毕业设计:基于混合推荐算法的音乐歌曲个性化推荐系统
基于协同过滤算法的音乐推荐方法,结合用户行为数据和物品特征,旨在实现精准的个性化音乐推荐。我们首先构建了一个包含用户评分和音乐特征的数据集,采用基于用户和基于物品的协同过滤技术进行推荐分析。通过计算用户之间的相似度和音乐之间的相似度,我们设计并实现了一个音乐推荐系统。对于计算机专业、人工智能专业、大数据专业、信息安全专业、软件工程专业的毕业生而言,不论是对推荐系统、机器学习还是数据挖掘感兴趣的同学
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于混合推荐算法的音乐歌曲个性化推荐系统
课题背景和意义
随着数字音乐平台的普及,用户面临海量的音乐选择,如何为用户提供精准的音乐推荐成为一个重要的研究课题。个性化推荐系统能够根据用户的兴趣和行为,智能地推荐符合其口味的音乐,从而提升用户体验和满意度。协同过滤算法作为一种经典的推荐技术,主要分为基于用户和基于物品的两种方法。基于用户的协同过滤通过分析用户之间的相似性来进行推荐,而基于物品的协同过滤则关注于物品之间的相似性。本课题旨在深入研究协同过滤算法在音乐推荐中的应用,探索如何提高推荐系统的准确性和效率,为用户提供更好的个性化音乐推荐体验。
实现技术思路
一、算法理论基础
1.1 网络爬虫
网络爬虫技术在个性化音乐推荐系统的构建中扮演着重要的角色。通过自动化程序抓取和获取互联网平台上的音乐数据,爬虫系统能够为推荐算法提供丰富的用户行为数据和音乐特征信息。具体来说,网络爬虫可以从各大音乐平台(如Spotify、网易云音乐、QQ音乐等)获取用户的听歌历史、评分、评论、歌单以及其他相关信息。这些数据不仅能够帮助系统了解用户的音乐偏好,还能为后续的推荐模型提供训练数据,从而实现更加精准的个性化推荐。通过对网络爬虫的灵活应用,个性化音乐推荐系统能够不断更新其推荐内容,保持对用户偏好的敏感度,并及时响应用户的需求变化。
在构建网络爬虫系统时,各个组件的协作至关重要。调度器负责生成待抓取的URL队列,确保爬虫系统能够按照合理的顺序进行抓取;URL管理器则存储待抓取和已抓取的URL,避免重复抓取同一页面。下载器通过HTTP协议向目标网站发起请求并获取HTML响应,而爬虫引擎则负责协调这些操作,将待抓取的URL分配给下载器,并将返回的HTML内容传递给解析器。解析器利用HTML解析库将页面内容转化为可处理的格式,从中提取出用户行为和音乐特征等关键信息。数据存储器负责将提取的数据保存到数据库中,以供后续分析和模型训练使用。通过这些组件的高效协作,网络爬虫能够快速、准确地完成大规模数据的抓取,支持个性化音乐推荐系统的实时更新和优化。
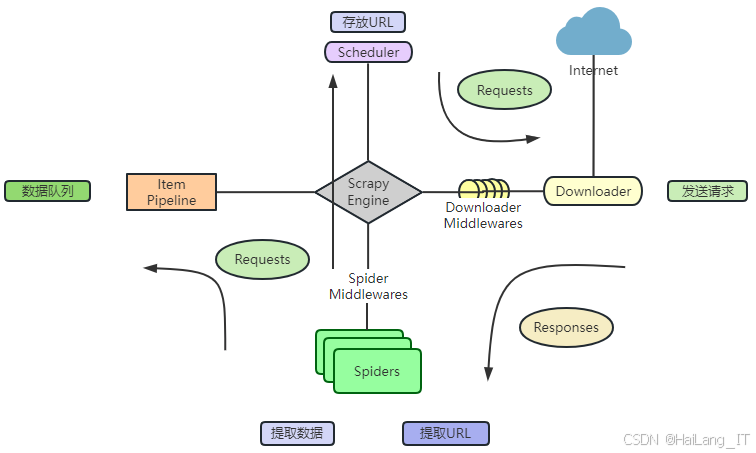
为了确保网络爬虫在复杂多变的网络环境中顺利完成抓取任务,系统必须具备高性能、可扩展性和健壮性。高性能意味着爬虫能够快速下载和处理大量页面,从而提高数据抓取的效率,确保推荐系统能够及时响应用户的需求。可扩展性使得爬虫系统能够灵活应对大规模数据和不断变化的功能需求,支持多节点的分布式环境扩展,进而提高系统的整体处理能力。而健壮性则确保爬虫系统在面对网络波动、目标网站变化和异常情况下能够稳定运行,持续执行数据抓取任务。通过实现高性能、可扩展性和健壮性,网络爬虫为个性化音乐推荐系统提供了强大的技术支撑,确保系统能够在不断变化的网络生态中高效地执行任务,提供准确而个性化的音乐推荐服务。
