机器学习——探索k-近邻算法及其分类器实现
探索k-近邻算法及其分类器实现
探索k-近邻算法及其分类器实现
一、前言
在 机器学习 领域,有许多经典的算法可以用于分类问题。而 K近邻(KNN)算法 是其中一种简单而有效的方法。本文将深入探讨KNN算法的原理和实现,并介绍基于KNN算法的分类器的实际应用。
二、什么是KNN算法
KNN(K-Nearest Neighbors)算法,即 k - 近邻算法 ,是一种基本且简单的监督学习算法,既可以用于分类问题,也可以用于回归问题。
基本思想
KNN 算法的核心思想基于 “物以类聚” 的原则,给定一个训练数据集,对于新的输入实例,在训练数据集中找到与该实例最邻近的 k 个实例,然后根据这 k 个实例的类别(分类问题)或数值(回归问题)来决定新实例的类别或数值。
基本要素:
(1)k值的选择: 一般而言,我们只选择样本数据集中前k个最相似的数据 。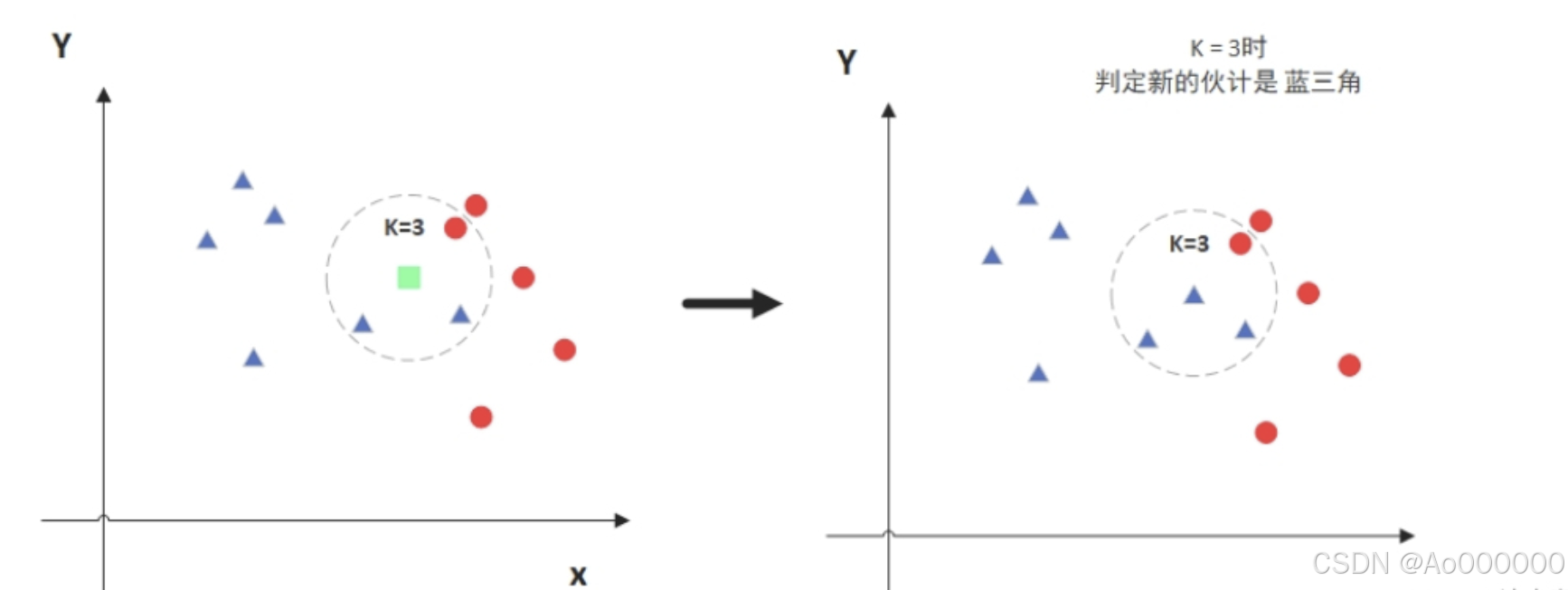
假设图中绿色方性是我们的预测值,令k=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角。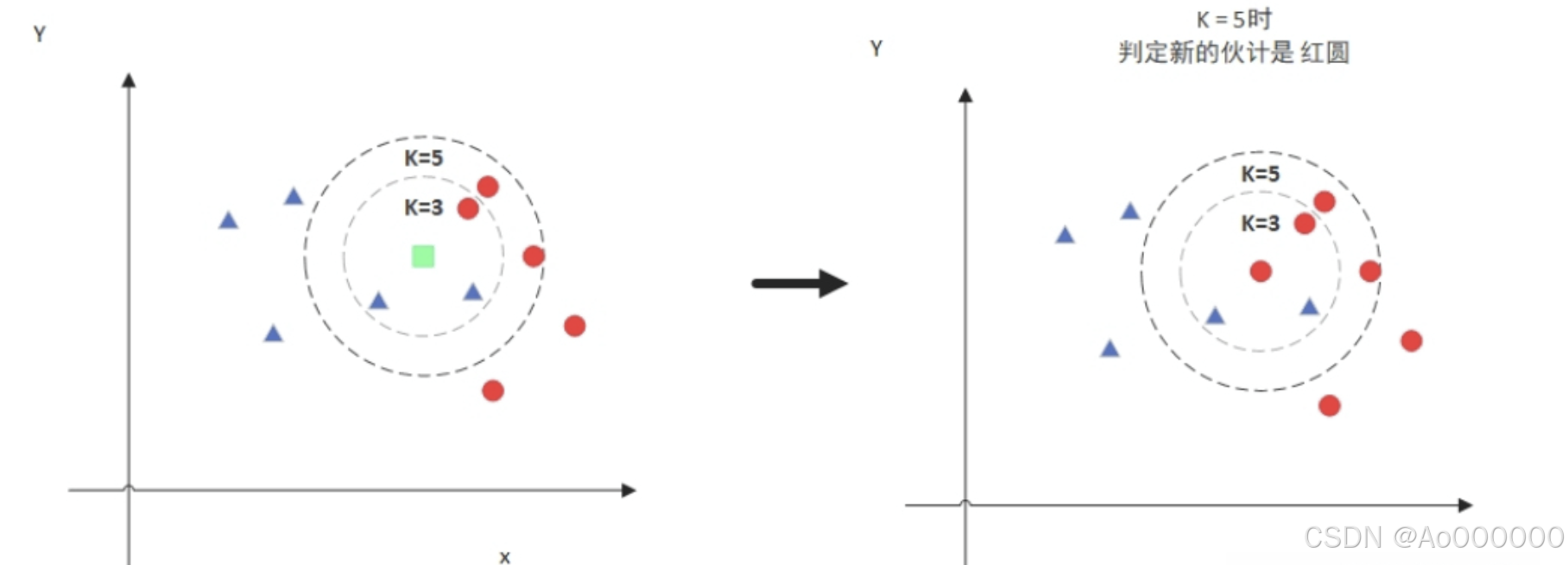
但是,当k=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出k的取值是很重要的。
(2)距离度量:一般采用 欧氏距离、曼哈顿距离 。
算法步骤
对于未知类别属性的数据集中的每个点依次执行一下操作:
(1)计算已知数据集中每个点与当前点之间的距离
(2)按照距离递增排序
(3)选取与当前距离最小的k个点
(4)确定前k个点所在类别的出现频率
(5)返回前k个点出现频率最高的类别作为当前点的预测分类
优缺点
优点:
(1)可以处理分类问题,算法简单易懂
(2)可以免去训练过程
(3)KNN还可以处理回归问题,也就是预测
缺点:
(1)效率低,每一次分类都要对训练数据进行运算
(2)对训练数据依赖特别大,过拟合、欠拟合问题难以权衡
(3)存在维度灾难问题
三、基于k-近邻算法的分类器实现
基本步骤 / 流程
-
收集数据(Data Collection)
获取训练数据集。每个数据点由多个特征(attributes)和对应的标签(label)组成。 -
数据预处理(Data Preprocessing)
对数据进行归一化,将特征缩放到 0 到 1 的范围。目的是避免某些特征因其数值较大而主导距离计算。
-
选择 k 值(Choosing the Value of k)
KNN 算法的关键参数是 k,即选择最近邻的数量。通常,较小的 k 值可能导致过拟合,较大的 k 值可能导致欠拟合。 -
计算距离(Distance Calculation)
对于测试数据点,你需要计算它与训练数据集中每个样本之间的距离。 -
找到 k 个最近邻(Finding the K Nearest Neighbors)
计算完所有数据点的距离后,你将测试数据点与所有训练数据点的距离按从小到大的顺序排列,选择距离最近的 个点。 -
