[人工智能学习]从Word2Vec入手学习神经网络相关知识
RNNLM克服了前馈 NNLM 的某些局限性,例如需要指定上下文长度(模型 N 的阶数)。这段讲的是NNLM首先接受N个词项的输入,每个词项都是one-hot编码,在投影层通过N×D的投影矩阵,然后在隐藏层接着运算,最后输出层回到V,也就是词典的大小,输出表示概率,是进行了归一化操作的,就是概率都在0-1之间,和为1,这里分析了由于投影层数据的稠密性,在投影层和隐藏层计算的复杂度很高,虽然可以在最
本文从经典的词向量嵌入模型word2vec入手,由原始论文介绍相关知识。
首先要明白word2vec是用来做什么的,简单来说,以最近比较火的deepseek-r1为例,当我们输入一段中文给deepseek时,我们知道,计算机是无法处理自然语言的,由于计算机指令架构的设置,其只能对二进制数进行操作,平时的英文是以ascii码形式展现,中文则是gbk等,但自然语言要比单单的英文字母和汉字复杂得多,如何让计算机理解呢?
这时就需要将我们输入的中文,也就是自然语言,转换为计算机能看懂的符号,也就是一堆二进制数,它可以是整数,也可以是小数(浮点型),但仅仅是一个数肯定是不够的,因此我们需要一个高维的向量来表示(比如BERT是768维的向量表示句子),而word2vec是将单个词项(token)转换为向量的一个方案,由google研究团队在2013年提出,原始文章:[1301.3781v3] Efficient Estimation of Word Representations in Vector Space
下面我们来着手学习:
我们将词项转换为向量肯定是有一定需求的,不然最简单的one-hot编码即可实现要求(N个单词对应N维向量,第i个单词的i维为1,其余为0),像word2vec就可以实现嵌入的符合常识:意思相近的单词向量也相似,意思相差较多的向量也不相似。
word2vec是一个基于神经网络的词嵌入模型,其主要为了降低训练的复杂度,在其之前,也有类似的基于神经网络的词嵌入模型,论文也进行了分析:
首先是概率前馈神经网络语言模型(NNLM):

这段讲的是NNLM首先接受N个词项的输入,每个词项都是one-hot编码,在投影层通过N×D的投影矩阵,然后在隐藏层接着运算,最后输出层回到V,也就是词典的大小,输出表示概率,是进行了归一化操作的,就是概率都在0-1之间,和为1,这里分析了由于投影层数据的稠密性,在投影层和隐藏层计算的复杂度很高,虽然可以在最后输出的时候通过哈夫曼树的形式将较大的词典数降为log(V),但中间的计算仍然很复杂,就是那个N×D×H。
