自然语言处理(10:改进版word2vec的学习以及总结)
到目前为止,我们进行了word2vec的改进。首先说明了Embedding层,又介绍了负采样的方法,然后对这两者进行了实现。现在我们进一步来实现进行了这些改进的神经网络,并在PTB数据集上进行学习,以获得更加实用的单词的分布式表示。下面开始更加进一步的改进,如果遇到问题,可以问Deepseek,我都觉得有些地方不需要我来解答了,哈哈!当然最重要的,希望能留下各位的三连加关注!!!一、这里的类推问题
系列文章目录
第一章 1:同义词词典和基于计数方法语料库预处理
第一章 2:基于计数方法的分布式表示和假设,共现矩阵,向量相似度
第一章 3:基于计数方法的改进以及总结
第二章 1:word2vec
第二章 2:word2vec和CBOW模型的初步实现
第二章 3:CBOW模型的完整实现
第二章 4:CBOW模型的补充和skip-gram模型的理论
第三章 1:word2vec的高速化(CBOW的改进)
第三章 2:word2vec高速化(CBOW的二次改进)
第三章 3:改进版word2vec的学习以及总结
第四章 1:RNN(RNN的前置知识和引入)
第四章 2:RNN(RNN的正式介绍)
前言
到目前为止,我们进行了word2vec的改进。首先说明了Embedding层,又介绍了负采样的方法,然后对这两者进行了实现。现在我们进一步来实现进行了这些改进的神经网络,并在PTB数据集上进行学习,以获得更加实用的单词的分布式表示。下面开始更加进一步的改进,如果遇到问题,可以问Deepseek,我都觉得有些地方不需要我来解答了,哈哈!当然最重要的,希望能留下各位的三连加关注!!!
一、改进版word2vec的学习
1.CBOW模型的实现
这里,我们将改进上一章的简单的SimpleCBOW类,来实现CBOW模型。() 改进之处在于使用Embedding层(在这一节自然语言处理(8:word2vec的高速化(CBOW的改进))-CSDN博客)和Negative Sampling Loss层。(这一层在上一节实现了:自然语言处理(9:word2vec的高速化(CBOW的二次改进))-CSDN博客)此外,我 们将上下文部分扩展为可以处理任意的窗口大小。 改进版的CBOW类的实现如下所示。首先,我们来看一下初始化方法。
from negative_sampling_layer import NegativeSamplingLoss
from common.layers import Embedding
import numpy as np
class CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
# 初始化W
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
# 生成层
self.in_layers = []
for i in range(2 * window_size):
layers = Embedding(W_in)
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
# 将所有的权重和梯度整理到列表中
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.params += layer.params
# 将单词分布式表示设置为成员变量
self.word_vecs = W_in
def forward(self, contexts, target):
"""
见下面
"""
pass
这个初始化方法有4个参数。vocab_size是词汇量,hidden_size是中间层的神经元个数,corpus是单词ID列表。另外,通过window_size指定上下文的大小,即上下文包含多少个周围单词。如果window_size是2,则目标词的左右2个单词(共4个单词)将成为上下文。
在权重的初始化结束后,继续创建层。这里,创建2 * window_size个 Embedding 层,并将其保存在成员变量in_layers中。然后,创建Negative Sampling Loss 层。
在创建好层之后,将神经网络中使用的参数和梯度放入成员变量params 和grads 中。另外,为了之后可以访问单词的分布式表示,将权重W_in设置 为成员变量word_vecs。下面,我们来看一下正向传播的forward()方法和反 向传播的backward()方法:
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None这里的实现只是按适当的顺序调用各个层的正向传播(或反向传播), 这是对上一章的SimpleCBOW类的自然扩展。不过,虽然forward (contexts, target) 方法取的参数仍是上下文和目标词,但是它们是单词ID形式的(上 一章中使用的是one-hot向量,不是单词ID),具体示例如图:
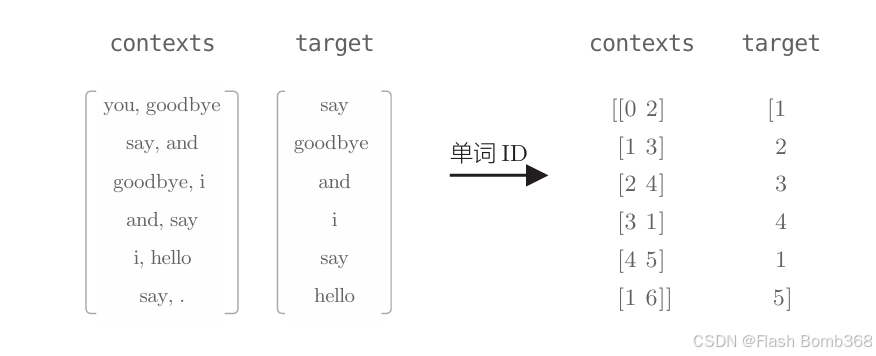
上图的右侧显示的单词ID列表是contexts和target的例子。可以看出,contexts 是一个二维数组,target是一个一维数组,这样的数据被输 入forward(contexts, target) 中。以上就是 CBOW 类的说明。
2.CBOW模型的学习代码
最后,我们来实现CBOW模型的学习部分。其实只是复用一下神经网络的学习,如下所示:
import pickle
from common.trainer import Trainer
from common.optimizer import Adam
from cbow import CBOW # 刚刚上面实现的CBOW类
from skip_gram import SkipGram
from common.util import create_contexts_target, to_cpu
from dataset import ptb
import numpy as np
# 设定超参数
window_size = 5
hidden_size = 100
batch_size = 100
max_epoch = 10
# 读入数据
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
if config.GPU:
contexts, target = to_gpu(contexts), to_gpu(target)
# 生成模型等
model = CBOW(vocab_size, hidden_size, window_size, corpus)
# model = SkipGram(vocab_size, hidden_size, window_size, corpus)
optimizer = Adam()
trainer = Trainer(model, optimizer)
# 开始学习
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()
# 保存必要数据,以便后续使用
word_vecs = model.word_vecs
if config.GPU:
word_vecs = to_cpu(word_vecs)
params = {}
params['word_vecs'] = word_vecs.astype(np.float16)
params['word_to_id'] = word_to_id
params['id_to_word'] = id_to_word
pkl_file = 'cbow_params.pkl' # or 'skipgram_params.pkl'
with open(pkl_file, 'wb') as f:
pickle.dump(params, f, -1)最后的运行结果类似如下:
本次的CBOW模型的窗口大小为5,隐藏层的神经元个数为100。虽 然具体取决于语料库的情况,但是一般而言,当窗口大小为2~10、中间 层的神经元个数(单词的分布式表示的维数)为50~500时,结果会比较好。 稍后我们会对这些超参数进行讨论。
这次我们利用的PTB语料库比之前要大得多,因此学习需要很长时间 (半天左右),如果要使用GPU运行,你可以尝试修改一下啊,我就不会弄了,自己学习的时候我觉得没必要GPU,当然实现项目训练的时候,肯定得在Nvidia GPU上运行(至少目前是这样,本人这里预言一波,再过10几年,甚至不到,老黄必然会遭反噬,因为“物极必反”)。
在学习结束后,取出权重(输入侧的权重),并保存在文件中以备后用 (用于单词和单词ID之间的转化的字典也一起保存)。这里,使用Python 的pickle 功能进行文件保存。pickle可以将Python代码中的对象保存到文 件中(或者从文件中读取对象)。