投票分类(Voting)
对这 k 个最近邻样本的标签进行投票:
对于分类问题,选取票数最多的类别作为预测结果。
如果 k 为偶数,则可能需要通过其他方式解决平票问题,如选择距离最近的点的类别。 -
返回预测结果(Return Prediction)
基于投票结果返回类别预测。如果是回归问题,则返回 k 个邻居的均值作为预测结果。
算法实现
(1)问题引入
海伦一直使用在线约会网站寻找适合自己的约会对象。她曾交往过三种类型的人:
- 不喜欢的人
- 一般喜欢的人
- 非常喜欢的人
这些人包含以下三种特征
- 每年获得的飞行常客里程数
- 玩视频游戏所耗时间百分比
- 每周消费的冰淇淋公升数
该网站现在需要尽可能向海伦推荐她喜欢的人,需要我们设计一个分类器,根据用户的以上三种特征,识别出是否该向海伦推荐。
数据集: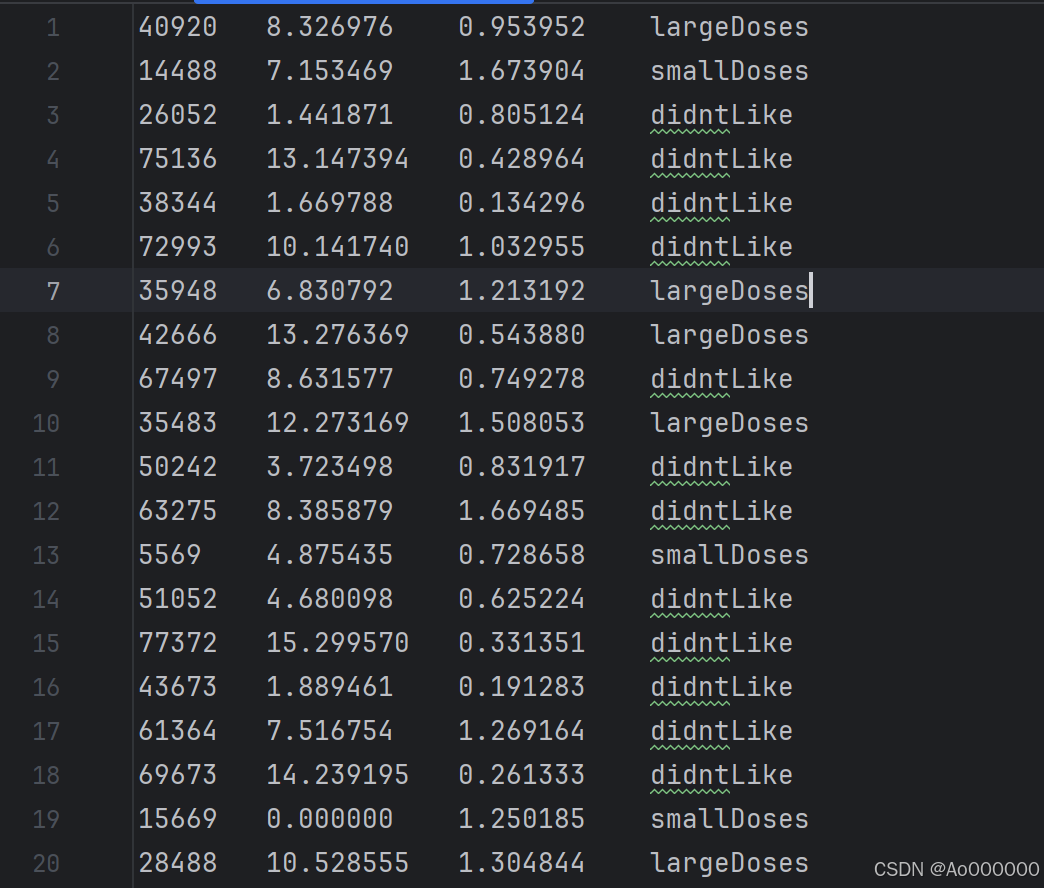
每行的前三个分量分别表示 " 每年获得的飞行常客里程数 " 、 " 玩视频游戏所耗时间百分比 " 、 " 每周消费的冰淇淋公升数 " ; 最后的分量为特征值(largeDoses " 非常喜欢的人 " ; smallDoses " 一般喜欢的人 " ;didntLike " 不喜欢的人 ")
(2)需求概要分析
根据问题,我们可知,样本特征个数为3,样本标签为三类(不喜欢的人、一般喜欢的人、非常喜欢的人)。现需要实现将一个待分类样本的三个特征值输入程序后,能够识别该样本的类别,并且将该类别输出。
(3)程序结构设计说明
根据问题,可以知道程序大致流程如下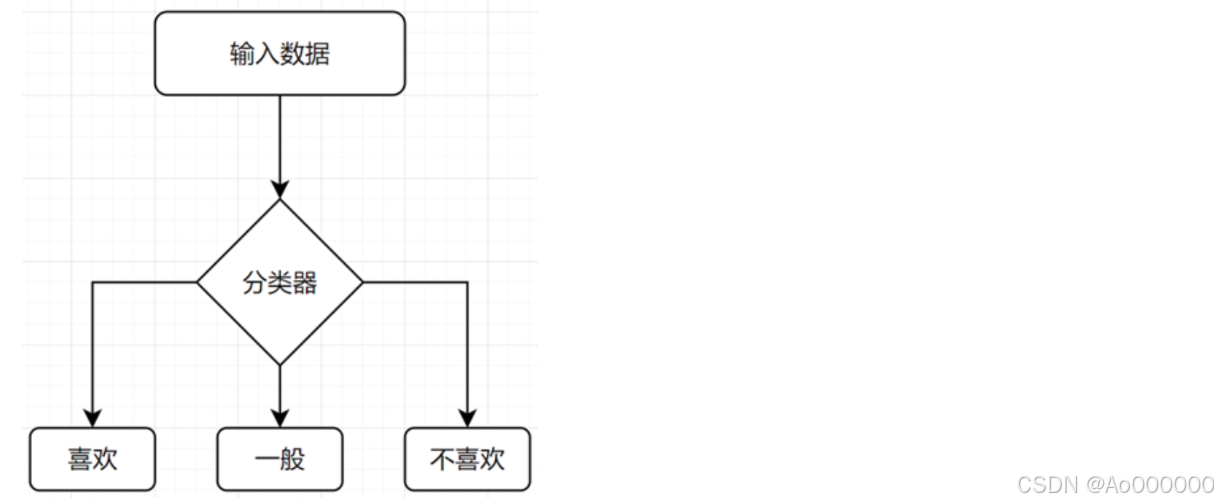
其中输入数据应包含三个值,输出应为喜欢、一般、不喜欢(三个中的一个)。
(4)具体实现步骤
(1)读取数据
函数名:file2matrix(filename)
这个函数用于从文件中读取数据并将其转换为适合处理的矩阵形式。
输入:文件名 filename(格式为文本文件,每一行包含数据和标签,数据用制表符分隔)。
输出:返回两个值
returnMat:一个二维NumPy数组,每一行包含一个数据点的特征(3个特征,分别是 " 视频游戏时间百分比 " " 飞行常客里程 " " 每年冰淇淋消费量 " )。
classLabelVector:一个包含类别标签的列表,标签分别表示 “didntLike” , “smallDoses” , “largeDoses”(分别用数字1、2、3表示)。
import numpy as np
import matplotlib.pyplot as plt
import operator
def file2matrix(filename):
with open(filename, 'r') as fr:
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = np.zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
label = listFromLine[-1]
