使用层次分析引入的很多不足和问题,提高了算法的执行效率,并在算法评估中获得了更高得分。
曾山主要研究了模糊聚类的相关问题,基于模糊CC-均值聚类算法(FCM)现存的一些不足和短板,提出了改进计算效率的算法,有效解决了计算量大得问题,通过增加相似度度量,提出了基于基于紧邻嵌入的流行学习算法的改进算法,还提出了基于几何流行距离进行聚类技术创新的研究,最后的研究结果表明,这些改进的算法在一些特殊场景下面取得了良好效果,计算量也较小,并且聚类效果也相当客观。
伍育红在深入研究了相关聚类技术的基础之上,针对网格聚类算法的不足,提出了新的算法拟解决这些不足,这些算法相较之于之前的算法,在算法的执行效率和聚类效果上面都有很大改进,新提出的算法是基于多密度的网格聚类算法,结合了网格聚类和密度聚类的一些优势,又规避了相应算法的一些不足,这主要是通过在不同的算法过程中采用不同的函数进行聚类而完成的,研究表明,新的算法确实规避了传统算法的不足,在特定的数据集下面表现了不俗的聚类效果。
综上,国内外对机器学习中的聚类算法研究热情高涨,总体上从原型聚类算法、密度聚类算法、层次聚类算法展开研究,此外还有一些其他算法,例如,模糊聚类、网格聚类等算法。
三、对比实验
K-means是原型聚类中的一种常见聚类方法,K-means中使用距离公式对样本距离进行计算,。
利用K-means对数据集iris进行聚类,聚类之后的结果与原始数据集的标签有一些差距。利用K-means对iris的聚类代码如下所示。
from sklearn.cluster import KMeans
import numpy as np
X=pd.DataFrame(irisPlot,columns=["spalLength","spalWidth"]);
kmeans = KMeans(n_clusters=3, random_state=0).fit(X)
kmeans.labels_
X["tag"]=kmeans.labels_
sns.scatterplot(x="spalLength", y="spalWidth",hue="tag", style="tag", data=X)
plt.show()
K-means聚类之后的聚类类别如图1所示。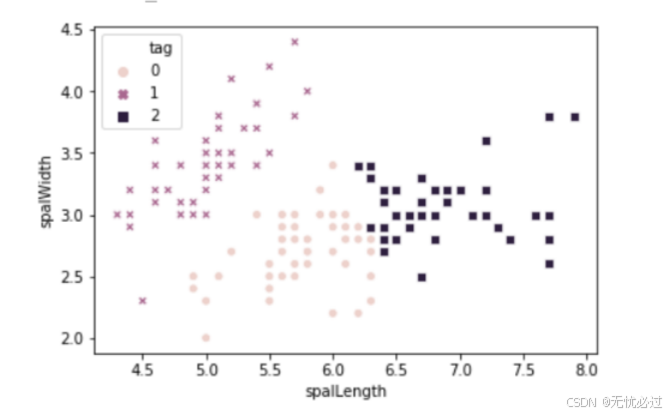
图1 K-means聚类散点图
DBSCAN是聚类方法中的密度聚类中的代表算法,DBSCAN中使用距离公式对样本距离进行计算,。利用DBSCAN对数据集iris进行聚类,聚类之后的结果与原始数据集的标签有一些差距。利用DBSCAN对iris的聚类代码如下所示。
from sklearn.cluster import DBSCAN
import numpy as np
X=pd.DataFrame(irisPlot,columns=["spalLength","spalWidth"]);
clustering = DBSCAN(eps=0.3, min_samples=3).fit(X)
clustering.labels_
X["tag"]=clustering.labels_
sns.scatterplot(x="spalLength", y="spalWidth",hue="tag", style="tag", data=X)
plt.show()
DBSCAN聚类之后的聚类类别如图2所示。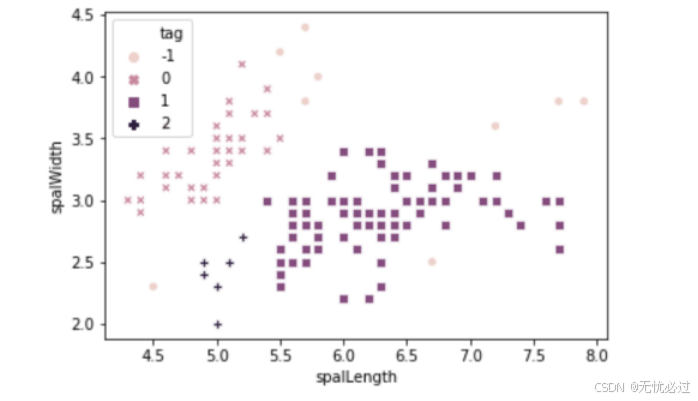
图2 DBSCAN聚类散点图
