深度学习(tensorflow)2——数据准备1
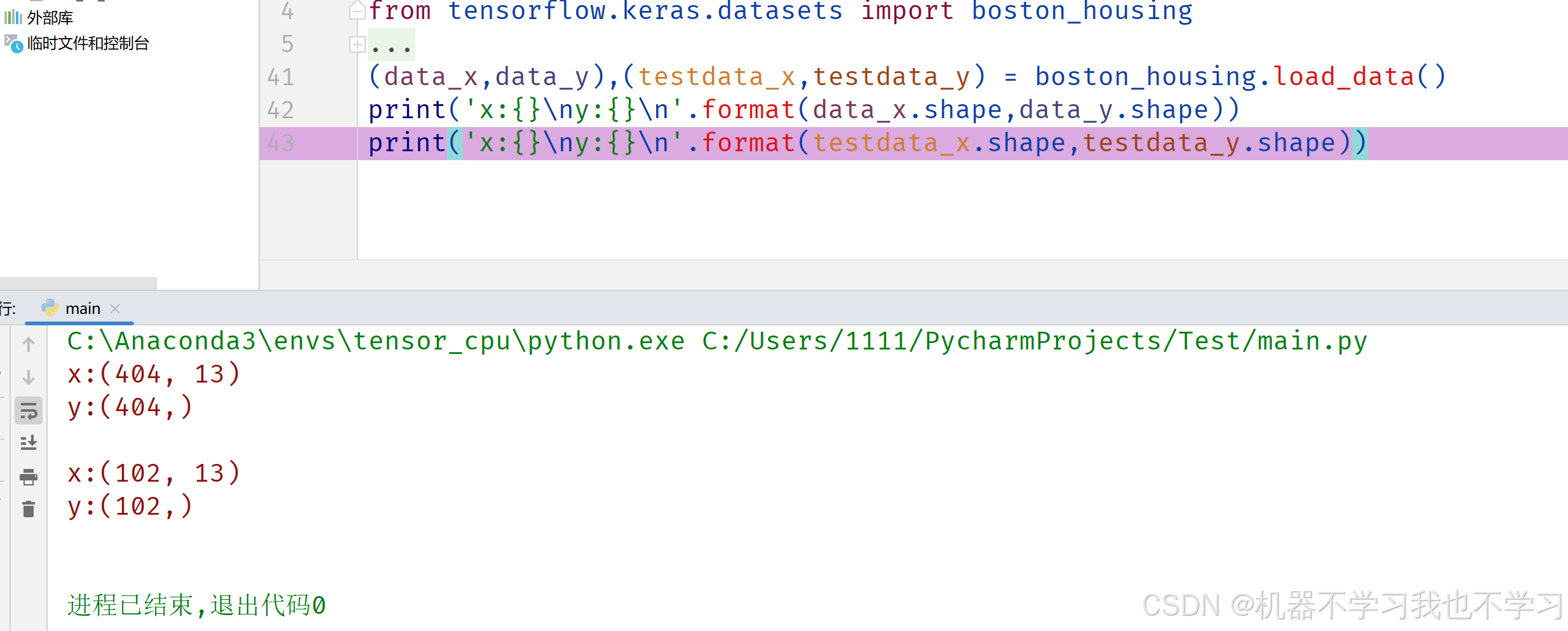
加载完成后,数据需调整格式,转换为Dataset对象,才能在tensorflow中流转,使用tensorflow中提供的各种便捷,使用tf.data.Dataset.from_tensor_slices(data)将data转为Dataset对象。使用load_data()函数加载,然后划分为训练数据集(data_x,data_y)及测试数据集(testdata_x,testdata_y),并输出
一、数据加载
1、内置数据集加载
datasets模块内置许多常用经典数据集,例如波士顿房价数据集Bonston Housing、手写数字数据集MNIST/Fashion_MNIST、情感分类任务数据集IMDB等,如需加载波士顿房价数据集:
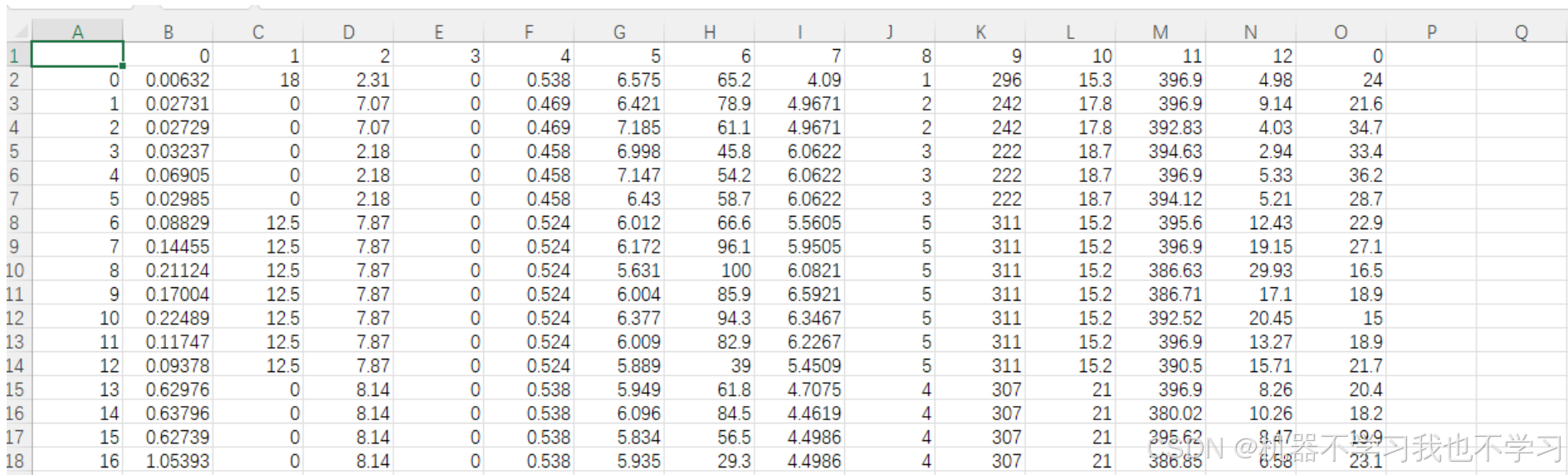
原数据集:
使用load_data()函数加载,然后划分为训练数据集(data_x,data_y)及测试数据集(testdata_x,testdata_y),并输出了分割后数据集的shape值
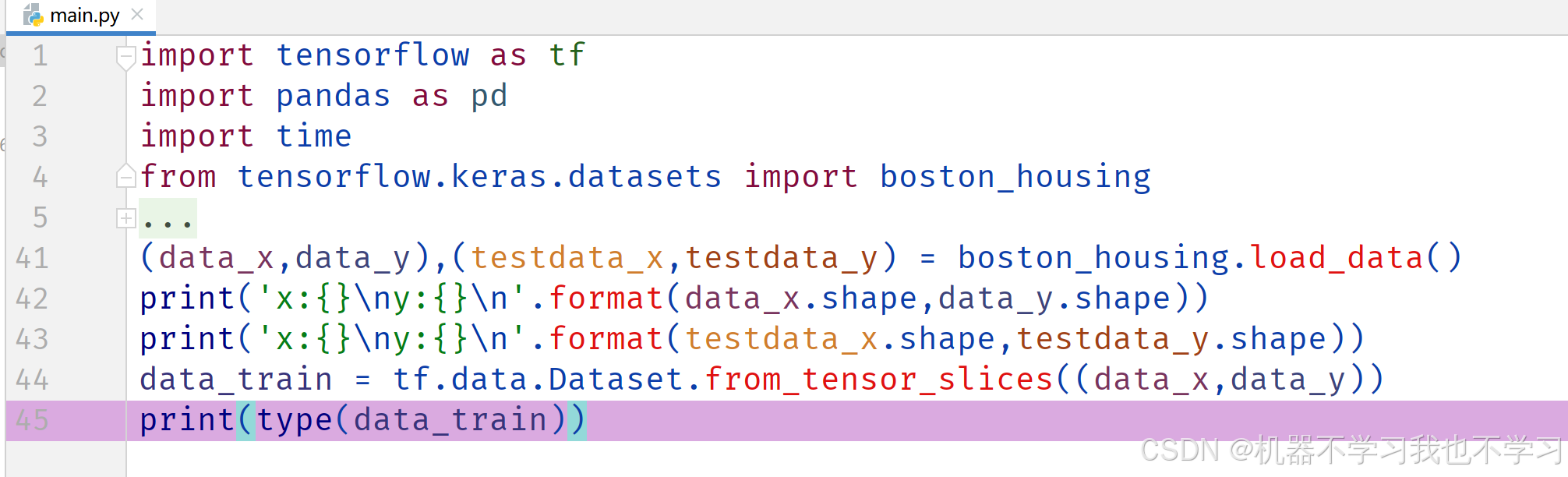
加载完成后,数据需调整格式,转换为Dataset对象,才能在tensorflow中流转,使用tensorflow中提供的各种便捷,使用tf.data.Dataset.from_tensor_slices(data)将data转为Dataset对象。
2、外部数据文件加载
外部文件数据加载可能会有不同的数据格式,常见的外部数据文件格式有CSV文件、TFRecord文件、文本文件和文件集等。