下面我们讲一下这里面提到的一些概念,首先是神经网络的结构,在NNLM中,包括了输入层,投影层,隐藏层和输出层,其中输入层和输出层较为简单就是字面意思,投影层的功能有降维和升维等,其主要就是一个投影矩阵构成,在该例子中,大小为[输入层大小(在完整的模型中,一般直接就是词汇表大小了),词嵌入维度(就是最后要表示的向量维度)],关于投影的相关知识可以参考:线性代数拾遗(6)—— 向量空间投影与投影矩阵-CSDN博客这个投影矩阵一般是随机的数,只用来更改维度,为线性运算;然后是隐藏层,也就是神经网络中关键的部分,更新的权重参数都在这部分,隐藏层可以实现非线性的运算,即线性的运算然后加上非线性的激活函数处理,通过一层或多层(多层的就是深度神经网络)的隐藏层处理,最后输出到输出层,通过输出层的输出与真实值计算得到的损失值(用损失函数计算)在优化函数(有不同的方法,比如梯度下降等)中计算,然后更新隐藏层的参数,反复这样就完成了一个基本的神经网络的训练。
然后又提及了更优的基于递归神经网络的语言模型(RNNLM):

RNNLM克服了前馈 NNLM 的某些局限性,例如需要指定上下文长度(模型 N 的阶数)。RNN 模型没有投影层,只有输入层、隐藏层和输出层。这种模型的特殊之处在于使用延时连接将隐藏层与自身连接起来的递归矩阵。这使得递归模型能够形成某种短期记忆,因为过去的信息可以通过隐层状态来表示,而隐层状态则根据当前输入和上一时间步的隐层状态进行更新。RNNLM没有投影层,因此复杂度如上面的Q所示,包含了两部分,分别代表隐藏层的计算和隐藏层到输出层的计算,同理,到输出层可以优化到比较低的水平,那么主要来源就是隐藏层的计算了。
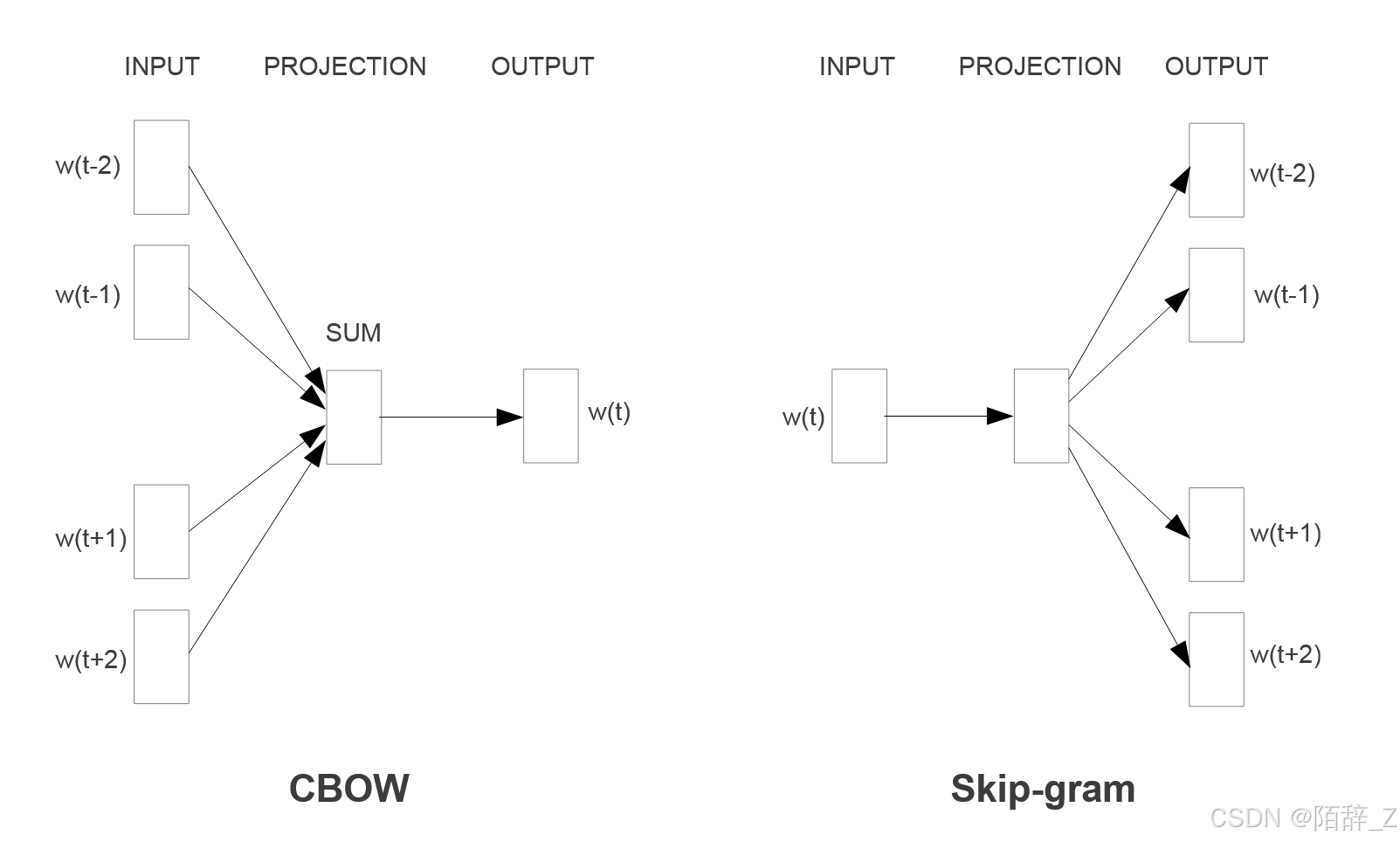
而word2vec在这些基础上提出了两种模型:CBOW和skip-gram。
CBOW创新性地摒弃了隐藏层,只保留投影层,在训练时更新共享的投影矩阵,最后得到的投影矩阵即为和token id相对应的词嵌入矩阵,这样就进一步的降低了复杂度。其输入为四个历史词和四个未来词,通过上下文来预测中心词。
另一个模型skip-gram则是通过中心词来预测上下文,原理和CBOW差不多,只不过最后计算的是上下文的词项概率而不是由上下文计算中心词,由于要计算每个上下文词的概率,因此复杂度会比CBOW要高一点,但效果也比CBOW要好。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)