1.2 推荐算法
基于内容过滤的推荐算法在个性化音乐推荐系统中扮演着重要的角色,其原理是通过用户的过往选择记录或偏好记录,向用户推荐与其过去喜好相似的音乐作品。该算法的工作流程主要包括以下几个步骤。首先,系统通过分析用户的显性和隐性反馈,获取用户在某段时间内的交互记录,并从中学习用户的音乐偏好,将其转化为特征向量。接着,系统提取每首音乐的特征,包括文本描述、标签、曲风等信息,建立音乐的特征模型。然后,计算用户的兴趣特征与待推荐音乐之间的相似度,通常采用余弦相似度等方法进行计算。最后,根据相似度排序生成推荐列表,向用户展示最符合其兴趣的音乐。这种方法的优越性在于能够有效应对新音乐的冷启动问题,并且推荐结果容易解释。然而,基于内容过滤的算法也存在一定的局限性,如用户容易陷入“信息过滤气泡”,仅接触到相似类型的音乐,以及难以适应用户兴趣的动态变化。
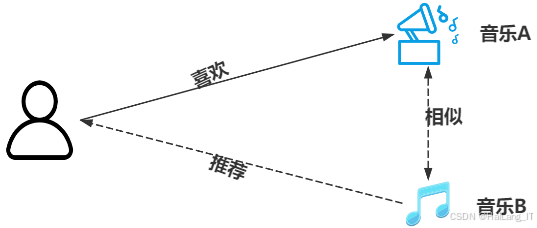
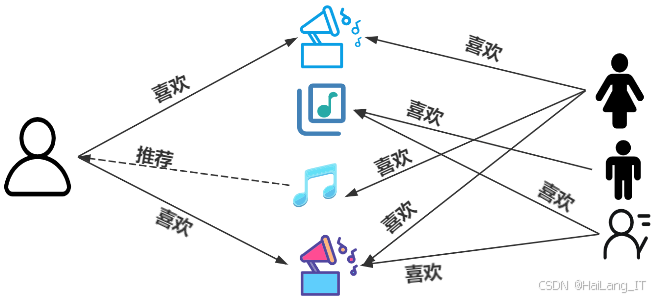
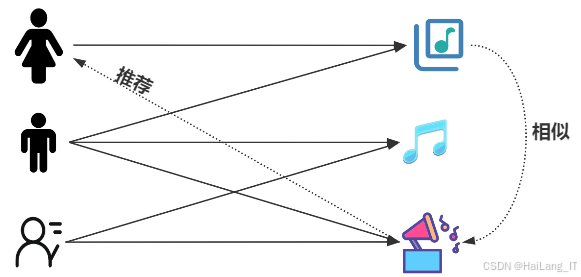
协同过滤算法则侧重于利用用户群体的历史行为数据来分析和预测目标用户可能感兴趣的音乐作品。协同过滤主要分为基于用户的协同过滤和基于物品的协同过滤。在基于用户的协同过滤中,系统通过计算用户之间的相似度,识别与目标用户兴趣相近的用户群体,并推荐这些邻近用户喜欢但目标用户尚未接触的音乐。相比之下,基于物品的协同过滤则关注于不同音乐之间的相似性,若用户A和用户B对同一首音乐有共同喜好,则可以推测他们对其他相似音乐的兴趣。虽然协同过滤能够提供多样化的推荐,但也面临冷启动和数据稀疏性的问题。因此,推荐系统通常采用稠密矩阵分解、引入内容信息或降低计算复杂度等方法来增强推荐的准确性和可扩展性。
混合推荐算法结合多种推荐策略的优势,以更全面地满足用户的个性化需求。其中,加权融合通过对不同推荐算法的输出结果赋予权重,以生成最终推荐列表;级联融合首先生成初步推荐列表,再利用其他算法对其进行优化;并行融合允许多个推荐算法独立运行,最终通过合并结果生成推荐;特征组合融合则通过整合不同算法提取的特征,形成更加丰富的用户和音乐特征表示;模型集成混合则通过对多个推荐模型的结果进行综合决策,形成最终的推荐列表。这些混合策略能够有效提高个性化音乐推荐系统的准确性和灵活性,确保系统能够在多变的用户需求和音乐环境中提供精准的个性化推荐服务,从而提升用户的满意度和体验。
1.3 特征工程
TF-IDF是一种用于文本挖掘和信息检索的特征向量化方法。其主要目的是评估某个词在特定文档中的重要性。TF-IDF包含两个关键部分,词频和逆文档频率。词频表示某个词在文档中出现的频率,通常通过该词在文档中出现的次数与文档总词数的比值来计算。频繁出现在文档中的词,其重要性分数较高,反映了词在文档内部的相关性。逆文档频率则衡量词在整个文档集合中的普遍性,计算方式是根据包含该词的文档数量推导该词的独特性。若一个词在多个文档中出现,则说明其区分能力较弱,因此IDF值较低。通过结合这两部分,TF-IDF能够突出在文档中频繁出现但在其他文档中相对少见的词汇,降低常见词的影响,聚焦更具信息量的特征。