3.CBOW模型的评价
现在,我们来评价一下上一节学习到的单词的分布式表示。这里我们使用实现的most_similar()函数(下面有),显示几个单词的最接近的单词:
from common.util import most_similar, analogy # 以下为这两个函数
import pickle
"""
def analogy(a, b, c, word_to_id, id_to_word, word_matrix, top=5, answer=None):
for word in (a, b, c):
if word not in word_to_id:
print('%s is not found' % word)
return
print('\n[analogy] ' + a + ':' + b + ' = ' + c + ':?')
a_vec, b_vec, c_vec = word_matrix[word_to_id[a]], word_matrix[word_to_id[b]], word_matrix[word_to_id[c]]
query_vec = b_vec - a_vec + c_vec
query_vec = normalize(query_vec)
similarity = np.dot(word_matrix, query_vec)
if answer is not None:
print("==>" + answer + ":" + str(np.dot(word_matrix[word_to_id[answer]], query_vec)))
count = 0
for i in (-1 * similarity).argsort():
if np.isnan(similarity[i]):
continue
if id_to_word[i] in (a, b, c):
continue
print(' {0}: {1}'.format(id_to_word[i], similarity[i]))
count += 1
if count >= top:
return
def most_similar(query, word_to_id, id_to_word, word_matrix, top=5):
'''相似单词的查找
:param query: 查询词
:param word_to_id: 从单词到单词ID的字典
:param id_to_word: 从单词ID到单词的字典
:param word_matrix: 汇总了单词向量的矩阵,假定保存了与各行对应的单词向量
:param top: 显示到前几位
'''
if query not in word_to_id:
print('%s is not found' % query)
return
print('\n[query] ' + query)
query_id = word_to_id[query]
query_vec = word_matrix[query_id]
vocab_size = len(id_to_word)
similarity = np.zeros(vocab_size)
for i in range(vocab_size):
similarity[i] = cos_similarity(word_matrix[i], query_vec)
count = 0
for i in (-1 * similarity).argsort():
if id_to_word[i] == query:
continue
print(' %s: %s' % (id_to_word[i], similarity[i]))
count += 1
if count >= top:
return
"""
pkl_file = 'cbow_params.pkl'
# pkl_file = 'skipgram_params.pkl'
with open(pkl_file, 'rb') as f:
params = pickle.load(f)
word_vecs = params['word_vecs']
word_to_id = params['word_to_id']
