基于无标签数据的自监督学习理论研究与分析
无标签数据(Unlabeled Data)指未被人工标注或缺乏明确语义信息的数据。例如,一段未标注情感倾向的文本、一张未标记物体类别的图像,或一组未分类的传感器信号。这些数据本身仅包含原始特征(如像素值、文本词汇、时间序列等),但缺乏与特定任务直接相关的监督信号(如分类标签、回归目标)。无标签数据规模通常远超有标签数据,传统算法(如基于全连接层的神经网络)需消耗大量计算资源。半监督学习或自监督学习
目录
3.2 对比学习(Contrastive Learning)
自监督学习是一种机器学习方法,它利用无标签数据进行学习,通过自动生成监督信号来训练模型,从而挖掘数据中的内在结构和模式。自监督学习的核心是将无标签数据转化为有监督学习的形式,通过定义一些基于数据本身的预测任务,让模型从数据中自动学习特征表示。这些预测任务通常是根据数据的固有属性或潜在结构设计的,例如图像中的像素关系、文本中的上下文信息等。模型通过预测这些由数据自身生成的标签来学习,从而捕捉到数据的内在规律。
0.无标签数据的定义
无标签数据(Unlabeled Data)指未被人工标注或缺乏明确语义信息的数据。例如,一段未标注情感倾向的文本、一张未标记物体类别的图像,或一组未分类的传感器信号。这些数据本身仅包含原始特征(如像素值、文本词汇、时间序列等),但缺乏与特定任务直接相关的监督信号(如分类标签、回归目标)。
无标签数据规模通常远超有标签数据,传统算法(如基于全连接层的神经网络)需消耗大量计算资源。
半监督学习或自监督学习模型的训练需平衡标注与未标注数据的利用效率。
1.常见的自监督任务
图像修复:将图像中的部分区域遮挡或损坏,让模型预测被遮挡部分的内容。例如,随机遮挡图像中的一些方块,模型需要根据周围未被遮挡的像素信息来恢复出被遮挡区域的图像。这迫使模型学习图像的局部和全局结构,理解不同区域之间的语义关系。
图像旋转预测:将图像随机旋转一定角度,让模型预测旋转的角度。模型需要学习图像的特征,以便能够识别出不同旋转状态下的图像,从而捕捉到图像的方向信息和几何不变性。
以图像旋转预测为例:

掩码语言模型(Masked Language Model,MLM):在文本中随机遮挡一些单词或字符,让模型根据上下文预测被遮挡的部分。例如,对于句子 “The dog is [MASK] in the park”,模型需要预测出 “running” 等合适的单词。通过这种方式,模型可以学习到单词之间的语义关系和上下文信息,理解文本的语法和语义结构。
下一句预测(Next Sentence Prediction,NSP):给定两个句子,让模型判断第二个句子是否是第一个句子的下一句。这有助于模型学习句子之间的逻辑关系和连贯性,捕捉文本的篇章结构信息。
以掩码语言模型为例:

2.自监督学习的基本原理
在传统监督学习中,数据标注成本占比通常超过 70%(IDC 2024 报告)。自监督学习通过构建代理任务(Pretext Task),将无标签数据转化为 "伪监督信号"。其核心数学框架可表示为:

根据互信息最大化(Mutual Information Maximization)理论,模型需要学习输入数据的高维表示h,使得h与原始数据x的互信息I(h;x)最大化。对比学习的 InfoNCE 损失函数即为该原理的具体实现:
3.自监督学习核心技术体系
3.1 生成式自监督
变分自编码器(VAE)通过最大化证据下界(ELBO)学习数据分布:

GAN通过对抗训练学习生成器G和判别器D:
![]()
生成式自监督主要应用于:
1.图像修复:通过部分遮挡图像生成完整图像
2.文本生成:基于前向文本预测后续内容
3.异常检测:重建误差作为异常评分
3.2 对比学习(Contrastive Learning)
Google提出的SimCLR通过数据增强构建正样本对:
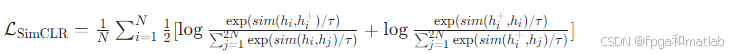
字节跳动的MoCo引入动量编码器和队列机制:
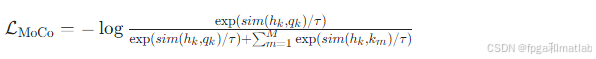
对比学习主要应用于:
1.图像分类:在 ImageNet 上实现无监督预训练
2.视频理解:通过帧间对比学习时序特征
3.点云分析:3D 数据增强与特征对齐
3.3 掩码预测(Masked Prediction)
BERT的MLM目标函数:
![]()
掩码预测主要应用于:
1.多模态理解:图文联合掩码训练
2.分子结构预测:原子级掩码建模
3.时间序列预测:未来值掩码推断
自监督学习通过构建代理任务,将无标签数据转化为可利用的监督信号,在降低标注依赖的同时提升模型泛化能力。其数学基础涵盖信息论、博弈论和统计学习理论,应用场景已扩展至几乎所有 AI 领域。未来随着理论的完善和硬件的进步,自监督学习有望成为实现通用人工智能的关键技术之一。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)