if label == 'didntLike':
classLabelVector.append(1)
elif label == 'smallDoses':
classLabelVector.append(2)
elif label == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
(2)数据可视化
函数名:showData(datingDataMat, datingLabels)
这个函数用于将数据以3D散点图的形式展示。
输入:
datingDataMat:包含数据特征的矩阵。
datingLabels:数据对应的标签。
输出:
显示一个3D散点图,X、Y和Z轴分别代表3个特征。不同类别的点通过颜色区分。
def showData(datingDataMat, datingLabels):
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d') # 设置为3D图
ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], datingDataMat[:, 2], c=datingLabels, cmap=plt.cm.RdYlBu)
ax.set_xlabel('Feature 1') # 设置X轴标签
ax.set_ylabel('Feature 2') # 设置Y轴标签
ax.set_zlabel('Feature 3') # 设置Z轴标签
plt.show()
(3)数据归一化
函数名:autoNorm(dataSet)
这个函数用于对数据进行归一化处理,使得数据点的特征值都在 [0, 1] 之间。
输入:
dataSet:一个二维NumPy数组,包含了所有的数据特征。
输出:
normDataSet:归一化后的数据集,数据特征值已被缩放到 [0, 1] 区间。
ranges:数据集中每个特征的取值范围(最大值 - 最小值)。
minVals:数据集中每个特征的最小值。
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = (dataSet - minVals) / ranges
return normDataSet, ranges, minVals
(4)KNN分类算法
函数名:classify0(inX, dataSet, labels, k)
这是k-近邻算法的核心实现函数,用于根据距离进行分类。
输入:
inX:一个包含待分类数据点的特征值的向量。
dataSet:包含训练数据集的矩阵,每一行是一个数据点。
labels:一个包含每个数据点标签的列表。
k:选择k个最近邻来进行投票决定类别。
输出:
返回inX对应的类别标签。该类别由k个最近邻中最多投票的标签决定。
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndices = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndices[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