1)CSV文件:
方式一:
该格式以纯文本格式存储表格数据。对于较小的 CSV 数据集,可将其作为 Pandas Dataframe 或 NumPy 数组加载到内存中,再使用from_tensor_slices()函数将数据从内存中转化为Dataset对象实例。
# 波士顿房价数据集加载
# 波士顿房价数据集加载csv1
dataframe =pd.read_csv('boston.csv')
print(dataframe.shape)#输出一下shape
print(dataframe.head(4))#展示一下前4行
dataframe_dataset = tf.data.Dataset.from_tensor_slices(dict(dataframe))
print(type(dataframe_dataset))
for feture_batch in dataframe_dataset.take(count = 1):
#使用take()函数在列轴的位置1处取值,take函数用于从数据集中获取前 count 个元素,并返回一个新的数据集
# print("quanbu:",feture_batch)
# print(type(feture_batch))#feture_batch是一个字典类型
for key ,value in feture_batch.items():#遍历这个字典,输出一下对应的键和值
print(key,':',value)
方式二:
使用make_csv_dataset()函数加载数据,从磁盘中加载,每次运行得批数据可能不同,输出结果可能不同,也就是随机选择batch_size条数据。
tf.data.experimental.make_csv_dataset(file_pattern,batch_size,label_name)
参数:
file_pattern:包含CSV记录的文件列表或文件路径模式。必填。
batch_size:一个int,表示要在单个批次中合并的记录数。必填。
label_name:对应于标签列的可选字符串。如果提供了此列的数据,则将其与Tensor要素字典分开返回,以便数据集符合tf.Estimator.train或tf.Estimator.evaluate输入函数期望的格式。选填。
# 波士顿房价数据集加载csv2
data = tf.data.experimental.make_csv_dataset('./boston.csv',batch_size=4,label_name='MEDV')
#中位数房价(MEDV)
for feture_batch,label_batch in data.take(1):
# 使用take()函数在列轴的位置1处取值,take函数用于从数据集中获取前 count 个元素,并返回一个新的数据集
# print("feture_batch结果:",feture_batch)
# print("label_batch结果:",label_batch)
print('MEDV:{}'.format(label_batch))
print('features:')
for key ,value in feture_batch.items():
print(key,':',value)