id_to_word = params['id_to_word']
# most similar task
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)
# analogy task
print('-'*50)
analogy('king', 'man', 'queen', word_to_id, id_to_word, word_vecs)
analogy('take', 'took', 'go', word_to_id, id_to_word, word_vecs)
analogy('car', 'cars', 'child', word_to_id, id_to_word, word_vecs)
analogy('good', 'better', 'bad', word_to_id, id_to_word, word_vecs)
运行上面的代码,可以得以下结果(具体结果会根据各自的学习环境而 有所差异)
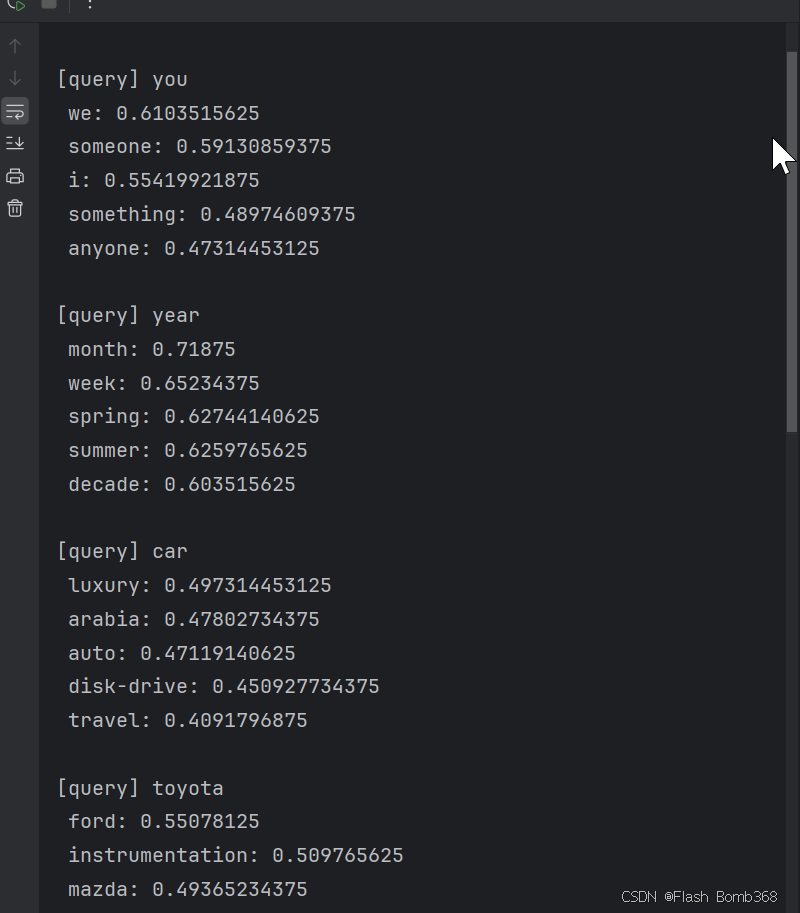
我们看一下结果。首先,在查询you的情况下,近似单词中出现了人 称代词i(=I)和we等。接着,查询year,可以看到month、week等表示时间区间的具有相同性质的单词。然后,查询toyota,可以得到ford、 mazda 和 nissan 等表示汽车制造商的词汇。从这些结果可以看出,由 CBOW模型获得的单词的分布式表示具有良好的性质。 此外,由word2vec获得的单词的分布式表示不仅可以将近似单词聚 拢在一起,还可以捕获更复杂的模式,其中一个具有代表性的例子是因 “king − man +woman =queen”而出名的类推问题(类比问题)。更准确地说,使用word2vec的单词的分布式表示,可以通过向量的加减法来解决类推问题。
如下图所示,要解决类推问题,需要在单词向量空间上寻找尽可能 使“man → woman”向量和“king → ?”向量接近的单词。
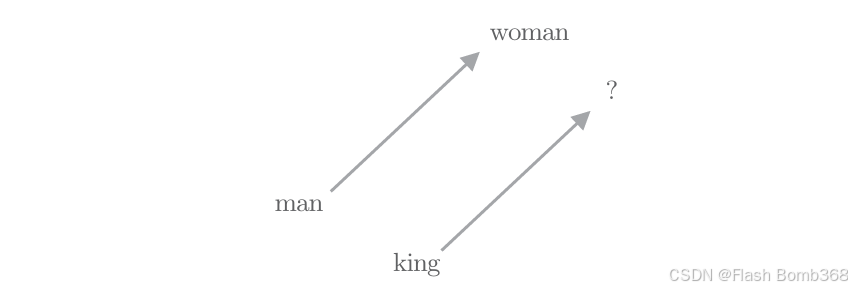
这里用vec(‘man’)表示单词man的分布式表示(单词向量)。如此一来, 上图中要求的关联性可以用数学式表示为vec(‘woman’)−vec(‘man’)= vec(?) − vec(‘king’)。将其变形,有vec(‘king’) + vec(‘woman’) − vec(‘man’) = vec(?)。也就是说,我们的任务是找到离向量vec(‘king’)+vec(‘woman’) − vec(‘man’) 最近的单词向量。
现在,我们来实际解决几个类推问题。下面是4个问题(代码的输出结果):
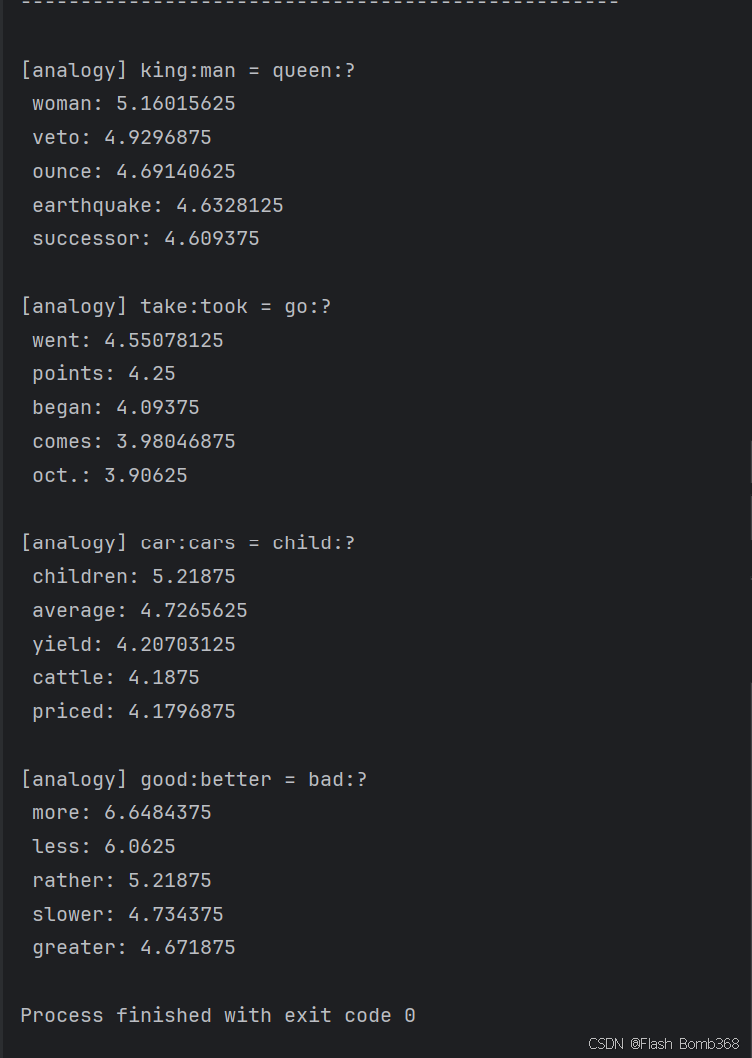
结果符合我们的预期。第1个问题是“king : man = queen : ?”,这里 正确地回答了“woman”。 第 2个问题是“take : took = go : ?”,也按预期 回答了“went”。这是捕获了现在时和过去时之间的模式的证据,可以解释 为单词的分布式表示编码了时态相关的信息。
从第3题可知,单词的单数形 式和复数形式之间的模式也被正确地捕获。可惜的是,对于第4题“good : better = bad : ?”,并没能回答出“worse”。不过,看到more、less等比较 级的单词出现在回答中,说明这些性质也被编码在了单词的分布式表示中。
像这样,使用word2vec获得的单词的分布式表示,可以通过向量的加减法求解类推问题。不仅限于单词的含义,它也捕获了语法中的模式。另 外,我们还在word2vec的单词的分布式表示中发现了一些有趣的结果,比如good和best之间存在better这样的关系。
总结
这里的类推问题的结果看上去非常好。不过遗憾的是,它是特意选出来的能够被顺利解决的问题。
实际上,很多问题都无法 获得预期的结果。这是因为PTB数据集的规模还是比较小。如 果使用更大规模的语料库,可以获得更准确、更可靠的单词的分 布式表示,从而大大提高类推问题的准确率。
这一节我们实现了CBOW模型的最后的改进(当然你也可以在这个基础上继续改进),并且进行了实例化。还是那句话,希望能给博主给个大大的赞加关注!!!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)