AGNES是层次聚类算法中的一种常用算法,AGNES是聚类方法中的层次聚类中的代表算法。利用AGNES对iris进行聚类,聚类之后的结果与原始数据集的标签有一些差距。利用AGNES对iris的聚类代码如下所示。
from sklearn.cluster import AgglomerativeClustering
import numpy as np
X=pd.DataFrame(irisPlot,columns=["spalLength","spalWidth"]);
agnes = AgglomerativeClustering(n_clusters=3).fit(X)
agnes.labels_
X["tag"]=agnes.labels_
sns.scatterplot(x="spalLength", y="spalWidth",hue="tag", style="tag", data=X)
plt.show()
AGNES聚类之后的聚类类别如图3所示。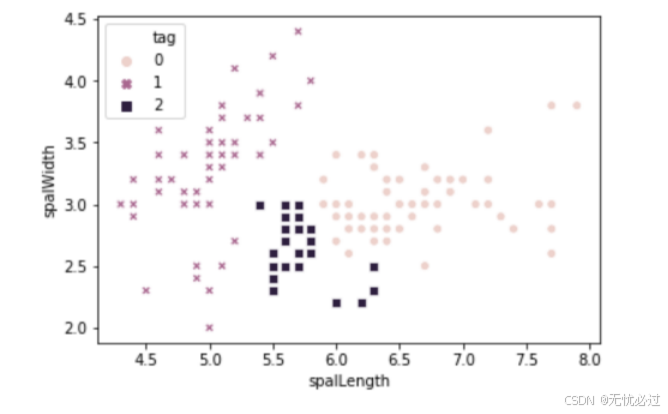
图3 AGNES聚类散点图
参考文献
[1]Anil K.Jain. Data clustering: 50 years beyond K-means[J]. Pattern Recognition Letters,2010,651-666.
[2]Clark F. Olson.Parallel Algorithms for Hierarchical Clustering[J]. pattern analysis & machine intelligence ieee transactions on,2016.
[3]Dey P,Roy S,Roy S. Ego based community detection in online social network[C]. International Conference on Distributed Computing and Internet Technology. Springer,Cham, 2018: 205-210.
[4]王鹏. 基于密度算法的应用与改进[D]. 内蒙古大学,2017.
[5]李伟雄. 基于密度的聚类算法研究[D]. 湖南大学,2010.
[6]缪元武. 基于层次聚类的数据分析[D]. 安徽大学,2013.
[7]Wes McKinney,唐学韬. 利用python进行数据分析[M]. 机械工业出版社,2014.
[8]靳鹏飞. 一种改进的Sobel图像边缘检测算法[J]. 应用光学,2008,(4):625-628.
[9]韩晓冬,王浩森,王硕. Python在图像处理中的应用[J]. 北京测绘,2018,(3):312-317.
[10]李荟娆. K-means聚类方法的改进及其应用[D]. 东北大学,2014.
[11]乔端瑞. 基于K-means算法及层次聚类算法的研究与应用[D]. 吉林大学,2016.
[12]周志华. 机器学习:发展与未来[J]. 中国计算机学会通讯,2017(013),001,44-51.
[13]周志华. 机器学习[M]. 北京:清华大学出版社,2016.
[14]蔡静颖. 模糊聚类算法及应用[M]. 冶金工业出版社,2015.
[15]王骏,王士同,邓赵红. 聚类分析研究中的若干问题[J]. 控制与决策,2012(03).

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)