#每次运行得批数据可能不同,输出结果可能不同,也就是随机选择batch_size条数据。
2)TFRecord文件
TFRecord 是 TensorFlow 自带的一种数据格式,将图像数据和标签统一存储的二进制文件,也是TensorFlow 推荐的数据保存格式,其读取操作更加高效,更适合数据量大的情况。读取 TFRecord 文件有两种方式,queue / tf.data,以下为第二种。
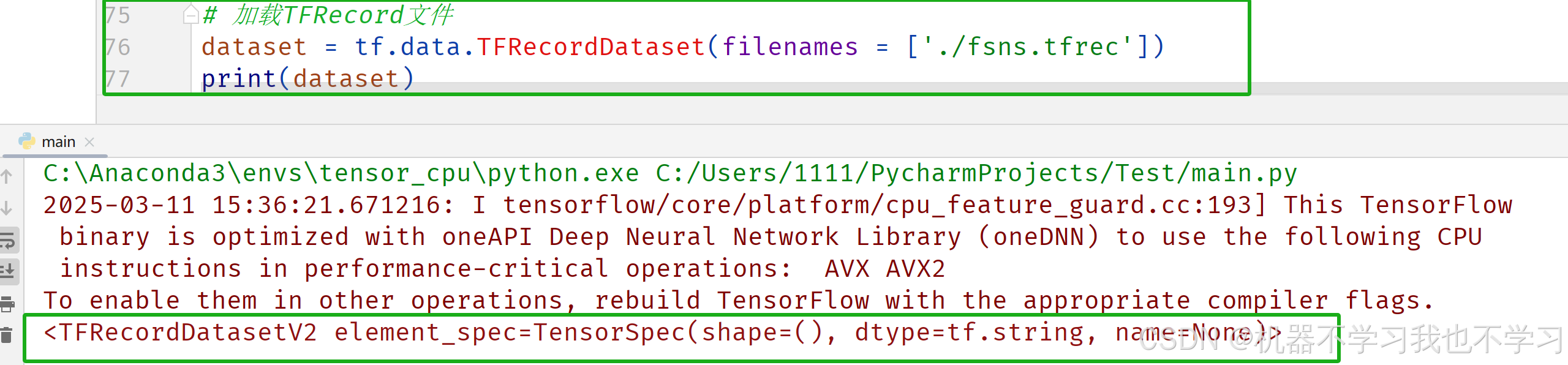
读取TFRecord文件
tf.data.TFRecordDataset( filenames, compression_type = None, buffer_size = None, num_parallel_reads = None) 参数: filenames:字符串或字符串列表,指定要读取的TFRecord文件的路径。可以是一个字符串(单个文件),也可以是一个字符串列表(多个文件)。 compression_type:字符串或None,指定TFRecord文件的压缩类型。支持的选项包括'GZIP'(表示文件使用GZIP压缩)、'ZLIB'(表示文件使用ZLIB压缩)和None(表示文件未压缩,默认值)。 buffer_size:整数或None,指定读取文件时的缓冲区大小(以字节为单位)。较大的缓冲区可以提高 I / O性能,尤其是在处理大型文件时。默认值为None,表示使用系统默认的缓冲区大小。 num_parallel_reads:整数或None,指定并行读取文件的数量。如果为None,则文件将按顺序读取。如果是一个正整数,则表示同时读取多个文件。
参考以下:
Tensorflow之TFRecord的原理和使用心得 - 知乎![]() https://zhuanlan.zhihu.com/p/352025069
https://zhuanlan.zhihu.com/p/352025069
https://www.cnblogs.com/wj-1314/p/11211333.html https://www.cnblogs.com/wj-1314/p/11211333.html
https://www.cnblogs.com/wj-1314/p/11211333.html
3)文本文件
详细教程参考以下:
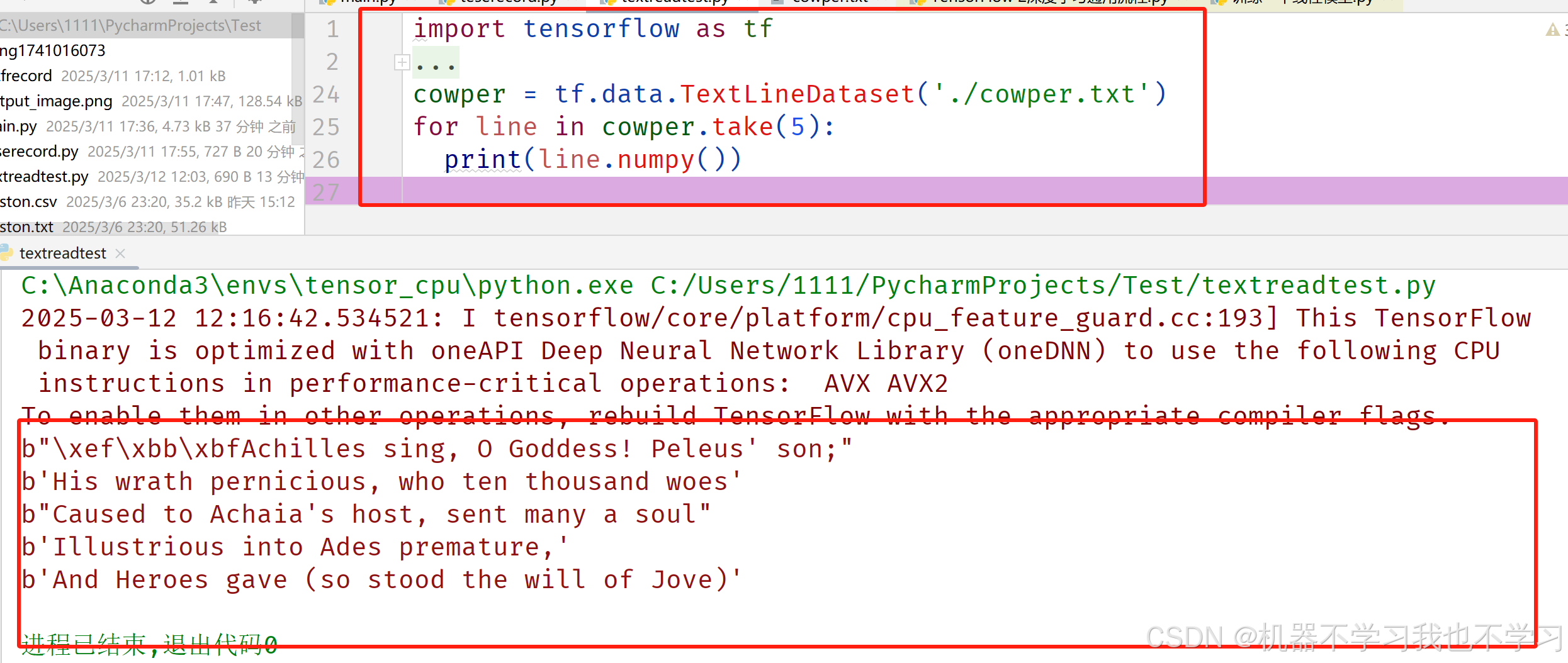
加载文本 | TensorFlow Corehttps://tensorflow.google.cn/tutorials/load_data/text?hl=zh-CN此处我们只采用TextLineDataset()函数加载文本数据并查看。
TextLineDataset(filenames,compression_type,buffer_size)
参数: filenames: 单个或者多个string格式的文件名或者目录 compression_type: 格式是ZLIB或者GZIP,可选。 buffer_size: 决定缓冲字节数多少,可选。
tf.data.TextLineDataset 提供了一种方法从文件中读取数据。这个接口会自动构造一个dataset,文本中的一行,就是一个元素,是string类型的tensor,保存至返回值。
4)文件集
以读取猫狗分类数据集为例,数据集如下:

1、首先,使用pathlib库中的Path获取对应文件夹的绝对路径。