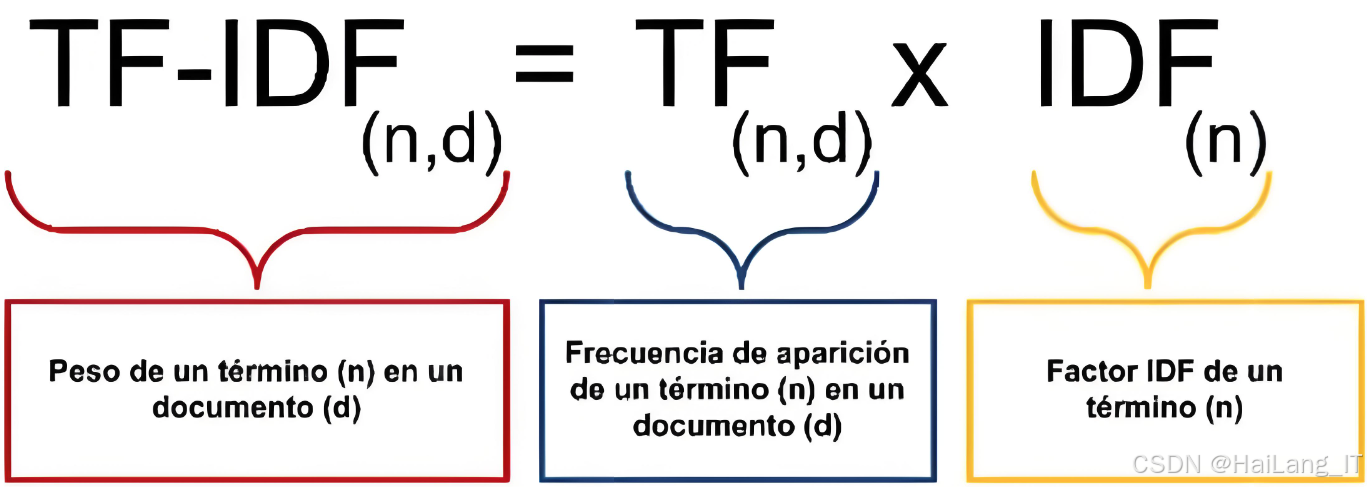
实际应用中,TF-IDF广泛用于文本分类、信息检索、关键词提取、文档相似度计算等领域。个性化音乐推荐系统中,TF-IDF能够提取音乐歌词、描述、标签等文本数据特征,从而帮助系统理解用户兴趣和偏好,实现精准推荐。这种方法提高推荐算法效果,提供更具个性化和相关性的音乐选择。
二、 数据集
2.1 数据集
收集多来源音乐数据,包括用户行为数据和音乐特征数据。用户行为数据包括用户的播放历史、评分记录、收藏夹内容、评论等。音乐特征数据包括曲风、艺术家、专辑、发行年份、歌词等信息。使用网络爬虫技术从主流音乐平台(如Spotify、网易云音乐、QQ音乐等)抓取数据,确保数据的多样性和代表性。设计爬虫系统,设置合理的抓取频率和范围,确保数据的更新和完整性。对收集的数据进行初步清洗,去除重复和无效数据。
2.2 数据处理
使用标签体系为用户的行为进行分类,例如将用户的播放记录标记为“喜好”或“未互动”。对音乐特征进行结构化标注,提取出各项特征并建立特征向量。可使用人工标注结合自动化工具提高标注效率,确保标注结果的一致性和准确性。记录每个用户的偏好类型,形成用户兴趣模型,为推荐算法提供基础数据支持。标准化用户行为数据和音乐特征数据,确保数据格式统一。进行数据去重和缺失值处理,填补缺失值或删除缺失数据行。使用特征选择方法,提取出对推荐系统最有用的特征,降低维度,提升模型性能。将处理后的数据划分为训练集、验证集和测试集,为模型的训练和评估提供基础。
三、实验及结果分析
3.1 实验环境搭建

3.2 模型训练
数据收集可以通过网络爬虫从多个音乐平台获取用户行为数据和音乐特征数据。爬虫技术能够高效地抓取用户的播放记录、评分、评论等信息,以及音乐的曲风、艺术家、专辑等特征。这些数据需要经过清洗,去除重复项和无效记录,以确保数据的质量和可靠性。用户行为数据可以标注为“喜好”或“未互动”,而音乐特征数据则需要提取出各项特征并构建特征向量。标注过程可以通过人工审核和自动化工具相结合,提高标注的准确性和一致性。
import requests
from bs4 import BeautifulSoup
def fetch_music_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
music_data = []
for item in soup.find_all('div', class_='music-item'):
title = item.find('h2').text
artist = item.find('p', class_='artist').text
music_data.append({'title': title, 'artist': artist})
return music_data
music_url = 'https://example.com/music'