(5)分类器测试
函数名:datingClassTest()
这个函数用于进行交叉验证,测试分类器在测试集上的表现。
输入:无
输出:
通过datingTestSet.txt文件加载数据。
使用10%的数据作为测试集,90%的数据作为训练集。
使用k-近邻算法对每个测试数据点进行分类,并计算总错误率(预测值与实际值不符的比例)。
def datingClassTest():
filename = 'datingTestSet.txt'
hoRatio = 0.10
datingDataMat, datingLabels = file2matrix(filename)
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
errorCount = 0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 4)
print(f'Predicted: {classifierResult}, Actual: {datingLabels[i]}')
if classifierResult != datingLabels[i]:
errorCount += 1
print(f'Total error rate: {errorCount / float(numTestVecs):.2%}')
(6)交互式分类
函数名:classifyPerson()
这个函数用于根据用户输入的特征值预测该人喜欢约会的类型。
输入:
从用户获取三个特征值:percentTats(玩视频游戏的时间百分比)、ffMiles(每年获得的常客航程)、iceCream(每年冰淇淋消费量)。
输出:
使用k-近邻算法预测该人的喜欢程度(‘not at all’, ‘in small doses’, ‘in large doses’)。
输出预测结果,并根据预测结果告诉用户该人可能喜欢的约会类型。
def classifyPerson():
filename = 'datingTestSet.txt'
resultList = ['not at all', 'in small doses', 'in large doses']
percentTats = float(input('Percentage of time spent playing video games? '))
ffMiles = float(input('Frequent flier miles earned per year? '))
iceCream = float(input('Liters of ice cream consumed per year? '))
datingDataMat, datingLabels = file2matrix(filename)