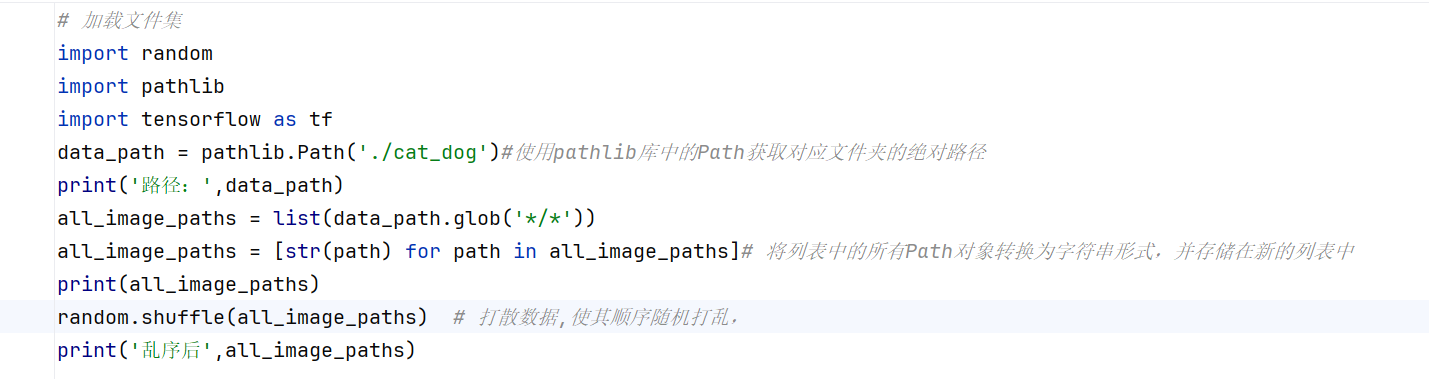
结果如下:
2、可以看看读取了多少张数据、所有图片有几个分类、给分类创建标签等。
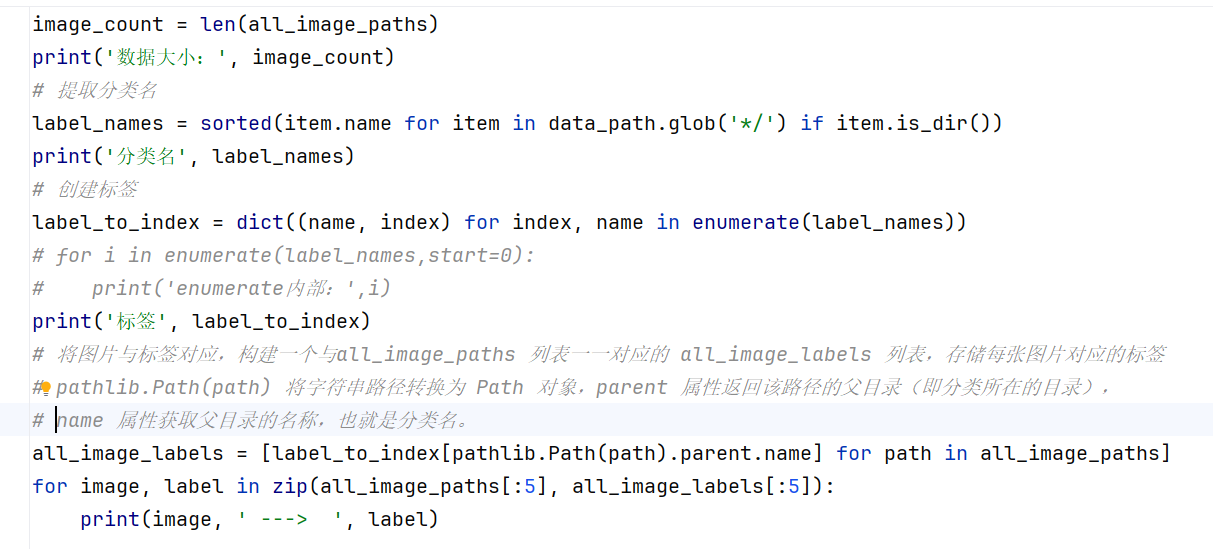
结果如下:
其中:enumerate(sequence, [start=0])
参数:
sequence -- 一个序列、迭代器或其他支持迭代对象。
start -- 下标起始位置的值,默认为0开始,依次增1。
返回 enumerate(枚举) 对象
zip([iterable, ...])
参数:
iterable -- 一个或多个迭代器;
a = [1, 2, 3]
b = [4, 5, 6]
zipped = zip(a, b)# 使用zip函数将列表a和b中的对应元素打包成元组
3、把他们都转化为Dataset对象实例
# 转化为Dataset对象实例

结果:

补充遇见的一个问题解释:
1、以上代码针对以上数据集样式,分类名即内层文件夹的名称。
如分类名是cat、dog,假设修改了文件夹名为dog、pig:
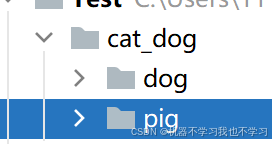
对应分类名就变成了dog、pig了

2、所有图片在一个文件中。
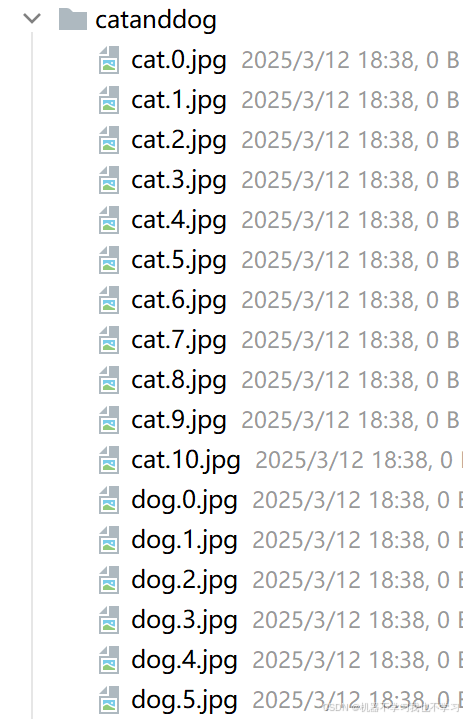
想要继续使用以上代码,你可以:
方法1、手动调整数据集样式
方法2、代码调整成以上数据集
from pathlib import Path
import shutil
import pathlib
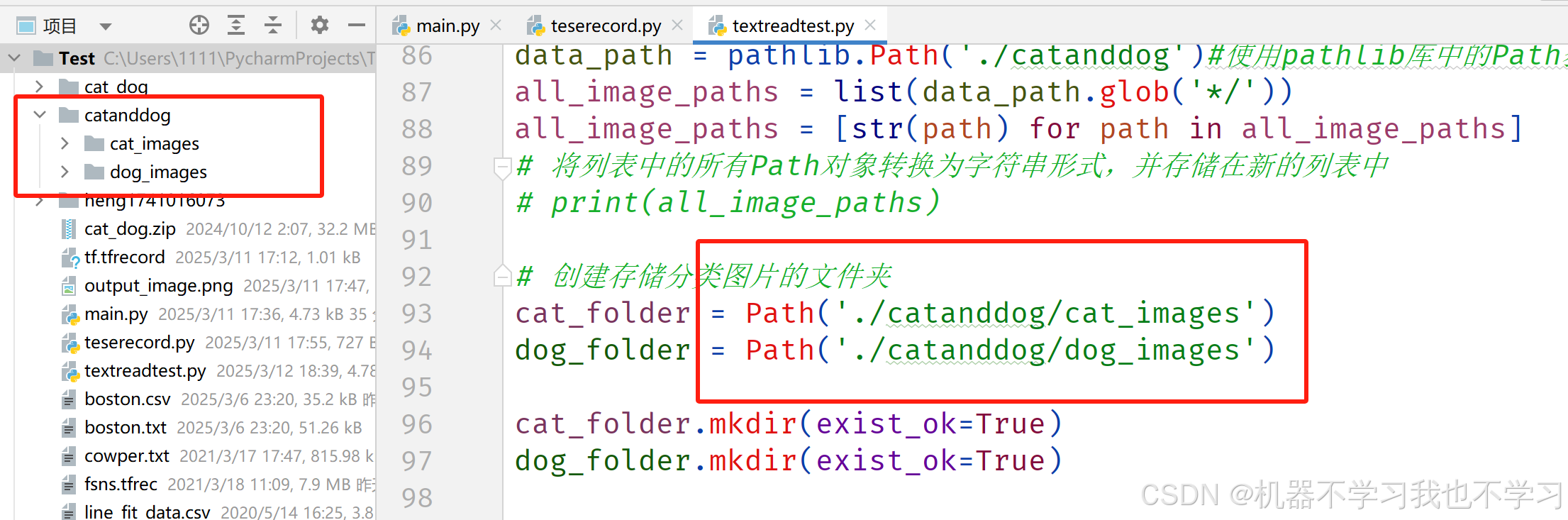
data_path = pathlib.Path('./catanddog')#使用pathlib库中的Path获取对应文件夹的绝对路径
all_image_paths = list(data_path.glob('*/'))
all_image_paths = [str(path) for path in all_image_paths]
# 将列表中的所有Path对象转换为字符串形式,并存储在新的列表中
# print(all_image_paths)
# 创建存储分类图片的文件夹
cat_folder = Path('./catanddog/cat_images')
dog_folder = Path('./catanddog/dog_images')
cat_folder.mkdir(exist_ok=True)
dog_folder.mkdir(exist_ok=True)
# 遍历文件列表进行分类并移动文件
for file in all_image_paths:
file_path = Path(file)
if 'cat' in file_path.name.lower():
shutil.move(file_path, cat_folder / file_path.name)
elif 'dog' in file_path.name.lower():
shutil.move(file_path, dog_folder / file_path.name)
print("图片分类移动完成。")
结果如下:

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)