music_data = fetch_music_data(music_url)需要对音乐特征进行向量化处理,例如使用TF-IDF或Word2Vec等方法将文本特征转化为数值特征。此外,还要考虑用户的行为特征,将用户的历史偏好转化为兴趣模型。这些特征将用于后续的推荐算法训练,以优化推荐效果。根据选择的混合推荐算法,可以使用基于内容过滤和协同过滤的结合方法,利用用户兴趣模型与音乐特征模型进行训练。可以选择机器学习算法(如决策树、随机森林)或深度学习模型(如神经网络)进行训练,确保模型能够准确预测用户对未互动音乐的兴趣。
from sklearn.feature_extraction.text import TfidfVectorizer
# 假设已有音乐描述数据
music_descriptions = pd.Series(['A beautiful ballad', 'An energetic pop song', 'A soulful jazz piece'])
vectorizer = TfidfVectorizer()
music_features = vectorizer.fit_transform(music_descriptions)
print(music_features.toarray())使用交叉验证和评估指标(如准确率、召回率、F1值等)来评估模型的表现。同时,可以使用测试集对模型进行验证,确保其在未见数据上的泛化能力。模型评估结果将为后续模型的优化和调整提供依据。
from sklearn.metrics import accuracy_score, f1_score
# 预测测试集结果
y_pred = model.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f'Accuracy: {accuracy}, F1 Score: {f1}')根据用户的兴趣模型和未互动的音乐特征,计算相似度并生成推荐结果。可以选择最具潜在兴趣的音乐作品加入推荐列表,以提高用户的满意度和体验。
def recommend_music(user_profile, all_music_features, model):
predictions = model.predict(all_music_features)
recommended_indices = predictions.argsort()[-5:][::-1] # 取最有潜力的前5个
return recommended_indices
# 假设有所有音乐的特征
all_music_features = music_features # 已经向量化的音乐特征
user_profile = ... # 当前用户的特征向量
recommended_indices = recommend_music(user_profile, all_music_features, model)
print("Recommended Music Indices:", recommended_indices)海浪学长项目示例:



最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 19
19 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)