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = np.array([ffMiles, percentTats, iceCream])
classifierResult = classify0((inArr - minVals) / ranges, normMat, datingLabels, 4)
print(f'You will probably like this person: {resultList[classifierResult - 1]}')
(7)主函数
if name == “main”:
这个部分是主程序,执行以下步骤:
· 通过file2matrix函数加载数据。
· 调用showData显示数据的3D散点图。
· 调用datingClassTest进行分类器的交叉验证测试,计算错误率。
· 调用classifyPerson根据用户输入的特征预测其喜欢的约会类型。
if __name__ == "__main__":
filename = 'datingTestSet.txt'
datingDataMat, datingLabels = file2matrix(filename)
showData(datingDataMat, datingLabels) # 显示3D散点图
datingClassTest()
classifyPerson()
(5)结果分析
· 运行结果会显示出一个3D的散点图
· 前面会显示出一些数据集训练的结果:
· 并可以通过输入测试值进行预测:
(6)不同k值的影响
-
k值过小(如k=1)
优点:模型对训练数据的拟合能力很强,能够捕捉到数据的局部特征。决策边界非常复杂,能够适应训练数据中的噪声和异常值。
缺点:容易过拟合,泛化能力差。对噪声敏感,容易受到异常值的影响。在测试集上的表现可能较差。 -
k 值适中(如 k=3 到 k=10)
优点:模型对训练数据的拟合能力适中,既能捕捉到数据的局部特征,又能保持一定的泛化能力。决策边界相对平滑,能够较好地平衡偏差和方差。在测试集上的表现通常较好。
缺点:需要根据具体数据集选择合适的 k 值。 -
k 值过大(如 k=50 或更大)
优点:模型对训练数据的拟合能力较弱,泛化能力较强。决策边界非常平滑,能够减少噪声和异常值的影响。
缺点:容易欠拟合,无法捕捉到数据的局部特征。在测试集上的表现可能较差。 -
代码中 k 值的实验
在代码中,k 值是通过 classify0 函数的参数传递的。可以通过修改 k 值来观察其对分类结果的影响。
算法改进
对于一个KNN算法来说
假设给定N个训练样本,每个样本为M维向量 / 特征
· 当k=1时,时间复杂度为O(NM)
· 当k=n时,时间复杂度为O(NM)
为了降低时间复杂度,我们可以采用 KD树 策略
四、总结
K近邻算法是一种简单而有效的分类算法,它通过测量样本之间的距离来对新样本进行分类。基于KNN算法的分类器在实际应用中具有广泛的应用,可以用于图像分类、文本分类、推荐系统等领域。


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)